一、🌐 WAIC 2025 大會看點:AI 正在“長出眼睛與身體”
在 2025 年的人工智能大會(WAIC 2025)上,“大模型退幕后,具身智能登場”成為最具共識的趨勢轉向。從展區到主論壇,再到各大企業發布的新品線,可以清晰看到:AI 正在告別純“云上智囊”式的角色,逐步邁向物理世界中的可視化、可移動、可感知的具身智能系統。

🧠 什么是“具身智能”?它不僅是能動的機器人,更是“有眼、有腦、有反饋”的感知閉環
具身智能(Embodied Intelligence)不是一個新詞,但它在 2025 年被重新定義:
-
不再只指仿生機器人或機械臂;
-
而是強調AI 在物理世界中擁有“主動感知 + 實時反饋 + 自主控制”能力;
-
即:AI 擁有“身體”(運動執行器)、“眼睛”(視頻輸入系統)、“神經”(低延遲數據通道)、“大腦”(模型推理單元);
在今年的 WAIC 2025 上,大量具身 AI 產品亮相,包括:
| 代表設備 | 特點 |
|---|---|
| 🤖 人形機器人 | 全身關節控制 + 多視角相機融合,強調動作實時糾偏 |
| 🚁 無人機智能編隊 | 基于視覺感知的自主避障與協同飛行,依賴高清視頻流回傳 |
| 🏭 工業協作臂 | 集成視頻 + 力覺傳感,進行動態環境理解與位置自適應 |
| 🕶 XR感知頭顯 | 實時圖傳與環境識別輔助遠程操控或協同決策 |
這些系統背后的共同特征是:實時視頻流成為 AI 感知的主輸入,視頻質量、延遲、幀同步等技術指標決定了智能行為是否可靠。
🔍 從“對話式AI”到“感知式AI”,核心轉折點就是“看見世界”
過去幾年,AI 的主旋律是 ChatGPT 引領的自然語言處理與云端大模型,它們擅長理解文本、生成內容、總結知識。
但它們對現實世界看不見、摸不著、感受不到,注定只能是輔助類智能。
而今天的 AI 系統需要:
-
識別畫面中人的行為;
-
跟隨移動物體;
-
實時避障導航;
-
精確感知并執行復雜任務。
這一切的前提,是AI 要具備視頻級感知能力,甚至像人一樣從視頻中“學習與行動”。
這就讓原本“邊緣模塊”的視頻輸入,變成了 AI 系統真正的“第一感官”。
🎥 視頻入口:AI具身智能系統中不可忽視的關鍵基礎設施
具身智能從“研究概念”走向“行業系統”,背后正是視頻輸入與處理技術的成熟推動:
| 能力維度 | 技術要求 |
|---|---|
| 延遲 | 視頻采集至推理處理必須控制在 100–250ms 之內 |
| 穩定性 | 斷網重連、流中斷恢復、碼流切換必須支持 |
| 多平臺部署 | 能適配機器人、頭顯、工業盒子、移動端等多種硬件形態 |
| 可編程性 | 支持幀級數據回調(YUV/RGB/裸流),便于對接 AI 模型 |
| 多協議兼容 | 能處理 RTSP、RTMP、HTTP-FLV 等多類型視頻流源 |
這背后所依賴的,正是一套工程級、可控、穩定的低延遲視頻輸入 SDK,它不再是“播放工具”,而是支撐整個 AI 感知系統的大動脈。
二、🎯 AI 進入“視頻驅動時代”:感知輸入成為核心挑戰
隨著 AI 從云端大模型演進到“具身智能”,感知輸入的重要性正在迅速上升。
如果說過去的 AI 靠“大模型 + 大數據”推動的是知識智能,那么現在的 AI 系統——無論是機器人、無人機還是智能頭顯——都必須靠攝像頭、傳感器、音視頻流來“看見”和“理解”真實世界。
而視頻,正在取代傳統結構化數據,成為 AI 系統的第一感知源頭。
📌 為什么“視頻感知”如此關鍵?
| 感知維度 | 視頻感知的價值 |
|---|---|
| 🧠 認知理解 | 從實時畫面中提取行為、動作、目標,成為 AI 推理的基礎 |
| 🧍 具身反饋 | 驅動機器人控制、避障導航等動作的依據 |
| 🔄 環境適應 | 根據場景變化動態調整策略(如工業臂避讓、巡檢轉向) |
| 📊 AI訓練數據源 | 視頻回流供離線分析/標注/微調,持續提升模型性能 |
| 🌐 多模態融合 | 視頻+語音+IMU/GPS 構成完整的感知輸入鏈路 |
📉 感知輸入的現實挑戰有哪些?
雖然視頻成為主流感知入口,但在工程落地中,以下問題反復出現:
| 挑戰維度 | 典型表現 | 技術影響 |
|---|---|---|
| 延遲問題 | 攝像頭到 AI 推理間延遲秒級 | 導致識別/控制滯后,無法閉環 |
| 幀數據不可控 | 無法獲取穩定 YUV/RGB 回調幀 | 無法對接 AI 模型或幀級標注工具 |
| 播放模塊通用化嚴重 | 采用 VLC 等通用播放器無回調能力 | 無法參與智能分析,僅能觀看 |
| 協議/分辨率不統一 | 攝像頭RTSP、無人機裸流、視頻文件混合輸入 | 系統需要自行轉碼,資源浪費嚴重 |
| 平臺割裂 | 需要在 Unity、Android、Linux、嵌入式中統一處理視頻輸入 | 跨平臺開發成本高、維護困難 |
| 弱網不穩定 | 網絡抖動/斷流無自動恢復機制 | 視頻輸入鏈斷裂,系統失效風險大 |
🧭 具身智能背景下,視頻入口模塊的新要求
為支撐 AI 系統高質量感知輸入,視頻處理模塊必須從“播放器”轉型為“可控、可嵌入、可協同”的輸入通道:
| 能力要求 | 描述 |
|---|---|
| ? 實時性保障 | 視頻接入至可用數據輸出的總鏈路延遲需控制在 100–250ms |
| ? 數據開放性 | 支持 YUV、RGB、碼流、幀時間戳等數據結構直接回調 |
| ? 跨協議解碼能力 | 無需依賴云端,邊緣端即可解碼 RTSP / RTMP / 裸碼流等 |
| ? 平臺兼容性強 | 同一套接口兼容 Unity、Android、Linux、頭顯等系統 |
| ? 邊緣運行能力 | 可運行在工業盒子、AI終端等本地硬件中,長時間穩定 |
| ? 異常恢復機制 | 自動重連、弱網補償、狀態上報,保障流暢輸入不中斷 |
? 小結:感知入口,決定智能閉環是否成立
如果說“大模型決定了AI的上限”,
那么“視頻輸入能力決定了AI是否能真正落地”。
沒有高質量、低延遲、結構化可控的視頻輸入,AI 系統就無法真正“看見世界”;
沒有標準化、可嵌入的輸入模塊,具身智能也只能停留在實驗室。
三、如何打造具身智能時代的“視頻神經系統”?
在 AI 正全面邁向“可視化、可感知、可操控”的具身智能階段,視頻輸入模塊早已不再是可有可無的“播放器插件”,而是智能系統中與推理引擎并列的重要組成部分。
大牛直播SDK憑借其工程穩定性、低延遲、平臺適配廣、數據可控度高的優勢,逐步確立了在眾多“AI 具身系統”中的感知入口標準模塊地位,被廣泛應用于:
-
工業機器人智能視覺
-
無人機回傳與控制
-
XR 沉浸式感知終端
-
AI邊緣盒子與遠程識別系統
-
多模態智能協作平臺
? 大牛直播SDK架構總覽:為“看得見 + 反饋快 + 可編程”而生
以下是大牛直播SDK的典型模塊結構,圍繞AI視頻輸入場景專門設計:
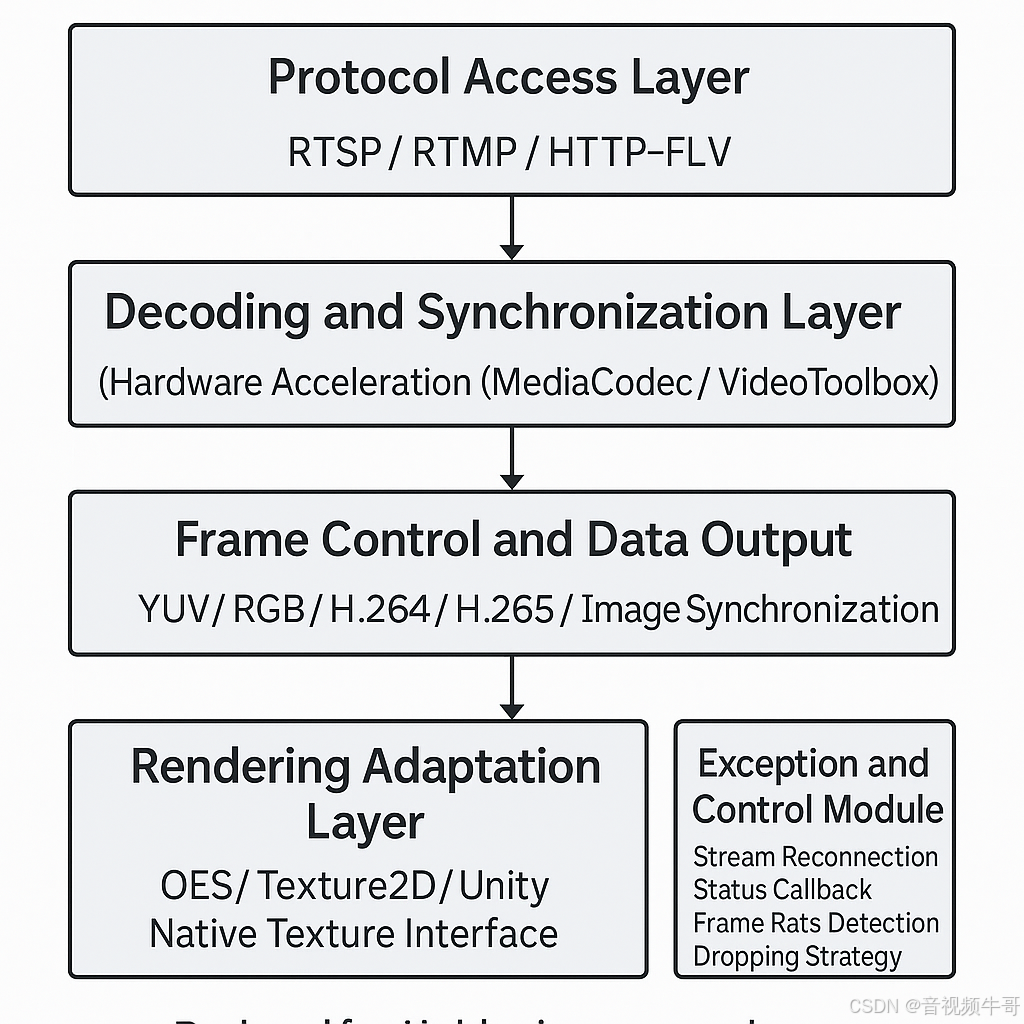
🎯 技術優勢一覽:解決“具身 AI 視頻輸入”的六大關鍵問題
| 問題維度 | 傳統方案 | 大牛直播SDK的優勢 |
|---|---|---|
| 延遲控制 | 秒級常態,受限于緩沖機制 | 即到即播架構,實測延遲 100–250ms 內,首幀快啟 <200ms |
| AI對接能力 | 通用播放器無 YUV/RGB 回調,難集成模型 | 原生支持 YUV、RGB、碼流裸流回調,幀級時間戳、格式元信息可同步傳出 |
| 平臺兼容性 | FFmpeg等開源方案維護復雜,頭顯/嵌端難適配 | 全平臺適配(Android/iOS/Linux/Windows/Unity/Pico/Quest)一套接口多端部署 |
| 協議兼容性 | 多源混流需自行封裝切換 | 內建多協議接入(RTSP/RTMP/HTTP-FLV),支持動態切流 |
| 異常容錯 | 無斷流處理,播放容易中斷 | 支持斷流自動重連、網絡波動恢復、弱網緩沖優化 |
| 渲染效率 | CPU-GPU 數據頻繁拷貝,耗電高、發熱大 | 支持 OES 紋理 + Unity Shader 渲染,避免冗余傳輸,適配XR頭顯實時播放 |
🚀 高度可嵌入:為 AI 系統打造“類驅動級”感知能力
大牛直播SDK不僅僅是“播放器引擎”,更像是一個可內嵌、可調度、可編排的視頻輸入中間件,其特點包括:
-
? SDK即插件:體積輕,易嵌入,單進程內運行,不依賴外部組件;
-
? 可編程控制:每幀數據可通過 C/C++/Java/C# 回調,供模型分析或保存;
-
? 與AI推理流并行處理:支持邊解碼邊回調、邊渲染邊分析,保證視頻與控制邏輯同步;
-
? 配合邊緣計算節點:可運行在 Jetson、RK、全志等 AI SOC 上,與本地模型閉環協作;
-
? 與Unity深度適配:用于構建 XR 可視系統、工業仿真平臺、遠程交互終端等。
🧬 技術應用延伸:不僅“能播”,更“能用”在AI實際場景中
| 應用領域 | 能力體現 |
|---|---|
| 工業檢測 | 高幀率 RTSP、RTMP攝像頭輸入,YUV回調供圖像缺陷檢測模型處理 |
| 無人機圖傳 | 實時回傳延遲100-250ms,支持 AI 駕駛輔助與目標跟蹤 |
| XR可視終端 | Unity 中低延遲視頻貼圖,無縫融合場景交互與視覺感知 |
| 智能交通 | 多路攝像頭接入 + 分流播放,供 AI 識別異常車輛、交通違章 |
| 醫療輔控 | 遠程視頻采集 + 回調 + 云端模型識別,實現遠程診斷或機器人輔助操作 |
? 小結:不是播放器,而是“視覺通感接口層”
Android平臺Unity共享紋理模式RTMP播放延遲測試
在具身 AI 系統中,視頻輸入不再是單向播放,而是交互系統的核心感官通道。
大牛直播SDK通過完整的接入-解碼-回調-渲染鏈路,為 AI 感知系統提供了工程級“視頻神經元”,幫助它:
-
快速感知世界;
-
高效獲取畫面;
-
與識別推理模塊實時交互;
-
構建具身智能中的“視覺閉環”。
這不再是播放器,而是讓 AI 真正“看得清、看得快、看得穩”的關鍵技術基礎。
四、📦 面向未來:AI系統中的“視頻入口層”標準化趨勢
隨著 AI 從“可計算”走向“可具身”,系統架構正經歷深刻的演變。尤其在機器人、無人機、工業終端、安防平臺等具身智能落地場景中,“視頻入口層”正成為與算法模型、執行控制并列的核心模塊。
而在這個系統中,視頻輸入不再只是被動的信號源,而是承擔著“感知感官”的角色。一個穩定、低延遲、結構化的視頻入口,將直接決定 AI 系統是否具備可用性、實時性與閉環能力。
🔍 未來 AI 系統的感知架構趨勢:入口層地位持續上升
具身智能系統的標準感知鏈條逐步清晰:
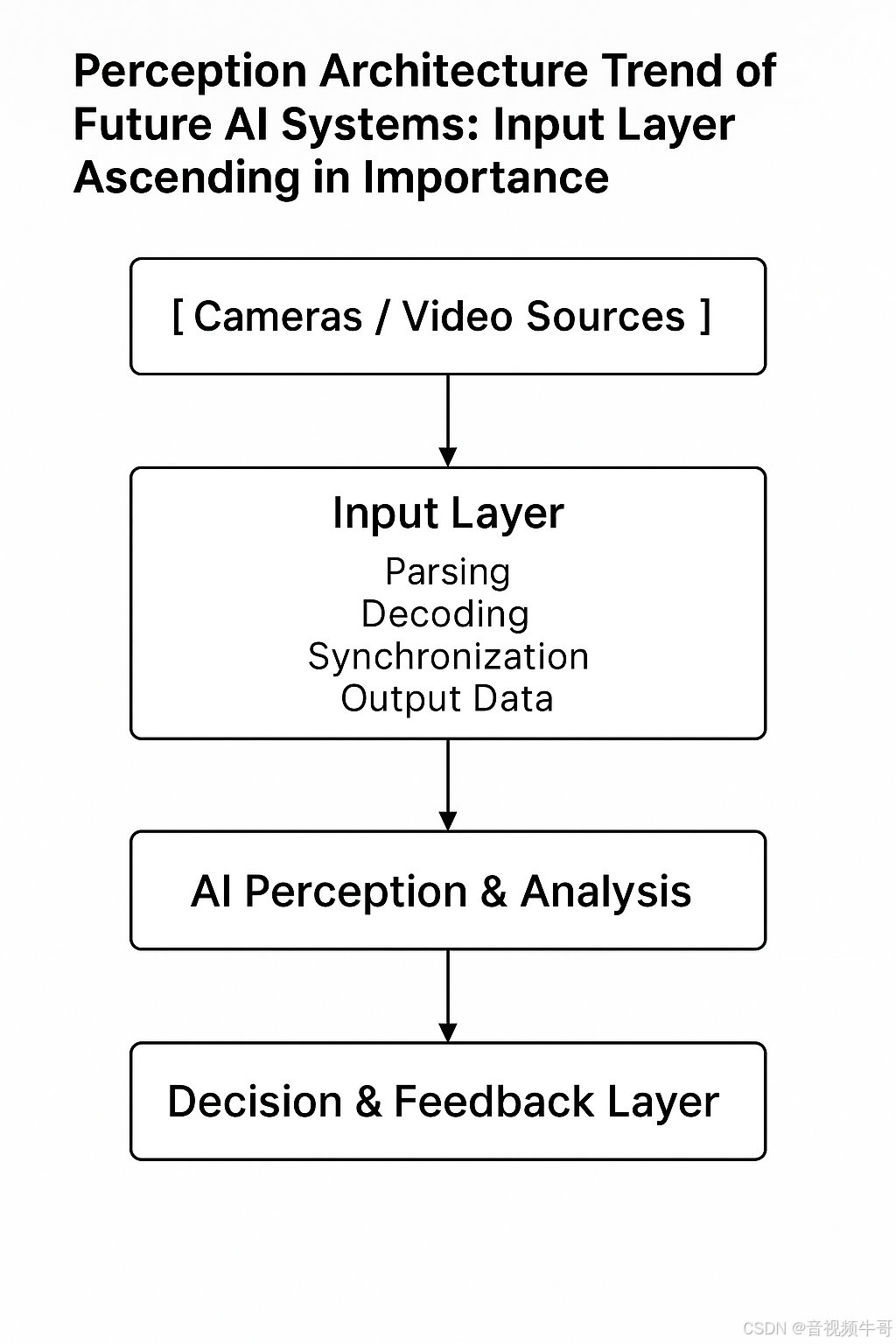
過去,這一流程的“入口層”往往使用開源播放器或簡單軟解處理,而未來,視頻入口將承擔以下核心職責:
| 核心職責 | 技術要求 |
|---|---|
| 📶 多源接入 | 支持 RTSP/RTMP/HTTP-FLV等主流流媒體協議 |
| 🧩 可編排性 | 視頻數據幀級輸出,支持與 AI 模型并行處理 |
| 🧠 智能協同 | 可嵌入到 AI 系統中與識別/控制模塊高效協作 |
| 🖥 跨平臺適配 | 可運行在 Unity/Android/Linux/邊緣盒子等平臺 |
| ? 異常恢復 | 網絡波動自動重連,斷流可自愈 |
| 📊 狀態可觀測 | 可回調幀率、延遲、錯誤碼、播放狀態等指標 |
📈 視頻入口標準化的三大發展趨勢
| 發展趨勢 | 描述 | 典型應用體現 |
|---|---|---|
| ① 低延遲解碼標準化 | 從“緩沖優先”轉向“即時送幀、邊解碼邊用” | AI控制系統、VR頭顯遠程交互 |
| ② 幀級數據開放 | 從“黑盒播放”轉向“YUV/RGB 回調 + 元信息結構化輸出” | 視頻結構化識別、AI推理接口 |
| ③ 跨平臺嵌入標準化 | 支持同一 SDK 在多平臺部署,支持嵌入運行 | 多端部署的邊緣 AI 模塊 / XR設備 |
🧠 為什么說視頻入口是“智能系統的神經起點”?
類比人體神經系統:
-
攝像頭等設備 = 感官;
-
視頻入口 = 神經元突觸,負責編碼并將感知信號送入大腦;
-
AI模型 = 大腦皮層,進行判斷與思考;
-
執行控制層 = 肌肉系統,執行反應行為。
如果視頻入口斷、卡、延遲,整個“感知—思考—反饋”鏈條就中斷,系統將陷入“盲視狀態”,即便算法模型再強,也無法真實響應世界。
🧩 大牛直播SDK的架構思路:先定義標準,再覆蓋平臺
在應對這些趨勢中,像大牛直播SDK這類工程化組件,已經通過如下方式實現了視頻入口標準化能力:
| 架構策略 | 落地能力 |
|---|---|
| 📦 解耦式模塊封裝 | 協議解析 / 解碼 / 渲染 分離,易于嵌入與替換 |
| 🛠 標準接口回調 | C/C++/C#/Java 多語言接口,數據結構統一 |
| 🌍 全平臺兼容 | Unity、Android、iOS、Windows、Linux 全覆蓋 |
| 📡 多協議接入 | RTSP/RTMP/HTTP-FLV 自動適配、可切流 |
| ?? 狀態監控完善 | 延遲、幀率、錯誤碼、解碼信息全部可回調 |
| 💾 資源輕量可控 | 支持低功耗設備運行,適配嵌入式/ARM平臺 |
? 小結:AI 時代的“視頻入口層”,應當具備三性合一
| 能力 | 含義 |
|---|---|
| 標準化 | 統一接口、協議、回調,降低系統復雜度 |
| 工程化 | 穩定、可監控、支持部署與遠程管理 |
| 智能協同化 | 能與模型推理、控制系統、回傳機制實時互動 |
正是這三性融合,讓“視頻入口”從播放模塊變成 AI 系統的“神經核心”。
五、🚀 總結:AI系統的“眼睛”,值得用工業級方案來構建
在具身智能的新時代,AI 不再只是“算力中心”或“語言接口”,而正逐步演化為能看、能感、能動的系統。而“看”的這一步,正是由視頻輸入能力所決定。
過去,我們或許可以用開源播放器湊合展示一段視頻流;但在如今機器人控制、無人機避障、XR 實時渲染、工業瑕疵檢測這些強依賴視頻實時性與結構化感知的場景下,“視頻播放”已經轉變為“視頻神經系統”。
? 為什么視頻輸入模塊值得“工業級對待”?
| 關鍵能力 | 對AI系統的影響 |
|---|---|
| ? 低延遲 | 決定系統是否“來得及反應”,特別關鍵于控制閉環 |
| 🎯 數據結構化 | 決定能否用于模型識別、行為判斷等智能推理 |
| ?? 跨平臺嵌入能力 | 決定是否可部署于真實應用環境中的邊緣終端 |
| 🔄 異常容錯能力 | 決定系統能否在復雜/弱網/斷流情況下持續運行 |
| 🧠 協同控制能力 | 決定視頻是否能與 AI 模型、控制邏輯同步配合 |
這些能力不是 VLC 播放器、FFmpeg 解碼片段可以“拼”出來的,而必須通過專業的、工程化的 SDK 方案系統構建。
🧩 為什么說視頻輸入是“智能閉環”的第一步?
如果把一個具身 AI 系統比作“智能生命體”,那么:
-
視頻流 = 感官
-
視頻輸入模塊 = 神經中樞入口
-
AI 模型 = 大腦
-
控制執行 = 肌肉
一個無法看清楚、無法快速感知外界的“生命體”,是不可能做出正確判斷、也無法安全地與環境交互的。
🧠 結語:選擇“專業的視頻入口”,是對整個 AI 系統的尊重
“你為 AI 系統選擇的視頻輸入方式,就是你對其認知與行動能力上限的定義。”
這不是一句口號,而是過去數年中大量 AI 應用工程實踐得出的經驗結晶:
-
工業現場不等人,延遲必須受控;
-
機器人不容錯,數據必須完整;
-
多模態不亂配,接口必須開放;
-
云邊不割裂,架構必須統一。
因此,在 AI 系統中構建“眼睛”時,請放下“能播就行”的幻想,轉向一個真正為智能系統設計的工業級視頻輸入框架。
更令人欣慰的是,在本次 WAIC 2025 大會上,我們也看到了許多來自無人機視覺、工業檢測、XR遠程協作、AI盒子系統等領域的客戶與合作伙伴,他們正是通過大牛直播SDK將“可控、可嵌入的視頻能力”部署進了具身智能項目之中。
在這個“AI長出眼睛和身體”的關鍵時代,能為這些真正落地的智能系統提供一部分“視覺神經”,既是技術積累的結果,也是一份值得珍惜的參與感。
這不是播放器,這是 AI 時代的感知基礎設施。
??📘 CSDN官方博客專欄:音視頻牛哥-CSDN


(通過SO文件過檢測原理))
















