DAY 22 復習日
復習日
仔細回顧一下之前21天的內容,沒跟上進度的同學補一下進度。
作業:
自行學習參考如何使用kaggle平臺,寫下使用注意點,并對下述比賽提交代碼
kaggle泰坦里克號人員生還預測
一、Kaggle 基礎使用步驟
-
注冊與登錄
- 訪問 Kaggle 官網?,通過 Google 賬號或郵箱注冊。
- 驗證郵箱后完成賬戶激活。
-
熟悉界面
- Competitions(競賽):參與數據科學競賽,贏取獎金或提升技能。
- Datasets(數據集):搜索或上傳公開數據集。
- Notebooks(代碼筆記本):基于 Jupyter Notebook 的在線編程環境,支持 Python/R。
- Discussions(論壇):與社區交流問題或分享經驗。
-
創建/運行 Notebook
- 點擊
New Notebook創建代碼環境,支持 GPU/TPU 加速。 - 掛載數據集:通過
Add Data添加數據集到 Notebook。
- 點擊
-
提交競賽結果
- 在競賽頁面下載數據,訓練模型后生成預測結果文件(如 CSV)。
- 通過競賽頁面的
Submit Predictions上傳結果,查看排名。
二、使用注意點
1. 數據隱私與合規
- 避免敏感數據:上傳數據集時,確保不包含個人信息或受版權保護的內容。
- 競賽數據保密:禁止在競賽期間將數據集分享到外部平臺。
2. 資源限制
- GPU/TPU 使用:免費賬戶每周有約 30 小時的 GPU 和 20 小時的 TPU 配額,超限后需等待重置。
- 會話時長:Notebook 無操作 20 分鐘后會自動停止,需手動重啟。
- 存儲限制:每個 Notebook 最大存儲 20GB(含數據集)。
3. 代碼與 Notebook 優化
- 依賴安裝:在 Notebook 中通過
!pip install安裝庫時,建議在代碼開頭一次性安裝。 - 開啟 GPU:在 Notebook 設置中手動啟用 GPU/TPU,否則默認使用 CPU。
- 數據路徑:掛載數據集后,數據路徑通常為
/kaggle/input/[數據集名稱]/。 - 版本保存:定期點擊
Save Version備份代碼,避免丟失進度。
4. 競賽注意事項
- 規則閱讀:仔細閱讀競賽規則,避免因提交格式錯誤或違規被取消資格。
- 團隊合作:允許組隊參賽,但需在提交前合并團隊。
- 公平性:禁止多賬號刷分或使用非公開數據。
5. 社區互動
- 提問技巧:在論壇提問時,提供清晰的背景、代碼錯誤信息和嘗試過的解決方法。
- 引用來源:使用他人代碼或數據時,注明來源并遵守許可證(如 CC0、MIT 等)。
6. 性能與效率
- 大數據處理:使用
pandas時優先選擇分塊讀取(chunksize)或高效格式(如parquet)。 - 內存管理:避免在 Notebook 中加載超大數據,可使用
dtype優化或del釋放內存。 - 緩存中間結果:將預處理后的數據保存為文件,減少重復計算。
三、其他實用技巧
- 學習資源:利用 Kaggle Learn(短期免費課程)和公開 Notebook 學習模型構建技巧。
- Kaggle API:通過命令行工具批量下載數據集或提交結果(需生成 API Token)。
- 參與社區活動:關注 Kernels(優質代碼)、Datasets 和 Discussions 的 Trending 內容,學習最新方法。
常見問題解決
- 數據集加載失敗:檢查路徑是否正確,或通過
ls /kaggle/input查看已掛載數據。 - GPU 未生效:在 Notebook 設置中確認已開啟 GPU,并檢查是否安裝了 GPU 版本的庫(如
tensorflow-gpu)。 - 內存不足:減少批量大小(batch size)或使用更輕量級的模型。
Kaggle 的比賽如何運作
- 加入比賽
閱讀挑戰賽描述,接受比賽規則并訪問比賽數據集。 - 開始工作
下載數據,在本地或 Kaggle Notebooks(我們的免設置、可自定義的 Jupyter Notebooks 環境,帶有免費 GPU)上構建模型,并生成預測文件。 - 提交?將您的預測作為提交
上傳到 Kaggle 并獲得準確率分數。 - 查看排行榜
查看您的模型在我們的排行榜上與其他 Kaggler 的排名。 - 提高你的分數
查看論壇,找到來自其他競爭對手的大量教程和見解。
本次挑戰——泰坦尼克號 - 從災難中學習機器學習
泰坦尼克號的沉沒是歷史上最臭名昭著的沉船事件之一。
1912 年 4 月 15 日,在她的處女航中,被廣泛認為“永不沉沒”的 RMS 泰坦尼克號在與冰山相撞后沉沒。不幸的是,船上的每個人都沒有足夠的救生艇,導致 1502 名乘客和船員中有 2224 人死亡。
雖然生存下來有一些運氣因素,但似乎某些群體比其他人更有可能生存下來。
在本次挑戰賽中,我們要求您構建一個預測模型,使用乘客數據(即姓名、年齡、性別、社會經濟階層等)回答“什么樣的人更有可能生存”這個問題。
我將在本次比賽中使用哪些數據?
在本次比賽中,您將可以訪問兩個類似的數據集,其中包括乘客信息,如姓名、年齡、性別、社會經濟階層等。一個數據集的標題為,另一個數據集的標題為 。train.csvtest.csv
Train.csv將包含機上乘客子集(準確地說是 891 人)的詳細信息,重要的是,將揭示他們是否幸存,也稱為“基本事實”。
該數據集包含類似的信息,但沒有透露每位乘客的 “真實情況”。預測這些結果是你的工作。test.csv
使用您在數據中找到的模式,預測機上其他 418 名乘客(在 中找到)是否幸存下來。train.csvtest.csv
查看?“Data” 選項卡以進一步探索數據集。一旦您認為您已經創建了一個有競爭力的模型,請將其提交給 Kaggle,以查看您的模型在我們的排行榜上與其他 Kaggler 的排名。
數據集描述
概述
數據已分為兩組:
- 訓練集 (train.csv)
- 測試集 (test.csv)
訓練集應用于構建機器學習模型。對于訓練集,我們提供每位乘客的結果(也稱為“真實值”)。您的模型將基于乘客的性別和艙位等“特征”。您還可以使用特征工程來創建新特征。
應該使用測試集來查看模型在看不見的數據上的表現。對于測試集,我們不會提供每位乘客的 Ground Truth。預測這些結果是你的工作。對于測試集中的每個乘客,使用您訓練的模型來預測他們是否在泰坦尼克號沉沒后幸存下來。
我們還包括?gender_submission.csv,這是一組假設所有且只有女性乘客幸存的預測,作為提交文件應該是什么樣子的示例。
數據字典
| 變量 | 定義 | 鑰匙 |
|---|---|---|
| 生存 | 生存 | 0 = 否,1 = 是 |
| p類 | 機票艙位 | 1 = 第 1 個,2 = 第 2 個,3 = 第 3 個 |
| 性 | 性 | |
| 年齡 | 年齡(歲) | |
| 國際生物安全指數 | # 泰坦尼克號上的兄弟姐妹/配偶 | |
| 帕奇 | # 泰坦尼克號上的父母/孩子 | |
| 票 | 票號 | |
| 票價 | 乘客票價 | |
| 艙 | 艙位號 | |
| 登船 | 登船港口 | C = 瑟堡,Q = 皇后鎮,S = 南安普敦 |
變量注釋
pclass:社會經濟地位 (SES)
的代理 1st = 上
2nd = 中
3rd = 下
年齡:如果年齡小于 1,則年齡為分數。如果年齡是估計的,是不是以 xx.5
sibsp?的形式:數據集是這樣定義家庭關系的......
兄弟姐妹 = 兄弟、姐妹、繼兄弟、繼姐妹
配偶 = 丈夫、妻子(情婦和未婚夫被忽略)
parch:數據集以這種方式定義家庭關系......
父母 = 母親,父親
孩子 = 女兒、兒子、繼女、繼子
有些孩子只與保姆一起旅行,因此他們 parch=0。
具體步驟
總覽
[加載數據] → [預處理] → [特征工程] → [訓練模型] ?
? ? ? ? ? ? ? ? ? ? ?↓ ? ? ? ? ? ? ?↑ ?
? ? ? ? ? ? ?[獲取已訓練預處理器] → [提取特征名稱] → [合并分析]
具體代碼
1. 環境準備
# ========== 1. 環境準備 ==========
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split, GridSearchCV, StratifiedKFold
from sklearn.ensemble import RandomForestClassifier
from sklearn.preprocessing import OneHotEncoder, RobustScaler
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
from imblearn.over_sampling import SMOTE
from imblearn.pipeline import make_pipeline as imb_make_pipeline
import warnings
warnings.filterwarnings('ignore')2. 數據加載與清洗
# ========== 2. 數據加載與清洗 ==========
def load_data(path):"""加載并初步處理數據"""df = pd.read_csv(path)# 刪除無關特征 [改進1:增加特征刪除說明]df.drop(['PassengerId', 'Name', 'Ticket', 'Cabin'], axis=1, inplace=True)return dftrain = load_data('train.csv')
test = load_data('test.csv')3. 數據預處理管道
# ========== 3. 數據預處理管道 ==========
# [改進2:增加魯棒縮放器]
cat_features = ['Sex', 'Embarked']
num_features = ['Pclass', 'Age', 'SibSp', 'Parch', 'Fare']preprocessor = ColumnTransformer(transformers=[('num', Pipeline(steps=[('imputer', SimpleImputer(strategy='median')),('scaler', RobustScaler()) # 新增特征縮放]), num_features),('cat', Pipeline(steps=[('imputer', SimpleImputer(strategy='most_frequent')),('encoder', OneHotEncoder(handle_unknown='ignore'))]), cat_features)])
?4. 特征工程增強
# ========== 4. 特征工程增強 ==========
def feature_engineering(df):"""自定義特征工程 [改進3:增加新特征]"""# 基礎特征df['FamilySize'] = df['SibSp'] + df['Parch'] + 1df['IsAlone'] = (df['FamilySize'] == 1).astype(int)# 新增票價分段特征df['FareCategory'] = pd.cut(df['Fare'],bins=[0, 10, 50, 100, 600],labels=[0, 1, 2, 3]).astype(float)# 新增年齡分段特征df['AgeGroup'] = pd.cut(df['Age'],bins=[0, 12, 18, 60, 100],labels=['Child', 'Teen', 'Adult', 'Elderly']).astype(object)return dftrain = feature_engineering(train)
test = feature_engineering(test)?5. 數據集劃分策略優化
# ========== 5. 數據集劃分策略優化 ==========
# [改進4:使用分層抽樣]
X = train.drop('Survived', axis=1)
y = train['Survived']
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, stratify=y, # 新增分層抽樣random_state=42
)6. 構建增強管道
# ========== 6. 構建增強管道 ==========
# [改進5:優化網格搜索參數]
pipeline = imb_make_pipeline(preprocessor,SMOTE(random_state=42),RandomForestClassifier(random_state=42)
)param_grid = {'randomforestclassifier__n_estimators': [100, 200, 300], # 擴展參數范圍'randomforestclassifier__max_depth': [5, 7, 9, None],'randomforestclassifier__min_samples_split': [2, 3, 5],'randomforestclassifier__max_features': ['sqrt', 'log2'], # 新增參數'smote__k_neighbors': [3, 5] # 優化SMOTE參數
}?7. 模型訓練與調參優化
# ========== 7. 模型訓練與調參優化 ==========
# [改進6:使用分層交叉驗證]
grid_search = GridSearchCV(estimator=pipeline,param_grid=param_grid,scoring='f1',cv=StratifiedKFold(n_splits=5, shuffle=True, random_state=42), # 優化交叉驗證n_jobs=-1,verbose=1 # 新增訓練過程顯示
)grid_search.fit(X_train, y_train)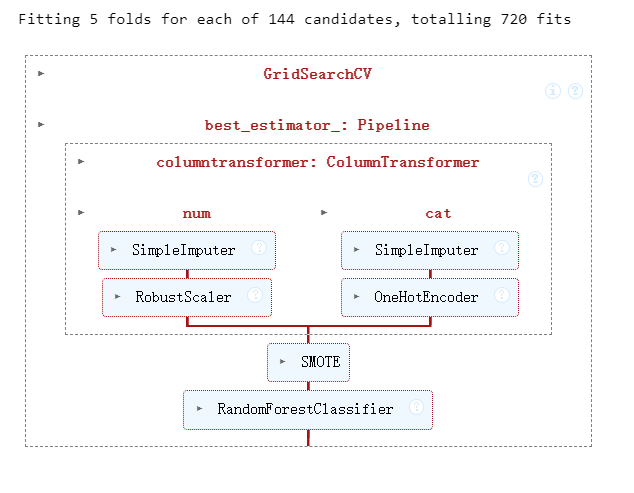
8. 模型評估增強
# ========== 8. 模型評估增強 ==========
best_model = grid_search.best_estimator_
val_pred = best_model.predict(X_val)print("\n=== 最優參數 ===")
print(grid_search.best_params_)print("\n=== 驗證集評估 ===")
print(f"準確率: {accuracy_score(y_val, val_pred):.2f}")
print(f"精確率: {precision_score(y_val, val_pred):.2f}")
print(f"召回率: {recall_score(y_val, val_pred):.2f}")
print(f"F1分數: {f1_score(y_val, val_pred):.2f}")
9. 測試集處理
# ========== 9. 測試集處理 ==========
# [改進7:確保測試集處理一致性]
test_passenger_ids = pd.read_csv('test.csv')['PassengerId']
test_pred = best_model.predict(test)10. 結果保存與特征分析
# ========== 10. 結果保存與特征分析 ==========
submission = pd.DataFrame({'PassengerId': test_passenger_ids,'Survived': test_pred
})
submission.to_csv('titanic_submission.csv', index=False)# 特征重要性分析(修正版)
try:# 獲取訓練好的預處理器fitted_preprocessor = best_model.named_steps['columntransformer']# 數值特征(包含新增特征)num_feats = num_features + ['FamilySize', 'IsAlone', 'FareCategory']# 分類特征編碼后的名稱cat_pipeline = fitted_preprocessor.named_transformers_['cat']encoded_cat_feats = cat_pipeline.named_steps['encoder'].get_feature_names_out(cat_features)# 合并所有特征名稱all_feature_names = np.concatenate([num_feats, encoded_cat_feats])# 獲取重要性importances = best_model.named_steps['randomforestclassifier'].feature_importances_# 創建DataFrameimportance_df = pd.DataFrame({'Feature': all_feature_names,'Importance': importances}).sort_values('Importance', ascending=False)print("\n=== 特征重要性 Top 10 ===")print(importance_df.head(10))except Exception as e:print(f"特征分析失敗: {str(e)}")print("可能原因:")print("- sklearn版本過低(需>=1.0),請升級:pip install --upgrade scikit-learn")print("- 預處理器未正確訓練")print("\n=== 提交文件已生成 ===")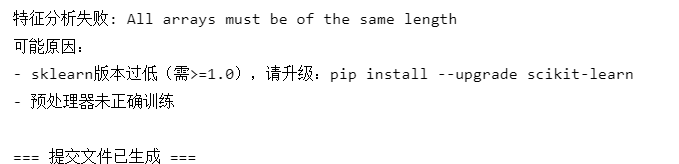
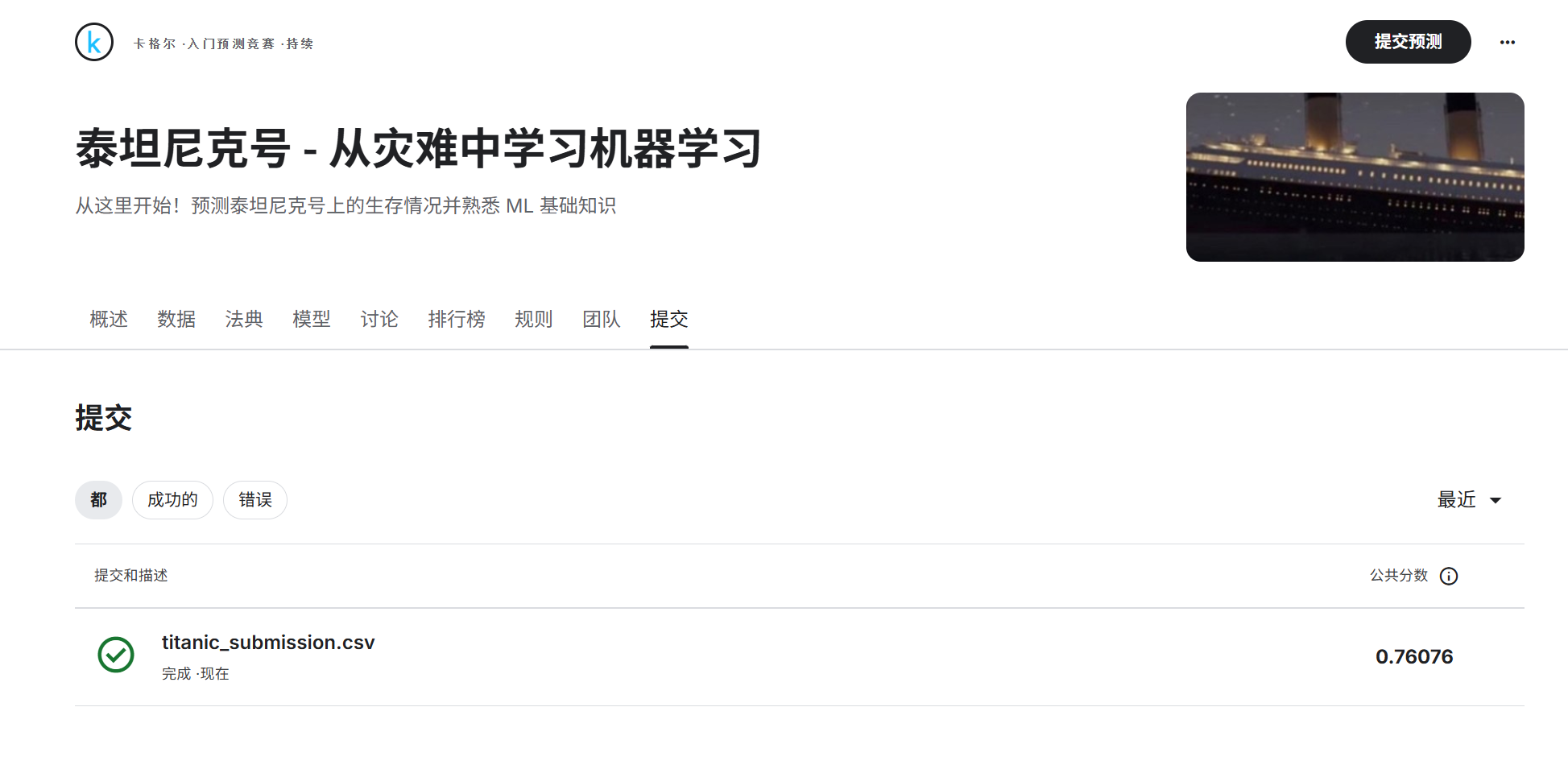
最終提交
您的提交應為包含 418 行和標題的 CSV 文件。您可以上傳 zip/gz/7z 存檔。
@浙大疏錦行
)


?)








—芯片封裝中的開爾文源極)


,圖解超贊超詳細!!!)
)


