針對推理模型,主要講了四種方法,兩種不需要訓練模型,兩種需要。

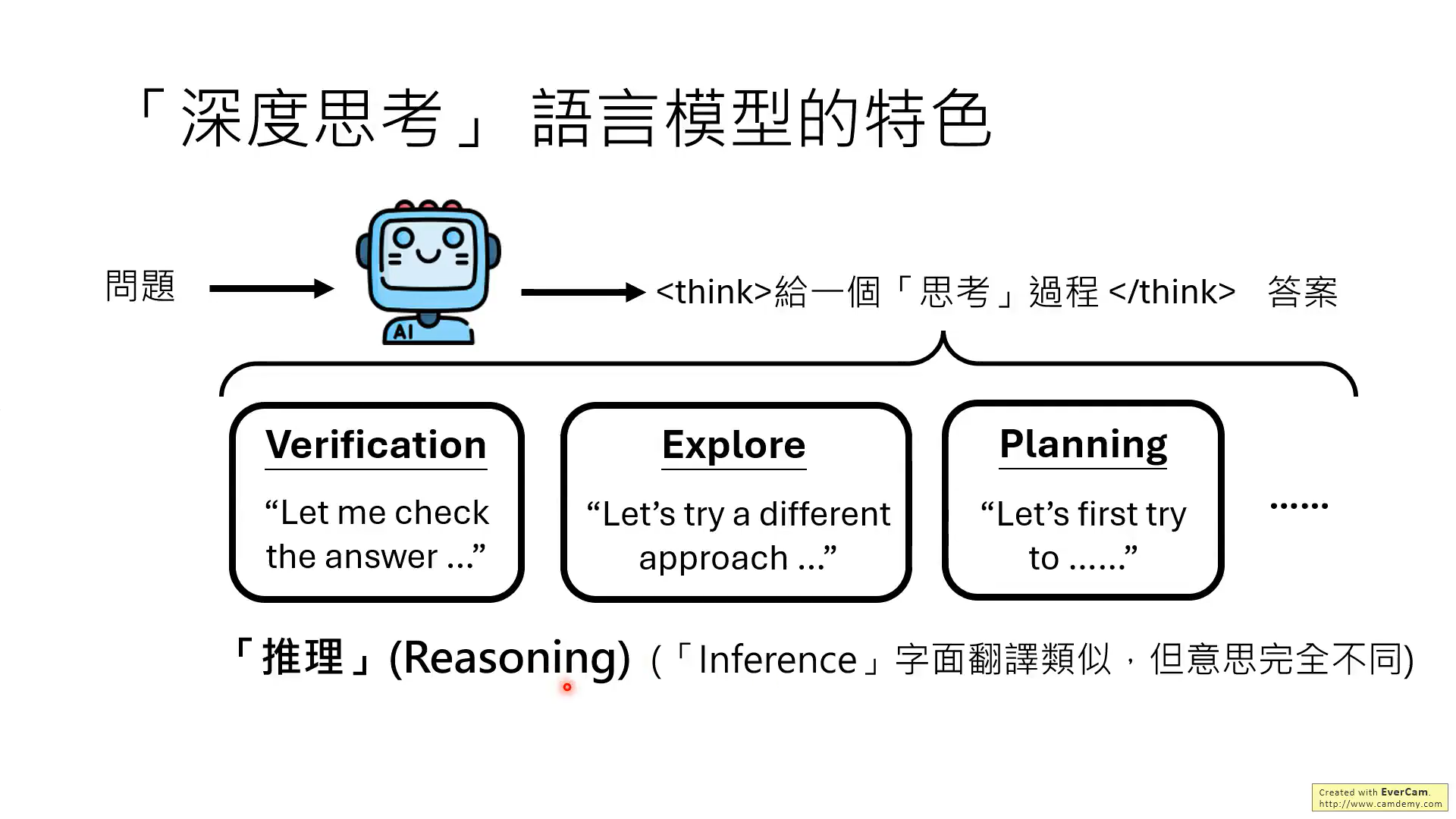
對于reason和inference,這兩個詞有不同的含義!
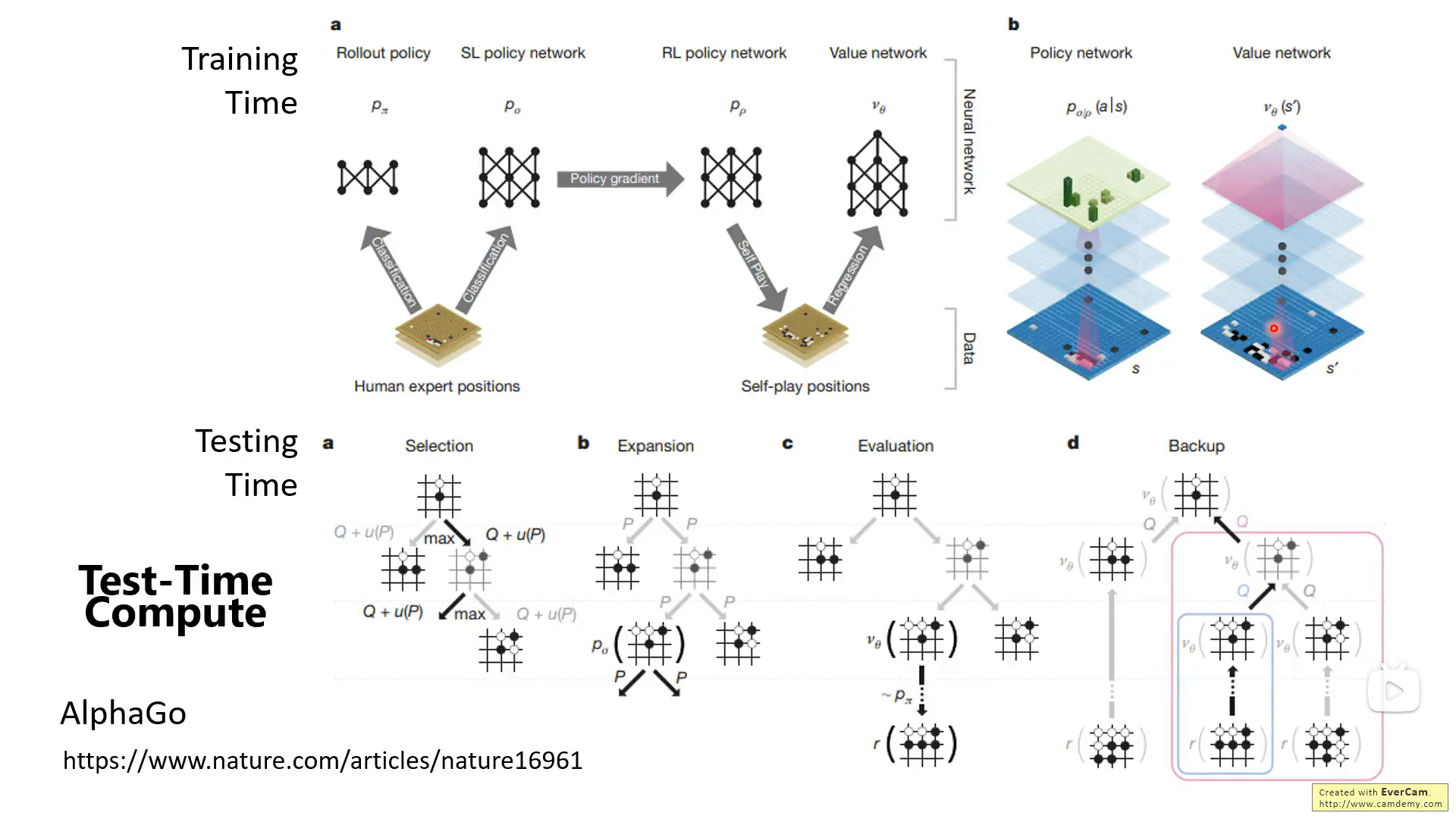
推理時計算不是新鮮事,AlphaGo就是如此。
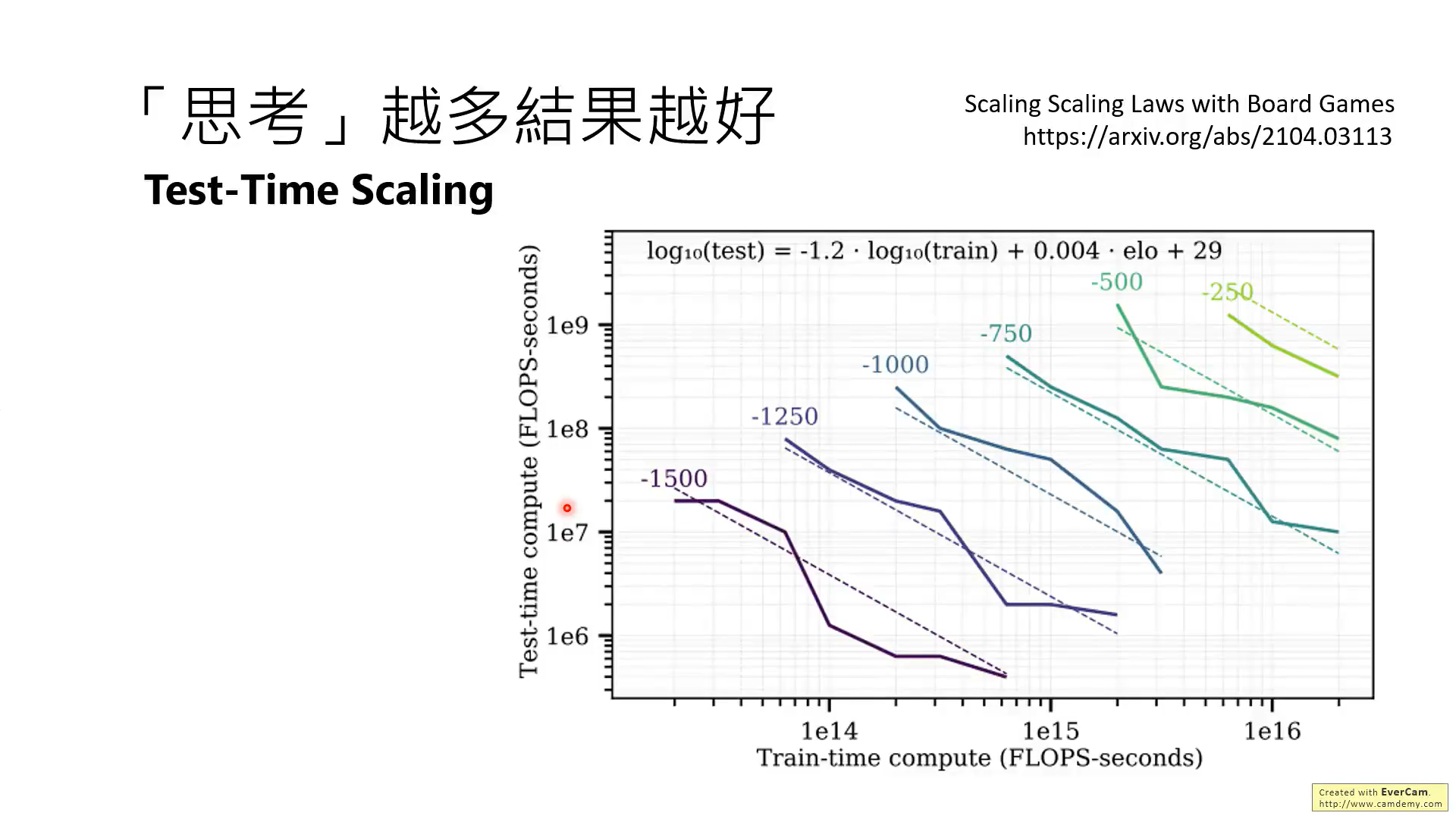
這張圖片說明了將訓練和推理時計算綜合考慮的關系,-1500到-250這些數值表示模型的準確度。
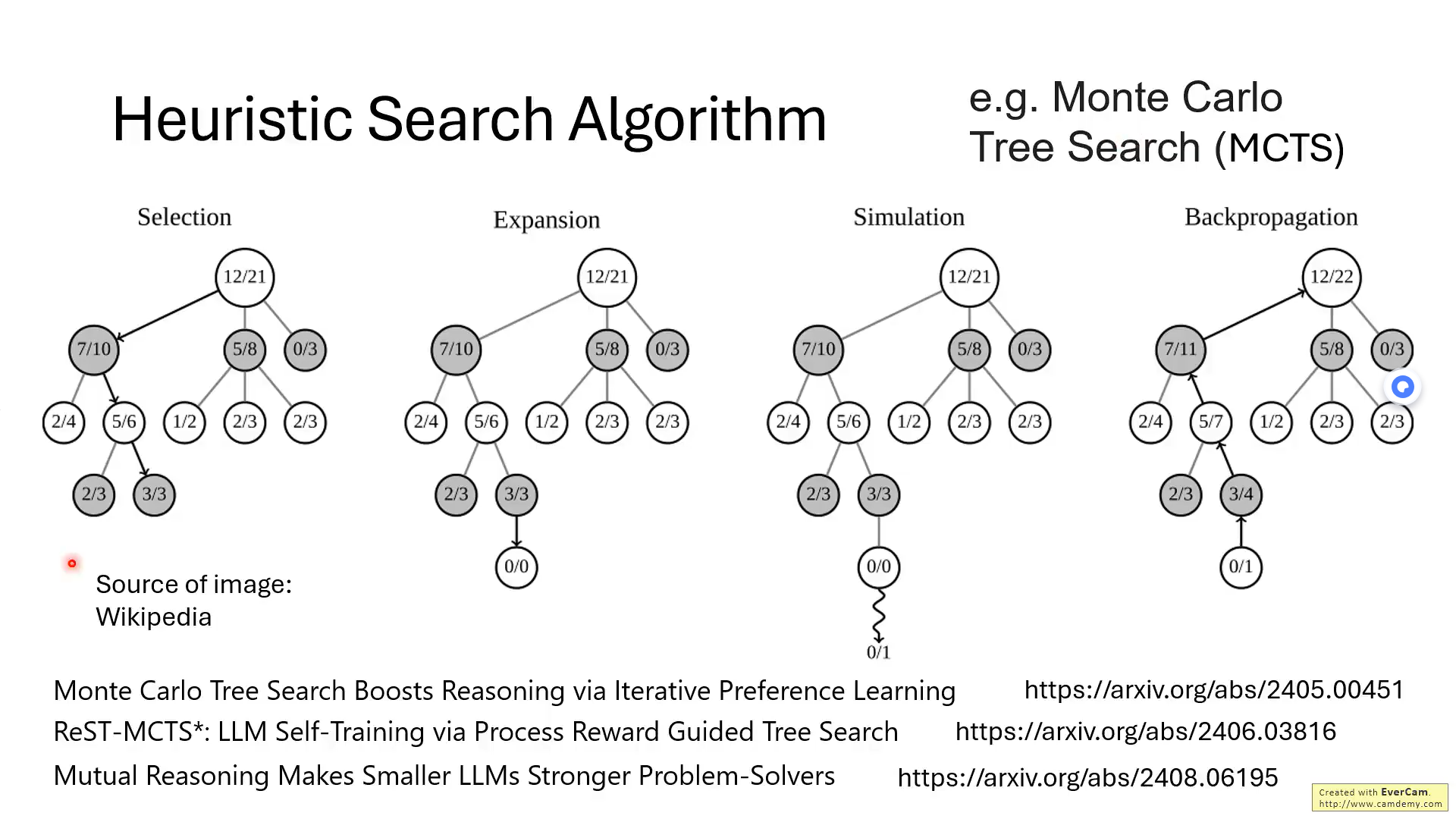
這張圖片有關MCTS用于推理模型的幾篇主要論文。
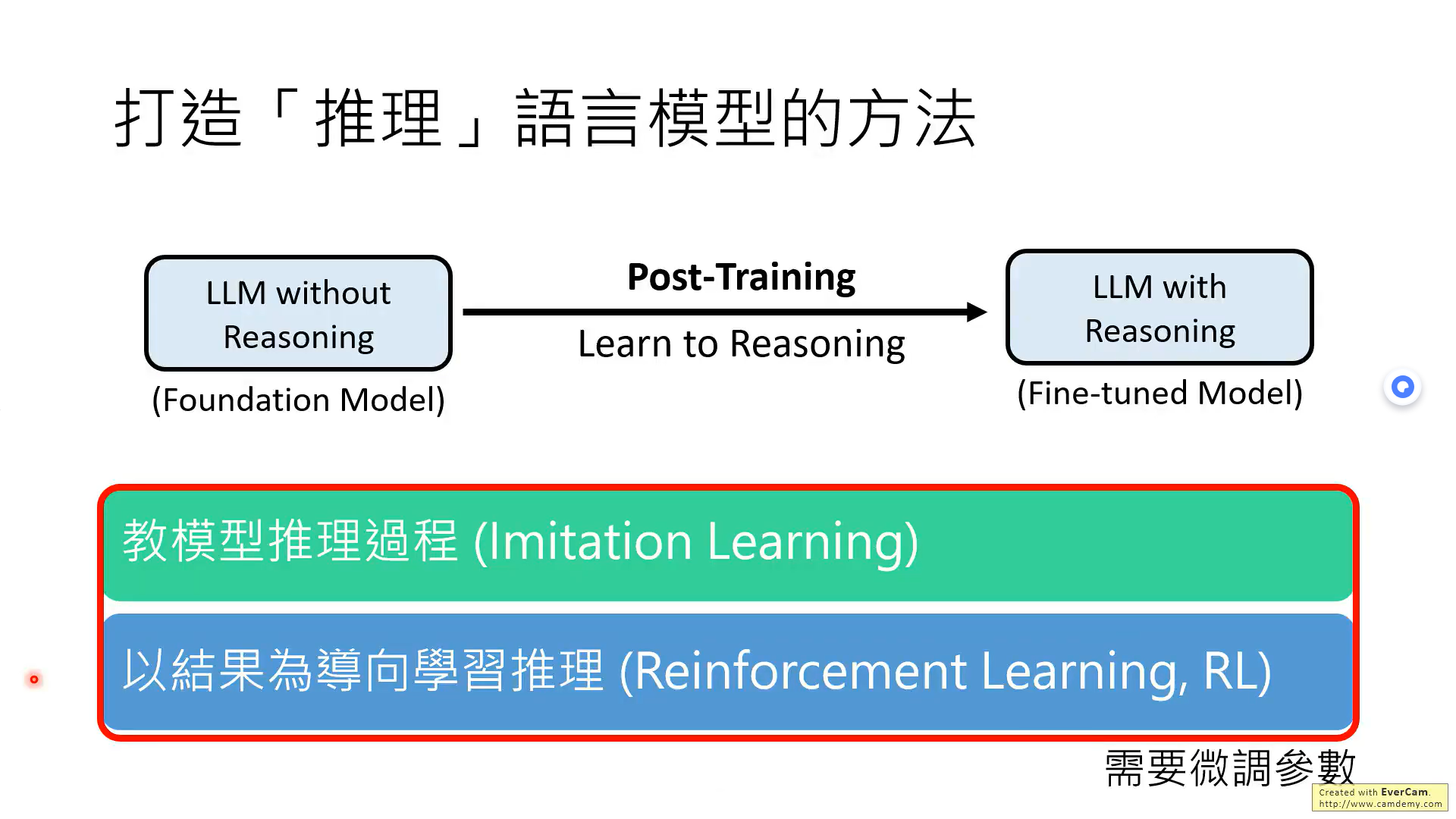
下面是兩種需要微調模型的方法。
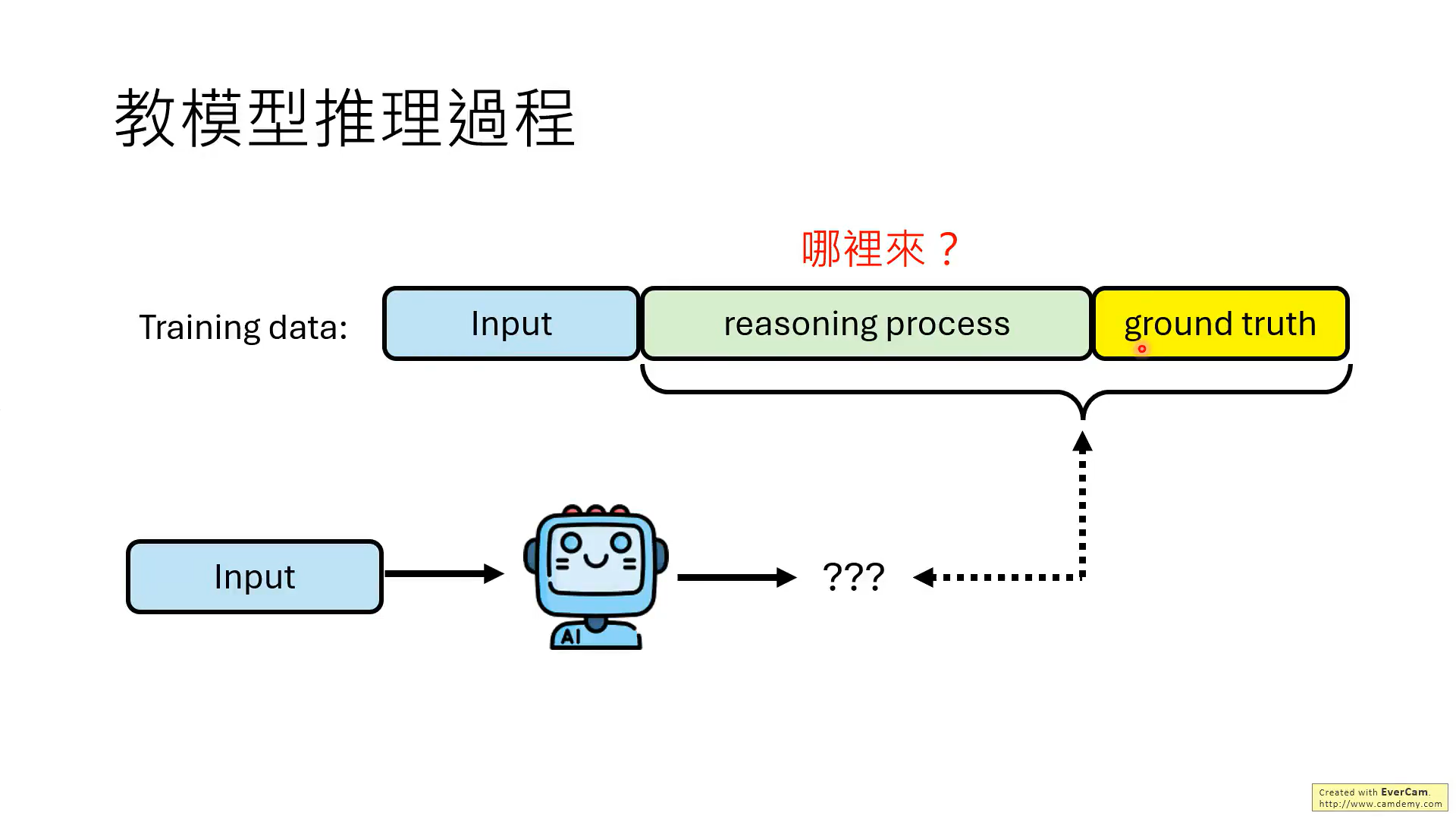
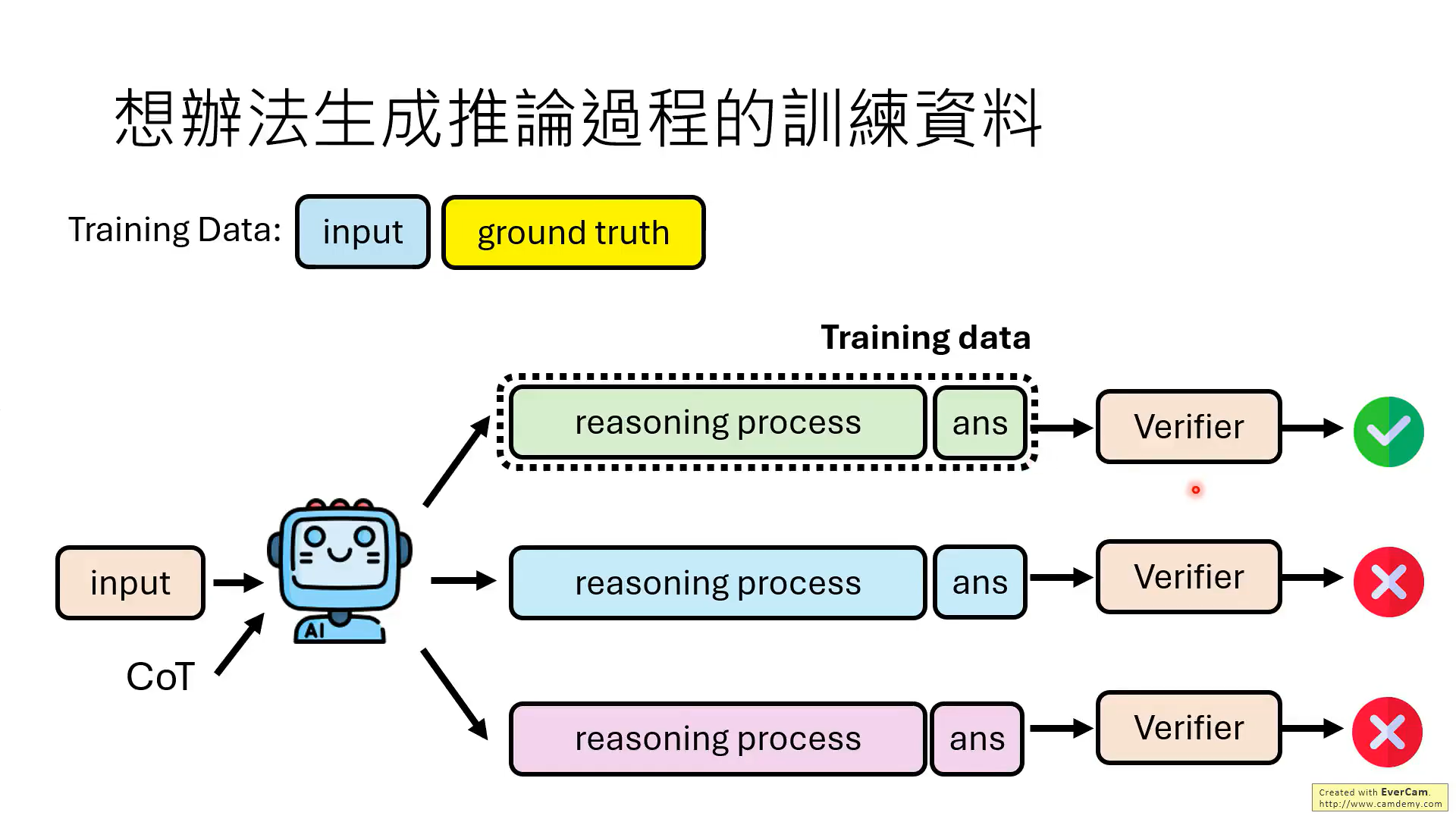
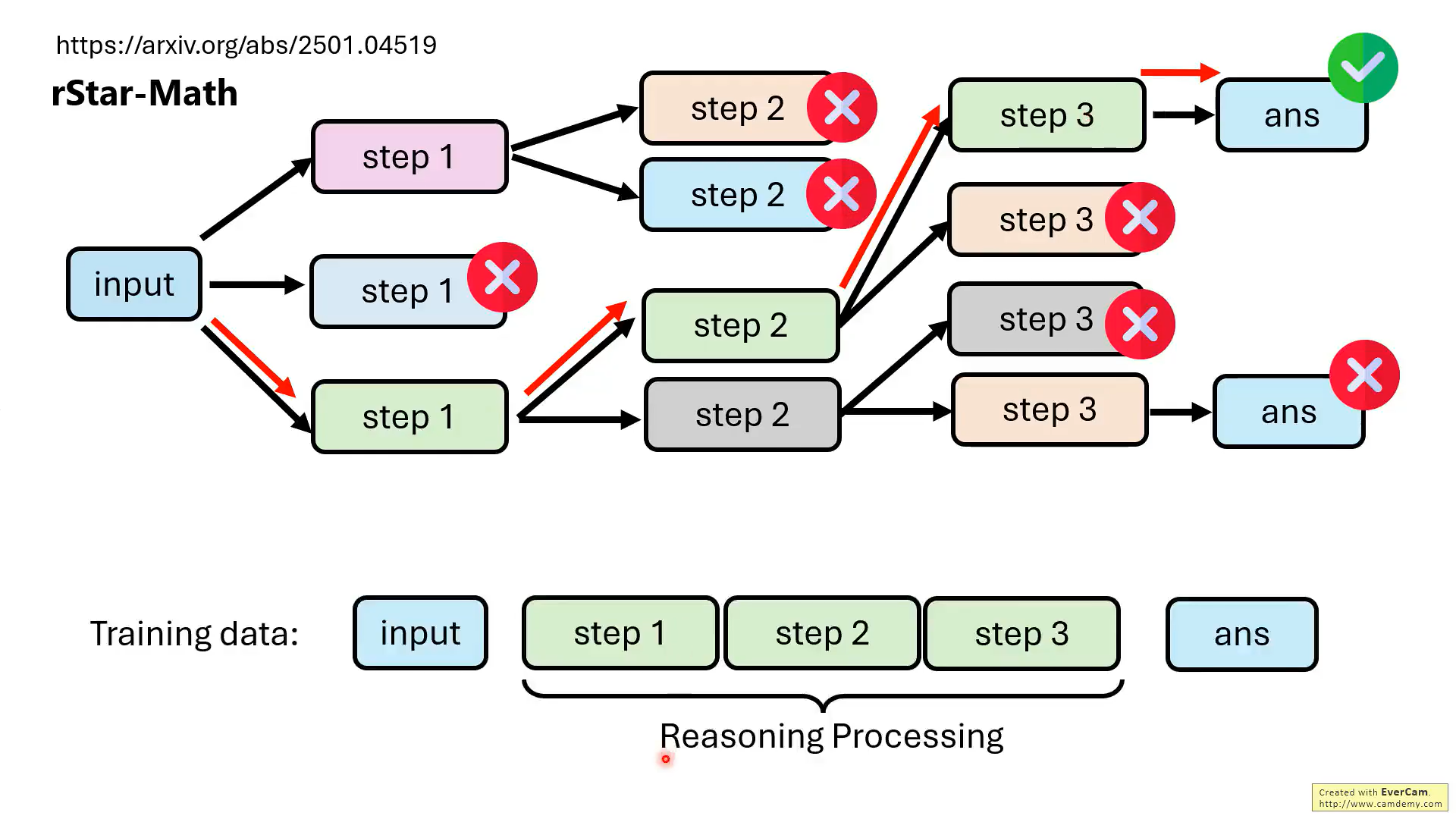
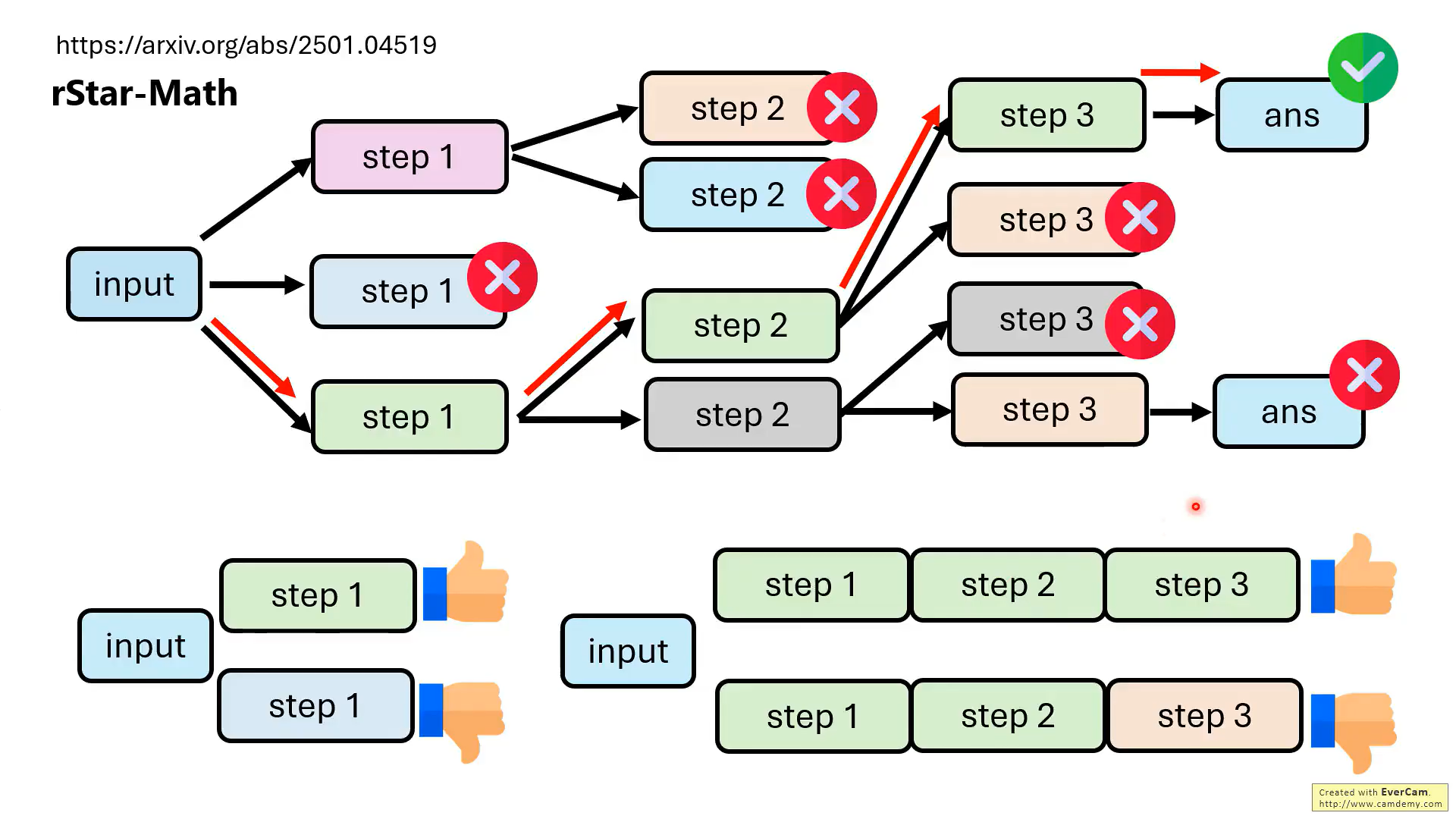

但是,實際上,并不需要模型每一步推理都是對的,最后結果對就可以。
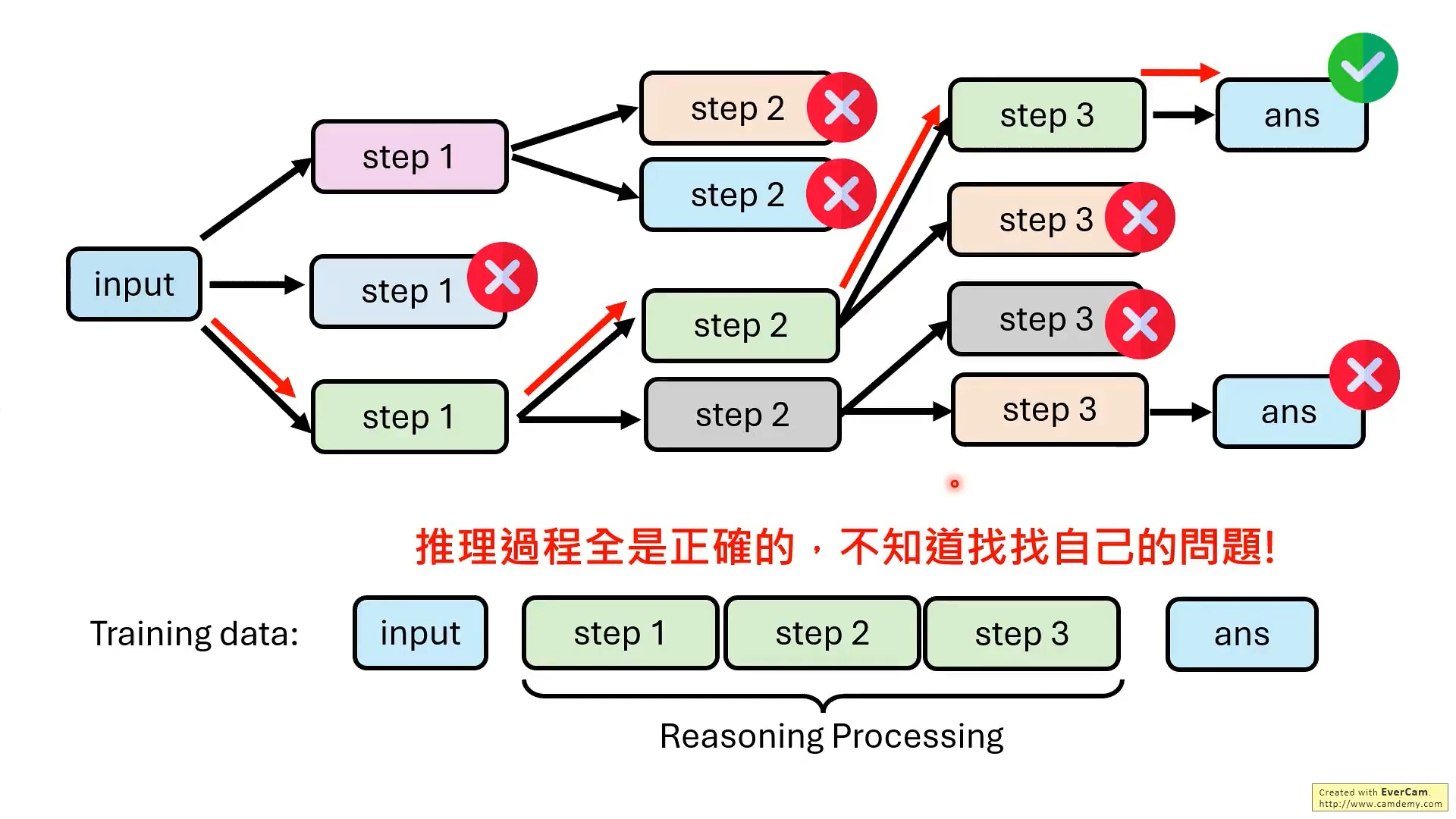
關鍵是要教會模型知錯能改!!那如何教?
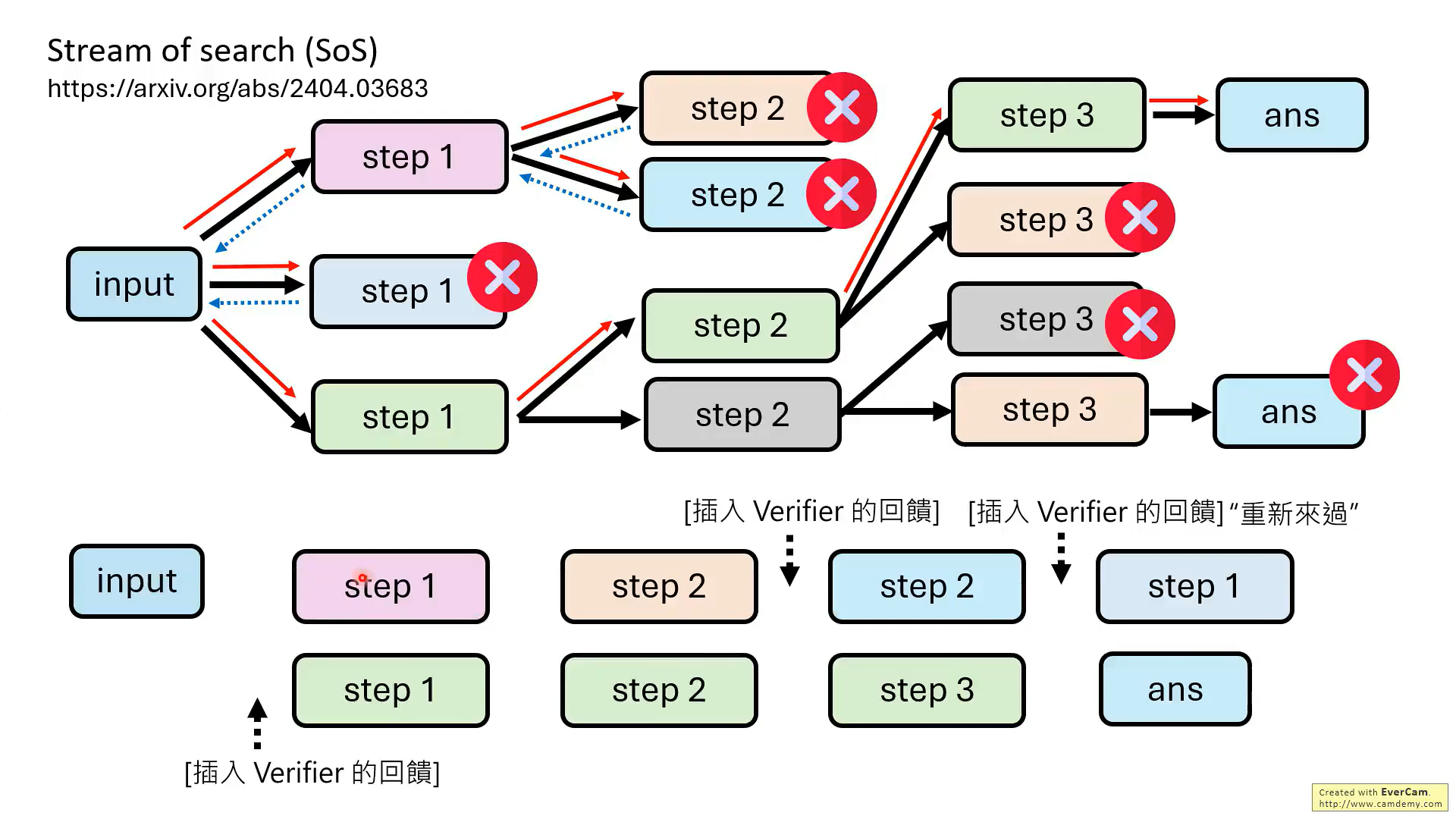
SoS這篇論文的意思,就是把錯誤的推理過程也加入訓練數據,形成帶有錯誤推理步驟的訓練數據。
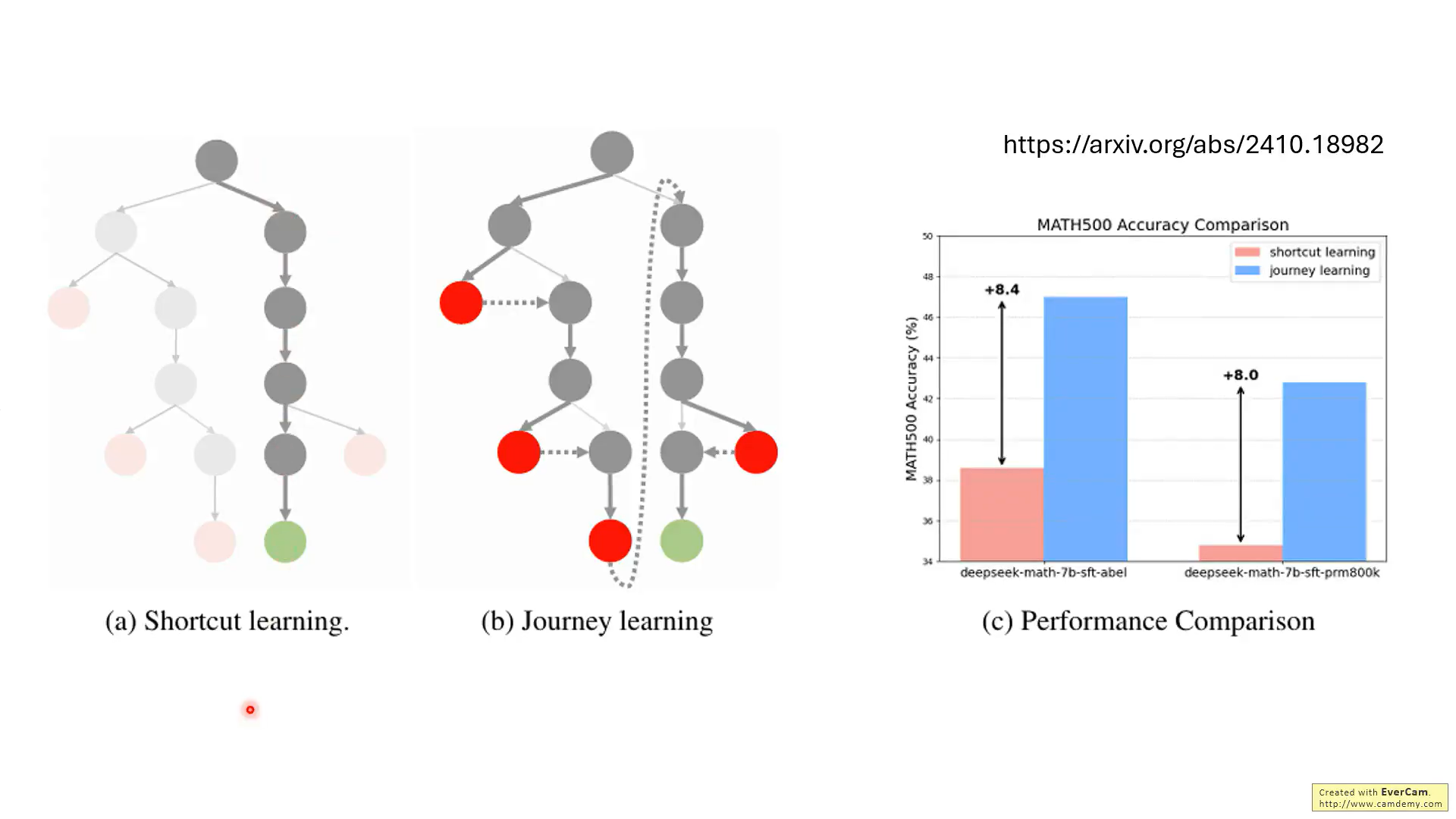
這篇論文也類似,在推理過程中包含錯誤的步驟。
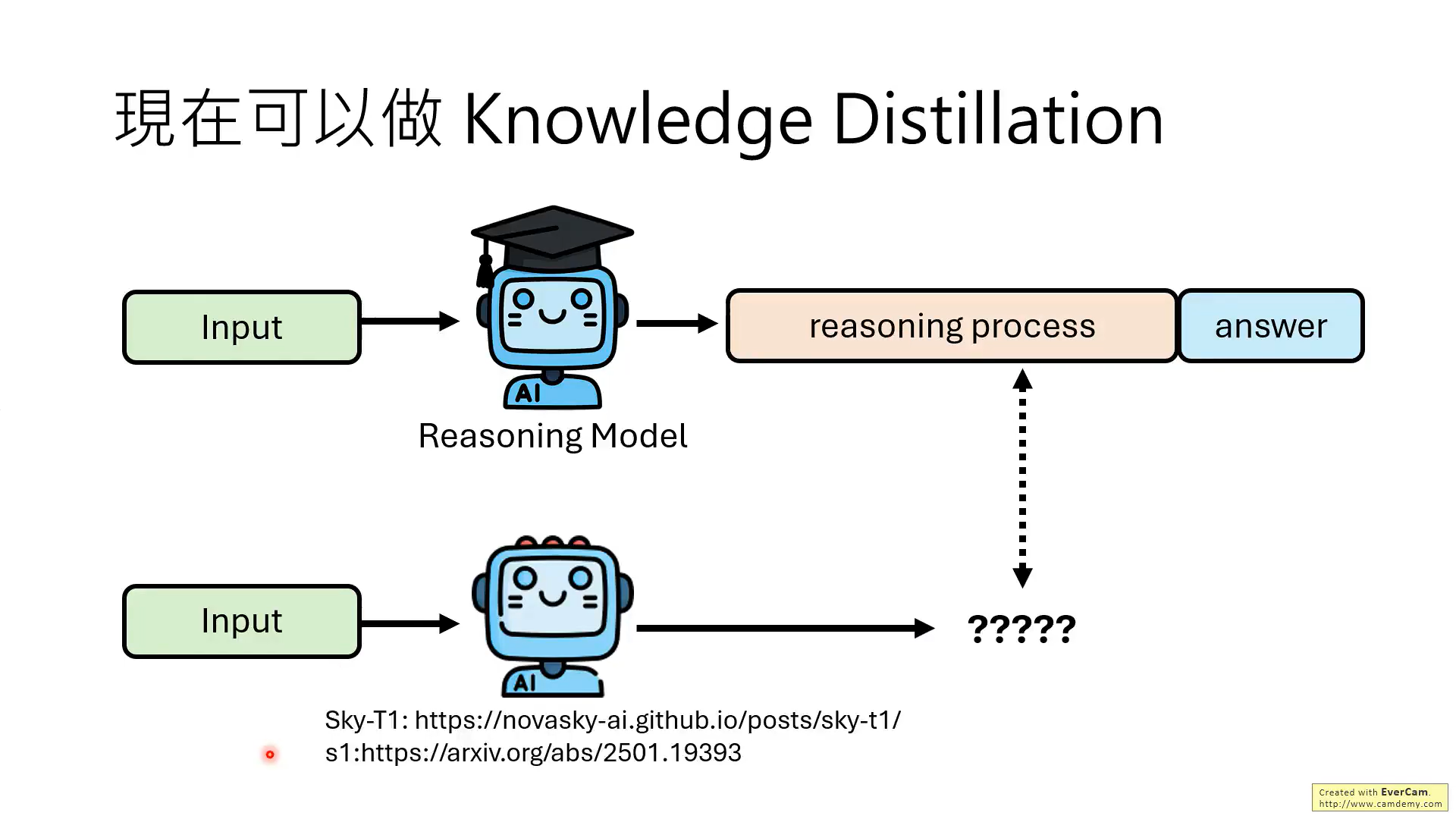
這就是知識蒸餾,如Sky-T1、s1等
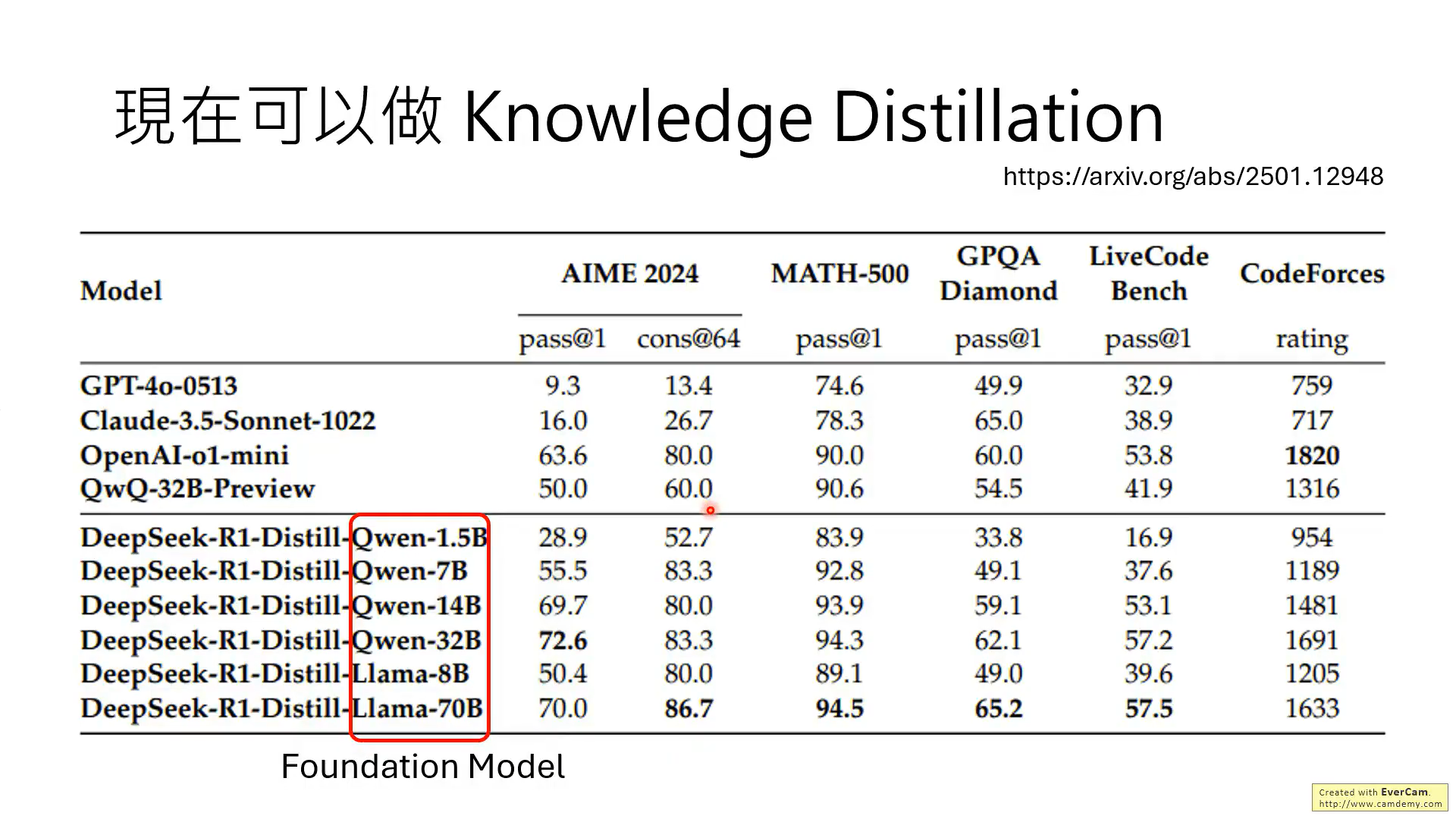
可以看到通過Deepseek-R1蒸餾基礎模型后的性能提升。
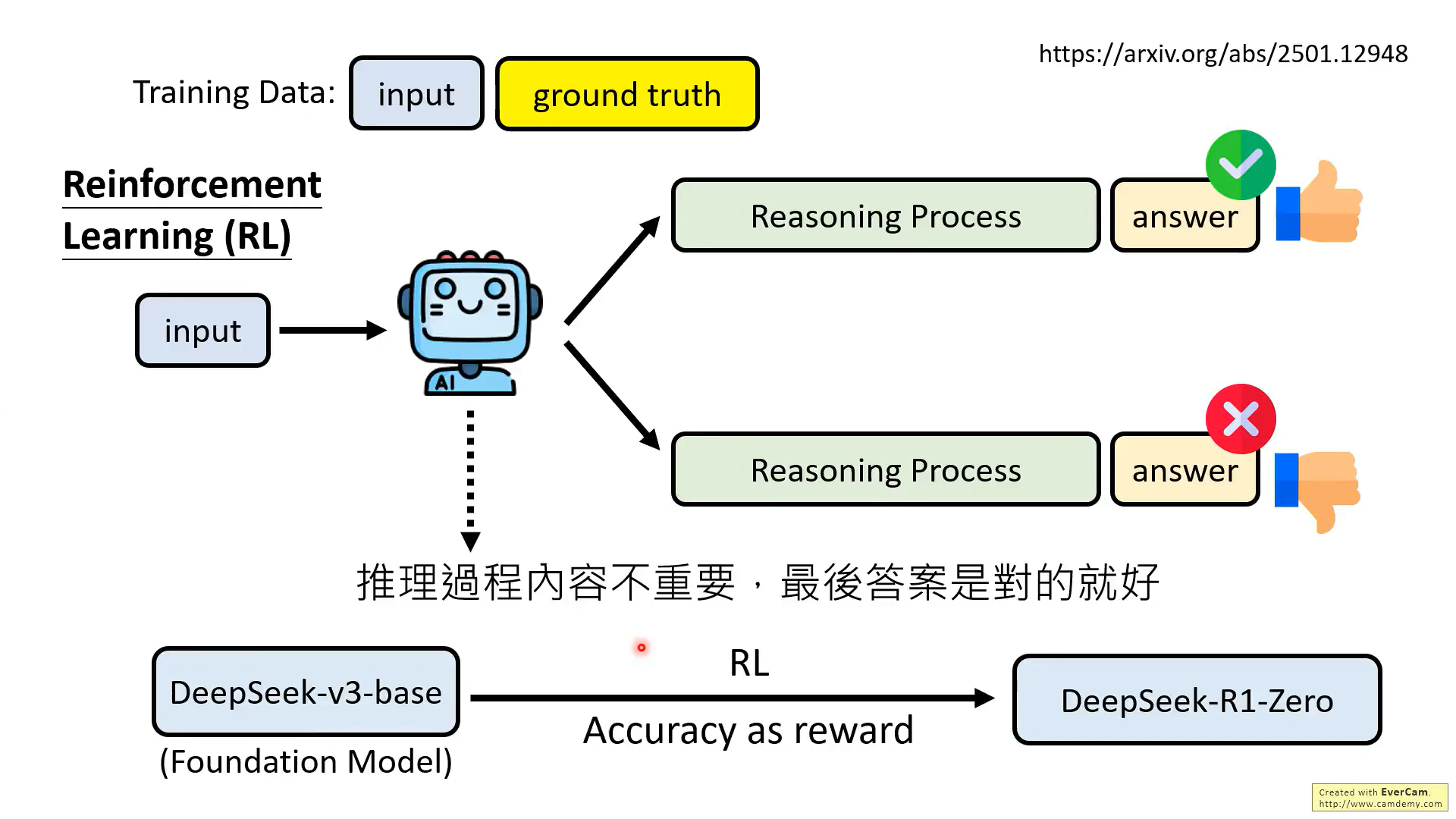
最后一種方法,只看結果的RL方法,就是DeepSeek的方法
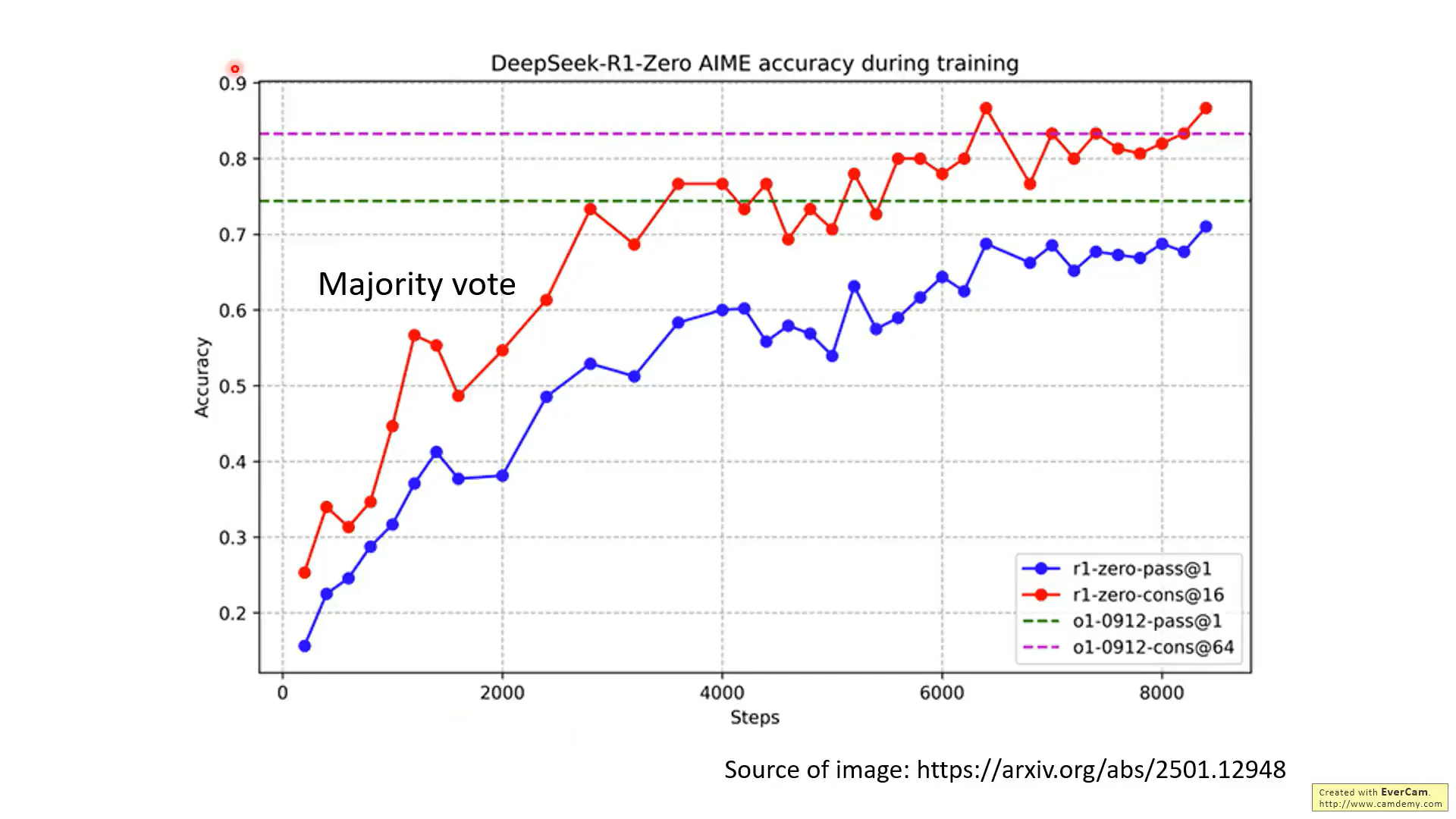
這張圖展現了R1推理16次后再通過投票的性能增益,這也說明,深度思考的幾種方法,是可以結合的,這里就是把RL和前面的Best of N進行了結合。

Aha時刻
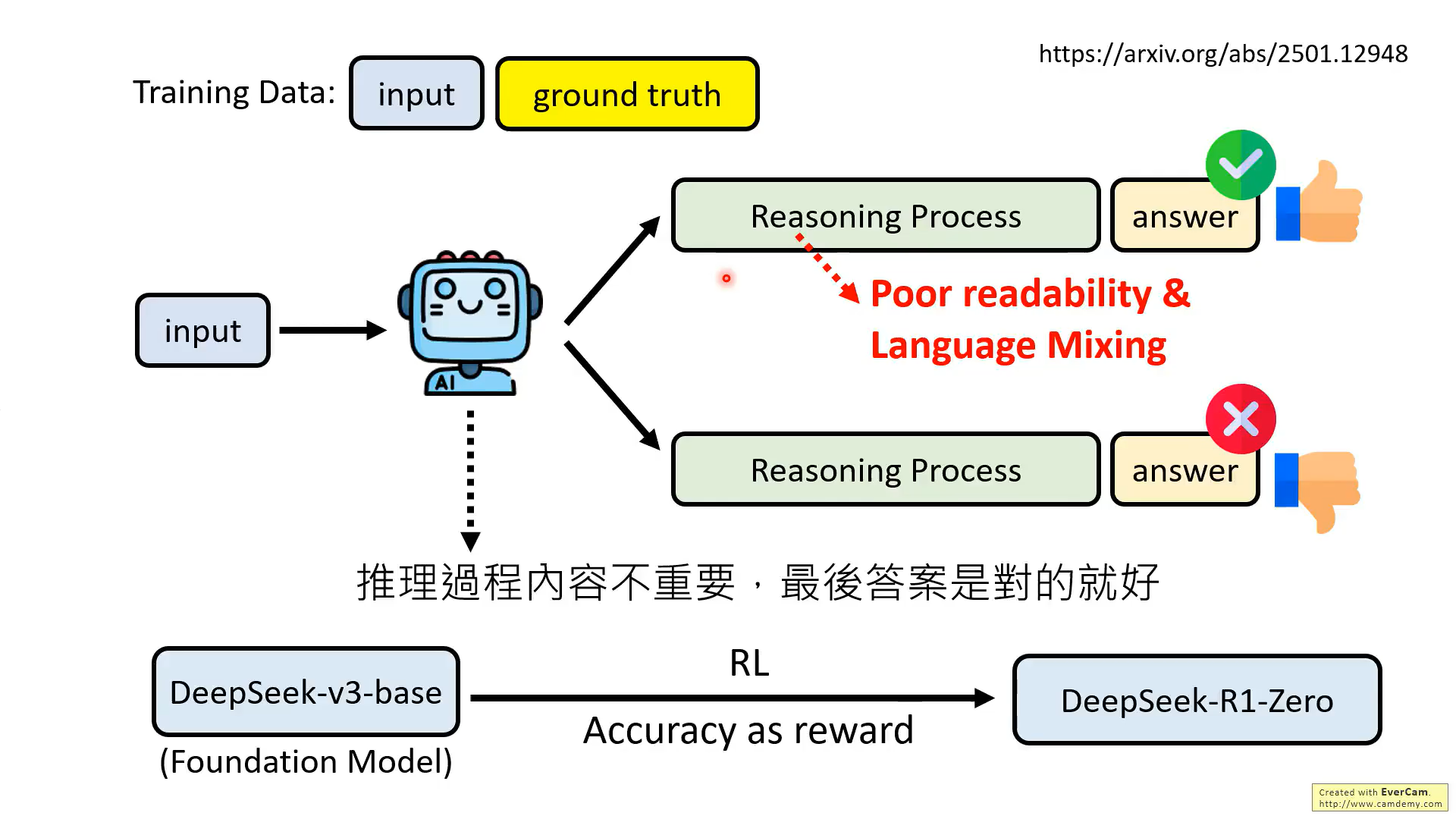
但是R1-zero并沒有拿出來用,只看重結果,導致輸出的推理過程可讀性差
在R1訓練中的幾個重點:
1、前面的幾種方法都有用到,而不是單純的RL
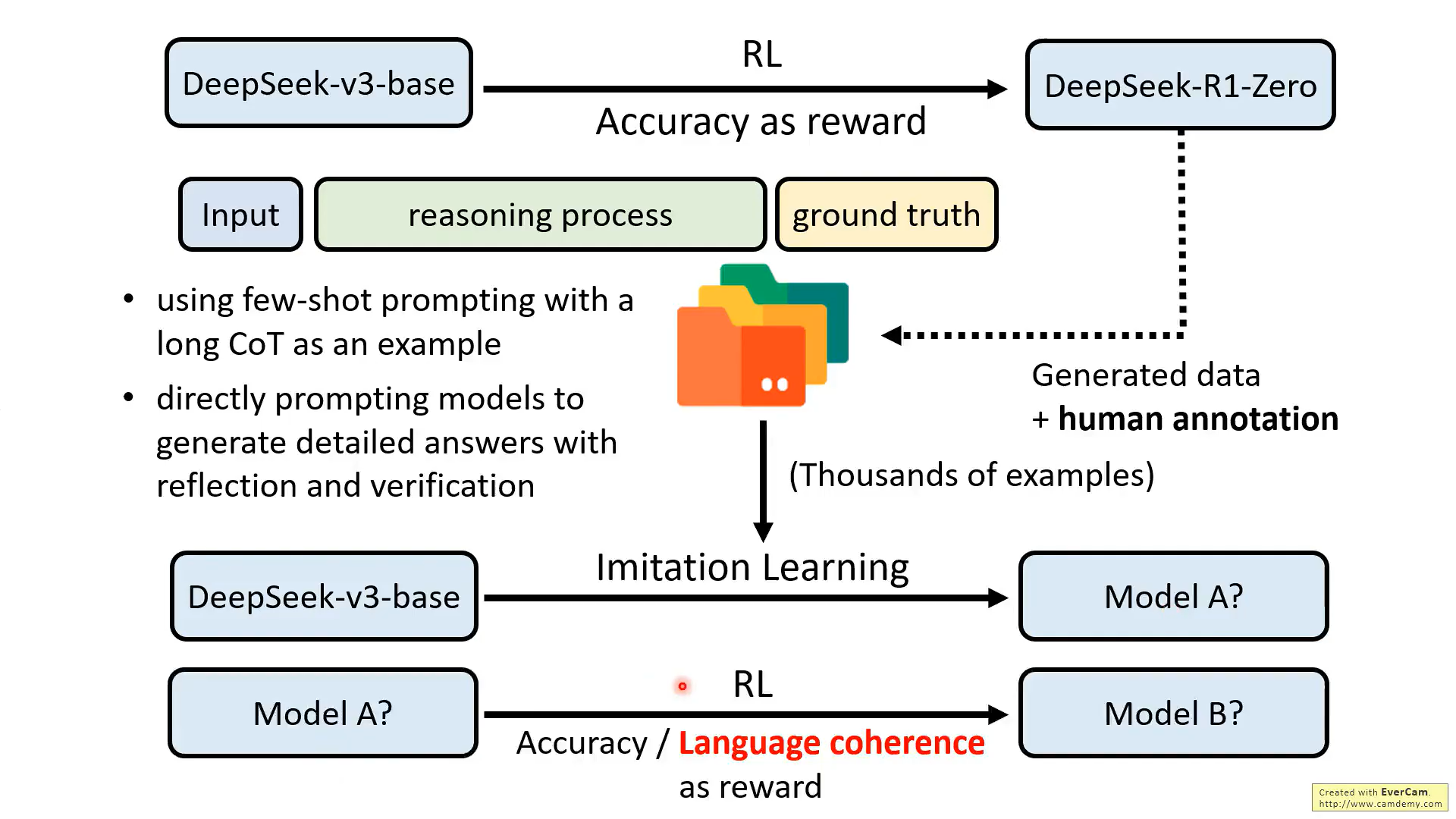
2、R1-Zero生成推理數據,用于訓練下一個模型,但是R1-zero輸出的數據可讀性差,所以需要大量的人力矯正,而這個過程R1技術報告說得并不清楚
3、另外還需要通過few shot方式的提示和讓模型生成帶有反思和驗證的提示,來由另一個模型產生數據,這個過程的具體情況也不清楚
4、最后模型訓練,在準確性的基礎上增加了語言一致性的目標,這樣會導致性能略微下降,但是增強可讀性,所以還是用了這種方式。
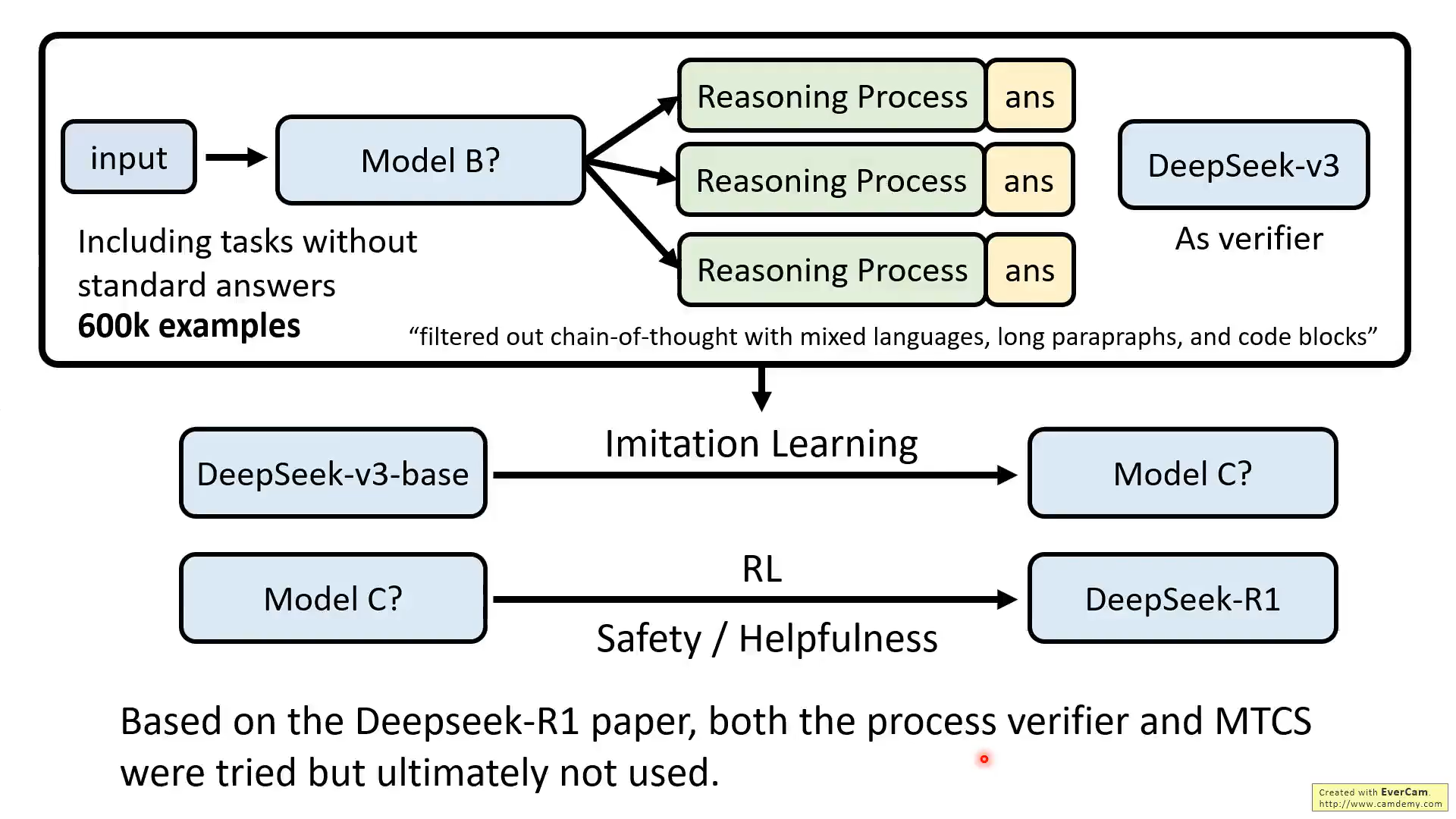
然后這個Model B還是用來生成數據,同時這個數據需要V3作為驗證器,評估正確性,以及過濾數據
最后Model C再經過RL獲得最終的R1,但是這個RL的過程在技術報告描述的不詳細。

R1推理過程中有一些奇怪的輸出,例如缺了括號、語言混亂,說明推理過程并沒有人的監督
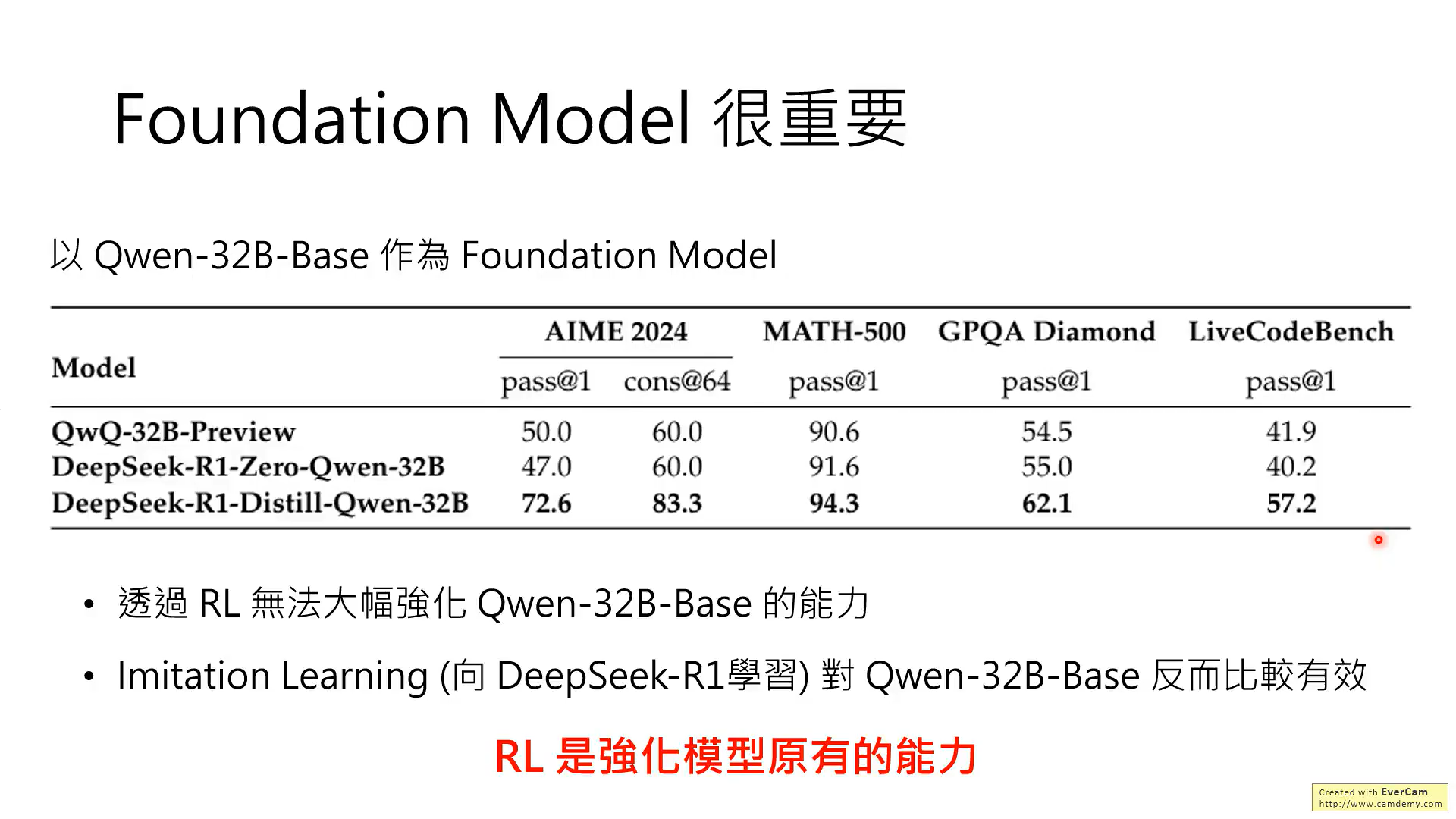
這張圖是說,小的模型上使用RL的方法行不通
背后的原因可能性:RL只是強化基礎模型的能力,就是說,基礎模型作對了,獎勵,做錯了,懲罰,來強化作對的能力,但是前提是基礎模型需要有作對的能力!!
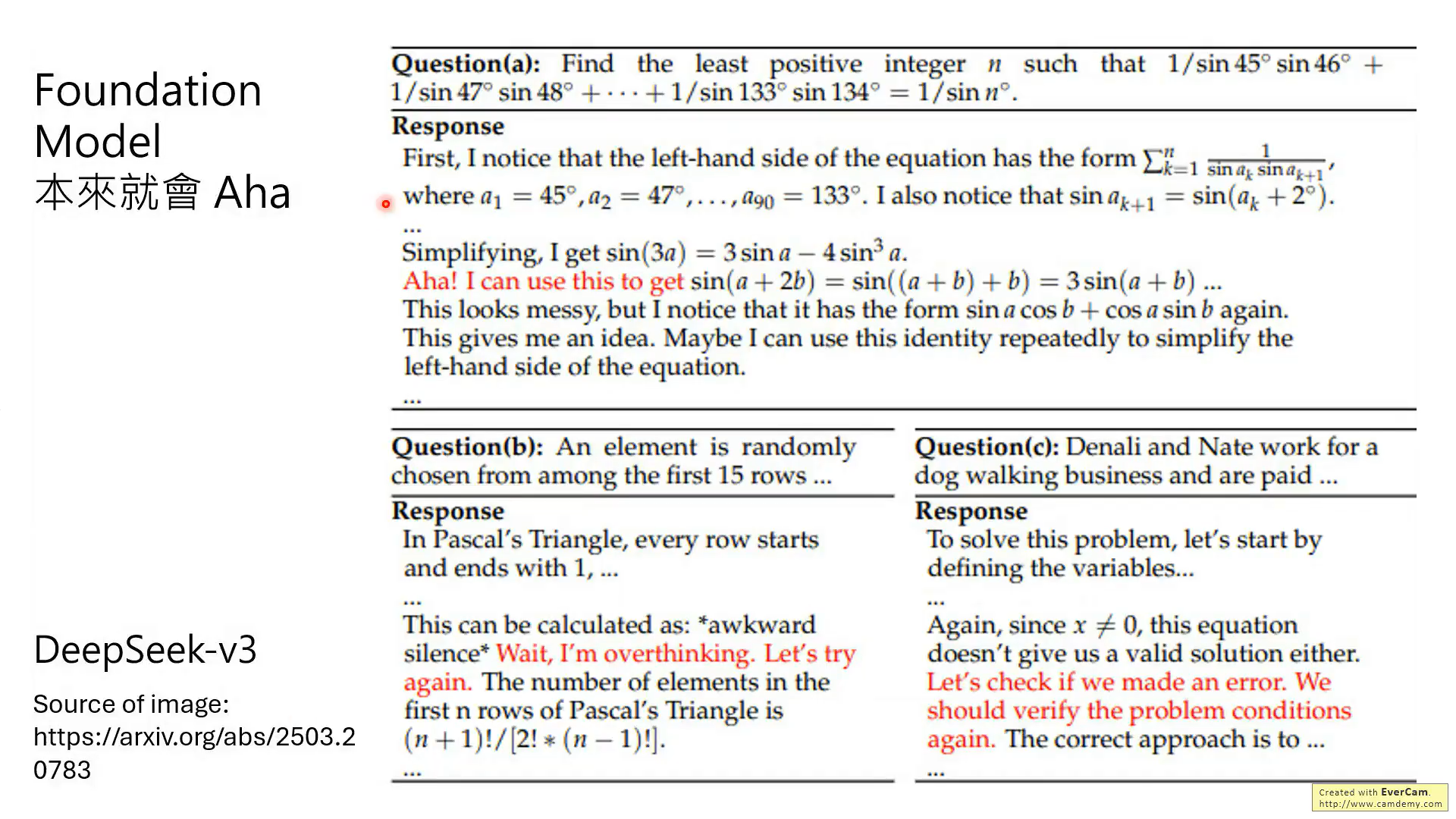
所以,相關論文就發現,V3本身就是有Aha能力,R1只是強化這種能力
接下來探討推理模型的問題。
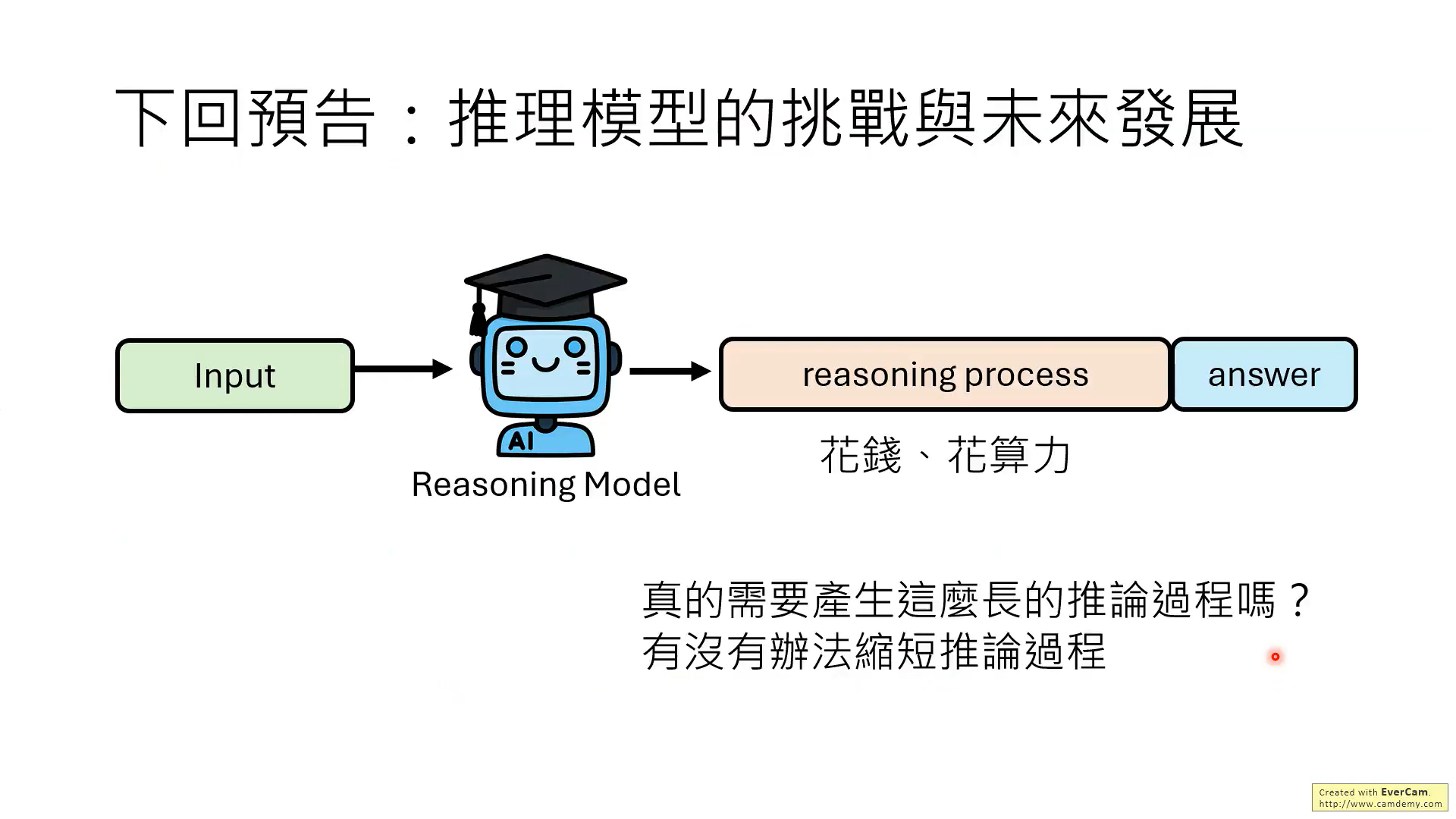



)
VTK C++開發示例 ---將圖片映射到平面2)

【詳細版】)



)




)

)

