selenium
一、前期準備
1、概述
selenium本身是一個自動化測試工具。它可以讓python代碼調用瀏覽器。并獲取到瀏覽器中加載的各種資源。 我們可以利用selenium提供的各項功能。 幫助我們完成數據的抓取。
2、學習目標
-
掌握 selenium發送請求,加載網頁的方法
-
掌握 selenium簡單的元素定位的方法
-
掌握 selenium的基礎屬性和方法
-
掌握 selenium退出的方法
3、安裝
安裝:pip install selenium
它與其他庫不同的地方是他要啟動你電腦上的瀏覽器, 這就需要一個驅動程序來輔助.
這里推薦用chrome瀏覽器
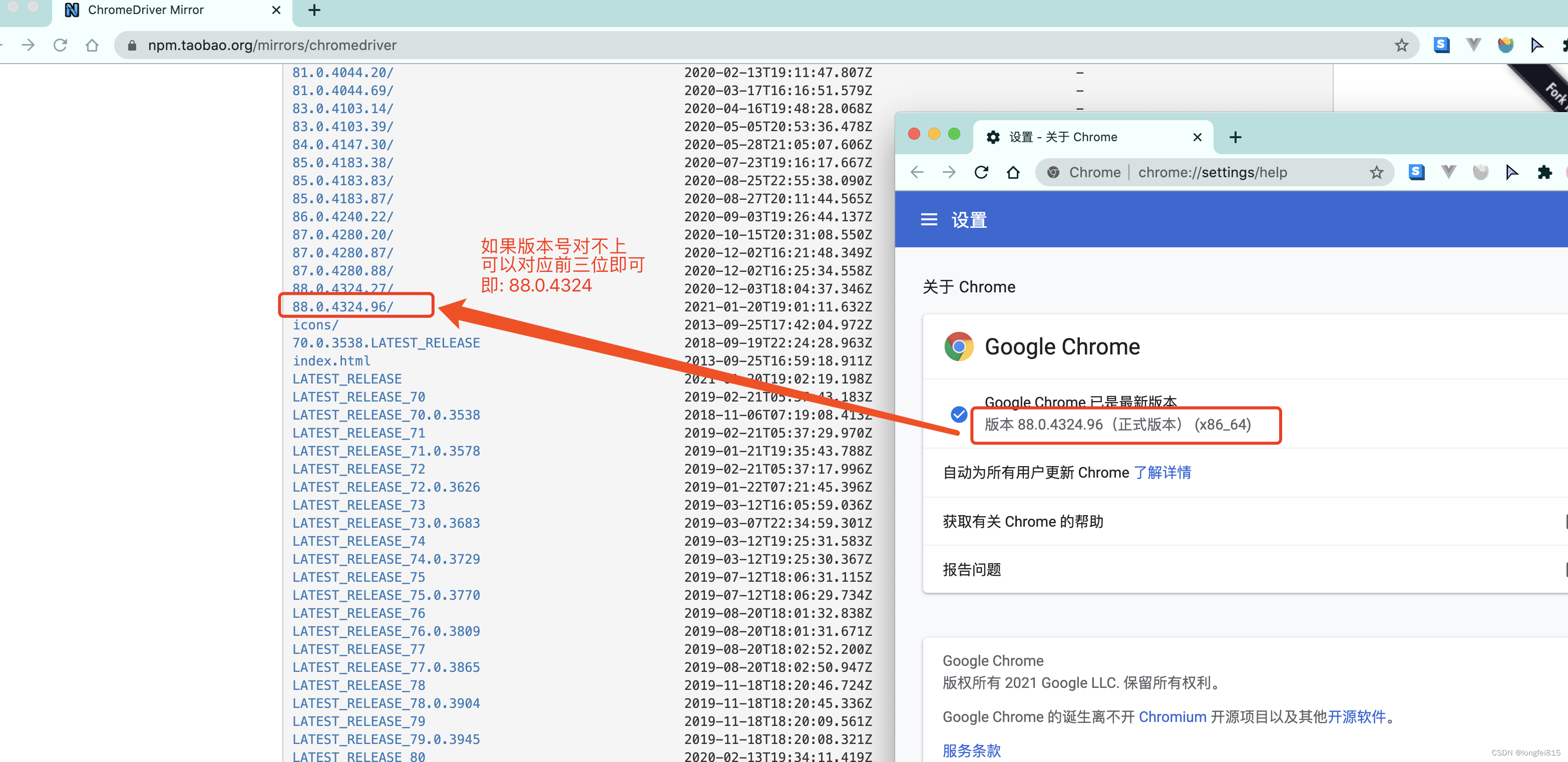
chrome驅動地址:http://chromedriver.storage.googleapis.com/index.html
 ?
?
根據你電腦的不同自行選擇吧. win64選win32即可.
然后關鍵的來了. 把你下載的瀏覽器驅動放在python解釋器所在的文件夾
Windwos: py -0p 查看Python路徑
Mac: open + 路徑
例如:open /usr/local/bin/

前期準備工作完畢. 上代碼看看 感受一下selenium
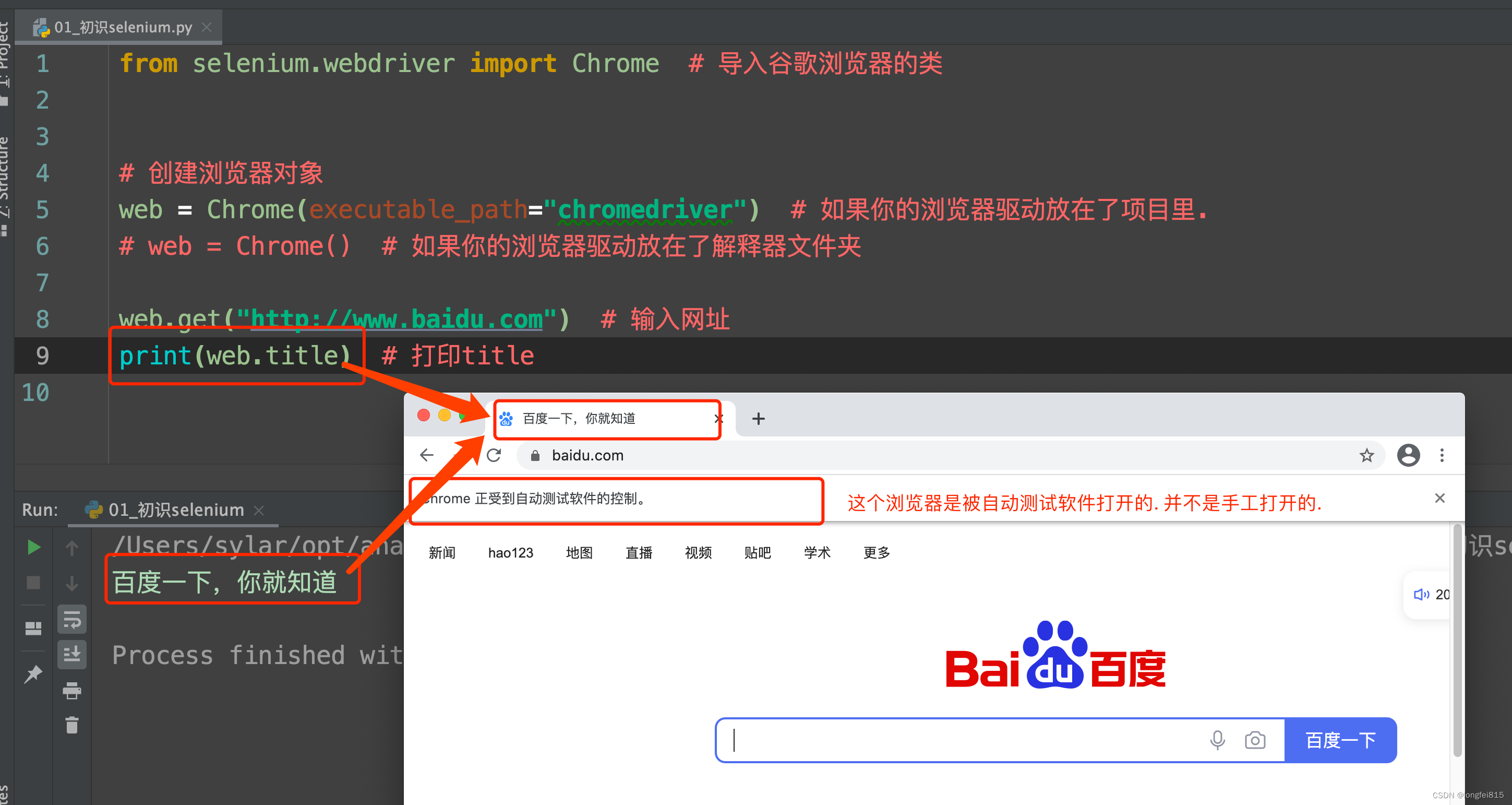
from selenium.webdriver import Chrome ?# 導入谷歌瀏覽器的類
?
?
# 創建瀏覽器對象
web = Chrome() ?# 如果你的瀏覽器驅動放在了解釋器文件夾
?
web.get("http://www.baidu.com") ?# 輸入網址
print(web.title) ?# 打印title運行一下你會發現神奇的事情發生了. 瀏覽器自動打開了. 并且輸入了網址. 也能拿到網頁上的title標題.
二、selenium的基本使用
1、加載網頁:
selenium通過控制瀏覽器,所以對應的獲取的數據都是elements中的內容
from selenium import webdriver
from selenium.webdriver.common.by import By
?
driver = webdriver.Chrome()
# 訪問百度
driver.get("http://www.baidu.com/")
# 截圖
driver.save_screenshot("baidu.png")2、定位和操作:
# 搜索關鍵字 杜卡迪
driver.find_element(By.ID, "kw").send_keys("杜卡迪")
# 點擊id為su的搜索按鈕
driver.find_element(By.ID, "su").click()3、查看請求信息:
driver.page_source ? # 獲取頁面內容
driver.get_cookies()
driver.current_url4、退出
driver.close() ?# 退出當前頁面
driver.quit() ? # 退出瀏覽器小結
-
selenium的導包:
from selenium import webdriver -
selenium創建driver對象:
webdriver.Chrome() -
selenium請求數據:
driver.get("http://www.baidu.com/") -
selenium查看數據:
driver.page_source -
關閉瀏覽器:
driver.quit() -
根據id定位元素:
driver.find_element_by_id("kw")/driver.find_element(By.ID, "kw") -
操作點擊事件:
click() -
給輸入框賦值:
send_keys()
三、元素定位的方法
學習目標
-
掌握 selenium定位元素的方法
-
掌握 selenium從元素中獲取文本和屬性的方法
通過selenium的基本使用可以簡單定位元素和獲取對應的數據,接下來我們再來學習下 定位元素的其他方法
1、selenium的定位操作
-
元素定位的兩種寫法:
-
直接調用型
el = driver.find_element_by_xxx(value)# xxx是定位方式,后面我們會講,value為該方式對應的值 -
使用By類型(需要導入By) 建議使用這種方式
# 直接掉用的方式會在底層翻譯成這種方式 from selenium.webdriver.common.by import By driver.find_element(By.xxx,value)
-
-
元素定位的兩種方式:
-
精確定位一個元素,返回結果為一個element對象,定位不到則報錯
driver.find_element(By.xx, value) ?# 建議使用 driver.find_element_by_xxx(value) -
定位一組元素,返回結果為element對象列表,定位不到返回空列表
driver.find_elements(By.xx, value) ?# 建議使用 driver.find_elements_by_xxx(value)
-
-
元素定位的八種方法:
以下方法在element之后添加s就變成能夠獲取一組元素的方法
-
By.ID 使用id值定位
el = driver.find_element(By.ID, '') el = driver.find_element_by_id() ? -
By.XPATH 使用xpath定位
el = driver.find_element(By.XPATH, '') el = driver.find_element_by_xpath() ? ? ? -
By.TAG_NAME. 使用標簽名定位
el = driver.find_element(By.TAG_NAME, '') el = driver.find_element_by_tag_name() ? ? -
By.LINK_TEXT使用超鏈接文本定位
el = driver.find_element(By.LINK_TEXT, '') el = driver.find_element_by_link_text() -
By.PARTIAL_LINK_TEXT 使用部分超鏈接文本定位
el = driver.find_element(By.PARTIAL_LINK_TEXT , '') el = driver.find_element_by_partial_link_text() -
By.NAME 使用name屬性值定位
el = driver.find_element(By.NAME, '') el = driver.find_element_by_name() -
By.CLASS_NAME 使用class屬性值定位
el = driver.find_element(By.CLASS_NAME, '') ? el = driver.find_element_by_class_name() -
By.CSS_SELECTOR 使用css選擇器定位
el = driver.find_element(By.CSS_SELECTOR, '') ? el = driver.find_element_by_css_selector()
-
注意:
-
建議使用find_element/find_elements
-
find_element和find_elements的區別 -
by_link_text和by_partial_link_text的區別: 全部文本和包含某個文本
-
使用: 以豆瓣為例
import time from selenium import webdriver from selenium.webdriver.common.by import By ? driver = webdriver.Chrome() driver.implicitly_wait(10) ?# 等待節點加載完成 driver.get("https://www.douban.com/search?q=%E6%9D%B0%E6%A3%AE%E6%96%AF%E5%9D%A6%E6%A3%AE") time.sleep(2) # 使用id的方式獲取右上角的搜索框 # ret1 = driver.find_element(By.ID, 'inp-query') # ret1 = driver.find_element(By.ID, 'inp-query').send_keys("杰森斯坦森") # ret1 = driver.find_element_by_id("inp-query") # print(ret1) ? # 輸出為:<selenium.webdriver.remote.webelement.WebElement (session="ea6f94544ac3a56585b2638d352e97f3", element="0.5335773935305805-1")> ? # 搜索輸入框 使用find_elements進行獲取 # ret2 = driver.find_elements(By.ID, "inp-query") # ret2 = driver.find_elements_by_id("inp-query") # print(ret2) #輸出為:[<selenium.webdriver.remote.webelement.WebElement (session="ea6f94544ac3a56585b2638d352e97f3", element="0.5335773935305805-1")>] ? # 搜索按鈕 使用xpath進行獲取 # ret3 = driver.find_elements(By.XPATH, '//*[@id="inp-query"]') # ret3 = driver.find_elements_by_xpath("//*[@id="inp-query"]") # print(len(ret3)) # print(ret3) ? # 匹配圖片標簽 ret4 = driver.find_elements(By.TAG_NAME, 'img') for url in ret4:print(url.get_attribute('src')) ?#ret4 = driver.find_elements_by_tag_name("img") print(len(ret4)) ? ret5 = driver.find_elements(By.LINK_TEXT, "瀏覽發現") # ret5 = driver.find_elements_by_link_text("瀏覽發現") print(len(ret5)) print(ret5) ? ret6 = driver.find_elements(By.PARTIAL_LINK_TEXT, "瀏覽發現") # ret6 = driver.find_elements_by_partial_link_text("瀏覽發現") print(len(ret6)) # 使用class名稱查找 ret7 = driver.find_elements(By.CLASS_NAME, 'nbg') print(ret7) driver.close()
注意:
find_element與find_elements區別
-
只查找一個元素的時候:可以使用find_element(),find_elements() find_element()會返回一個WebElement節點對象,但是沒找到會報錯,而find_elements()不會,之后返回一個空列表
-
查找多個元素的時候:只能用find_elements(),返回一個列表,列表里的元素全是WebElement節點對象
-
找到都是節點(標簽)
-
如果想要獲取相關內容(只對find_element()有效,列表對象沒有這個屬性) 使用 .text
-
如果想要獲取相關屬性的值(如href對應的鏈接等,只對find_element()有效,列表對象沒有這個屬性):使用 .get_attribute("href")
2、元素的操作
find_element_by_xxx方法僅僅能夠獲取元素對象,接下來就可以對元素執行以下操作 從定位到的元素中提取數據的方法
-
從定位到的元素中獲取數據
el.get_attribute(key) ? ? ? ? ? # 獲取key屬性名對應的屬性值
el.text ? ? ? ? ? ? ? ? ? ? ? # 獲取開閉標簽之間的文本內容-
對定位到的元素的操作
el.click() ? ? ? ? ? ? ? ? ? ? ?# 對元素執行點擊操作
?
el.submit() ? ? ? ? ? ? ? ? ? ? # 對元素執行提交操作
?
el.clear() ? ? ? ? ? ? ? ? ? ? ?# 清空可輸入元素中的數據
?
el.send_keys(data) ? ? ? ? ? ? ?# 向可輸入元素輸入數據使用示例:
from selenium import webdriver
from selenium.webdriver.common.by import By
?
driver =webdriver.Chrome()
?
driver.get("https://www.douban.com/")
# 打印頁面內容 (獲取到以后可以進行后續的xpath,bs4 或者存儲等)
print(driver.page_source)
?
ret4 = driver.find_elements(By.TAG_NAME, "h1")
print(ret4[0].text)
#輸出:豆瓣
?
ret5 = driver.find_elements(By.LINK_TEXT, "下載豆瓣 App")
print(ret5[0].get_attribute("href"))
#輸出:https://www.douban.com/doubanapp/app?channel=nimingye
?
driver.close()小結
-
根據xpath定位元素:
driver.find_elements(By.XPATH,"//*[@id='s']/h1/a") -
根據class定位元素:
driver.find_elements(By.CLASS_NAME, "box") -
根據link_text定位元素:
driver.find_elements(By.LINK_TEXT, "下載豆瓣 App") -
根據tag_name定位元素:
driver.find_elements(By.TAG_NAME, "h1") -
獲取元素文本內容:
element.text -
獲取元素標簽屬性:
element.get_attribute("href") -
向輸入框輸入數據:
element.send_keys(data)
四、selenium的其他操作
學習目標
-
掌握 selenium處理cookie等方法
-
掌握 selenium中switch的使用
-
掌握selenium中無頭瀏覽器的設置
1、無頭瀏覽器
我們已經基本了解了selenium的基本使用了. 但是呢, 不知各位有沒有發現, 每次打開瀏覽器的時間都比較長. 這就比較耗時了. 我們寫的是爬蟲程序. 目的是數據. 并不是想看網頁. 那能不能讓瀏覽器在后臺跑呢? 答案是可以的
from selenium.webdriver import Chrome
from selenium.webdriver.chrome.options import Options
?
opt = Options()
opt.add_argument("--headless")
opt.add_argument('--disable-gpu')
opt.add_argument("--window-size=4000,1600") ?# 設置窗口大小
?
web = Chrome(options=opt)1、selenium 處理cookie
通過driver.get_cookies()能夠獲取所有的cookie
-
獲取cookie
dictCookies = driver.get_cookies() -
設置cookie
driver.add_cookie(dictCookies) -
刪除cookue
#刪除一條cookie driver.delete_cookie("CookieName") # 刪除所有的cookie driver.delete_all_cookies()
2、頁面等待
-
為什么需要等待 如果網站采用了動態html技術,那么頁面上的部分元素出現時間便不能確定,這個時候就可以設置一個等待時間,強制等待指定時間,等待結束之后進行元素定位,如果還是無法定位到則報錯
-
頁面等待的三種方法
-
強制等待
import time time.sleep(n) ? ? ?# 阻塞等待設定的秒數之后再繼續往下執行 -
顯式等待(自動化web測試使用,爬蟲基本不用)
from selenium.webdriver.common.keys import Keys from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC ? WebDriverWait(driver, 10,0.5).until( EC.presence_of_element_located((By.ID, "myDynamicElement")) # 顯式等待指定某個條件,然后設置最長等待時間10,在10秒內每隔0.5秒使用指定條件去定位元素,如果定位到元素則直接結束等待,如果在10秒結束之后仍未定位到元素則報錯 -
隱式等待 隱式等待設置之后代碼中的所有元素定位都會做隱式等待
driver.implicitly_wait(10) ? ?# 在指定的n秒內每隔一段時間嘗試定位元素,如果n秒結束還未被定位出來則報錯
-
注意:
Selenium顯示等待和隱式等待的區別 1、selenium的顯示等待 原理:顯示等待,就是明確要等到某個元素的出現或者是某個元素的可點擊等條件,等不到,就一直等,除非在規定的時間之內都沒找到,就會跳出異常Exception
(簡而言之,就是直到元素出現才去操作,如果超時則報異常)
2、selenium的隱式等待
原理:隱式等待,就是在創建driver時,為瀏覽器對象創建一個等待時間,這個方法是得不到某個元素就等待一段時間,直到拿到某個元素位置。 注意:在使用隱式等待的時候,實際上瀏覽器會在你自己設定的時間內部斷的刷新頁面去尋找我們需要的元素
3、switch方法切換的操作
3.1 一個瀏覽器肯定會有很多窗口,所以我們肯定要有方法來實現窗口的切換。切換窗口的方法如下:
也可以使用 window_handles 方法來獲取每個窗口的操作對象。例如:
# 1. 獲取當前所有的窗口
current_windows = driver.window_handles
?
# 2. 根據窗口索引進行切換
driver.switch_to.window(current_windows[1])
?
driver.switch_to.window(web.window_handles[-1]) ?# 跳轉到最后一個窗口
driver.switch_to.window(current_windows[0]) ?# 回到第一個窗口3.2 iframe是html中常用的一種技術,即一個頁面中嵌套了另一個網頁,selenium默認是訪問不了frame中的內容的,對應的解決思路是
driver.switch_to.frame(name/el/id) ? ? 傳入的參數可以使iframe對應的id值,也可以是用元素定位之后的元素對象
動手:qq郵箱
在使用selenium登錄qq郵箱的過程中,我們會發現,無法在郵箱的登錄input標簽中輸入內容,通過觀察源碼可以發現,form表單在一個frame中,所以需要切換到frame中
3.3 當你觸發了某個事件之后,頁面出現了彈窗提示,處理這個提示或者獲取提示信息方法如下:
alert = driver.switch_to_alert()4. 頁面前進和后退
driver.forward() ? ? # 前進
driver.back() ? ? ? ?# 后退
driver.refresh() # 刷新
driver.close() ? ? ? # 關閉當前窗口5、設置瀏覽器最大窗口
driver.maximize_window() #最大化瀏覽器窗口4、selenium的優缺點
-
優點
-
selenium能夠執行頁面上的js,對于js渲染的數據和模擬登陸處理起來非常容易
-
使用難度簡單
-
爬取速度慢,爬取頻率更像人的行為,天生能夠應對一些反爬措施
-
-
缺點
-
由于selenium操作瀏覽器,因此會將發送所有的請求,因此占用網絡帶寬
-
由于操作瀏覽器,因此占用的內存非常大(相比較之前的爬蟲)
-
速度慢,對于效率要求高的話不建議使用
-
小結
-
獲取cookie:
get_cookies() -
刪除cookie:
delete_all_cookies() -
切換窗口:
switch_to.window() -
切換iframe:
switch_to.frame()
5、selenium的配置
selenium啟動谷歌瀏覽器的參數設置
通知、位置、攝像頭和麥克風權限控制的配置
options = webdriver.ChromeOptions()options.add_experimental_option("prefs", { \"profile.default_content_setting_values.media_stream_mic": 1, # 麥克風 1:allow, 2:block "profile.default_content_setting_values.media_stream_camera": 1, # 攝像頭 1:allow, 2:block "profile.default_content_setting_values.geolocation": 1, # 地理位置 1:allow, 2:block "profile.default_content_setting_values.notifications": 1, # 通知 1:allow, 2:block 'download.default_directory': download_path # 下載路徑})driver = webdriver.Chrome(chrome_options=options)
其他參數
options.add_argument(‘headless’) # 無頭模式
options.add_argument(‘window-size={}x{}’.format(width, height)) # 直接配置大小和set_window_size一樣
options.add_argument(‘disable-gpu’) # 禁用GPU加速
options.add_argument(‘proxy-server={}’.format(self.proxy_server)) # 配置代理
options.add_argument(’–no-sandbox’) # 沙盒模式運行
options.add_argument(’–disable-setuid-sandbox’) # 禁用沙盒
options.add_argument(’–disable-dev-shm-usage’) # 大量渲染時候寫入/tmp而非/dev/shm
options.add_argument(’–user-data-dir={profile_path}’.format(profile_path)) # 用戶數據存入指定文件
options.add_argument(‘no-default-browser-check) # 不做瀏覽器默認檢查
options.add_argument(“–disable-popup-blocking”) # 允許彈窗
options.add_argument(“–disable-extensions”) # 禁用擴展
options.add_argument(“–ignore-certificate-errors”) # 忽略不信任證書
options.add_argument(“–no-first-run”) # 初始化時為空白頁面
options.add_argument(’–start-maximized’) # 最大化啟動
options.add_argument(’–disable-notifications’) # 禁用通知警告
options.add_argument(’–enable-automation’) # 通知(通知用戶其瀏覽器正由自動化測試控制)
options.add_argument(’–disable-xss-auditor’) # 禁止xss防護
options.add_argument(’–disable-web-security’) # 關閉安全策略
options.add_argument(’–allow-running-insecure-content’) # 允許運行不安全的內容
options.add_argument(’–disable-webgl’) # 禁用webgl
options.add_argument(’–homedir={}’) # 指定主目錄存放位置
options.add_argument(’–disk-cache-dir={臨時文件目錄}’) # 指定臨時文件目錄
options.add_argument(‘disable-cache’) # 禁用緩存
options.add_argument(‘excludeSwitches’, [‘enable-automation’]) # 開發者模式
options.add_argument(’–disable-infobars’) # 禁止策略化
options.add_argument(‘–incognito’) # 隱身模式(無痕模式)
options.add_argument(‘–disable-javascript’) # 禁用javascript
options.add_argument(‘–hide-scrollbars’) # 隱藏滾動條, 應對一些特殊頁面
options.add_argument(‘blink-settings=imagesEnabled=false’) # 不加載圖片, 提升速度
options.binary_location = r"C:\Program Files (x86)\Google\Chrome\Application\chrome.exe" # 手動指定使用的瀏覽器位置
options.add_argument(‘lang=en_US’) # 設置語言
prefs = {“”:“”}
prefs[“credentials_enable_service”] = False
prefs[“profile.password_manager_enabled”] = False
chrome_option_set.add_experimental_option(“prefs”, prefs) # 屏蔽’保存密碼’提示框
更多flags參數請參考:[https://blog.alanwei.com/blog/2021/03/15/chrome-flags/]
其他配置方式
可以自己復制谷歌瀏覽器的配置文件夾修改,并在啟動時指定使用的文件夾
from selenium import webdriver
from selenium.webdriver.chrome.options import Optionsoptions = webdriver.ChromeOptions()
options.add_argument("user-data-dir=C:\\Users\\username\\AppData\\Local\\Google\\Chrome\\User Data\\Default")
driver = webdriver.Chrome(chrome_options=options)
driver.get("https://ceshiren.com")
使用同一個瀏覽器進行多次操作
首先用cmd從谷歌瀏覽器目錄以指定端口啟動瀏覽器:
chrome.exe --remote-debugging-port=12306
再在腳本中使用參數來獲取連接,這樣就可以一直使用命令行打開的谷歌瀏覽器進行操作
from selenium import webdriver
from selenium.webdriver.chrome.options import Optionsoptions = Options()
options.add_experimental_option("debuggerAddress", "127.0.0.1:12306")
driver = webdriver.Chrome(options=options)
?上面的參數很多不是經常用到或者在selenium操作過程中使用,所以這里并沒有驗證,供大家參考。
)


![[LeetBook]【學習日記】類鏈表反轉——尋找倒數第cnt個元素](http://pic.xiahunao.cn/[LeetBook]【學習日記】類鏈表反轉——尋找倒數第cnt個元素)


)








)



—— 前端開發規范之命名規范、html 規范、css 規范、js 規范)