前言
從最初對人工智能的懵懂認知,到逐漸踏入Prompt工程的世界,我們一路探索,從私有化部署的實際場景,到對DeepSeek技術的全面解讀,再逐步深入到NL2SQL、知識圖譜構建、RAG知識庫設計,以及ChatBI這些高階應用。一路走來,我們在AI的領域里一步一個腳印,不斷拓展視野和能力邊界。如果你是第一次點開這篇文章,或許會覺得今天的內容稍有挑戰。但別擔心,之前我創作的的每一篇人工智能文章都是精心鋪設學習前置的基石。如果希望更深入地理解接下來我們將討論的「從知識圖譜到精準決策:基于MCP的招投標貨物比對溯源系統實踐」這一主題,不妨先回顧我以往分享過的基礎與進階文章,相信它們會讓你的學習過程更加順暢自然。

我是Fanstuck,致力于將復雜的技術知識以易懂的方式傳遞給讀者,每一篇文章都凝聚著我對技術的深刻洞察。從人工智能的基礎理論到前沿研究成果,從熱門框架的深度解析到實戰項目的詳細拆解,內容豐富多樣。無論是初學者想要入門,還是資深開發者追求進階,都能在這里找到契合自身需求的知識養分。如果你對大模型的創新應用、AI技術發展以及實際落地實踐感興趣,那么請關注Fanstuck。
背景
招投標過程中,相關信息高度分散且多為非結構化文本,人工整理既費時又易錯。例如,一位投標經理需要手動查閱多個招標公告頁面,提取項目名稱、預算、投標人、評標結果等關鍵數據。這種手工操作不僅繁瑣,而且容易出錯,也難以保證信息的完整性和時效性。傳統方法下,投標決策往往依賴人工經驗和各部門零散文檔,難以及時比對貨物同質化程度及來源,有可能忽略同款貨物的歷史供應商記錄或價格異常。
?
招投標貨物比對與溯源痛點
- 數據分散與孤立: 企業內部以及行業內的數據分布在多個系統和平臺,缺乏有效統一的數據管理平臺,難以實現跨部門、跨系統的數據共享。
- 人工核對效率低下、出錯率高: 傳統的人工核對需要反復對照招標公告、歷史采購記錄、技術規格等文檔,人力投入大且易出錯,稍有疏漏就可能導致投標失敗或采購失誤。
- 缺乏快速精準的溯源分析: 當企業希望從歷史招投標案例中快速提取相關貨物信息作為新項目的決策支持時,由于缺乏智能化工具和系統化的溯源機制,往往需要耗費大量時間精力。
傳統解決方案的局限性
- 時效性差的人工處理模式: 企業常使用Excel表格或簡單的數據庫記錄,難以實時更新數據且效率受限,無法滿足快速決策需求。
- 缺乏有效分類和結構化存儲: 數據缺乏行業領域特定知識的結構化分類,難以有效支持高級分析或自動化決策流程。
- 無法實現實時決策支持: 傳統方法難以提供實時的數據分析和決策指導,企業往往在項目投標決策上無法迅速響應市場變化,影響競爭力。
因此,如何打通數據孤島,實現高效的數據聯動、精準的貨物溯源與比對分析,成為當前企業招投標管理亟待解決的關鍵問題。因此,需要一種智能化手段,將分布于公告、歷史檔案和采購文檔中的信息整合起來,實現貨物自動比對與溯源,從而支持更精準的決策。基于MCP協議的招投標貨物比對溯源系統實踐應運而生,以知識圖譜技術和AI智能聯動為核心,將為企業帶來從數據采集到精準決策的全面升級與優化。
場景案例

以醫療設備采購項目為例:某醫院計劃采購CT機、透析機等多種儀器設備。負責采購的工程師需對多個投標單位提交的設備規格、型號、價格及服務條款等進行比對。但供應商提供的信息格式各異,有的只給出文字說明,有的以表格形式呈現,且不同廠家的CT機型名稱稍有差異(如X100與X-100),給匹配帶來難度。同時,為保證公正采購,還需核查設備供應商的過往履約記錄和設備歷史價格。傳統情況下,工作人員需要打開多個PDF文檔、爬取政府平臺公告、比對不同數據源,很難快速梳理出兩套信息是否指向同一類設備,或是否存在重復采購風險。此時,如果有一個系統能自動識別“X型CT機”和“X-100 CT”是一致設備,并提示該設備曾由哪些供應商提供過、過去價格區間等信息,就能大大降低人工比對成本,提高決策效率和準確度。
二、方案整體架構設計與MCP應用價值展示
技術方案整體架構圖
本方案通過構建完整的數據采集到決策反饋鏈路,招投標全流程信息數據采集知識圖譜系統具體架構流程如下:
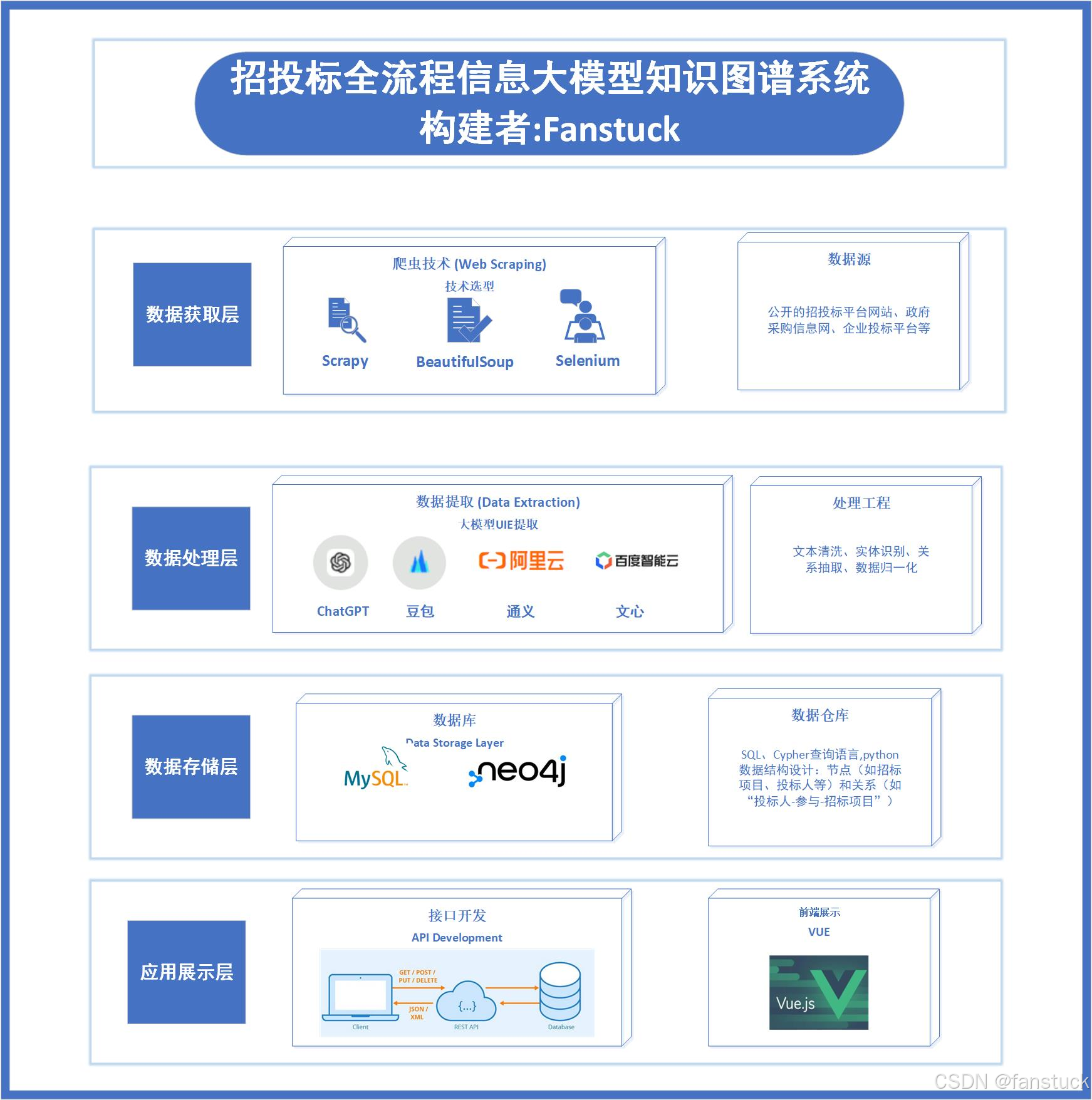
1. 數據獲取層:爬蟲技術
首先,使用爬蟲技術從多個公共平臺抓取招投標信息。這些平臺包含了大量公開的招標公告、投標公告、開標結果等信息。爬蟲能夠自動化地從這些平臺獲取最新的數據,并將其存儲為原始文本格式。
2. 數據處理層:大語言模型的數據提取
抓取到的數據往往是非結構化的文本,需要經過數據處理才能提取出關鍵信息。在這一層,我們使用大語言模型(如GPT)對數據進行處理,自動識別并提取出項目ID、招標人、投標人、標的物、投標金額等重要字段。
3. 數據存儲層:Neo4j圖數據庫
提取出來的數據會被存入圖數據庫(如Neo4j)中。我們將不同的數據項(如項目、投標人、評標標準等)表示為節點,并通過關系連接起來,形成一張全景式的招投標知識圖譜。
4. 展示層:前后端聯通與知識圖譜可視化
通過API開發,前端系統能夠調用圖數據庫中的數據,并以可視化的方式展示給用戶。用戶可以通過圖形化界面查詢相關招投標信息,進行多維度分析與決策支持。
貨物溯源、智能決策反饋整體架構如下:
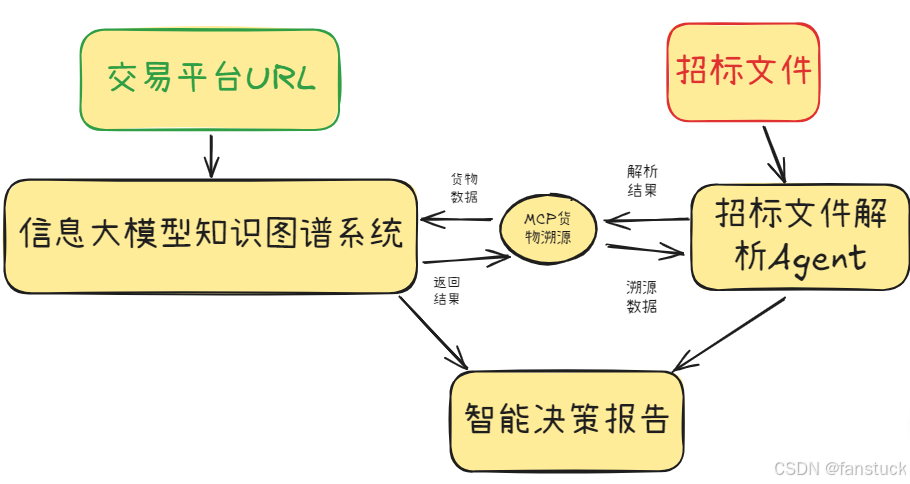
- 招標公告采集:從公開招標網站抓取并存儲至數據庫;
- 數據庫存儲:使用騰訊云DB或MongoDB存儲數據;
- 貨物知識圖譜抽取:基于大數據和知識圖譜技術,將原始數據結構化,并構建動態更新的知識圖譜;
- 招標文件解析:結構化解析招標文檔中貨物信息;
- MCP驅動貨物溯源:利用MCP協議自動聯動知識圖譜與數據庫,快速進行精準的數據溯源和比對;
- 智能決策反饋:基于分析結果為企業提供精準決策支持。
本系統采用多Agent協作的架構,并通過MCP(Model Context Protocol)協議進行集成和調度。系統中主要包含:
- 招投標公告數據采集與抽取Agent:自動化爬取政府采購平臺和行業門戶上的招投標公告。利用爬蟲獲取公告頁面后,結合正則表達式和NLP技術解析文本,抽取項目ID、公告日期、貨物名稱、規格型號、供應商信息、預算金額等字段。例如,用正則
re.search(r"項目編號:(\w+)", text)提取項目編號,用大模型(如騰訊云通義)識別公告摘要內容。采集到的數據先結構化存入關系型數據庫(騰訊云TDSQL-C,以MySQL兼容形式部署)。 - 貨物知識圖譜構建Agent:針對公告和歷史數據中的貨物信息進行實體關系抽取,構建知識圖譜。該Agent從結構化數據中生成三元組(如設備名稱-型號-價格、設備-廠商等關系),并將其寫入Neo4j圖數據庫。Neo4j擅長存儲復雜的關系型數據,能夠快速查詢項目與投標人、設備與供應商之間的多層關系,提高跨表查詢效率。同時,Agent會維護圖譜更新機制:當新的公告到來時,自動觸發圖譜更新,補充新增實體和關系。知識圖譜技術通過“節點-關系”結構打破數據孤島,將分散的招投標信息關聯起來,實現自動化信息提取和多維度查詢。
- 招標文件解析Agent:針對采購方提供的招標文件(通常為Word/PDF格式),該Agent使用OCR和自然語言處理技術提取貨物清單和技術指標。解析后的貨物列表(包括名稱、型號、數量等)與圖譜中的實體進行比對。例如,調用OCR庫讀取圖片文本后,用模型或規則提取“X型CT機”清單信息,并傳遞給圖譜Agent進行匹配。
- MCP協議整合與調度:本系統核心由一個MCP主機(可由大模型AI Agent承擔,如Claude Agent)負責協調。MCP采用客戶端-服務器架構:主機應用負責發起與各Agent的連接,各Agent以MCP服務器形式開放能力。主機創建多個MCP客戶端,每個客戶端與一個特定Agent服務器一一對應。在運行中,主機根據任務需要通過MCP調用不同Agent。例如,當需要獲取最新公告時,主機會通過公告采集Agent的MCP服務請求數據;待公告數據返回后,相關上下文(如新項目ID、公告鏈接)會傳遞給圖譜構建Agent,觸發知識圖譜更新;隨后,主機可再調用文件解析Agent,將采購文件中的貨物列表與知識圖譜中現有實體進行匹配和溯源。MCP客戶端和服務器之間通過JSON-RPC消息(requests/responses/notifications)進行交互,可靈活傳遞查詢參數和返回結果。
整個架構中采用的技術棧包括騰訊云MCP SDK(可選用Python/Node版)開發Agent間通信,中間結果存儲使用Neo4j圖數據庫和TDSQL-C關系型數據庫,日志與監控則依托騰訊云CLS日志服務記錄系統運行軌跡。通過MCP協議,系統實現了AI應用與爬蟲、數據庫、OCR等外部資源的無縫對接,正如MCP被喻為AI領域的“通用接口”,能夠安全地將LLM與各種資源相連。
MCP交互泳道圖
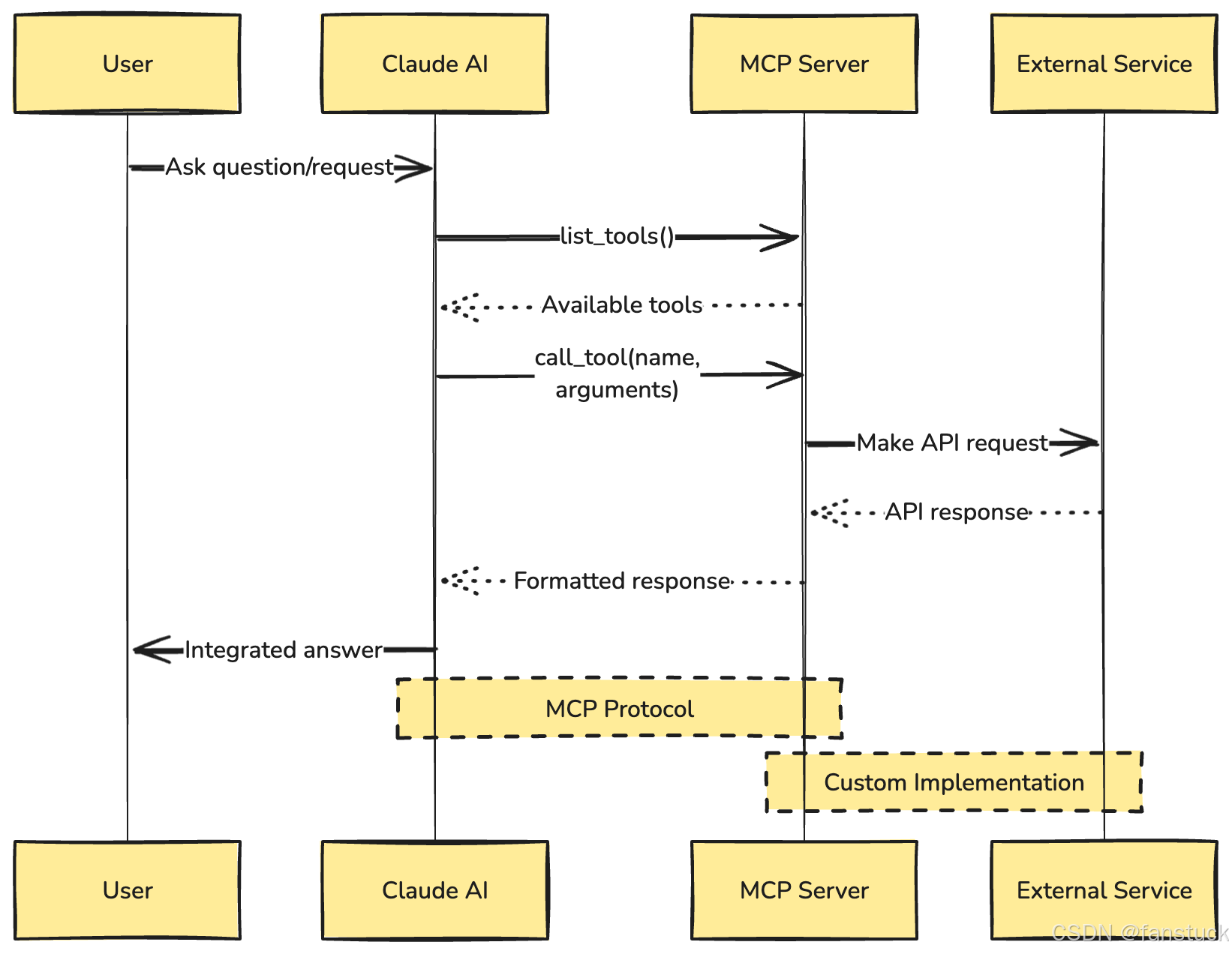
MCP采用客戶端-服務器架構,主要組件包括客戶端、服務器和資源。:
MCP主機(Host):MCP主機是運行AI應用程序的環境,負責發起與外部資源的連接。例如,Claude Desktop等AI助手應用,需要通過MCP訪問本地文件、數據庫或遠程API。在實際應用中,用戶通過Claude Desktop與AI助手交互,當需要訪問本地文件時,Claude Desktop作為MCP主機,協調AI助手與本地文件系統之間的通信。
MCP客戶端(Client):MCP客戶端是嵌入在主機應用中的連接器,負責與MCP服務器建立一對一的連接。它充當AI模型與外部資源之間的橋梁,管理數據請求和響應的傳遞。例如,在Claude Desktop中,MCP客戶端會向服務器請求訪問特定的本地文件或遠程API,并將獲取的數據傳遞給AI模型進行處理。
MCP服務器(Server):MCP服務器是一個輕量級程序,通過標準化的MCP協議開放特定功能。它負責處理來自客戶端的請求,與本地或遠程資源交互,并將結果返回給客戶端。例如,MCP服務器可以連接到本地文件系統,提供文件讀取和寫入功能;或連接到遠程API,獲取實時數據。這種設計使得AI應用能夠通過統一的接口訪問多種資源,簡化了開發和集成的復雜度。
當AI模型需要訪問外部數據或功能時,MCP客戶端向MCP服務器發送請求,服務器與相應的數據源或工具交互后,將結果返回給客戶端,最終供AI模型使用。清晰地看出MCP 本身不處理復雜的邏輯;它只是協調 AI 模型和工具之間數據和指令的流動。
?三、技術實現與核心代碼詳解
1、整體技術實現邏輯(概述)
整體實現的邏輯為:
招投標公告采集Agent:
- 通過爬蟲獲取招投標公告頁面數據;
- 使用大模型或規則抽取關鍵信息;
- 將結構化數據存儲在TDSQL-C(MySQL)數據庫;
- 數據存儲成功后,通過MCP發送通知至知識圖譜Agent。
貨物知識圖譜構建Agent:
- 接收公告Agent的數據;
- 使用大語言模型(如騰訊云通義)、NLP技術抽取實體關系;
- 存入Neo4j圖數據庫;
- 構建完成圖譜更新后,通過MCP通知招標文件解析Agent。
招標文件解析Agent:
- 接收采購方上傳的招標文件;
- 使用OCR、規則或大模型抽取貨物信息;
- 通過MCP調用知識圖譜進行比對;
- 將比對后的分析結果返回給前端界面,呈現給用戶。
MCP主機Agent:
- 基于騰訊云MCP協議協調各個Agent;
- 傳遞上下文數據,管理調用鏈路,自動觸發各Agent任務。
2.MCP工具選型與配置流程
為了實現多個Agent之間的高效協作,我們選擇使用騰訊云代碼助手 Craft 開發智能體進行本地 MCP Server 配置,擴展應用程序的功能。結合MCP(Model Context Protocol)協議來構建和配置MCP Server。
自定義配置 MCP Server
與 Cursor、Claude Desktop、Cherry Studio 等這些 MCP Host(支持了 MCP 的應用程序)一樣,騰訊云代碼助手也提供了配置 MCP Server 的入口。
首先需要確保開發環境滿足具備安裝MCP Server 的包管理工具,常見的有 NPX、UVX 和 PIP。
NPX
NPX 是 Node.js 的一個命令行工具,用于直接運行 npm 包中的命令,無需全局安裝或顯式指定路徑,安裝 nodejs 就默認自帶這個工具。如果未安裝,請進行安裝 Node.js。安裝好后,可以用以下命令查看是否安裝成功:
代碼語言:shell
AI代碼解釋
node -v # 查看 Node.js 版本
npm -v # 查看 npm 版本UV
uvx 是 uv 工具鏈的擴展命令,是一個用 Rust 編寫的極快的 Python 包和項目管理器。
PIP
PIP 是 Python 的包管理工具。
在 Craft 模式下,單擊 MCP 配置按鈕:
單擊配置 MCP Server 進行配置:
也可通過單擊**+**號進行配置。
在 Craft_mcp_settings.json 配置文件中添加 MCP Server 服務器的配置。
配置格式如下:
AI代碼解釋
{"mcpServers": {"mcp-server-time": {"command": "python","args": ["-m","KnowledgeGraphAgent"],"disabled": false}}
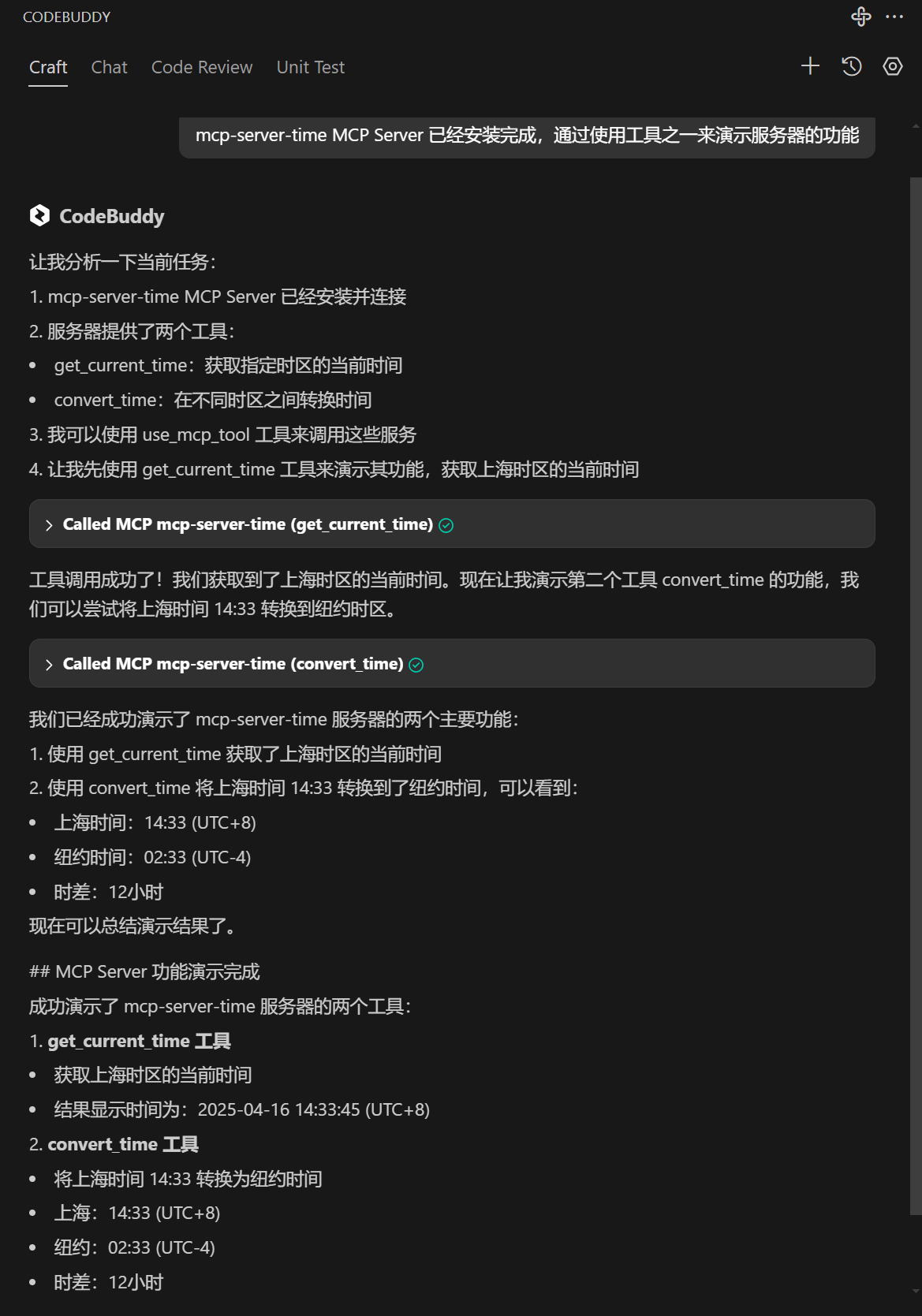
}配置文件填寫完成并保存后,可在 MCP Server 配置列表查看是否配置生效。mcp-server服務器的狀態為綠色,表示生效,紅色表示未生效。調用成功示例:
3、詳細步驟與核心代碼示例(模塊化)
(1)招投標公告數據采集Agent核心邏輯
Agent功能定義:
- 爬取招標網站公告數據;
- 數據結構化存入TDSQL-C;
- MCP消息推送給知識圖譜Agent。

(2)貨物知識圖譜構建Agent核心邏輯
此Agent功能:
- 接收公告數據,抽取知識;
- 構建知識圖譜(Neo4j);
- MCP通知招標文件解析Agent圖譜更新完成。
代碼語言:python
核心邏輯為知識圖譜更新后通過MCP通知解析Agent啟動后續流程。
數據存儲到 Neo4j 圖數據庫設計思路
Neo4j 是一種圖數據庫,特別適合存儲復雜關系數據。在本項目中,我們將招投標公告的數據存儲為以下結構:
- 節點(Node):
Project(項目):表示每個招投標項目。
Bidder(投標人):表示每個投標公司。
- 關系(Relationship):
BID_ON:表示投標人對項目的投標行為,包含投標金額等屬性。
我們通過 Neo4j 的 Python 驅動實現數據存儲:
代碼語言:python
(3)招標文件解析Agent核心邏輯
此Agent功能:
- 接收招標文件;
- OCR/NLP解析貨物列表;
- 使用MCP向知識圖譜Agent查詢數據;
- 輸出匹配結果。
(4)MCP主機Agent邏輯示意(任務調度Agent)
騰訊云MCP的典型用法即為構建一個主機Agent統一調度各子Agent:
四、效果驗證與實踐落地成果展示
在系統正式部署前,數據的獲取和處理常常依賴于人工抓取和手動清洗,過程繁瑣且效率低。為了實現“結構化提取 + 高效比對 + 智能溯源”的目標,我們構建了以下閉環流程。
招標公告信息采集與處理
在第一步,通過自主開發的爬蟲系統,我們從多個公開資源平臺批量采集招標公告、結果公告等文本數據。下圖為爬蟲抓取模塊的流程示意:


原始數據多為HTML格式或非結構化文本,經過初步清洗后會被送入大語言模型進行智能抽取。
大語言模型輔助結構化抽取
我們利用如DeepSeek、Qwen等大語言模型,在結合預設Prompt的情況下,對公告文本進行實體識別、屬性提取和字段歸類,最終輸出統一格式的JSON結構,便于后續處理與入庫。

這些數據隨后被統一入庫,形成結構化的數據集,為后續的圖譜構建與解析比對提供原始素材。
知識圖譜驅動的貨物溯源分析
以“心電圖機”為例,當某新項目招標中出現該關鍵詞時,系統自動聯動知識圖譜模塊,根據品牌、型號、參數、采購數量等字段,在圖譜中檢索出過往中標記錄,提供溯源路徑。
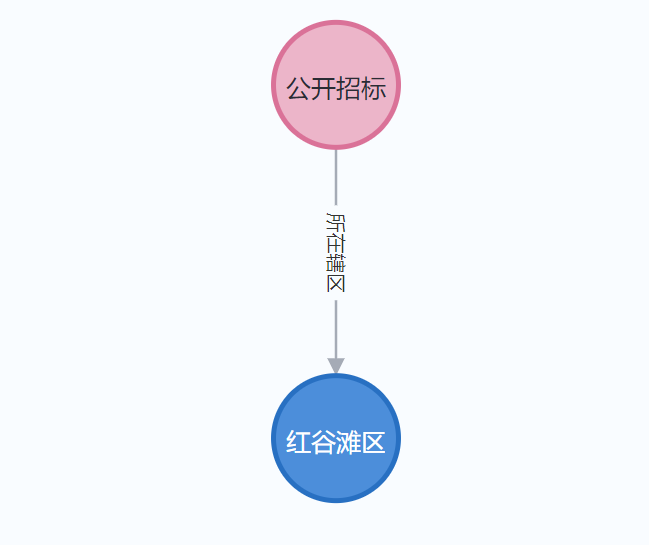
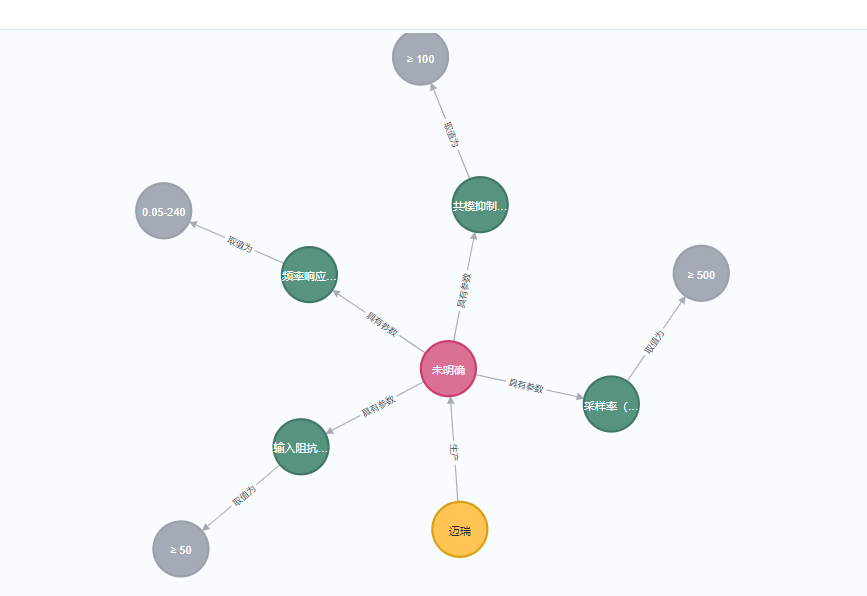
MCP在其中扮演調度核心角色,負責在多個Agent之間傳遞解析內容、調用知識圖譜Agent、返回結果,實現端到端自動化聯動。
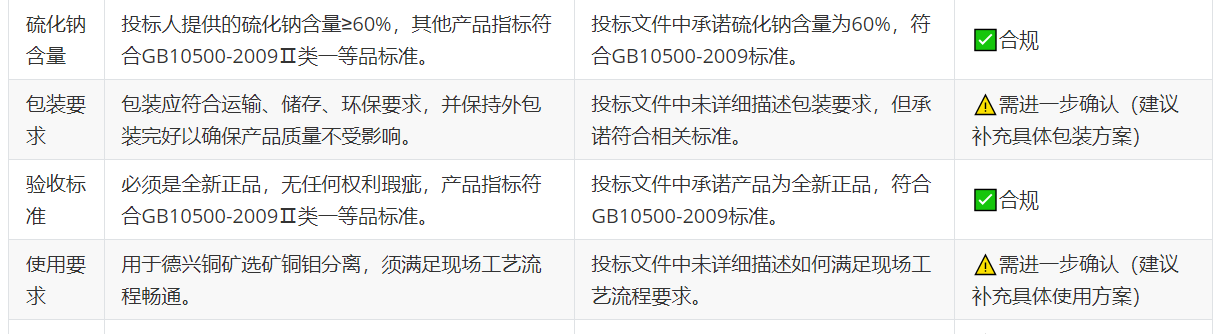
招標文件解析智能輔助決策
招標單位往往不會將所有評審重點直白列出,而是通過評分細則、技術條款、合同約束等方式隱含表達訴求。我們的系統通過招標文件解析Agent,對文檔內容進行語義理解和結構化提取,結合知識圖譜,自動判斷招標需求是否與投標人資質、產品信息匹配。
最終結果以可視化方式呈現,供投標人員決策參考,大幅提升中標率并規避無效投標。
五、項目結語:從場景創新邁向智能決策的未來
在本次“從知識圖譜到精準決策:基于MCP的招投標貨物比對溯源系統實踐”項目中,我們成功地將人工智能、大數據處理、知識圖譜構建以及MCP協議集成等前沿技術,應用于招投標領域的實際業務場景中,構建了一個高效、智能的招投標貨物比對溯源系統。
在人工智能技術不斷發展的今天,如何將其有效地應用于實際業務場景,提升生產力,是每一個開發者需要思考的問題。本項目的實踐,正是對這一問題的積極探索和回答。我們相信,隨著技術的不斷進步和應用的深入,未來的招投標領域將更加智能、高效、透明。
我們誠邀廣大開發者加入到MCP廣場的建設中,共同推動工具普惠,分享實踐經驗,助力更多企業實現數字化轉型。
讓我們攜手前行,在AI技術重構生產力的時代,共同開創更加智能、高效的未來!
?)








—芯片封裝中的開爾文源極)


,圖解超贊超詳細!!!)
)



-圖像識別的實現)

