SHAP分析!Transformer-BiLSTM組合模型SHAP分析,模型可解釋不在發愁!
目錄
- SHAP分析!Transformer-BiLSTM組合模型SHAP分析,模型可解釋不在發愁!
- 效果一覽
- 基本介紹
- 程序設計
- 參考資料
效果一覽
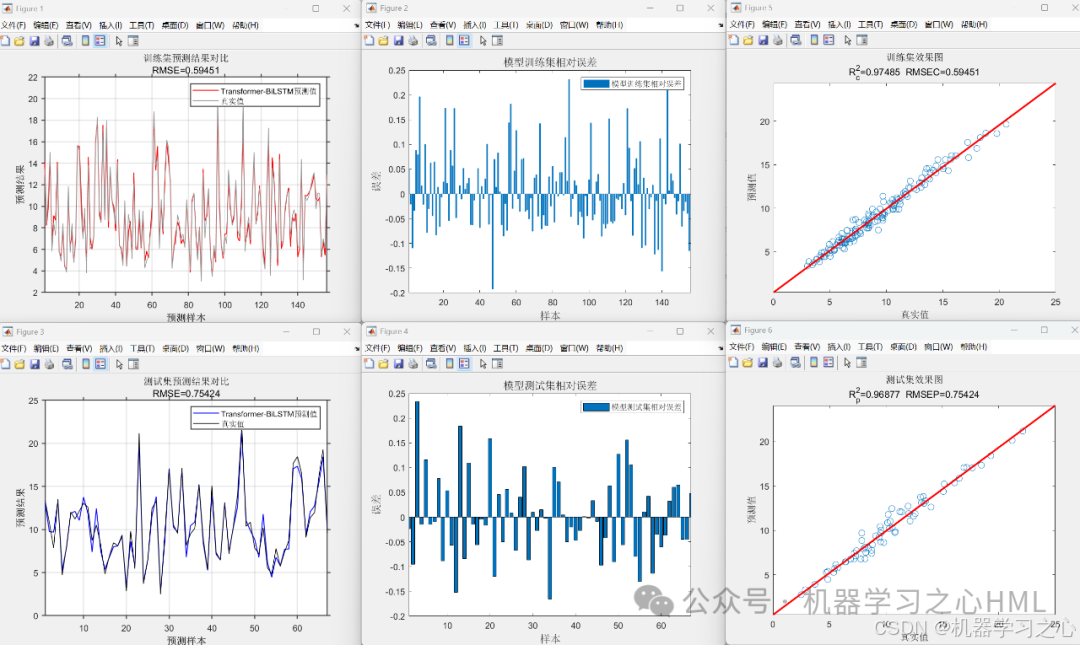
基本介紹
基于SHAP分析的特征選擇和貢獻度計算,Matlab2023b代碼實現;基于MATLAB的SHAP可解釋Transformer-BiLSTM回歸模型,敏感性分析方法。
詳細介紹
詳細介紹
-
引言
在正向滲透(Forward Osmosis, FO)過程中,水通量的精準預測對于優化膜分離工藝和提升系統效率具有重要工程意義。然而,傳統機理模型常受限于復雜的傳質動力學方程,難以兼顧預測精度與可解釋性。本研究提出一種融合Transformer-BiLSTM與SHapley加性解釋(SHAP)的混合建模框架,旨在構建高精度且可解釋的回歸模型,以解析操作參數對水通量的非線性影響機制。該模型以膜面積、進料/汲取液流速及濃度等關鍵操作參數為輸入特征,通過SHAP方法量化特征貢獻,為工藝優化提供透明化決策支持。 -
方法論
2.1 數據準備與預處理
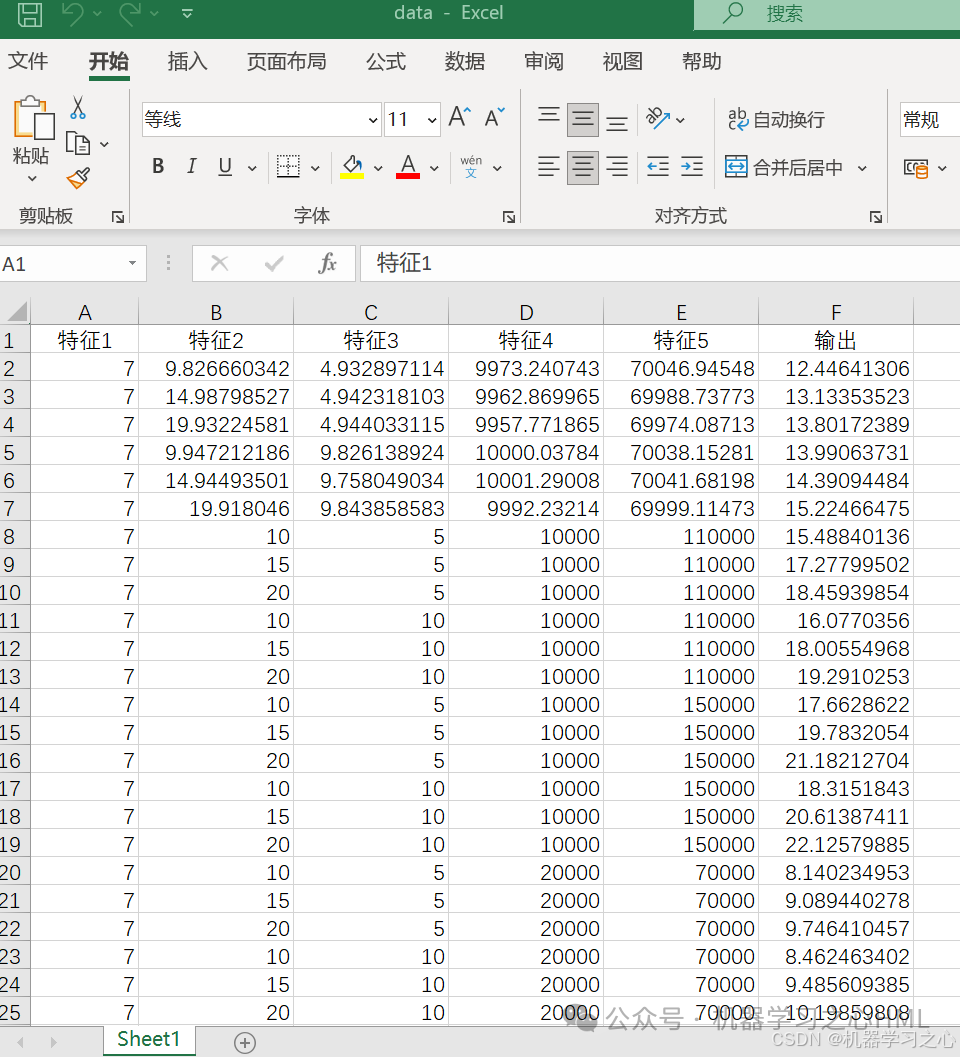
實驗數據采集自FO工藝數據庫,包含六維參數(5輸入特征,1輸出目標)。輸入特征涵蓋膜面積、進料流速、汲取液流速、進料濃度及汲取液濃度。數據經歸一化處理,以消除量綱差異。
2.2 Transformer-BiLSTM組合模型構建與訓練
位置編碼(Position Embedding)
:為序列數據添加位置信息,彌補自注意力機制對位置不敏感的缺陷。
自注意力層(Self-Attention)
:捕捉輸入序列中不同位置間的全局依賴關系,通過多頭注意力機制(4個頭)增強模型表達能力。
BiLSTM層
:捕獲數據的時序特征。
全連接層(Fully Connected Layer)
:映射到目標輸出維度(回歸任務)。
采用MATLAB R2023b實現Transformer-BiLSTM架構。使用Adam優化器,結合學習率衰減(初始學習率1e-3,450輪后衰減為初始值的10%)和L2正則化(系數1e-4)防止過擬合。
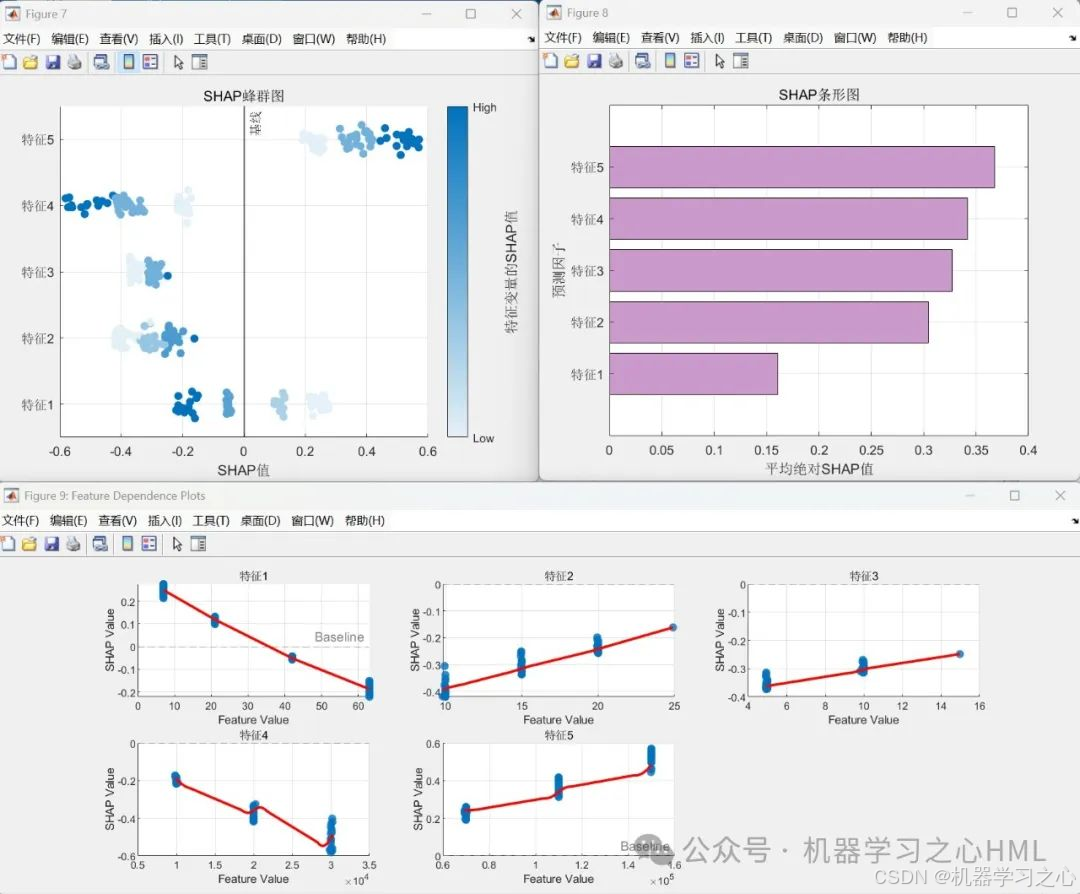
2.3 SHAP可解釋性分析
SHAP值基于合作博弈論中的Shapley值理論,量化特征對模型預測的邊際貢獻。通過Shapley值量化每個特征對預測結果的貢獻,提供模型可解釋性。

- 結論
本研究成功構建了基于Transformer-BiLSTM與SHAP的可解釋回歸模型,實現了FO水通量的高精度預測與特征貢獻解析。方法學創新體現于:引入SHAP方法打破黑箱限制,提供全局及局部雙重解釋視角。
實現步驟
數據準備:
導入數據并隨機打亂。
劃分訓練集和測試集,歸一化至[0, 1]區間。
調整數據格式為序列輸入(reshape和cell格式)。
模型構建:
定義輸入層、位置編碼層、自注意力層和全連接層。
通過加法層將輸入與位置編碼相加。
訓練與預測:
使用trainNetwork進行模型訓練。
預測結果反歸一化后計算誤差指標。
可視化與解釋:
繪制預測結果對比圖、誤差分布圖及線性擬合圖。
計算SHAP值并生成特征重要性圖和依賴圖。
應用場景
回歸預測任務:適用于需要預測連續值的場景,如:
時序預測(股票價格、能源需求、氣象數據)。
工業預測(設備壽命、產量預測)。
商業分析(銷售額、用戶行為預測)。
需解釋性的場景:SHAP分析可幫助理解特征影響,適用于:
金融風控(解釋貸款違約風險的關鍵因素)。
醫療診斷(分析生理指標對疾病預測的貢獻)。
科學研究(識別實驗數據中的關鍵變量)。
數據集
程序設計
- 完整程序和數據下載私信博主回復Matlab也能實現組合模型SHAP可解釋分析!Transformer-BiLSTM+SHAP分析,模型可解釋不在發愁!。
數據預處理與劃分:導入數據并劃分為訓練集(70%)和測試集(30%),進行歸一化處理以適應模型輸入。
模型構建:搭建基于Transformer-BiLSTM結構,包含位置編碼、自注意力機制、LSTM層和全連接層。
模型訓練與預測:使用Adam優化器訓練模型,并在訓練集和測試集上進行預測。
性能評估:計算R2、MAE、MAPE、MSE、RMSE等回歸指標,并通過圖表展示預測結果與真實值的對比。
模型解釋:通過SHAP(Shapley值)分析特征重要性,生成摘要圖和依賴圖,增強模型可解釋性。
.rtcContent { padding: 30px; } .lineNode {font-size: 10pt; font-family: Menlo, Monaco, Consolas, "Courier New", monospace; font-style: normal; font-weight: normal; }
%% 清空環境變量
warning off % 關閉報警信息
close all % 關閉開啟的圖窗
clear % 清空變量
clc % 清空命令行
rng('default');
%% 導入數據
res = xlsread('data.xlsx');
%% 數據分析
num_size = 0.7; % 訓練集占數據集比例
outdim = 1; % 最后一列為輸出
num_samples = size(res, 1); % 樣本個數
res = res(randperm(num_samples), :); % 打亂數據集(不希望打亂時,注釋該行)
num_train_s = round(num_size * num_samples); % 訓練集樣本個數
f_ = size(res, 2) - outdim; % 輸入特征維度
%% 劃分訓練集和測試集
P_train = res(1: num_train_s, 1: f_)';
T_train = res(1: num_train_s, f_ + 1: end)';
M = size(P_train, 2);
P_test = res(num_train_s + 1: end, 1: f_)';
T_test = res(num_train_s + 1: end, f_ + 1: end)';
N = size(P_test, 2);
% ------------------ SHAP值計算 ------------------
x_norm_shap = mapminmax('apply', data_shap', x_settings)'; % 直接應用已有歸一化參數
% 初始化SHAP值矩陣
shapValues = zeros(size(x_norm_shap));
refValue = mean(x_norm_shap, 1); % 參考值為特征均值
% 計算每個樣本的SHAP值
rtcContent { padding: 30px; } .lineNode {font-size: 10pt; font-family: Menlo, Monaco, Consolas, "Courier New", monospace; font-style: normal; font-weight: normal; }
for i = 1:numSamplesx = shap_x_norm(i, :); % 當前樣本(歸一化后的值)shapValues(i, :) = shapley_transformer-Bilstm(net, x, refValue_norm); % 調用SHAP函數
end參考資料
[1] https://blog.csdn.net/kjm13182345320/article/details/128163536?spm=1001.2014.3001.5502
[2] https://blog.csdn.net/kjm13182345320/article/details/128151206?spm=1001.2014.3001.5502





—芯片封裝中的開爾文源極)


,圖解超贊超詳細!!!)
)



-圖像識別的實現)





