摘要
文檔是視覺豐富的結構,不僅通過文本傳遞信息,還包括圖表、頁面布局、表格,甚至字體。然而,由于現代檢索系統主要依賴從文檔頁面中提取的文本信息來索引文檔(通常是冗長且脆弱的流程),它們難以高效利用關鍵的視覺線索。這種局限性影響了許多實際的文檔檢索應用,如 Retrieval Augmented Generation (RAG)。
為了對當前系統在視覺豐富文檔檢索中的能力進行基準測試,我們引入了 Visual Document Retrieval Benchmark (ViDoRe),該基準涵蓋多個領域、語言和實際場景下的頁面級檢索任務。由于現有系統在應對這些復雜任務時存在性能瓶頸,我們提出了一種新的概念:直接通過嵌入文檔頁面圖像來進行文檔檢索。
我們發布了 ColPali,一種 Vision Language Model (VLM),專門用于從文檔頁面圖像生成高質量的多向量嵌入。結合后期交互匹配機制(late interaction matching mechanism),ColPali 在性能上遠超現代文檔檢索管道,同時極大地簡化了流程,提高了速度,并且可以端到端訓練。我們在 https://hf.co/vidore 公開發布所有模型、數據、代碼和基準測試。
1 介紹
文檔檢索 的目標是在給定的語料庫中,將用戶查詢與相關文檔進行匹配。這一任務在許多工業應用中至關重要,可以作為獨立的排名系統(如搜索引擎),也可以作為更復雜的信息提取或 Retrieval Augmented Generation (RAG)流水線的一部分。
近年來,預訓練語言模型(PLMs) 使文本嵌入模型的性能取得了顯著提升。然而,在實際工業環境中,影響文檔檢索效率的主要瓶頸往往不是嵌入模型的表現,而是 數據攝取(ingestion)過程的復雜性。例如,索引一個標準的 PDF 文檔通常需要多個步驟:
- 使用 PDF 解析器或 Optical Character Recognition (OCR) 系統提取頁面上的文本;
- 運行 文檔布局檢測(Document Layout Detection)模型,分割段落、標題以及諸如表格、圖像、頁眉等頁面對象;
- 設計文本分塊(chunking) 策略,以保證語義連貫性;
- 現代檢索系統甚至可能引入 圖像描述(captioning),將視覺元素轉換為自然語言,以便文本嵌入模型處理。
我們的實驗(見表 2)表明,在視覺豐富的文檔檢索任務中,與其優化文本嵌入模型,不如優化數據攝取管道,這樣可以獲得更顯著的性能提升。
貢獻 1:ViDoRe
在本研究中,我們認為文檔檢索系統的評估不應僅限于文本嵌入模型的能力(Bajaj et al., 2016; Thakur et al., 2021; Muennighoff et al., 2022),還應考慮文檔的上下文和視覺元素。因此,我們創建并公開發布ViDoRe,一個綜合基準,用于評估系統在頁面級文檔檢索(page-level document retrieval) 方面的表現。ViDoRe 覆蓋多個領域、視覺元素和語言,針對現實文檔檢索場景進行評測,其中查詢通常需要結合 文本和視覺信息才能準確匹配相關文檔。
我們在 ViDoRe 評測中揭示了當前以文本為中心的檢索系統在這些任務上的不足。
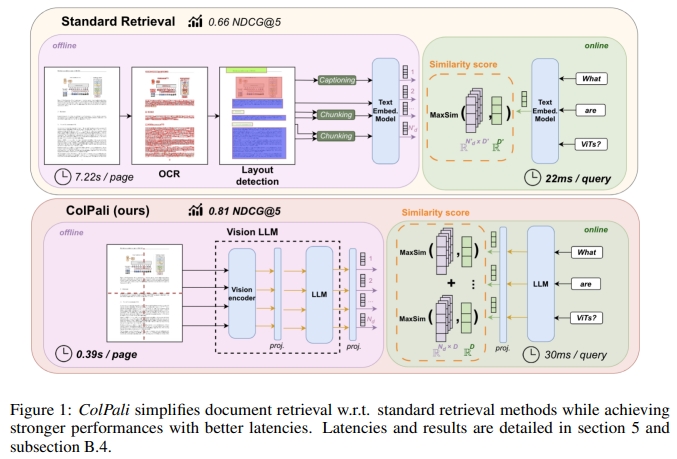
貢獻 2:ColPali
我們提出了一種新的概念和模型架構,基于 Vision Language Models (VLMs),可以 純粹基于文檔的視覺特征進行高效索引,并結合 后期交互匹配機制(late interaction matching mechanism, Khattab & Zaharia, 2020) 實現快速查詢匹配。
我們的方法 ColPali在 ViDoRe 任務上的表現遠超其他檢索系統,同時具備更快的檢索速度,并且可以端到端訓練。這一結果表明,我們提出的 “視覺空間檢索(Retrieval in Vision Space)” 概念具有巨大潛力,并可能從根本上改變工業界對文檔檢索的處理方式。
我們在 https://hf.co/vidore公開發布所有資源。
2 問題定義與相關工作
問題設定
在本研究中,檢索系統的目標是對語料庫 D 中的文檔 d 計算其相對于查詢 q 的相關性評分 s(q, d) ∈ ?,然后基于該評分對所有 |D| 個文檔進行排序,以提取最相關的文檔。本研究關注 頁面級檢索(page-level retrieval),即在給定查詢的情況下,系統是否能夠檢索到正確的文檔頁面。為了與現有文獻保持一致,我們進一步使用 document 一詞來指代單個頁面,即在本設定中可檢索的最小元素。
由于我們關注的是 實際工業檢索應用(如 RAG 和搜索引擎)且語料庫可能極其龐大,因此對檢索系統的 查詢延遲(latency) 施加了約束。大多數現代檢索系統可以分為兩個階段:
- 離線索引階段(offline indexation phase):構建文檔索引。
- 在線查詢階段(online querying phase):查詢與索引中的文檔進行匹配,并確保低延遲,以優化用戶體驗。
在這些工業約束下,我們識別出一個高效文檔檢索系統應具備的三大核心特性:
- (R1) 強檢索性能:以標準檢索指標衡量的系統檢索能力。
- (R2) 快速在線查詢:通過平均查詢延遲來衡量響應速度。
- (R3) 高吞吐量的語料索引:即在給定時間內能夠嵌入的頁面數量。
2.1 文本檢索方法
文本空間中的文檔檢索
基于 詞頻統計 的方法,如 TF-IDF(Sparck Jones, 1972)和 BM25(Robertson et al., 1994),因其簡單高效,至今仍被廣泛應用。近年來,基于 大規模語言模型(LLMs) 的 神經嵌入模型(Neural Embedding Models) 在多種文本嵌入任務上表現出色,并在檢索排行榜中取得領先地位(Muennighoff et al., 2022)。
神經檢索(Neural Retrievers)
- 雙編碼器模型(Bi-Encoder Models)(Reimers & Gurevych, 2019; Karpukhin et al., 2020; Wang et al., 2022):文檔在離線階段獨立映射到 稠密向量空間(dense vector space),查詢時在線計算嵌入,并通過快速的 余弦距離計算(cosine similarity computation) 進行匹配。
- 交叉編碼器模型(Cross-Encoder Systems)(Wang et al., 2020; Cohere, 2024):將查詢和文檔拼接為單一輸入序列,并逐一計算匹配分數。這種方法可以進行 全注意力計算(full attention computation),但因必須對 |D| 個文檔逐一編碼,計算成本較高。
基于后期交互的多向量檢索(Multi-Vector Retrieval via Late Interaction)
ColBERT(Khattab & Zaharia, 2020)提出了 后期交互(late interaction) 檢索范式,即:
- 每個文檔的 token 級別嵌入(token embeddings) 預先計算并索引;
- 運行時,僅計算 查詢 token 與 文檔 token 之間的相似度。
該方法結合了 雙編碼器(高效離線計算)和 交叉編碼器(強匹配能力)的優勢。詳見附錄 E。
檢索系統評估(Retrieval Evaluation)
雖然已有多個基準和排行榜用于評測文本嵌入模型(Thakur et al., 2021; Muennighoff et al., 2022),但在實際工業場景中,提升檢索系統性能的關鍵往往在于 優化數據攝取流程(data ingestion pipeline),而非僅優化嵌入模型本身。
此外,盡管文檔通常依賴 視覺元素 來更高效地傳遞信息,但基于文本的檢索系統很少能充分利用這些視覺線索。部分研究專門針對 表格 或 圖表 檢索(Zhang et al., 2019; Nowak et al., 2024),但僅限于特定任務,未能在 端到端、多文檔類型、多主題 的實際應用場景中全面評測檢索系統的能力。
目前尚無公開基準能全面評估文檔檢索系統在 實際應用環境 下的性能,同時結合 文本 與 視覺特征 進行評測。
2.2 視覺特征的整合(Integrating Visual Features)
對比視覺語言模型(Contrastive Vision Language Models)
將 文本內容的隱表示(latent representations) 映射到 對應的視覺表示 已成為主流方法,通常通過 對比損失(contrastive loss) 訓練 獨立的視覺和文本編碼器(Radford et al., 2021; Zhai et al., 2023)。
盡管這些模型具備一定的 OCR 能力,但視覺組件通常 未針對文本理解進行優化。
Fine-grained Interactive Language-Image Pre-training(Yao et al., 2021)進一步擴展了 后期交互機制(late interaction mechanism) 到 跨模態(cross-modal)視覺語言模型,通過 最大相似度運算(max similarity operations) 計算 文本 token 與 圖像 patch 之間的交互。
視覺豐富文檔理解(Visually Rich Document Understanding)
部分專門針對 文檔 的模型同時編碼:
- 文本 token
- 視覺布局特征(document layout features)
相關研究包括(Appalaraju et al., 2021; Kim et al., 2021; Huang et al., 2022; Tang et al., 2022)。
近年來,強推理能力的大型語言模型(LLMs) 被結合到 Vision Transformers (ViTs)(Dosovitskiy et al., 2020)中,形成 Vision Language Models (VLMs)(Alayrac et al., 2022; Liu et al., 2023; Bai et al., 2023; Lauren?on et al., 2024b)。在這些模型中:
- 通過 對比訓練(contrastive training) 訓練的 ViT 圖像 patch 向量(Zhai et al., 2023),被輸入到 LLM 中;
- 并與 文本 token 嵌入 進行拼接。
PaliGemma
PaliGemma-3B(Beyer et al., 2024)基于 Pali3(Chen et al., 2023),將 SigLIP-So400m/14(Alabdulmohsin et al., 2023) 的 patch 嵌入 投影到 Gemma-2B 的文本向量空間(Gemma Team et al., 2024)。
相比于其他高性能 VLMs,PaliGemma-3B 具有較小的模型尺寸,并且其文本模型經過 全塊注意力(full-block attention) 進行微調,適用于前綴(指令文本和圖像 token)。詳見附錄 E。
盡管 VLMs 在 視覺問答(Visual Question Answering)、圖像字幕生成(captioning) 和 文檔理解(document understanding) 方面表現出色(Yue et al., 2023),但 尚未針對檢索任務進行優化。
3 ViDoRe 基準測試
現有的對比視覺-語言模型基準主要用于評估自然圖像的檢索能力(Lin et al., 2014; Borchmann et al., 2021; Thapliyal et al., 2022)。另一方面,文本檢索基準(Muennighoff et al., 2022)主要評測文本段落級別的檢索能力,并未專門針對文檔檢索任務進行優化。
我們提出 ViDoRe,一個專門利用視覺特征進行文檔檢索的綜合性基準,以填補這一研究空白。
3.1 基準設計
ViDoRe 旨在全面評估檢索系統在頁面級別匹配查詢與相關文檔的能力。該基準涵蓋多個正交子任務,重點關注以下多個維度:
- 不同模態:文本、圖表、信息圖、表格等。
- 不同主題領域:醫學、商業、科學、行政管理等。
- 不同語言:英語、法語等。
此外,任務的復雜度也涵蓋不同層次,以便測試較弱系統和較強系統在不同任務上的表現。
由于許多檢索系統需要大量時間進行頁面索引(例如,基于圖像字幕生成的方法,每頁可能需要數十秒處理),我們對每個檢索任務的候選文檔數量進行了限制,以便在合理的時間范圍內評測復雜系統,同時不犧牲檢索質量。
對于可訓練的檢索系統,ViDoRe 還提供了一個參考訓練集,以便不同系統之間的公平對比。
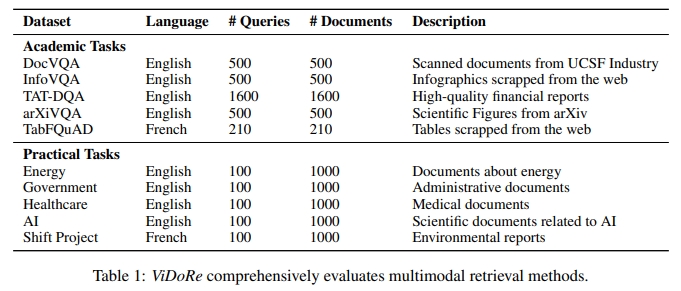
學術任務 我們將廣泛使用的視覺問答基準重新用于檢索任務:對于每個頁面-問題-答案三元組,我們使用問題作為查詢,關聯的頁面作為標準文檔(表 1)。這些學術數據集要么關注單一特定模態(Mathew et al., 2020; 2021; Li et al., 2024),要么面向更豐富的視覺文檔(Zhu et al., 2022)。此外,我們引入了 TabFQuAD,這是一個基于法語工業 PDF 文檔提取的表格數據集,并由人工標注。本節 A.1 提供了詳細信息。
實踐任務 為了超越傳統 QA 數據集的應用范圍,并評估檢索系統在更現實的工業環境(如 RAG)中的表現,我們構建了涵蓋多個領域的主題特定檢索基準。為此,我們收集了公開可訪問的 PDF 文檔,并使用 Claude-3 Sonnet(Anthropic, 2024)這一高質量的專有視覺-語言模型,生成與文檔頁面相關的查詢。最終,我們為每個主題收集了 1,000 個文檔頁面,并為其匹配了 100 條經過人工嚴格篩選以確保質量和相關性的查詢。基準測試的主題被刻意設計得較為專門化,以最大化文檔之間的句法相似性,從而形成更具挑戰性的檢索任務,同時覆蓋多個不同的領域(表 1)。
評估指標 我們使用檢索領域的標準指標(nDCG、Recall@K、MRR)來評估系統在 ViDoRe 基準上的表現(需求 R1)。在本研究中,我們主要報告 nDCG@5 作為核心性能指標,并發布完整的結果集及模型。
為了評估系統是否符合實際工業需求(第 2 節),我們還考慮查詢延遲(R2)和索引吞吐量(R3)。
3.2 評估當前系統
Unstructured 我們評估了在標準工業 RAG 流水線中常見的檢索系統。按照慣例,我們使用 Unstructured 這一開源工具,在最高分辨率設置下從 PDF 文檔中構建高質量的文本塊。Unstructured 負責協調整個文檔解析流程,包括使用深度學習視覺模型檢測標題和文檔布局(Ge et al., 2021)、OCR 引擎(Smith, 2007)提取非原生 PDF 文本,以及采用專門的方法或模型檢測并重建表格。此外,它實現了一種基于標題的分塊策略,以便在拼接文本時保留檢測到的文檔結構,從而保持章節邊界。
在最基本的 Unstructured 配置(僅文本)中,僅保留文本元素,而圖表、圖片和表格等被視為噪聲信息并被過濾掉。
Unstructured + X
雖然 Unstructured 本身是一個強大的基線,但我們進一步增強了其輸出,使其能夠整合視覺元素。
- 在 (+ OCR) 配置中,表格、圖表和圖片會經過 OCR 引擎處理,并由 Unstructured 解析后獨立分塊。
- 在 (+ Captioning) 配置中,我們設定了一套完整的圖像字幕生成策略(Zhao et al., 2023),其中將視覺元素輸入強大的專有視覺-語言模型 Claude-3 Sonnet(Anthropic, 2024),以獲得高度詳細的文本描述。
這兩種策略都旨在將視覺元素納入檢索流程,但都會帶來較高的延遲和資源消耗(第 5.2 節)。
Embedding Model 對于文本塊的嵌入,我們評估了 Okapi BM25(當前標準的稀疏統計檢索方法)以及 BGE-M3(Chen et al., 2024),這是一種在同等規模下達到 SOTA 性能的多語言神經方法。文本塊被獨立嵌入并評分,頁面級別的得分則通過對該頁面所有文本塊得分的 max-pooling 獲得。
對比 VLMs 我們還評估了當前最強的視覺-語言嵌入模型,包括 Jina CLIP(Koukounas et al., 2024)、Nomic Embed Vision(Nomic, 2024)和 SigLIP-So400m/14(Alabdulmohsin et al., 2023)。
結果 從性能角度來看,最佳結果來自將 Unstructured 解析器與視覺信息相結合的方案,例如使用字幕策略或對視覺元素運行 OCR(表 2)。BM25 和 BGE-M3 嵌入方法之間的差異很小,突出了視覺信息的瓶頸效應。對比 VLMs 的表現相對較弱。
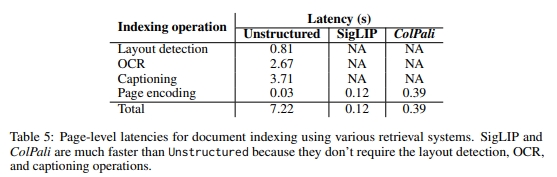
除了檢索性能(R1)外,索引延遲(R2)結果(圖 2)表明,PDF 解析流水線的耗時可能會很長,尤其是在整合 OCR 或字幕策略時。所有評測系統的在線查詢延遲(R3)均表現良好(在 NVIDIA L4 上≤22ms),得益于快速的查詢編碼和余弦相似度匹配。

4 基于延遲交互的視覺檢索
4.1 架構設計
視覺語言模型:基于現有視覺語言模型(VLMs)在文檔理解任務中的優異表現,我們提出將其適配至檢索場景。核心思想是利用多模態微調過程中獲得的文本與圖像token輸出嵌入的對齊特性。為此,我們開發了ColPali——基于PaliGemma-3B模型的擴展架構,可生成ColBERT風格的多向量文本與圖像表示(圖1)。選擇PaliGemma-3B因其模型體積小、提供多種針對不同圖像分辨率與任務的微調檢查點,以及在文檔理解基準測試中的卓越表現。我們新增投影層將語言模型輸出的文本/圖像token嵌入映射至降維空間( D = 128 D=128 D=128,與ColBERT論文設定一致),以維持輕量級的嵌入表示。
延遲交互機制:給定查詢 q q q與文檔 d d d,其多向量表示分別為 E q ∈ R N q × D \mathbf{E_q} \in \mathbb{R}^{N_q \times D} Eq?∈RNq?×D和 E d ∈ R N d × D \mathbf{E_d} \in \mathbb{R}^{N_d \times D} Ed?∈RNd?×D,其中 N q N_q Nq?、 N d N_d Nd?分別表示查詢與文檔頁面的向量數量。延遲交互算子LI ( q , d ) (q,d) (q,d)定義為所有查詢向量 E q ( i ) \mathbf{E_q}^{(i)} Eq?(i)與文檔向量 E d ( 1 : N d ) \mathbf{E_d}^{(1:N_d)} Ed?(1:Nd?)最大點積之和:
L I ( q , d ) = ∑ i ∈ [ ∣ 1 , N q ∣ ] max ? j ∈ [ ∣ 1 , N d ∣ ] ? E q ( i ) ∣ E d ( j ) ? (1) \mathrm{LI}\left(q,d\right) = \sum_{i\in\lbrack\left|1,N_q\right|\rbrack} \operatorname*{max}_{j\in\lbrack\left|1,N_d\right|\rbrack} \langle \mathbf{E_q}^{\mathrm{\,}(i)} | \mathbf{E_d}^{\mathrm{\,}(j)} \rangle \tag{1} LI(q,d)=i∈[∣1,Nq?∣]∑?j∈[∣1,Nd?∣]max??Eq?(i)∣Ed?(j)?(1)
對比損失函數:延遲交互操作完全可微,支持反向傳播。設批次數據 { q k , d k } k ∈ [ ∣ 1 , b ∣ ] \{q_k,d_k\}_{k\in[|1,b|]} {qk?,dk?}k∈[∣1,b∣]?包含 b b b個查詢-文檔對,其中每個文檔 d k d_k dk?為查詢 q k q_k qk?的真實匹配。參照Khattab & Zaharia (2020),我們定義批次內對比損失 L \mathcal{L} L為正向分數 s k + = L I ( q k , d k ) s_k^+=\mathrm{LI}(q_k,d_k) sk+?=LI(qk?,dk?)相對于最大負向分數 s k ? = max ? l , l ≠ k L I ( q k , d l ) s_k^-=\operatorname*{max}_{l,l\neq k}\mathrm{LI}(q_k,d_l) sk??=maxl,l=k?LI(qk?,dl?)的softmax交叉熵:
L = ? 1 b ∑ k = 1 b log ? [ exp ? ( s k + ) exp ? ( s k + ) + exp ? ( s k ? ) ] = 1 b ∑ k = 1 b log ? ( 1 + exp ? ( s k ? ? s k + ) ) (2) \mathcal{L} = -\frac{1}{b}\sum_{k=1}^b \log\left[\frac{\exp\left(s_k^+\right)}{\exp\left(s_k^+\right)+\exp\left(s_k^-\right)}\right] = \frac{1}{b}\sum_{k=1}^b \log\left(1+\exp\left(s_k^- - s_k^+\right)\right) \tag{2} L=?b1?k=1∑b?log[exp(sk+?)+exp(sk??)exp(sk+?)?]=b1?k=1∑b?log(1+exp(sk???sk+?))(2)
4.2 模型訓練
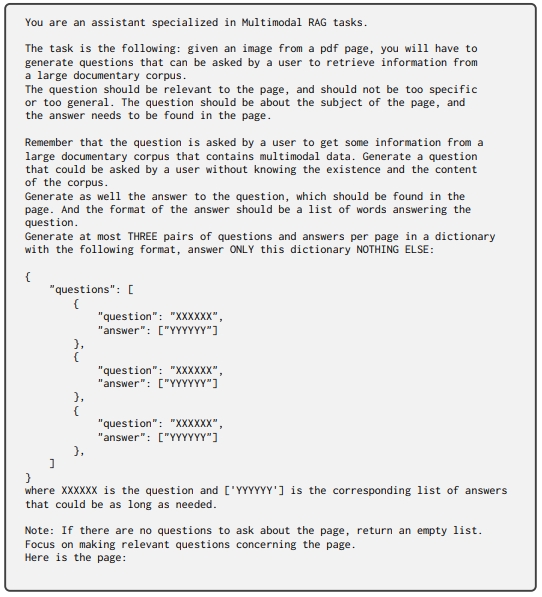
數據集 我們的訓練數據集包含118,695個查詢-頁面對,由以下兩部分構成:
- 公開學術數據集的訓練集(63%)
- 網絡爬取PDF文檔頁面組成的合成數據集(37%),并采用VLM(Claude-3 Sonnet)生成偽問題進行數據增強
(具體數據集劃分細節見附錄A.3小節)
該訓練集設計為純英文數據集,便于研究對非英語語言的零樣本泛化能力7。我們嚴格確保ViDoRe評估集與訓練集之間不存在多頁PDF文檔的重疊,以避免評估污染。另從樣本中抽取2%構建驗證集用于超參數調優。我們將公開該訓練數據集8以促進研究可復現性。
參數配置 所有模型均在訓練集上進行1個epoch的訓練,默認配置如下:
- 精度格式:bfloat16
- 適配器:在語言模型的transformer層及隨機初始化的最終投影層應用LoRA(Hu等人,2021),參數α=32,r=32
- 優化器:分頁adamw 8bit
- 硬件:8 GPU數據并行
- 學習率:5e-5(含2.5%預熱步長的線性衰減)
- 批次大小:32
查詢增強
參照Khattab & Zaharia(2020)的方法,我們在查詢token后追加5個特殊token,作為可微分的軟查詢擴展/重加權機制。
5 實驗結果
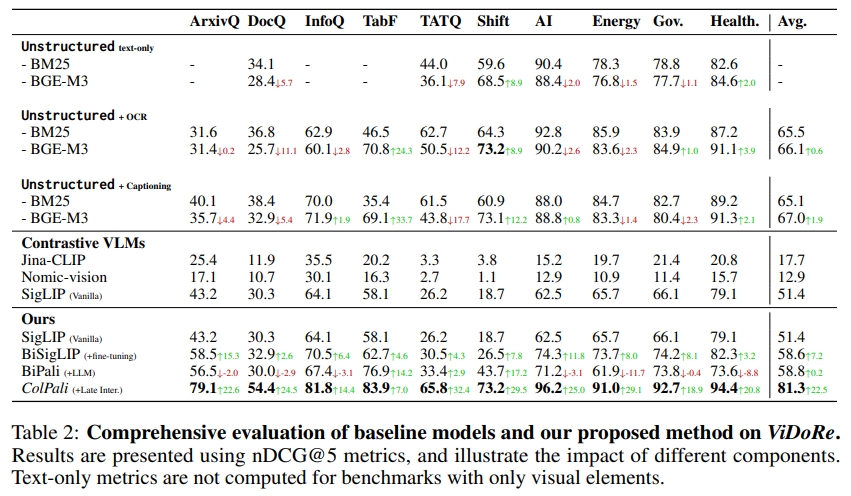
5.1 檢索性能(R1)
我們通過三個關鍵因素的迭代組合實現性能突破:
- 精心構建的領域專用數據集
- 預訓練LLM與視覺模型的協同架構
- 采用多向量嵌入表征替代單向量表示
文檔檢索定向微調的視覺模型:BiSigLIP 基于WebLI英文數據集預訓練的SigLIP9雙編碼器模型,經過我們文檔數據集的定向微調(BiSigLIP)后,在圖表檢索(ArxivQA)和表格檢索(TabFQuAD)任務中表現顯著提升。
LLM圖像塊處理:BiPali PaliGemma架構將SigLIP生成的圖像塊嵌入輸入文本語言模型,獲得經LLM上下文優化的圖像塊表征10。通過平均池化生成的單向量模型(BiPali)在英語任務中略遜于BiSigLIP,但在未訓練的法語任務中展現出色遷移能力11,證明Gemma 2B LLM的多語言理解優勢。
基于延遲交互的多向量嵌入:ColPali 通過語言模型處理的圖像塊嵌入天然對齊文本查詢的潛在空間,這使得采用ColBERT策略構建每個圖像塊token的獨立嵌入成為可能。如表2所示,ColPali在InfographicVQA(信息圖)、ArxivQA(圖表)、TabFQuAD(表格)等視覺復雜任務上顯著超越基于Unstructured和標題生成的基線模型,同時在所有評估領域和語言中保持最優文本檢索性能。
失敗案例 ColSigLIP(BiSigLIP的延遲交互變體)因預訓練階段僅優化池化表征導致性能低下。BiSigLIPPaliGemma則因SigLIP與Gemma嵌入空間錯位而表現不佳(詳見附錄C.1)。
5.2 延遲與內存占用
在線查詢(R2) ColPali查詢編碼耗時約30ms12,較BGE-M3的22ms略高。但優化后的延遲交互引擎(Santhanam等人,2022;Lee等人,2023)可支持百萬級文檔庫的毫秒級檢索。
離線索引(R3) 如圖2所示,ColPali通過端到端圖像編碼跳過了傳統PDF處理的布局檢測/OCR/分塊等耗時步驟,索引速度顯著提升13。固定序列長度設計支持高效批處理,并能利用Flash Attention(Dao,2023)等LLM加速技術。
存儲優化 每頁存儲需求為257.5KB(投影維度D=128)。通過分層均值token池化(Clavie等人,2024)可將向量數量減少66.7%同時保持97.8%性能(圖3左)。但文本密集型文檔(如Shift數據集)因信息密度高而更易受池化影響。
Token池化技術
Token池化(Clavie等人,2024)是一種符合CRUDE標準的方法(支持文檔動態增刪),旨在減少多向量嵌入的數量。在ColPali系統中,許多圖像塊(如白色背景區域)包含冗余信息。通過池化處理這些相似圖像塊,我們可以在保留大部分信息的前提下顯著減少嵌入向量數量。
如圖3(左)所示,采用分層均值token池化處理圖像嵌入時,當池化因子設為3時:
- 向量總量減少66.7%
- 仍能保持97.8%的原始檢索性能
值得注意的是,以高文本密度著稱的Shift數據集表現出明顯異常——信息密集度更高的文檔所含冗余圖像塊更少,因此在該池化技術下可能遭受更嚴重的性能衰減。
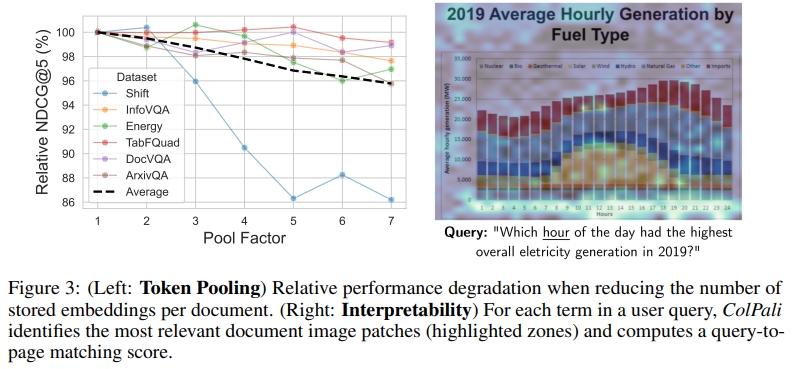
5.3 INTERPRETABILITY
通過將 late interaction heatmap 疊加在原始圖像上,我們可以可視化查詢的每個術語對應的最顯著圖像區域,從而獲得關于模型關注區域的可解釋性見解。如圖 3(右)所示,我們觀察到 ColPali 具有較強的 OCR 能力,因為“hourly”和“hours”這兩個詞與查詢 token <hour> 具有較高的相似度。此外,我們還注意到模型特別關注一些非顯而易見的圖像特征,例如代表小時的 x 軸具有顯著性。其他可視化示例見附錄 D。
6 ABLATION STUDY
我們進行了多種消融實驗,以更好地理解模型的工作機制。除非另有說明,以下報告的結果變化指的是所有 ViDoRe 任務的平均 nDCG@5 變化值。詳細結果見附錄 C.2。
模型規模與圖像 patch 數量之間的權衡
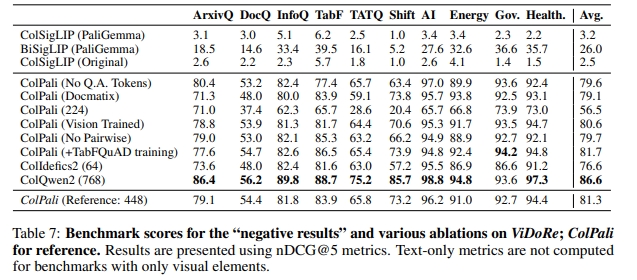
我們訓練了一個 PaliGemma 變體,將圖像 patch 數量減少至一半(512)。相比于 1024-patch 的 ColPali 模型,我們觀察到明顯的性能下降( ? 24.8 -24.8 ?24.8 nDCG@5),但內存使用量顯著降低。
作為 PaliGemma 的替代方案,我們訓練了 Idefics2-8B(Lauren?on et al., 2024b),這是一種 VLM,采用與 PaliGemma 類似的架構,但基于 Mistral-7B(Jiang et al., 2023)語言模型,并使用 SigLIP 視覺編碼器與 perceiver resampler 進行配對。這兩者的主要區別在于語言模型的規模(分別為 2B 和 7B)以及圖像 patch 的數量(PaliGemma 介于 512 到 2048 之間,而 Idefics2 經過 resampling 僅保留 64 個 patch)。
我們的結果表明,更強的語言模型可以提高圖像嵌入的表示效率——ColIdefics2 僅使用 64 個 patch 就遠超 ColPali(512 個 patch),提升了 + 20.1 +20.1 +20.1 nDCG@5。然而,ColIdefics2(64)仍然不及 ColPali(1024),性能下降 ? 4.7 -4.7 ?4.7 nDCG@5,同時在訓練和推理延遲方面大約慢兩倍。這些結果表明,在性能(R1)、在線查詢延遲(R2)、離線索引階段(R3)以及索引內存大小之間存在權衡。
解凍視覺組件
我們訓練了一個 ColPali 變體,允許反向傳播更新視覺編碼器及其投影層。這導致了輕微的性能下降( ? 0.7 -0.7 ?0.7 nDCG@5)。不過,在更大規模的訓練數據下,這一結論可能會有所變化。
“query augmentation” token 的影響
在 ColBERT 中,特殊 token 被連接到輸入查詢,以充當軟查詢增強緩沖區。當不使用這些 token 進行訓練時,我們在英語基準測試中未觀察到顯著的性能變化。然而,在法語任務上,性能有所提升(Shift 數據集 + 9.8 +9.8 +9.8 nDCG@5,TabFQuAD 數據集 + 6.3 +6.3 +6.3 nDCG@5,見表 7)。
Pairwise CE loss 的影響
在訓練過程中,若使用 in-batch negative contrastive loss 而非僅考慮最難負樣本的 pairwise CE loss,則整體基準測試的性能會略有下降( ? 1.6 -1.6 ?1.6 nDCG@5)。
適應新任務
與更復雜的多步檢索流水線不同,ColPali 可端到端訓練,直接優化下游檢索任務,從而極大地簡化了針對特定領域、多語言檢索或模型難以處理的視覺元素的微調過程。
為了驗證這一點,我們在訓練集中額外加入了 1552 個代表法語表格及其相關查詢的樣本。這些樣本是訓練集中唯一的法語數據,其他數據保持不變。結果表明,TabFQuAD 基準測試的 nDCG@5 顯著提升( + 2.6 +2.6 +2.6),Recall@1 提升更為明顯( + 5 +5 +5),而其他基準任務的性能未受影響(總體提升 + 0.4 +0.4 +0.4 nDCG@5)。
更強的 VLM 促進更好的視覺檢索器
隨著更先進的 VLM 發布,我們可以觀察當這些模型適配為圖像檢索任務時,是否能延續其在生成任務上的優異表現。
我們使用相同的數據和訓練策略,訓練了最近發布的 Qwen2-VL 2B(Wang et al., 2024b),這是一款 SOTA 級別的 20 億參數生成式 VLM,生成 ColQwen2-VL。為了大致匹配 ColPali 的內存需求,我們將圖像 patch 數量限制在 768,比 ColPali 的 1024 略少。結果顯示,ColQwen2-VL 的性能比 ColPali 提高了 + 5.3 +5.3 +5.3 nDCG@5,這表明在生成任務上的改進確實可以轉換為檢索任務的性能提升。
跨領域泛化能力
ViDoRe 基準中的部分數據集具有訓練集,我們已將這些數據集整合至 ColPali 的訓練集中(例如學術任務)。這種做法在嵌入模型中較為常見(Wang et al., 2024a; Lee et al., 2024)。雖然 ColPali 在未見過的任務(如法語數據)上仍然表現出色,但研究模型在完全不同的數據分布上訓練后的表現仍然值得探討。
為此,我們僅使用最新的 DocMatix 數據集(Lauren?on et al., 2024a)訓練了一個 ColPali 變體。DocMatix 是一個大規模、合成標注的視覺文檔問答數據集,我們對其進行子采樣,使訓練集規模與原始訓練集相當。ViDoRe 評測結果表明,性能下降幅度較小( ? 2.2 -2.2 ?2.2 nDCG@5),但仍然比最接近的基線方法高出 12 個百分點。這些結果表明 ColPali 在未見過的領域仍能很好地泛化,同時也證明了我們的結果并未因可用的微調數據而對基線方法(如 BGE-M3)造成不公平的優勢。
7 結論
在本研究中,我們提出了 Visual Document Retrieval Benchmark (ViDoRe),用于評估在包含視覺復雜文檔的現實環境中進行文檔檢索的系統。我們證明了當前的檢索流水線和對比式 Vision-Language 模型難以有效利用文檔中的視覺信息,從而導致性能次優。
為了解決這一問題,我們提出了一種新的檢索方法 ColPali,該方法利用 Vision-Language Models 僅通過視覺文檔特征創建高質量的多向量嵌入。ColPali 在很大程度上超越了現有最佳文檔檢索方法,同時加快了語料庫索引時間,并保持了較低的查詢延遲,從而規避了現代文檔檢索應用中的許多痛點。我們希望通過公開發布 ViDoRe 基準、數據、代碼庫以及所有模型和基線,推動工業界的應用,并鼓勵未來的研究工作。
未來工作 除了可以通過更優質的數據、更強的基礎模型或更好的訓練策略提升性能之外,我們的長期愿景是結合視覺檢索系統與視覺基礎的查詢回答(visually grounded query answering),從而創建僅依賴圖像特征運行的端到端 RAG 系統。這一構想得到了同期研究的支持(Ma et al., 2024),該研究表明 VLMs 在視覺 QA 任務中展現出極大的潛力,并最終可能成為文檔處理的新工業標準。
在這一研究方向上,系統的可靠性至關重要。信息檢索方法的置信度估計技術可能成為實現拒答機制(abstention mechanisms)的核心(GisserotBoukhlef et al., 2024)。考慮到 late interaction 系統的信息豐富的多向量評分機制,這一方向尤其值得關注。此外,擴展基準測試范圍以覆蓋更多語言、模態和任務也是未來研究的重要方向(Jiang et al., 2024)。
附錄A 基準數據集
A.1 學術數據集
DocVQA (Mathew et al., 2020) 包含從UCSF Industry Documents Library 收集的圖像,問題和答案均由人工標注。
InfoVQA (Mathew et al., 2021) 包含從互聯網上使用搜索關鍵詞 “infographics”收集的信息圖,問題和答案均由人工標注。
TAT-DQA (Zhu et al., 2022) 是一個大規模的 Document VQA 數據集,構建自公開可用的真實世界財務報告,重點關注包含豐富表格和文本內容且需要數值推理的文檔。問題和答案均由金融領域的專家手工標注。
arXivQA (Li et al., 2024) 是一個基于arXiv 論文中提取的圖表構建的 VQA 數據集。問題由GPT-4 Vision 以合成方式生成。
TabFQuAD (Table French Question Answering Dataset) 旨在評估 TableQA 模型在現實工業環境中的表現。我們使用與 A.2 小節相同的方法,基于已有的人工標注數據額外生成了一些查詢。
A.2 實踐數據集
方法論。 構建一個與真實應用場景接近的檢索數據集是一項重大挑戰,該數據集需要足夠大以支持有效的微調,同時足夠多樣以涵蓋廣泛的模態(全文、表格、圖表等)、領域(工業、醫療等)和查詢-文檔交互方式(抽取式問題、開放式問題等)。我們的方法包括以下幾個步驟:
- 使用Web 爬蟲收集與不同主題和來源相關的公開文檔;
- 將這些 PDF 轉換為一系列圖像,每頁對應一張圖片;
- 使用 VLM 生成與每張圖像相關的查詢。
Web 爬蟲
我們實現了一個 Web 爬蟲來高效收集與指定主題相關的大量文檔。爬蟲以用戶定義的查詢(例如 “artificial intelligence”)為起點,并使用 GPT-3.5 Turbo 生成相關主題和子主題,以實現查詢擴展策略,從而在廣度和深度上增強搜索能力。
隨后,GPT-3.5 Turbo 進一步用于從每個子主題生成不同的搜索查詢,并將其傳遞給一組并行工作進程,這些進程負責抓取相關性最高的文檔。
我們使用SerpAPI 以及文件類型過濾(僅限 PDF 文檔)來自動化爬取 Google 搜索排名。每個文件都會經過哈希計算并存入Bloom Filter(Bloom, 1970),該濾波器在所有工作進程之間共享,以避免最終語料庫中出現重復文檔。去重后的文檔會被下載,并存入SQLite 數據庫,同時存儲額外的元數據。
Datamix
通過Web 爬蟲,我們為以下四個主題分別收集了約 100 份文檔:
- energy(能源)
- government reports(政府報告)
- healthcare industry(醫療行業)
- artificial intelligence(人工智能)
這些主題經過精心挑選,以匹配檢索模型的實際應用場景,并確保文檔包含豐富的視覺內容。同時,我們移除了所有可能包含私人信息的文檔。
查詢生成
為了提高查詢生成方案的效率并減少 API 調用次數,我們最多為每張圖像生成 3 個問題。
在所有收集到的文檔中,我們隨機抽樣每個主題 10,000張圖像,并調用Claude-3 Sonnet,使用以下提示詞(prompt):
人工驗證
我們對 ViDoRe 中每一條合成生成的查詢都進行了人工驗證,以確保查詢的質量、相關性,并符合該基準測試評估工業應用場景下檢索任務的目標。在此過程中,我們隨機分配文檔-查詢對給 4 名志愿標注者,并指導他們篩除不符合上述標準的查詢。
此外,我們還要求標注者標記任何他們認為包含 PII(個人身份信息)或不適用于學術基準測試的文檔。然而,在整個過程中沒有發現任何需要標記的情況,這驗證了我們先前的 PDF 采集策略的合理性。
最終,每個主題篩選出 100 條查詢,標注者均為論文作者的同事和合作者,他們自愿參與該項目。每位標注者大約花費 3 小時,從更大規模的查詢集中篩選出每個主題 100 條高質量查詢。
A.3 訓練數據集
訓練集的統計信息如下表所示。其構建方法與 A.2 小節相同。
我們確保:
- 同一 PDF 文檔的頁面不會同時出現在訓練集和測試集中,以防止數據泄漏。
- 每個數據劃分(訓練集、測試集)內都不存在重復文檔。
B 實現細節
B.1 代碼庫
代碼庫使用 PyTorch 編寫,并利用 HuggingFace 工具實現模型和訓練器。
B.2 超參數
超參數在訓練數據集的 2% 驗證集上進行調優。我們發現,雙編碼器方法比基于晚期交互的模型對學習率變化更為敏感,在所有模型中,學習率 5 e ? 5 5e-5 5e?5 達到最佳性能。我們嘗試了 LoRA 的 rank 和 α 值,但未觀察到 r = α = 32 r = α = 32 r=α=32 之后有顯著的性能提升。由于序列長度較長,較大的批量規模會使得擴展變得更加復雜,因此每個設備的批量大小保持較小。我們通過多 GPU 訓練模擬較大的批量規模,并使用總批量大小 b = 32 b = 32 b=32 進行訓練,無需梯度累積,訓練 1 個 epoch。
B.3 嵌入大小
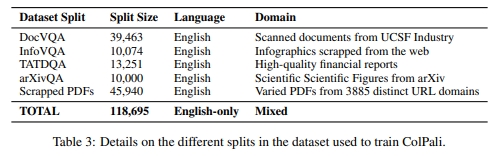
在工業檢索系統中,如果數據庫包含數百萬個文檔,最小化存儲占用可能至關重要。基于此標準,我們比較了本研究中模型的嵌入大小。如表 4 所示,ColPali 的嵌入大小比 BM25 大一個數量級,比 BGE-M3 大兩個數量級。然而,在實際場景中,通過中心聚類池化多向量嵌入,或將嵌入量化為二進制表示,可以將存儲成本降低兩個數量級(Santhanam 等,2022),且對性能的影響最小,從而使得存儲成本與其他系統競爭。
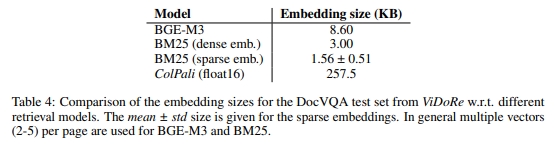
B.4 延遲計算
為了確保比較的公平性,圖 2 中展示的不同檢索系統的延遲是在相同的 g2-standard-8 GCP 虛擬機(配備 NVIDIA L4 GPU)上測量的。文檔頁面使用 Unstructured 的最高設置和標題生成(參見 3.2 小節)進行嵌入。SigLIP 和 ColPali 都加載了 bfloat16 類型的參數。表 5 中報告的時間是對 ViDoRe 基準測試集的 1000 個隨機選擇文檔進行每頁索引操作時的平均延遲。BGE-M3 模型與 Unstructured 配合使用時的批量大小為 8,而 SigLIP 和 ColPali 的批量大小為 4。
B.5 標注
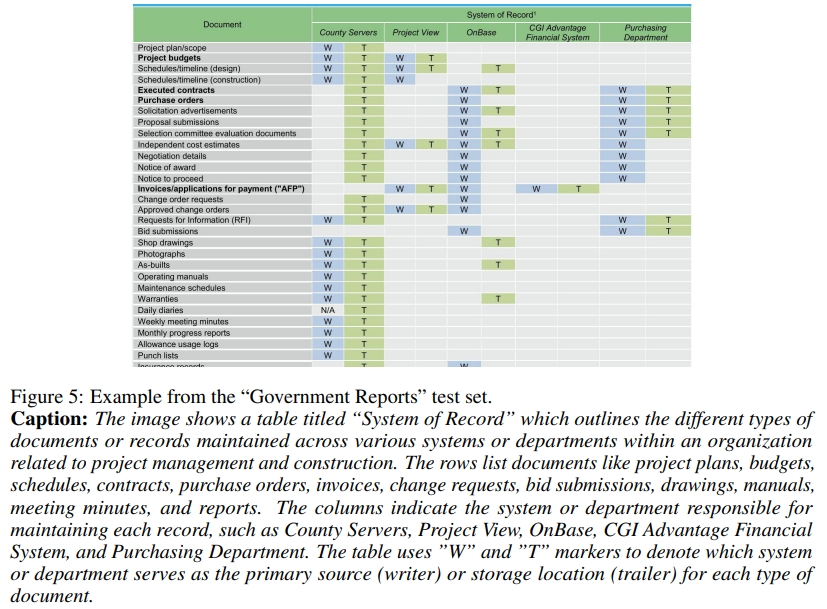
使用 Claude-3 Sonnet 為視覺豐富的文檔塊生成的標注示例如圖 5 和圖 4 所示。生成描述時使用的提示如下:

C 附加結果
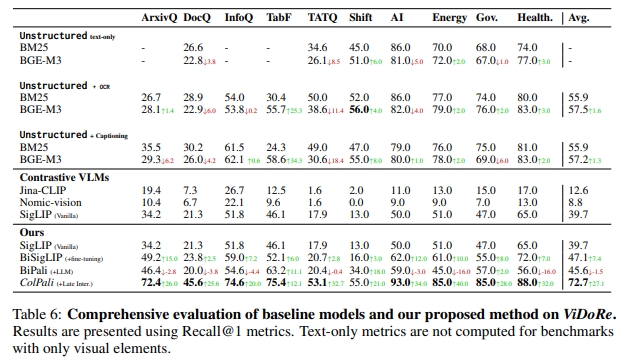
C.1 其他指標
C.2 模型變種
D 更多相似性圖
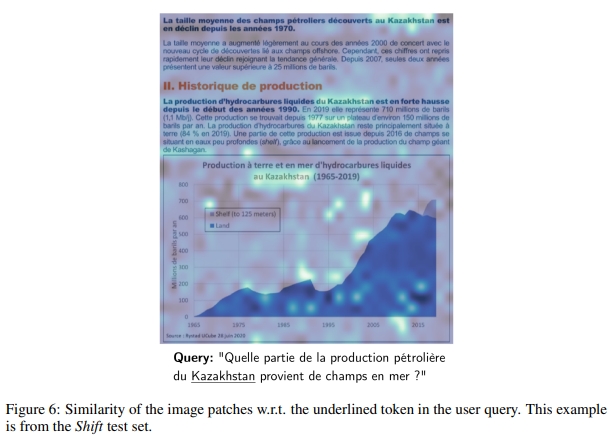
在圖6中,當給定標記時,ColPali會將“哈薩克斯坦”一詞的所有圖塊賦予較高的相似度。此外,我們的模型似乎展示了世界知識的能力,因為圍繞詞語“卡沙甘”(哈薩克斯坦的一個海上油田)的圖塊也顯示出較高的相似度分數。
還值得注意的是,這個相似性圖以及圖3(右側)顯示的圖像中都展示了一些具有較高相似度分數的白色圖塊。這個行為初看可能令人驚訝,因為白色圖塊不應該攜帶來自原始圖像的有意義信號。我們認為,這些圖塊關聯的向量與ViT寄存器(Darcet等人,2023)有類似的作用,也就是說,這些圖塊被重新用作內部計算,并存儲了整個圖像的全局信息。
E 模型術語表
1. SIGLIP
SigLIP(Sigmoid Loss for Language Image Pre-Training)基于CLIP(Contrastive Language-Image Pretraining)構建——一個通過最大化正確圖像-文本對的相似度,并最小化錯誤圖像-文本對的相似度來對齊圖像和文本的基礎模型,利用對比損失(Zhai等人,2023)。與CLIP(Radford等人,2021)不同,SigLIP使用sigmoid激活函數,而不是softmax函數。這一創新消除了對批次中所有圖像-文本對之間全局相似度的需求,使得批量大小的擴展更加靈活(每批次可達1M項,最佳批量大小為32k)。這種方法使SigLIP在零-shot圖像分類任務中實現了最先進的性能。
2. PALIGEMMA
PaliGemma是一個具有30億參數的視覺-語言模型。它將SigLIP視覺編碼器與Gemma-2B語言解碼器結合,通過多模態線性投影層連接(Lucas Beyer等人,2024)。該模型通過將圖像分割為固定數量的Vision Transformer(Dosovitskiy等人,2020)標記進行處理,并將這些標記添加到可選的文本提示中。
? PaliGemma的一個顯著特征是它作為一個前綴語言模型(Prefix-LM)運作。這種設計確保了圖像標記和用戶提供的輸入(前綴)之間 的全注意力機制,同時自動回歸地生成輸出(后綴)。這一架構使得圖像標記在處理過程中能夠訪問任務特定的查詢,從而促進更有效的任務依賴推理。
? PaliGemma的訓練分為四個階段:單模態預訓練、擴展的多模態預訓練、高分辨率短期預訓練以及任務特定的微調。
3. COLBERT
ColBERT(Contextualized Late Interaction over BERT)是一種旨在平衡信息檢索任務中的速度和效果的檢索模型(Khattab & Zaharia,2020)。傳統的檢索模型通常根據其交互類型進行分類:要么獨立地處理查詢和文檔以提高效率(雙編碼器),要么聯合處理以捕捉豐富的上下文關系(交叉編碼器)。ColBERT通過一種新的晚期交互機制結合了這兩種方法的優點。
查詢和文檔使用BERT分別進行編碼,從而實現文檔表示的離線預計算,便于擴展。ColBERT并不像其他模型那樣將嵌入池化成單一向量,而是保留了標記級別的嵌入,并使用MaxSim操作符計算細粒度的相似度分數。對于每個查詢標記,模型確定與文檔標記的最大相似度,并將這些分數加總以計算相關性。這種架構保留了深度語言模型的上下文豐富性,同時顯著提高了計算效率。通過推遲交互步驟,ColBERT支持向量相似度索引,從而在大型文檔集合中實現端到端檢索,且不會產生過高的成本。基于段落搜索數據集的實證評估表明,ColBERT與現有基于BERT的模型(Devlin等人,2018)相比,能夠在執行查詢時快上幾個數量級,并顯著降低計算需求。
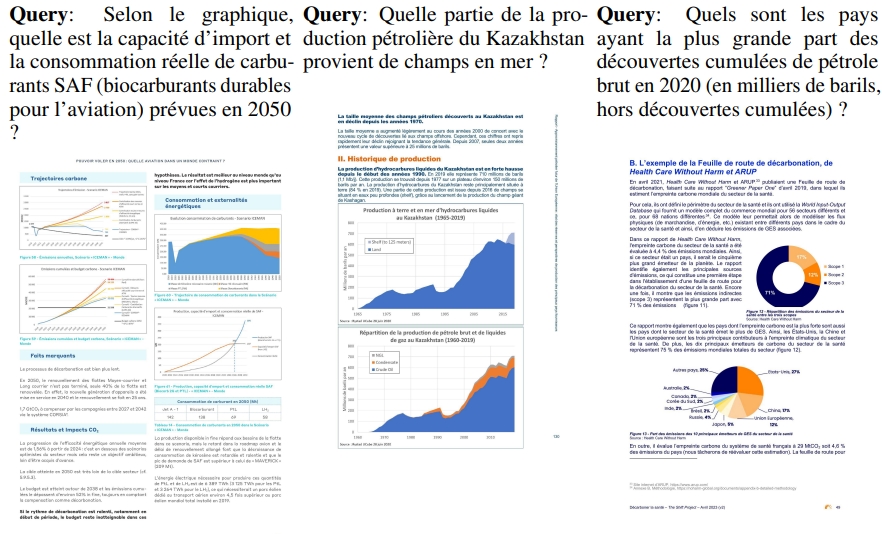
F 來自ViDoRe基準的數據示例

? 人工智能

? 醫療行業

? 政府報告

? Shift


——自適應優化系統、遺傳算法調參、Service Worker智能降級方案)




![【網絡流 圖論建模 最大權閉合子圖】 [六省聯考 2017] 壽司餐廳](http://pic.xiahunao.cn/【網絡流 圖論建模 最大權閉合子圖】 [六省聯考 2017] 壽司餐廳)
:axios有哪些常用的方法)



Hive聚合函數深度解析:從基礎統計到多維聚合的12個生產級技巧)






