總結
本系列是機器學習課程的第02篇,主要介紹機器學習中專家系統的應用介紹
本門課程的目標
完成一個特定行業的算法應用全過程:

定義問題(Problem Definition) -> 數據收集(Data Collection) -> 數據分割(Dataset Spit up) -> 模型訓練(Model Training) -> 模型評估(Model Evaluation) -> 應用部署(System Deployment) -> 改變世界(Impact the world)!
作者:adi0229
鏈接:「ML筆記」- 機器學習生命周期(Machine Learning Lifecycle)
懂業務+會選擇合適的算法+數據處理+算法訓練+算法調優+算法融合
+算法評估+持續調優+工程化接口實現
機器學習算法流程
關于機器學習的定義,Tom Michael Mitchell的這段話被廣泛引用:
對于某類任務T和性能度量P,如果一個計算機程序在T上其性能P隨著經驗E而自我完善,那么我們稱這個計算機程序從經驗E中學習。

機器學習流程
為了更好的理解機器到底是如何獲得學習能力的,我們可以思考人類學習的過程,想象一個小孩子學習認知動物的過程,我們帶小孩去公園。公園里有很多人在遛狗。簡單起見,咱們先考慮二元分類例子。你告訴小孩哪些是狗。假設此時一只貓跑了過來,你告訴他,這個不是狗。久而久之,小孩就會產生認知模式。這個就是“學習”的過程。所形成的認知模式,就是“模型”。訓練之后。這時,再跑過來一個動物時,你問小孩,這個是狗吧?他會回答,是/否。這個就叫“預測”。仔細思考小朋友認知事物的例子,我們發現在這個學習過程當中,我們可以把學習過程拆分為如下步驟

1.選擇知識即小朋友選擇認知動物外貌這樣的一個知識,
2.選擇學習方法即選擇一個合適的方法去學習知識,在例子中我們是通過眼睛辨認這樣的方法進行學習,
3學習或記憶,即反復對動物外面進行認知學習的這一過程,
4.運用,小孩進行大量認知記憶的練習后,可以將所知的認知對動物進行辨別,
5.評測學習效果,站在一個客觀的角度對學習效果進行評測,
6.知識保存,通過大人的評測后,小孩就會將這個知識保存在自己的腦海中。這不就是一個人類典型的學習過程嗎?那么基于這樣的一個學習過程,我們是否可以將這個過程復制在機器上呢?其實我們已經這樣做了,而構建機器學習的過程,即構建機器學習框架的步驟正和人類學習的步驟是一樣的。

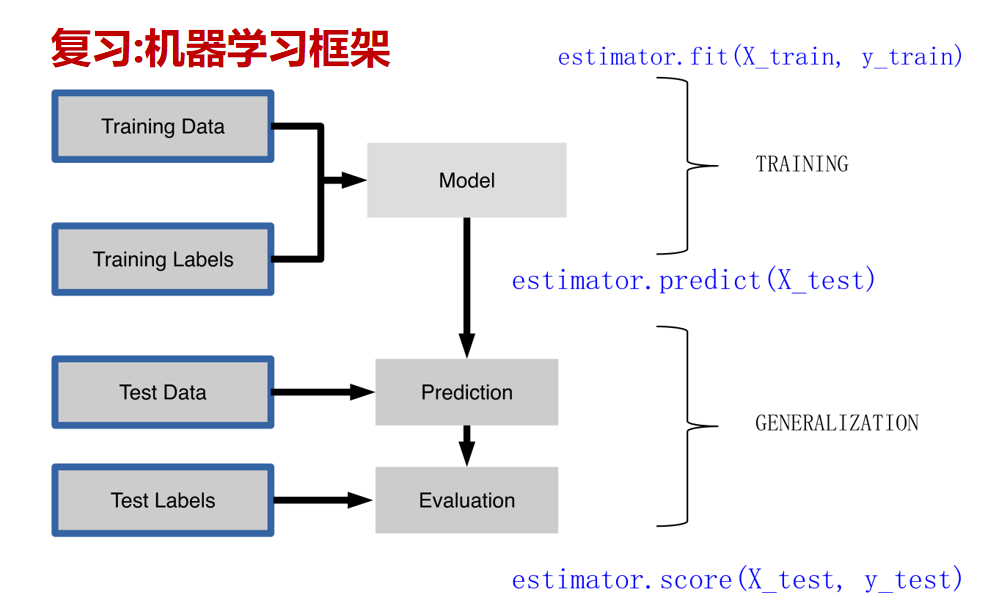
(1)在此,我們模仿人類學習的行為方式,將這樣的行為方式復制于機器上,并且形成一一對應的關系,從而得到了機器學習的框架,我們仔細了解機器學習框架后會發現,機器學習的步驟是與人類學習行為的步驟一致的,可分為數據的加載,選擇模型,模型的訓練,模型的預測,模型的評測,模型的保存6個步驟,第一步數據的加載即為選擇知識,表示的是我們希望計算機學習什么樣的知識(數據),因為機器需要從過往經驗中學習知識,因此我們第一步需要做的事就是為其提供可學習的數據。
(2)緊接著第二步我們需要為計算機選擇一個學習的模型,即選擇一個學習的方法使計算機依據模型進行學習。
(3)第三步模型的訓練為為計算機根據設定的方法對數據進行反復訓練的過程。
(4)第四步,預測,指計算機再進行大量數據認識的訓練后,可以將所知的認知對新事物進行應用,即對未知數據的預測等。
(5)第五步評測,指的是一個客觀的角度(測試指標)對計算機學習效果進行評測。
(6)最后是將學習過程進行保存,便于將來使用,通過這樣的對應,我們可以發現,機器學習的思想并不復雜,僅僅是對人類在生活中學習成長的一個模擬。

那如何才能實現機器學習模型呢?sklearn是機器學習中一個常用的python第三方模塊,自2007年發布以來,scikit-learn已經成為Python重要的機器學習庫了。scikit-learn簡稱sklearn,支持包括分類、回歸、降維和聚類四大機器學習算法。還包含了特征提取、數據處理和模型評估三大模塊。sklearn是Scipy的擴展,建立在NumPy和matplotlib庫的基礎上。利用這幾大模塊的優勢,可以大大提高機器學習的效率。sklearn擁有著完善的文檔,上手容易,具有著豐富的API,在學術界頗受歡迎。sklearn已經封裝了大量的機器學習算法,包括LIBSVM和LIBINEAR。同時sklearn內置了大量數據集,節省了獲取和整理數據集的時間。

sklearn庫的框架
train_x, train_y, test_x, test_y = getData()
model = somemodel()
model.fit(train_x,train_y)
predictions = model.predict(test_x)
score =score_function(test_y, predictions)
joblib.dump(model, 'filename.pkl')
"""
構建一個機器學習框架似乎并不容易實現,好在我們的scikit-learn模塊已經幫我們搭建好,
如上,這簡單的六行代碼顯示了使用scikit-learn模塊構建機器學習框架的六個部分,
既數據的加載、選擇模型、模型的訓練、模型的預測、模型的評測,模型的保存。
其中我們使用
getData方法泛指數據的加載,
somemodel方法泛指選擇模型,
fit方法實現訓練,
predict方法實現預測,
score_function方法評測模型,
dump方法用于模型保存。
也許我們現在并不明白這些代碼的含義,我們將會在接下來的學習中為大家解答。
"""
sklearn實現
第一步使用sklearn導入數據并分割
模塊自帶數據集,參考
https://sklearn.apachecn.org/
https://blog.csdn.net/u013044310/article/details/103678248
了解sklearn自帶的數據集有那些,數據集有哪些屬性
了解數據集。
首先我們來了解一下如何為機器學習加載數據,為了方便學習,我們使用scikit-learn機器學習模塊自帶的數據集進行數據的加載練習,scikit-learn機器學習模塊提供了一些模塊自帶的數據集,
自帶的小數據集(packaged dataset):sklearn.datasets.load_<name>
可在線下載的數據集(Downloaded Dataset):sklearn.datasets.fetch_<name>
計算機生成的數據集(Generated Dataset):sklearn.datasets.make_<name>
svmlight/libsvm格式的數據集:sklearn.datasets.load_svmlight_file(...)
這些數據集都可以在官網上查找到demo,例如用于分類的iris、digits數據集和波士頓房價回歸等數據集,我們通過以下的例子來了解如何進行數據的加載
#導入數據集模塊
from sklearn import datasets
#分別加載iris和digits數據集
iris_dataset = datasets.load_iris() #鳶尾花數據集
print(dir(datasets))
"""
['__all__', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__',
'__package__', '__path__', '__spec__', '_base', '_california_housing', '_covtype', '_kddcup99',
'_lfw', '_olivetti_faces', '_openml', '_rcv1', '_samples_generator', '_species_distributions',
'_svmlight_format_fast', '_svmlight_format_io', '_twenty_newsgroups', 'clear_data_home', 'data',
'descr', 'dump_svmlight_file', 'fetch_20newsgroups', 'fetch_20newsgroups_vectorized',
'fetch_california_housing', 'fetch_covtype', 'fetch_kddcup99', 'fetch_lfw_pairs',
'fetch_lfw_people', 'fetch_olivetti_faces', 'fetch_openml', 'fetch_rcv1',
'fetch_species_distributions', 'get_data_home', 'load_boston', 'load_breast_cancer',
'load_diabetes', 'load_digits', 'load_files', 'load_iris', 'load_linnerud', 'load_sample_image',
'load_sample_images', 'load_svmlight_file', 'load_svmlight_files', 'load_wine', 'make_biclusters',
'make_blobs', 'make_checkerboard', 'make_circles', 'make_classification', 'make_friedman1',
'make_friedman2', 'make_friedman3', 'make_gaussian_quantiles', 'make_hastie_10_2', 'make_low_rank_matrix',
'make_moons', 'make_multilabel_classification', 'make_regression', 'make_s_curve', 'make_sparse_coded_signal',
'make_sparse_spd_matrix', 'make_sparse_uncorrelated', 'make_spd_matrix', 'make_swiss_roll']
"""
print(iris_dataset.keys())
# dict_keys(['data', 'target', 'frame', 'target_names', 'DESCR', 'feature_names', 'filename', 'data_module'])
首先啟動一個Python解釋器,然后加載iris和digits數據集,數據集是一個類似字典的對象,它保存有關數據集的所有數據和一些樣本特征數據。該數據存儲在.data成員中,在有監督學習中,一個或多個標記類別存儲在.target成員中,例如,在iris數據集中,iris.data保存的是分類的樣本特征,iris.target保存的是分類的樣本標簽,Iris數據集是常用的分類實驗數據集,由Fisher, 1936收集整理。Iris也稱鳶尾花卉數據集,是一類多重變量分析的數據集。數據集包含150個數據集,分為3類,每類50個數據,每個數據包含4個屬性。可通過花萼長度,花萼寬度,花瓣長度,花瓣寬度(Sepal.Length& Sepal.Width& Petal.Length& Petal.Width)4個屬性預測鳶尾花卉屬于(Setosa,Versicolour,Virginica)三個種類中的哪一類
#使用.data() 和.target()方法熟悉導入的數據結構
print(iris.data)
print(iris.target)
加載完成后,我們可以通過print函數查看iris數據具體數值,iris.data表示數據集內鳶尾花的花萼長度,花萼寬度,花瓣長度,花瓣寬度4個屬性,iris.target表示數據集內鳶尾花的真實類別,也就是我們期望從每個鳶尾花屬性數據中學得的相應的類別標記
機器學習是從數據的屬性中學習經驗,并將它們應用到新數據的過程。但是由于使用驗證集來選擇最終模型,因此最終模型對驗證數據的錯誤率估計是有偏的(小于真實錯誤率),且在用測試集評估最終模型之后,我們不能進一步調整模型。這就是為什么機器學習中評估算法的普遍實踐是把數據分割成訓練集(我們從中學習數據的屬性)和測試集(我們測試這些性質)。那什么是訓練集和測試集呢?
訓練集(Training set)作用是用來擬合模型,通過設置分類器的參數,訓練分類模型。
測試集(Test set)通過訓練,得出最優模型后,使用測試集進行模型預測。用來衡量該最優模型的性能和分類能力。即可以把測試集視為從來不存在的數據集,當已經確定模型后,使用測試集進行模型性能評價。

那測試的數據從何而來?,如果我們自己已經有了一個大的標注數據集,想要完成一個有監督模型的測試,那么通常使用均勻隨機抽樣的方式,將數據集劃分為訓練集、測試集,這倆個集合不能有交集。但是由于現實世界中某些原因,或是機密數據,或是稀缺數據,從而導致數據量過少我們只能將少量的數據進行分割,生成訓練集和測試集,常見的比例是8:2,當然比例是人為的。從數據的角度來看,2個集合都是同分布的,因此都是具參考性的。
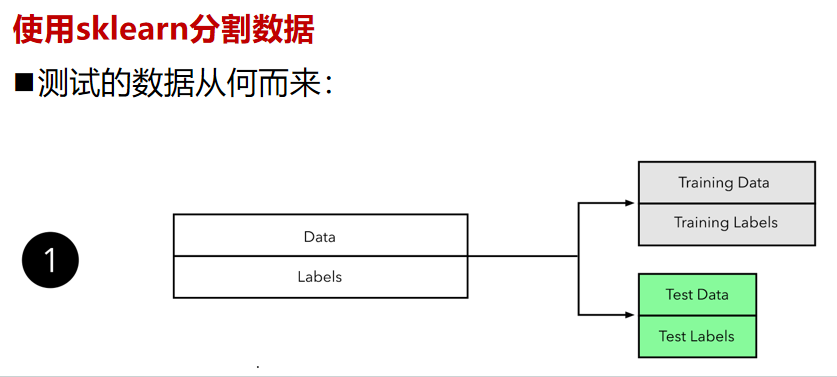
# 使用sklearn分割數據from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test=train_test_split(iris.data,iris.target,test_size=0.4,random_state=0)
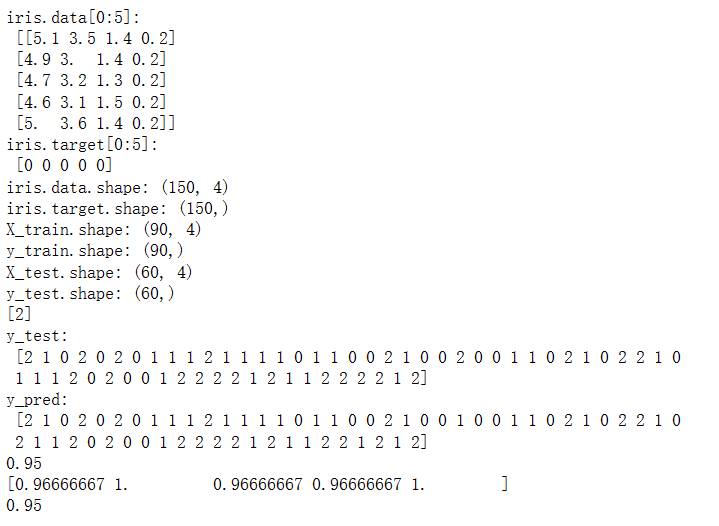
print("iris.data[0:5]:\n",iris.data[0:5])
print("iris.target[0:5]:\n",iris.target[0:5])
print("iris.data.shape:",iris.data.shape)
print("iris.target.shape:",iris.target.shape)
print("X_train.shape:",X_train.shape)
print("y_train.shape:",y_train.shape)
print("X_test.shape:",X_test.shape)
print("y_test.shape:",y_test.shape)
輸出為:
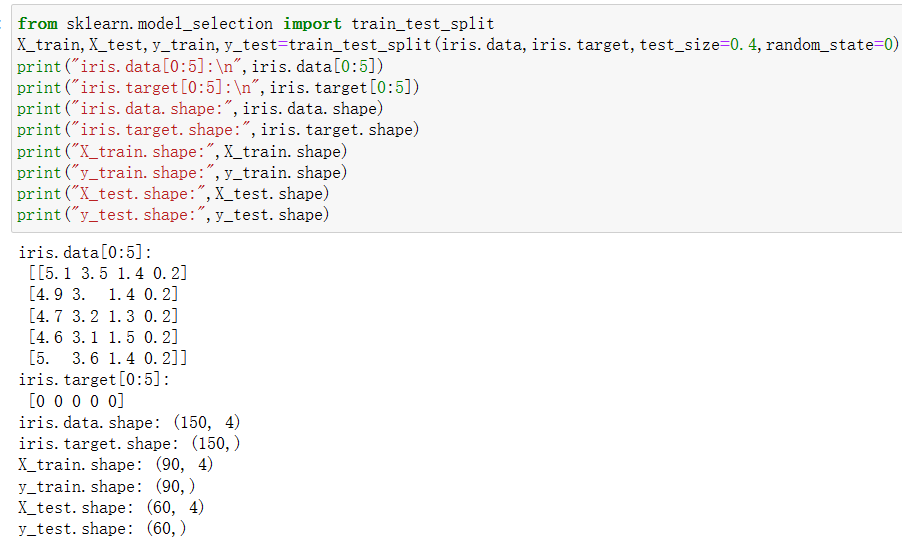
現在我們來學習如何使用sklearn實現分割數據集,在這里我們使用sklearn.model_selection模塊中的train_test_split方法分割成訓練數據集和測試數據集,其中我們把參數test_size設置成0.4,表示分配了40%的數據給測試數據集。剩下60%的數據將用于訓練數據集,參數random_state=0表示對隨機種子的使用情況,而X_train,X_test,y_train,y_test分別為將原始數據iris.data,iris.target按照test_size的數值進行分割后的輸出,其中iris.data的60%輸出為X_train,iris.data的40%輸出為X_test,iris.target的60%輸出為y_train,iris.target的40%輸出為y_test。
第二步使用sklearn模型的選擇
學會加載模型,對于不同類型的數據選擇不同的方法(智能算法)進行學習。
在機器學習的算法中存在著實現分類,聚類,回歸,降維等功能的模型,而每個模型功能、效率、特性各具不同,如何選擇一個合適的模型就變得至關重要,在面對大量的機器學習模型時,我們該如何選擇某個機器學習的模型呢?
我們需要思考這樣的以下問題:
1.數據的大小、質量及性質,
2.可用計算時間,
3.任務的急迫性,
4.數據的使用用途。
在沒有測試過不同算法之前,即使是經驗豐富的數據科學家和機器學習算法開發者也都不能分辨出哪種模型性能最好。我們并不提倡一步到位,但是我們確實希望根據一些明確的因素為模型的選擇提供一些參考意見,sklearn機器學習模型速查表(官網可查)可幫助你從大量模型之中篩選出解決你的特定問題的模型。
# 第二步使用sklearn模型的選擇
from sklearn import svm
svc = svm.SVC(gamma='auto')
本章中我們不會對機器學習的算法機理進行講解,我們希望在本章中學員學會如何將算法模型實例化,因為sklearn已經將常用的機器學習模型進行了封裝,那如何使用代碼構建一個模型呢?以上代碼表面了我們選擇一個分類算法SVC,SVC實現了分類功能 。模型的構造函數以相應模型的參數為參數,但目前我們將把SVC分類模型視為黑箱即可,因此我們發現使用sklearn實現一個模型的實例話相當簡單,我們只需要導入相關模塊然后依據模型名稱進行實例化即可,如python語句svc = svm.SVC()。
第三步使用sklearn模型的訓練
接下來我們將了解機器學習訓練的過程,從數據中學得模型的過程稱為“訓練”(learning),這個過程通過執行某個學習模型算法來完成。學得模型對應了關于數據的某種潛在的規律,因此亦稱“假設”(hypothesis);這種潛在規律自身,則稱為“真相”或“真實”(ground- truth),訓練過程就是為了找出或逼近真相。從模型角度而言,模型可以理解為函數。訓練模型就是用已有的數據,通過一些方法(最優化或者其他方法)確定函數的參數,參數確定后的函數就是訓練的結果,使用模型就是把新的數據代入函數求值。機器學習中的“訓練” 過程可以對應到人類的“學習” 過程

#第三步使用sklearn模型的訓練
svc.fit(X_train, y_train)
輸出為:

在scikit-learn模塊中,模型的訓練過程是一個Python對象,它使用fit(X, y)函數方法實現,在上圖python代碼svc.fit(X_train, y_train)中,我們通過向fit方法提供輸入訓練數據集后即可訓練模型。
第四步使用sklearn進行模型的預測

# 第四步使用sklearn進行模型預測
print(svc.predict([[5.84,4.4,6.9,2.5]]))
輸出為:
2
在scikit-learn模塊中,模型的預測過程是一個Python對象,它predict()函數方法實現,在上圖python代碼svc.predict()中,我們通過向predict方法提供輸入測試數據集后即可通過模型對新數據進行預測。
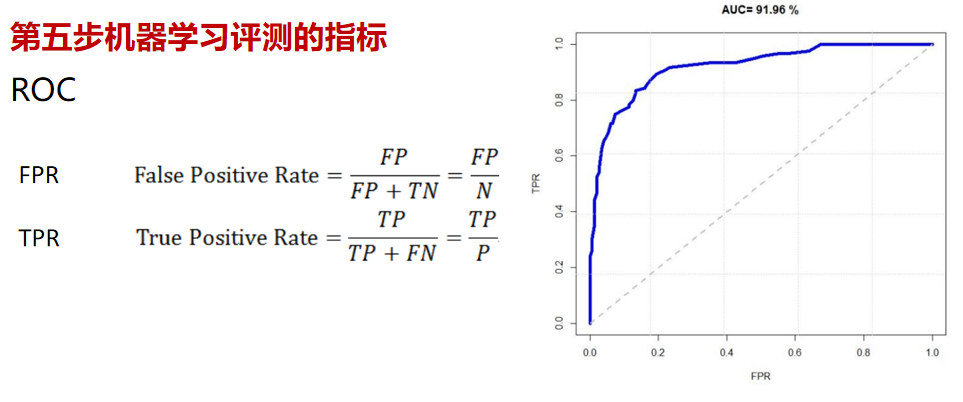
第五步機器學習評測的指標
學習到此,我們訓練完成我們的模型了,同時我們希望了解訓練出的模型效果如何,這時我們需要通過一些數學指標來表明其效果,但在此之前了解一下誤差的概念。我們把模型的實際預測輸出與樣本的真實輸出之間的差異稱為“誤差”(error),模型在訓練集上的誤差稱為“訓練誤差” (training error),在新樣本上的誤差稱為“泛化誤差”( generalization error)。顯然,我們希望得到泛化誤差小的模型。然而,我們事先并不知道新樣本是什么樣,實際能做的是努力使經驗誤差最小化。而對于不同的算法我們通常會采用不同的指標來評判,分類算法采用分類指標,回歸算法采用回歸指標,聚類算法采用聚類指標。

本章中,我們只對評測分類算法和回歸算法的指標進行講解,關于評測聚類算法的指標我們將在無監督學習章節中講解,分類下我們關心的常用的指標有:
準確率( accuracy),準確率是指對于給定的測試數據集,分類器正確分類的樣本數與總樣本數之比,假設分類正確的樣本數量=70,而總分類樣本數量=100,那么精度=70/100=70.00%。
另外一個常用的分類指標為AUC:AUC(Area Under Curve)是一個概率值,當你隨機挑選一個正樣本以及一個負樣本,當前的分類算法根據計算得到的Score值將這個正樣本排在負樣本前面的概率就是AUC值,而作為一個數值,對應AUC更大的分類器效果更好


本章中,我們只對評測分類算法和回歸算法的指標進行講解,關于評測聚類算法的指標我們將在無監督學習章節中講解,分類下我們關心的常用的指標有:
準確率( accuracy),準確率是指對于給定的測試數據集,分類器正確分類的樣本數與總樣本數之比,假設分類正確的樣本數量=70,而總分類樣本數量=100,那么精度=70/100=70.00%。
另外一個常用的分類指標為AUC:AUC(Area Under Curve)是一個概率值,當你隨機挑選一個正樣本以及一個負樣本,當前的分類算法根據計算得到的Score值將這個正樣本排在負樣本前面的概率就是AUC值,而作為一個數值,對應AUC更大的分類器效果更好


#第五步機器學習評測的指標
#機器學習庫sklearn中,我們使用metrics方法實現:
import numpy as np
from sklearn.metrics import accuracy_score
y_pred = [0, 2, 1, 3]
y_true = [0, 1, 2, 3]
accuracy_score(y_true, y_pred)
輸出為:

#第五步機器學習評測的指標
#機器學習庫sklearn中,我們使用metrics方法實現:
import numpy as np
from sklearn.metrics import accuracy_score
print("y_test:\n",y_test)
y_pred = svc.predict(X_test)
print("y_pred:\n",y_pred)
accuracy_score(y_test, y_pred)
輸出為:
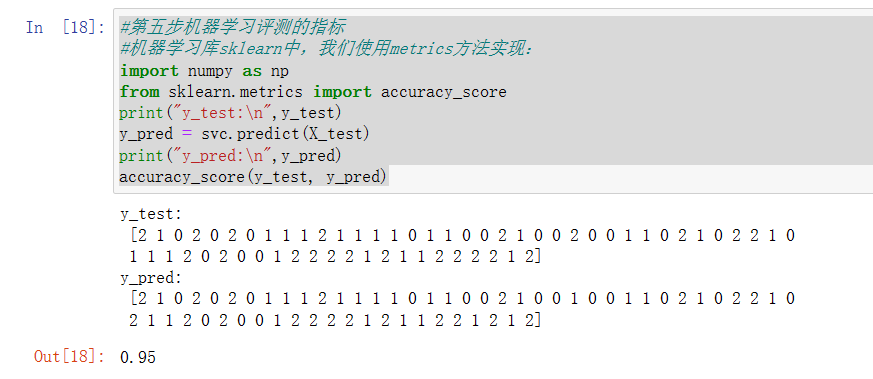
現在我們看看如何實現對分類模型和回歸模型的評測。這里使用的是scikit-learn模塊中metrics方法實現,metrics模塊包括評分函數,性能指標和成對指標以及距離計算,用來計算真實值與預測值之間的預測誤差:
以_score結尾的函數,返回一個最大值,越高越好
以_error結尾的函數,返回一個最小值,越小越好;如果使用make_scorer來創建scorer時,將greater_is_better設為False,本例中我們調用了accuracy_score函數,該函數將會計算輸入的參數y_pred對于y_true的準確率。而python語句from sklearn.metrics import accuracy_score實現了將accuracy_score函數導入的功能。
從之前的學習中我們了解到模型會先行在訓練集上進行訓練,通過對模型進行調整使模型的性能達到了最佳狀態;但是即使模型在訓練集上表現良好,往往其在測試集上可能會出現表現不佳的情況。此時,測試集的反饋足以推翻訓練模型,并且度量不再有效地反映模型的泛化性能。為了解決這樣的問題,我們必須準備另一部分稱為驗證集(validation set)的數據集。完成模型后,在驗證集中評估模型。如果驗證集上的評估實驗成功,則在測試集上執行最終評估,但是,如果我們將原始數據進行劃分為我們所說的訓練集、驗證集、測試集,那么我們可用的數據將會大大的減少,為了解決這個問題,我們提出了交叉驗證這樣的解決辦法。
那什么是交叉驗證呢?交叉驗證 (Cross validation)是將原始數據分成K個子集(一般是均分),將每個子集數據分別做一次測試集 (testing test),其余的K-1組子集數據作為訓練集(trainning test),這樣會得到K個模型,用這K個模型最終的驗證集的分類指標的平均數作為此K-CV下分類器的性能指標。
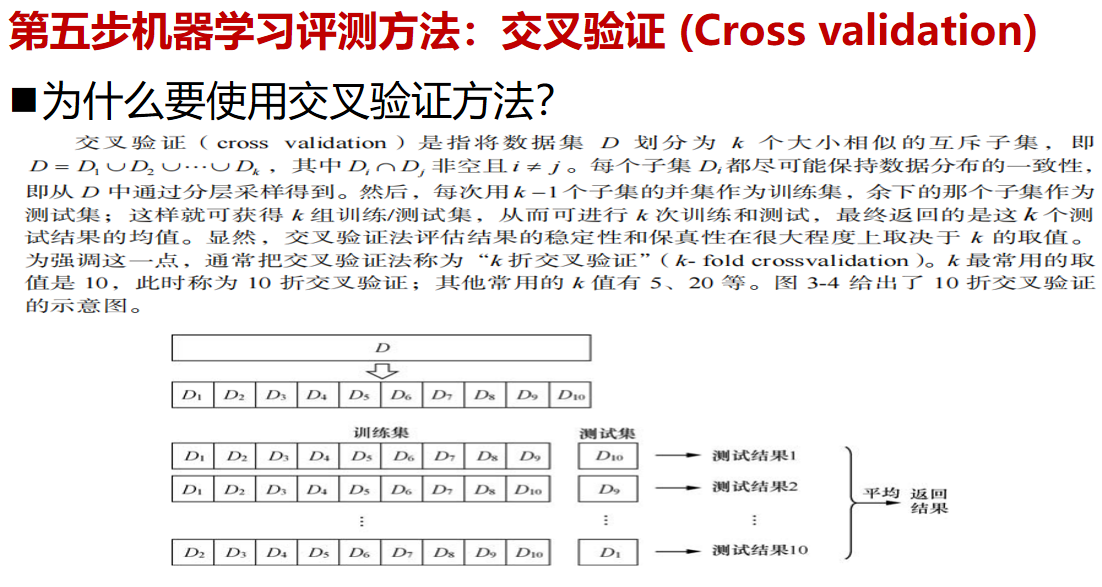
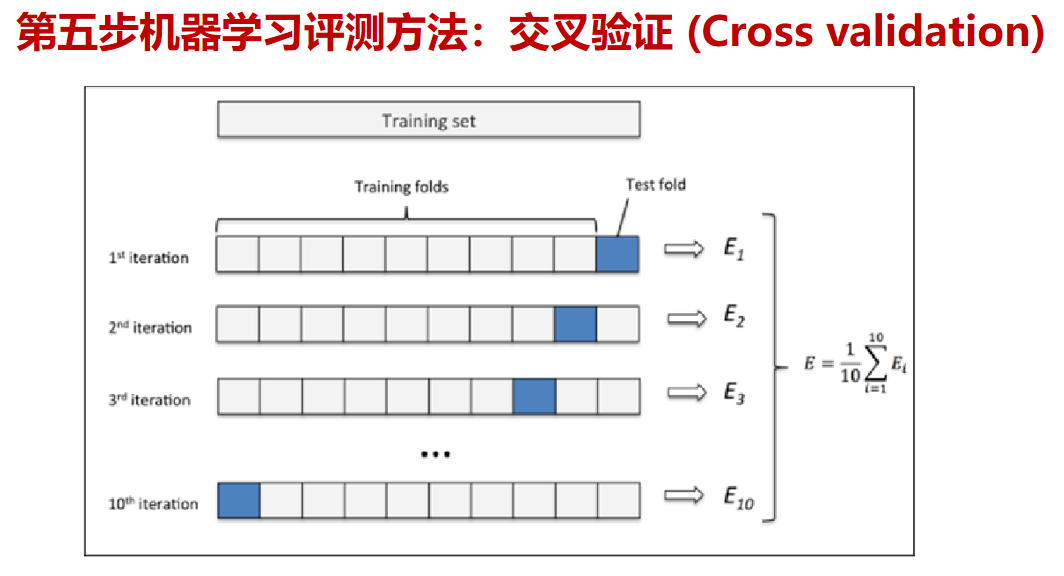
在交叉驗證 (Cross validation)中K一般大于等于2,且每次用k-1個子集的并集作為訓練集,余下的那個子集作為測試集;這樣就可獲得k組訓練/測試集,從而可進行k次訓練和測試,最終返回的是這個測試結果的均值。而交叉驗證 (Cross validation)的優點是對所有的樣本都被作為了訓練集和測試集,每個樣本都被驗證一次。其中10-folder通常被最長使用

上圖顯示了交叉驗證的運行過程。這里采用的是10折交叉驗證。
#第五步機器學習評測方法:交叉驗證 (Cross validation)
#機器學習庫sklearn中,我們使用cross_val_score方法實現:
from sklearn.model_selection import cross_val_score
scores = cross_val_score(svc, iris.data, iris.target, cv=5)
scores
輸出為:
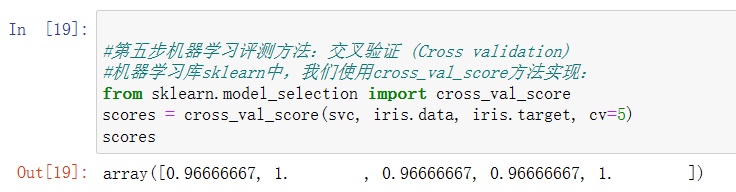
那如何實現交叉驗證算法呢?本節中我們將使用scikit-learn模塊實現交叉驗證,最簡單的實現方法是在模型和數據集上調用 cross_val_score 輔助函數,該函數將會擬合模型和計算連續cv(cv為cross_val_score函數的參數)次的分數(每次不同分割)來估計模型在數據集上的精度,如示例中python語句scores = cross_val_score(knn, iris.data, iris.target, cv=5),其中knn參數為待評估模型,iris.data, iris.target參數為數據集,cv參數為拆分子集數量,通常在默認情況下,每次cross_val_score迭代計算的指標結果是保存在屬性scores中的,同時我們可以通過使用scoring參數來選擇不同的指標,關于scoring的參數詳情設置請參考官方文檔
第六步機器學習:模型的保存
當我們的機器學習模型訓練完成后,我們可以將我們的模型永久化,這樣可以我們就下次可以直接使用我們的模型,避免下次大量數據訓練花費過長時間以及方便我們進行模型的轉移,而我們會使用pickle文件進行保存,pickle文件只能在python中使用,python中幾乎所有的數據類型(列表,字典,集合,類等)都可以用pickle來序列化,且pickle序列化后的數據,可讀性差,人一般無法識別。

#第六步機器學習:模型的保存
#機器學習庫sklearn中,我們使用joblib方法實現:
# from sklearn.externals import joblib
import joblib
joblib.dump(svc, 'filename.pkl')
svc1 = joblib.load('filename.pkl')
#測試讀取后的Model
print(svc1.score(X_test, y_test))
輸出為:

模型的保存的實現方法是調用sklearn.externals包中joblib類方法,如PPT中python代碼joblib.dump(knn, ‘filename.pkl‘) ,其中joblib類中dump方法的會將參數knn序列化對象,并將結果數據流寫入到文件對象中,其中參數knn為待保存的模型,參數‘filename.pkl‘指明pickle文件路徑。而代碼svc1 = joblib.load(’filename.pkl‘) 實現了反序列化對象過程。即將文件中的數據解析為一個Python對象,通俗而已就是將我們保存的模型在此實例化,并且命名為svc1。其中要注意的是,在load(file)的時候,要讓python能夠找到類的定義,否則會報錯
完整代碼
#導入數據集模塊
from sklearn import datasets
#分別加載iris和digits數據集
iris_dataset = datasets.load_iris() #鳶尾花數據集
# print(dir(datasets))
# print(iris_dataset.keys())
# dict_keys(['data', 'target', 'frame', 'target_names', 'DESCR', 'feature_names', 'filename', 'data_module'])from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test=train_test_split(iris.data,iris.target,test_size=0.4,random_state=0)
print("iris.data[0:5]:\n",iris.data[0:5])
print("iris.target[0:5]:\n",iris.target[0:5])
print("iris.data.shape:",iris.data.shape)
print("iris.target.shape:",iris.target.shape)
print("X_train.shape:",X_train.shape)
print("y_train.shape:",y_train.shape)
print("X_test.shape:",X_test.shape)
print("y_test.shape:",y_test.shape)# 第二步使用sklearn模型的選擇
from sklearn import svm
svc = svm.SVC(gamma='auto')#第三步使用sklearn模型的訓練
svc.fit(X_train, y_train)# 第四步使用sklearn進行模型預測
print(svc.predict([[5.84,4.4,6.9,2.5]]))#第五步機器學習評測的指標
#機器學習庫sklearn中,我們使用metrics方法實現:
import numpy as np
from sklearn.metrics import accuracy_score
print("y_test:\n",y_test)
y_pred = svc.predict(X_test)
print("y_pred:\n",y_pred)
print(accuracy_score(y_test, y_pred))#第五步機器學習評測方法:交叉驗證 (Cross validation)
#機器學習庫sklearn中,我們使用cross_val_score方法實現:
from sklearn.model_selection import cross_val_score
scores = cross_val_score(svc, iris.data, iris.target, cv=5)
print(scores)#第六步機器學習:模型的保存
#機器學習庫sklearn中,我們使用joblib方法實現:
# from sklearn.externals import joblib
import joblib
joblib.dump(svc, 'filename.pkl')
svc1 = joblib.load('filename.pkl')
#測試讀取后的Model
print(svc1.score(X_test, y_test))
輸出為:
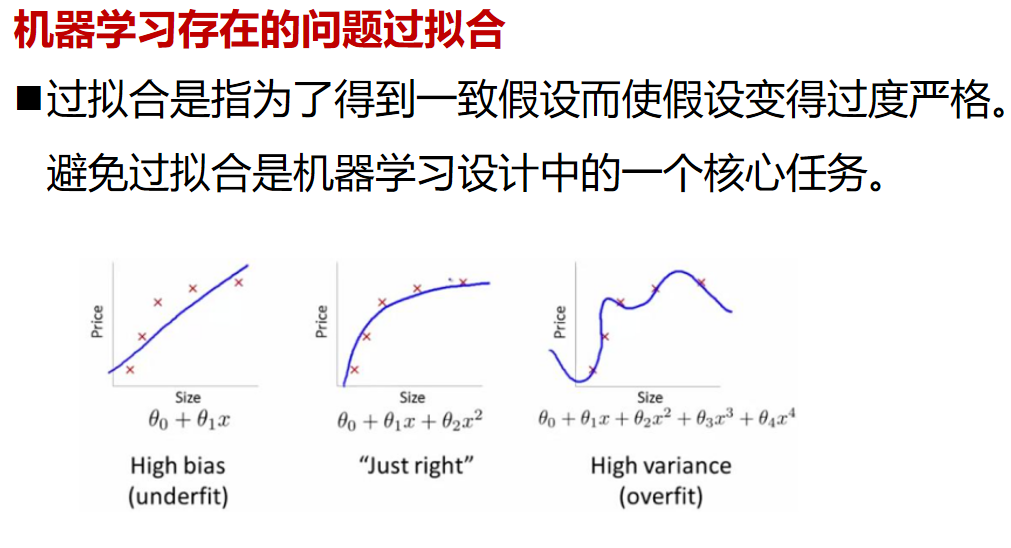
機器學習中的擬合問題



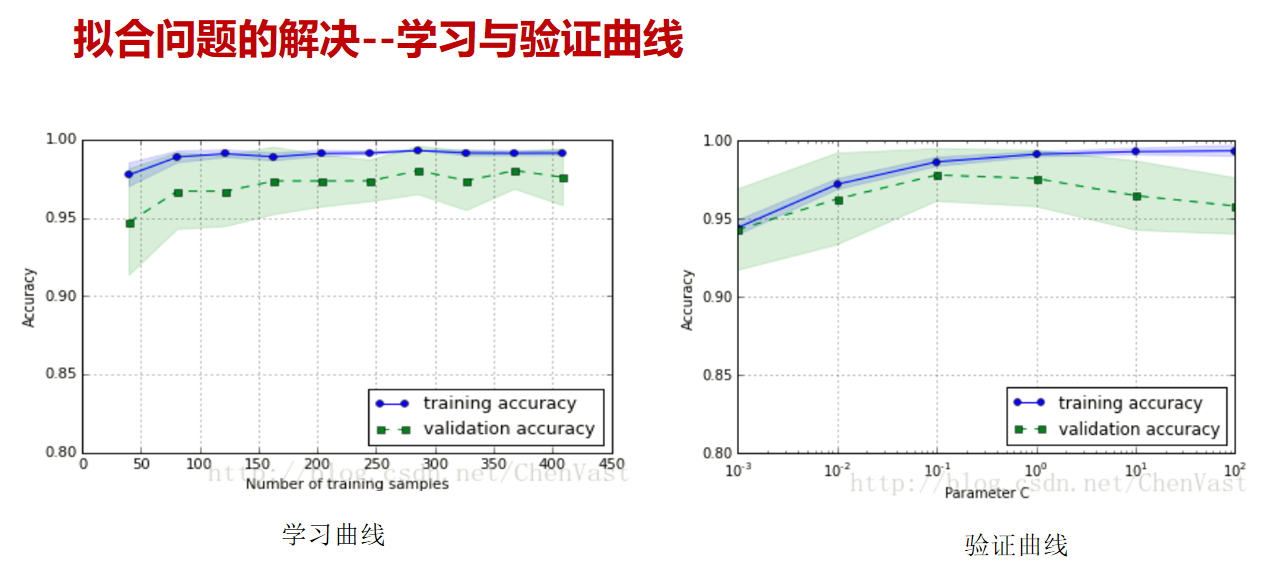
流行的開源框架

Scikit-Learn是用于機器學習的Python模塊,它建立在SciPy之上。基本功能主要被分為六個部分:分類、回歸、聚類、數據降維、模型選擇、數據預處理。
https://scikit-learn.org/stable/preface.html
GitHub項目地址:
https://github.com/scikit-learn/scikit-learn
Paddle 是 Parallel Distributed Deep Learning 的縮寫,中文名字是并行分布式深度學習。paddle 的原意是“用漿劃動”,所以 logo 也是兩個劃船的小人,也就是等待眾人劃槳的中國 AI 大船。
從2016年9月27日發布至今,其前身是百度于2013年自主研發的易用、高效、靈活、可擴展的深度學習平臺,且一直為百度內部工程師研發使用,可以認為是一個類似Facebook支持的PyTorch、Google的TensorFlow等工業優而開源的又一個典范。
https://www.paddlepaddle.org.cn/
TensorFlow是谷歌基于C++開發、發布的第二代機器學習系統。開發目的是用于進行機器學習和深度神經網絡的研究。目前Google 的GoogleApp的語音識別、Gmail的自動回復功能、Google Photos的圖片搜索等都在使用 TensorFlow 。
官網英文
官網中文
GitHub項目地址:
https://github.com/tensorflow/tensorflow

PyTorch的設計追求最少的封裝,盡量避免重復造輪子。不像 TensorFlow 中充斥著session、graph、operation、name_scope、variable、tensor、layer等全新的概念,PyTorch的設計遵循tensor→variable(autograd)→nn.Module 三個由低到高的抽象層次,分別代表高維數組(張量)、自動求導(變量)和神經網絡(層/模塊),而且這三個抽象之間聯系緊密,可以同時進行修改和操作。 簡潔的設計帶來的另外一個好處就是代碼易于理解。PyTorch的源碼只有TensorFlow的十分之一左右,更高的抽象、更直觀的設計使得PyTorch的源碼十分易于閱讀。
pytorch官網
GitHub項目地址:
https://pytorch.org/

MindSpore
MindSpore 是華為公司推出的一款開源 AI 計算框架,在國產框架中認知度排第一,而且具備全方位能力,既能夠提供特定的能力(如開發大模型,進行科學計算),又能實現全生命周期的 開發(即端到端開發,從訓練到部署)。
官網

Spark MLlib是Spark對常用的機器學習算法的實現庫,同時包括相關的測試和數據生成器。Spark的設計初衷就是為了支持一些迭代的Job, 這正好符合很多機器學習算法的特點。Spark基于內存的計算模型天生就擅長迭代計算,多個步驟計算直接在內存中完成,只有在必要時才會操作磁盤和網絡。
官網
GitHub項目地址:
https://github.com/apache/spark

確定方向過程
針對完全沒有基礎的同學們
1.確定機器學習的應用領域有哪些
2.查找機器學習的算法應用有哪些
3.確定想要研究的領域極其對應的算法
4.通過招聘網站和論文等確定具體的技術
5.了解業務流程,查找數據
6.復現經典算法
7.持續優化,并嘗試與對應企業人員溝通心得
8.企業給出反饋
![[LeetBook]【學習日記】類鏈表反轉——尋找倒數第cnt個元素](http://pic.xiahunao.cn/[LeetBook]【學習日記】類鏈表反轉——尋找倒數第cnt個元素)


)








)



—— 前端開發規范之命名規范、html 規范、css 規范、js 規范)


