
目錄:
- 第一題. 百萬級別或以上的數據如何刪除?
- 第二題. 前綴索引
- 第三題. 什么是最左前綴原則?什么是最左匹配原則?
- 第四題. B樹和B+樹的區別
- 第五題. 使用B樹和B+樹好處
第一題. 百萬級別或以上的數據如何刪除?
關于索引:由于索引需要額外的維護成本,因為索引文件是單獨存在的文件,所以當我們對數據的增加,修改,刪除,都會產生額外的對索引文件的操作,這些操作需要消耗額外的IO,會降低增/改/刪的執行效率。所以,在我們刪除數據庫百萬級別數據的時候,查詢MySQL官方手冊得知刪除數據的速度和創建的索引數量是成正比的。
- 所以我們想要刪除百萬數據的時候可以先刪除索引(此時大概耗時三分多鐘)
- 然后刪除其中無用數據(此過程需要不到兩分鐘)
- 刪除完成后重新創建索引(此時數據較少了)創建索引也非常快,約十分鐘左右。
- 與之前的直接刪除絕對是要快速很多,更別說萬一刪除中斷,一切刪除會回滾。那更是坑了。
第二題. 前綴索引
語法:index(field(10)),使用字段值的前10個字符建立索引,默認是使用字段的全部內容建立索引。
前提:前綴的標識度高。比如密碼就適合建立前綴索引,因為密碼幾乎各不相同。
實操的難度:在于前綴截取的長度。
我們可以利用select count(*)/count(distinct left(password,prefixLen));,通過從調整prefixLen的值(從1自增)查看不同前綴長度的一個平均匹配度,接近1時就可以了(表示一個密碼的前prefixLen個字符幾乎能確定唯一一條記錄)
第三題. 什么是最左前綴原則?什么是最左匹配原則?
- 顧名思義,就是最左優先,在創建多列索引時,要根據業務需求,where子句中使用最頻繁的一列放在最左邊。
- 最左前綴匹配原則,非常重要的原則,mysql會一直向右匹配直到遇到范圍查詢(>、<、between、like)就停止匹配,比如a = 1 and b = 2 and c > 3 and d = 4如果建立(a,b,c,d)順序的索引,d是用不到索引的,如果建立(a,b,d,c)的索引則都可以用到,a,b,d的順序可以任意調整。
- =和in可以亂序,比如a = 1 and b = 2 and c = 3 建立(a,b,c)索引可以任意順序,mysql的查詢優化器會幫你優化成索引可以識別的形式
第四題. B樹和B+樹的區別
- 在B樹中,你可以將鍵和值存放在內部節點和葉子節點;但在B+樹中,內部節點都是鍵,沒有值,葉子節點同時存放鍵和值。
- B+樹的葉子節點有一條鏈相連,而B樹的葉子節點各自獨立。
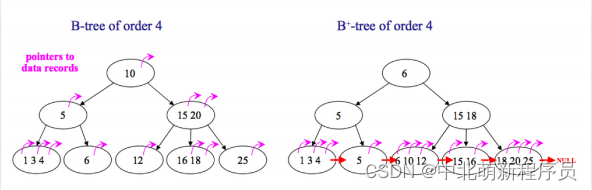
第五題. 使用B樹和B+樹好處
使用B樹的好處
B樹可以在內部節點同時存儲鍵和值,因此,把頻繁訪問的數據放在靠近根節點的地方將會大大提高熱點數據的查詢效率。這種特性使得B樹在特定數據重復多次查詢的場景中更加高效。
使用B+樹的好處
由于B+樹的內部節點只存放鍵,不存放值,因此,一次讀取,可以在內存頁中獲取更多的鍵,有利于更快地縮小查找范圍。 B+樹的葉節點由一條鏈相連,因此,當需要進行一次全數據遍歷的時候,B+樹只需要使用O(logN)時間找到最小的一個節點,然后通過鏈進行O(N)的順序遍歷即可。而B樹則需要對樹的每一層進行遍歷,這會需要更多的內存置換次數,因此也就需要花費更多的時間
如果我的內容對你有幫助,請點贊,評論,收藏。創作不易,大家的支持就是我堅持下去的動力

















)


