作者: Lucien-盧西恩 原文來源: https://tidb.net/blog/e7034d1b
Java 應用開發技術發展歷程
在業務開發早期,用 Java 借助 JDBC 進行數據庫操作,雖能實現基本交互,但需手動管理連接、編寫大量 SQL 及處理結果集,開發與維護成本高且易出錯。隨著業務發展,數據庫表結構復雜,這種方式弊端凸顯。為解決該問題,ORM 技術誕生。它將數據庫表映射為 Java 類,使開發者能用面向對象方式操作數據庫,提高開發效率、降低耦合度。
而企業級應用規模擴大、業務邏輯變復雜后,需要更有效的管理和組織。Spring 框架應運而生,它提供 IoC 和 AOP 等核心功能。在數據訪問上,Spring 可整合 JDBC,通過 spring-JDBC、spring-TX 簡化使用;也能與 ORM 框架集成,如 Spring Data JPA。其還結合事務管理功能保證數據一致性,讓開發者能依業務選合適訪問方式,更好應對業務需求。
名詞解釋:
- ORM(對象關系映射,Object Relational Mapping):可以把它想象成一座橋梁,連接著 Java 這樣的編程語言和數據庫。在編程中,我們習慣用對象來處理數據,而數據庫是以表和字段的形式存儲數據。ORM 就負責把 Java 里的對象和數據庫中的表對應起來,讓我們能用面向對象的方式操作數據庫,不用再寫大量復雜的 SQL 語句。比如,有一個 “用戶” 對象,ORM 能自動把這個對象的屬性(像用戶名、密碼等)和數據庫里 “用戶表” 的字段對應上,進行保存、讀取等操作 。
- IoC(控制反轉,Inversion of Control):這就好比你開一家餐廳,以前是自己親自去買菜、做菜、上菜,所有事情都得自己操心。現在通過 IoC,你把這些工作交給專業的供應商和服務員,你只需要告訴他們你的需求,具體的執行就由他們負責。在 Java 開發里,IoC 就是把對象的創建和管理工作從代碼中剝離出來,交給專門的容器去處理。這樣一來,代碼變得更簡潔,各個模塊之間的依賴關系也更好管理,提高了代碼的可維護性和可擴展性。
- AOP(面向切面編程,Aspect - Oriented Programming):傳統的編程方式就像切蛋糕,按照業務功能一塊一塊地切;而 AOP 則是橫著切,把一些通用的功能,比如日志記錄、事務管理、權限控制等,單獨拿出來做成 “切面”。這些切面可以在不修改原有業務代碼的基礎上,動態地添加到程序中。比如,在一個電商系統里,不管是用戶下單、支付還是查詢訂單,都需要記錄日志。使用 AOP,就可以把日志記錄功能做成一個切面,統一添加到各個業務方法上,而不用在每個方法里都重復寫日志記錄代碼 。
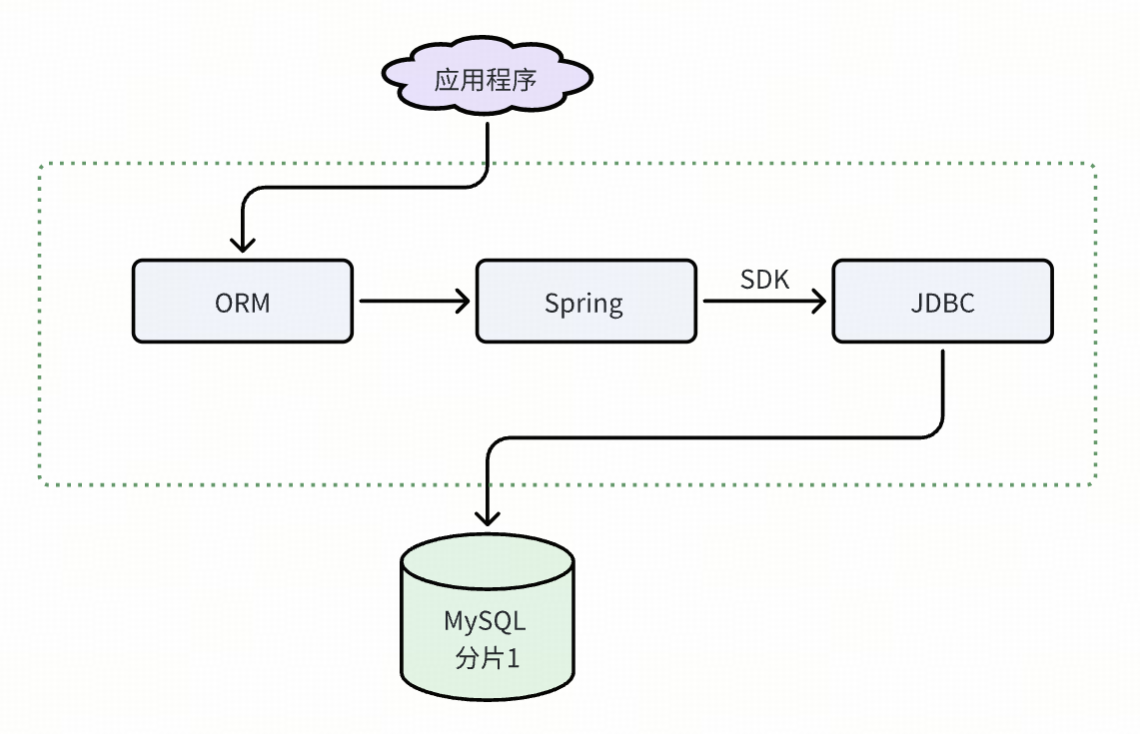
在數字化浪潮下,企業數據量呈爆炸式增長,傳統數據庫在處理海量數據和高并發訪問時力不從心。同時,企業為提升業務靈活性和擴展性,需分布式數據庫解決方案。MyCat 等分布式數據庫中間件應運而生,作為一款專注于開源分布式數據庫中間件,它能將數據分散存儲于多個節點,提高系統性能與可擴展性。
分布式數據庫中間件位于應用程序與數據庫之間,承擔性能優化、高可用保障、負載均衡、數據分片管理等重任。比如 ShardingSphere 和 MyCAT,支持數據分片、讀寫分離,能應對海量數據和高并發。它還負責管理數據庫連接,保障數據一致性與安全性,降低應用與數據庫耦合,為 Java 開發構建穩定、高效的數據交互架構。
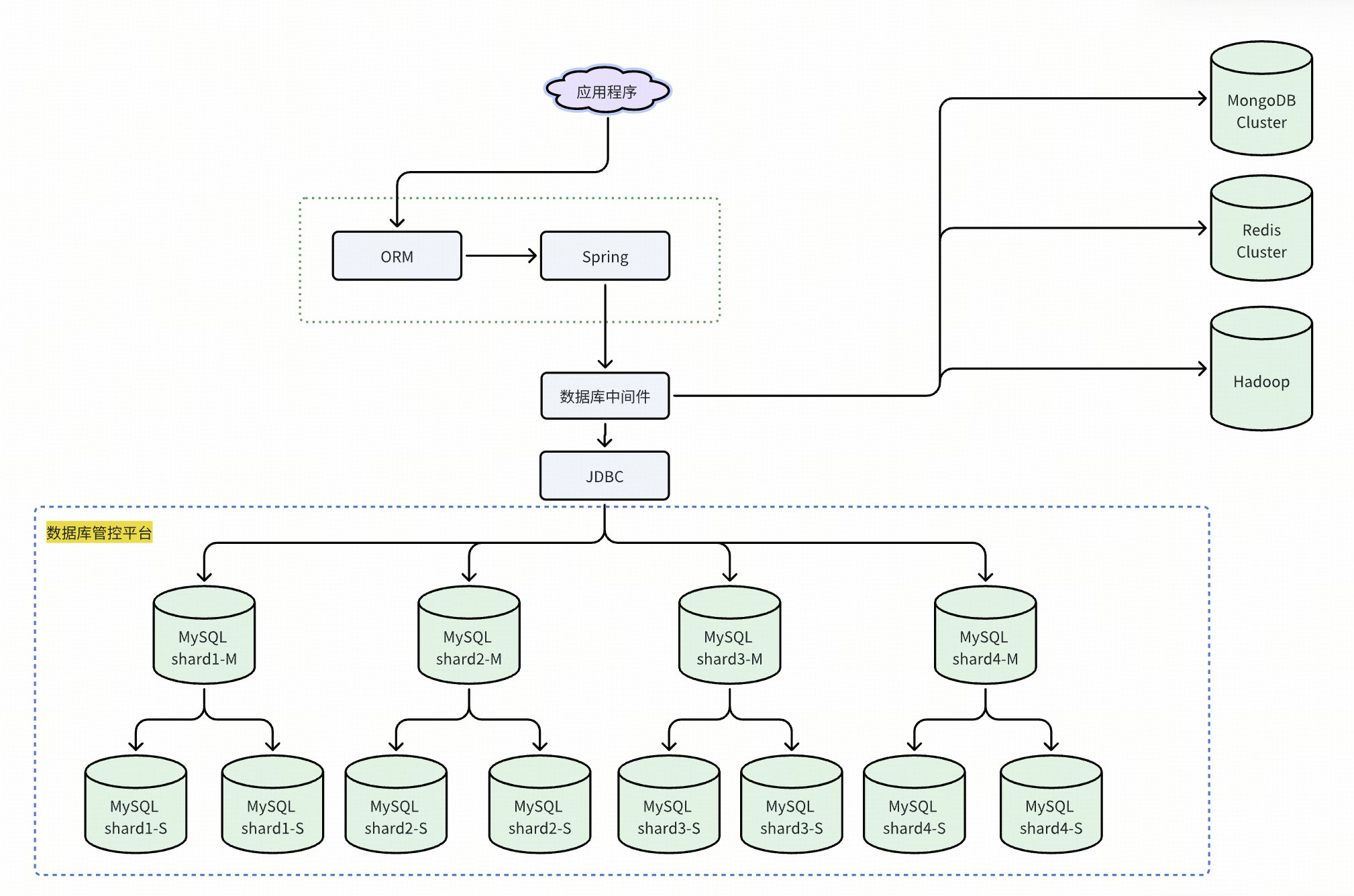
MyCat 等數據庫中間件產品具備諸多優勢。它支持多種數據分片策略,如范圍、哈希、枚舉分片等,可根據業務需求靈活分配數據;提供讀寫分離功能,自動將讀寫請求路由到不同數據庫節點,減輕主庫壓力,提升系統并發處理能力;還支持分布式事務,采用兩階段提交協議,保障數據一致性。此外,像專注于 MySQL 數據庫中間件產品如 DBLE 完全兼容 MySQL 協議和語法,應用程序無需大幅修改代碼即可集成,降低了企業使用成本和技術門檻。
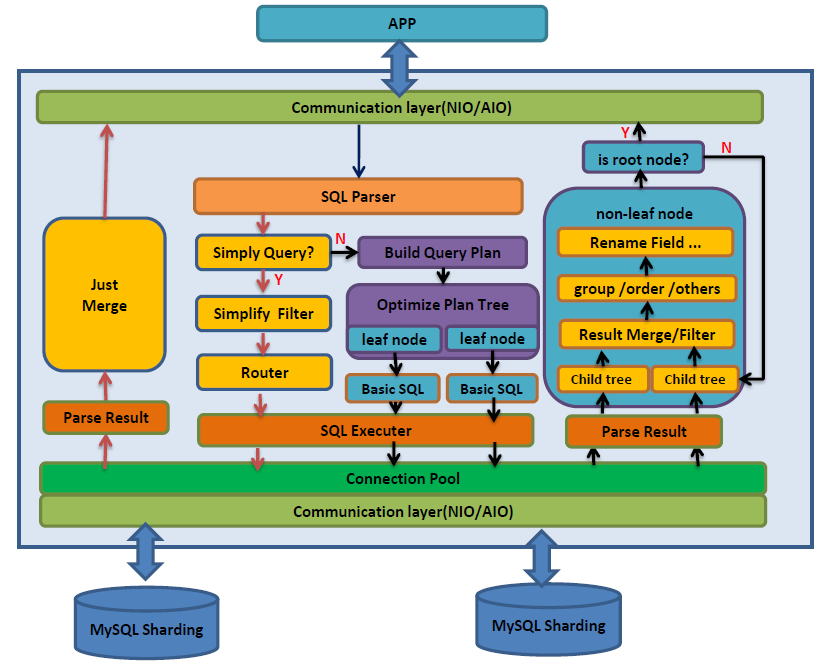
在電商、金融等行業,基于開源 MyCat 分布式數據庫中間件開發企業級數據庫中間件廣泛應用。電商平臺借助數據庫中間件的數據分片和讀寫分離功能,能輕松應對大促期間的高并發訪問。金融系統利用其分布式事務特性,確保交易數據的準確與完整。客戶端層的 Java 應用程序有與數據庫交互需求,通過 JDBC 層的 JDBC 驅動與數據庫中間件通信,JDBC 驅動將 Java 應用的 SQL 請求轉換為適合與數據庫中間件交互的格式。數據庫中間件核心層的 SQL 解析器接收請求后進行語法和語義分析并轉化為抽象語法樹,路由計算模塊依據解析結果和分片規則算出路由節點,數據分片模塊按結果將請求分發到數據庫驅動層。數據庫驅動層包含對應不同 MySQL 數據庫節點的 MySQL 驅動以及可選的其他數據庫驅動,負責將數據庫中間件的 SQL 語句轉換為對應數據庫協議格式并處理結果返回。數據庫層有 MySQL 數據庫節點和可選的其他數據庫存儲實際數據。數據庫中間件核心層的結果合并模塊收集各驅動返回的結果進行合并處理,事務管理模塊管理分布式事務保證數據一致性,最終處理結果經 JDBC 驅動返回給 Java 應用程序。
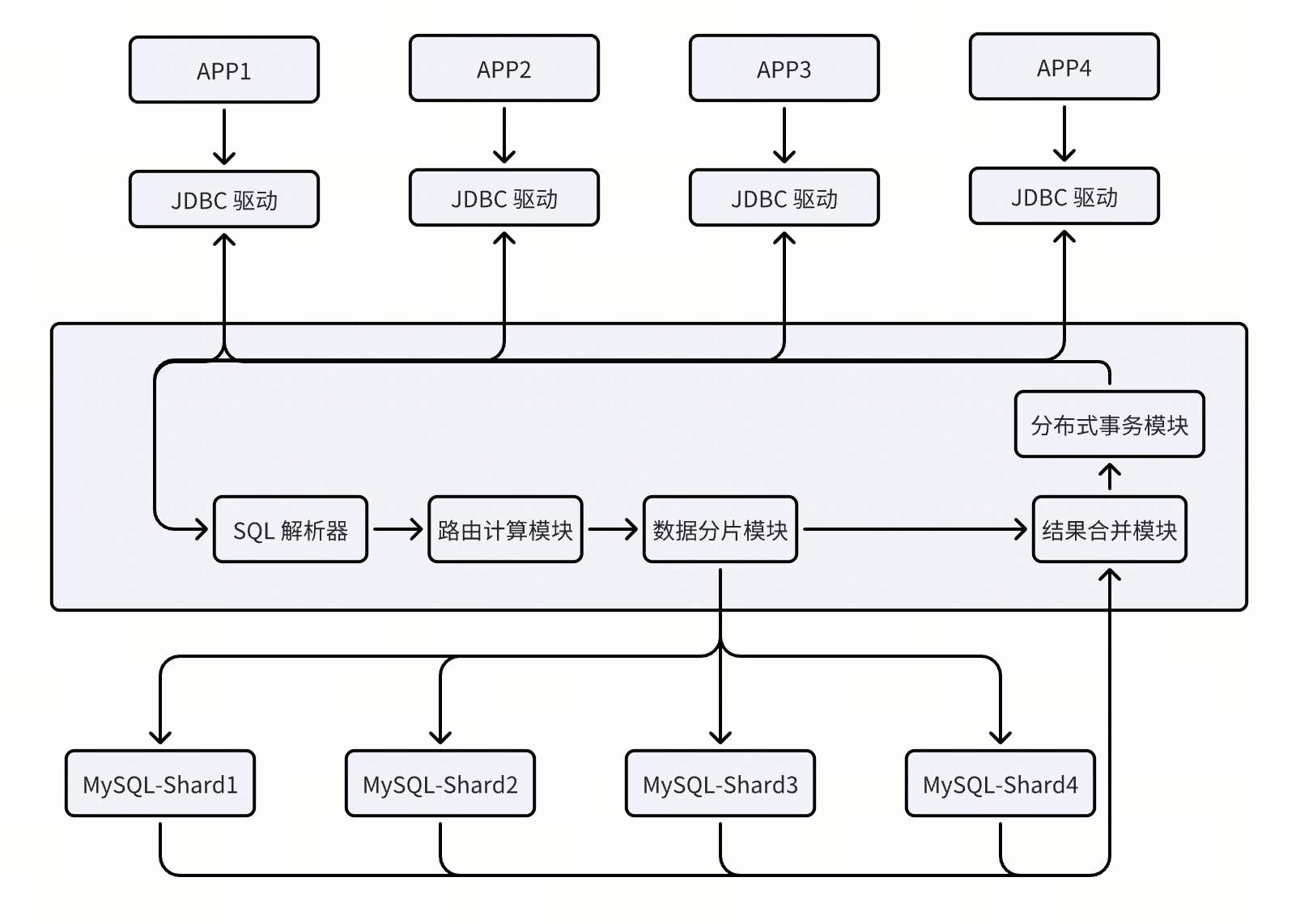
業務開發技術不同階段對比
從代碼開發維護成本的層面展開對比,在 20 世紀末至 21 世紀初這段時期,由于互聯網基礎設施持續完善,互聯網企業以及傳統企業的數字化轉型順勢而生,各式各樣的業務架構和數據架構紛紛涌現,用于支撐業務的發展與迭代。伴隨業務數據處理請求呈現井噴式增長且不斷演進,對于分布式架構以及分布式數據庫的需求變得越發顯著。在數據處理架構進行迭代以滿足當下業務需求的過程中,也遭遇了諸多問題。通過下面的列表進行概括,可以知曉典型場景中面臨的挑戰。
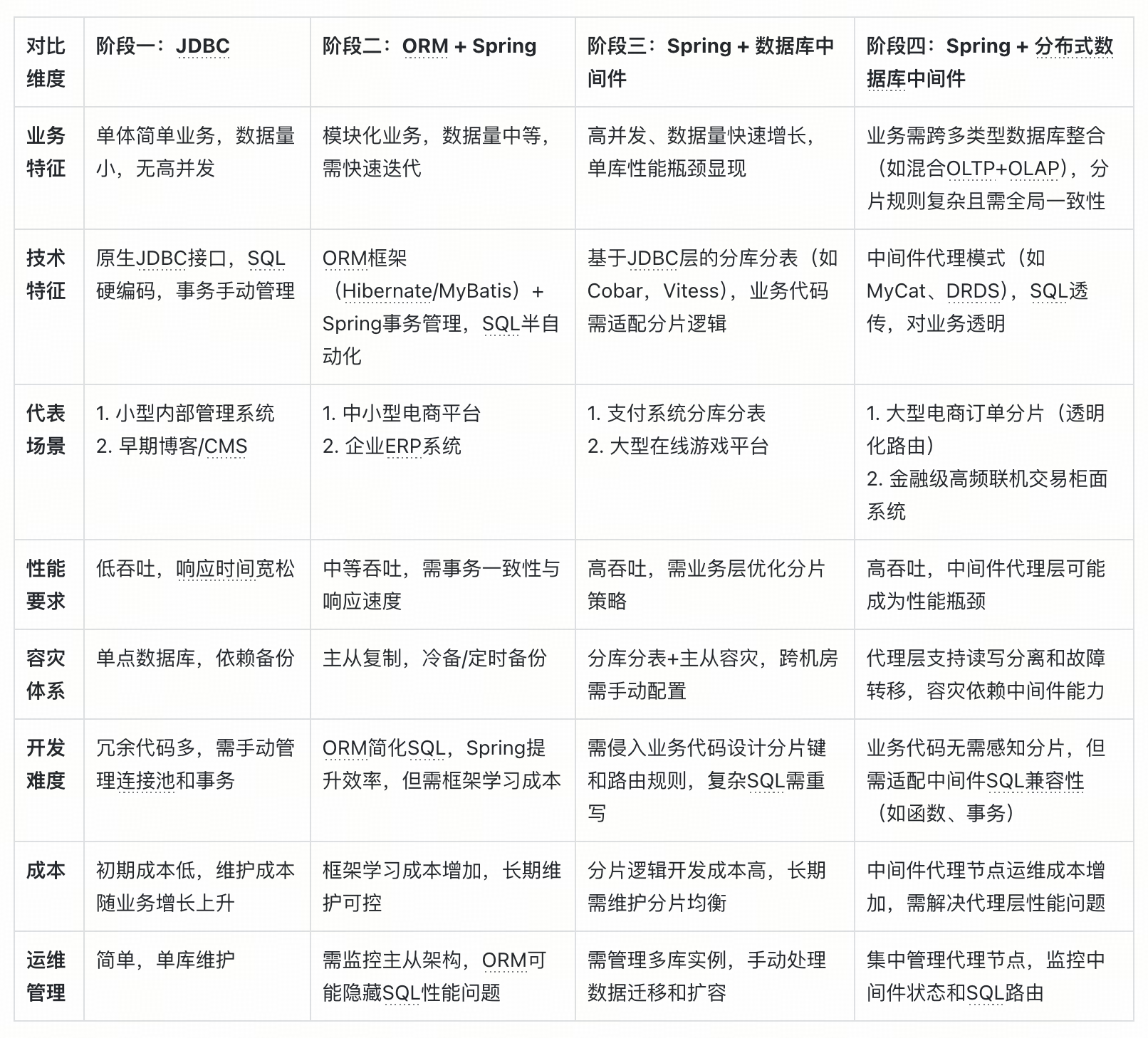
以上 4 類數據架構方案中,簡單總結出以下幾類顯著問題:
- 直連 JDBC 架構存在手動處理數據庫連接、SQL 編寫及結果解析導致開發成本高,且應對表結構和業務變化時維護成本大的問題,適合在小規模高頻量化交易場景快速業務上線支撐;
- ORM + Spring 架構有 ORM 映射性能損耗及學習框架成本高,但是開發效率提升加快更大規模多模態業務的搭建,在構建 O2O 小規模電商場景類業務應用較多。
- Spring + 數據庫中間件架構面臨系統復雜度和故障排查難度增加帶來的成本提升,隨著業務井噴式增長,多模態業務復雜度逐步增加,需要跨業務間的數據頻繁交互以及數據聚合,大型電商一體化平臺業務平臺逐步成本市場的引領者,且架構靈活面向 OLTP 簡單事務處理以及并發分析處理能力得以快速上線。但是在數據庫中間件層需要進行開發維護成本也指數級增加。
- Spring + 分布式數據庫中間件架構則因分布式系統極高復雜度和高昂資源投入致使開發維護成本極高等等。在絕大部份業務場景中,維護分布式數據庫中間層的分片路由、擴容節點 等開發運維工作中,從開發及維護層面中低效、成本高的問題日益凸顯。
典型數據庫中間件應用示例
以 MyCat 類數據庫中間件為例,假設有一個 Orders 訂單表,按照訂單金額和訂單創建時間進行分片路由。
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100"><table name="orders" dataNode="dn1,dn2,dn3" rule="order_rule"></table>
</schema><dataNode name="dn1" dataHost="localhost1" database="db1"/>
<dataNode name="dn2" dataHost="localhost2" database="db2"/>
<dataNode name="dn3" dataHost="localhost3" database="db3"/><dataHost name="localhost1" maxCon="1000" minCon="10" balance="0"writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100"><heartbeat>select user()</heartbeat><writeHost host="hostM1" url="jdbc:mysql://127.0.0.1:3306" user="root" password="password"/>
</dataHost>
<dataHost name="localhost2" maxCon="1000" minCon="10" balance="0"writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100"><heartbeat>select user()</heartbeat><writeHost host="hostM2" url="jdbc:mysql://127.0.0.2:3306" user="root" password="password"/>
</dataHost>
<dataHost name="localhost3" maxCon="1000" minCon="10" balance="0"writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100"><heartbeat>select user()</heartbeat><writeHost host="hostM3" url="jdbc:mysql://127.0.0.3:3306" user="root" password="password"/>
</dataHost><function name="order_rule" class="io.dble.route.function.AutoPartitionByLong"><property name="mapFile">partition-long.txt</property><property name="defaultNode">0</property>
</function>
在 partition-long.txt 中定義分片規則:
# 訂單金額范圍和時間范圍組合的分片規則
# 金額區間 0 - 1000 且時間在 2024 年之前
0-1000|2024-01-01 00:00:00=0
# 金額區間 1001 - 5000 且時間在 2024 年之前
1001-5000|2024-01-01 00:00:00=1
# 金額大于 5000 且時間在 2024 年之前
5001-99999999|2024-01-01 00:00:00=2
# 金額區間 0 - 1000 且時間在 2024 年之后
0-1000|2024-01-01 00:00:01=0
# 金額區間 1001 - 5000 且時間在 2024 年之后
1001-5000|2024-01-01 00:00:01=1
# 金額大于 5000 且時間在 2024 年之后
5001-99999999|2024-01-01 00:00:01=2
在 Java 代碼塊示例
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Timestamp;public class DBLEComplexShardingDemo {private static final String JDBC_URL = "jdbc:mysql://your_dble_host:your_dble_port/TESTDB";private static final String USER = "your_username";private static final String PASSWORD = "your_password";public static void main(String[] args) {try (Connection connection = DriverManager.getConnection(JDBC_URL, USER, PASSWORD)) {// 插入訂單數據insertOrder(connection, 2000, Timestamp.valueOf("2023-12-31 12:00:00"));insertOrder(connection, 6000, Timestamp.valueOf("2024-01-02 12:00:00"));// 查詢訂單數據queryOrders(connection);} catch (SQLException e) {e.printStackTrace();}}private static void insertOrder(Connection connection, int orderAmount, Timestamp orderTime) throws SQLException {String sql = "INSERT INTO orders (order_amount, order_time) VALUES (?, ?)";try (PreparedStatement preparedStatement = connection.prepareStatement(sql)) {preparedStatement.setInt(1, orderAmount);preparedStatement.setTimestamp(2, orderTime);preparedStatement.executeUpdate();System.out.println("Order inserted successfully.");}}private static void queryOrders(Connection connection) throws SQLException {String sql = "SELECT * FROM orders";try (PreparedStatement preparedStatement = connection.prepareStatement(sql);ResultSet resultSet = preparedStatement.executeQuery()) {while (resultSet.next()) {int orderId = resultSet.getInt("order_id");int orderAmount = resultSet.getInt("order_amount");Timestamp orderTime = resultSet.getTimestamp("order_time");System.out.println("Order ID: " + orderId + ", Amount: " + orderAmount + ", Time: " + orderTime);}}}
}
代碼解釋
- 中間件配置配置:在
schema.xml中定義了orders表的分片規則,根據order_rule函數進行分片。partition-long.txt文件中定義了根據訂單金額和訂單創建時間的復雜分片規則。 - Java 代碼:使用 JDBC 連接到中間件,插入不同金額和時間的訂單數據,并查詢所有訂單數據。MyCat 會根據配置的分片規則將數據路由到不同的數據庫節點。
這個示例展示了一個較為復雜的分片邏輯,結合了訂單金額和訂單創建時間進行分片。你可以根據實際需求調整分片規則和代碼邏輯。隨著分片增加、主從節點讀寫分離、主從節點容災切換 等路由邏輯會出現指數級復雜維護,也導致后續業務模型迭代受到路由分片規則方案的制約。
在分布式數據庫技術發展進程里,MyCat 作為聚焦 MySQL 的開源分布式數據庫中間件,曾有效解決海量數據存儲與高并發數據路由分片訪問難題,大力推動了企業數字化轉型。但當下,業務迭代面臨嚴峻挑戰。業務開發模式轉變,平臺化整合加速,企業對業務敏捷性和數據價值挖掘的需求飆升。系統架構需應對 PB 級數據容量、百萬 QPS 吞吐量及混合業務模式;數據架構要靈活調整且支持多維度差異化訪問和服務。傳統分庫分表產品在快速迭代中,數據訪問局限盡顯,難滿足實時洞察與快速響應需求。在此背景下,TiDB 分布式云原生數據庫應運而生,以獨特優勢帶來新解,為企業應對復雜業務挑戰提供了多元選擇。
TiDB 為極簡業務開發提效
TiDB 分布式云原生數據庫,自帶透明數據分片與水平彈性擴展能力,讓開發者無需手動編寫復雜的數據拆分、路由和合并代碼,降低了數據庫水平擴展模塊的開發維護成本;同時其內置的數據強一致性解決方案,免去了開發者自行實現分布式事務協議的困擾。
TiDB 是一體化的分布式數據庫,集計算、存儲和分布式管理功能于一身,使用 TiDB 可以避免引入額外的中間件層,簡化了系統架構。例如,在一些中小型企業的應用系統中,使用 TiDB 可以減少周邊生態組件數量,降低架構的復雜性和維護成本。其具備自動將數據分散到不同的節點上,并根據節點的負載情況動態調整數據分布,保證系統的性能和穩定性。在電商系統中,隨著業務的發展,商品數據量不斷增加,TiDB 可以自動處理數據的分片和均衡,無需人工過多干預。數據存儲層采用了 Raft 協議,能夠提供分布式環境下的強一致性保證,確保數據在多個副本之間的一致性,對于對數據一致性要求較高的金融交易系統等場景非常適用。
名詞解釋:
Raft 協議:在分布式系統中,數據會存儲在多個節點上,要保證這些節點的數據一致可不是件容易的事。Raft 協議就像是一個指揮官,負責協調各個節點,讓它們在數據更新、故障恢復等情況下保持一致。它通過選舉出一個領導者節點,其他節點作為跟隨者,領導者負責接收客戶端的請求,然后把數據同步給跟隨者。如果領導者出現故障,就會重新選舉新的領導者,確保系統能持續穩定運行,就像一個組織里有明確的領導和分工,即使領導臨時有事,也能迅速選出新領導,保證組織正常運轉。
- 數據庫中間件在處理二級索引場景中,實現需手動協調多節點,查詢交互頻繁,開發調試難。而 TiDB 內置且自動管理維護,可以在線進行 DDL 操作,優化器智能利用二級索引實現數據分片檢索,讓開發人員專注業務開發;
- 數據庫中間件依賴復雜協議實現分布式事務,要手動編寫大量異常處理代碼,大部分中間件產品會采用 GTM 單節點實現統一全局事務管理能力,額外需要采用 TCC、Saga 事務補償機制帶來大量代碼開發量。TiDB 提供簡單接口,用標準 SQL 管理,自動維護并發控制與全局一致性事務,通過 PD 微服務框架方案,可以實現并發處理數據自動負載、全局一致性事務 TSO 保障以及數據調度能力。
- 在復雜的 2PC (兩階段事務提交)分布式事務能力下,TiDB 提供更簡單的事務處理提交方案,無論是 TB 級別復雜事務還是百萬級 QPS 海量并發訂單處理場景,都可以像單機 MySQL 一樣實現事務自閉環處理。無需強制業務邏輯拆分來迎合數據庫中間件產品能力。TiDB 提供分布式事務執行的可觀測性全鏈路檢測,高效處理事務響應問題,提供分析定位能力。
綜合而言,分布式數據庫中間件增加開發復雜度,TiDB 以透明化、自動化、智能化簡化流程,為開發提效帶來更多可能。
TiDB 作為一體化分布式數據庫,有效整合軟硬件資源,無需額外部署復雜的數據庫中間件和多個數據庫組件,從而顯著減少了硬件采購與維護成本。例如,企業能夠將原本分散用于不同功能數據庫和中間件的服務器整合為一個集群。同時,TiDB 具備自動伸縮能力,可依據業務需求動態調整資源。像在促銷活動期間增加資源,活動結束后釋放,極大地節省了成本。此外,TiDB 兼容 MySQL 協議,降低了開發人員的學習成本和應用遷移難度,有效提升了開發效率。
TiDB 還提供了強大的數據隔離與流控隔離方案。基于數據的隔離方案,TiDB 借助 Placement rule 實現。通過 Placement rule,用戶能夠對數據的存儲位置進行細粒度控制,可以將不同業務、不同重要級別的數據放置在不同的存儲節點或存儲區域,避免數據相互干擾,確保關鍵業務數據的高可用性和高性能。例如,將核心交易數據與普通日志數據分別存儲在不同的節點組。基于流控的隔離方案則依托于 Resource control,它可將 TiDB 集群資源劃分成不同資源組,并為每個組設置獨立的資源使用限制和優先級,如 CPU、內存使用限制等。不同的 SQL 語句可分配到不同資源組執行,保證高優先級業務不受低優先級業務影響,提升資源使用效率和系統穩定性。

為提升整體資源利用效果,TiDB 建立完善的監控系統,實時監測集群資源使用和性能指標,依據監控數據調整 Placement rule 和 Resource control 配置,同時優化 SQL 語句與系統參數,達到資源利用最大化方案。此外,在運維期間,需定期評估業務需求,合理規劃資源,使 TiDB 能夠更好地適配業務變化,充分發揮其在降本增效、資源管控以及一體化方面的優勢。
暫時無法在飛書文檔外展示此內容
TiDB 對比分布式數據庫中間件局限與權衡
前文闡述了 TiDB 在降本增效、資源管控及一體化方面展現出諸多優勢,如軟硬件整合降低成本、自動伸縮適應業務需求、借助 Placement rule 和 Resource control 實現有效資源隔離等。不過,與分布式數據庫中間件相比,TiDB 也存在一定局限。TiDB 相比部分中間件方案,其在極少數需要深度定制化路由的場景中可能存在適應性限制。綜合來看,TiDB 的優勢仍使其在眾多場景中成為極具競爭力的選擇,接下來可進一步探討如何在不同場景下權衡使用 TiDB 與分布式數據庫中間件。
-
兼容多種數據庫
- 分布式數據庫中間件可以連接多種不同類型的數據庫,如 MySQL、Oracle 等,實現對異構數據庫的統一管理和訪問。TiDB 主要是一個獨立的分布式數據庫,雖然它兼容 MySQL 協議,提供了結構化數據、半結構化、向量等數據的讀寫處理以及實時海量數據分析能力,但無法直接管理 NoSQL 類型的數據庫。在一些企業中,可能同時存在多種不同類型的數據庫,需要使用分布式數據庫中間件來實現數據的整合和統一訪問。
-
歷史系統集成
- 對于一些已經存在的歷史系統,可能已經與特定的分布式數據庫中間件深度集成,替換為 TiDB 可能需要對系統進行大規模的改造,成本較高。在這種情況下,繼續使用分布式數據庫中間件可能是更合適的選擇,以避免對現有系統造成過大的影響。從長遠角度考慮,如果業務進行跨越式迭代產品升級,數據庫中間件維護成本依然高于大規模改造分布式數據庫成本。業務運營長尾收益角度,現代化應用架構設計應用 TiDB 分布式數據庫。無論業務開發效率提升、數據庫維護效能增強,都可以在 1-2 年左右有顯著收益。
-
定制化路由和策略
- 分布式數據庫中間件允許用戶根據業務需求自定義復雜的路由規則和策略,如基于業務邏輯、數據特征等進行靈活的數據路由。TiDB 的分片和路由策略是基于其內部的算法和機制,雖然可以滿足大多數場景的需求,但對于一些有特殊定制化需求的場景,可能不夠靈活。TiDB 提供特定場景下業務架構改造的完整解決方案,TiDB 產品能力會不留余力得會將業務數據讀寫邏輯通過 TiDB 強大的數據熱點離散均衡算法策略,充分利用存算分離分布式能力,使軟硬件一體化的 ROI 最大化,達成企業高效基礎軟硬件轉型目標。
極簡開發體驗做長期主義
數據庫架構從 JDBC 到融合 ORM、數據庫中間件,再到分布式數據庫中間件,一路演進,各有其獨特的應用場景與優劣勢。JDBC 雖開發維護成本高,卻在高頻量化交易這類對性能和響應速度要求嚴苛的場景中,憑借其直接高效的交互優勢站穩腳跟;ORM 結合 Spring 框架,大幅提升開發效率,降低維護難度,在小型電商管理系統等業務邏輯相對簡單的場景中表現出色;引入數據庫中間件,增強了對數據庫的管理能力,實現讀寫分離與數據分片,滿足了大型在線游戲平臺等高并發、大數據量的業務需求,不過也帶來了系統復雜度、擴容硬件成本指數倍增加等問題;分布式數據庫中間件適用于金融級高頻聯機交易柜面系統這類對分布式事務強一致性和高可用性要求極高的場景,但其架構復雜、成本高昂。
TiDB 作為分布式云原生數據庫,強兼容 MySQL 生態,并在降本增效、資源管控及一體化方面優勢顯著。它透明數據分片與自動水平垂直擴展能力,內置數據強一致性解決方案,實現軟硬件資源整合,降低成本并提升開發效率;借助 Placement rule in SQL 和Resource control 實現強大的資源隔離。
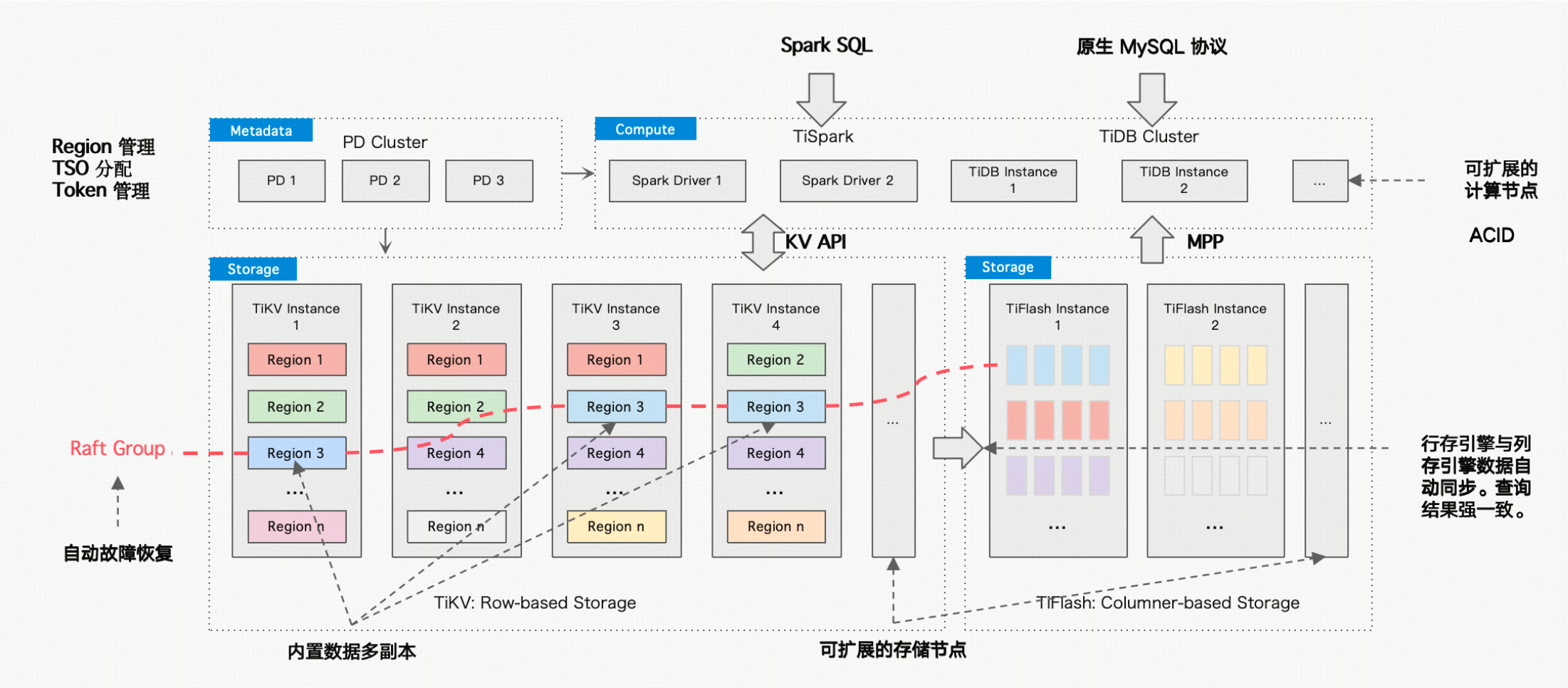
選擇 TiDB,是因為它集數據分片與自動擴展、數據一致性保障、軟硬件資源整合、成本控制、資源管控以及 MySQL 協議兼容等諸多優勢于一身,能有效簡化系統架構、提升開發效率、降低運維成本,契合多樣化業務場景需求 。讓業務開發者釋放出的精力用于業務開發迭代上面,實現 DBA、開發者、業務、企業共贏。

)

![[免費]微信小程序寵物醫院管理系統(uni-app+SpringBoot后端+Vue管理端)【論文+源碼+SQL腳本】](http://pic.xiahunao.cn/[免費]微信小程序寵物醫院管理系統(uni-app+SpringBoot后端+Vue管理端)【論文+源碼+SQL腳本】)
)




,支持經緯度定位與查找)







)

