文章目錄
- 任務介紹
- 數據概覽
- 數據處理
- 數據讀取與拼接
- 字符數據轉化
- 標簽數據映射
- 數據集劃分
- 數據標準化
- 模型構建與訓練
- 模型構建
- 數據批處理
- 模型訓練
- 文件提交
- 結果
- 附錄
任務介紹
本次任務為毒蘑菇的二元分類,任務本身并不復雜,適合初學者,主要亮點在于對字符數據的處理,還有嘗試了加深神經網絡深度的效果,之后讀者也可自行改變觀察效果,比賽路徑將于附錄中給出。
數據概覽
本次任務的數據集比較簡單
- train.csv 訓練文件
- test.csv 測試文件
- sample_submission.csv 提交示例文件
具體內容就是關于毒蘑菇的各種特征,可在附錄中獲取數據集。
數據處理
數據讀取與拼接
這段代碼提取了數據文件,并且對兩個不同來源的數據集進行了拼接,當我們的數據集較小時,就可采用這種方法,獲取其他的數據集并將兩個數據集合并起來。
import pandas as pd
from sklearn.preprocessing import LabelEncoder, StandardScaler
file = pd.read_csv("/kaggle/input/playground-series-s4e8/train.csv", index_col="id")
file2 = pd.read_csv("/kaggle/input/mushroom-classification-edible-or-poisonous/mushroom.csv")
file_all = pd.concat([file, file2])
字符數據轉化
這段代碼主要就是提取出字符數據,因為字符是無法直接被計算機處理,所以我們提取出來后,再將字符數據映射為數字數據。
char_features = ['cap-shape', 'cap-surface', 'cap-color', 'does-bruise-or-bleed', 'gill-attachment', 'gill-spacing', 'gill-color', 'stem-root', 'stem-surface', 'stem-color', 'veil-type', 'veil-color', 'has-ring', 'ring-type', 'spore-print-color', 'habitat', 'season']
for i in char_features:file_all[i] = LabelEncoder().fit_transform(file_all[i])
file_all = file_all.fillna(0)
train_col = ['cap-diameter', 'stem-height', 'stem-width', 'cap-shape', 'cap-surface', 'cap-color', 'does-bruise-or-bleed', 'gill-attachment', 'gill-spacing', 'gill-color', 'stem-root', 'stem-surface', 'stem-color', 'veil-type', 'veil-color', 'has-ring', 'ring-type', 'spore-print-color', 'habitat', 'season']
X = file_all[train_col]
y = file_all['class']
標簽數據映射
除了用上述方法進行字符轉化外,還可以使用map函數,以下是具體操作。
y.unique()
# 構建映射字典
applying = {'e': 0, 'p': 1}
y = y.map(applying)
數據集劃分
這段代碼使用sklearn庫將數據集劃分為訓練集和測試集。
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(X, y, test_size=0.1)
x_train.shape, y_train.shape
數據標準化
這段代碼將我們的數據進行歸一化,減小數字大小方便計算,但是仍然保持他們之間的線性關系,不會對結果產生影響。
scaler = StandardScaler()
x_train = scaler.fit_transform(x_train)
x_test = scaler.fit_transform(x_test)
模型構建與訓練
這段代碼使用torch庫構建了深度學習模型,主要運用了線性層,還進行了正則化操作,防止模型過擬合。
模型構建
import torch
import torch.nn as nn
class Model(nn.Module):def __init__(self):super().__init__()self.linear = nn.Linear(20, 256)self.relu = nn.ReLU()self.dropout = nn.Dropout(p=0.2)self.linear1 = nn.Linear(256, 128)self.linear2 = nn.Linear(128, 64)self.linear3 = nn.Linear(64, 48)self.linear4 = nn.Linear(48, 32)self.linear5 = nn.Linear(32, 2)def forward(self, x):out = self.linear(x)out = self.relu(out)out = self.linear1(out)out = self.relu(out)out = self.dropout(out)out = self.linear2(out)out = self.relu(out)out = self.linear3(out)out = self.dropout(out)out = self.relu(out)out = self.linear4(out)out = self.relu(out)out = self.linear5(out)return out
對模型類進行實例化。
model = Model()
數據批處理
由于數據一條一條的處理起來很慢,因此我們可以將數據打包,一次給模型輸入多條數據,能有效節省時間。
import torch.nn.functional as F
class Dataset(torch.utils.data.Dataset):def __init__(self, x, y):self.x = xself.y = ydef __len__(self):return len(self.x)def __getitem__(self, i):x = torch.Tensor(self.x[i])y = torch.tensor(self.y.iloc[i])return x, y
train_data = Dataset(x_train, y_train)
test_data = Dataset(x_test, y_test)
loader = torch.utils.data.DataLoader(train_data, batch_size=64, drop_last=True, shuffle=True)
test_loader = torch.utils.data.DataLoader(test_data, batch_size=256, drop_last=True, shuffle=True)
模型訓練
這段代碼就是模型的訓練過程,包括創建優化器,定義損失函數等,還在訓練過程中測試準確率與損失函數值,動態的觀察訓練過程。
from tqdm import tqdm
import matplotlib.pyplot as plt
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.1, weight_decay=1e-5)
from sklearn.metrics import matthews_corrcoef
flag = 0
for i in range(10):for x, label in tqdm(loader):out = model(x)loss = criterion(out, label)loss.backward()optimizer.step()optimizer.zero_grad()flag+=1if flag%500 == 0:test = next(iter(test_loader))t_out = model(test[0]).argmax(dim=1)print("loss=", loss.item())acc = (t_out == test[1]).sum().item()/len(test[1])mcc = matthews_corrcoef(t_out, test[1])print("acc=", acc)print("mcc=", mcc)文件提交
這段代碼主要就是使用訓練好的模型在測試集上預測,并且將其整合成提交文件。
test_file = pd.read_csv("/kaggle/input/playground-series-s4e8/test.csv")
for i in char_features:test_file[i] = LabelEncoder().fit_transform(test_file[i])
test_file.fillna(0)
test_x = torch.Tensor(test_file[train_col].values)
test_x = torch.Tensor(scaler.fit_transform(test_x))
out = model(test_x)
out = pd.Series(out.argmax(dim=1))
map2 = {0: 'e', 1: 'p'}
result = out.map(map2)
answer = pd.DataFrame({'id': test_file['id'], "class": result})
answer.to_csv('submission.csv', index=False)
結果
將文件提交后,得到了0.97的成績,已經非常接近1了,證明模型的效果非常不錯。
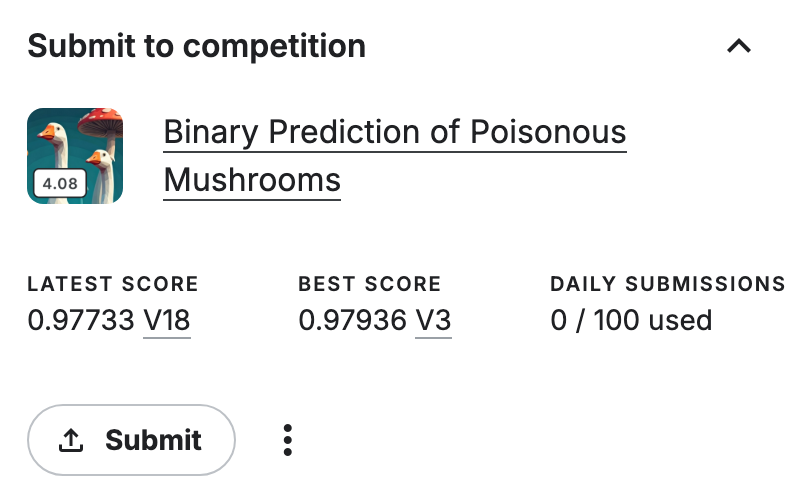
附錄
比賽鏈接:https://www.kaggle.com/competitions/playground-series-s4e8
額外數據集地址:https://www.kaggle.com/datasets/vishalpnaik/mushroom-classification-edible-or-poisonous





的?》的部分紀要)



)
VTK C++開發示例 ---將圖片映射到平面2)

【詳細版】)



)


