SQL概述與數據庫定義
SQL的基本組成
1、數據定義語言。SQL DDL提供定義關系模式和視圖、刪除關系和視圖、修改關系模式的命令。
2、交互式數據操縱語言。SQL DML提供查詢、插入、刪除和修改的命令。
3、事務控制。SQL提供定義事務開始和結束的命令。
4、嵌入式SQL和動態SQL。用于嵌入到某種通用的高級語言中混合編程。其中,SQL負責操縱數據庫,
高級語言負責控制程序流程。
5、完整性。SQL DDL包括定義數據庫中的數據必須滿足的完整性約束條件的命令,對于破壞完整性
約束條件的更新將被禁止。
6、權限管理。SQL DDL中包括說明對關系和視圖的訪問權限。
7、SQL語言中完成核心功能的9個動詞:
(1)數據查詢:Select
(2)數據定義:Create、Drop、Alter
(3)數據操縱:Insert、Update、Delete
(4)數據控制:Grant、Revoke
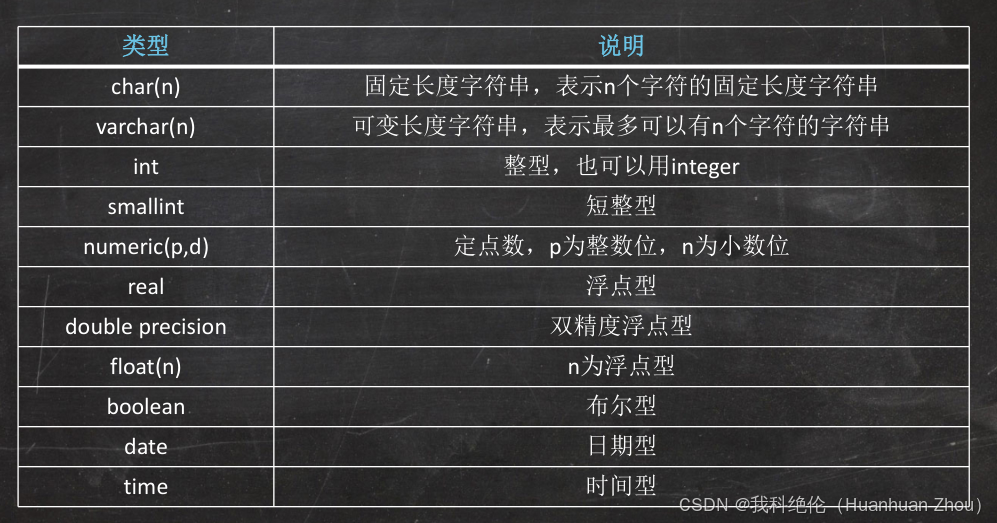
SQL的數據類型
表的創建、修改和刪除
1、創建表
語句格式:CREATE TABLE <表名> (<列名><數據類型>[列級完整性約束條件]
[,<列名><數據類型>[列級完整性約束條件]]…
[,<表級完整性約束條件>]);
注:[ ]表示可選,< >表示必填。
1)、實體完整性約束:
(1)在列后面加 PRIMARY KEY
(2)在最后加PRIMARY KEY(屬性名1,屬性名2)
//主碼為屬性組(兩個或以上屬性的組合)只能
用這種方法
2)、參照完整性約束:
(1)在列后面加 References 表名(屬性名)
(2)在最后面加,有幾個外碼,就寫幾行。
Foreign Key (屬性名) References 表名(屬性名)
[ON DELETE [CASCADE|SET NULL]
ON DELETE CASCADE 表示刪除被參照關系的元組時,同時刪除參照關系中的元組;
ON DELETE SET NULL表示刪除被參照關系的元組時,將參照關系的相應屬性值置為空值。
3)、屬性值上的約束
(1)NOT NULL:表示不允許取空值;
(2)UNIQUE:表示取值唯一;
(3)NOT NULL UNIQUE:表示取值唯一且不為空;
(4)CHECK:限制列中值的取值范圍。
如:CHECK (Sex=‘男’ OR Sex=‘女’),CHECK (余額>=0),CHECK (年齡>=18 AND 年齡<=60)
4)、全局約束
1)基于元組的檢查子句:
這種約束是對單個關系的元組值加以約束。
例:入職日期小于等于離職日期,可以用 CHECK (入職日期<=離職日期)
CREATE TABLE E
(Eno CHAR(8) PRIMARY KEY,
入職日期 DATE,
離職日期 DATE,
CHECK (入職日期<=離職日期) );
2)基于斷言的語法格式:
CREATE ASSERTION <斷言名> CHECK (<條件>)
例:教學數據庫的模式Students、SC、C中創建一個約束ASSE_SC1:不允許男同學選修“張勇”老師的課。
CREATE ASSERTION ASSE_SC1 CHECK
(NOT EXISTS
(SELECT * FROM SC WHERE Cno IN
(SELECT Cno FROM C WHERE TEACHER=‘張勇’)
AND Sno IN
(SELECT Sno FROM Students WHERE SEX=‘M’)));
2、修改表
語句格式:ALTER TABLE <表名> [ADD <新列名><數據類型>[列級完整性約束條件]]
[DROP <完整性約束名>]
[Modify <列名><數據類型>]);
如:
ALTER TABLE S ADD Zap CHAR(6);
//在表S中新增一列ZAP,該列的數據為空
ALTER TABLE S MODIFY Status INT;
//將表S的Status屬性的數據類型更改為INT
ALTER TABLE S ADD Constraint C_cno CHECK(…) //在表S中新增CHECK約束,取名為C_cno
3、刪除表
語句格式:DROP TABLE <表名>
如:
DROP TABLE S;
//表刪除后,不再是數據庫模式的一部分
索引的創建和刪除
1、索引的概念
? 數據庫中的索引與書籍中的索引類似,在一本書中,利用索引可以快速查找到所需信息,無須閱
讀整本書。在數據庫中,索引使數據庫無須對整個表進行掃描,就可以在其中找到所需數據。
? 比如在字典中,我們按字母建立索引。在數據庫中,索引是某個表中的一列或者若干列的值的集
合,和相應的指向表中物理標識這些值的數據頁的邏輯指針清單。
2、索引的作用
(1)通過創建唯一索引,可以保證數據記錄的唯一性。
(2)可以大大加快數據檢索速度。
(3)可以加速表與表之間的連接,這一點在實現數據的參照完整性方面有特別的意義。
(4)在使用ORDER BY和GROUP BY子句中進行檢索數據時,可以顯著減少查詢中分組和排序的時間。
(5)使用索引可以在檢索數據的過程中使用優化隱藏器,提高系統性能。
索引分為聚集索引和非聚集索引。聚集索引是指索引表中索引項的順序與表中記錄的物理順序
一致的索引。
3、建立索引:
語句格式:CREATE [UNIQUE][CLUSTER] INDEX <索引名>
ON <表名>(<列名>[<次序>][,<列名>[<次序>]]…);
? 次序:ASC(升序)或DESC(降序),默認為升序。
? UNIQUE:表明此索引的每一個索引值只對應唯一的數據記錄。
? CLUSTER:表明要建立的索引是聚簇索引,意為索引項的順序是與表中記錄的物理順序一致的索引組織
如:
CREATE UNIQUE INDEX S_Sno on S(Sno);
//在表S的Sno列上建立索引S_Sno,默認為升序
CREATE UNIQUE INDEX P_Pno on P(Pno);
//在表P的Pno列上建立索引P_Pno,默認為升序
CREATE UNIQUE INDEX J_Jno on J(Jno);
//在表J的Jno列上建立索引J_Jno,默認為升序
CREATE UNIQUE INDEX SPJ_NO on SPJ(Sno ASC,Pno DESC,Jno ASC);
//在表SPJ上建立索引SPJ_NO,屬性Sno按升序,Pno按降序,Jno按升序
4、刪除索引
語句格式:DROP INDEX <索引名>
例:DROP INDEX StudentIndex;
//刪除索引StudentIndex
視圖的創建和刪除
1、視圖的作用:
視圖是從一個或者多個基本表或視圖中導出的表,其結構和數據是建立在對表的查詢基礎上的。和真實的表一樣,視圖也包括幾個被定義的數據列和多個數據行,但從本質上講,這些數據列和數據行來源于其所引用的表。因此,視圖不是真實存在的基本表,而是一個虛擬表,視圖所對應的數據并不實際地以視圖結構存儲在數據庫中,而是存儲在視圖所引用的表中。使用視圖的優點和作用如下:
(1)可以使視圖集中數據、簡化和定制不同用戶對數據庫的不同數據要求。(2)使用視圖可以屏蔽數據的復雜性,用戶不必了解數據庫的結構,就可以方便地使用和管理數據,簡化數據權限管理和重新組織數據以便輸出到其他應用程序中。
(3)視圖可以使用戶只關心他感興趣的某些特定數據和所負責的特定任務,而那些不需要的或者無用的數據則不在視圖中顯示。
(4)視圖大大地簡化了用戶對數據的操作。
(5)視圖可以讓不同的用戶以不同的方式看到不同或者相同的數據集。
(6)在某些情況下,由于表中數據量太大,因此在表的設計時常將表進行水平或者垂直分割,但表的結構的變化對應用程序產生不良的影響。
(7)視圖提供了一個簡單而有效的安全機制。
2、創建視圖
語句格式:CREATE VIEW 視圖名(列表名)
AS SELECT 查詢子句
[WITH CHECK OPTION];
? 視圖的創建中,必須遵循如下規定:
(1)子查詢可以是任意復雜的SELECT語句,但通常不允許含有ORDER BY子句和DISTINCT短語。
(2)WITH CHECK OPTION表示對UPDATE,INSERT,DELETE操作時保證更新、插入或刪除的行滿足視圖
定義中的謂詞條件(即子查詢中的條件表達式)
(3)組成視圖的屬性列名或者全部省略或者全部指定。如果省略屬性列名,則隱含該視圖由SELECT
子查詢目標列的主屬性組成。
例:學生關系模式S(Sno,Sname,Sage,Sex,SD,Email,Tel),建立計算機系(CS表示計算機系)學生的
視圖,并要求進行修改、插入操作時保證該視圖只有計算機系的學生。
CREATE VIEW CS_STUDENT
//創建視圖CS_STUDENT
AS SELECT Sno,Sname,Sage,Sex
//選擇學號、姓名、年齡、性別列
FROM Student
//從學生表中查詢
Where SD=‘CS’
//選擇系名等于“CS”的行
WITH CHECK OPTION;
//以后對該視圖進行修改、插入操作時DBMS
會自動加上SD='CS’的條件,
保證視圖中只有計算機系的學生
3、刪除視圖
語句格式:DROP VIEW 視圖名
如:DROP VIEW CS_STUDENT //刪除視圖CS_STUDENT
數據操作
SQL的數據操作功能包括SELECT(查詢)、INSERT(插入)、DELETE(刪除)和UPDATE(修改)4條語句。
Select 基本結構

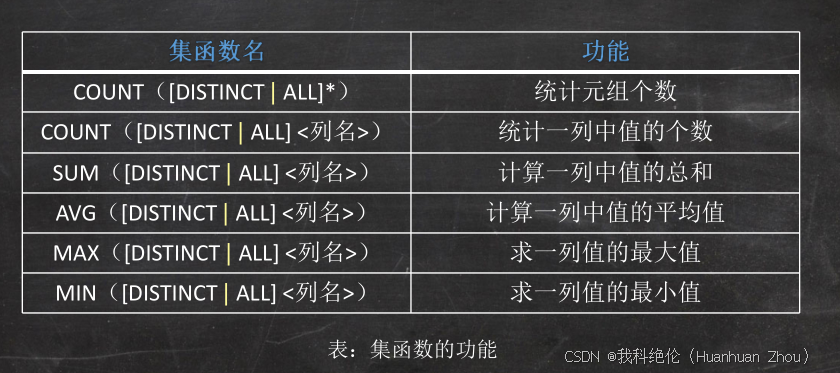
聚集函數
? 聚集函數是一個值的集合為輸入,返回單個值的函數。SQL提供了5個預定義集函數:
平均值AVG()、最小值MIN()、最大值MAX()、求和SUM()、計數COUNT()
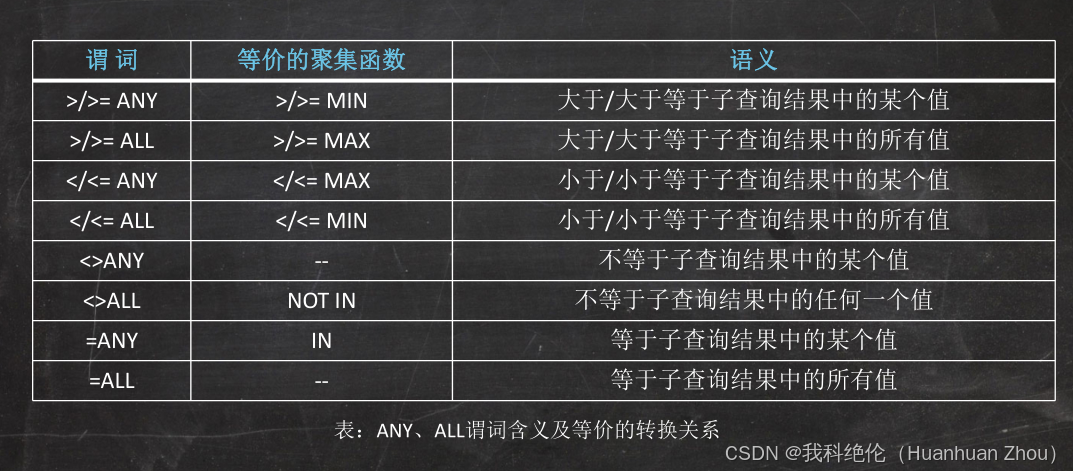
授權與觸發器
授權(GRANT)
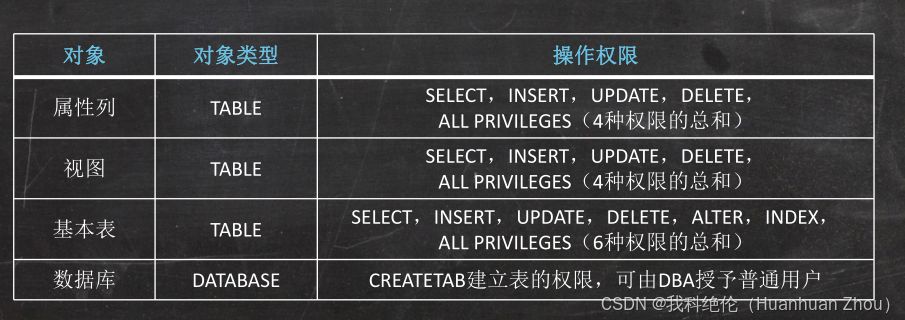
語句格式: GRANT 權限 ON TABLE/DATABASE 表名/數據庫名 TO 用戶1,用戶2… /PUBLIC
[WITH GRANT OPTION];
PUBLIC:表示將權限授予所有人
WITH GRANT OPTION:表示獲得了這個權限的用戶還可以將權限賦給其他用戶。
授權(GRANT)
例:用戶要求把數據庫SPJ中供應商S、零件P、項目J表賦予各種權限。各種授權要求如下:
(1)將對供應商S、零件P、項目J的所有操作權限賦給用戶User1及User2。
GRANT ALL PRIVILEGES
ON TABLE S,P,J
TO USER1,USER2;
(2)將對供應商S的插入權限賦給用戶User1,并允許將此權限賦給其他用戶。
GRANT INSERT
ON TABLE S
TO USER1 WITH GRANT OPTION;
(3)DBA把數據庫SPJ中建立表的權限賦給用戶User1。
GRANT CREATETAB
ON DATABASE SPJ
TO User1;
收回權限(REVOKE)
語句格式: REVOKE 權限 ON TABLE/DATABASE 表名/數據庫名
FROM 用戶1,用戶2… /PUBLIC
[RESTRICT | CASCADE];
RESTRICT:表示只收回語句中指定的用戶的權限
CASCADE:表示除了收回指定用戶的權限外,還收回該用戶賦予的其他用戶的權限。
例:將用戶User1及User2對供應商S、零件P、項目J的所有操作權限收回:
REVOKE ALL PRIVILEGES ON TABLE S,P,J FROM User1,User2;
將所有用戶對供應商S的所有查詢權限收回:
REVOKE SELECT ON TABLE S FROM PUBLIC;
將User1用戶對供應商S的供應商編號Sno的修改權限收回。
REVOKE UPDATE(Sno) ON TABLE S FROM User1;
觸發器概述
? 觸發器主要有以下三方面的特點:
(1)當數據庫程序員聲明的事件發生時,觸發器被激活。聲明的事件可以是對某個特定關系的插入、刪除或更
新。
(2)當觸發器被事件激活時,不是立即執行,而是首先由觸發器測試觸發條件,如果事件不成立,響應該事件
的觸發器什么都不做。
(3)如果觸發器聲明的條件滿足,則與該觸發器相連的動作由DBMS執行。動作可以阻止事件發生,可以撤銷事
件。
? 創建觸發器時需指定:
(1)觸發器名稱
(2)在其上定義觸發器的表
(3)觸發事件:觸發器將何時激發
(3)觸發條件:滿足什么條件時執行觸發動作
(4)觸發動作:指明觸發器執行時應做的動作
? 觸發器可以引用當前數據庫以外的對象,但只能在當前數據庫中創建觸發器。
? 不能在臨時表或系統表上創建觸發器,但觸發器可以引用臨時表。
創建觸發器
CREATE TRIGGER 觸發器名稱 [BEFORE | AFTER]
[DELETE | INSERT | UPDATE OF 列名]
//觸發事件
ON 表名
[REFERENCING <臨時視圖名>]
[FOR EACH ROW | FOR EACH STATEMENT]
[WHEN <觸發條件>]
//WHEN后面跟觸發條件,指明當什么條件滿足時,執行下面的觸發動作
BEGIN
<觸發動作>
//BEGIN…END 中定義觸發動作,即當觸發條件滿足時,需要數據庫做什么
END [觸發器名稱]
BEFORE/AFTER:指明是在執行觸發語句之前激發觸發器還是執行觸發語句之后激發觸發器。
DELETE:當一個DELETE語句從表中刪除行時激發觸發器。
INSERT:當一個INSERT語句向表中插入行時激發觸發器。
UPDATE/UPDATE OF(列名):當UPDATE修改表中的值時,激發觸發器,也可加(OF 列名)指定是某一列的值被修改時激發觸發器。
REFERENCING:觸發器運行過程中,系統會生成兩個臨時視圖,分別存放更新前和更新后的值,對于行級觸發器,為OLD ROW
和NEW ROW,對于語句級觸發器,為OLD TABLE和NEW TABLE。
REFERENCING new row AS nrow / REFERENCING old row AS orow 。
FOR EACH ROW:表示為行級觸發器,對每一個被影響的元組(即每一行)執行一次觸發過程。
FOR EACH STATEMENT:表示為語句級觸發器,對整個事件只執行一次觸發過程,為默認方式。
更改和刪除觸發器
1、更改觸發器
語句格式:
ALTER TRIGGER <觸發器名> [BEFORE|AFTER]
DELETE|INSERT|UPDATE OF [列名]
ON 表名|視圖名
AS
BEGIN
要執行的SQL語句
END
2、刪除觸發器
語句格式:
DROP TRIGGER <觸發器名>
嵌入式SQL與存儲過程
嵌入式SQL
? SQL提供了將SQL語句嵌入到某種高級語言中的方式,通常采用預編譯的方法。
1、區分主語言與SQL語句的方式:
EXEC SQL <SQL語句>
2、向主語言傳遞SQL語句執行的狀態信息的方式:
SQLCA,即SQL通信區,是系統默認定義的全局變量。
3、主變量(共享變量):
? 主語言通過主變量向SQL語句提供參數,主變量是由主語言的程序定義的,并用SQL的DECLARE語句
說明。
? 在SQL語句中,為了與SQL中的屬性名區分,在引用共享變量時,前面需要加“:”
游標
? SQL語言是面向集合的,一條SQL語句可以產生或處理多條記錄。而主語言是面向記錄的,一組主變量一次只能放一條記錄,所以,引入游標,通過移動游標指針來決定獲取哪一條記錄。

存儲過程
? 存儲過程(Procedure):是一組為了完成特定功能的SQL語句集合,經編譯后存儲在數據
庫中,用戶通過指定存儲過程的名稱并給出參數來執行。
? 存儲過程中可以包含邏輯控制語句和數據操縱語句,它可以接受參數、輸出參數、返回
單個或多個結果集以及返回值。
? 由于存儲過程在創建時即在數據庫服務器上進行了編譯并存儲在數據庫中,所以存儲過
程運行要比單個的SQL語句塊要快。
? 語句格式:
CREATE PROCEDURE 存儲過程名(IN|OUT|IN OUT 參數1 數據類型,IN|OUT|IN OUT 參數2 數據類型…)
[AS]
//參數的數據類型只需要指明類型名即可,不需要指定寬度。具體寬度由外部調用者決定
BEGIN
<SQL語句>
END
IN:為默認值,表示該參數為輸入型參數,在過程體中值一般不變。
OUT:表示該參數為輸出參數,可以作為存儲過程的輸出結果,供外部調用者使用。
IN OUT: 既可作為輸入參數,也可作為輸出參數。


)


)


:)
基礎自定義分區器)






![[250521] DBeaver 25.0.5 發布:SQL 編輯器、導航器全面升級,新增 Kingbase 支持!](http://pic.xiahunao.cn/[250521] DBeaver 25.0.5 發布:SQL 編輯器、導航器全面升級,新增 Kingbase 支持!)


