JVM?
Java虛擬機
jdk java開發工具包
jre java運行時環境
jvm java虛擬機(解釋執行 java 字節碼)
java作為一個半解釋,半編譯的語言,可以做到跨平臺. java 通過javac把.java文件=>.class文件(字節碼文件)
字節碼文件, 包含的就是java字節碼, jvm把字節碼進行翻譯轉化為不同系統上可以識別的cpu指令.

JVM的內存劃分(面試題)
JVM本質上是一個進程

進程運行中, 要從操作系統這里申請一些資源(內存就是核心的資源)
JVM作為一個進程, 從系統中申請了一大塊內存, 這一大塊內存給java程序使用的時候, 又會根據實際的使用用途來劃分出不同的空間(比如java定義變量的時候,就是使用JVM從系統這邊申請到的內存)
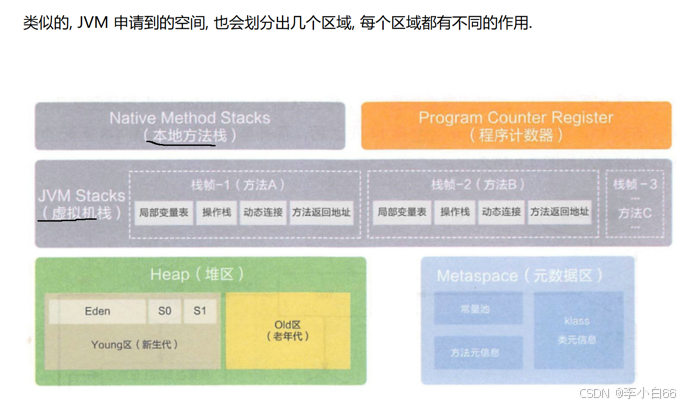
JVM劃分各區域的解釋
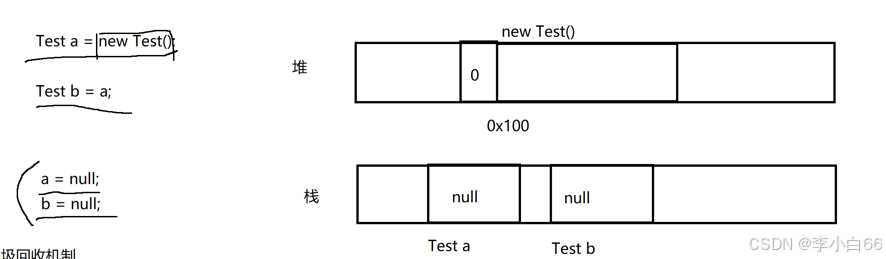
1> 堆 代碼中new出來的對象就都是在堆里面. 對象中持有的非靜態成員變量, 也就是在堆里面(后面GC主要就是回收這里的引用)
2> 棧?
本地方法棧: jvm內部, 通過c++代碼的調用關系和局部變量
虛擬機棧: 記錄了java代碼的調用關系和java里面的局部變量
此處的堆和棧和數據結構里面的不一樣
3> 程序計數器: 主要存儲下一條要執行的 java 指令的地址(每個線程都有自己的程序計數器和棧)
4> 元數據區(之前叫做方法區): 這里放一些輔助性,描述性質的屬性(比如在硬盤上保存數據的本體,還有一些輔助信息: 文件的大小, 文件的位置,文件的擁有者,文件的修改時間...).比如類的信息,方法的信息(一個程序有哪些類, 每個類里面又包含哪些方法, 每個方法里面包含哪些指令.
堆, 元數據區(整個進程有一份)?棧, 程序計數器(每個線程有一份)

常考的筆試題

JVM的類加載機制(面試題)
類加載: java進程運行的時候, 需要把.class文件從硬盤讀取到內存, 并進行一系列解析的校驗解析的過程.
類加載的過程:?
1> 加載 把硬盤上的 .class 文件找到, 打開文件, 讀取到文件的內容.(二進制的數據)
2> 驗證 確認當前讀到的文件內容是合法的 .class 文件(字節碼) 格式.(里面有jvm開發的版本信息, 高版本的可以運行低版本的 .class)(校驗.class 文件的格式是否符合 JVM 規范要求
3> 準備 給類對象, 申請內存空間(此時申請到的內存空間, 里面的默認值, 全都是0)
4> 解析 針對類中的字符串常量進行管理(java虛擬機將常量池里面的 符號引用 替換為 直接引用
的過程)?
class Test{ private String s = "hello"}? s里面包含的是"hello"的內存地址, 地址存的是內存的地址, 但是此時我們訪問的是.class文件, 文件里面不存在地址的概念,? 文件是放在硬盤上的, 因此我們.class文件里面的s存的是"hello"的相對偏移量,此時文件中填充的s的"hello"偏移量就是 符號引用 ,后續我們把.class放在內存里面,就會把"hello"加載到內存中, 此時"hello"就有地址了,此時內存中的s保存的是"hello"的內存地址, 此時就是 直接引用
5> 初始化: 針對類對象完成后續的初始化(執行靜態代碼的邏輯), 對對象的各個部分的屬性進行賦值填充
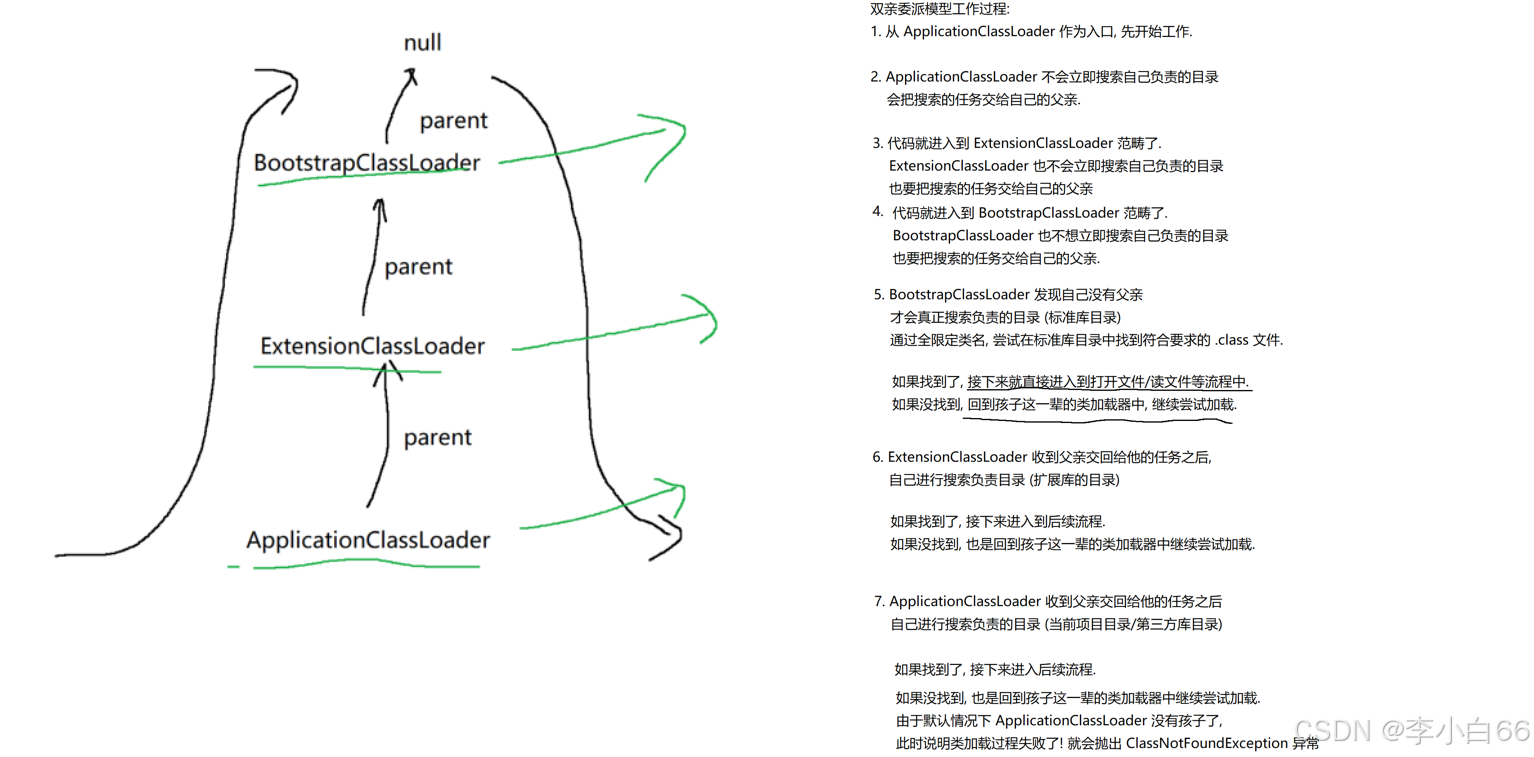
雙親委派模型(加載環節)
描述怎么查找 .class 文件的策略
JVM的幾個類加載器
BootstrapClassLoader: 負責查找標準庫的目錄
ExtensionClassLoader: 負責查找擴展庫的目錄( java 規范里面描述了標準庫中應該有哪些功能)
ApplicationClassLoader: 負責查找當前項目的代碼目錄, 以及第三方庫的目錄
從下面開始,逐層先把搜索任務交給上層,直到沒有上層為止, 然后從最上層開始進行搜索,如果找到了就進入打開文件, 讀文件的操作.如果沒有搜索到就去下層目錄開始找.以此往下到最后一層, 如果沒有找到就拋出 ClassNotFoundException 異常
JVM的垃圾回收算法(GC)面試題
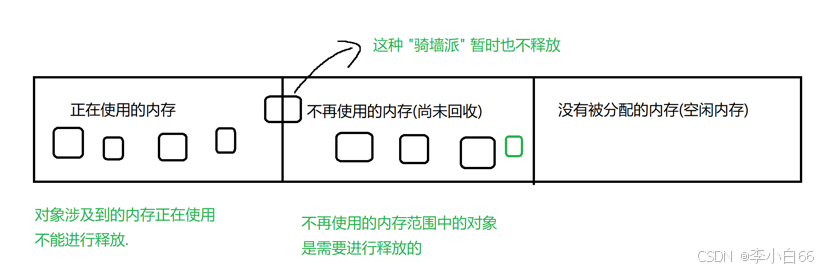
我們主要GC的區域就是堆(new 對象的區域)

垃圾回收,主要回收的是對象, 每次垃圾回收的時候, 釋放若干個對象
?垃圾回收機制
1> 識別出垃圾: 哪些是垃圾, 哪些不是垃圾(對象沒有引用了,匿名對象除外)
判定整個對象后續是否需要繼續使用(看整個對象是否被引用),如果一個對象都沒有引用指向他, 就視為無法被代碼中使用, 就可以視作垃圾.
創建的對象是放在堆, 引用的關系存放在棧
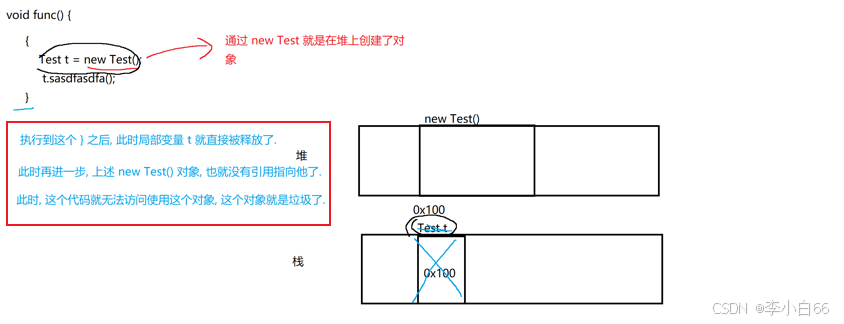
多個對象引用

如何計算引用?
1. 引入計數器 給每個對象安排一個額外的空間, 空間里面要保存當前整個對象有幾個引用.
此時的垃圾回收機制,就是看整個引用計數是否為0,是0就可以釋放了
問題1: 消耗額外的內存空間, 我們需要給每個對象都安排一個計數器
問題2: 引用計數可能會產生" 循環引用的問題 " . 此時, 引用計數就無法正確工作了

2. 可達性分析(JVM用的是這個)
相比于消耗一個空間來計算引用數目, 我們用時間來換空間
在寫代碼的時候, 會寫很多的變量, 此時我們以這些對象變量為起點, 根據引用關系向下搜索,所有能夠被搜索到的對象就不是垃圾了,搜索一圈也沒有訪問到的對象,就是垃圾.
比如我有若干個結點, 通過引用關系來構成二叉樹, 我們從根結點開始遍歷, 遍歷它的左子樹, 遍歷完后遍歷右子樹, 直到葉子結點沒有子節點為止, 此時我們遍歷到的結點都不是垃圾 ,如果我們把某個結點的?left設置為null, left之前結點就遍歷不到了, 此時就是不可達, 就是垃圾

2> 把標記為垃圾的對象的內存空間進行釋放
釋放的方式
a> 標記-清除
把標記為垃圾的對象直接釋放掉(會產生內存碎片的問題: 產生很多小的 離散的 空閑內存空, 我們申請內存空間是申請的一塊連續的內存空間)

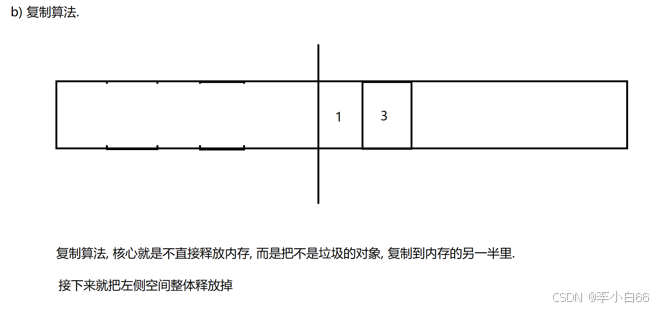
b> 復制算法
不直接釋放內存, 而是把不是垃圾的對象復制到內存的另一半里面, 然后釋放掉原先一半的內存空間(總的內存變少了, 每次復制的對象如果很多, 那么復制的開銷就會很大)
c> 標記 - 整理?
類似于 順序表 刪除中間元素(搬運)

分帶回收
引入概念, 對象的年齡
JVM 中有專門的線程負責周期性掃描/釋放
一個對象, 如果被線程掃描了一次, 就不是垃圾, 年齡+1(初始年齡是0)
JVM 中會根據對象年齡的差異, 把整個堆的內存分成倆大部分: 新生代(年齡小的對象) / 老年代(年齡大的對象)
新生代又分為伊甸區,生存區, 幸存區

1> 當new出一個新的對象, 就放在伊甸區.(伊甸區就會有, 很多的對象)
2>?第一輪GC: 之后大部分的對象都沒了, 還存在的對象會被使用復制算法拷貝放在生存區
后續的GC掃描線程伊甸區和生存去都會掃描, 然后進行垃圾清理, 在生存區存活下來的對象會使用復制算法放在幸存區里面,每一次GC的掃描,對象的年齡都會+1
3> 如果在生存區里面經歷若干輪GC, 還存在的對象, 就會被拷貝到老年區
4> 老年區掃描的頻次大大低于其他區域, 掃描線程主要掃描的還是新手區
5> 在老年區里面的對象沒有引用后, 就會被JVM按照標記整理的方式進行搬運處理掉.
垃圾收集器









——自適應優化系統、遺傳算法調參、Service Worker智能降級方案)




![【網絡流 圖論建模 最大權閉合子圖】 [六省聯考 2017] 壽司餐廳](http://pic.xiahunao.cn/【網絡流 圖論建模 最大權閉合子圖】 [六省聯考 2017] 壽司餐廳)
:axios有哪些常用的方法)



Hive聚合函數深度解析:從基礎統計到多維聚合的12個生產級技巧)
