5. 決策樹(Decision Tree) - 第5章
算法思想:基于信息增益(ID3)或基尼不純度(CART)遞歸劃分特征。
編寫 test_dtree_1.py? 如下
# -*- coding: utf-8 -*-
""" 5. 決策樹(Decision Tree) """
from sklearn.datasets import load_breast_cancer
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split# 加載 乳腺癌數據
data = load_breast_cancer()
X, y = data.data, data.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)model = DecisionTreeClassifier(criterion='entropy', max_depth=3)
model.fit(X_train, y_train)
print("Accuracy:", model.score(X_test, y_test))
Anaconda 3
運行 python test_dtree_1.py?
?Accuracy: 0.9736842105263158
編寫? test_dtree_2.py? 如下
# -*- coding: utf-8 -*-
""" 5. 決策樹(Decision Tree) """
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn import preprocessing
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix,accuracy_score
from sklearn.tree import plot_tree# 加載鳶尾花數據集
iris = datasets.load_iris()
X = iris.data
y = iris.target
f_names = iris.feature_names
t_names = iris.target_names# 數據預處理:按列歸一化
X = preprocessing.scale(X)
# 切分數據集:測試集 20%
X_train,X_test,y_train,y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 初始化 決策樹 分類模型
dtc = DecisionTreeClassifier()
# 模型訓練
dtc.fit(X_train,y_train)
# 模型預測
y_pred = dtc.predict(X_test)
# 模型評估
# 混淆矩陣
#print(confusion_matrix(y_test,y_pred))
print("準確率: %.4f" % accuracy_score(y_test,y_pred))# 可視化決策樹
plt.figure(figsize=(12,10))
plot_tree(dtc, feature_names=f_names, class_names=t_names, filled=True)
plt.show()
?運行 python test_dtree_2.py?
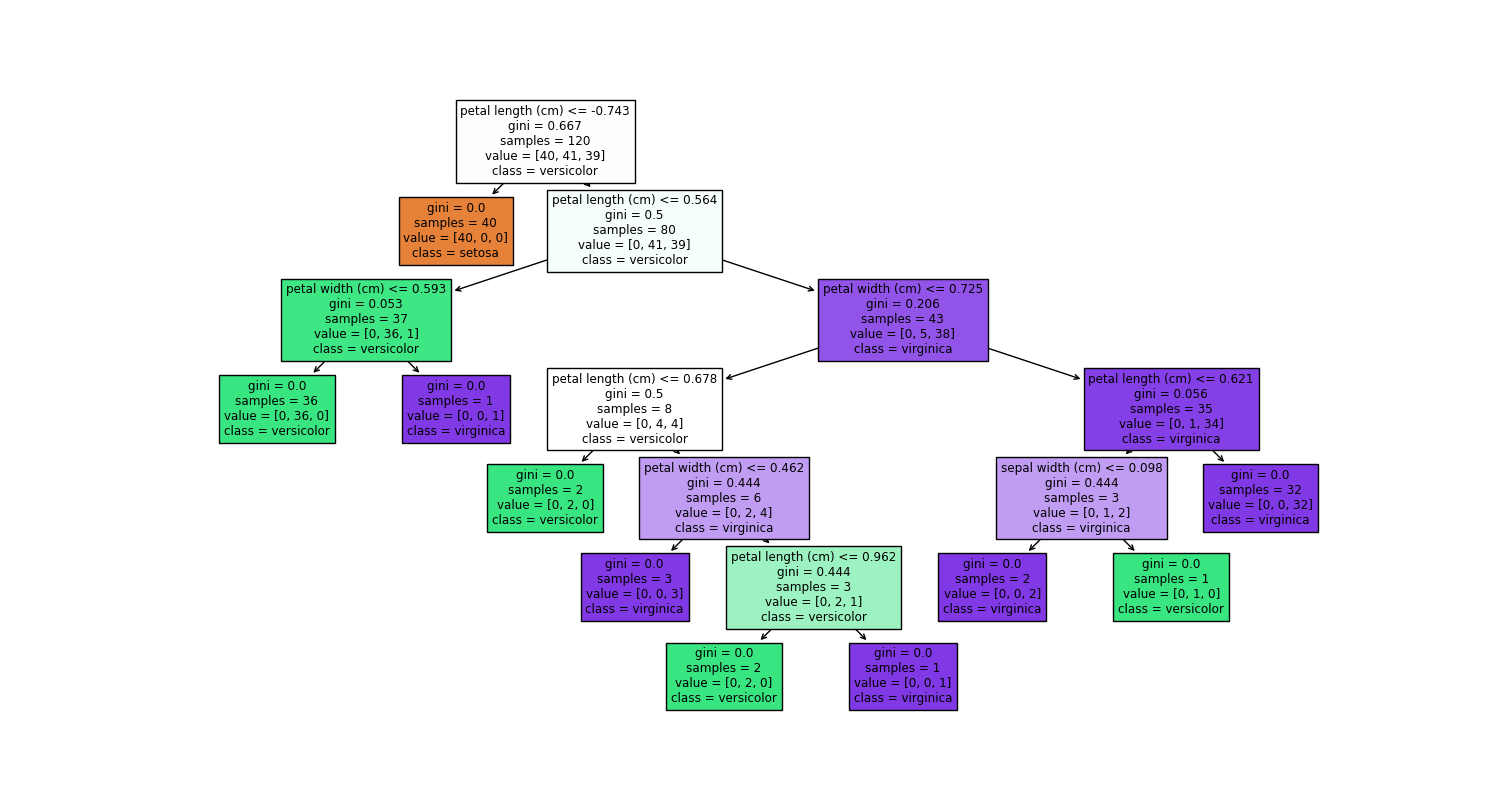






![[Python開發] 如何用 VSCode 編寫和管理 Python 項目(從 PyCharm 轉向)](http://pic.xiahunao.cn/[Python開發] 如何用 VSCode 編寫和管理 Python 項目(從 PyCharm 轉向))
)



:かもしれません (~た?~ない)ほうがいいです)







的?》的部分紀要)