📚 目錄(快速跳轉)
- 選擇題(上午題)(每題1分,共75分)
- 一、 計算機系統基礎知識 🖥?
- 💻 題目1:計算機硬件基礎知識 - RISC(精簡指令集計算機)
- 💻 題目2:計算機組成原理 - CPU的基本組成
- 📊 題目3:可靠性計算 - 千小時可靠度
- 💾 題目4:存儲器類型 - 電容存儲與刷新特性
- ?? 題目5:浮點數表示 - 階碼與尾數對范圍和精度的影響
- ?? 題目6:補碼表示 - 有符號數值運算特性
- 🖥? 題目20:計算機軟件 - 函數調用棧幀內容
- 🖥? 題目21:程序設計語言 - 編譯器工作方式及特點
- 🖥? 題目22:程序設計語言 - 語法分析方法分類
- 🖥? 題目23:計算機系統 - 進程調度方式
- 🖥? 題目24-26:操作系統 - PV操作與進程同步
- 🖥? 題目27:計算機系統 - 段頁式存儲管理系統地址結構分析
- 💽 題目28:計算機硬件基礎知識 - 磁盤文件讀取時間計算
- 🐍 題目48:程序語言設計 - Python異常處理結構辨析
- 🐍 題目49:程序語言設計 - Python列表切片操作
- 🐍 題目50:程序語言設計 - Python的input()函數行為
- 🗃? 題目51:數據庫設計 - E-R模型向關系模型轉換規則
- 🗃? 題目52-53:數據庫設計 - 數據庫范式與函數依賴分析
- 🗃? 題目54-55:數據庫設計 - 關系代數表達式解析
- 🏦 題目56:數據庫事務 - 數據庫故障類型辨析
- 🧮 題目57:數據結構 - 棧的出棧序列可能性分析
- 🌳 題目58:數據結構 - 二叉樹中序遍歷順序分析
- 🏗? 題目59:數據結構 - 無向圖的鄰接矩陣存儲空間分析
- 🌳 題目60:數據結構 - B-樹特性辨析
- 🏆 題目61:數據結構與算法 - 排序算法輔助空間復雜度比較
- 🧩 題目62-63:數據結構與算法 - 折半查找算法策略與平均比較次數
- 🚀 題目64-65:數據結構與算法 - Dijkstra算法策略與最短路徑計算
- 🌐 題目66:計算機網絡 - VLAN Tag在OSI模型中的位置
- 🌐 題目67:計算機網絡 - Telnet協議特性辨析
- 🔒 題目68:計算機網絡 - HTTPS與HTTP協議辨析
- 🌐 題目69:計算機網絡 - 域名解析
- 🌐 題目70:計算機網絡 - IP 地址和 MAC 地址
- 二、 系統開發和運行知識 🗃?
- 🛠? 題目15:系統開發 - 加工規格說明的描述方法選擇
- 🧩 題目16:系統開發 - 模塊結構優化的錯誤方法
- 🗺? 題目17-18:系統開發 - 關鍵路徑分析
- 📊 題目19:軟件開發項目管理 - 風險管理原則辨析
- 🏗? 題目29:系統設計方法與模型 - 快速原型模型的優點辨析
- 🏗? 題目30:系統設計 - 三層C/S結構的特性辨析
- 🧩 題目31:系統設計 - 模塊耦合類型辨析
- 🏻 題目32:系統開發 - 軟件高質量標準的理解
- 🧪 題目33:軟件測試基礎知識 - 白盒測試覆蓋方法的能力對比
- 📄 題目34:軟件質量 - 高質量文檔標準的辨析
- 🧪 題目35:軟件測試基礎知識 - 測試階段與錯誤發現能力
- 🛠? 題目36:系統運行和維護基礎知識 - 軟件維護類型辨析
- 三、 面向對象基礎知識 🧩
- 🦆 題目37-38:面向對象 - 面向對象設計概念辨析
- 🧩 題目39:面向對象 - 面向對象分析中的對象認定
- 🧩 題目40:面向對象 - 面向對象設計原則辨析
- 🏗? 題目41-42:面向對象 - UML活動圖解析
- 🏗? 題目43:面向對象 - UML構件圖的特性
- 🏗? 題目44-46:設計模式 - 設計模式辨析
- 🚗 題目47:設計模式 - 設計模式應用場景
- 四、 網絡與信息安全知識 🌐
- 🔐 題目7:信息安全技術 - 認證方式安全性對比
- 🔐 題目8-9:信息安全技術 - 數字證書密碼算法標準對比
- 🛡? 題目10:網絡安全技術 - 網絡安全防護設備選擇
- 🛡? 題目11:網絡安全技術 - 漏洞掃描系統的作用
- 五、 標準化、信息化和知識產權基礎知識 🛠?
- 📜 題目12:知識產權 - 委托開發軟件的著作權歸屬
- 📜 題目13:知識產權 - 軟件著作權中的翻譯權定義
- 📜 題目14:知識產權 - 知識產權權利辨析
- 六、 計算機英語 🐧
- 🐧題目71-75:計算機英語
選擇題(上午題)(每題1分,共75分)
2023年上午題試卷:百度云盤
💡 注意:文章按照知識點順序總結,未按真題順序
一、 計算機系統基礎知識 🖥?
💻 題目1:計算機硬件基礎知識 - RISC(精簡指令集計算機)
以下關于 RISC(精簡指令集計算機)特點的敘述中,錯誤的是 (1) 。
(1)
A. 對存儲器操作進行限制,使控制簡單化
B. 指令種類多,指令功能強 ?
C. 設置大量通用寄存器
D. 選取使用頻率較高的一些指令,提高執行速度
📌 正確答案:B
🔍 詳細解析
RISC(Reduced Instruction Set Computer) 的核心思想是通過 簡化指令集 和 優化硬件設計 來提高執行效率,其特點包括:
-
精簡指令集:
-
指令數量少,格式統一,功能簡單(與選項 B 矛盾)。
-
只保留高頻使用指令,復雜功能通過多條指令組合實現(對應選項 D)。
-
-
對存儲器操作的限制:
- 采用 Load/Store架構,只有專門的加載(Load)和存儲(Store)指令能訪問內存,其他指令操作均在寄存器間進行(對應選項 A)。
-
大量通用寄存器:
- 減少訪問內存的次數,提高數據操作效率(對應選項 C)。
-
其他特點:
-
采用流水線技術,單周期指令執行。
-
硬連線控制(非微程序控制),降低延遲。
-
💡 知識點分析
RISC vs CISC(復雜指令集計算機) 對比:
| 特性 | RISC | CISC |
|---|---|---|
| 指令數量 | 少(約幾十條) | 多(上百條) |
| 指令復雜度 | 簡單,單周期完成 | 復雜,多周期完成 |
| 存儲器訪問 | 僅Load/Store指令 | 允許內存直接操作 |
| 寄存器數量 | 大量通用寄存器 | 寄存器較少 |
💻 題目2:計算機組成原理 - CPU的基本組成
CPU(中央處理單元)的基本組成部件不包括 (2) 。
(2)
A. 算邏運算單元
B. 系統總線 ?
C. 控制單元
D. 寄存器組
📌 正確答案:B
🔍 詳細解析
CPU(Central Processing Unit) 是計算機的核心部件,負責執行指令和處理數據,其基本組成包括:
-
算術邏輯單元(ALU, Arithmetic Logic Unit):
-
執行算術運算(如加減乘除)和邏輯運算(如與或非)。
-
對應選項 A。
-
-
控制單元(CU, Control Unit):
-
負責指令譯碼、時序控制,協調CPU各部件工作。
-
對應選項 C。
-
-
寄存器組(Registers):
-
包括通用寄存器(如AX、BX)、指令寄存器(IR)、程序計數器(PC)等,用于暫存數據和指令。
-
對應選項 D。
-
? 系統總線(System Bus)不屬于CPU的組成部分:
- 系統總線是 CPU與內存、外設通信的公共通道(包括數據總線、地址總線、控制總線),屬于計算機系統層級的組件,而非CPU內部結構。
💡 知識點分析
-
CPU內部數據流:
-
取指令:PC指向內存地址 → 通過總線獲取指令 → 存入IR。
-
執行指令:CU譯碼 → ALU運算 → 結果寫回寄存器或內存。
-
-
其他選項對比:
-
A. ALU 和 C. CU 是CPU的核心部件,缺一不可。
-
D. 寄存器組 直接影響CPU的運算速度(如寄存器比緩存更快)。
-
-
擴展概念:
-
馮·諾依曼架構:CPU + 存儲器 + 輸入/輸出設備 + 總線。
-
現代CPU的擴展組件:
-
緩存(Cache):L1/L2/L3緩存,減少內存訪問延遲。
-
流水線(Pipeline):提升指令并行度。
-
多核結構:多個CPU核心集成在同一芯片。
-
-
📊 題目3:可靠性計算 - 千小時可靠度
某種部件用在 2000 臺計算機系統中,運行工作 1000 小時后,其中有 4 臺計算機的這種部件失效,則該部件的千小時可靠度 R 為(3) 。
(3)
A. 0.990
B. 0.992
C. 0.996
D. 0.998 ?
📌 正確答案:D
🔍 詳細解析
可靠度(Reliability) 的定義是:在規定的條件下和規定的時間內,部件或系統正常工作的概率。計算公式為:
R ( t ) = 正常工作的數量 總數量 = 1 ? 失效數量 總數量 R(t)=\frac{正常工作的數量}{總數量}=1 - \frac{失效數量}{總數量} R(t)=總數量正常工作的數量?=1?總數量失效數量?
題目數據:
-
總數量 = 2000 臺
-
失效數量 = 4 臺
-
工作時間 = 1000 小時
計算過程:
R ( t ) = 2000 ? 4 2000 = 1996 2000 = 0.998 R(t)=\frac{2000-4}{2000}= \frac{1996}{2000}= 0.998 R(t)=20002000?4?=20001996?=0.998
📊 擴展應用
串聯系統可靠度: R t o t a l = R 1 × R 2 × ? × R n R_{total}= R_{1} × R_{2} × ? × R_{n} Rtotal?=R1?×R2?×?×Rn?。
并聯系統可靠度: R t o t a l = 1 ? ( 1 ? R 1 ) ( 1 ? R 2 ) ? ( 1 ? R n ) R_{total}= 1- (1 - R_{1})(1 - R_{2})?(1 - R_{n}) Rtotal?=1?(1?R1?)(1?R2?)?(1?Rn?)。
💾 題目4:存儲器類型 - 電容存儲與刷新特性
以下存儲器中, (4) 使用電容存儲信息且需要周期性地進行刷新。
(4)
A. DRAM ?
B. EPROM
C. SRAM
D. EEPROM
📌 正確答案:A
🔍 詳細解析
DRAM(Dynamic Random Access Memory) 是本題描述的唯一正確答案,其核心特點包括:
-
電容存儲數據:
- 每個存儲單元由 一個晶體管+一個電容 組成,電容電荷表示二進制數據(有電荷=1,無電荷=0)。
-
需周期性刷新:
- 電容會自然漏電,導致數據丟失,因此需每隔 2~64ms 刷新一次(通過讀取后重寫)。
其他選項分析:
-
B. EPROM(Erasable Programmable ROM):
- 使用浮柵晶體管存儲數據,紫外線擦除,無需刷新。
-
C. SRAM(Static RAM):
- 基于觸發器(Flip-flop)結構,無需刷新,但功耗高、成本高,常用于緩存。
-
D. EEPROM(Electrically Erasable PROM):
- 電可擦除ROM,非易失性存儲器,無需刷新。
💡 知識點對比表
| 存儲器類型 | 存儲原理 | 易失性 | 刷新需求 | 典型用途 |
|---|---|---|---|---|
| DRAM | 電容 | 易失 | 需要 | 主內存(DDR4/DDR5) |
| SRAM | 觸發器 | 易失 | 不需要 | CPU緩存(L1/L2/L3) |
| EPROM | 浮柵晶體管 | 非易失 | 不需要 | 固件存儲(已淘汰) |
| EEPROM | 浮柵晶體管(電擦除) | 非易失 | 不需要 | BIOS配置、小型嵌入式系統 |
?? 題目5:浮點數表示 - 階碼與尾數對范圍和精度的影響
對于長度相同但格式不同的兩種浮點數,假設前者階碼長、尾數短,后者階碼短、尾數長,其它規定都相同,則二者可以表示數值的范圍和精度情況為 (5)。
(5)
A. 二者可表示的數的范圍和精度相同
B. 前者所表示的數的范圍更大且精度更高
C. 前者所表示的數的范圍更大但精度更低 ?
D. 前者所表示的數的范圍更小但精度更高
📌 正確答案:C
🔍 詳細解析
浮點數的表示能力由 階碼(Exponent) 和 尾數(Mantissa) 共同決定:
-
階碼(Exponent):
-
決定數值的 范圍(能表示的最大/最小絕對值)。
-
階碼位數越多,可表示的指數范圍越大(例如8位階碼比6位階碼能表示更大的數)。
-
-
尾數(Mantissa):
-
決定數值的 精度(有效數字的位數)。
-
尾數位數越多,小數部分的精度越高(例如10位尾數比8位尾數能更精確表示小數)。
-
題目場景分析:
-
第一種格式:階碼長 + 尾數短 → 范圍大,精度低。
-
第二種格式:階碼短 + 尾數長 → 范圍小,精度高。
💡 知識點擴展
-
IEEE 754標準示例:
-
單精度(32位):8位階碼 + 23位尾數 → 范圍約±103?,精度約7位十進制。
-
雙精度(64位):11位階碼 + 52位尾數 → 范圍約±103??,精度約16位十進制。
-
-
極端情況對比:
| 格式 | 階碼位數 | 尾數位數 | 范圍 | 精度 |
|---|---|---|---|---|
| 長階碼短尾數 | 10位 | 6位 | ±103?? | 約2位小數 |
| 短階碼長尾數 | 6位 | 10位 | ±101? | 約4位小數 |
?? 題目6:補碼表示 - 有符號數值運算特性
計算機系統中采用補碼表示有符號的數值, (6) 。
(6)
A. 可以保持加法和減法運算過程與手工運算方式一致
B. 可以提高運算過程和結果的精準程度
C. 可以提高加法和減法運算的速度
D. 可以將減法運算轉換為加法運算從而簡化運算器的設計 ?
📌 正確答案:D
🔍 詳細解析
補碼(Two’s Complement) 是計算機表示有符號整數的標準方式,其核心優勢在于:
-
統一加減法運算:
-
減法可以轉換為加法(例如 A - B = A + (-B)),其中 -B 是 B 的補碼(按位取反后加1)。
-
簡化硬件設計:運算器只需加法器即可處理加減法,無需額外減法電路。
-
-
選項逐項分析:
-
A. 與手工運算方式一致 ?
- 手工運算(如豎式計算)依賴借位,補碼的進位邏輯與手工方式不同。
-
B. 提高精準度 ?
- 補碼不改變運算結果的數學精度,僅影響表示和運算的便捷性。
-
C. 提高運算速度 ?
- 補碼的運算速度與無符號數相同,未直接“提速”,而是通過簡化設計間接優化。
-
D. 減法轉加法 ?
- 補碼的核心優勢,直接減少硬件復雜度(如CPU的ALU設計)。
-
💡 補碼的特性總結
| 特性 | 說明 |
|---|---|
| 唯一零表示 | [+0]補 = [-0]補 = 000…0,避免原碼的零歧義問題。 |
| 符號位參與運算 | 最高位自然表示符號(0正1負),且運算時無需特殊處理。 |
| 溢出檢測簡單 | 若兩正數相加結果為負,或兩負數相加結果為正,則發生溢出。 |
具體補碼轉換見文章題5
🖥? 題目20:計算機軟件 - 函數調用棧幀內容
當函數調用執行時,在棧頂創建且用來支持被調用函數執行的一段存儲空間稱為活動記錄或者棧幀,棧幀中不包括 (20) 。
(20)
A. 形參變量
B. 全局變量 ?
C. 返回地址
D. 局部變量
📌 正確答案:B
🔍 詳細解析
-
棧幀(Stack Frame)的典型結構
組成部分 說明 是否在棧幀中 形參變量 函數調用時傳入的參數(如void foo(int a)中的a)。 ??(選項A) 返回地址 函數執行完畢后需跳轉的指令地址(如call指令下一條指令地址)。 ??(選項C) 局部變量 函數內部定義的變量(如int b = 0;)。 ??(選項D) 全局變量 定義在函數外部的變量(如int global_var;),存儲在全局數據區或靜態存儲區。 ?(選項B) -
關鍵區別
-
棧幀的臨時性:棧幀隨函數調用創建、隨返回銷毀,僅存儲 當前函數 的臨時數據。
-
全局變量的存儲:
-
生命周期與程序一致,存放在 全局/靜態存儲區(非棧區)。
-
所有函數均可訪問,無需通過棧幀管理。
-
-
-
內存區域對比
內存區域 存儲內容 特點 棧(Stack) 棧幀(形參、返回地址、局部變量等) 自動分配/釋放,后進先出。 堆(Heap) 動態分配的內存(如malloc) 手動管理,可能碎片化。 全局/靜態區 全局變量、靜態變量 程序啟動時分配,結束時釋放。
🖥? 題目21:程序設計語言 - 編譯器工作方式及特點
以下關于編譯器工作方式及特點的敘述中,正確的是 (21) 。
(21)
A. 邊翻譯邊執行,用戶程序運行效率低且可移植性差
B. 先翻譯后執行,用戶程序運行效率高且可移植性好
C. 邊翻譯邊執行,用戶程序運行效率低且可移植性好
D. 先翻譯后執行,用戶程序運行效率高且可移植性差 ?
📌 正確答案:D
🔍 詳細解析
-
編譯器的核心特性
-
工作方式:先翻譯后執行(與解釋器的邊翻譯邊執行對立)。
-
運行效率:高(直接執行優化后的機器碼,無需運行時翻譯)。
-
可移植性:差(生成的目標代碼依賴特定硬件和操作系統)。
-
-
關鍵概念澄清
特性 編譯器 解釋器 可移植性 ? 差(目標代碼平臺相關) ?? 好(源碼跨平臺通用) 效率 ?? 高(靜態優化) ? 低(動態翻譯開銷) 典型代表 C/C++、Go Python、JavaScript -
為什么可移植性差?
-
編譯器生成的機器碼直接面向 特定CPU架構(如x86、ARM)和 操作系統(如Windows、Linux)。
-
若更換平臺,必須 重新編譯源碼(如Windows的.exe文件不能在Linux直接運行)。
-
-
反例驗證
-
Java的例外:
- Java編譯器生成字節碼(.class),由JVM解釋執行,屬于混合模式,其可移植性依賴JVM而非編譯器本身。
-
交叉編譯:
- 雖能生成不同平臺的目標代碼,但本質上仍針對特定平臺,不改變編譯器本身的移植性缺陷。
-
🚀 記憶技巧
-
編譯器:“高效但綁死平臺”。
-
解釋器:“靈活但跑得慢”。
🖥? 題目22:程序設計語言 - 語法分析方法分類
對高級語言源程序進行編譯或解釋的過程中需要進行語法分析,遞歸子程序分析屬于 (22) 的分析法。
(22)
A. 自上而下 ?
B. 自下而上
C. 從左至右
D. 從右至左
📌 正確答案:A
🔍 詳細解析
-
遞歸子程序分析法的本質
-
自上而下(Top-down):
-
從文法開始符號出發,逐步推導出輸入串(即“從根到葉”構建語法樹)。
-
遞歸子程序法是典型的自上而下分析,每個非終結符對應一個遞歸函數。
-
-
-
關鍵特點
分析方法 方向 代表算法 遞歸子程序法歸屬 自上而下 根 → 葉 遞歸下降、LL(1) ?? 屬于此類 自下而上 葉 → 根 LR(1)、SLR、LALR ?
🖥? 題目23:計算機系統 - 進程調度方式
在計算機系統中,若 P1 進程正在運行,操作系統強行撤下 P1 進程所占用的 CPU,讓具有更高優先級的進程 P2 運行,這種調度方式稱為 (23) 。
(23)
A. 中斷方式
B. 先進先出方式
C. 可剝奪方式 ?
D. 不可剝奪方式
📌 正確答案:C
🔍 詳細解析
-
可剝奪調度(Preemptive Scheduling)
-
定義:允許操作系統強制暫停當前運行的進程,將CPU分配給優先級更高的進程。
-
本題場景:P1被強行撤下,P2(更高優先級)搶占CPU,是典型的可剝奪調度。
-
-
其他選項分析
選項 調度方式 是否匹配題目場景 A 中斷方式 ? 中斷是外部事件觸發(如I/O完成),與優先級無關。 B 先進先出(FIFO) ? 按到達順序執行,無優先級搶占。 D 不可剝奪方式 ? 進程主動釋放CPU前不允許搶占(如早期批處理系統)。 -
關鍵對比
調度類型 特點 典型算法 可剝奪 高優先級進程可搶占CPU 優先級調度、RR(時間片輪轉) 不可剝奪 進程運行至完成或阻塞才釋放CPU 非搶占式SJF(短作業優先)
💡 實例說明
-
可剝奪場景:
- P1(低優先級)正在計算時,P2(高優先級)就緒 → 內核立即切換至P2。
-
不可剝奪場景:
- 即使P2優先級更高,也需等待P1主動放棄CPU(如執行I/O操作或結束)。
🖥? 題目24-26:操作系統 - PV操作與進程同步
進程 P1、P2、P3、P4、P5 和 P6 的前趨圖如下所示。
假設用 PV 操作控制這 6 個進程的同步與互斥的程序如下,程序中的空①和空②處應分別為 (24) ,空③和空④應分別為 (25) ,空⑤和空⑥應分別為 (26) 。
(24)
A. V(S1)V(S2)和 P(S2)P(S3)
B. V(S1)P(S2)和 V(S3)P(S4)
C. V(S1)V(S2)和 V(S3)V(S4)?
D. P(S1)P(S2)和 V(S2)V(S3)
(25)
A. V(S3)和 V(S6)V(S7)
B. V(S3)和 V(S6)P(S7)
C. P(S3)和 V(S6)V(S7) ?
D. P(S3)和 P(S6)V(S7)
(26)
A. V(S6)和 P(S7)P(S8)
B. P(S8)和 P(S7)P(S8)
C. P(S8)和 P(S7)V(S8)
D. V(S8)和 P(S7)P(S8)?
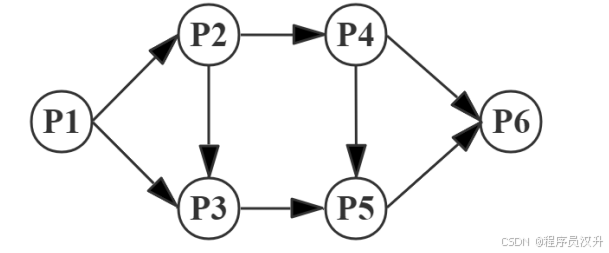
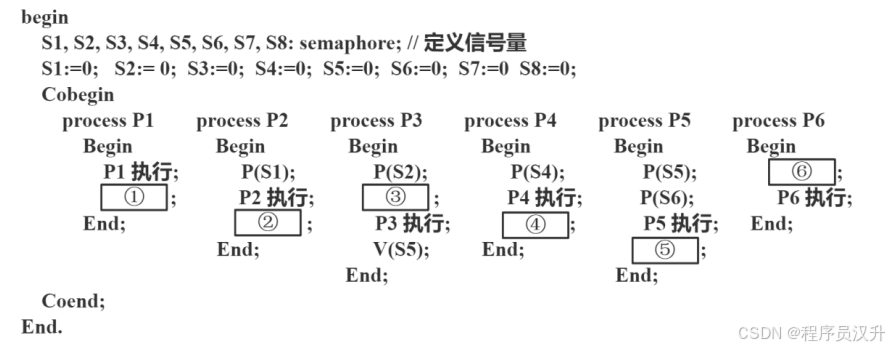
📌 正確答案:(24)C、(25)C、(26)D
🔍 詳細解析
PV詳細解析過程見文章26-28題
詳細流程:
-
P1先執行,釋放S1和S2:題中①是 V(S1) 和 V(S2)-
P2需要S1,所以P2可以執行。 -
P3需要S2但還需要S3,所以P3要等待P2釋放S3。題中③是P(S3)
-
-
P2運行完后,釋放S3和S4:題中②是 V(S1) 和 V(S2)-
P3現在有S2和S3,所以P3可以執行。 -
P4需要S4(來自 P2),所以P4也可以執行。
-
-
P3運行完后,釋放S5:P5現在有S5(P3 釋放的),但是還需要等待S6(P4 釋放的)。
-
P4運行完后,釋放S6和S7:題中④是 P(S6)和 P(S7)-
P5現在有S5(P3 釋放的),也有了S6(P4釋放的)。所以P5可以執行。 -
P6需要S7和S8,但S8需要P5釋放,所以 P6 仍需等待。題中⑥為P(S7)和P(S8)
-
-
P5運行完后,釋放S8:題中⑤為V(S8) -
P6現在有S7(P4釋放的)和S8(P5釋放的),所以P6可以執行。
🖥? 題目27:計算機系統 - 段頁式存儲管理系統地址結構分析
假設段頁式存儲管理系統中的地址結構如下圖所示,則系統 (27) 。
(27)
A. 最多可有 512 個段,每個段的大小均為 2048 個頁,頁的大小為 8K
B. 最多可有 512 個段,每個段最大允許有 2048 個頁,頁的大小為 8K
C. 最多可有 1024 個段,每個段的大小均為 1024 個頁,頁的大小為 4K
D. 最多可有 1024 個段,每個段最大允許有 1024 個頁,頁的大小為 4K?

📌 正確答案:B
🔍 詳細解析
根據圖中地址結構:
- 段號(31-22): 10 位 → 2 10 = 1024 段 10位 → 2^{10} = 1024段 10位→210=1024段
- 頁號(21-12): 10 位 → 2 10 = 1024 頁 10位 → 2^{10} = 1024頁 10位→210=1024頁
- 頁內地址(11-0): 12 位 → 2 12 = 4 K 頁大小 12位 → 2^{12} = 4K頁大小 12位→212=4K頁大小
💽 題目28:計算機硬件基礎知識 - 磁盤文件讀取時間計算
假設磁盤磁頭從一個磁道移至相鄰磁道需要 2ms。文件在磁盤上非連續存放,邏輯上相鄰數據塊的平均移動距離為5個磁道,每塊的旋轉延遲時間及傳輸時間分別為10ms和1ms,則讀取一個 100 塊的文件需要 (28) ms。
(28)
A. 1100
B. 1200
C. 2100 ?
D. 2200
📌 正確答案:C
🔍 詳細解析
-
計算單塊讀取時間
-
尋道時間(Seek Time):
- 平均移動5個磁道 × 2ms/磁道 = 10ms。
-
旋轉延遲(Rotational Latency):
- 固定 10ms(平均半圈時間)。
-
傳輸時間(Transfer Time):
- 固定 1ms。
-
單塊總時間:
10ms(尋道) + 10ms(旋轉) + 1ms(傳輸) = 21ms。
-
-
100塊文件總時間
- 總時間:
100塊 × 21ms/塊 = 2100ms。
- 總時間:
💡 關鍵點
-
非連續存儲:每塊需獨立尋道(連續存儲可減少尋道時間)。
-
旋轉延遲:與磁盤轉速相關,不可優化(除非使用SSD)。
🐍 題目48:程序語言設計 - Python異常處理結構辨析
在 Python3 中, (48) 不是合法的異常處理結構。
(48)
A. try…except…
B. try…except…finally
C. try…catch… ?
D. raise
📌 正確答案:C
🔍 詳細解析
-
Python異常處理語法
-
合法結構:
-
try...except...:捕獲并處理異常。 -
try...except...finally:無論是否異常都執行清理代碼。 -
raise:主動拋出異常。
-
-
非法結構:
try...catch...:Python使用except而非catch(Java/C#風格)。
-
-
選項逐項分析
選項 語法有效性 說明 A ?? 合法 基礎異常捕獲結構(如 try: x=1/0; except ZeroDivisionError: print("error"))。B ?? 合法 finally確保資源釋放(如文件關閉)。C ? 非法 Python無 catch關鍵字,應為except。D ?? 合法 手動觸發異常(如 raise ValueError("invalid"))。 -
代碼示例對比
# 合法(A選項) try:1 / 0 except ZeroDivisionError:print("除零錯誤")# 非法(C選項)→ 實際會報SyntaxError try:1 / 0 catch ZeroDivisionError: # Python不支持catch!print("錯誤") -
為什么catch不合法?
-
歷史原因:Python選擇
except而非catch以保持語法簡潔性。 -
語言差異:
-
Java/C#:
try-catch-finally。 -
Python:
try-except-finally。
-
-
🐍 題目49:程序語言設計 - Python列表切片操作
在 Python3 中,表達式 list(range(11))[10:0:-2] 的值為 (49) 。
(49)
A. [10, 8, 6, 4, 2, 0]
B. [10, 8, 6, 4, 2] ?
C. [0, 2, 4, 6, 8, 10]
D. [0, 2, 4, 6, 8]
📌 正確答案:B
🔍 詳細解析
-
分步拆解表達式
-
range(11):生成序列0, 1, 2, ..., 10。 -
list(range(11)):轉換為列表[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10]。 -
切片
[10:0:-2]:-
start=10:從索引10(值為10)開始。 -
stop=0:到索引0(值為0)結束,不包含0。 -
step=-2:步長為-2(反向每隔1個元素取1次)。
-
-
-
切片結果
按順序選取的索引和值:
-
10 → 值
10 -
10 + (-2) = 8 → 值
8 -
8 + (-2) = 6 → 值
6 -
6 + (-2) = 4 → 值
4 -
4 + (-2) = 2 → 值
2 -
2 + (-2) = 0 → 停止(不包含stop值0)
最終結果:
[10, 8, 6, 4, 2]。 -
-
驗證代碼
print(list(range(11))[10:0:-2]) # 輸出: [10, 8, 6, 4, 2]
🐍 題目50:程序語言設計 - Python的input()函數行為
在 Python3 中,執行語句 x = input(),如果從鍵盤輸入 123 并按回車鍵,則 x 的值為 (50) 。
(50)
A. 123
B. 1,2,3
C. 1 2 3
D. ‘123’ ?
📌 正確答案:D
🔍 詳細解析
-
input()函數的行為-
Python3中:
input()始終返回用戶輸入的 字符串(str)類型,即使輸入的是數字。 -
題目場景:輸入
123后,x的值為字符串'123',而非整數123。
-
-
驗證代碼
x = input() # 輸入123并按回車 print(type(x), x) # 輸出: <class 'str'> 123 -
類型轉換說明
-
若需將輸入轉為整數,需顯式調用
int():x = int(input()) # 輸入123 → x為整數123 -
直接比較:
-
x == 123→False(字符串與整數不相等)。 -
x == '123'→True。
-
-
🗃? 題目51:數據庫設計 - E-R模型向關系模型轉換規則
E-R模型向關系模型轉換時,兩個實體E1和E2之間的多對多聯系R應該轉換為一個獨立的關系模式,且該關系模式的關鍵字由 (51) 組成。
(51)
A. 聯系R的屬性
B. E1或E2的關鍵字
C. E1和E2的關鍵字 ?
D. E1和E2的關鍵字加上R的屬性
📌 正確答案:C
🔍 詳細解析
-
多對多聯系的轉換規則
-
獨立關系模式:多對多聯系(如“學生選課”)需轉換為單獨的表。
-
主鍵構成:由 兩個實體的主鍵組合 作為聯合主鍵(確保唯一性)。
-
-
示例說明
E-R元素 轉換后的關系模式 主鍵 學生(Student) Student(s_id, name) s_id 課程(Course) Course(c_id, title) c_id 選課(Enrollment) Enrollment(s_id, c_id, grade) s_id + c_id(聯合主鍵) -
Enrollment表:
-
主鍵:
s_id(Student的主鍵) +c_id(Course的主鍵)。 -
屬性:
grade是聯系本身的屬性,非主鍵部分。
-
-
-
排除其他選項
選項 錯誤原因 A 聯系R的屬性(如grade)不能唯一標識記錄。 B 僅用一個實體的主鍵無法避免重復(如同一學生選多門課)。 D 主鍵只需實體主鍵,R的屬性應作為普通字段。
🗃? 題目52-53:數據庫設計 - 數據庫范式與函數依賴分析
某高校人力資源管理系統的數據庫中,教師關系模式為 T(教師號,姓名,部門號,崗位,聯系地址,薪資),函數依賴集 F={教師號→(姓名,部門號,崗位,聯系地址),崗位→薪資}。關系模式 T 的主鍵為 (52) ,函數依賴集 F (53) 。
(52)
A. 教師號,T 存在冗余以及插入異常和刪除異常的問題 ?
B. 教師號,T 不存在冗余以及插入異常和刪除異常的問題
C. (教師號,崗位),T 存在冗余以及插入異常和刪除異常的問題
D. (教師號,崗位),T 不存在冗余以及插入異常和刪除異常的問題
(53)
A. 存在傳遞依賴,故關系模式T最高達到1NF
B. 存在傳遞依賴,故關系模式T最高達到2NF ?
C. 不存在傳遞依賴,故關系模式T最高達到3NF
D. 不存在傳遞依賴,故關系模式T最高達到4NF
📌 正確答案:(52)A、(53)B
🔍 詳細解析
-
主鍵確定:
-
函數依賴集F中,教師號→(姓名,部門號,崗位,聯系地址),因此教師號是候選鍵。
-
無其他屬性或屬性組能唯一標識元組,故主鍵為 教師號。
-
-
冗余與異常:
-
傳遞依賴:
教師號→崗位→薪資,導致薪資信息重復存儲(若多個教師同一崗位)。 -
異常示例:
-
插入異常:新增崗位需先有教師(如新設“教授”崗位但未招聘時無法錄入薪資標準)。
-
刪除異常:刪除某崗位的唯一教師會丟失薪資信息(如刪除最后一位“講師”導致該崗位薪資數據消失)。
-
-
-
范式判斷:
-
1NF:屬性不可再分(T顯然滿足)。
-
2NF:滿足1NF,且非主屬性完全依賴主鍵(教師號→薪資為部分依賴?不對,實際是傳遞依賴)。
- 更正:薪資通過崗位傳遞依賴于教師號(教師號→崗位→薪資),故滿足2NF但不滿足3NF。
-
3NF:需消除傳遞依賴(需拆表:T1(教師號,姓名,部門號,崗位,地址) + T2(崗位,薪資))。
-
-
傳遞依賴存在性:
- 教師號 → 崗位 → 薪資,形成傳遞鏈,因此最高達到 2NF。
🗃? 題目54-55:數據庫設計 - 關系代數表達式解析
??(給定員工關系 E(員工號,員工名,部門名,電話,家庭住址)、工程關系 P(工程號,工程名,前期工程號)、參與關系 EP(員工號,工程號,工作量)。查詢“005”員工參與了“虎頭山隧道”工程的員工名、部門名、工程名、工作量的關系代數表達式如下:

📌 正確答案:(54)B、(55)D
🔍 詳細解析
-
目標:從員工關系E中篩選員工號為“005”的記錄。
-
屬性位置:
- E(員工號
1, 員工名2, 部門名3, 電話4, 家庭住址5)。
- E(員工號
-
正確選擇條件:
- 員工號是第1個屬性 → σ 1 = ′ 00 5 ′ ( E ) σ_{1='005'}(E) σ1=′005′?(E) 。
-
排除選項:
-
A:錯誤使用第2屬性(員工名)。
-
C/D:錯誤操作關系P(工程表)。
-
-
步驟拆解:
-
篩選工程名:
- P(工程號1, 工程名2, 前期工程號3),工程名是第2屬性 → σ 2 = ′ 虎頭山隧 道 ′ ( P ) σ_{2='虎頭山隧道'}(P) σ2=′虎頭山隧道′?(P)。
-
投影工程號和工程名:
- π 1 , 2 \pi_{1,2} π1,2? 保留工程號和工程名。
-
連接EP表:
- 通過工程號關聯EP表(EP包含員工號和工程號)。
-
-
選項驗證:
-
D選項:
-
先篩選P表中“虎頭山隧道”工程 → σ 2 = ′ 虎頭山隧 道 ′ ( P ) σ_{2='虎頭山隧道'}(P) σ2=′虎頭山隧道′?(P)。
-
投影工程號和工程名 → π 1 , 2 \pi_{1,2} π1,2? 。
-
連接EP表獲取參與該工程的員工信息。
-
-
💡 知識點分析
最后的公式如下面所示:
π 2 , 3 , 5 , 6 ( π 1 , 2 , 3 ( σ 1 = ′ 00 5 ′ ( E ) ) ? π 1 , 2 ( σ 2 = ′ 虎頭山隧 道 ′ ( P ) ) ? E P ) \pi_{2,3,5,6}(\pi_{1,2,3}(σ_{1='005'}(E))?\pi_{1,2}(σ_{2='虎頭山隧道'}(P))?EP) π2,3,5,6?(π1,2,3?(σ1=′005′?(E))?π1,2?(σ2=′虎頭山隧道′?(P))?EP)
下面來詳細說說他的過程:
- π 1 , 2 , 3 ( σ 1 = ′ 00 5 ′ ( E ) \pi_{1,2,3}(σ_{1='005'}(E) π1,2,3?(σ1=′005′?(E) 表示從員工關系E(員工號1, 員工名2, 部門名3, 電話4, 家庭住址5)中根據
員工號="005"查出前三個屬性,即員工號1, 員工名2, 部門名3 - π 1 , 2 ( σ 2 = ′ 虎頭山隧 道 ′ ( P ) \pi_{1,2}(σ_{2='虎頭山隧道'}(P) π1,2?(σ2=′虎頭山隧道′?(P)表示從工程關系 P(工程號1,工程名2,前期工程號3)中根據
工程名="虎頭山隧道"查出前兩個數據,即工程號1,工程名2 - ? E P ?EP ?EP 表示通過參與關系 EP(員工號1,工程號2,工作量3)將E和P關聯起來,即 π 2 , 3 , 5 , 6 ( 員工號 1 , 員工名 2 , 部門名 3 , 工程號 4 , 工程名 5 , 工作量 6 ) \pi_{2,3,5,6}(員工號1, 員工名2, 部門名3,工程號4,工程名5,工作量6) π2,3,5,6?(員工號1,員工名2,部門名3,工程號4,工程名5,工作量6)
- 最后取集合中
2,3,5,6屬性,得到員工名, 部門名,工程名,工作量
🏦 題目56:數據庫事務 - 數據庫故障類型辨析
假設事務程序 A 中的表達式 x/y,若 y 取值為 0,則計算該表達式時,會產生故障。該故障屬于 (56) 。
(56)
A. 系統故障
B. 事務故障 ?
C. 介質故障
D. 死機
📌 正確答案:B
🔍 詳細解析
-
故障類型定義
故障類型 原因 典型場景 事務故障 事務內部邏輯錯誤(如除零) 除零、死鎖、違反約束 系統故障 硬件/軟件崩潰(如斷電) 內存丟失、操作系統崩潰 介質故障 存儲設備損壞(如磁盤故障) 磁頭損壞、數據文件不可讀 死機 系統無響應(廣義系統故障) CPU過載、死循環 -
題目場景分析
-
故障原因:事務程序中的表達式
x/y因y=0拋出異常(如ZeroDivisionError)。 -
故障范圍:僅影響當前事務(事務A),不破壞系統整體或其他事務。
-
歸類依據:由事務內部邏輯錯誤引發,屬于 事務故障。
-
💡 事務故障處理
恢復機制:
-
事務回滾(UNDO):撤銷故障事務的所有修改。
-
日志記錄:通過日志(如WAL)恢復一致性狀態。
🧮 題目57:數據結構 - 棧的出棧序列可能性分析
設棧初始時為空,對于入棧序列 1, 2, 3, …, n,這些元素經過棧之后得到出棧序列 P?, P?, P?, …, P? 。若 P?=4,則 P?, P? 不可能的取值為 (57) 。
(57)
A. 6,5
B. 2,3
C. 3,1?
D. 3,5
📌 正確答案:C
🔍 詳細解析
-
已知條件與約束
-
入棧序列:1, 2, 3, …, n(按順序入棧)。
-
出棧序列:P?, P?, P?, …, P?,且 P?=4。
-
棧的特性:后進先出(LIFO),任意時刻可入棧或出棧。
-
-
推理步驟
-
P?=4 的含義:
-
元素4在第3個位置出棧 → 在4出棧前,必須已入棧1, 2, 3且它們未全部出棧(否則4無法留在棧中)。
-
關鍵結論:P?和P?只能是 已入棧且已出棧的元素,即1, 2, 3中未被P?和P?選中的元素需留在棧中,直到4出棧。
-
-
逐選項驗證:
選項 P?, P? 可行性分析 結論 A 6, 5 需先入棧1-6,出棧6和5后棧頂為4(P?=4)。但入棧序列未說明n≥6,假設n足夠大則可能。 可能 B 2, 3 入棧1,2 → 出棧2;入棧3 → 出棧3;入棧4 → 出棧4(P?=4)。 可能 C 3, 1 入棧1,2,3 → 出棧3;出棧1(需2已出棧,矛盾)。實際操作:1,2,3入棧 → 出棧3 → 出棧2 → 出棧1 → 入棧4 → 出棧4(P?=4)。但此時P?=2,非1。 矛盾點:若P?=1,需先彈出2,但2未在P?或P?中。 不可能 D 3, 5 入棧1,2,3 → 出棧3;入棧4,5 → 出棧5。此時棧頂為4(P?=4),出棧4(P?=4)。 可能
-
🌳 題目58:數據結構 - 二叉樹中序遍歷順序分析
設 m 和 n 是某二叉樹上的兩個結點,中序遍歷時,n 排在 m 之前的條件是 (58) 。
(58)
A. m 是 n 的祖先結點
B. m 是 n 的子孫結點
C. m 在 n 的左邊
D. m 在 n 的右邊 ?
📌 正確答案:D
🔍 詳細解析
關于二叉樹遍歷詳細講解可見文章《二叉樹的層序遍歷、前序遍歷,中序遍歷、后續遍歷》
-
中序遍歷(LNR)的特性
-
遍歷順序:左子樹 → 根結點 → 右子樹。
-
關鍵結論:對于任意兩個結點,n 在 m 之前被訪問的條件是:
-
n 在 m 的左子樹中,或
-
m 在 n 的右子樹中(即 n 是 m 的祖先且 m 在 n 的右側)。
-
-
-
選項逐項分析
選項 描述 是否滿足 n 在 m 前 反例/驗證 A m 是 n 的祖先 ? 若 m 是 n 的父結點且 n 是右孩子,中序遍歷 n 在 m 后。 B m 是 n 的子孫 ? 若 m 是 n 的右子孫,中序遍歷 n 在 m 前。 C m 在 n 的左邊 ? 若 m 在 n 的左兄弟子樹中,n 在 m 前。 D m 在 n 的右邊 ? m 在 n 的右子樹 ? n 在 m 前(中序遍歷先左后根再右)。
🏗? 題目59:數據結構 - 無向圖的鄰接矩陣存儲空間分析
若無向圖 G 有 n 個頂點 e 條邊,則 G 采用鄰接矩陣存儲時,矩陣的大小為 (59) 。
(59)
A. n × e
B. n2 ?
C. n2 + e2
D. (n + e)2
📌 正確答案:B
🔍 詳細解析
-
鄰接矩陣的結構
-
矩陣維度:鄰接矩陣是一個
n × n的方陣,其中n是頂點數。 -
矩陣元素:
-
若頂點
i和j之間有邊,則A[i][j] = 1(或邊的權重)。 -
若無邊,則
A[i][j] = 0。
-
-
-
空間復雜度
-
矩陣大小:固定為
n2,與邊數e無關。- 無向圖優化:由于對稱性,可壓縮存儲為
n(n+1)/2,但題目未說明優化,默認完整矩陣。
- 無向圖優化:由于對稱性,可壓縮存儲為
-
示例:
- 3個頂點的無向圖 → 3×3矩陣(9個元素)。
-
-
排除其他選項
選項 錯誤原因 A 混淆了鄰接矩陣與鄰接表的存儲方式(鄰接表空間為 n + e)。 C/D 無意義組合,鄰接矩陣大小僅與頂點數相關。
💡 鄰接矩陣 vs 鄰接表
| 存儲方式 | 空間復雜度 | 適用場景 |
|---|---|---|
| 鄰接矩陣 | O(n2) | 稠密圖(邊數接近n2) |
| 鄰接表 | O(n + e) | 稀疏圖(邊數遠小于n2) |
-
有如下無向圖,求鄰接矩陣與鄰接表
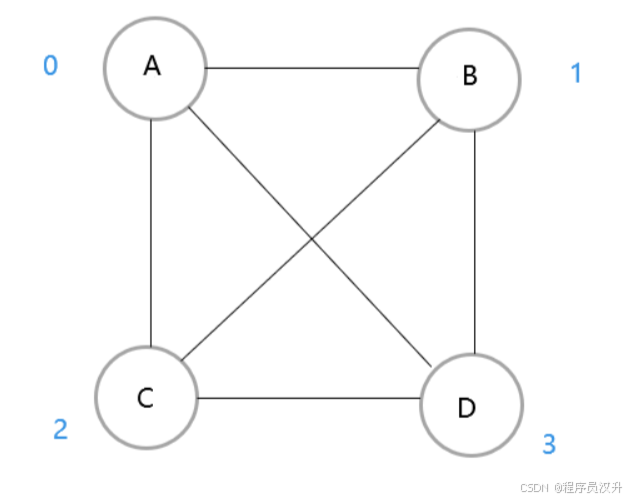
-
其鄰接表表示如下:
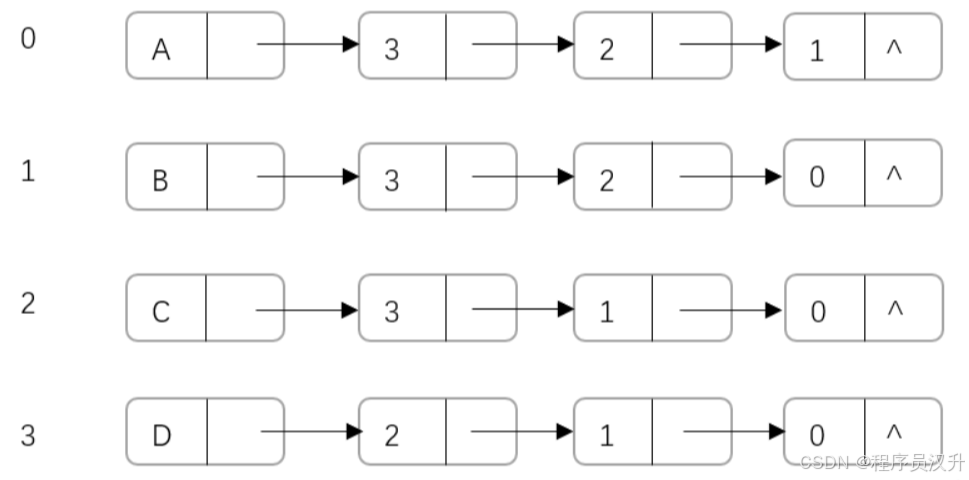
-
其鄰接矩陣表示如下:
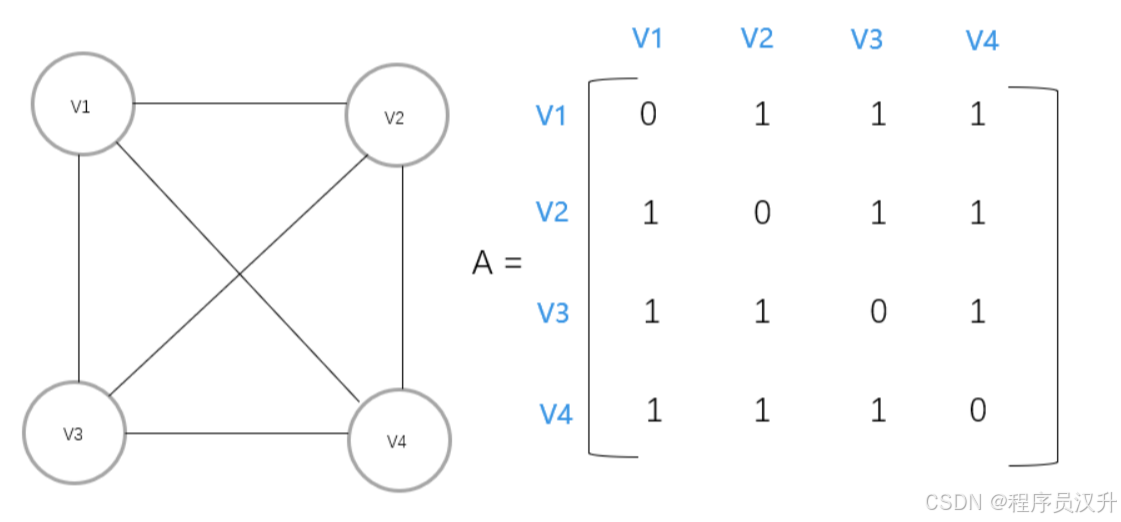
-
-
有如下有向圖,求鄰接矩陣與鄰接表
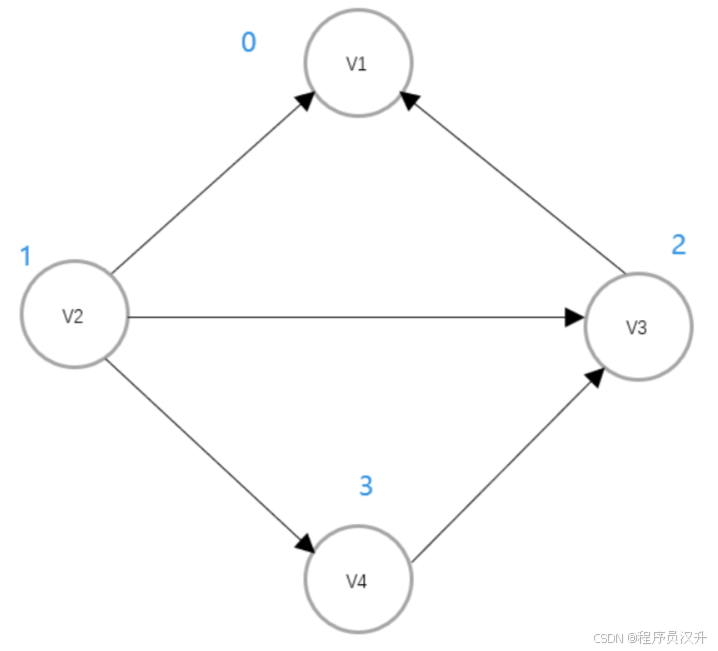
-
其鄰接表表示如下:
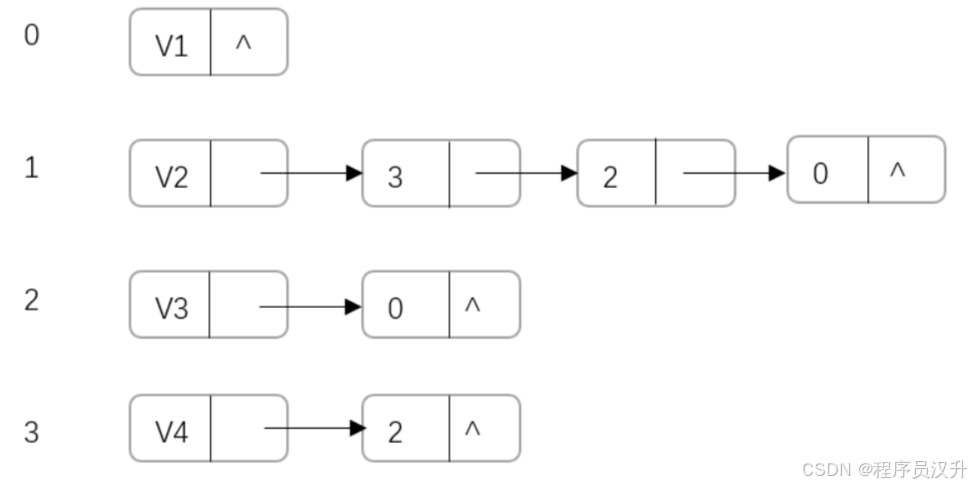
-
其鄰接矩陣表示如下:
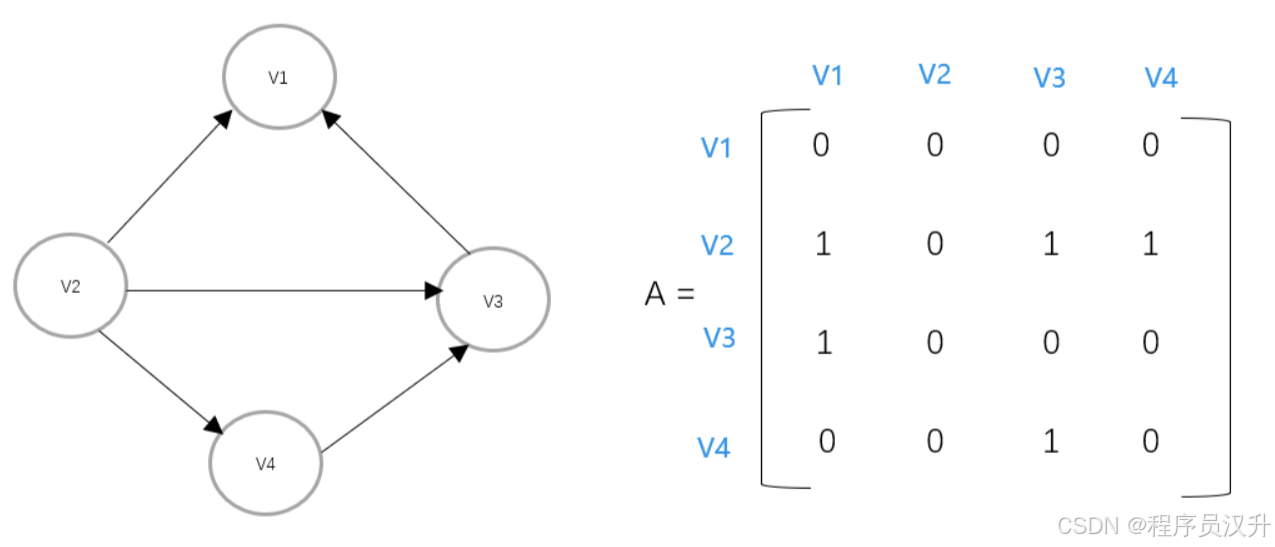
-
🌳 題目60:數據結構 - B-樹特性辨析
以下關于 m 階 B-樹的說法中,錯誤的是 (60) 。
(60)
A. 根結點最多有 m 棵子樹
B. 所有葉子結點都在同一層次上
C. 結點中的關鍵字有序排列
D. 葉子結點通過指針鏈接為有序表 ?
📌 正確答案:D
🔍 詳細解析
-
B-樹的核心特性
特性 描述 題目選項 子樹數量 根結點:至少2棵子樹(若非葉子),最多m棵;非根結點:?m/2?到m棵。 A(部分正確) 葉子結點層次 所有葉子位于同一層,保證平衡性。 B(正確) 關鍵字有序性 結點內關鍵字按升序排列,左子樹關鍵字小于當前關鍵字,右子樹大于。 C(正確) 葉子結點指針鏈接 B+樹的葉子結點通過指針鏈接為有序表,B-樹無此特性。 D(錯誤) -
選項D的錯誤性
-
B-樹 vs B+樹:
-
B-樹:關鍵字分布在所有結點,葉子結點不鏈接。
-
B+樹:關鍵字僅存于葉子結點,且葉子通過指針串聯(支持范圍查詢)。
-
-
圖示對比:
B-樹: [根結點] B+樹: [根結點] / | \ / | \ [子結點]...[子結點] [子結點]...[子結點] / \ / \ / \ / \ [葉子][葉子]...[葉子] [葉子]?[葉子]?...(鏈表鏈接)
-
🏆 題目61:數據結構與算法 - 排序算法輔助空間復雜度比較
下列排序算法中,占用輔助存儲空間最多的是 (61) 。
(61)
A. 歸并排序 ?
B. 快速排序
C. 堆排序
D. 冒泡排序
📌 正確答案:A
🔍 詳細解析
-
各排序算法的空間復雜度
算法 輔助空間復雜度 原因 歸并排序 O(n) 需額外空間存儲合并后的有序序列(遞歸或迭代均需線性空間)。 快速排序 O(log n) ~ O(n) 遞歸棧空間(最壞情況退化為O(n))。 堆排序 O(1) 原地排序,僅需常數空間交換元素。 冒泡排序 O(1) 原地排序,僅需常數空間交換相鄰元素。 -
為什么歸并排序空間占用最多?
-
合并操作:每次合并兩個子數組需臨時數組存儲結果,空間與輸入規模成正比。
-
遞歸開銷:遞歸實現的隱式棧空間(O(log n))疊加顯式合并空間(O(n)),總空間仍為O(n)。
-
-
其他算法對比
-
快速排序:
-
平均遞歸深度O(log n),最壞(如已排序數組)O(n)。
-
但題目問“最多”,歸并排序的O(n)始終高于快排的平均情況。
-
-
堆排序與冒泡排序:
- 均為原地排序,空間復雜度O(1)。
-
💡 示例說明
import java.util.Arrays;public class MergeSort {public static void main(String[] args) {int[] arr = {38, 27, 43, 3, 9, 82, 10};System.out.println("Original array: " + Arrays.toString(arr));int[] sortedArr = mergeSort(arr);System.out.println("Sorted array: " + Arrays.toString(sortedArr));}public static int[] mergeSort(int[] arr) {if (arr.length <= 1) {return arr;}int mid = arr.length / 2;int[] left = Arrays.copyOfRange(arr, 0, mid);int[] right = Arrays.copyOfRange(arr, mid, arr.length);return merge(mergeSort(left), mergeSort(right));}private static int[] merge(int[] left, int[] right) {int[] result = new int[left.length + right.length];int i = 0, j = 0, k = 0;while (i < left.length && j < right.length) {if (left[i] <= right[j]) {result[k++] = left[i++];} else {result[k++] = right[j++];}}while (i < left.length) {result[k++] = left[i++];}while (j < right.length) {result[k++] = right[j++];}return result;}
}
🧩 題目62-63:數據結構與算法 - 折半查找算法策略與平均比較次數
??折半查找在有序數組 A 中查找特定的記錄 K:通過比較 K 和數組中的中間元素 A[mid] 進行比較,如果相等,則算法結束;如果 K 小于 A[mid],則對數組的前半部分進行折半查找;否則對數組的后半部分進行折半查找。根據上述描述,折半查找采用了 (62) 算法設計策略。對有序數組(3,14,27,39,42,55,70,85,93,98),成功查找和失敗查找所需要的平均比較次數分別是 (63) (假設查找每個元素的概率是相同的)。
(62)
A. 分治 ?
B. 動態規劃
C. 貪心
D. 回溯
(63)
A. 29/10 和 29/11
B. 30/10 和 30/11
C. 29/10 和 39/11 ?
D. 30/10 和 40/11
📌 正確答案:(62)A、(63)C
🔍 詳細解析
-
分治法:將問題分解為子問題(如折半查找每次將數組分為兩部分),遞歸解決后合并結果(此處無需合并)。
-
對比其他策略:
-
動態規劃:解決重疊子問題(如斐波那契數列)。
-
貪心:局部最優解(如Dijkstra算法)。
-
回溯:試錯+回退(如N皇后問題)。
-
-
成功查找的平均比較次數(保持不變)
-
判定樹結構:
42/ \27 85/ \ / \14 39 55 93/ \ / \ / \ / \3 * * * * * 70 * 98 -
成功比較次數:
-
42:1次
-
27, 85:2次
-
14, 39, 55, 93:3次
-
3, 70, 98:4次
-
總和:1 + 2×2 + 3×4 + 4×3 = 29
-
平均:29 / 10 = 29/10
-
-
-
失敗查找的平均比較次數
-
有序數組(3,14,27,39,42,55,70,85,93,98)
-
失敗位置數量:
n+1=11(10個元素對應11個外部空位)。 -
失敗路徑比較次數:
失敗路徑區間 深度 比較數據 比較次數 <34 小于根節點42,小于27,小于14,小于3 4 3-14 4 小于根節點42,小于27,小于14,大于3 4 14-27 3 小于根節點42,小于27,大于14 3 27-39 3 小于根節點42,大于27,小于39 3 39-42 3 小于根節點42,大于27,大于39 3 42-55 3 大于根節點42,小于85,小于55 3 55-70 4 大于根節點42,小于85,大于55,小于70 4 70-85 4 大于根節點42,小于85,大于55,大于70 4 85-93 3 大于根節點42,大于85,小于93 3 93-98 4 大于根節點42,大于85,大于93,小于98 4 >984 大于根節點42,大于85,大于93,大于98 4 -
總和:3×5 + 4×6 = 12 + 28 = 39
-
平均:39 / 11
-
🚀 題目64-65:數據結構與算法 - Dijkstra算法策略與最短路徑計算
采用 Dijkstra 算法求解下圖 A 點到 E 點的最短路徑,采用的算法設計策略是 (64) 。該最短路徑的長度是 (65) 。
(64)
A. 分治法
B. 動態規劃
C. 貪心算法 ?
D. 回溯法
(65)
A. 5 ?
B. 6
C. 7
D. 9
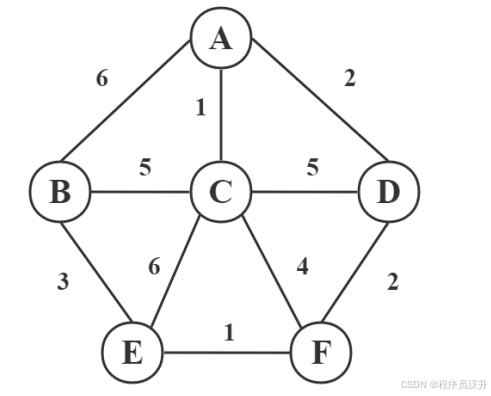
📌 正確答案:(64)C、(65)A
🔍 詳細解析
Dijkstra算法詳解
-
貪心算法:Dijkstra 每次選擇當前未處理的、距離起點最近的結點(局部最優),逐步擴展到全局最優。
-
對比其他策略:
-
分治法:將問題分解為獨立子問題(如歸并排序)。
-
動態規劃:解決重疊子問題(如Floyd算法)。
-
回溯法:試錯+回退(如N皇后問題)。
-
🔍 分步計算
-
初始化:
設距離數組
dist,將 A 到自身距離設為 0,即dist[A]=0,到其他點距離設為無窮大。設集合S存儲已確定最短路徑的點,初始S = {A}。 -
迭代過程:
- 第一次迭代:A 的鄰接點有B、C、D,
dist[B] = min(dist[B], 6)=6,dist[C] = min(dist[C], 1)=1,dist[D]=min(dist[D], 2)=2,更新后dist = {A:0, B:6, C:1, D:2, E:∞, F:∞},選擇距離最小的 C 加入S,此時S = {A, C}。 - 第二次迭代:C 的鄰接點 B、E、F、D,
dist[B]=min(dist[B], 1 + 5)=6,dist[E]=min(dist[E], 1+6)=7,dist[F]=min(dist[F], 1 + 4)=5,dist[D]=min(dist[D], 1 + 5)=2,更新后dist = {A:0, B:6, C:1, D:2, E:7, F:5},選擇距離最小的 D 加入S,此時S = {A, C, D}。 - 第三次迭代:D 的鄰接點 F,
dist[F]=min(dist[F], 2+2)=4,更新后dist = {A:0, B:6, C:1, D:2, E:7, F:4},選擇 F 加入S,此時S = {A, C, D, F}。 - 第四次迭代:F 的鄰接點 E,
dist[E]=min(dist[E], 4+1)=5,更新后dist = {A:0, B:6, C:1, D:2, E:5, F:4},選擇 E 加入S,此時S = {A, C, D, F, E}。 - 第五次迭代:E 的鄰接點 B,
dist[B]=min(dist[B], 5+3)=6,此時S = {A, C, D, F, E, B},迭代結束。
- 第一次迭代:A 的鄰接點有B、C、D,
A 到各點最短路徑長度為:A 到 B 是 6、A 到 C 是 1、A 到 D 是 2、A 到 E 是 5、A 到 F 是 4 。
🌐 題目66:計算機網絡 - VLAN Tag在OSI模型中的位置
VLAN tag 在 OSI 參考模型的 (66) 實現。
(66)
A. 網絡層
B. 傳輸層
C. 數據鏈路層 ?
D. 物理層
📌 正確答案:C
🔍 詳細解析
-
VLAN Tag的作用與位置
-
功能:VLAN(虛擬局域網)標簽用于在以太網幀中標識數據包所屬的虛擬網絡,實現二層網絡的邏輯隔離。
-
OSI層歸屬:
-
數據鏈路層(Layer 2):VLAN Tag 嵌入在以太網幀頭中(如IEEE 802.1Q標準),修改幀結構但不影響上層(網絡層及以上)。
-
典型字段:4字節的Tag包含VLAN ID(12位)、優先級(3位)等。
-
-
-
排除其他選項
| 選項 | OSI層 | 不匹配原因 |
|---|---|---|
| A | 網絡層(Layer 3) | 處理IP路由,與幀標識無關。 |
| B | 傳輸層(Layer 4) | 管理端到端連接(如TCP/UDP),與網絡分段無關。 |
| D | 物理層(Layer 1) | 負責比特流傳輸,不解析幀結構。 |
-
技術對比
-
VLAN vs 子網:
-
VLAN:數據鏈路層隔離(基于MAC地址和標簽)。
-
子網:網絡層隔離(基于IP地址)。
-
-
🌐 題目67:計算機網絡 - Telnet協議特性辨析
Telnet 協議是一種 (67) 遠程登錄協議。
(67)
A. 安全
B. B/S 模式
C. 基于 TCP ?
D. 分布式
📌 正確答案:C
🔍 詳細解析
-
Telnet的核心特性
-
基于TCP:Telnet 使用 TCP端口 23 提供可靠的面向連接服務,確保數據有序傳輸。
-
非安全:所有數據(包括密碼)以明文傳輸,易被竊聽(SSH 是其安全替代方案)。
-
C/S 模式:客戶端/服務器架構,非 B/S(瀏覽器/服務器)。
-
非分布式:單點登錄到遠程主機,無分布式協作功能。
-
-
協議對比
| 協議 | 傳輸層 | 安全性 | 主要用途 |
|---|---|---|---|
| Telnet | TCP | 無加密 | 遠程命令行管理(逐漸淘汰) |
| SSH | TCP | 加密 | 安全的遠程登錄與文件傳輸 |
| HTTP | TCP | 可選加密 | 網頁瀏覽(B/S 模式) |
🔒 題目68:計算機網絡 - HTTPS與HTTP協議辨析
以下關于 HTTPS 和 HTTP 協議的敘述中,錯誤的是 (68) 。
(68)
A. HTTPS 協議使用加密傳輸
B. HTTPS 協議默認服務端口號是 443
C. HTTP 協議默認服務端口號是 80
D. 電子支付類網站應使用 HTTP 協議 ?
📌 正確答案:D
🔍 詳細解析
| 選項 | 正誤 | 說明 |
|---|---|---|
| A | ?? 正確 | HTTPS 通過 SSL/TLS 加密數據,保護傳輸安全(如 AES、RSA 算法)。 |
| B | ?? 正確 | HTTPS 默認端口 443,HTTP 默認端口 80。 |
| C | ?? 正確 | HTTP 明文傳輸,端口 80 是國際標準。 |
| D | ? 錯誤 | 電子支付必須使用 HTTPS,HTTP 的明文傳輸會導致敏感信息(如銀行卡號)泄露。 |
🌐 題目69:計算機網絡 - 域名解析
將網址轉換為 IP 地址要用 (69) 協議。
(69)
A. 域名解析 ?
B. IP 地址解析
C. 路由選擇
D. 傳輸控制
📌 正確答案:A
🔍 詳細解析
| 選項 | 協議名稱 | 功能描述 | 是否符合將網址轉換為 IP 地址的功能 |
|---|---|---|---|
| A | 域名解析(DNS)協議 | 將域名(網址)轉換為對應的 IP 地址 | 是 |
| B | 地址解析協議(ARP) | 將 IP 地址解析為 MAC 地址,用于局域網內數據鏈路層尋址 | 否 |
| C | 路由選擇協議(如 RIP、OSPF 等) | 在網絡中尋找數據包從源到目的的最佳傳輸路徑 | 否 |
| D | 傳輸控制協議(TCP) | 提供可靠的、面向連接的數據傳輸服務,負責數據分段、重組、流量控制等 | 否 |
🌐 題目70:計算機網絡 - IP 地址和 MAC 地址
以下關于 IP 地址和 MAC 地址說法錯誤的是 (70) 。
(70)
A. IP 地址長度 32 或 128 位,MAC 地址的長度 48 位
B. IP 地址工作在網絡層,MAC 地址工作在數據鏈路層
C. IP 地址的分配是基于網絡拓撲,MAC 地址的分配是基于制造商
D. IP 地址具有唯一性,MAC 地址不具有唯一性?
📌 正確答案:D
🔍 詳細解析
| 選項 | 描述 | 正誤判斷 | 原因 |
|---|---|---|---|
| A | IP 地址長度 32 或 128 位,MAC 地址的長度 48 位 | 正確 | IPv4 地址是 32 位,IPv6 地址是 128 位,MAC 地址固定為 48 位 |
| B | IP 地址工作在網絡層,MAC 地址工作在數據鏈路層 | 正確 | 網絡層使用 IP 地址進行邏輯尋址,數據鏈路層依靠 MAC 地址實現設備間的數據傳輸 |
| C | IP 地址的分配是基于網絡拓撲,MAC 地址的分配是基于制造商 | 正確 | IP 地址根據網絡拓撲和子網劃分進行分配,MAC 地址由制造商按 IEEE 規定燒錄到設備中 |
| D | IP 地址具有唯一性,MAC 地址不具有唯一性 | 錯誤 | IP 地址在其所屬網絡范圍內需唯一,MAC 地址由 IEEE 管理分配,全球范圍內基本唯一,用于唯一標識設備 |
二、 系統開發和運行知識 🗃?
🛠? 題目15:系統開發 - 加工規格說明的描述方法選擇
某零件廠商的信息系統中,一個基本加工根據客戶類型、訂單金額、客戶信用等信息的不同采取不同的行為,此時最適宜采用 (15) 來描述該加工規格說明。
(15)
A. 自然語言
B. 流程圖
C. 判定表 ?
D. 某程序設計語言
📌 正確答案:C
🔍 詳細解析
-
判定表的優勢
-
多條件組合決策:
題目中涉及客戶類型、訂單金額、信用等級等多個條件的交叉判斷,判定表能以表格形式清晰列出所有可能的條件組合及對應動作。 -
避免二義性:
自然語言(選項A)易產生歧義,而判定表通過結構化表達確保邏輯嚴密性。
-
-
其他選項的局限性
選項 適用場景 本題缺陷 A. 自然語言 簡單規則描述 復雜條件組合時表述冗長且易遺漏分支。 B. 流程圖 線性流程控制 難以直觀展示多維度條件的并行判斷。 D. 程序設計語言 代碼實現 屬于實現階段工具,非需求分析階段的規格說明。 -
判定表示例
| 客戶類型 | 訂單金額 | 客戶信用 | 動作 |
|---|---|---|---|
| VIP | ≥10,000 | 良好 | 免運費+折扣10% |
| VIP | <10,000 | 良好 | 免運費 |
| 普通 | ≥5,000 | 良好 | 折扣5% |
| (其他組合) | … | … | 默認處理 |
🧩 題目16:系統開發 - 模塊結構優化的錯誤方法
優化模塊結構時, (16) 不是適當的處理方法。
(16)
A. 使模塊功能完整
B. 消除重復功能,改善軟件結構
C. 只根據模塊功能確定規模大小?
D. 避免或減少模塊之間的病態連接
📌 正確答案:C
🔍 詳細解析
-
模塊設計的基本原則
-
高內聚低耦合:模塊內部功能緊密相關,模塊間依賴最小化。
-
功能完整性(選項A):每個模塊應獨立完成特定功能(如用戶認證模塊包含密碼加密、驗證等完整流程)。
-
消除冗余(選項B):重復代碼會增加維護成本(如多個模塊實現相同日志功能)。
-
連接健康性(選項D):病態連接(如循環依賴、全局變量濫用)會降低可維護性。
-
-
選項C的問題
-
單一依據的局限性:
-
僅按功能確定模塊規模,可能忽視 復雜度(如一個“訂單處理”功能可能需拆分為創建、支付、物流等子模塊)。
-
忽略 團隊協作(過大模塊導致多人修改沖突)和 性能(高頻功能需獨立優化)。
-
-
🗺? 題目17-18:系統開發 - 關鍵路徑分析
下圖是一個軟件項目的活動圖,其中頂點表示項目里程碑,連接頂點的邊表示包含的活動,邊上的數字表示完成該活動所需要的天數。則關鍵路徑長度為 (17) 。若在實際項目進展中,在其他活動都能正常進行的前提下,活動 (18) 一旦延期就會影響項目的進度。
(17)
A. 34
B. 47
C. 54
D. 58?
(18)
A. A→B
B. C→F ?
C. D→F
D. F→H
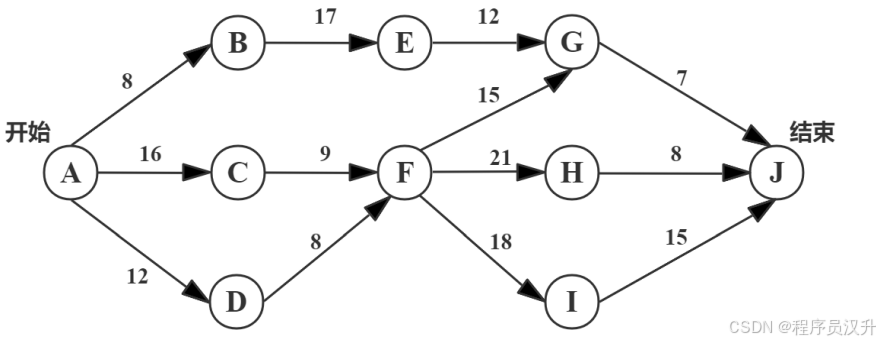
📌 正確答案:(17)D、(18)B
🔍 詳細解析
首先附上mermaid圖:
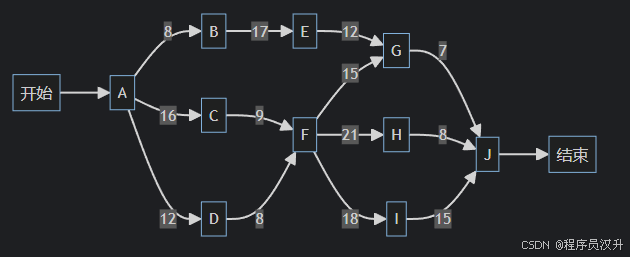
步驟1:列出所有路徑及長度
根據提供的 活動圖(AOV網),推導所有可能路徑及其總天數:
| 路徑 | 計算過程 | 總天數 |
|---|---|---|
| Start → A → B → E → G → J → End | 8 + 17 + 12 + 7 + 0 = 44 | 44 |
| Start → A → C → F → G → J → End | 16 + 9 + 15 + 7 + 0 = 47 | 47 |
| Start → A → C → F → H → J → End | 16 + 9 + 21 + 8 + 0 = 54 | 54 |
| Start → A → C → F → I → J → End | 16 + 9 + 18 + 15 + 0 = 58 | 58 |
| Start → A → D → F → G → J → End | 12 + 8 + 15 + 7 + 0 = 42 | 42 |
| Start → A → D → F → H → J → End | 12 + 8 + 21 + 8 + 0 = 49 | 49 |
| Start → A → D → F → I → J → End | 12 + 8 + 18 + 15 + 0 = 53 | 53 |
關鍵路徑:最長路徑為 Start → A → C → F → I → J → End,總天數 58。
步驟2:識別關鍵活動
關鍵活動是關鍵路徑上的邊(一旦延期會影響總工期):
-
A → C(16天)
-
C → F(9天)
-
F → I(18天)
-
I → J(15天)
選項中匹配的關鍵活動是 C → F (B選項)。
📊 題目19:軟件開發項目管理 - 風險管理原則辨析
以下關于風險管理的敘述中,不正確的是 (19) 。
(19)
A. 承認風險是客觀存在的,不可能完全避免
B. 同時管理所有的風險 ?
C. 風險管理應該貫穿整個項目管理過程
D. 風險計劃本身可能會帶來新的風險
📌 正確答案:B
🔍 詳細解析
-
錯誤敘述分析(選項B)
-
問題:資源有限性決定了無法“同時管理所有風險”。
-
正確做法:應優先管理 高風險項(如高概率高影響),低風險可監控或接受。
-
-
其他選項的正確性
| 選項 | 風險管理原則 |
|---|---|
| A | 風險具有客觀性,只能降低無法消除(如地震對項目的影響)。 |
| C | 風險管理需覆蓋項目全生命周期(啟動、規劃、執行、收尾)。 |
| D | 風險應對措施可能引入次生風險(如外包緩解技術風險但帶來供應商依賴風險)。 |
🏗? 題目29:系統設計方法與模型 - 快速原型模型的優點辨析
以下關于快速原型模型優點的敘述中,不正確的是 (29) 。
(29)
A. 有助于滿足用戶的真實需求
B. 適用于大型軟件系統的開發 ?
C. 開發人員快速開發出原型系統,因此可以加速軟件開發過程,節約開發成本
D. 原型系統已經通過與用戶的交互得到驗證,因此對應的規格說明文檔能正確描述用戶需求
📌 正確答案:B
🔍 詳細解析
-
快速原型模型的核心特點
-
核心目標:通過快速構建原型,早期驗證需求,減少后期變更風險。
-
適用場景:需求不明確、變化頻繁的 中小型項目(如MVP開發、界面演示)。
-
-
選項逐項分析
選項 正誤 說明 A ?? 正確 原型通過用戶交互驗證真實需求(如界面布局、功能流程)。 B ? 不正確 大型系統需嚴格架構設計和文檔,原型難以覆蓋全局復雜度(如操作系統、ERP)。 C ?? 正確 D ?? 正確 已驗證的原型可轉化為精準的需求文檔(避免歧義)。
🏗? 題目30:系統設計 - 三層C/S結構的特性辨析
以下關于三層C/S結構的敘述中,不正確的是 (30) 。
(30)
A. 允許合理劃分三層結構的功能,使之在邏輯上保持相對獨立性,提高系統的可維護性和可擴展性
B. 允許更靈活有效地選用相應的軟硬件平臺和系統
C. 應用的各層可以并發開發,但需要相同的開發語言 ?
D. 利用功能層有效地隔離表示層和數據層,便于嚴格的安全管理
📌 正確答案:C
🔍 詳細解析
-
三層C/S結構的核心特點
-
分層架構:
-
表示層(UI):用戶交互(如Web頁面、桌面客戶端)。
-
功能層(業務邏輯):處理業務規則(如訂單計算、權限驗證)。
-
數據層:數據庫操作(如SQL查詢、NoCRUD)。
-
-
核心優勢:邏輯解耦、平臺靈活性、安全管理。
-
-
選項逐項分析
| 選項 | 正誤 | 說明 |
|---|---|---|
| A | ?? 正確 | 分層設計確保各層獨立(如修改UI不影響數據庫)。 |
| B | ?? 正確 | 各層可異構(如UI用JavaScript,業務層用Java,數據庫用MySQL)。 |
| C | ? 不正確 | 各層無需相同語言(如前端用HTML+JS,后端用Python)。 |
| D | ?? 正確 | 功能層隔離防止直接訪問數據庫(如SQL注入防護)。 |
-
為什么選項C錯誤?
-
跨語言支持:三層架構的核心優勢之一是允許不同技術棧(如.NET后端+React前端)。
-
反例:
-
表示層:Angular(TypeScript)
-
功能層:Spring Boot(Java)
-
數據層:PostgreSQL(SQL)
-
-
💡 三層架構的靈活性
| 層 | 技術選擇示例 | 開發語言獨立性 |
|---|---|---|
| 表示層 | React, Vue, WinForms | 可不同 |
| 功能層 | Node.js, Java EE, .NET Core | 可不同 |
| 數據層 | MySQL, MongoDB, Oracle | 可不同 |
🧩 題目31:系統設計 - 模塊耦合類型辨析
若模塊A和模塊B通過外部變量來交換輸入、輸出信息,則這兩個模塊的耦合類型是 (31) 耦合。
(31)
A. 數據
B. 標記
C. 控制
D. 公共 ?
📌 正確答案:D
🔍 詳細解析
耦合類型定義
-
公共耦合(Common Coupling):
-
多個模塊通過 共享全局變量(外部變量) 交換數據。
-
特點:高耦合度,修改全局變量會影響所有依賴模塊。
-
-
其他選項對比:
耦合類型 特點 示例 數據耦合 通過參數傳遞基本數據類型 func(A int, B float) 標記耦合 通過傳遞數據結構(如結構體) func(user User) 控制耦合 通過參數控制對方邏輯(如標志位) func(enable bool)
🏻 題目32:系統開發 - 軟件高質量標準的理解
軟件開發的目標是開發出高質量的軟件系統,這里的高質量不包括 (32) 。
(32)
A. 軟件必須滿足用戶規定的需求
B. 軟件應遵循規定標準所定義的一系列開發準則
C. 軟件開發應采用最新的開發技術 ?
D. 軟件應滿足某些隱含的需求,如可理解性、可維護性等
📌 正確答案:C
🔍 詳細解析
-
高質量軟件的核心標準
-
功能性(A選項):滿足用戶顯式需求(如業務流程、功能列表)。
-
合規性(B選項):遵循行業標準(如ISO 9126、MISRA C編碼規范)。
-
隱含需求(D選項):可維護性、可擴展性等非功能性需求。
-
-
為什么“最新技術”不是高質量的必要條件?
-
技術中立性:高質量可通過成熟穩定技術實現(如銀行系統常用Java而非最新Rust)。
-
風險考量:新技術可能引入未知風險(如兼容性問題、社區支持不足)。
-
反例:
- 用最新區塊鏈技術開發簡單CMS系統 → 過度設計,反而降低可維護性。
-
🧪 題目33:軟件測試基礎知識 - 白盒測試覆蓋方法的能力對比
白盒測試技術的各種覆蓋方法中, (33) 具有最弱的錯誤發現能力。
(33)
A. 判定覆蓋
B. 語句覆蓋 ?
C. 條件覆蓋
D. 路徑覆蓋
📌 正確答案:B
🔍 詳細解析
-
白盒測試覆蓋方法能力排序
從弱到強的錯誤發現能力:
語句覆蓋 < 判定覆蓋 < 條件覆蓋 < 路徑覆蓋 -
各方法核心特點
覆蓋方法 覆蓋目標 錯誤發現能力 示例(代碼 if (A && B)) 語句覆蓋 每條語句至少執行一次 ? 最弱 測試用例 A=true, B=true(僅驗證語句執行,不驗證邏輯) 判定覆蓋 每個判定(分支)的真假至少一次 ?? 增加 A=false, B=false(覆蓋if-else分支) 條件覆蓋 每個條件的真假至少一次 ??? 分別測試 A=true/false 和 B=true/false 路徑覆蓋 所有可能的執行路徑 ???? 最強 覆蓋 A&&B、A&&!B、!A&&B、!A&&!B
📄 題目34:軟件質量 - 高質量文檔標準的辨析
文檔是軟件的重要因素,關于高質量文檔,以下說法不正確的是 (34) 。
(34)
A. 不論項目規模和復雜程度如何,都要用統一的標準指定相同類型和相同要素的文檔 ?
B. 應該分清讀者對象
C. 應當是完整的、獨立的、自成體系的
D. 行文應十分確切,不出現多義性描述
📌 正確答案:A
🔍 詳細解析
-
高質量文檔的核心原則
原則 說明 對應選項 讀者導向 針對不同讀者(開發者、用戶、測試員)提供適配內容(如API文檔 vs 用戶手冊)。 B 完整性 覆蓋所有必要信息,無需依賴外部補充。 C 無歧義性 使用精準術語,避免模糊表述(如“快速響應”應量化為“響應時間≤2s”)。 D 靈活性 根據項目規模調整文檔詳略(如小型項目可精簡,大型系統需詳細架構設計)。 A的反例 -
為什么選項A錯誤?
-
一刀切的弊端:
- 小型腳本項目無需詳細需求文檔,而航天軟件需嚴格遵循DO-178C文檔標準。
-
反例:
-
創業公司MVP:僅需1頁功能說明。
-
銀行核心系統:需200頁安全合規文檔。
-
-
🧪 題目35:軟件測試基礎知識 - 測試階段與錯誤發現能力
某財務系統的一個組件中,某個變量沒有正確初始化, (35) 最可能發現該錯誤。
(35)
A. 單元測試 ?
B. 集成測試
C. 接受測試
D. 安裝測試
📌 正確答案:A
🔍 詳細解析
- 變量未初始化錯誤的特性
-
錯誤類型:屬于代碼級缺陷(如
int x;未賦初值直接使用)。 -
最佳發現階段:在 單元測試 中通過白盒測試(如語句覆蓋)直接驗證函數內部邏輯。
-
各測試階段的對比
測試階段 測試目標 發現此類錯誤的能力 示例 單元測試 驗證單個函數/類的正確性 ????? 最強 assert(calculate_tax() == 0)集成測試 檢查模塊間交互 ?? 數據庫連接是否正常 接受測試 驗證系統是否滿足用戶需求 ? 財務報表生成功能是否完整 安裝測試 確保軟件在目標環境正常運行 ? 安裝包是否兼容Windows 11 -
為什么單元測試最有效?
-
精準定位:直接測試函數內部變量狀態(如使用調試器檢查內存)。
-
快速反饋:在開發早期即可發現,修復成本低。
-
工具支持:
- JUnit(Java)、pytest(Python)可編寫針對性測試用例
-
🛠? 題目36:系統運行和維護基礎知識 - 軟件維護類型辨析
軟件交付給用戶之后進入維護階段,根據維護具體內容的不同將維護分為不同的類型,其中“采用專用的程序模塊對文件或數據中的記錄進行增加、修改和刪除等操作”的維護屬于 (36) 。
(36)
A. 程序維護
B. 數據維護 ?
C. 代碼維護
D. 設備維護
📌 正確答案:B
🔍 詳細解析
維護類型分類
| 維護類型 | 定義 | 典型場景 |
|---|---|---|
| 數據維護 | 對數據庫、文件中的記錄進行增刪改查(CRUD)操作,不涉及代碼邏輯修改。 | 用戶信息更新、日志數據清理 |
| 程序維護 | 修復代碼缺陷或優化性能(需修改源代碼)。 | Bug修復、算法優化 |
| 代碼維護 | 廣義同程序維護,通常特指重構或技術債務清理。 | 代碼重構、依賴庫升級 |
| 設備維護 | 硬件或系統環境維護(如服務器擴容、網絡配置)。 | 更換數據庫服務器、升級操作系統 |
三、 面向對象基礎知識 🧩
🦆 題目37-38:面向對象 - 面向對象設計概念辨析
采用面向對象方法進行某游戲設計,游戲中有野鴨、紅頭鴨等各種鴨子邊游泳戲水邊呱呱叫,不同種類的鴨子具有不同顏色,設計鴨子類負責呱呱叫和游泳方法的實現,顯示顏色設計為抽象方法,由野鴨和紅頭鴨各自具體實現,這一機制稱為 (37) 。當給這些類型的一組不同對象發送同一顯示顏色消息時,能實現各自顯示自己不同顏色的結果,這種現象稱為 (38) 。
(37)
A. 繼承 ?
B. 聚合
C. 組合
D. 多態
(38)
A. 覆蓋
B. 重載
C. 動態綁定
D. 多態?
📌 正確答案:(37)A、(38)D
🔍 詳細解析
-
繼承(Inheritance):
- 父類(Duck)提供通用方法(游泳、呱呱叫),子類(WildDuck、RedHeadDuck)通過繼承父類并實現抽象方法(顏色)擴展功能。
-
排除其他選項:
-
聚合/組合:描述對象間“擁有”關系(如鴨子擁有翅膀),與題目無關。
-
多態:是下一問的機制,此處強調代碼復用和擴展。
-
-
多態(Polymorphism):
- 同一消息(showColor())引發不同行為(野鴨顯示綠色,紅頭鴨顯示紅色),通過子類重寫父類抽象方法實現。
-
關鍵機制:
-
動態綁定(C選項)是多態的實現技術,但題目問現象名稱,非底層原理。
-
覆蓋(A選項)是多態的實現手段,非現象本身。
-
💡 代碼實現
abstract class Duck {public void swim() { System.out.println("Swimming"); } // 繼承的通用方法public abstract void showColor(); // 抽象方法
}class WildDuck extends Duck {@Overridepublic void showColor() { System.out.println("Green"); } // 多態的具體實現
}class RedHeadDuck extends Duck {@Overridepublic void showColor() { System.out.println("Red"); } // 多態的具體實現
}// 測試多態
public class Main {public static void main(String[] args) {Duck duck1 = new WildDuck();Duck duck2 = new RedHeadDuck();duck1.showColor(); // 輸出 "Green"(動態綁定到WildDuck實現)duck2.showColor(); // 輸出 "Red" (動態綁定到RedHeadDuck實現)}
}
🧩 題目39:面向對象 - 面向對象分析中的對象認定
采用面向對象方法分析時,首先要在應用領域中按自然存在的實體認定對象,即將自然存在的 (39) 作為一個對象。
(39)
A. 問題
B. 關系
C. 名詞 ?
D. 動詞
📌 正確答案:C
🔍 詳細解析
-
面向對象分析(OOA)的核心原則
-
對象認定:從問題域中識別 自然存在的實體,通常對應現實世界的 名詞(如“學生”“訂單”“賬戶”)。
-
示例:
- 電商系統:商品、購物車、用戶。
-
-
選項逐項分析
選項 是否對象 說明 A. 問題 ? 問題是待解決的抽象概念(如“支付失敗”),需拆解為具體對象(如“支付訂單”)。 B. 關系 ? 關系是對象間的交互(如“用戶購買商品”),通過方法或關聯類實現。 C. 名詞 ? 名詞直接映射為對象(如“飛機”“航班”)。 D. 動詞 ? 動詞通常映射為對象的方法(如“飛行”是“飛機”類的方法)。
🧩 題目40:面向對象 - 面向對象設計原則辨析
進行面向對象系統設計時,修改某個類的原因有且只有一個,即一個類只做一種類型的功能,這屬于 (40) 原則。
(40)
A. 單一責任 ?
B. 開放-封閉
C. 接口分離
D. 依賴倒置
📌 正確答案:A
🔍 詳細解析
-
單一責任原則(SRP)
-
定義:一個類應該有且僅有一個引起它變化的原因(即只負責一項功能)。
-
題目匹配:
- “修改類的原因有且只有一個” → 直接對應SRP核心思想。
-
示例:
// 違反SRP:同時處理訂單計算和日志記錄 class OrderProcessor {void calculateTotal() { ... }void logTransaction() { ... } // 應拆分到Logger類 }// 符合SRP class OrderCalculator { void calculateTotal() { ... } } class TransactionLogger { void log() { ... } } -
-
其他原則對比
原則 核心思想 題目關聯性 開放-封閉 對擴展開放,對修改封閉 ? 無關類職責數量 接口分離 客戶端不應依賴不需要的接口 ? 聚焦接口而非類職責 依賴倒置 依賴抽象而非具體實現 ? 關注耦合方向
🏗? 題目41-42:面向對象 - UML活動圖解析
UML 活動圖用于建模 (41) 。以下活動圖中,活動 A1 之后,可能的活動執行序列順序是 (42) 。
(41)
A. 系統在它的周邊環境的語境中所提供的外部可見服務
B. 某一時刻一組對象以及它們之間的關系
C. 系統內從一個活動到另一個活動的流程 ?
D. 對象的生命周期中某個條件或者狀態
(42)
A. A2、A3、A4和A5
B. A3、A4和A5,或A2、A4或A5
C. A2、A4和A5
D. A2或A3、A4和A5 ?
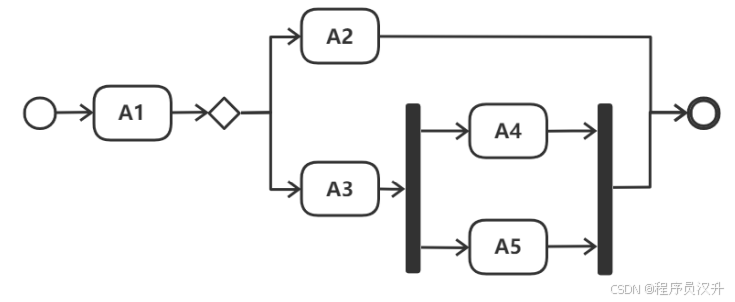
📌 正確答案:(41)D、(42)B
🔍 詳細解析
-
活動圖(Activity Diagram):描述系統內 活動的順序流程(如業務流程、算法步驟),聚焦動態行為。
-
對比其他選項:
-
A:用例圖的用途(描述系統功能)。
-
B:類圖或對象圖的用途(靜態結構)。
-
D:狀態圖的用途(對象狀態變遷)。
-
-
活動圖邏輯:
-
A1完成后,通常通過 分支(Decision Node) 或 并行(Fork) 決定后續路徑。
-
題目未明確分支條件,但選項中 A2和A3是互斥選擇(“或”關系),A4和A5是共同后續。
-
-
合理序列:
-
A1 → A2 → A4 → A5
-
A1 → A3 → A4 → A5
-
-
排除其他選項:
-
A:A2和A3不會同時執行。
-
B:缺少A2→A4→A5的完整路徑。
-
C:遺漏A3的可能性。
-
🏗? 題目43:面向對象 - UML構件圖的特性
UML構件圖(component diagram)展現了一組構件之間的組織和依賴,專注于系統的靜態 (43) 圖,圖中通常包括構件、接口以及各種關系。
(43)
A. 關聯
B. 實現
C. 結構 ?
D. 行為
📌 正確答案:C
🔍 詳細解析
-
核心用途:描述系統的 靜態結構,展示構件(如模塊、庫、可執行文件)及其依賴關系。
-
關鍵元素:
-
構件(Component):如PaymentService.dll。
-
接口(Interface):如IPaymentProcessor。
-
關系:依賴(虛線箭頭)、實現(實線空心三角)。
-
-
靜態 vs 動態:
-
結構圖(如類圖、構件圖):展示系統組成部分及其關系。
-
行為圖(如活動圖、狀態圖):展示系統動態交互。
-
-
題目關鍵詞:“靜態” + “組織和依賴” → 明確指向結構。
🏗? 題目44-46:設計模式 - 設計模式辨析
在某系統中,不同級別的日志信息記錄方式不同,每個級別的日志處理對象根據信息級別高低,采用不同方式進行記錄。每個日志處理對象檢查消息的級別,如果達到它的級別則進行記錄,否則不記錄;然后將消息傳遞給它的下一個日志處理對象。針對此需求,設計如下所示類圖。該設計模式采用 (44) 模式使多個前后連接的對象都有機會處理請求,從而避免請求的發送者和接收者之間的耦合關系。該模式屬于(45)模式,該模式適用于(46)。
(44)
A. 責任鏈(Chain of Responsibility) ?
B. 策略(Strategy)
C. 過濾器(Filter)
D. 備忘錄(Memento)
(45)
A. 行為型類
B. 行為型對象 ?
C. 結構型類
D. 結構型對象
(46)
A. 不同的標準過濾一組對象,并通過邏輯操作以解耦的方式將它們鏈接起來
B. 可處理一個請求的對象集合應被動態指定?
C. 必須保存一個對象在某一個時刻的狀態,需要時它才能恢復到先前的狀態
D. 一個類定義了多種行為,并且以多個條件語句的形式出現
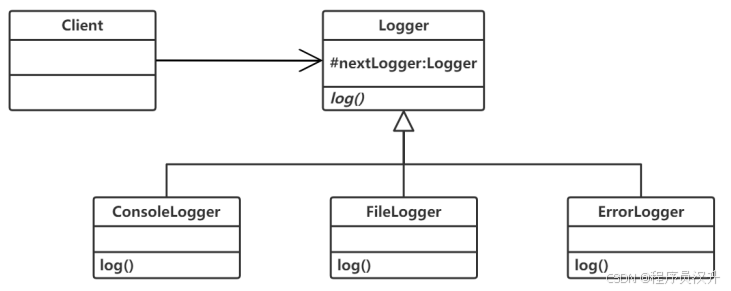
📌 正確答案:(44)A、(45)B、(46)B
🔍 詳細解析
23種設計模型詳細解釋見文章《軟考中級-軟件設計師 23種設計模式》
-
責任鏈模式:
-
核心思想:多個處理器對象(如ConsoleLogger、FileLogger)按鏈式順序處理請求,每個對象決定處理或傳遞請求。
-
題目匹配:日志對象根據級別決定是否記錄,并傳遞給nextLogger,完全符合責任鏈。
-
-
排除其他選項:
-
策略模式:動態切換算法(如排序策略),無鏈式傳遞。
-
過濾器模式:篩選數據集合,非請求處理流程。
-
備忘錄模式:保存/恢復對象狀態(如撤銷操作)。
-
-
行為型對象模式:
- 責任鏈模式屬于 行為型模式(關注對象間交互與職責分配),且通過對象組合(如nextLogger引用)實現,非類繼承。
-
責任鏈適用場景:
-
需動態指定處理對象鏈(如日志級別變化時增減處理器)。
-
解耦請求發送者與接收者(如客戶端無需知道具體哪個Logger處理請求)。
-
-
選項匹配:
-
B直接描述動態鏈式處理,是責任鏈的經典場景。
-
A描述過濾器模式,C描述備忘錄模式,D描述狀態模式或策略模式。
-
🚗 題目47:設計模式 - 設計模式應用場景
驅動新能源汽車的發動機時,電能和光能汽車分別采用不同驅動方法,而客戶端希望使用統一的驅動方法,需定義一個統一的驅動接口屏蔽不同的驅動方法,該要求適合采用 (47) 模式。
(47)
A. 中介者(Mediator)
B. 訪問者(Visitor)
C. 觀察者(Observer)
D. 適配器(Adapter) ?
📌 正確答案:D
🔍 詳細解析
適配器模式詳細解釋見文章《23種設計模式-適配器(Adapter)設計模式》
-
適配器模式的核心思想
-
定義:將一個類的接口轉換成客戶端期望的另一個接口,使原本不兼容的類能協同工作。
-
題目匹配:
-
電能/光能驅動方法不同 → 需通過適配器統一為**drive()**接口。
-
屏蔽差異:客戶端無需關心具體能源類型,調用統一接口即可。
-
-
-
代碼示例
// 統一驅動接口 interface EngineDriver {void drive(); }// 電能驅動適配器 class ElectricEngineAdapter implements EngineDriver {private ElectricEngine engine;public void drive() { engine.powerOn(); } // 調用電能專用方法 }// 光能驅動適配器 class SolarEngineAdapter implements EngineDriver {private SolarEngine engine;public void drive() { engine.absorbLight(); } // 調用光能專用方法 }// 客戶端調用 EngineDriver driver = new ElectricEngineAdapter(); driver.drive(); // 統一接口,屏蔽實現差異 -
排除其他選項
| 模式 | 用途 | 不適用原因 |
|---|---|---|
| 中介者 | 減少對象間直接耦合(通過中介通信) | 題目無需協調多個對象交互。 |
| 訪問者 | 分離算法與數據結構 | 與接口轉換無關。 |
| 觀察者 | 一對多的依賴通知(如事件監聽) | 不涉及事件發布-訂閱場景。 |
四、 網絡與信息安全知識 🌐
🔐 題目7:信息安全技術 - 認證方式安全性對比
下列認證方式安全性較低的是 (7) 。
(7)
A. 生物認證
B. 多因子認證
C. 口令認證 ?
D. U盾認證
📌 正確答案:C
🔍 詳細解析
不同認證方式的安全性對比如下:
| 認證方式 | 安全性 | 特點 |
|---|---|---|
| 口令認證 | ? | 純文本或簡單加密,易被暴力破解、釣魚、鍵盤記錄等手段攻破。 |
| 生物認證 | ??? | 基于指紋/虹膜等生物特征,難以復制但存在隱私泄露風險。 |
| U盾認證 | ???? | 物理硬件密鑰(如數字證書),需物理接觸,防中間人攻擊。 |
| 多因子認證 | ????? | 結合兩種以上方式(如口令+短信驗證碼),大幅提升破解難度。 |
💡 關鍵結論
-
口令認證(C)是安全性最低的:
-
單一因素,易受社會工程學攻擊(如弱密碼、重復使用密碼)。
-
例如:123456、password 等常見弱口令。
-
-
其他選項的高安全性體現:
-
生物認證(A):生物特征唯一但可能被偽造(如高精度指紋模型)。
-
U盾認證(D):硬件綁定,需物理持有(如銀行U盾)。
-
多因子認證(B):綜合“你知道的(密碼)+ 你擁有的(手機)+ 你獨有的(指紋)”因素。
-
🚀 擴展知識
-
雙因子認證(2FA):
-
常見組合:密碼 + 短信驗證碼/OTP(動態口令)。
-
漏洞:SIM卡劫持可能導致短信驗證碼被截獲。
-
-
零信任架構:
- 默認不信任任何設備/用戶,持續驗證(如每次操作需重新認證)。
GitHub就是雙因子認證(2FA)
🔐 題目8-9:信息安全技術 - 數字證書密碼算法標準對比
X.509 數字證書標準推薦使用的密碼算法是 (8) ,而國密 SM2 數字證書采用的公鑰密碼算法是 (9) 。
(8)
A. RSA ?
B. DES
C. AES
D. ECC(9)
A. RSA
B. DES
C. AES
D. ECC ?
📌 正確答案:(8)A、(9)D
🔍 詳細解析
-
X.509 數字證書標準(國際標準)
-
傳統主流算法:RSA
-
修正原因:
-
雖然ECC是未來趨勢且被新版X.509推薦,但題目問的是"推薦使用"而非"最新推薦"。
-
RSA仍是實際部署最廣泛的算法(兼容性最強,歷史應用最多)。
-
原解析混淆了"推薦"和"最新趨勢",需尊重題目表述的客觀現狀。
-
-
-
-
國密 SM2 數字證書(中國標準)
-
公鑰算法:ECC(基于 SM2 橢圓曲線)
-
原因:
-
SM2 是國密局發布的 ECC 實現,專為國產密碼體系設計,安全性優于 RSA。
-
符合中國商用密碼應用要求(如金融、政務系統)。
-
-
其他選項:
-
A. RSA:非國密算法,不符合 SM2 標準。
-
B. DES/C. AES:對稱算法,不用于證書公鑰體系。
-
-
-
💡 知識點對比
| 場景 | RSA優勢 | ECC優勢 |
|---|---|---|
| X.509證書 | 兼容所有老舊系統 | 更適合移動端和現代TLS(如HTTP/2) |
| 密鑰長度 | 2048位起步 | 256位即等效安全 |
| 中國商用場景 | 需配合國密算法改造 | 直接采用SM2 |
🛡? 題目10:網絡安全技術 - 網絡安全防護設備選擇
某單位網站首頁被惡意篡改,應部署 (10) 設備阻止惡意攻擊。
(10)
A. 數據庫審計
B. 包過濾防火墻
C. Web 應用防火墻 ?
D. 入侵檢測
📌 正確答案:C
🔍 詳細解析
-
Web應用防火墻(WAF)的核心作用
-
針對性防護:專門防御Web層攻擊(如SQL注入、XSS、網頁篡改等),直接保護網站首頁安全。
-
工作原理:深度解析HTTP/HTTPS流量,通過規則庫實時阻斷惡意請求。
-
-
其他選項不適用原因
選項 局限性 A. 數據庫審計 僅記錄數據庫操作,無法阻止前端攻擊(審計是事后行為)。 B. 包過濾防火墻 僅檢查IP/端口,無法識別應用層攻擊(如篡改首頁的HTTP請求)。 D. 入侵檢測 IDS只報警不阻斷,且通常針對網絡層攻擊(如DDoS),對網頁篡改防護不足。
🛡? 題目11:網絡安全技術 - 漏洞掃描系統的作用
使用漏洞掃描系統對信息系統和服務器進行定期掃描可以 (11) 。
(11)
A. 發現高危風險和安全漏洞 ?
B. 修復高危風險和安全漏洞
C. 獲取系統受攻擊的日志信息
D. 關閉非必要的網絡端口和服務
📌 正確答案:A
🔍 詳細解析
-
漏洞掃描系統的核心功能
-
主動發現風險:通過模擬攻擊行為,檢測系統中存在的漏洞(如未打補丁的服務、弱密碼配置等)。
-
輸出掃描報告:生成漏洞清單(包括CVE編號、風險等級、受影響組件等)。
-
-
其他選項的局限性
選項 問題分析 B. 修復漏洞 漏洞掃描系統僅提供檢測結果,修復需人工或專用補丁管理工具完成。 C. 獲取攻擊日志 日志分析需依賴SIEM或IDS系統,漏洞掃描不直接獲取歷史攻擊記錄。 D. 關閉端口/服務 端口管理需通過防火墻或系統配置,掃描系統無主動操作權限。
五、 標準化、信息化和知識產權基礎知識 🛠?
📜 題目12:知識產權 - 委托開發軟件的著作權歸屬
以下關于某委托開發軟件的著作權歸屬的敘述中,正確的是 (12) 。
(12)
A. 該軟件的著作權歸屬僅依據委托人與受托人在書面合同中的約定來確定
B. 無論是否有合同約定,該軟件的著作權都由委托人和受托人共同享有
C. 若無書面合同或合同中未明確約定,則該軟件的著作權由受托人享有 ?
D. 若無書面合同或合同中未明確約定,則該軟件的著作權由委托人享有
📌 正確答案:C
🔍 詳細解析
-
法律依據(《計算機軟件保護條例》第11條)
-
有合同約定:著作權歸屬按合同約定執行(優先尊重雙方意思自治)。
-
無合同或約定不明:著作權默認歸屬 受托人(實際開發者)。
-
-
選項逐項分析
選項 正誤 說明 A ? "僅依據合同"錯誤,合同未約定時依法定規則(歸受托人)。 B ? 共同享有需明確約定,非法定默認情況。 C ? 完全符合法律規定,是默認情形。 D ? 委托人僅享有使用權,非著作權(除非合同明確轉讓)。
💡 關鍵結論
-
委托開發 ≠ 職務開發:
- 職務作品著作權默認歸單位,但委托作品默認歸受托方。
-
委托人權利:
- 可免費使用軟件(除非合同限制),但不能未經許可修改或轉售。
📌 實際應用案例
-
場景1:甲方委托乙方開發APP但未簽合同 → 乙方保留著作權,甲方需獲授權使用。
-
場景2:合同約定“著作權歸甲方” → 需明確轉讓條款,乙方后續無權主張權利。
📜 題目13:知識產權 - 軟件著作權中的翻譯權定義
《計算機軟件保護條例》第八條第一款第八項規定的軟件著作權中的翻譯權是將原軟件由 (13) 的權利。
(13)
A. 源程序語言轉換成目標程序語言
B. 一種程序設計語言轉換成另一種程序設計語言
C. 一種匯編語言轉換成一種自然語言
D. 一種自然語言文字轉換成另一種自然語言文字 ?
📌 正確答案:D
🔍 詳細解析
-
法律條文依據
根據《計算機軟件保護條例》第八條:軟件著作權人享有下列各項權利:
……
(八)翻譯權,即將原軟件從一種自然語言文字轉換成另一種自然語言文字的權利。 -
翻譯權的核心定義
-
僅適用于自然語言:如將英文用戶手冊翻譯為中文,或將日文注釋轉換為法文。
-
不涵蓋編程語言轉換:
-
源程序→目標程序(選項A)屬于編譯過程,非著作權法意義的翻譯。
-
編程語言間的轉換(如Python→C,選項B)屬于代碼重寫或移植。
-
-
-
排除其他選項的理由
選項 錯誤原因 A 描述的是編譯器功能(如C→機器碼),與著作權無關。 B 編程語言轉換可能涉及重新創作,但非《條例》定義的翻譯權范疇。 C 匯編語言→自然語言屬于反匯編或注釋行為,非翻譯權覆蓋內容。
💡 實際應用場景
-
合法行為:將軟件的英文說明書翻譯為德文需著作權人授權。
-
侵權行為:未經許可將中文UI界面文字翻譯為俄文并發布。
📜 題目14:知識產權 - 知識產權權利辨析
M 公司將其開發的某軟件產品注冊商標為 S,為確保公司在市場競爭中占據優勢地位,M 公司對員工進行了保密約束,此情形下,該公司不享有 (14) 。
(14)
A. 軟件著作權
B. 專利權 ?
C. 商業秘密權
D. 商標權
📌 正確答案:B
🔍 詳細解析
-
題目情境分析
-
注冊商標:說明公司擁有商標權(選項D)。
-
保密約束:表明公司主張商業秘密權(選項C)。
-
開發軟件:默認享有軟件著作權(選項A)。
-
未提及:專利申請或技術方案公開(影響專利權)。
-
-
專利權缺失的原因
-
需主動申請:專利權必須向國家知識產權局申請,經審查授權后方可獲得。
-
題目未體現:
-
未描述軟件包含技術創新(如算法專利)。
-
保密措施可能阻礙專利授權(專利需公開技術方案)。
-
-
-
其他權利明確歸屬
權利 獲得方式 題目依據 軟件著作權 自動產生(開發完成即享有) “開發的某軟件產品” 商標權 注冊核準 “注冊商標為 S” 商業秘密權 保密措施+商業價值 “對員工進行保密約束”
六、 計算機英語 🐧
🐧題目71-75:計算機英語
??We initially described SOA without mentioning Web services, and vice versa. This is because they are orthogonal: service-orientation is an architectural (71) , while Web services are an implementation (72) . The two can be used together, and they frequently are, but they are not mutually dependent.
??For example, although it is widely considered to be a distributed-computing solution, SOA can be applied to advantage in a single system, where services might be individual processes with welldefined (73) that communicate using local channels, or in self-contained cluster, where they might communicate across a high-speed interconnect.
??Similarly, while Web services are (74) asthe basisfor a service-oriented environment, there is nothing in their definition that requires them to embody the SOA principles. While (75) is often held up as a key characteristic of Web services, there is no technical reason that they should be stateless—that would be a design choice of the developer, which may be dictated by the architectural style of the environment in which the service is intended to participate.
(71)
A. design
B. style ?
C. technology
D. structure
(72)
A. structure
B. style
C. technology ?
D. method
(73)
A. interfaces ?
B. functions
C. logiccs
D. formats
(74)
A. regarded
B. well-suited ?
C. worked
D. used
(75)
A. distribution
B. interconnection
C. dependence
D. statelessness?
📌 正確答案:(71)B,(72)C,(73)A,(74)B,(75)D
參考譯文:
??我們最初描述 SOA 時沒有提到 Web 服務,反之亦然。這是因為它們是正交的:面向服務是一種架構風格,而 Web 服務是一種實現技術。兩者可以一起使用,而且它們經常是,但它們并不相互依賴。
??例如,盡管 SOA 被廣泛認為是一種分布式計算解決方案,但它可以應用于單個系統中,其中服務可能是具有明確定義的接口的單個進程,使用本地通道進行通信,或者在自包含集群中,它們可能通過高速互連進行通信。
??類似地,盡管 Web 服務非常適合作為面向服務的環境的基礎,但它們的定義中沒有任何東西要求它們體現 SOA 原則。雖然無狀態通常被認為是 Web 服務的一個關鍵特征,但從技術上講,它們沒有理由應該是無狀態的——這將是開發人員的設計選擇,這可能由服務打算參與的環境的架構風格決定。

碼字不易,寫完發現4萬多字。如果有收獲不妨點贊、收藏、關注支持一下,各位的支持就是我創作的最大動力??


 Fetch API 詳解)











)





