如果把人的身體比作一座龐大的城市,那么血管無疑就是這座城市的「道路」,動脈、靜脈以及毛細血管對應著高速公路、城市道路以及鄉間小道,它們相互協作,通過血液將營養物質、氧氣等輸送到身體各處,從而維持著這座「城市」的高效、穩定運行。而當這些道路出現問題時,人們的身體自然也會隨之發生病變。
血管分割是檢查這些「道路」是否存在問題的重要手段,如同城市建設中通過交通影像發現問題一般,它是醫學圖像處理中的一項關鍵任務。血管分割可以從醫學圖像中精準識別和提取血管的結構,從而應用于各種血管疾病的分析、診斷和治療,例如在心血管疾病方面,對冠狀動脈血管的分割有助于醫生評估血管的狹窄程度,從而為患者制定合適的治療方案。
近些年,血管分割在計算機和醫學影像技術的加持下已經取得了顯著進步。然而,當面對特定任務的成像時,準確和穩健的分割全連接的血管仍是一個具有挑戰性的問題,尤其是在 3D 血管分割中。一方面是血管自身原因所限,復雜微小的血管幾何形狀帶來的分割難度的陡然增長;另一方面是由成像方式和協議所限,特定的信噪比、血管模式、成像偽影以及背景組織的變化引起的顯著域間隙。
雖然目前出現了多種基于基礎模型的醫學影像分割方法,如 SAM(Segment Anything Model)以及針對 3D 醫學圖像的 SAM-Med3D、VISTA3D 等,但這些模型在血管分割任務中仍存有局限性。因此,3D 血管分割對于醫護人員和研究人員而言仍然是一項勞動密集型的工作,需要進行大量手動的體素級注釋才能進一步實現準確的血管圖像分析。
針對于此,來自蘇黎世大學、蘇黎世聯邦理工學院和慕尼黑工業大學的團隊提出了一個專為 3D 血管分割而設計的基礎模型 vesselFM。該模型在一個大規模數據集(Dreal)及通過域隨機化(Ddrand)和基于流匹配的生成模型(Dflow)生成的合成數據上進行訓練,能夠在零樣本、單樣本和少樣本場景中實現優于現有先進模型的分割能力和泛化能力。
相關研究以「vesselFM: A Foundation Model for Universal 3D Blood Vessel Segmentation」為題發表,并入選了 CVPR 2025。
研究亮點:
* 研究提出了一種具有零樣本、泛化能力的 3D 血管分割通用基礎模型,可供研究人員和醫護人員「開箱即用」
* 團隊策劃了最大的 3D 血管分割數據集,包括經過精心處理的真實 3D 血管圖像和匹配的體素級注釋
* 研究提出了一種針對 3D 血管分割的精細領域隨機化策略,同時將流匹配引入 3D 醫學圖像生成當中。

論文地址:
https://go.hyper.ai/lVad9
?
數據集:3 個異構數據源
研究人員使用了 3 個異構數據源對其進行訓練,首先是一個內含不同真實數據的數據集 Dreal(Diverse Real Data);其次為 2 個合成數據源,分別是領域隨機數據集 Ddrand(Domain Randomization)以及從基于流匹配的生成模型中采集的數據 Dflow(Flow Matching-Based)。
其中,Dreal 是迄今為止應用于 3D 血管分割任務中最大的真實數據集,涵蓋來自不同生物體的各種解剖區域的廣泛成像模式,包含了 17 個注釋來源的超 115,000 個形狀為 1283 的 3D patches。具體來說,其廣泛的臨床成像包括 MRA、CTA、X 光片、雙光子顯微鏡以及 vEM 等,生物樣本來自人類、實驗鼠的大腦、腎臟和肝臟等,這為研究提供了不同結構和功能特性的血管模式。如下圖所示。
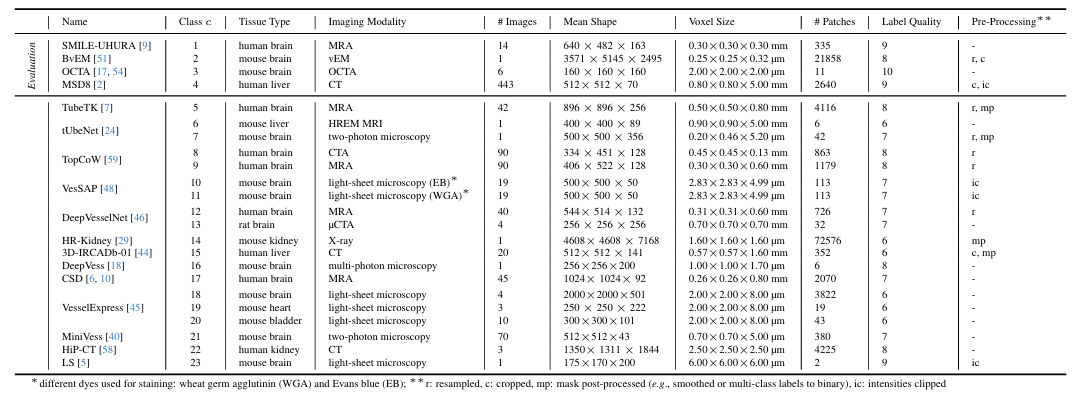
Dreal 數據集總覽(23 個數據集統計信息,包括 4 個驗證數據集)
隨后,研究人員又根據組織類型、成像方式以及協議,進一步將 Dreal 劃分為了 23 個數據集,并且對每個數據集進行了預處理,最后從圖像及其相應的標簽中提取目標形狀為 1283 的 patches。
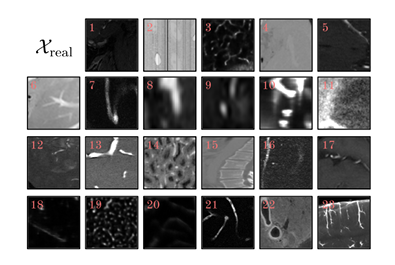
數據示例圖
研究人員引入了域隨機化策略創建了 Ddrand,如下圖所示。該方法通過在真實血管數據上施加一系列的空間變換和人工偽影,生成大量具有多樣性的合成圖像-掩碼對,以此提升模型對真實數據的魯棒性。具體來說可分為 3 步,即前景生成、背景生成和背景融合。
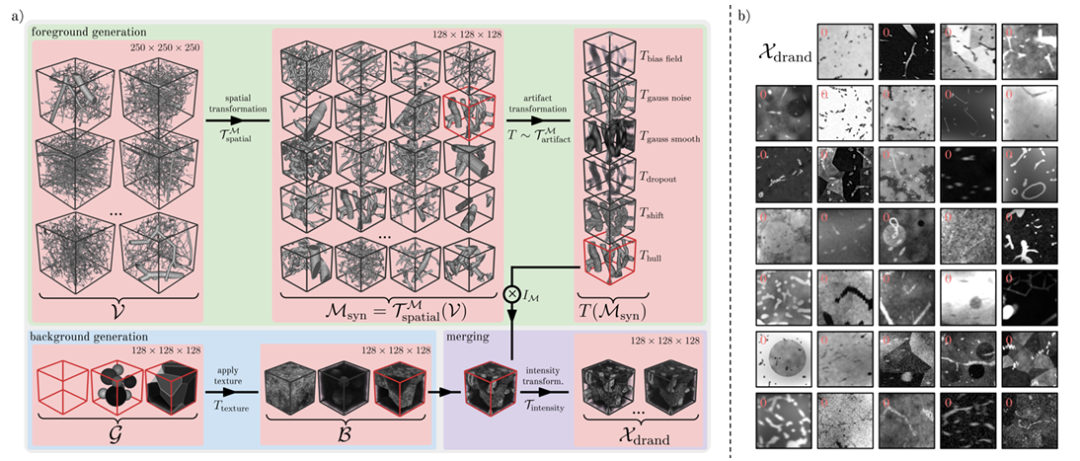
圖 a 為用于生成 Ddrand 的領域隨機生成管道的示意圖;圖 b 為示例圖
在前景生成階段,研究人員利用 Wittmann 等提供的 1,137 個形狀為 2503 的血管板塊 v 作為合成掩碼的基礎,這些血管斑塊來自于腐蝕鑄型的圖形表示,具有高保真性。
研究人員采用的主要方法是通過空間變換,如隨機裁剪、翻轉、擴張和縮放、隨機彈性變形以及二元平滑來實現生成廣泛的真實血管模式。接下來,研究人員又通過選擇偽影變換,如偏置場、高斯噪聲、高斯平滑、dropout、偏移、模糊等來模擬真實血管圖像中存在的各種前景偽影。
在背景生成階段,研究人員對包含不同紋理的各種背景幾何形狀的背景圖像進行了建模,主要包括 3 種變體:球體(非重疊球體)、多面體(使用 Voronoi 將圖像分割成多個多面體區域)以及不包含任何背景的幾何圖像。
在背景融合階段,研究人員通過體素加減法或用掩模強度值替換背景強度值,將前景合并到背景中。為了擴大圖像域,研究人員連續通過隨機偏置場增強、添加高斯噪聲、在 k 空間中應用隨機局部峰值、隨機調整圖像對比度,對所有空間維度的個體或共享 σ 值執行高斯平滑、添加 Rician 噪聲和 Gibbs 噪聲、執行隨機高斯銳化,并隨機變換強度直方圖,最終得到合成圖像 Xdrand(如上圖 b 中所示)。
為了進一步豐富真實數據 Dreal 的分布,研究人員進一步訓練并采樣了一個基于 Flow Matching 的條件生成模型 F,生成了第三個數據源 Dflow。如下圖所示。

3 個數據源 Dreal(藍色陰影)、Dflow (紅色陰影)以及 Ddrand (灰色陰影)分布示意圖
模型架構:引入深度生成模型和域隨機化策略
總體而言,vesselFM 是一個專門為 3D 血管分割而設計的通用基礎模型,能夠在各種模式和組織類型中精準分割 3D 血管系統。在模型的設計過程中,研究人員通過 3 個異構數據源對其進行訓練,實現了其強大的分割能力和泛化能力。
?
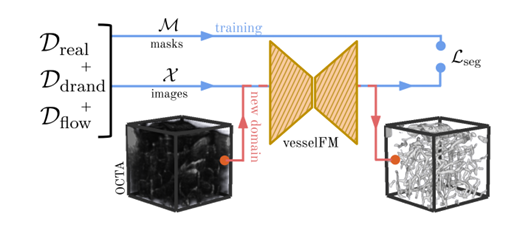
vesselFM 的訓練及應用概覽
在這一過程,研究人員引入了 2 個關鍵步驟,分別是深度生成模型和域隨機化策略。上文數據集介紹部分詳細闡述了域隨機化策略,本部分著重介紹生成 Dflow 數據集所使用的深度生成模型。
深度生成模型是合成醫學圖像生成的重要手段,以擴散模型(Diffusion Model)為主,用于生成大量高保真合成數據。為了將這些數據進行分割任務,需要精確匹配圖像-掩碼對,比如 Med-DDPM、SegGuidedDiff 等方法,就是為了應對這一挑戰而設計。它們通過通道級聯分割掩碼到模型輸入來整合語義條件,從而產生符合一致解剖約束的圖像掩碼對。前者為 3D 腦成像合成量身定制,后者為 2D 乳腺 MRI 和腹部 CT 生成而設計。
在本研究中,研究人員采用了不同于擴散模型的方法,使用 Flow Matching 的生成模型方法。它通過學習數據從一個已知分布到目標分布的連續變換過程,從而生成新的樣本,相比于擴散模型,后者在自然圖像上顯示出了更卓越的性能。
具體在研究中,生成模型 F 利用一個 θ 參數化的網絡,表示一個學習與時間相關的速度場 v,然后通過常微分方程(Ordinary Differential Equation, ODE)將樣本 x?~N(0,I)映射到數據分布的樣本 x?。同時,為了訓練模型 F,研究人員還優化了流匹配目標,使預測速度與采樣真值速度在時間刻度上的損失最小化。
此外,訓練模型 F 還采用了掩碼和類別條件,通過將掩碼通道與輸入圖像連接 x? 來實現掩碼調理。研究人員將類嵌入加入到時間嵌入中來合并類信息,然后通過加法注入到中間特征層中。為了生成 Dflow,研究人員最終通過歐拉積分(Euler integration)對 x? 進行離散化,從而對大量圖像 Xflow 進行采樣,如下圖所示。
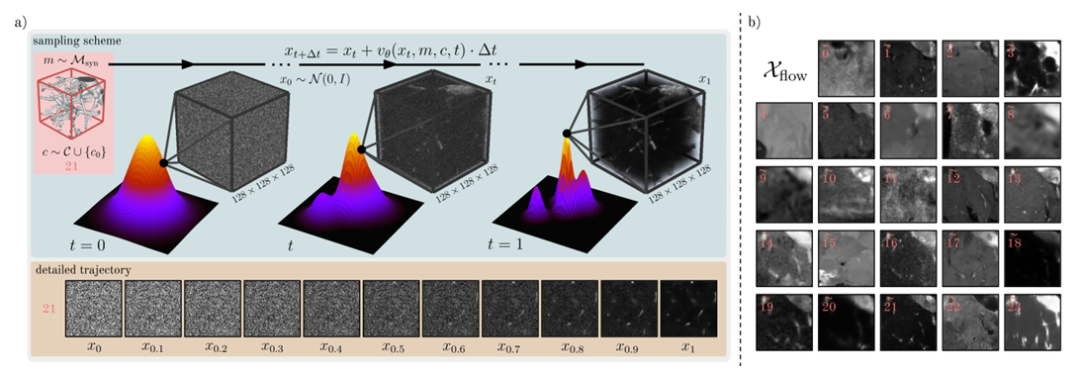
圖 a 為基于 Flow Matching 的采樣過程;圖 b 為示例圖
實驗結果:性能優于當前最先進模型
為了驗證 vesselFM 的有效性和可靠性,研究人員通過對比的方式進行了評估,并展示了其在零樣本、單一樣本以及少樣本場景下的分割能力。
具體來說,驗證階段采用了 4 個臨床數據集:SMILE-UHURA、MSD8、OCTA 和 BvEM。研究人員從這些評估數據集中提取形狀為 1283 的 3 個 patches,并利用其將單一樣本和少樣本分割任務定義為在其中一個或全部三個數據塊上,以便對模型進行微調。其余數據用于測試和驗證。對于零樣本評估,模型將直接應用測試數據而無需預先微調。
同時將 4 款專門為 3D 血管分割而設計的基礎模型作為比較對象,分別為:tUbeNet、VISTA3D、SAM-Med3D 和 MedSAM-2。
研究人員使用單卡 NVIDIA RTX A6000 GPU,從模型 F 中采樣了 1 萬個圖像掩碼,在 3 天時間內生成 Dflow。同時為了管理 Ddrand,研究人員從域隨機化生成管道中抽取了 50 萬個圖像掩碼對,每個圖像掩碼對的形狀均為 1283。所使用的 3 個數據源權重大致根據其大小來設置,分別為 Ddrand(70%)、Dreal(20%)和 Dflow(10%)。
具體結果如下圖所示。vesselFM 在所有 4 個數據集和任務上都展示了卓越的泛化能力和優秀性能。其中零樣本任務中,在 MSD8 數據集上,vesselFM 的 Dice 得分比 VISTA3D 高出 5.86 分(VISTA3D 在 11,454 個 CT 數據上進行訓練,本身包括來自 MSD8 的數據),這更加凸顯了 vesselFM 強大的歸納偏置。
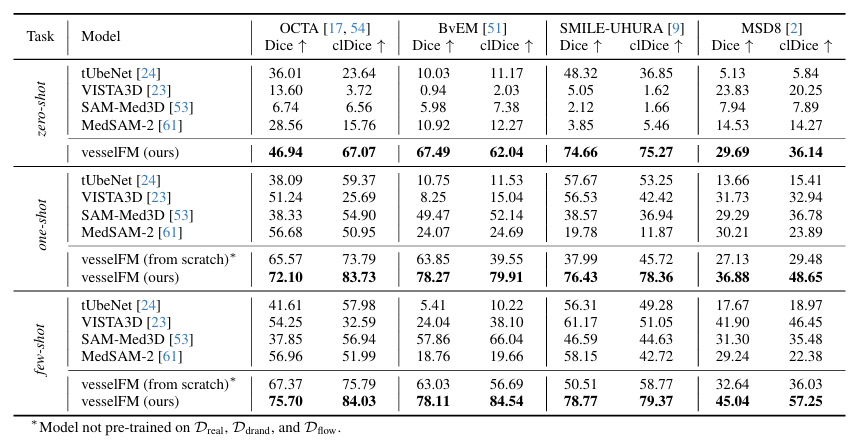
在 4 個驗證集上的對比結果
相比之下,通用 3D 血管分割模型 tUbeNet 在更復雜的成像模態中表現并不佳,另外 2 個通用分割模型 SAM-Med3D 和 MedSAM-2 在零樣本設置下均無法分割血管。值得一提的是,在 SMILE-UHURA 數據集上,vesselFM 在零樣本場景下的 Dice 和 clDice 得分甚至超過了基線模型在少樣本場景下的得分。定性結果表明了 vesselFM 在零樣本下卓越的泛化能力,且不存在注釋者特定的偏差。如下圖所示。
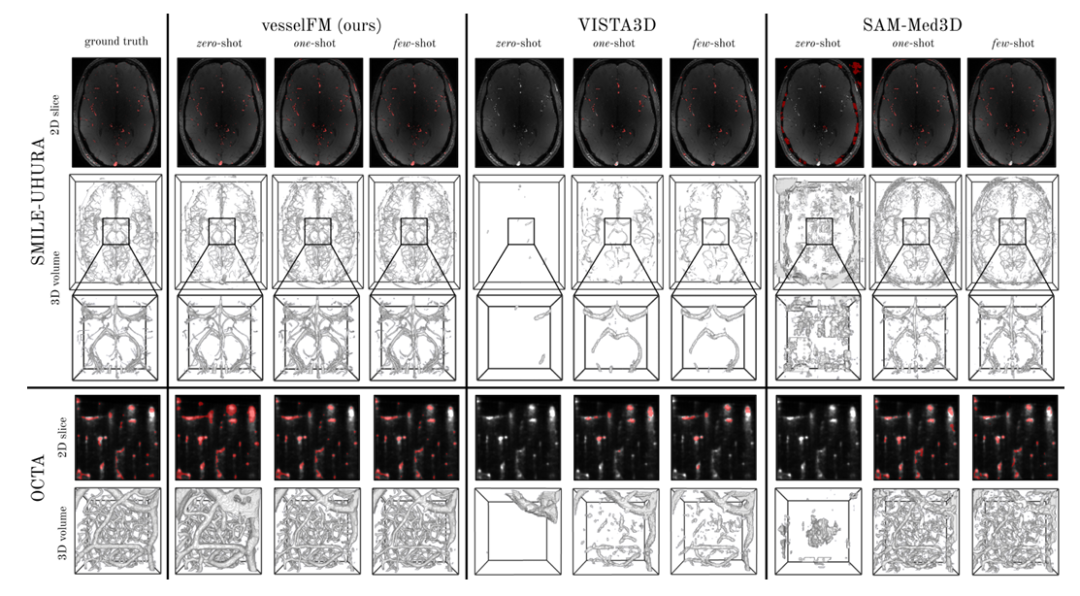
部分驗證集上的可視化結果
深度學習開啟血管分割研究的新道路
綜上而言,vesselFM 的相關研究無疑推動了 3D 血管分割研究的進步,為血管類疾病的治療和研究提供了全新的道路,有望促進新的先進工具誕生和應用,并最終實現造福患者的目標。
而值得慶幸的是,vesselFM 并非一次孤單嘗試。隨著深度學習技術的發展和醫療數據的日益豐富,通過人工智能的方式處理醫學圖像已經是現代醫療變革的一個重要方向。越來越多的實驗室和研究機構都將注意力放到了這一領域,并希望通過自己的研究來解決人類所面臨的血管類疾病挑戰。
比如中國科學院的團隊曾發表過一篇題為「VesselSAM: Leveraging SAM for Aortic Vessel Segmentation with LoRA and Atrous Attention」的研究。研究提出了一種增強版本的 SAM,命名為 VesselSAM,專門用于主動脈血管分割。該模型集成空洞注意力模塊和低秩適應(LoRA),解決了 SAM 的關鍵局限性,增強了其捕捉醫學圖像中復雜的層次特征的能力。
論文地址:
https://arxiv.org/abs/2502.18185
來自中國上海交通大學的團隊聯手上海第一人民醫院、貝爾法斯特女王大學和路易斯安娜州立大學等團隊,發表題為「Self-Supervised Vessel Segmentation via Adversarial Learning」的研究。該研究提出通過對抗學習來訓練 2 個生成器,一個是注意力引導生成器,一個是分割生成器,讓它們分別合成假血管、從冠狀動脈血管造影圖像中分割血管,從而學習血管的特征表示。該論文還入選了 CVPR 2021。
論文地址:
https://openaccess.thecvf.com/content/ICCV2021/papers/Ma_Self-Supervised_Vessel_Segmentation_via_Adversarial_Learning_ICCV_2021_paper.pdf
來自葡萄牙里斯本大學的團隊聯合葡萄牙天主教大學的團隊同樣也在血管分割方面發表了相關研究,他們提出了一種基于深度學習開發的 3D 視網膜血管網絡自動分割和定量軟件 3DVascNet。該軟件不僅實現了對血管的精準分割,同時還可以量化血管形態測量參數,如血管密度、分支長度、血管半徑和分支點密度等。更重要的是,該軟件為一款免費軟件,同時其強大泛化能力又進一步促進了醫護人員研究三維血管網絡的能力。相關研究以「3DVascNet: An Automated Software for Segmentation and Quantification of Mouse Vascular Networks in 3D」為題發表。
論文地址:
https://www.ahajournals.org/doi/10.1161/ATVBAHA.124.320672
總而言之,血管分割作為醫學圖像處理中一項關鍵而又兼具挑戰性的任務,仍然有諸多難題亟待解決,但科研人員們的一次又一次嘗試無疑讓我們看到了這些難題正在土崩瓦解。更令人相信的是,在不久的將來,或許血管類疾病將也將會隨著人工智能應用的加深,而被逐漸攻克。


:Worker節點啟動全解析)


)


?)








—芯片封裝中的開爾文源極)

