25年4月來自香港中文大學和浙大的論文“ADGaussian: Generalizable Gaussian Splatting for Autonomous Driving with Multi-modal Inputs”。
提出 ADGaussian 方法,用于可泛化的街道場景重建。所提出的方法能夠從單視圖輸入實現高質量渲染。與之前主要關注幾何細化的 gaussian Splatting 方法不同,其強調聯合優化圖像和深度特征以實現準確的高斯預測的重要性。為此,首先將稀疏 LiDAR 深度作為一種額外的輸入模態,將高斯預測過程制定為視覺信息和幾何線索的聯合學習框架。此外,提出一種多模態特征匹配策略,結合多尺度高斯解碼模型,以增強多模態特征的聯合細化,從而實現高效的多模態高斯學習。在兩個大規模自動駕駛數據集 Waymo 和 KITTI 上進行的大量實驗表明, ADGaussian 實現最先進的性能,并在新視圖轉換中表現出卓越的零樣本泛化能力。
最近,3D Gaussian Splatting (3DGS) [14] 因其實時渲染速度和高質量輸出而在 3D 場景重建和新視圖合成領域引起了廣泛關注。一個關鍵應用是從圖像序列建模街道場景,這在自動駕駛等領域起著至關重要的作用。
在對城市場景進行建模時,一些方法遵循逐場景優化技術 [4, 17, 48],尤其是 Street-Gaussians [38],它將動態城市街道表示為一組配備語義邏輯和 3D 高斯的點云。雖然逐場景優化方法在高質量重建方面表現出色,但它往往難以應對昂貴的訓練成本和大范圍的新視圖合成。
為了實現可泛化的街道場景重建,大多數現有方法都建立在 Pix-elSplat [3] 或 MVSplat [6] 的架構之上。例如,GGRt [19] 引入一種無姿勢架構來迭代更新多視圖深度圖,隨后基于 PixelSplat 估計高斯基元。同樣,GGS [9] 通過集成多視圖深度細化模塊增強 MVSplat 的深度估計。
盡管如此,基于多視圖特征匹配的深度估計,可能會在無紋理區域和反射表面等具有挑戰性的條件下失敗。為了解決這個問題,并行工作 DepthSplat [36] 將 Depth Anything V2 [40] 中預訓練的深度特征與多視圖深度估計相結合,以實現準確的深度回歸,其中估計的深度特征進一步用于高斯預測。鑒于 Depth Anything V2 強大的泛化能力,將 DepthSplat 擴展到城市街道場景是合理的。然而,DepthSplat 在應用于這些環境時面臨特定的限制。首先,視覺渲染質量受到預訓練深度模型的有效性限制。此外,即使在深度質量較高的情況下,直接將圖像和深度特征連接起來進行高斯預測也會導致在復雜的自動駕駛情況下視覺重建不令人滿意(如圖所示)。
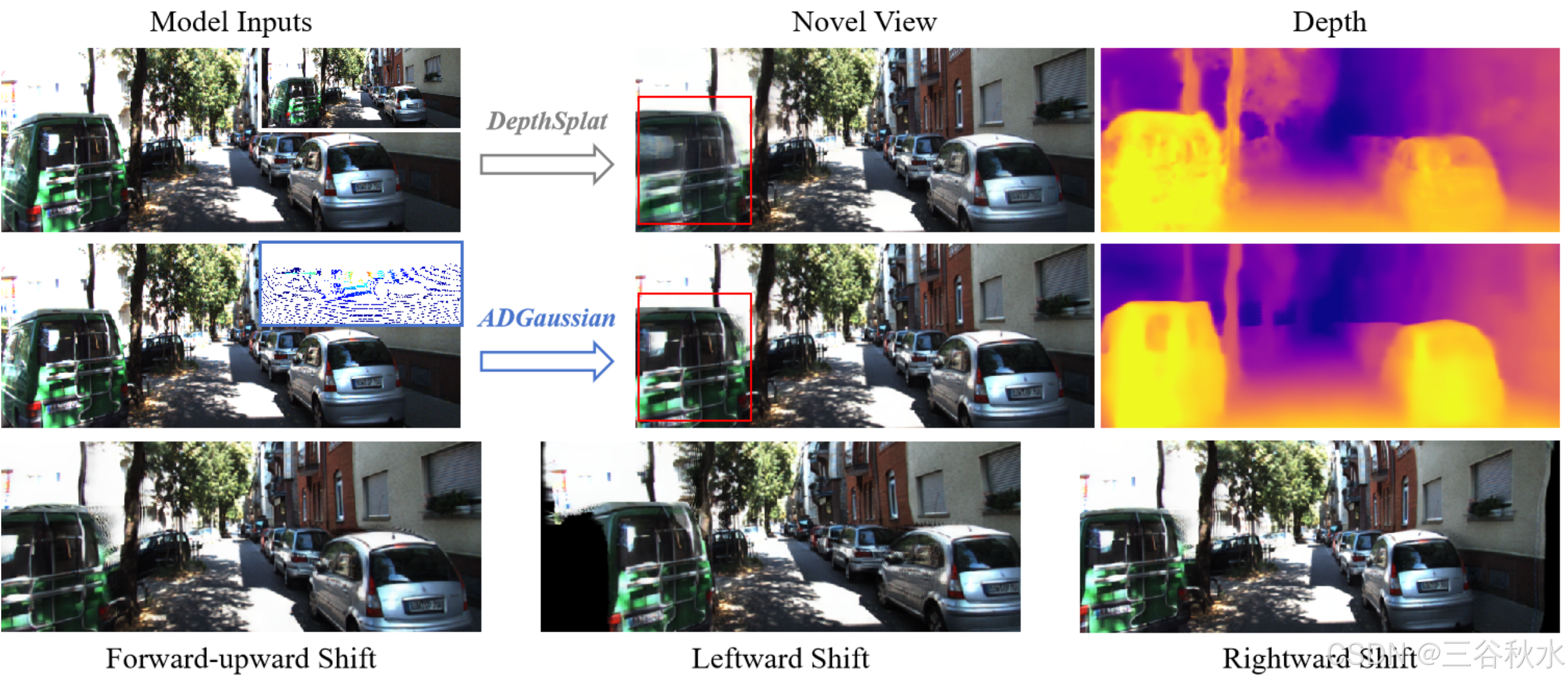
為此,提出一種多模態表示框架 ADGaussian,如上圖所示,旨在增強街道場景中的幾何建模和視覺渲染。
深度基礎模型 [1、2、39、40、42] 已被集成到Gaussian Splatting 中以改進幾何重建。然而,由于光度和幾何線索之間的相互作用不足,這種框架的渲染質量往往不理想。為了解決這個問題,提出 ADGaussian,這是一種同步多模態優化架構,它將稀疏深度數據與單目圖像相結合,以增強街景建模。
Gaussian Splatting 的深度基礎模型
最近,DepthSplat 等工作已經研究使用預訓練的深度基礎模型進行圖像條件 3D 高斯重建的優勢,并充分利用其在各種真實世界數據集中的出色性能。所有這些方法都利用預訓練的單目深度特征來增強最終的深度估計,從而提高高斯渲染的質量。
例如,DepthSplat 使用兩個并行分支處理多視圖圖像 {Ii} 以提取密集的每像素深度。一個分支專注于從多視圖輸入中建模成本體的特征 Ci,而另一個分支采用預訓練的單目深度主干,特別是 Depth Anything V2,以獲得單目深度特征 F^i_mono。隨后,將每視圖成本體和單目深度特征連接起來進行 3D 高斯預測。
直觀地說,這種模型可以輕松適應城市場景。盡管如此,重建的有效性在很大程度上取決于預訓練的深度基礎模型的性能,導致不同街道數據集和場景的準確性不一致。此外,圖像和深度特征的處理總是在每個視圖中并行進行,沒有任何信息共享或同步優化,這限制了模型的學習能力。
多模態特征匹配
這里找到一種有效的方法,將稀疏的 LiDAR 深度集成到 Gaussian Splatting 中,充分利用多模態特征。為此,提出了一種針對城市場景定制的多模態特征匹配架構,以實現稀疏深度信息和彩色圖像數據的同步集成。在此過程中,深度引導位置嵌入將深度線索納入位置嵌入,增強 3D 空間感知并提高多模態上下文理解。
多模態特征匹配。如圖所示,模型的核心是圖像中的光度特征和深度數據幾何線索的多模態特征匹配。這是通過 Siamese 式編碼器和信息交叉注意解碼器實現的,靈感來自 DUSt3R 系列 [18, 30]。
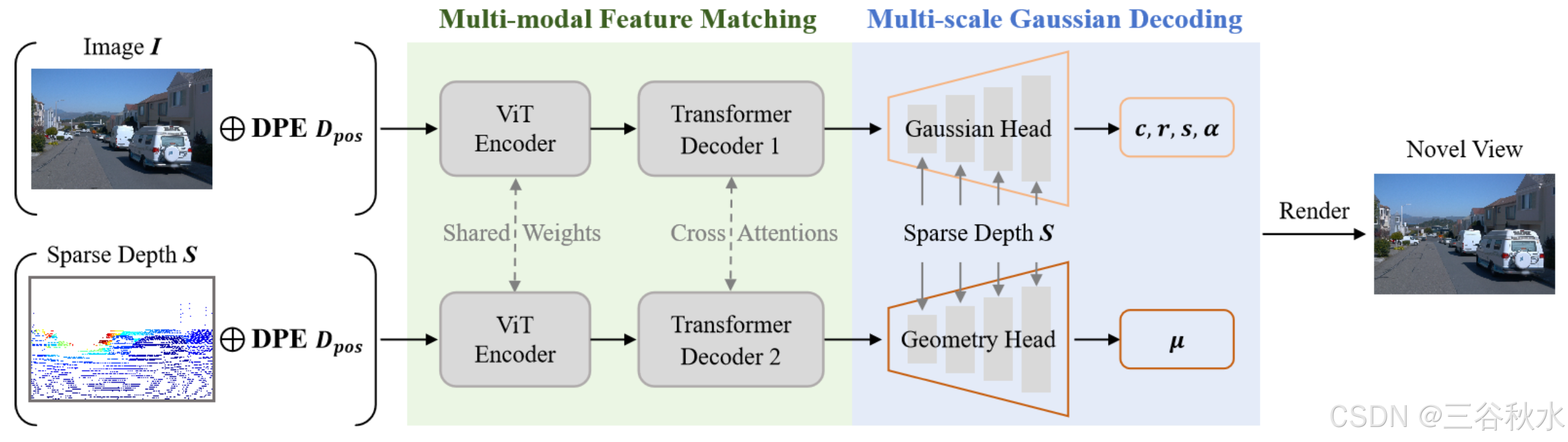
具體來說,單目圖像 I 和同步稀疏深度圖 S 以 Siamese 配置輸入權重共享 ViT 編碼器,產生兩個 token 表示 F_I 和 F_S 。兩個相同的編碼器以權重共享的方式協作處理多模態特征,從而實現相似特征的自動學習。
之后,配備交叉注意的 Transformer 解碼器用于增強兩個多模態分支之間的信息共享和同步優化。此步驟對于生成融合良好的多模態特征圖至關重要。
深度引導位置嵌入 (DPE)。 Vision Transformers 中的傳統位置嵌入對 2D 圖像平面上的相對或絕對空間位置進行編碼,以確保圖像內的空間感知。然而,僅僅依靠 2D 圖像平面的幾何特性不足以實現同步多模態設計。為此,提出一種直接的深度引導位置嵌入 (DPE),將深度位置與基于圖像的空間位置相結合。具體而言,給定下采樣的圖像和稀疏深度圖,首先將 2D 空間位置網格展平為 1D 矢量,其中每個元素對應于圖像中的特定空間位置。隨后,對稀疏深度圖進行下采樣以匹配圖像分辨率,從而生成一組獨立的深度索引來補充空間位置。最終的位置嵌入 D_pos 是通過將展平的空間位置與深度位置連接起來構建的,從而有效地在 xy-z 平面中編碼位置信息。通過整合空間和深度幾何,該模塊為有效的多模態特征匹配提供了全面的位置先驗。
多尺度高斯解碼
給定多模態 token G_I 和 G_S,目標是預測像素對齊的高斯參數 {(μ, α, Σ, c)},其中 μ、α、Σ 和 c 是 3D 高斯的中心位置、不透明度、協方差和顏色信息。為了充分利用圖像 token G_I 和深度 token G_S 提供的外觀線索和幾何先驗,實現兩個具有相同架構的獨立回歸頭,即高斯頭和幾何頭,以生成不同的高斯參數。
兩個回歸頭遵循 DPT [22] 架構,并通過額外的多尺度深度編碼增強,為高斯預測提供精確的尺度先驗。具體而言,在 DPT 解碼器中的每個尺度上,最初調整輸入稀疏深度圖的大小以與當前特征尺度的空間大小對齊。之后,調整過大小的深度圖,通過由兩個卷積層組成的淺層網絡進行處理,以提取深度特征,然后將其添加到 DPT 中間特征中。最后,輸入圖像和深度圖(每個都由單個卷積層處理)分別合并到高斯頭和幾何頭的最終特征中,以促進基于外觀或基于幾何的高斯解碼。
訓練損失
模型使用視圖合成損失和深度損失的組合進行訓練。
新視圖合成損失。用渲染和真值圖像顏色之間的均方誤差 (MSE) 和 LPIPS 損失的組合來訓練完整模型。
深度損失。利用深度損失來平滑相鄰像素的深度值,從而最大限度地減少小區域的突然變化。
數據集。在兩個廣泛使用的自動駕駛數據集上評估提出的方法:Waymo 開放數據集 [24] 和 KITTI 跟蹤基準 [8]。對于這兩個數據集,采用大約 1:7 的訓練-測試分割比。具體來說,在 Waymo 數據集上,主要關注靜態和動態場景,其中每種場景類型分為 4 個測試場景和 28 個訓練場景。同樣,對于 KITTI 數據集,分割由 5 個測試場景和 37 個訓練場景組成。這種劃分確保方法在不同場景中的平衡評估,同時也為有效的模型訓練提供足夠的訓練數據。
訓練細節。實現基于 Py-Torch 框架。采用 Adam [16] 優化器和余弦學習率策略,初始學習率為 1e-4。在 3090 Ti GPU 上訓練模型,在 Waymo 和 KITTI 數據集上均運行 150k 次迭代,批量大小為 1。為了確保公平比較,所有實驗均在 Waymo 數據集分辨率為 320×480 圖像和 KITTI 數據集分辨率為 256×608 圖像進行。






進程間通訊 之 信號量)




)





)

