參考Faiss
索引結構總結:
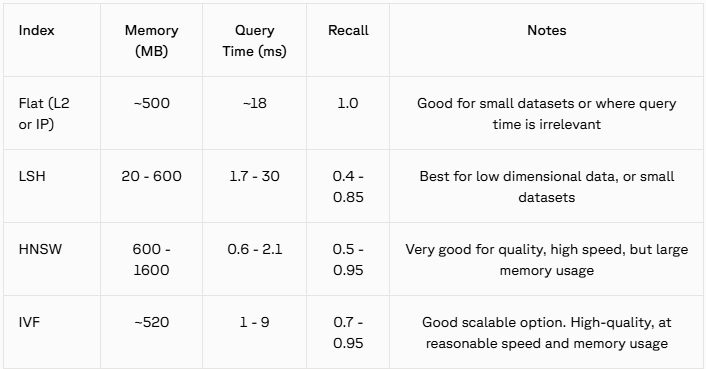
為了加深記憶,介紹一下Inverted File Index(IVF)的名字由來:
IVF索引的名字源自“倒排文件”(Inverted File)的概念。在傳統的信息檢索中,倒排文件是一種索引結構,用于記錄每個詞匯和文檔之間的關系,從而快速定位包含特定詞匯的文檔。
“倒排”是相對于文檔順序的“正排”而言的。在傳統的信息檢索中,文檔是按照其自然順序存儲的,稱為“正排文件”(Forward File)。在這種結構中,每個文檔包含的信息是完整的,比如文檔的內容以及可能包含的所有詞匯。如果需要搜索某個詞匯,系統就需要遍歷所有文檔,逐個檢查是否包含這個詞匯,這樣效率會非常低。
而“倒排文件”(Inverted File)則是通過將詞匯和文檔之間的關系“倒轉”過來實現的。它先建立一個詞匯表(詞典),然后為每個詞匯記錄它所出現的文檔編號或位置。這樣,當查詢某個詞匯時,系統可以直接通過倒排文件快速定位到包含該詞匯的文檔,而不需要逐一掃描所有文檔。這種方法顯著提高了檢索速度。
在向量相似性搜索中,IVF索引借用了這種倒排結構的思想,但將其應用于向量空間。數據集的向量被劃分到多個“簇”(clusters)或“細胞”(cells)中。這些簇是通過對向量進行聚類(Clustering)創建的,每個簇有一個中心點(Centroid)。查詢向量(Query Vector)通過與中心點的比較確定屬于哪個簇,然后搜索范圍限制在該簇或多個簇中。這種方法減少了搜索范圍,提高了搜索效率。
PQ(Product Quantization)
名字的由來
Product(產品、乘積)一詞的核心意義在于:
- 向量的整體量化是多個子空間量化的“乘積”,通過將整體問題分解成多個子問題,從而減少計算復雜性(所以這里product有點類似“分解”的意思)。
- 通過將一個高維向量拆分為多個子向量,并分別對這些子向量進行量化,最終的編碼可以看作這些獨立量化的“笛卡爾乘積”。
“Quantization”:指的是“量化”過程。量化的目的是用有限的質心(centroids)來近似表示連續向量空間,從而大幅降低存儲和計算成本。
“Product Quantization”表達了該技術的核心思想:通過對向量進行分解(product)和量化(quantization)以高效處理大型數據集。這種方法在保持精確性的同時顯著減少了存儲需求和計算開銷。
如何做查詢
如何構建參看上述Faiss鏈接
已知構建好后數據集中的data都可以表示為質心ID。
查詢方法一:
- 查詢向量量化:查詢向量同樣被分割為子向量,并映射到其各自子空間的最近質心,這使得查詢向量也可以被表示為一組質心ID。
- 計算距離:系統利用這些質心的編碼信息來快速計算查詢向量與數據庫中存儲向量之間的距離。由于向量被量化到有限的質心集合,這種計算變得更加高效。
- 最近鄰檢索:最終,系統基于計算的距離返回最接近查詢向量的多個候選向量(通常是 Top-k 結果)。
這里詳細解釋一下計算距離的操作,既然大家都是查詢編號了,我們是可以把查詢編號反映射回向量的,所以直接計算對應質心向量之間的(每個子空間的)距離結果求和(而非把重構的結果組合成完整的高維向量再做計算距離)的,但是這樣太慢了。
可以發現我們總是在求質心之間的距離,其實非常沒必要,我們可以是事先把每個子空間中的質心之間的的距離提前計算出來存著,要計算對應兩個質心的距離時直接查表即可(這樣也就不用映射回向量了!)。
查詢方法二:
- 查詢向量量化:查詢向量同樣被分割為子向量<但不映射為對應的ID,方法一在映射時也需要計算查詢向量的子向量到對應質心的向量的距離來判斷對應哪個ID>。
- 計算距離:詳見下。
- 最近鄰檢索:最終,系統基于計算的距離返回最接近查詢向量的多個候選向量(通常是 Top-k 結果)。
可以直接計算查詢向量的子向量到對應子空間的所有質心的距離,做成一個表<查詢向量與質心的表,注意與查詢一是構建質心之間的距離表>(不需要映射到最近的質心了,但其實也遍歷了與質心計算,少了對q的編碼那一步)。因為數據集中的數據已經表示為對應的質心ID了,所以到查詢向量到數據集中的data只需要查表然后累加。
相對簡潔些。
IVFPQ(Inverted File Index + Product Quantization)
相較于IndexPQ直接對向量 x x x 進行 PQ 量化,IVFPQ 先用 IVF 聚類,再對殘差進行PQ,相對量化誤差小,精度高,當然速度上會遜于單純的IndexPQ。
1. 預處理階段(構建索引)
在執行查詢之前,系統已經執行了以下步驟:
1.1 構建 IVF(倒排文件索引)
- 對所有數據庫向量運行 K-Means 聚類,得到 K 個簇中心(centroids)
- 每個數據庫向量x被分配到距離它最近的簇中心 C i C_i Ci?,并存儲在該簇的倒排列表中
1.2 對簇內的向量進行 PQ(產品量化)
- 對每個數據庫向量的偏移量 x ? C i x-C_i x?Ci?進行PQ
- 只存儲PQ編碼不存儲原始向量
2.查詢階段
給定查詢向量 q q q,IVFPQ 執行以下步驟來查找最近鄰:
Step 1:使用 IVF 找候選集
用 IVF 簇中心索引快速篩選候選集,避免遍歷整個數據庫。
- 計算 q q q 到所有K 個聚類中心的距離: d ( q , C i ) d(q,C_i) d(q,Ci?)
- 選取最近的前n個簇(通常 n < < K n<<K n<<K),只在這些簇的數據庫向量中進行搜索,而不掃描整個數據庫。
Step 2:計算查詢向量到候選向量的距離(使用 PQ)
對候選向量使用 PQ 查表計算近似距離,加速計算。
對于每個候選簇中的數據庫向量:
- 計算查詢向量相對簇中心的偏移量: q ′ = q ? C i q'=q-C_i q′=q?Ci?
- 利用 PQ 查找表計算近似距離:(1)預計算查詢向量到PQ質心的距離表<方式二>;(2)讀取數據庫向量的 PQ 編碼,從查找表中快速查找距離;(3)每個向量的距離計算變成了查表 + 加法操作,而不需要逐維計算歐幾里得距離
Step 3:返回最近鄰
在候選集中排序,選取最近的 k k k個向量作為最終查詢結果。
為什么是對殘差進行PQ
- 減少量化誤差
- 直接對整個數據庫向量 x x x進行 PQ 時,可能會出現較大的量化誤差。
- 但如果先用 IVF 找到最接近的簇中心,然后對其 殘差進行 PQ 量化,則編碼更加精細,可以減少誤差。
- 提高檢索精度
- 由于每個簇內的向量與簇中心的偏移較小(即殘差較小),因此殘差的值域更小,產品量化的效果更好。
- 這樣,查詢時可以用更少的 PQ 碼字(即更低的存儲成本)來獲得更高的搜索精度。
問題:nprobe 的選擇(找候選集的個數)
較低的nprobe會進一步加快速度,但是同時也大概率降低recall,可以適當提高nprobe
這里放上手冊中的對比圖:
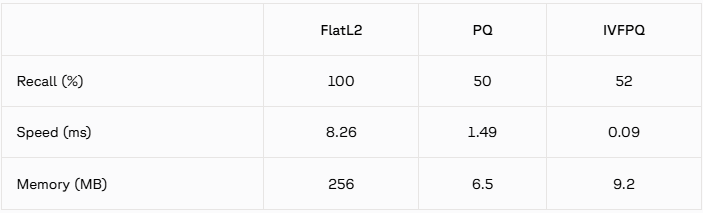
總結:PQ很快但是召回率較低,注意使用場景
這里給上GPT的回答:
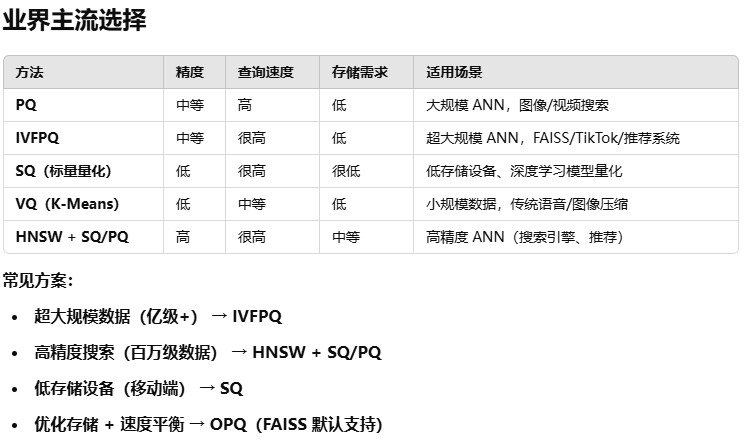
補充一下里面未涉及的有關量化的方法:






![【網絡流 圖論建模 最大權閉合子圖】 [六省聯考 2017] 壽司餐廳](http://pic.xiahunao.cn/【網絡流 圖論建模 最大權閉合子圖】 [六省聯考 2017] 壽司餐廳)
:axios有哪些常用的方法)



Hive聚合函數深度解析:從基礎統計到多維聚合的12個生產級技巧)








用于執行兩個矩陣(或圖像)逐元素乘法操作的函數mul())

