大數據核心技術概述
大數據基石三大論文:GFS(Hadoop HDFS)、BigTable(Apache HBase)、MapReduce(Hadoop MapReduce)。
搜索引擎的核心任務:一是數據采集,也就是網頁的爬取;二是數據搜索,也就是索引的構建。 數據采集離不開存儲,索引的構建也需要大量計算,所以存儲容器和計算能力貫穿搜索引擎的整個更迭過程。
Google在 2003/2004/2006 年相繼發布谷歌分布式文件系統 GFS(被Hadoop HDFS借鑒)、大數據分布式計算框架 MapReduce(被Hadoop MapReduce借鑒)、大數據 NoSQL數據庫 BigTable (被Apache Hbase借鑒),這三篇論文奠定了大數據技術的基石。
大數據基石三大論文——GFS
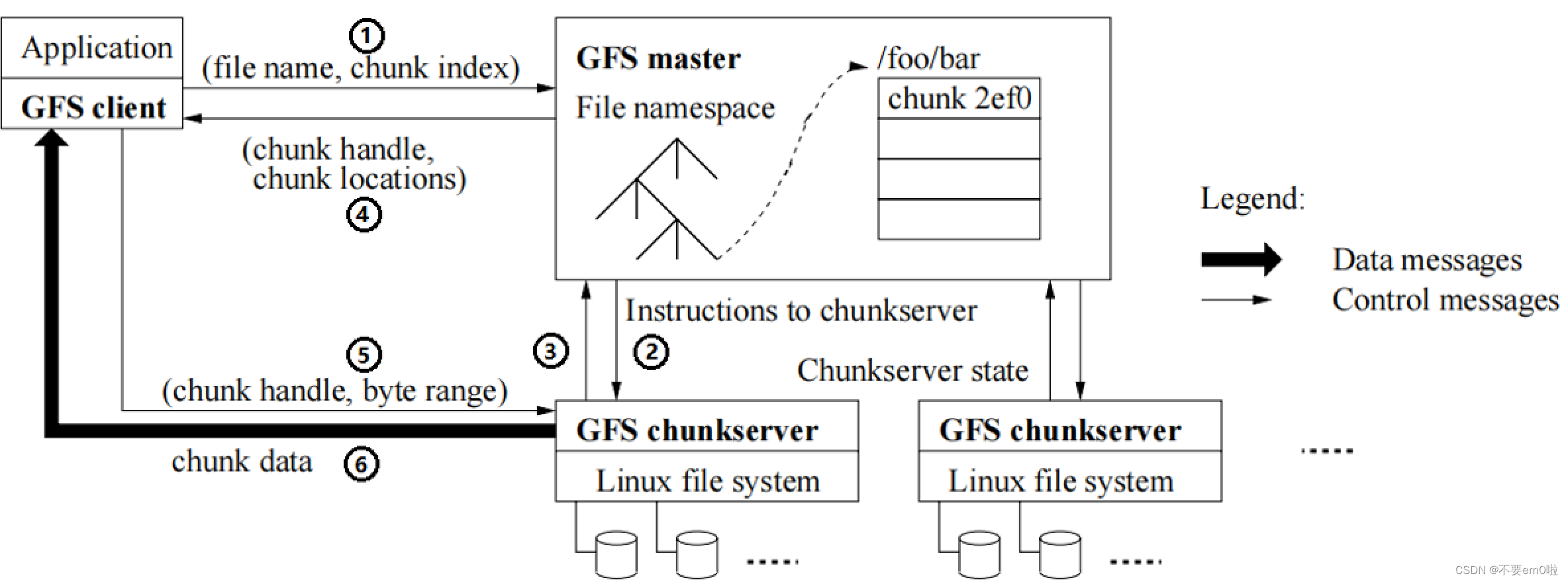
?GFS解決復雜工程問題的設計細節如下:
- 簡化系統元信息:Master 中維持了兩個重要的映射,分別是文件路徑到邏輯數據塊,邏輯塊與其多副本之間的關系。
- 較大的數據塊:選擇了當時看來相當大的 64M 作為數據存儲的基本單位,以此來減少元信息。
- 放寬的一致性:允許多副本間內容不一致來簡化實現、提高性能,通過讀校驗來保證損壞數據對用戶不可見。
- 高效副本同步:在多副本同步時分離控制流和數據流,利用網絡拓撲提高同步效率。
- 租約分散壓力:Master 通過租約將部分權力下放給某個 Chunkserver ,負責某個塊的多副本間的讀寫控制。
- 追加并發優化:多客戶端對同一文件進行并發追加,保證數據原子性及At Least Once的語義。
- 快速備份支持:使用 COW(Copy on Write) 策略實現快照操作,并通過塊的引用計數來進行寫時拷貝。
- 逐節點鎖控制:對于每個操作,需要沿著文件路徑逐節點獲取讀鎖,葉子節點獲取讀鎖或者寫鎖,當然文件路徑會進行前綴壓縮。
- 異步垃圾回收:將數據刪除與其他一些主節點的維護操作(損壞塊清除,過期數據塊移除)統一起來,成為一個定期過程。
- 版本號標記:幫助客戶端識別過期數據。
- 數據塊校驗和:針對每 64KB 的小塊打上 32 bit 的校驗和。
大數據基石三大論文——BigTable
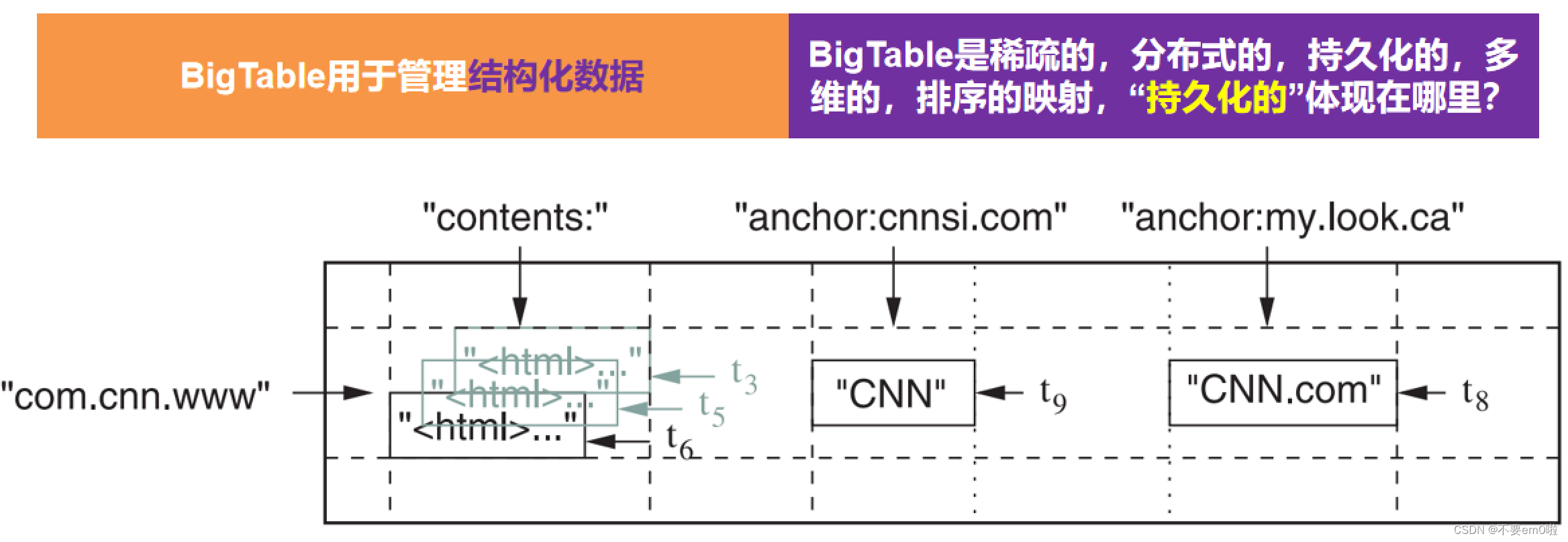
?
大數據基石三大論文——MapReduce?

大數據技術體系——以Hadoop為例
Hadoop1.0
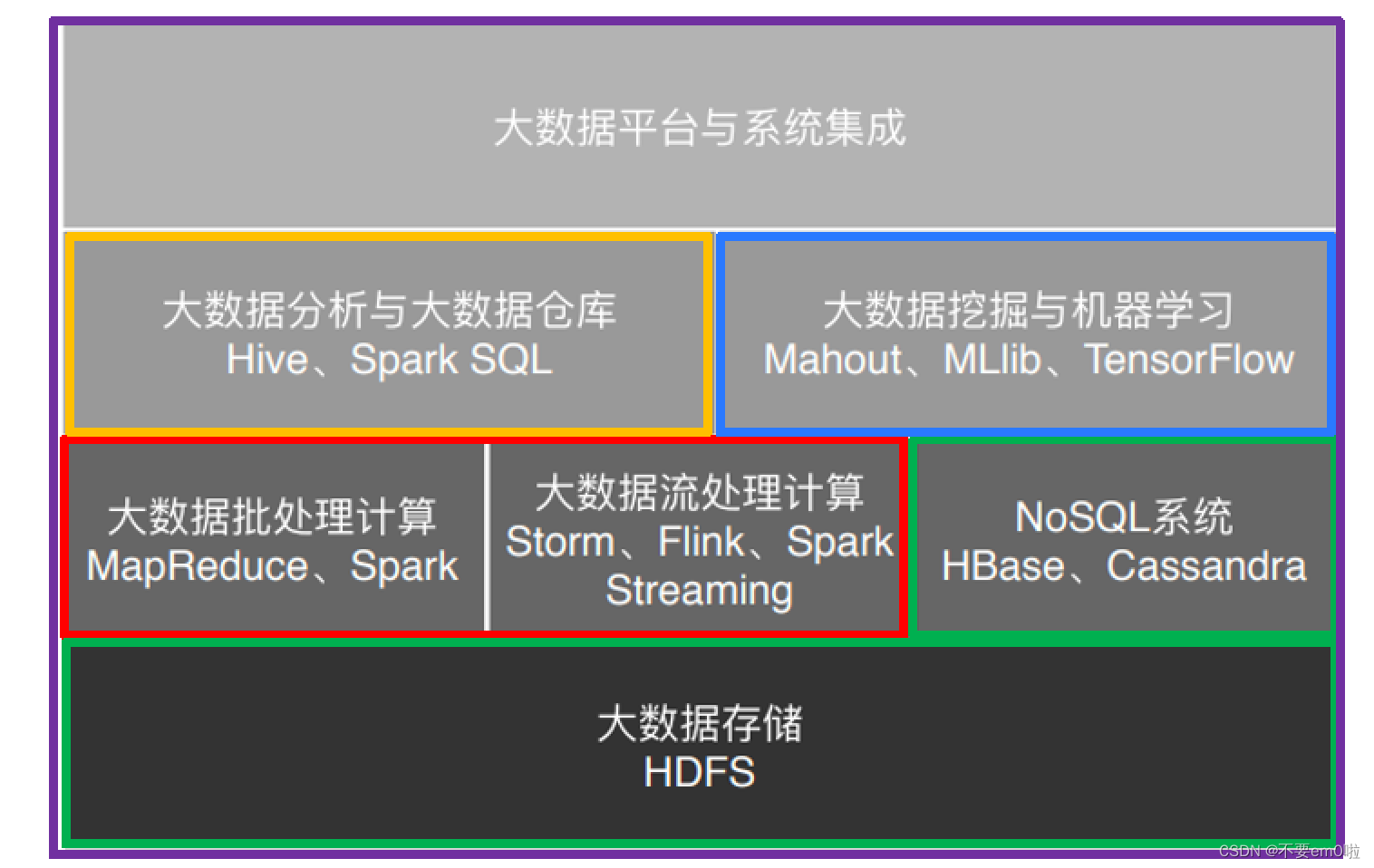
Hadoop2.0
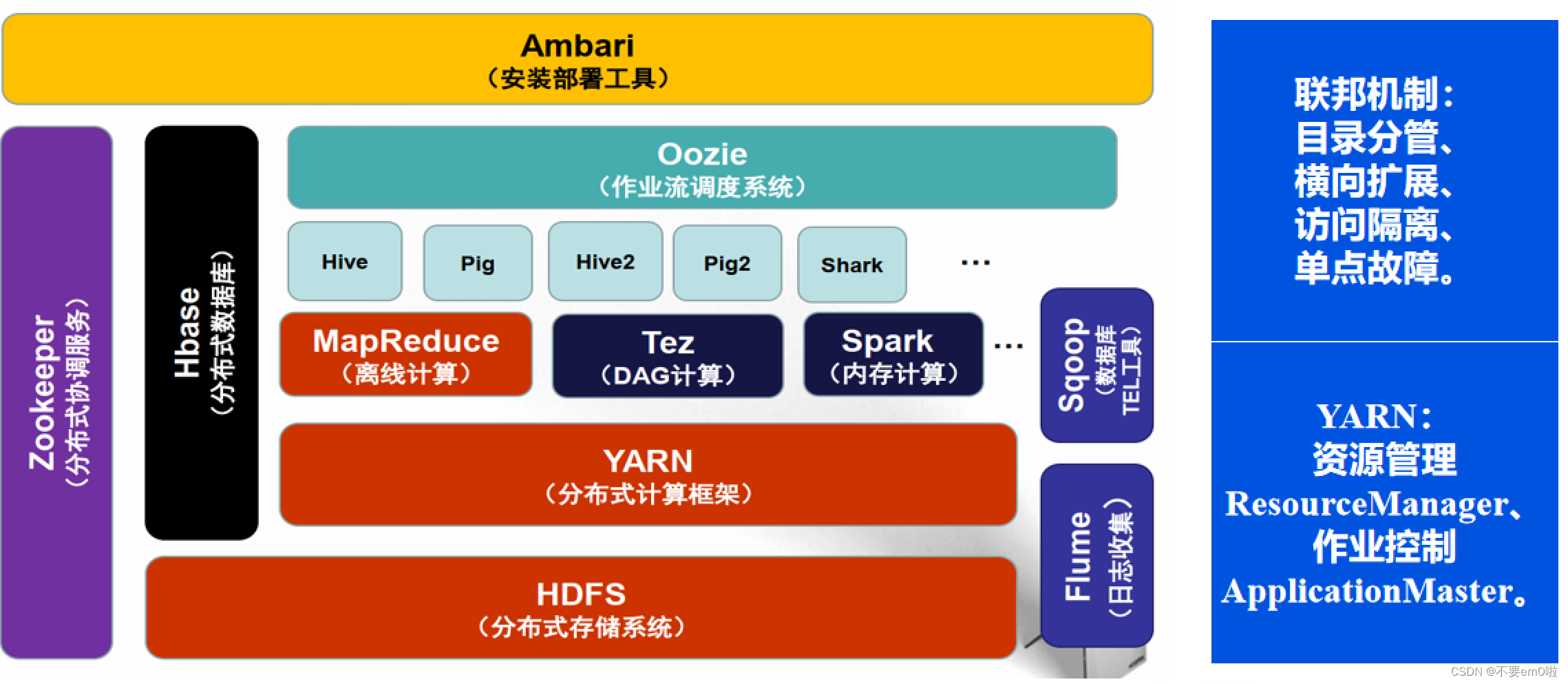
Hadoop的優勢?
- 易用性(低成本):Hadoop開源,軟件使用成本低;Hadoop可以運行在廉價機器構成的大型集群上,硬件使用成本低。
- 高可靠性(高容錯性):Hadoop能夠保存數據的多個副本,自動檢測處理節點失敗的情況,并能夠自動重新分配失敗的任務。
- 高效性:Hadoop能夠在節點之間動態的移動數據,并保證各個節點的動態平衡,因此處理速度非常快。
- 高擴展性:Hadoop在計算機集群上分配數據并完成計算任務,計算機集群中可以增設節點。









系統國際標準解讀(一))
)


:ProWindow和WPF的一些技巧)



)

)