寒假作業Day 03
一、選擇題

在C語言中,字符型指針char *p;通常用于指向字符數組(即字符串)的首字符。對于給定的選項,我們來分析每一個選項是否可以將字符串正確地賦值給p:
A: p=getchar();
getchar()函數從標準輸入讀取一個字符,并返回該字符的ASCII值。由于getchar()返回的是一個int類型的值(它可能是EOF,即文件結束標記,這是一個負值),所以直接將這個返回值賦給char *類型的p是不正確的。此外,即使忽略類型不匹配的問題,getchar()也僅僅讀取一個字符,而不是整個字符串。
B: scanf(“%s”,p);
這個語句試圖從標準輸入讀取一個字符串并存儲在p指向的位置。然而,這個語句有潛在的風險。因為p沒有被初始化指向一個有效的內存區域(即一個足夠大的字符數組),scanf可能會寫入一個隨機的內存位置,這可能會導致程序崩潰或未定義的行為。
C: char s[]=“china”; p=s;
這個語句是正確的。它首先定義了一個字符數組s并初始化為字符串"china"。然后,它將p指向s的首字符,即s[0](即’c’)。這樣,p就指向了一個有效的字符串。
D: *p=“china”;
這個語句是錯誤的。首先,*p表示p指向的字符,它是一個char類型的變量。然而,字符串"china"是一個字符數組,不是一個單個的字符。此外,你不能直接將一個字符串字面量賦給一個char類型的變量。
綜上所述,選項A、B和D都不能正確地將字符串賦值給字符型指針p。因此,正確答案是A、B和D。
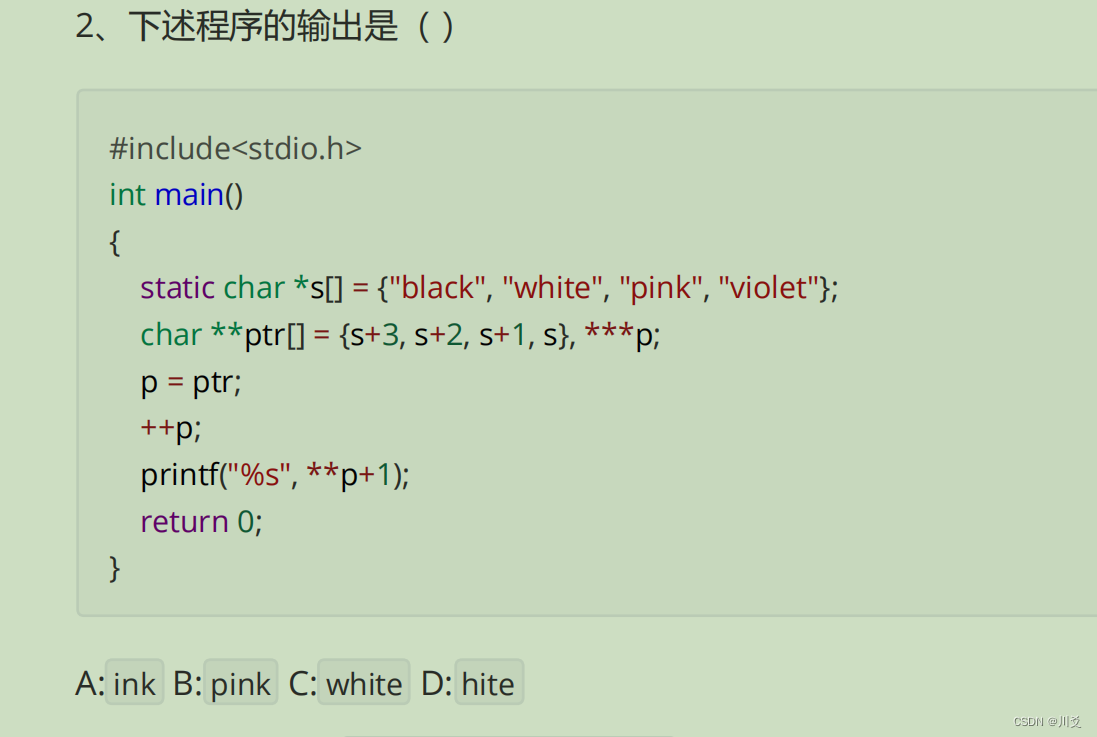
接下來,我們逐步分析:
static char *s[] = {“black”, “white”, “pink”, “violet”};
這里定義了一個靜態的字符串數組s,包含四個字符串元素。
char **ptr[] = {s+3, s+2, s+1, s}, ***p;
這里定義了一個名為ptr的指針數組,每個元素都是一個指向字符指針的指針。s+3、s+2、s+1和s分別指向s數組中的第四個、第三個、第二個和第一個字符串的起始地址。
所以,ptr數組的內容如下:
* ptr[0] 指向 "violet"
* ptr[1] 指向 "pink"
* ptr[2] 指向 "white"
* ptr[3] 指向 "black"
- p = ptr;
這里定義了一個名為p的指針,它指向一個指針的指針。然后將p指向ptr。- ++p;
將p的值增加1,由于p是一個指向指針的指針的指針,所以p現在指向ptr數組的下一個元素,即ptr[1],它指向"pink"。- printf(“%s”, **p+1);
這里有兩個*,所以**p首先解引用p,得到ptr[1],然后再次解引用得到"pink"。接著,**p+1將指針向前移動一個字符,指向’i’。因此,輸出的是從’i’開始的字符串,即"ink"。
總結:該程序的輸出是"ink"。

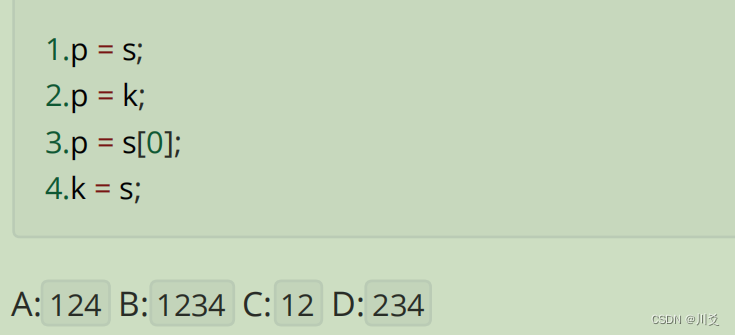
首先分析語句,char s[3][10]是一個3行10列的二維字符數組,char (*k)[3]是一個包含3個元素的字符指針數組,char *p是一個字符指針;
分析選項:1、p = s;:這是錯誤的。s是一個二維數組,其名字s在大多數上下文中會被解釋為指向其首行(即s[0])的指針,該指針的類型是char ( *)[10](指向包含10個字符的數組的指針)。但p是一個char *,即指向單個字符的指針。類型不匹配,所以這是錯誤的。
2、p = k;:這也是錯誤的。k是一個指向包含3個字符的數組的指針,即char ( *)[3]。但p是一個指向單個字符的指針,即char * 。類型不匹配。
3、p = s[0];:這是正確的。s[0]是s的第一行,它是一個包含10個字符的一維數組。在大多數上下文中,數組名s[0]會被解釋為指向其首元素的指針,即指向s[0][0]的指針。這個指針的類型是char *,與p的類型相同。
4、k = s;:這也是錯誤的,盡管可能看起來是正確的。s的名字在大多數上下文中會被解釋為指向其首行(即s[0])的指針,其類型是char ( * )[10](指向包含10個字符的數組的指針)。但k的類型是char ( *)[3],即指向包含3個字符的數組的指針。盡管s的首行確實有3個字符的空間(實際上是10個),但k和s的指針類型并不匹配,因此這是錯誤的。
故選擇答案A,只有選項3是正確的
4、假設 sizeof(void * ) 為4, sizeof(char) 為1,那么對于 char str[sizeof(“ab”)]; , sizeof(str) 的值是( )
A: 2 B: 3 C: 4 D: 代碼無法編譯
sizeof(“ab”)的值為3,其中有a,b和\0;char str[3],即str是有3個元素的字符數組,故sizeof(str)的值為3*1=3,選B
5、有如下程序段,則對函數 fun 的調用語句正確的是【多選】( )
char fun(char *);
int main()
{char *s = "one", a[5] = {0}, (*f1)(char *) = fun, ch;return 0;
}
A: * f1(&a); B: f1( * s); C: f1(&ch); D: ch = * f1(s);要改成( * f1)(s)才正確
首先,我們分析給定的程序段:
定義了一個函數fun,它接受一個字符指針作為參數,并返回一個字符。
在main函數中:
定義了一個字符指針s,指向字符串"one"。
定義了一個字符數組a,大小為5,并全部初始化為0。
定義了一個函數指針f1,它指向函數fun。這意味著f1可以用來調用fun函數。
定義了一個字符變量ch。
接下來,我們分析每個選項:
A: *f1(&a);
這是錯誤的。因為&a得到的是指向數組a的指針,但它的類型是char (*)[5],而不是char *。此外,*f1的解引用方式也是不正確的,應該是(*f1)(…)。
B: f1(*s);
這是錯誤的。*s得到的是s指向的字符串的第一個字符,即’o’。但fun函數期望一個字符指針作為參數,而不是一個字符。此外,調用函數指針的正確方式是(*f1)(…)。
C: f1(&ch);
這是錯誤的。雖然&ch得到的是一個字符指針,但是調用函數指針的正確方式是(*f1)(…)。
D: ch = *f1(s); 要改成 ( f1)(s) 才正確。
原始表達式f1(s)是錯誤的,因為它試圖先調用函數然后解引用返回的結果,但函數的返回類型不是指針。正確的調用方式是(*f1)(s),并且由于fun的返回類型是char,所以可以將返回值賦給ch,即ch = (*f1)(s);
二、編程題

方法1:qsort排序之后使用strcmp比較兩個字符串
int cmp(const void* _a,const void * _b){char a=*(char*)_a,b=*(char*)_b;return a-b;
}bool CheckPermutation(char* s1, char* s2){if(strlen(s1)!=strlen(s2))return false;qsort(s1,strlen(s1),sizeof(char),cmp);qsort(s2,strlen(s2),sizeof(char),cmp);return strcmp(s1,s2)==0;
}
方法二:哈希表
如果兩個字符串中的字符重新排列后相等,其實也就說明其中的字符種類和其數量是一致的,所以我們可以用一個頻次數組來記錄,在s1數組中碰到字符就增加其頻數,而在s2中則是減少頻數,如果其中一個頻數小于0,就說明兩者不相等
bool CheckPermutation(char* s1, char* s2){if(strlen(s1)!=strlen(s2))return false;int table[128]={0};for(int i=0;i<strlen(s1);i++){table[s1[i]]++;//對應下標頻數增加}for(int i=0;i<strlen(s2);i++){table[s2[i]]--;//對應下標頻數減少if(table[s2[i]]<0)return false;}return true;
}
哈希表
我們舉出幾個回文數的例子,比如abccba,abcccba,a和不是回文數的例子,比如ab,abc,abcd,abcddeba…我們會發現,如果是回文數,頂多有一個數出現的次數為奇數;而如果不是,則一定會出現兩個及以上的數出現的次數為奇數,通過這個,我們可以用哈希表記錄頻數,并記錄奇數次的個數
bool canPermutePalindrome(char* s){int table[128]={0};int count=0;for(int i=0;i<strlen(s);i++){table[s[i]]++;}for(int i=0;i<128;i++){if(table[i]%2==1){count++;}if(count>=2){return false;}}return true;
}


】)
)

)

)


![[LeetBook]【學習日記】類鏈表反轉——尋找倒數第cnt個元素](http://pic.xiahunao.cn/[LeetBook]【學習日記】類鏈表反轉——尋找倒數第cnt個元素)


)





