這篇論文主要圍繞利用深度學習模型檢測地下水位異常以識別地震前兆展開。
[1] Chen X, Yang L, Liao X, et al. Groundwater level prediction and earthquake precursor anomaly analysis based on TCN-LSTM-attention network[J]. IEEE Access, 2024, 12: 176696-176718.
期刊
IEEE Access
👨?🔬 作者信息(Author Information)
-
Xinfang Chen(IEEE 會員)
- 單位:
- 中國地震局防災科技學院 信息工程學院
- 河北省高校智慧應急應用技術研發中心
- 所在地:河北省三河市 065201
- 單位:
-
Lijia Yang(通訊作者 ??)
- 單位:同上
- 郵箱:23661627@st.cidp.edu.cn
核心內容可以概括為以下幾個方面:
🌍 研究背景
- 地震前,地下巖層在應力積累作用下會發生微裂或變形,影響地下水系統(如水壓、水位、水流和化學成分)。
- 因此,地下水位的異常波動可以作為地震前兆的潛在指示信號。
🧠 研究方法
- 使用多種深度學習模型(如 LSTM、TCN、TCN-LSTM-Attention 等)來預測地下水位。
- 通過將模型預測值與真實測量值進行對比,發現顯著偏差的時段即被認為是異常時期(SA period)。
- 并結合統計方法(如 EWMA 控制圖)對殘差進一步分析,精準識別異常開始時間。
🔬 關鍵實驗
- 分析了唐山地震(2020) 和建水地震(2015) 兩個典型案例的地下水井(趙各莊井、玉田集 03 井、建水井)的水位數據。
- 對比不同模型的表現后發現:
- TCN-LSTM-Attention 模型最敏感,最早識別出異常。
- 相比于無監督的 Isolation Forest 方法,它能更早檢測出地震前的地下水異常。
- 進行了模型的可遷移性測試(將模型應用到不同地理區域)和5 折交叉驗證(驗證模型的泛化能力)。
? 主要結論
- 地震前地下水位確實存在異常波動,且提前數天即可被檢測到。
- TCN-LSTM-Attention 模型表現最優,對異常波動最敏感,且能提前預警。
- 模型具有良好的可遷移性和泛化能力,可適用于不同區域和不同地震事件。
- 將深度學習模型與統計分析方法結合,可以顯著提升地震前兆識別的準確率與可靠性。
- 目前僅聚焦于地下水位,未來計劃引入更多指標(如水溫、氡濃度、電磁信號等)提升實用性。
📌 總體而言:
這是一個地震預測預警研究的交叉學科案例,結合地球物理學、地震學、水文學與人工智能,展示了用深度學習模型檢測地震前兆的前沿探索與實際價值。
摘要
地下水位的異常變化是地震前兆的重要指示之一。在地震發生前,地下水位通常會出現不同程度的異常,這些異常通常表現為地下水位的突然上升或下降,并持續一段時間。2020年7月12日6時38分,中國河北省唐山市古冶區(緯度39.78°N,經度118.44°E)發生了一次5.1級地震。本文以該地震為研究案例,分析了趙各莊井和玉田基03井兩個觀測井的地下水位數據。為準確識別地震前兆異常,將地下水位數據劃分為地震活躍期(SA)與地震非活躍期(non-SA),作為數據集劃分的依據。本文提出了一種TCN-LSTM-Attention模型,該模型結合了TCN在特征提取方面的優勢與LSTM在捕捉復雜時間依賴性方面的能力。實驗結果表明,所設計的模型在地下水位預測和地震前兆異常識別方面表現出較強的能力。為了進一步提高異常檢測的準確性,本文引入了指數加權移動平均(EWMA)控制圖,精確定位異常的起始時間點。通過對中國云南省建水縣地震的驗證,模型在不同地質條件下依然能有效識別地下水位異常,驗證了其泛化能力和實用性。最后,本文對所設計模型進行了交叉驗證,進一步提升了其在實際應用中的可靠性。本研究在地震前兆分析方面具有一定的科學創新性和實踐價值,為地震預警技術的發展及防災減災工作提供了新的技術支持和分析手段。
關鍵詞
地震異常前兆,EWMA控制圖,地下水位預測,地震活躍期,TCN-LSTM-Attention
Ⅰ、引言
地震是一種常見的自然災害,對人類社會產生了深遠影響。地震前兆異常是地震發生前出現的異常現象,對于地震預測至關重要。地下水位是地震前兆異常中的關鍵因素之一 [1],其對地震前兆的影響一直是地震學研究的重點。井水位觀測是監測地下流體地震前兆的重要手段之一 [2]。井水位的異常變化能夠客觀而敏感地反映地殼介質的應力-應變變化。由于地下水具有分布廣泛、流動性強和不可壓縮的特性,當其形成封閉承壓系統時,井水位的變化可以客觀、靈敏地指示地殼的應變狀態。對于承壓含水層,如圖1所示,觀測井在含水層系統中可以作為高靈敏度的體積應變計 [3]。含水層巖體中由于應力應變變化而引發的地下水微小波動,為了解地下應力狀態、當前構造運動以及地震活動和前兆提供了關鍵信息。
在地震孕育與發生過程中,局部應力的加載與卸載或大規模斷層活動會導致巖體變形。這種變形會改變含水層的孔隙壓力,進而改變地殼介質的滲透場,導致井水位發生動態波動,且水位變化的最大幅度與地震震級呈相關性 [4]。Sato 等人的觀測表明,確實存在地震前的井水位異常變化 [5]。例如,在魯甸地震發生前六個月,震中附近的地下水位就出現了顯著變化:2014年6月和7月,位于昭通和會澤測站的井水位顯著上升 [6]。這些變化為地震預測提供了關鍵的預警信息,表明地下水異常可以作為重要的地震前兆指標。研究地震孕育與發生過程中井水位的各種異常變化,對于理解地震的發生與發展過程具有重要的物理意義,也在地震前兆監測與預測實踐中發揮著重要作用 [7]。
在過去的幾十年中,地下水位預測常使用數值模擬和物理建模方法,其中MODFLOW是應用最廣泛的模型之一 [8]。這些模型的開發通常需要詳細的含水層特征信息,并考慮氣象、地形、水文地質和人類活動等多種因素的綜合影響 [9]。若對地下水系統的物理過程理解不充分,或參數選擇不當,模型結果可能會受到影響。此外,這些模型對計算資源要求較高,且數據不準確也會影響預測精度 [10]。因此,這類建模過程充滿不確定性和挑戰。
相比之下,數據驅動方法在應對復雜、不確定或難以建模的地下水系統方面通常更為適用。數學建模方法如ARMA、ARIMA 和 GM(1,1) 等,常用于利用歷史地下水位數據預測未來變化,在實時地下水位預測中提供了有效框架 [11]。但這些方法在處理非線性數據時難以實現高精度預測。近年來,隨著大數據和機器學習技術的發展,基于數據驅動的地下水位預測方法逐漸興起。通過采集和分析大量實時數據,機器學習方法可以基于歷史數據構建非線性模型,用以預測地下水位變化,使預測模型更智能、更精確。在許多場景下,機器學習方法的預測性能優于基于物理的模型 [12]–[14]。這種方法的優勢在于無需顯式定義環境所需的物理關系和參數,而是通過迭代學習過程近似輸入與輸出之間的關系 [15]。典型的方法包括支持向量回歸(SVR)和人工神經網絡(ANN) [16]–[19]。但這類方法往往難以有效處理變量間的依賴關系,限制了其預測精度。
深度學習是當前熱門的數據驅動算法,研究表明其性能優于傳統過程模型 [20]。卷積神經網絡(CNN)[21] 和長短期記憶網絡(LSTM)[22] 是水文研究中應用最廣泛的深度學習算法,能夠有效捕捉空間和時間依賴性。Wunsch 等人使用1D-CNN對德國118個監測井的地下水位趨勢進行了預測 [23],為響應措施的制定提供了重要參考。另一項研究發現,當將過去的地下水位作為輸入時,LSTM 和 CNN 模型的表現更佳 [24]。Hopfield 曾提出一種用于序列數據的循環神經網絡(RNN)[25],為后來的深度學習模型奠定了基礎,這些模型被廣泛認為是時間序列預測最有效的方法之一。盡管RNN已被成功應用于地下水建模 [26],但它在反向傳播中存在梯度消失和爆炸問題,難以記住長序列信息 [27]。為解決這些問題,Hochreiter 和 Schmidhuber 提出了LSTM網絡,增強了記憶能力 [28],目前被認為是時間序列預測中最先進的方法之一。LSTM網絡通過過濾掉無關信息,僅保留關鍵歷史事件的記憶,有效避免訓練過程中的問題。Zhang 等人利用LSTM網絡預測中國干旱的河套地區地下水位 [29],即便在數據稀缺的區域也表現良好。Bowes 等人研究了地下水位在周期性沿海洪水中的作用 [30],并探討了LSTM和RNN模型在風暴響應預測中的潛力。
在注意力機制提出后,其被廣泛應用于各類任務中。Noor 評估了深度學習與基于注意力機制的模型在洪水時空預測中的潛力 [31]。研究結果顯示,將注意力機制引入LSTM模型能顯著提升其性能。Babak Alizadeh 等人提出了一種結合注意力機制和貝葉斯優化的改進型LSTM模型,用于提升流量預測的精度 [32]。該LSTM-Attention模型通過聚焦關鍵時間點提升了處理復雜時間序列數據的能力,在流量預測任務中表現出色。
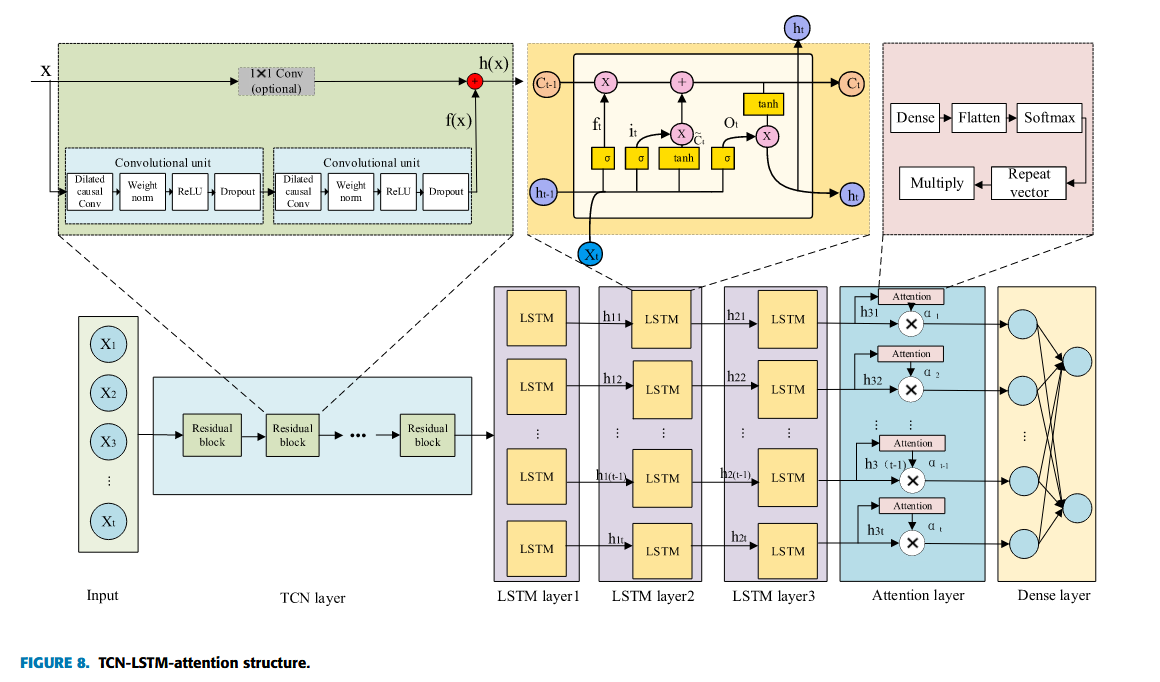
TCN 是一種用于時間序列預測的新型算法,由Lea等人于2016年首次提出 [33]。TCN通過一維卷積層從輸入序列中提取特征,已被證明在多種任務中效果良好 [34]。每種模型都有其優缺點,將不同模型結合以取長補短,形成集成模型,是近年來研究的一個熱點方向。多種模型組合在不同領域已被廣泛探討 [35]–[38]。LSTM適合處理時間依賴性強的序列數據,但存在梯度消失/爆炸問題,不擅長提取空間特征,且計算復雜度高;而TCN則在提取空間特征和并行計算方面更有優勢,訓練和推理效率高,但在捕捉長序列的時間依賴性方面略遜一籌 [39]。注意力機制的引入,使模型能夠聚焦于輸入序列中最相關的信息,彌補了LSTM和TCN在特征選擇方面的不足。本文提出的TCN-LSTM-Attention模型融合了三者的優點 [40],具備更強的表達能力與更高的預測精度,在復雜地下水位預測中展現出優異的性能。
為了更好地識別地震前兆異常,本文將時間序列劃分為地震活躍期(SA)與非活躍期(non-SA)[41]。模型首先學習非活躍期的正常數據,再對其他時期的地下水位進行預測,并比較模型預測值與實際觀測值之間的差異。若差異顯著,可能表明地震活動影響了監測數據,導致地下水位異常 [42]。為了檢測異常及其起始時間,本文引入了指數加權移動平均(EWMA)控制圖。此外,許多學者也采用無監督學習方法進行異常檢測。例如,Liu等人提出了基于分類思想的孤立森林算法 [43],被廣泛應用于數據異常檢測中。其他無監督方法,如一類支持向量機(One-Class SVM)和局部離群因子(LOF)也被用于異常檢測 [44]。Jamshidi 等人成功將無監督異常檢測技術應用于地下水及監測井異常檢測領域 [45]。因此,除了監督學習模型,本文還利用無監督學習的孤立森林算法來檢測地震引起的地下水位異常。
本文結構安排如下:第一部分簡要介紹研究背景與研究目標;第二部分闡述機器學習基本原理,并細化不同類型的機器學習模型;第三部分介紹數據處理與實驗方法;第四部分展示并分析具體預測結果;第五部分總結研究的主要發現與結論。
II. 機器學習原理
A. LSTM
LSTM 是 RNN 的一種變體,專門用于解決長期依賴問題。相比 RNN,LSTM 引入了門控機制,有助于緩解梯度消失或爆炸的問題,從而更有效地捕捉長期記憶與依賴關系。LSTM 的結構由一系列重復的神經網絡模塊組成,如圖 2 所示。
LSTM 包含三個門控單元:遺忘門(Forget Gate)、輸入門(Input Gate)和輸出門(Output Gate)。這些門接收來自當前時刻的輸入信息以及上一個時刻的隱藏狀態。
-
遺忘門 控制前一時刻的記憶單元狀態 C t ? 1 C_{t-1} Ct?1? 中需要被遺忘的信息量,其計算方式如公式(1)所示。輸出值在 0 0 0 到 1 1 1 之間, f t f_t ft? 趨近于 1 1 1 表示保留的信息更多,趨近于 0 0 0 表示遺忘的信息更多。
-
輸入門 決定當前時刻的輸入信息 x t x_t xt? 中有多少應被加入到記憶單元狀態中,計算方式如公式(2)所示。 i t i_t it? 趨近于 1 1 1 表示加入的信息較多,趨近于 0 0 0 表示較少。
-
輸出門 控制當前記憶單元狀態 C t C_t Ct? 中有多少信息作為隱藏狀態 h t h_t ht? 輸出,見公式(3)。 o t o_t ot? 趨近于 1 1 1 表示輸出較多,趨近于 0 0 0 表示輸出較少。
-
記憶單元狀態( C t C_t Ct?):結合遺忘門和輸入門的輸出更新。將上一個時刻的記憶狀態乘以遺忘門的輸出,再加上輸入門的輸出與生成的新候選記憶狀態的乘積。候選記憶狀態的計算如公式(4),記憶單元狀態的更新如公式(5)。
-
隱藏狀態( h t h_t ht?):通過輸出門和當前記憶狀態生成。 C t C_t Ct? 包含當前時刻的重要信息,而 o t o_t ot? 決定從 C t C_t Ct? 中輸出哪些信息到 h t h_t ht?,從而形成一個被過濾并轉換后的特征表示,見公式(6)。
f t = σ ( W f x t + U f h t ? 1 + b f ) (1) f_t = \sigma(W_f x_t + U_f h_{t-1} + b_f) \tag{1} ft?=σ(Wf?xt?+Uf?ht?1?+bf?)(1)
[ i t = σ ( W i x t + U i h t ? 1 + b i ) (2) [ i_t = \sigma(W_i x_t + U_i h_{t-1} + b_i) \tag{2} [it?=σ(Wi?xt?+Ui?ht?1?+bi?)(2)
o t = σ ( W o x t + U o h t ? 1 + b o ) (3) o_t = \sigma(W_o x_t + U_o h_{t-1} + b_o) \tag{3} ot?=σ(Wo?xt?+Uo?ht?1?+bo?)(3)
c ~ t = tanh ? ( W c x t + U c h t ? 1 + b c ) (4) \tilde{c}_t = \tanh(W_c x_t + U_c h_{t-1} + b_c) \tag{4} c~t?=tanh(Wc?xt?+Uc?ht?1?+bc?)(4)
C t = C t ? 1 ? f t + i t ? c ~ t (5) C_t = C_{t-1} \cdot f_t + i_t \cdot \tilde{c}_t \tag{5} Ct?=Ct?1??ft?+it??c~t?(5)
h t = o t ? tanh ? ( C t ) (6) h_t = o_t \cdot \tanh(C_t) \tag{6} ht?=ot??tanh(Ct?)(6)
其中, σ \sigma σ 表示 Sigmoid 函數, x t x_t xt? 是當前時刻的輸入, h t ? 1 h_{t-1} ht?1? 是前一時刻的隱藏狀態, C t C_t Ct? 為當前記憶單元狀態, c ~ t \tilde{c}_t c~t? 是候選記憶狀態, W W W、 U U U、 b b b 是各門控的可訓練參數。
B. CNN
CNN 由卷積層、激活函數、池化層和全連接層組成。卷積層通過卷積操作對輸入特征進行提取,激活函數引入非線性因素,池化層用于降維,全連接層用于最終的分類處理。輸出層通常使用 softmax 激活函數將全連接層的輸出轉換為類別概率分布。
本研究中,針對時間序列數據分析,使用了一維卷積層。一維卷積通過滑動窗口方式對輸入序列執行卷積操作,能夠捕捉輸入序列中的局部模式和特征。
C. TCN
TCN 模型是一種針對時間序列問題設計的簡單而高效的 CNN 架構,主要包括膨脹因果卷積和堆疊殘差單元。其優勢包括并行計算、參數共享和時序卷積,有助于提升對長時間依賴與長序列的建模能力。
1)因果卷積(Causal Convolutions)
因果卷積確保當前卷積的輸出僅依賴于當前及之前的輸入值,維護數據的時序因果關系。對輸入序列 x = { x 1 , x 2 , … , x T } x = \{x_1, x_2, \dots, x_T\} x={x1?,x2?,…,xT?},其輸出 y t y_t yt? 的計算公式如下:
y t = ∑ i = 0 k ? 1 w i ? x t ? i (7) y_t = \sum_{i=0}^{k-1} w_i \cdot x_{t-i} \tag{7} yt?=i=0∑k?1?wi??xt?i?(7)
其中, k k k 是卷積核大小, w i w_i wi? 是卷積核的權重, x t ? i x_{t-i} xt?i? 是輸入序列中的值。
2)膨脹卷積(Dilated Convolutions)
膨脹卷積引入一個膨脹因子 d d d,在卷積核每兩個元素間插入 d ? 1 d-1 d?1 個零,從而擴大感受野而不增加參數量。其公式如下:
y t = ∑ i = 0 k ? 1 w i ? x t ? d ? i (8) y_t = \sum_{i=0}^{k-1} w_i \cdot x_{t - d \cdot i} \tag{8} yt?=i=0∑k?1?wi??xt?d?i?(8)
其中, d d d 是膨脹因子, t ? d ? i t - d \cdot i t?d?i 表示在時序上的回溯位置。
結合因果卷積與膨脹卷積可構成膨脹因果卷積,兼具因果性與更大感受野的優點。
3)殘差模塊(Residual Block)
殘差模塊由兩個卷積單元和一個非線性映射單元組成,如圖 5 所示。每個卷積單元包含一維膨脹因果卷積、權重歸一化、ReLU 激活函數和 Dropout 操作。其操作公式如下:
h ( x ) = conv 1 × 1 ( x ) + f ( x ) (9) h(x) = \text{conv}_{1 \times 1}(x) + f(x) \tag{9} h(x)=conv1×1?(x)+f(x)(9)
其中, h ( x ) h(x) h(x) 為該層輸出并作為下一個殘差模塊的輸入, f ( x ) f(x) f(x) 為殘差映射。
D. 注意力機制(Attention Mechanism)
時間序列中的注意力機制指對不同時間步動態分配權重,以更好地捕捉序列中的關鍵信息,常用于預測、異常檢測和序列對齊等任務。引入注意力機制增強了神經網絡模型的靈活性和適應性。
本研究采用加權求和注意力機制對 LSTM 的輸出特征進行增強,如圖 6 所示。具體包括三個步驟:
-
通過全連接層計算每個時間步的注意力得分:
e t = tanh ? ( W t ? h t + b ) (10) e_t = \tanh(W_t \cdot h_t + b) \tag{10} et?=tanh(Wt??ht?+b)(10) -
使用 softmax 函數將注意力得分歸一化為注意力權重:
α t = exp ? ( e t ) ∑ k = 1 T exp ? ( e k ) (11) \alpha_t = \frac{\exp(e_t)}{\sum_{k=1}^{T} \exp(e_k)} \tag{11} αt?=∑k=1T?exp(ek?)exp(et?)?(11) -
計算上下文向量 c c c:
c = ∑ t = 1 T α t ? h t (12) c = \sum_{t=1}^{T} \alpha_t \cdot h_t \tag{12} c=t=1∑T?αt??ht?(12)
其中, W t W_t Wt? 和 b b b 為可學習參數, α t \alpha_t αt? 表示第 t t t 個時間步的重要性。
E. TCN-LSTM-Attention 混合模型
TCN-LSTM-Attention 混合模型融合了各自的優勢:
- TCN 通過局部感受野和多層卷積結構,提取時間序列的時空特征。
- LSTM 的門控機制有助于建模長期依賴信息。
- 注意力機制能夠動態聚焦于關鍵時間步,提高模型對序列中重要信息的識別能力。
該模型由五層組成:輸入層、TCN 層、LSTM 層、注意力層和全連接輸出層,如圖 8 所示。
- 輸入層:數據維度為 ( None , 10 , 1 ) (\text{None}, 10, 1) (None,10,1),每個樣本包含 10 個時間步,每個時間步 1 個特征。
- TCN 層:包含多個殘差塊,每個塊含兩個卷積單元(Dropout、ReLU、權重歸一化、膨脹因果卷積),輸出維度為 ( None , 10 , 64 ) (\text{None}, 10, 64) (None,10,64)。
- LSTM 層:包括三層 LSTM,每層輸出維度為 ( None , 10 , 50 ) (\text{None}, 10, 50) (None,10,50)。
- 注意力層:輸出維度為 ( None , 10 , 50 ) (\text{None}, 10, 50) (None,10,50)。
- 全連接層:輸出維度為 ( None , 1 ) (\text{None}, 1) (None,1)。
該模型訓練輪數為 100,學習率為 0.0001,優化器為 Adam。
F. 隔離森林(Isolation Forest)
隔離森林是一種常用于異常檢測的無監督學習算法,其核心思想是:異常點因遠離正常樣本而更容易被隔離。
該方法通過構造多個隨機決策樹對數據進行分割,最終為樣本分配異常得分,得分越高表明越可能是異常點。如圖 7 所示,其異常得分計算公式如下:
Isolation?Score ( x ) = 2 ? E ( h ( x ) ) c ( n ) (13) \text{Isolation Score}(x) = 2^{-\frac{E(h(x))}{c(n)}} \tag{13} Isolation?Score(x)=2?c(n)E(h(x))?(13)
其中, E ( h ( x ) ) E(h(x)) E(h(x)) 表示樣本 x x x 在多棵隨機樹中的平均隔離深度, c ( n ) c(n) c(n) 是與樣本數量 n n n 有關的常數。
III. 數據處理
A. 地震與觀測井介紹
根據中國地震臺網中心(CENC),2020年7月12日6時38分,河北省唐山市古冶區( 39.7 8 ° 39.78^\circ 39.78°N, 118.4 4 ° 118.44^\circ 118.44°E)發生 5.1 5.1 5.1級地震,震源深度為 10 km 10\,\text{km} 10km。此次 5.1 5.1 5.1級地震位于1976年 7.8 7.8 7.8級唐山地震的余震帶中部,距離1976年 7.8 7.8 7.8級唐山地震震中約 57 km 57\,\text{km} 57km,距1976年 7.1 7.1 7.1級灤州地震震中約 11 km 11\,\text{km} 11km。2020年5月至7月的全國地震概率預測結果表明,此次地震發生在地震活動相對高概率區。該地震是自1995年10月6日唐山 5.0 5.0 5.0級地震以來,唐山地震序列中24.8年來最大的一次 5.0 5.0 5.0級及以上地震。
趙各莊井位于北京市平谷區城關鎮趙各莊村,地理坐標為 117.0 1 ° 117.01^\circ 117.01°E, 40.1 3 ° 40.13^\circ 40.13°N,海拔 26.2 m 26.2\,\text{m} 26.2m。其觀測井剖面如圖9所示,井周地表大部分覆蓋第四系松散堆積物。監測含水層為第四系承壓孔隙水,主要包括:
- 深度為 171.00 ~ 254.00 m 171.00\sim254.00\,\text{m} 171.00~254.00m的第四系礫石及卵石與黏性砂混合層;
- 深度為 556.81 ~ 557.26 m 556.81\sim557.26\,\text{m} 556.81~557.26m的第四系石英砂巖層。
井中還包括 257.59 ~ 479.00 m 257.59\sim479.00\,\text{m} 257.59~479.00m的礫石和卵石夾黏性巖層以及 479.00 ~ 556.81 m 479.00\sim556.81\,\text{m} 479.00~556.81m的礫石和巨礫夾黏性巖層,均具有良好的滲透性。自2001年9月起開展了水位和水溫的數字化監測。長期觀測數據顯示,該井對周邊 4.0 4.0 4.0級以上地震具有良好的響應能力。
玉田基03井觀測臺站位于 117.7 8 ° 117.78^\circ 117.78°E, 39.8 2 ° 39.82^\circ 39.82°N,井深 456.42 m 456.42\,\text{m} 456.42m,觀測段深度為 317.00 ~ 456.42 m 317.00\sim456.42\,\text{m} 317.00~456.42m,含水層巖性為奧陶系灰巖,地下水類型為巖溶裂隙承壓水。其水位觀測數據連續可靠,脈沖少,基礎資料完備。觀測井表現出明顯的年變化規律,水位高峰通常出現在9月到11月之間,低谷多出現在6月。當水位年變化規律不與降雨相關并出現異常時,常伴隨中強地震的發生。例如1989年6月,水位上升異常后出現下降異常,不久后即在1989年10月19日發生了山西大同 M 6.1 M6.1 M6.1地震。
圖10顯示了震中位置與兩個監測井的位置。趙各莊井位于夏墊斷裂帶北端,其水溫和水位的異常變化與夏墊斷裂活動有關;玉田基03井則位于鎮子鎮斷裂帶附近。位于地震斷裂帶上的監測井更容易在地震前出現水位異常,這是由于斷裂帶地質活動可導致地下水流動和壓力發生變化,從而引起水位的變化。此外,這兩口井均采集自承壓含水層,相比其他類型的地下水,其對地殼應變狀態變化更具客觀性和敏感性。
B. 實驗流程與配置
本實驗包括三個主要步驟:數據預處理、訓練方法選擇與異常分析,如圖11所示。
在數據預處理階段,首先對采集的原始數據進行了缺失值處理,然后劃分為 S A SA SA和非 S A SA SA期,并進行了數據標準化。處理后的數據劃分為訓練集、驗證集和預測集。
實驗中采用了七種模型:LSTM、LSTM-Attention、CNN-LSTM、CNN-LSTM-Attention、TCN、TCN-LSTM 和 TCN-LSTM-Attention。其中包含LSTM的模型又進一步分為一層與三層兩種結構進行比較分析。訓練后模型用于對地下水水位數據進行預測分析,并通過 M S E MSE MSE、 M A E MAE MAE、 R M S E RMSE RMSE 和決定系數 R 2 R^2 R2等指標進行評估。
在異常分析階段,通過評估發現模型 TCN-LSTM(3層)-Attention 在異常檢測方面表現更優。該模型用于預測實際值與預測值之間的殘差,并進一步結合 E W M A EWMA EWMA控制圖分析,以確定最早的異常時間。實驗配置詳見表1。
C. 缺失值處理
本研究使用的數據集由中國地震臺網中心國家地震數據中心提供(http://data.earthquake.cn)。實驗中收集了地震發生前18個月和地震后10天內兩個井的分鐘級水位數據。數據集中缺失值以 999999.0 999999.0 999999.0表示。將 999999.0 999999.0 999999.0替換為 N a N NaN NaN后,發現趙各莊井有 4522 4522 4522個缺失值,玉田基03井有 2076 2076 2076個缺失值。采用線性插值法對缺失值進行填補。填補后的數據如圖12和圖13所示。圖中紅色虛線表示 S A SA SA期和非 S A SA SA期的分界,紅線左側為 S A SA SA期,右側直至地震發生為非 S A SA SA期,黑色虛線表示地震發生時刻。
D. SA與非SA期的劃分
為更準確識別前兆異常,將時間序列劃分為 S A SA SA期和非 S A SA SA期。當實際值與預測值出現顯著偏差時,說明可能存在地震活動對監測數據產生影響。因此,關鍵在于尋找合適的規則劃分非 S A SA SA期與 S A SA SA期的時間區間。
實驗中采用如下經驗公式來確定該時間區間,如公式14所示:
log ? R T = 0.63 M ± 0.15 (14) \log R T = 0.63 M \pm 0.15 \tag{14} logRT=0.63M±0.15(14)
其中, R ( km ) R\,(\text{km}) R(km)表示震中距, T ( days ) T\,(\text{days}) T(days)為前兆異常與后續地震之間的時間間隔, M M M為地震震級, log ? \log log表示以 10 10 10為底的對數。
從 T T T天前至地震時刻為 S A SA SA期,其余時間為非 S A SA SA期。根據公式計算,震中距趙各莊井約為 127.95 km 127.95\,\text{km} 127.95km,對應 T T T為 9.0356 ~ 18.0285 9.0356\sim18.0285 9.0356~18.0285天;震中距玉田基03井約 56.5 km 56.5\,\text{km} 56.5km,對應 T T T為 20.4621 ~ 40.8 20.4621\sim40.8 20.4621~40.8天。為便于實驗,取最長的前兆時間,分別為玉田基03井的 41 41 41天和趙各莊井的 19 19 19天。
因此,趙各莊井的 S A SA SA期為 2020 2020 2020年 6 6 6月 23 23 23日至 7 7 7月 12 12 12日,其余為非 S A SA SA期;玉田基03井的 S A SA SA期為 2020 2020 2020年 6 6 6月 1 1 1日至 7 7 7月 12 12 12日,其余為非 S A SA SA期。
E. 數據集劃分
為提升模型檢測潛在前兆異常的能力,根據前人研究及非 S A SA SA期數據,將訓練集和驗證集排除 S A SA SA期,僅選用非 S A SA SA期數據。將兩口井地震前18個月的數據分別劃分為訓練集( 80 % 80\% 80%)、驗證集( 10 % 10\% 10%)和預測集( 10 % 10\% 10%),以確保訓練與驗證階段不包含異常期數據。預測集中部分數據也來自非 S A SA SA期。圖14和圖15中,紅色豎線表示 2020 2020 2020年 6 6 6月 23 23 23日與 6 6 6月 1 1 1日,分別為趙各莊井和玉田基03井的 S A SA SA與非 S A SA SA期分界線。藍色段為訓練集,綠色段為驗證集,紅色段為預測集。
F. 數據歸一化
數據歸一化有助于加快模型收斂速度。當時間序列數據數值較大時,模型可能需要更多迭代才能達到最優解。通過縮放數據范圍,模型能更快學習有效參數。歸一化可增強模型穩定性,減少特征間數值差異對性能的影響。
本研究采用最小-最大歸一化方法,如公式15所示:
X i ? = X i ? X min ? X max ? ? X min ? (15) X_i^* = \frac{X_i - X_{\min}}{X_{\max} - X_{\min}} \tag{15} Xi??=Xmax??Xmin?Xi??Xmin??(15)
其中, X i X_i Xi?為第 i i i個樣本點的原始觀測數據, X i ? X_i^* Xi??為歸一化后的值, X max ? X_{\max} Xmax?與 X min ? X_{\min} Xmin?分別為原始數據中的最大值與最小值。
G. 模型評價指標
本文采用時間序列分析中常用的 M S E MSE MSE、 R M S E RMSE RMSE、 M A E MAE MAE與決定系數 R 2 R^2 R2來評估模型預測性能,具體計算公式如下:
M S E = 1 n ∑ i = 1 n ( y i ? y ^ i ) 2 (16) MSE = \frac{1}{n} \sum_{i=1}^{n} (y_i - \hat{y}_i)^2 \tag{16} MSE=n1?i=1∑n?(yi??y^?i?)2(16)
R M S E = 1 n ∑ i = 1 n ( y i ? y ^ i ) 2 (17) RMSE = \sqrt{ \frac{1}{n} \sum_{i=1}^{n} (y_i - \hat{y}_i)^2 } \tag{17} RMSE=n1?i=1∑n?(yi??y^?i?)2?(17)
M A E = 1 n ∑ i = 1 n ∣ y i ? y ^ i ∣ (18) MAE = \frac{1}{n} \sum_{i=1}^{n} |y_i - \hat{y}_i| \tag{18} MAE=n1?i=1∑n?∣yi??y^?i?∣(18)
R 2 = 1 ? ∑ i = 1 n ( y i ? y ^ i ) 2 ∑ i = 1 n ( y i ? y ˉ ) 2 (19) R^2 = 1 - \frac{ \sum_{i=1}^{n} (y_i - \hat{y}_i)^2 }{ \sum_{i=1}^{n} (y_i - \bar{y})^2 } \tag{19} R2=1?∑i=1n?(yi??yˉ?)2∑i=1n?(yi??y^?i?)2?(19)
其中, n n n為樣本數, y i y_i yi?為第 i i i個觀測值, y ^ i \hat{y}_i y^?i?為第 i i i個預測值, y ˉ \bar{y} yˉ?為觀測值的平均值。
H. EWMA控制圖
EWMA控制圖是一種用于監測和檢測過程微小變化或趨勢的統計過程控制圖。通過對數據施加指數加權,EWMA圖能更敏感地捕捉過程中的微小偏差。公式如下:
Z t = λ X t + ( 1 ? λ ) Z t ? 1 (20) Z_t = \lambda X_t + (1 - \lambda) Z_{t-1} \tag{20} Zt?=λXt?+(1?λ)Zt?1?(20)
U C L t = μ + L σ λ 2 ? λ ( 1 ? ( 1 ? λ ) 2 t ) (21) UCL_t = \mu + L \sigma \sqrt{ \frac{ \lambda }{ 2 - \lambda } (1 - (1 - \lambda)^{2t} ) } \tag{21} UCLt?=μ+Lσ2?λλ?(1?(1?λ)2t)?(21)
L C L t = μ ? L σ λ 2 ? λ ( 1 ? ( 1 ? λ ) 2 t ) (22) LCL_t = \mu - L \sigma \sqrt{ \frac{ \lambda }{ 2 - \lambda } (1 - (1 - \lambda)^{2t} ) } \tag{22} LCLt?=μ?Lσ2?λλ?(1?(1?λ)2t)?(22)
其中, Z t Z_t Zt?為 t t t時刻的EWMA值, X t X_t Xt?為 t t t時刻觀測值, λ \lambda λ為平滑系數( 0 < λ ≤ 1 0 < \lambda \leq 1 0<λ≤1),控制權重衰減速率, Z t ? 1 Z_{t-1} Zt?1?為 t ? 1 t-1 t?1時刻的EWMA值,初始值 Z 0 = μ Z_0 = \mu Z0?=μ, μ \mu μ為過程均值, σ \sigma σ為標準差。
本實驗中,取 L = 3 L=3 L=3, λ = 0.3 \lambda=0.3 λ=0.3,即控制界限設置為均值上下三個標準差,符合正態分布經驗法則,理論上 99.73 % 99.73\% 99.73%的數據應落在此區間內。
IV. 實例分析
A. 模型預測分析
1)趙各莊井水位預測結果分析
圖16展示了各個包含1層LSTM模型對趙各莊井水位的預測結果。在訓練集、驗證集以及預測集的早期階段(即非SA期間),所有模型的擬合效果都較好,表明各模型未發生過擬合。值得注意的是,在2020年6月23日至2020年7月12日的SA期間,所有模型均開始出現明顯的擬合不良,預測值與真實值之間出現較大偏差,可能表明地下水位出現了異常。為更好地檢測此類異常,應選擇在SA期間預測值與真實值偏差最大的模型。TCN-LSTM-Attention模型表現最為明顯,其次是TCN-LSTM模型。
表2給出了地震發生前十天早上6:38的預測值及殘差。LSTM的殘差范圍為 ? 0.0012 -0.0012 ?0.0012 至 0.0024 0.0024 0.0024,而TCN的殘差范圍為 ? 0.0254 -0.0254 ?0.0254 至 ? 0.0353 -0.0353 ?0.0353。相比之下,TCN模型的殘差約為LSTM模型的20倍,表明TCN模型更適合用于識別地下水異常作為地震前兆信號。CNN-LSTM模型的殘差范圍為 0.0089 0.0089 0.0089 到 0.0102 0.0102 0.0102,TCN-LSTM模型的殘差范圍為 0.0726 0.0726 0.0726 到 0.0933 0.0933 0.0933,約為CNN-LSTM模型的10倍,說明TCN和LSTM的組合比CNN和LSTM更適合識別本實驗中的地下水異常。而TCN-LSTM-Attention模型的殘差范圍為 0.2102 0.2102 0.2102 到 0.2444 0.2444 0.2444,為所有模型中殘差最大,說明TCN-LSTM-Attention模型在識別水位異常方面表現最佳。
圖16、17、18中,灰色背景為訓練集數據,黃色背景為驗證集數據,綠色背景為測試集數據。紅色虛線為SA與非SA期間的時間分界線,黑色虛線為地震發生時刻。實線黑線表示實際值,其他顏色實線為各模型的預測值。
圖17展示了包含3層LSTM的各模型對趙各莊井水位的預測結果。在監督學習模型中,各模型在非SA期間表現良好,但在SA期間均出現擬合不良現象,反映地下水位的異常。其中,TCN-LSTM-Attention模型異常識別最為明顯,其次是TCN-LSTM模型。
如表3所示,TCN-LSTM模型的殘差在 0.1633 0.1633 0.1633 至 0.2037 0.2037 0.2037 之間,TCN-LSTM-Attention模型的殘差在 0.9415 0.9415 0.9415 至 1.0617 1.0617 1.0617 之間,后者的殘差最大,進一步說明其在識別井水位異常數據方面的優越性。
此外,作為無監督學習方法,Isolation Forest模型也成功識別出趙各莊井的水位異常(見圖17),表明監督學習與無監督學習方法均可有效檢測地下水異常。但結果顯示,Isolation Forest模型識別異常的時間晚于TCN-LSTM-Attention模型。
同時,表2與表3顯示,TCN-LSTM(1層)-Attention模型的殘差為 0.2102 0.2102 0.2102 到 0.2444 0.2444 0.2444,而TCN-LSTM(3層)-Attention模型的殘差為 0.9415 0.9415 0.9415 到 1.0617 1.0617 1.0617,后者約為前者的5倍。因此,TCN-LSTM(3層)-Attention模型是檢測地下水位異常的最優模型。隨后,所有包含3層LSTM的模型被用于預測玉田集03井的水位。
2)玉田集03井水位預測結果分析
圖18展示了各個包含3層LSTM模型對玉田集03井水位的預測結果。在非SA期間,各模型表現良好,但在SA期間均表現出明顯的擬合異常,TCN-LSTM-Attention模型表現最為突出。
表4顯示了地震發生前第十天早上6:38的各模型預測值與殘差,其中TCN-LSTM-Attention模型的殘差最大。這說明該模型能夠在不同井位、同一地震事件中識別出水位異常,表明其具有良好的適用性和遷移能力。
同樣,我們也對玉田集03井水位數據采用Isolation Forest方法進行異常檢測(見圖18),在SA期間也成功識別出水位異常,證明其識別地下水異常的有效性。但不難發現,其識別時間仍晚于TCN-LSTM-Attention模型。
D. 綜合分析
地下水位的異常波動可以作為地震前兆的潛在指標。尤其在地震臨近時,地殼應力逐漸積累,可能導致地下巖層出現微小裂縫或變形。這些應力變化會影響地下水系統,特別是水壓、流速、水位以及化學成分等參數。因此,通過監測特定區域地下水位的異常波動,可以捕捉潛在的地震前兆信號,為地震預測提供關鍵的數據支持。
此次地震的震中位于唐山斷裂帶北段 [49],強震影響區約為 47 平方千米。然而,出現明顯地下水異常的區域卻延伸至 400 至 500 千米范圍。震前,靠近震中的流體觀測井顯示出高孔隙壓力,表明唐山古冶地區處于應力積累狀態。震前壓縮帶大致呈東西走向,特征為應力積累,井水位普遍呈現異常上升趨勢。
在本實驗中,位于震中西側的趙各莊井與玉田集03井均處于震前壓縮帶,其水位也表現出異常上升。對這些水位變化的監測可為地震預警提供重要信息。
根據美國地質調查局(USGS)的全球地震目錄,我們選取了在驗證與預測階段,震中距監測點500千米范圍內所有震級大于 M w > 5 M_w > 5 Mw?>5 的地震事件。研究發現該時段附近并無其他震級大于5的地震,因此可以判定,此次水文異常為唐山地震引起。
階段預測結果分析: 對于兩口井,在水文時間序列的非SA(異常)期間,各模型的預測結果均與實際值高度擬合。然而在SA期間,所有模型的預測結果與實際值均出現明顯偏差,說明該階段地下水位存在異常波動。
模型預測結果分析: 在非SA期間,各模型表現良好;但在SA期間,包括無監督方法Isolation Forest在內,所有模型均檢測到地下水位異常。其中,TCN-LSTM-Attention模型識別異常的時間早于Isolation Forest,具備更強的地震前兆預測優勢。與其他模型相比,TCN-LSTM-Attention模型在預測值與實際值之間存在最大的偏差,表明其更適合用于識別地下水異常。
TCN-LSTM-Attention模型的深層結構使其能夠更有效地捕捉地下水位時間序列中的復雜模式和長期依賴關系。其多層架構提升了模型的表達能力,使其能從數據中提取更多特征,從而提高對地下水異常的檢測準確性。
異常期分析: 通過EWMA控制圖識別到的最早異常時刻為:
- 趙各莊井:2020年6月16日 14:12:00;
- 玉田集03井:2020年6月28日 18:17:00。
這些異常的早期識別時間為災害預防、減災和救援提供了關鍵參考,使管理人員能夠及時采取措施防范潛在災害。
E. 模型的可遷移性
近年來,許多學者對遷移學習展開了研究。遷移學習的目標是將模型在源領域中學習到的知識遷移至目標領域,尤其在源領域與目標領域存在一定相關性但數據分布不同的情況下,如圖27所示。
圖27. 遷移學習的基本思想。
我們選取了2015年4月13日10:28發生于中國云南省建水縣的一次震級為4.7的地震作為研究對象。該地震的震中位于北緯23.96度、東經102.84度。我們使用TCN-LSTM-Attention模型對建水井的地下水位數據進行分析。該井距離震中約35.68千米。
根據公式10,本次地震的SA期約為震前37天。我們使用LSTM模型與TCN-LSTM-Attention模型分別對建水井的水位進行預測,如圖28所示。在非SA期,兩個模型的擬合效果都較好;而在震前14天左右,預測值與實際值之間開始出現明顯差異,說明兩個模型均檢測到了地下水異常,但TCN-LSTM-Attention模型檢測到的異常更為明顯。
表8顯示,在地震前10天,TCN-LSTM-Attention模型的殘差大約是LSTM模型的8倍,表明其對地下水異常更敏感,異常檢測能力更強。
表9顯示,兩種模型在測試集上的均方誤差(MSE)、均方根誤差(RMSE)和平均絕對誤差(MAE)均高于訓練集與驗證集,說明模型在測試集預測中成功檢測到了異常。
通過EWMA控制圖,我們識別到的最早異常時刻為2015年4月1日12:57:00。此次地震的前兆特征與唐山地震高度相似。
這一結果說明,本文提出的模型不僅適用于華北地區的唐山地下水數據分析,還可以遷移至地質結構不同的中國西南地區,有效識別其它地區的地下水異常。因此,對建水地震事件的分析進一步驗證了TCN-LSTM-Attention模型的泛化能力與可遷移性,展示出良好的適應性與魯棒性。這些結果為該模型在更廣泛的地震預測應用中提供了有力支持。
F. 模型精度驗證
交叉驗證是一種用于評估模型性能與泛化能力的統計方法 [50]。它將數據集劃分為多個稱為“折(fold)”的子集,并在不同的子集組合上多次訓練模型。
最常見的交叉驗證方法是 k k k 折交叉驗證( k k k-fold cross-validation),即將數據劃分為 k k k 個不重疊子集,每輪迭代使用 k ? 1 k - 1 k?1 個子集進行訓練,剩下的一個子集用于驗證。經過 k k k 次迭代后,計算所有驗證結果的平均值,以估計模型的穩健性與泛化能力。
在本實驗中,我們采用了5折交叉驗證,如圖30所示。我們使用趙各莊井的地下水位數據進行交叉驗證以驗證模型精度,結果見圖31。
訓練集與驗證集包含正常的地下水波動,擬合效果良好。然而在測試集中,當地下水位顯著偏離正常范圍時,模型未強行擬合真實值,從而導致預測值與實際值之間出現明顯差異。該差異反映了模型對異常檢測的有效性,成功識別出可能由地震活動引起的異常。
通過交叉驗證,我們觀察到本文提出的模型在不同訓練-驗證劃分組合下均表現出良好的異常檢測效果,表明其具有強泛化能力與對地下水異常變化的高敏感性。
綜上所述,交叉驗證不僅驗證了模型的穩定性與準確性,也進一步證明其在地震前兆監測中的潛力。
V. 結論
地下水水位的微小動態為地球動力學和地震監測提供了理論基礎。研究表明,地震與區域應力場的調整密切相關,應力場的變化會引起承壓含水層中的應力-應變變化。因此,地下水位異常常被視為地震前兆的指標。
本研究通過模型預測地下水位數據,并通過對比預測數據與實測數據識別異常點。研究結論如下:
1)根據經驗公式將數據集劃分為非震前活躍期(non-SA period)和震前活躍期(SA period)。對于玉田集 03 井,震前 41 天被視為 SA period,其余時間為 non-SA period;而趙各莊井的 SA period 為震前 19 天,其余為非活躍期。依據此方法對數據進行分段,有助于深入分析地震活動對地下水位的影響,不僅有助于識別地震前兆,還為未來地震預測與災害防控提供了關鍵的時間參考。
2)與其他模型相比,TCN-LSTM-Attention 模型在地震前期的預測結果與實際值偏差最大,表現出對異常數據的高靈敏性,且能早于無監督的 Isolation Forest 方法識別異常。該模型能有效捕捉地震前地下水位的顯著波動,清晰地反映 SA period 內的異常,為地震預測與防災減災提供了重要信息。
3)本研究利用 TCN-LSTM-Attention 模型的殘差并結合 EWMA 控制圖(Exponentially Weighted Moving Average)進行異常檢測,確定異常變化的起始時間。結果顯示,玉田集 03 井的最早異常檢測時間為 2020 年 6 月 28 日 18:55:00,趙各莊井為 2020 年 6 月 20 日 17:03:00,建水井為 2015 年 4 月 1 日 12:57:00。該方法不僅能夠有效識別地下水位的異常變化,還能精確定位其發生時間,表明將神經網絡模型與統計分析方法結合能顯著提升地下水異常檢測的準確性和及時性,為地震預測提供更可靠的參考依據。
4)本研究驗證了模型的可遷移性與準確性。將 TCN-LSTM-Attention 模型應用于同一次地震事件中的不同觀測井以及另一地震事件中的建水井,均能檢測出異常,說明該模型具有良好的泛化能力與遷移性。通過交叉驗證,模型在不同訓練-測試劃分下均表現出一致性,進一步驗證了其穩健性和對地下水異常的高敏感性。成功識別地下水異常為模型在更廣泛地震預測中的應用提供了有力支撐。
本研究提升了模型的預測能力與異常檢測靈敏度,增強了地震預警的準確性與效率,從而有效降低了地震災害風險,最大限度減少生命財產損失。然而,地震前兆異常表現形式多樣,包括地下水水位、水溫、氡濃度、電磁信號、地熱異常等多種因素。本研究僅聚焦于地下水水位異常,未來將進一步研究多種類型的數據,以提升地震異常檢測的準確性與實用性。





)

平臺設計)



)

和 plumberpdf 的對比分析及使用建議)
原理,公式,應用,算法改進研究綜述,matlab代碼)
,狀態))



