概述
Ragflow的助理配置中,有很多參數,盡管官方文檔給出了一定程度的解釋,但不夠詳細。
本文將對各項參數進行更詳細的解釋說明,并進一步挖掘某些參數中隱含的潛在陷阱。
助理設置
空回復
含義:輸入的問題若未能在知識庫中找到匹配的chunk塊,就默認輸出設置的內容,默認不啟用。
這個設置大多數場景都用不到,因為RAG本身就是通過知識庫對原本模型回答進行“增強”,除非是要求精確的查詢業務,才可能需要設置該值。
顯示引文
含義:開啟后,會在模型的回答中增加回答的引用提示,默認開啟。
此功能還是比較實用的,但存在一個小坑,開啟之后,在模型問答時,會在system prompt中添加默認提示,內容在rag\prompts.py的citation_prompt:
# Citation requirements:
- Inserts CITATIONS in format '##i$$ ##j$$' where i,j are the ID of the content you are citing and encapsulated with '##' and '$$'.
- Inserts the CITATION symbols at the end of a sentence, AND NO MORE than 4 citations.
- DO NOT insert CITATION in the answer if the content is not from retrieved chunks.--- Example START ---
<SYSTEM>: Here is the knowledge base:Document: Elon Musk Breaks Silence on Crypto, Warns Against Dogecoin ...
URL: https://blockworks.co/news/elon-musk-crypto-dogecoin
ID: 0
The Tesla co-founder advised against going all-in on dogecoin, but Elon Musk said it’s still his favorite crypto...Document: Elon Musk's Dogecoin tweet sparks social media frenzy
ID: 1
Musk said he is 'willing to serve' D.O.G.E. – shorthand for Dogecoin.Document: Causal effect of Elon Musk tweets on Dogecoin price
ID: 2
If you think of Dogecoin — the cryptocurrency based on a meme — you can’t help but also think of Elon Musk...Document: Elon Musk's Tweet Ignites Dogecoin's Future In Public Services
ID: 3
The market is heating up after Elon Musk's announcement about Dogecoin. Is this a new era for crypto?...The above is the knowledge base.<USER>: What's the Elon's view on dogecoin?<ASSISTANT>: Musk has consistently expressed his fondness for Dogecoin, often citing its humor and the inclusion of dogs in its branding. He has referred to it as his favorite cryptocurrency ##0$$ ##1$$.
Recently, Musk has hinted at potential future roles for Dogecoin. His tweets have sparked speculation about Dogecoin's potential integration into public services ##3$$.
Overall, while Musk enjoys Dogecoin and often promotes it, he also warns against over-investing in it, reflecting both his personal amusement and caution regarding its speculative nature.--- Example END ---
由于ragflow原生語言是英文,因此對于中文問題,直接加英文作為系統提示,混雜輸入或多或少會影響模型輸出性能,因此對于中文用戶,建議修改為中文的默認提示:
# 引用要求:
- 以格式 '##i$$ ##j$$'插入引用,其中 i, j 是所引用內容的 ID,并用 '##' 和 '$$' 包裹。
- 在句子末尾插入引用,每個句子最多 4 個引用。
- 如果答案內容不來自檢索到的文本塊,則不要插入引用。--- 示例 ---
<SYSTEM>: 以下是知識庫:Document: 埃隆·馬斯克打破沉默談加密貨幣,警告不要全倉狗狗幣 ...
URL: https://blockworks.co/news/elon-musk-crypto-dogecoin
ID: 0
特斯拉聯合創始人建議不要全倉投入 Dogecoin,但埃隆·馬斯克表示它仍然是他最喜歡的加密貨幣...Document: 埃隆·馬斯克關于狗狗幣的推文引發社交媒體狂熱
ID: 1
馬斯克表示他“愿意服務”D.O.G.E.——即 Dogecoin 的縮寫。Document: 埃隆·馬斯克推文對狗狗幣價格的因果影響
ID: 2
如果你想到 Dogecoin——這個基于表情包的加密貨幣,你就無法不想到埃隆·馬斯克...Document: 埃隆·馬斯克推文點燃狗狗幣在公共服務領域的未來前景
ID: 3
在埃隆·馬斯克關于 Dogecoin 的公告后,市場正在升溫。這是否意味著加密貨幣的新紀元?...以上是知識庫。<USER>: 埃隆·馬斯克對 Dogecoin 的看法是什么?<ASSISTANT>: 馬斯克一貫表達了對 Dogecoin 的喜愛,常常提及其幽默感和品牌中狗的元素。他曾表示這是他最喜歡的加密貨幣 ##0 ##1。
最近,馬斯克暗示 Dogecoin 未來可能會有新的應用場景。他的推文引發了關于 Dogecoin 可能被整合到公共服務中的猜測 ##3$$。
總體而言,雖然馬斯克喜歡 Dogecoin 并經常推廣它,但他也警告不要過度投資,反映了他對其投機性質的既喜愛又謹慎的態度。--- 示例結束 ---
關鍵詞分析
含義:開啟后,會在模型的回答中增加回答的引用提示,默認關閉。
開啟后,對于用戶輸入的問題會調用rag\prompts.py的keyword_extraction進行額外關鍵詞提取,關鍵詞提取會額外使用一輪模型問答,系統默認prompt:
Role: You're a text analyzer.
Task: extract the most important keywords/phrases of a given piece of text content.
Requirements: - Summarize the text content, and give top {topn} important keywords/phrases.- The keywords MUST be in language of the given piece of text content.- The keywords are delimited by ENGLISH COMMA.- Keywords ONLY in output.### Text Content
{content}
同理,對于中文用戶,可以設定為中文提示:
角色:文本分析器
任務:提取給定文本內容中最重要的關鍵詞/短語
要求:
- 總結文本內容,給出前{topn}個重要關鍵詞/短語
- 關鍵詞必須使用原文語言
- 關鍵詞之間用英文逗號分隔
- 僅輸出關鍵詞### 文本內容
{content}
提取完關鍵詞后,直接加在問題后面,相當于在prompt中對問題進行顯性強化,這樣方便在進行知識檢索中進行關鍵詞匹配。
這個功能比較看重實際場景,比如,對于數據精確度較高的業務,建議開啟,這樣更容易匹配到準確信息。對于普通問答業務,不建議開啟,因為會減慢模型響應速度。
文本轉語音
含義:開啟后,需要在系統模型設置中配置TTS模型,模型回答后,可點擊播放聲音按鈕,直接聽語音,默認關閉。
很雞肋的功能,開啟后無疑會顯著增加響應時間,絕大多數場景中用不到語音。
Tavily API Key
含義:用于將問題通過 Tavily 提供的外部資料庫進行進一步檢索,默認關閉。
這個功能不會將本地知識庫信息泄露到外部,而是在查完本地之后,再查一遍外部公網上的資料。個人認為沒有開啟的必要,因為需要網上的資料,直接用現成公開模型平臺的聯網搜索就可以了。
提示引擎
相似度閾值
含義:如果查詢和塊之間的相似度小于此閾值,則該塊將被過濾掉,默認值0.2。
輸入問題時,系統在查詢時會進行兩個操作,一方面提取關鍵詞,另一方面通過embedding模型變成詞向量,分別計算關鍵詞相似度和向量余弦相似度,最終相似度通過兩者加權得到,最終相似度如果超過此閾值,表明檢索成功。如果經常檢索不出內容,可以適當調低該值。
看源碼時,還發現一個小細節,在進行關鍵詞提取時,系統還會進行同義詞查詢,默認字典路徑為rag\res\synonym.json。
關鍵字相似度權重
含義:在混合檢索中,賦予關鍵字相似度的權重,默認值為0.7,向量余弦相似度權重為1-0.7=0.3。
如果業務是偏向精確搜索,可調大該值,如果偏模糊搜索,可適當降低該值。
Top N
含義:輸入到 LLM 的最大塊數。換句話說,即使檢索到更多塊,也只會提供前 N 個塊作為輸入。
多輪對話優化
含義:利用多輪對話中的現有上下文來增強用戶查詢,默認啟用。
非常雞肋的功能,前文分析過,開啟該功能后,在進行2輪以上對話時,會額外進行一輪大模型問答來優化第二次及以后提問的prompt,影響模型響應速率,建議關閉。
使用知識圖譜
含義:是否在檢索多跳問答時使用指定知識庫中的知識圖譜,默認關閉。
知識圖譜會極大增長檢索時間,除非業務特殊要求,否則不建議使用。
推理
含義:通過類似Deepseek-R1/OpenAI o1的推理過程來生成答案,開啟后聊天模型在回答問題時,遇到未知話題時會自主推理,生成答案。
如果用DeepSeek-R1系列模型,本身就是推理模型,不需要開啟。
Rerank模型
含義:使用重新排序模型,需要在系統模型設置中進行配置,作用是對檢索內容進行重新排序。如果開啟,混合相似度計算會使用關鍵詞相似度和重排器評分,重排器評分權重為1-關鍵字相似度權重。
個人覺得用Rerank作用不大,重排序的出發點是用來解決embedding固有的一些局限性問題,比如,"查找2025年4月3日的資料"容易檢索到”2024年4月3日的資料“,因為它倆就一字之差,在向量空間中可能是很接近的。ragflow已經采用了關鍵詞加權檢索來盡可能避免這個問題,再加一個重排序,有點過于保守,反而還會降低響應速度,因此不建議配置。
變量
含義:系統提示中要使用的變量,{knowledge}為特殊變量,用來將檢索的知識添加到系統prompt中。
有點雞肋的功能,如果需要修改系統prompt,直接改就行了,這里設置成變量形式,可能是為了后續拓展考慮,現階段作用不大,保持原樣即可。
模型設置
模型設置這幾個參數是LLM的固有屬性,系統并不會因此采取特殊策略。
溫度
含義:控制生成文本的隨機性和創造性,技術原理是通過softmax函數調整token概率分布的平滑程度。
低溫度 (如0.1-0.5):
- 輸出更確定、保守
- 傾向于高頻詞,適合事實性回答
- 示例:客服機器人回答"如何重置密碼?"
高溫度 (如0.7-1.0):
- 輸出更隨機、有創意
- 可能生成非常用詞,適合詩歌/故事
- 示例:寫科幻小說開頭時使用
Top P
含義:從概率最高的詞匯中動態劃出一個范圍,只從這個范圍內隨機選擇下一個詞。
概念比較抽象,舉個例子解釋:
問題:續寫句子 “The scientist discovered…”
模型預測的下一個詞概率可能如下:
- “a” (0.4)
- “the” (0.3)
- “that” (0.15)
- “an” (0.1)
- “quantum” (0.05)
- 如果 p=0.8:候選池 = {“a”, “the”, “that”}(累計概率0.4+0.3+0.15=0.85)
可能生成:“The scientist discovered the…”- 如果 p=0.95:候選池 = {“a”, “the”, “that”, “an”, “quantum”}可能生成:“The scientist discovered quantum…”(更有創意但風險更高)
通常,該值和溫度聯合使用,用來控制輸出保守或激進:
保守輸出(如問答):
- p=0.5~0.8(避免冷門詞,保持準確性)
創意輸出(如故事):
- p=0.9~1.0(允許更多可能性)
存在處罰
含義:通過懲罰對話中已經出現的單詞來抑制重復單詞的出現。
比較容易理解,模型輸出過的token會被降權,防止模型在同一個話題來回打轉。
頻率懲罰
含義:與存在懲罰類似,抑制模型輸出相同的內容。
存在處罰是出現過就懲罰一下,通常是固定值;頻率懲罰是出現頻率越高,懲罰強度越大。
對于嚴謹的問答場景,這兩個值就稍微調大;創意寫作場景,這兩個值就稍微調小。
如何加速模型聊天響應
我上一篇文章略微提到過加速模型響應的思路,在官方文檔中,也給出了以下幾點加速小貼士:
-
在聊天配置對話框的提示引擎選項卡中,禁用多輪優化將減少從 LLM 獲取答案所需的時間
-
在聊天配置對話框的提示引擎選項卡中,將重新排名模型字段留空將顯著減少檢索時間
-
使用重新排序模型時,請確保您有 GPU 來加速;否則重新排序過程將非常緩慢
-
在聊天配置對話框的助手設置選項卡中,禁用關鍵字分析將減少從 LLM 接收答復的時間
總結一下,加速方式總共就兩個方向,一個方向是關閉沒必要的選項,另一個方向是用GPU來加速embedding的過程。
官方給的docker啟動方式是運行這個文件:docker-compose.yml,如果使用其內置的embedding,可以通過這個文件docker-compose-gpu.yml進行啟動,這會運行docker調用存在gpu資源,一定程度上讓內置模型進行加速。
如果用的是ollama等其它框架外掛的embedding模型,可以忽略這一點。
修改默認值
其實官方也明確知道,多輪對話優化會影響模型輸出速度,然而它仍然將其保持了默認開啟的狀態,下面就通過修改初始值的方式,將其默認狀態設置為關閉。
助理相關的聊天配置文件在src\pages\chat\chat-configuration-modal這個文件夾下。
比如,想將多輪對話優化選項關閉,就修改prompt-engine.tsx的這部分內容:
<Form.Itemlabel={t('multiTurn')}tooltip={t('multiTurnTip')}name={['prompt_config', 'refine_multiturn']}initialValue={false}>
其它初始值的設置方式同理。
為什么模型不聽話?
之前有群友問到過這個問題,即設置了系統prompt,也在聊天時進行強調,為什么模型不按指定的規則來?在看官方文檔時,發現官方也特意強調了這個問題(看來問的人真的很多),這里順帶一提。
參考這個issue:
https://github.com/infiniflow/ragflow/issues/5627
這個用戶提了一個問題:為什么問答時,模型沒有正確檢索到本該檢索到的內容?
最后結論是,把DeepSeek-R1:14b切換成DeepSeek-R1:32b就解決了。
因此,想要模型正常理解意圖,至少采用32b以上的模型。
文檔解析的正確姿態
估計不少人都和我一樣,在向數據庫添加文件時,直接在知識庫界面點這里的上傳本地文件:
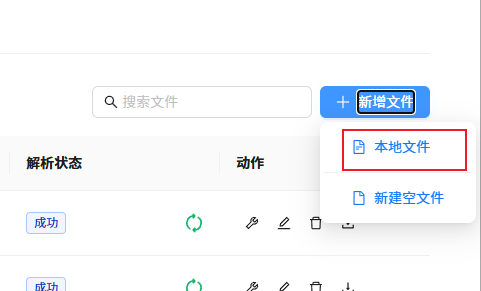
其實這樣操作會對文件管理產生問題,點到文件管理中,所有文件會被存放到.knowledgebase文件夾。
因此,正確上傳文件的姿態應該是先進入到文件管理界面,上傳文件,上傳完之后,選擇鏈接到知識庫。
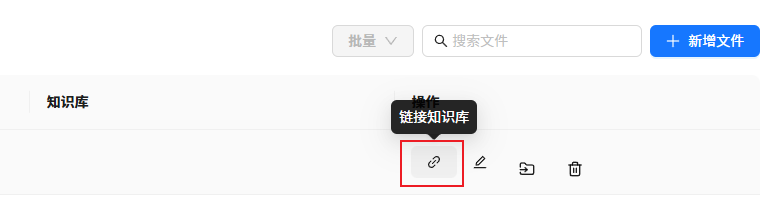
這樣,同一個文件夾是可以被多個知識庫共享的,這樣操作會更方便文件管理和知識庫的精細分類。
可參考的提示詞模板
看了系統內置的一些提示詞,不免對系統提示詞的設計再進行反思。
目前,新建助理時,默認的系統提示詞如下:
你是一個智能助手,請總結知識庫的內容來回答問題,請列舉知識庫中
的數據詳細回答。當所有知識庫內容都與問題無關時,你的回答必須包
括“知識庫中未找到您要的答案!”這句話。回答需要考慮聊天歷史。
以下是知識庫:
{knowledge}
以上是知識庫。
這樣寫比較通用,如果和實際業務結合,建議進行相應修改。
視頻[2]給出了一個可供參考的提示詞構建步驟:
- 指定角色:明確讓 AI 扮演的角色,例如情感專家、健身教練或知名人士。
- 描述問題:提供背景信息,包括現狀、目標和限制條件,例如年齡、體重、時間和資源。
- 提出請求:清楚地告知 AI 你需要的具體任務,如制定減肥計劃、分析分手原因或翻譯文章。
- 選擇格式:指定結果的呈現形式,如表格、郵件、合同等,并細化需求,如加粗重點。
- 設定語氣:說明期望的溝通風格,如正式、尊重、友愛等。
- 提供參考:附加具體的案例或樣例,以便 AI 更精準地理解和執行。
參考
1.官方文檔:
https://ragflow.io/docs/dev/start_chat
2.我用了3年的AI提示詞萬能公式,5分鐘解決70%提示詞問題~:
https://www.bilibili.com/video/BV1ib421E7Sy




——自適應優化系統、遺傳算法調參、Service Worker智能降級方案)




![【網絡流 圖論建模 最大權閉合子圖】 [六省聯考 2017] 壽司餐廳](http://pic.xiahunao.cn/【網絡流 圖論建模 最大權閉合子圖】 [六省聯考 2017] 壽司餐廳)
:axios有哪些常用的方法)



Hive聚合函數深度解析:從基礎統計到多維聚合的12個生產級技巧)




