目錄
一、數據需求產生
二、OLAP選型
2.1 需求
2.2 調研
?2.3 對比
三、StarRocks的優勢
四、業務場景和技術方案
4.1 整體的數據架構
4.2 BI自助/報表/多維分析
4.3 實時事件分析
4.5 直播教室引擎性能監控
4.4 B端業務后臺—斑馬
4.5 學校端數據產品—飛象星球
4.6 電商訂單分析
五、基礎建設
5.1 運維
5.2 EMR-Serverless- StarRocks
原文大佬寫的這篇EMR StarRocks數倉建設案例有借鑒意義,這里摘抄下來用作學習和知識沉淀。
一、數據需求產生
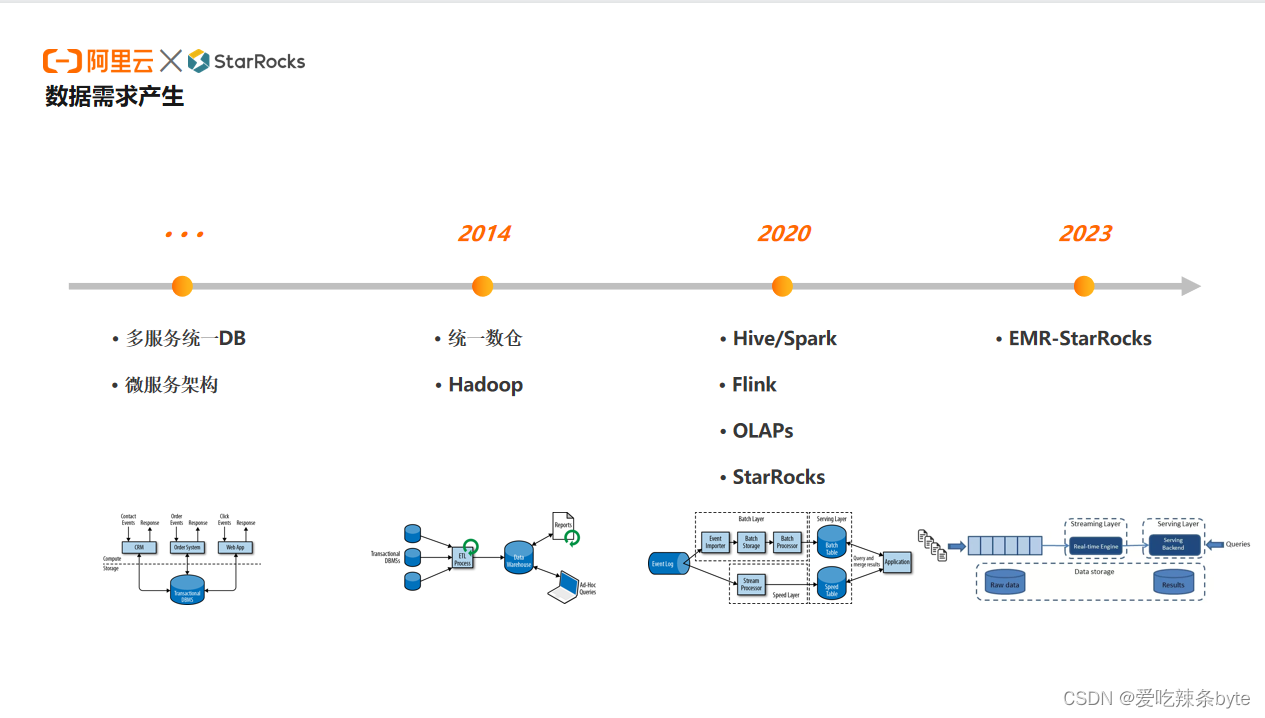
? ? 猿輔導成立多年,早期是基于關系型的 MySQL 數據庫來做數據的需求。隨著業務的發展,多個服務在一個 DB 去做數據的匯總,以及一些微服務架構的產生,使得數據逐漸走向分裂,很難在 MySQL 里完成統一的數倉。
? 因此在2014年,公司開始了統一數倉的假設,采用的是比較成熟的Hadoop體系。雖然是用hive,mapreduce做離線的批量ETL,但是為了保證用戶交互足夠快,延遲足夠短,還是會把最終的應用層的數據放在Mysql中來處理,包括現在很多離線需求也仍然是這樣的一個鏈路。
? ?隨著公司業務的快速增長,以及一些新的業務形態的出現,以Mysql作為BI存儲底座的瓶頸愈發明顯。2020年,新冠疫情爆發,公司業務出現了爆發式的增長,原本的離線t+1的鏈路已無法滿足業務上的數據需求。但是,我們做了很多實時的需求,有一條離線鏈路,一條實時鏈路,在應用層的存儲上完成實時和離線的統一。為了應對不同的業務業務場景,又引入了很多新的OLAP引擎來做不同的需求。我們希望能夠有一個引擎,可以完成在AP場景下的統一,此時發現了StarRocks。目前,除了自建的一些StarRocks集群,我們也在跟阿里云團隊合作,使用云上EMR的集群,是一個混合云多集群的模式。
二、OLAP選型
2.1 需求
? ?接下來介紹在 OLAP選型時,我們考慮的一些問題點。
? ?猿輔導 OLAP 支撐的場景,包括商業分析,廣告轉化,業務監控,還有一些用戶觸達等。很多BL應用還是在用Mysql來做存儲底座。所以需要去兼容原來的Mysql協議,也需要兼顧到查詢的性能,我們的需求主要有八點:
- 亞秒級的數據查詢延遲;
- 支持 大寬表以及多表join;
- 具備高并發的能力;
- 支持數據的流式和批式攝入;
- 支持標準化的sql;
- 具備高性能的精準去重能力;
- 低的運維成本;
- 能夠靈活的橫向擴縮容;
- 用戶對于業務是無感知的;
2.2 調研

? ?開源OLAP引擎分為MOLAP和ROLAP,前者屬于預計算方式,后者是關系行的模型,ROLAP又分為基于MPP的和DAG的基于Hadoo底座的這部分。
?2.3 對比
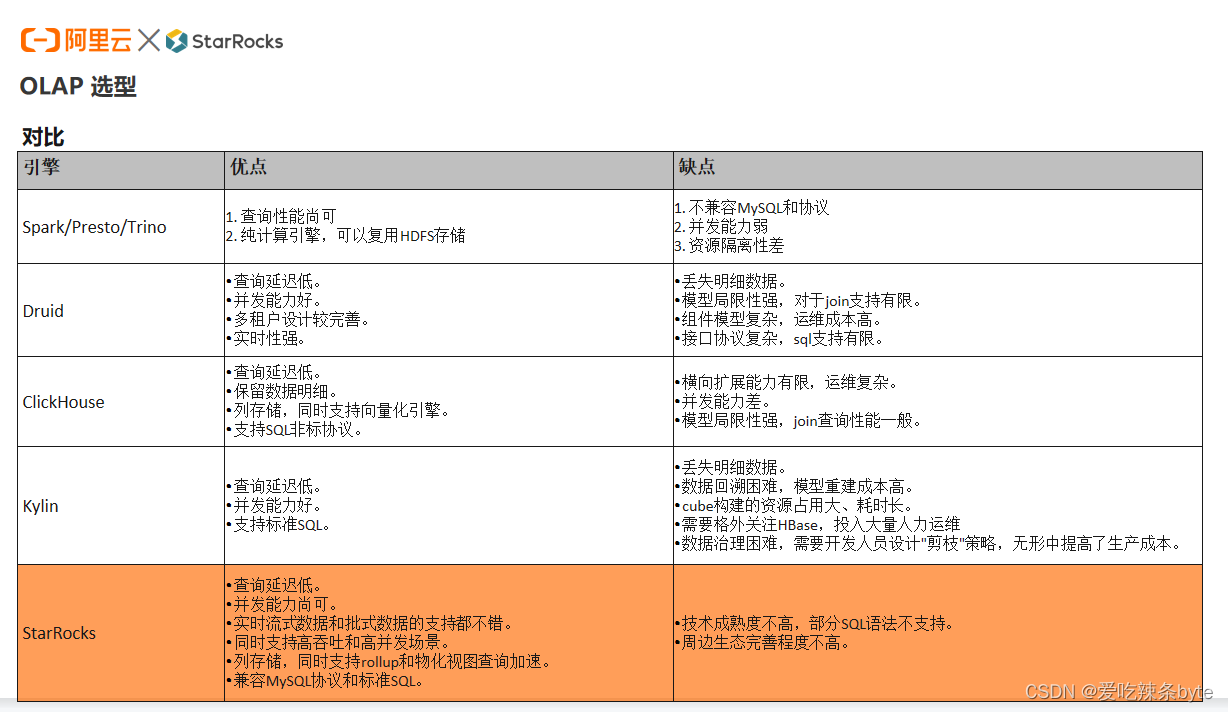
? 我們對比了不同引擎的優缺點。可以看到 Spark、 Presto 、Trino 引擎,更適合去做批處理,做一些查詢的加速,但是在并發場景下,支撐的能力是不夠的。Druid、Kylin引擎,因為是構建預計算的物化的能力,數據重放的成本會非常高,同時對數據開發人員的要求也相對較高,而 Doris 和 Clickhouse 的 MPP 架構的引擎,相比較下更能夠滿足當時的BI需求。考慮到運維成本以及多樣化的模型,當時選擇了Doris。隨后又發現 Doris 跟 StarRocks 相比,性能上還是會有一些差別。
? 下圖是我們當時做的一個Benchmark(性能測試),主要是拿猿輔導內部的一些BI場景的SQL來做的一個對比,可以發現可以發現當時 StarRocks 借助于它本身優秀的向量化引擎的能力,能夠在大部分場景下比 Doris有 2 到 3 倍的性能提升(這里的性能主要指查詢的延遲)

三、StarRocks的優勢
? StarRocks最大的優勢是極致性能。主要得益于列存,高效的IO,高效的編碼的存儲,豐富的索引加速(包括前綴索引、Bitmap倒排索引),物化視圖的加速查詢,全面的向量化,以及它的MPP的架構,通過并行執行中間結果不落盤的方式,能夠讓結果更快的跑出來,并且能夠在集群規模擴大的時候帶來性能的線性提升。
? ?第二個優勢是模型豐富,在猿輔導主要用到的是更新模型,目前在做的是把更多場景逐漸往主鍵模型上過渡,因為我們的很多場景是依賴于實時CDC的數據,它對 CDC 流有著更好的實時更新性能。另外,它原生的分區分桶設計架構,能夠利用到數據的冷熱的存儲,能夠利用分區裁剪的性能去更好的提升查詢性能。
? 另外StarRocks 也在快速迭代,經常能給我們帶來很多新的特性。比如 CBO,對比原本在之前的查詢優化和CPU的優化器,在一些場景下,可以看到3到4倍的性能提升。第二個是Catalog,因為數據底層存在很多不同的數據引擎,所以希望在 Catalog 這一層能夠去融合更多的數據,包括 Hive、MySQL、ES,以及 StarRocks 的其他集群,都可以在 Catalog 這層去做統一。第三是資源管理,可以用到 StarRocks 的資源管理的能力,做不同場景的大小查詢的一個隔離,可以做到查詢的熔斷,可以在CPU,內存包括并發上做一些限制。另外一個是異步多表物化視圖。
四、業務場景和技術方案
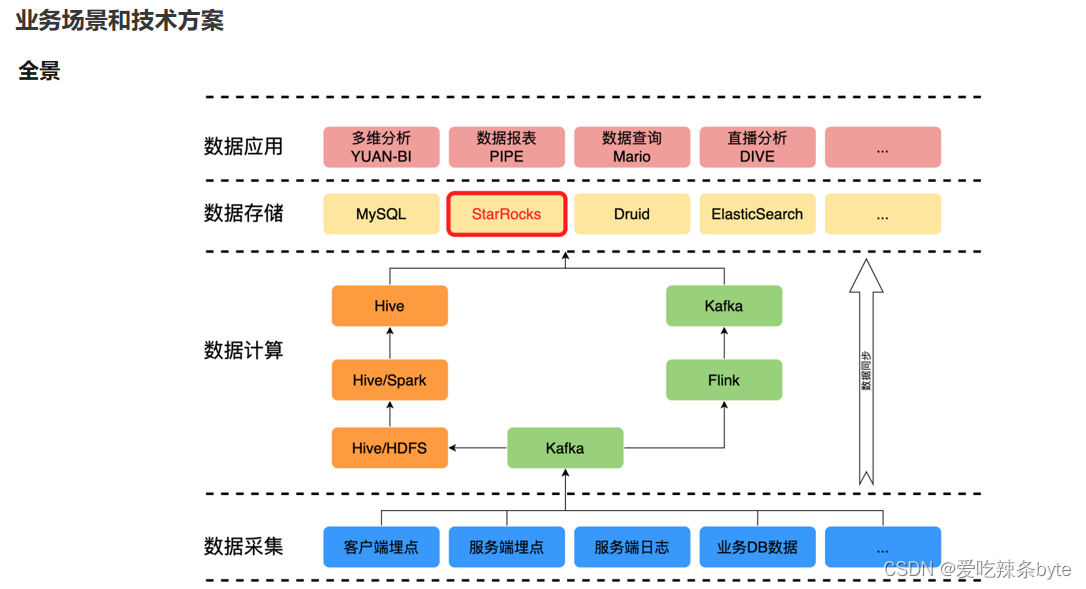
? 下面介紹一些在公司內落地的場景。 首先來介紹一下整體的數據架構。
4.1 整體的數據架構
4.2 BI自助/報表/多維分析
? ? 我們比較少用StarRocks來做數據計算,更多的還是將其作為數據應用的存儲底座。現在 StarRocks 最重要的一個場景,就是 BI 報表、多維分析的場景,如下圖:
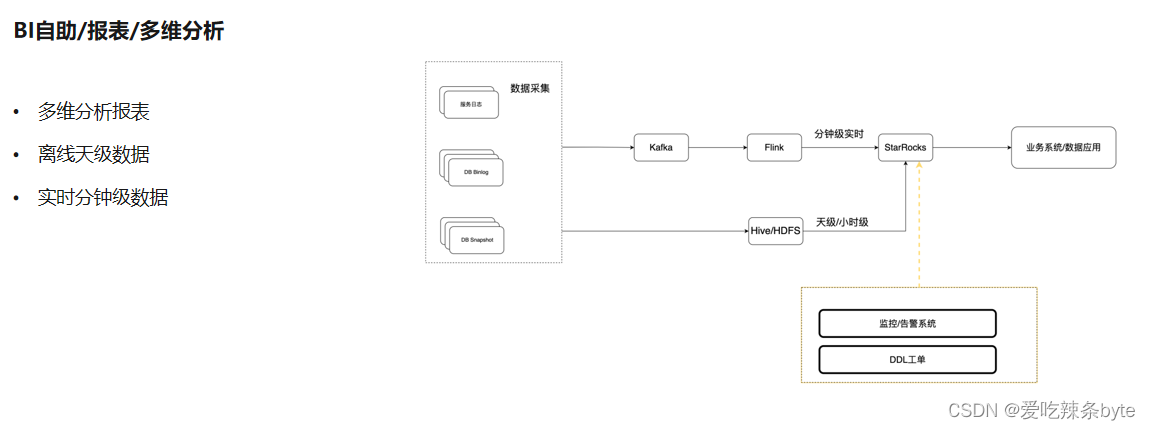
? 它還是一個Lambda架構,會有一些原始數據,比如業務 DB,有一些業務的日志埋點數據,實時這部分鏈路是kafka到flink,最終到starrocks,是分鐘級的數據;離線部分是 Hive 架構,主要是以天級和小時級的數據放到 StarRocks,上層去對接報表的應用。
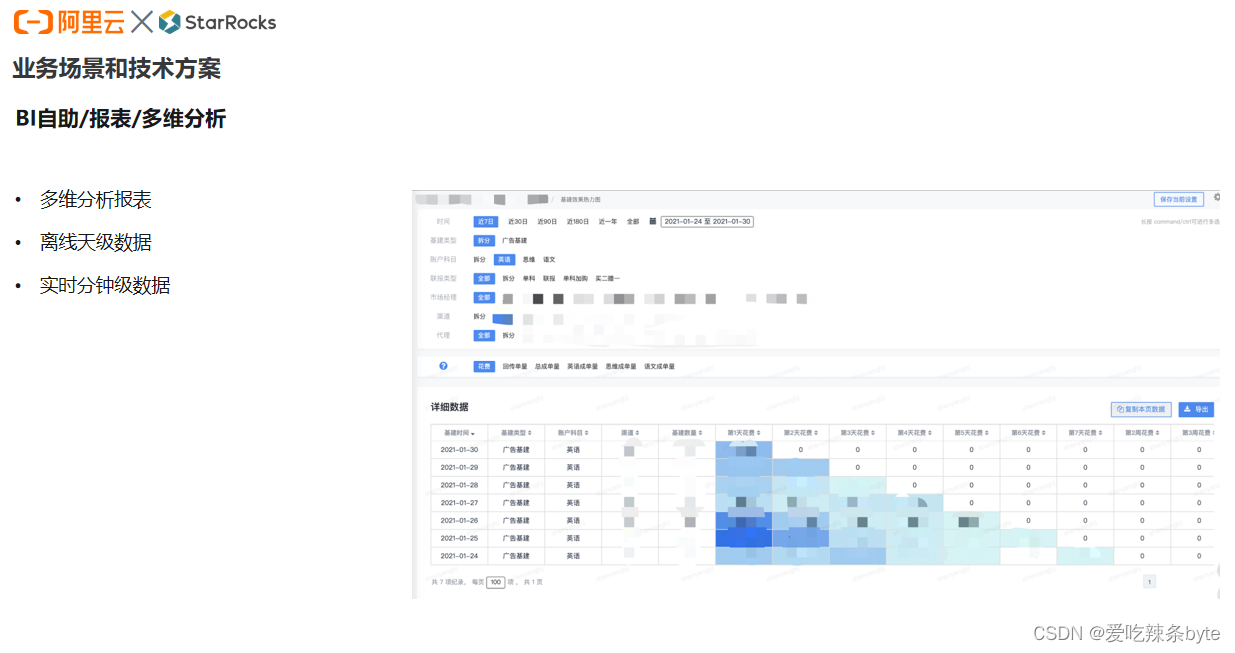
? ?上圖是一個多維分析報表,它是基于后臺寫的一個SQL,在前臺的報表進行多維的分析。原本是用Mysql做的BI報表的底座,但是在數據規模超過百萬,遇到一些高技術維度,多維度的數據的時候,查詢性能就會比較慢,所以用StarRocks替代Mysql來做多維分析,帶來的提升非常明顯。

?上圖也是一個BI的場景,是完全基于StarRocks做的一個指標平臺。它是一個 NOSQL 的方案,會由數倉的同學首先預先定義一些維度和指標。用戶在使用的時候,會先定義一個數據源,選擇一些維度,選擇一些指標,基于數據源再去生成一些單圖,再把它做成看板,當用戶自助的去生成一些圖表的時,后臺會轉換成一個SQL來執行。
?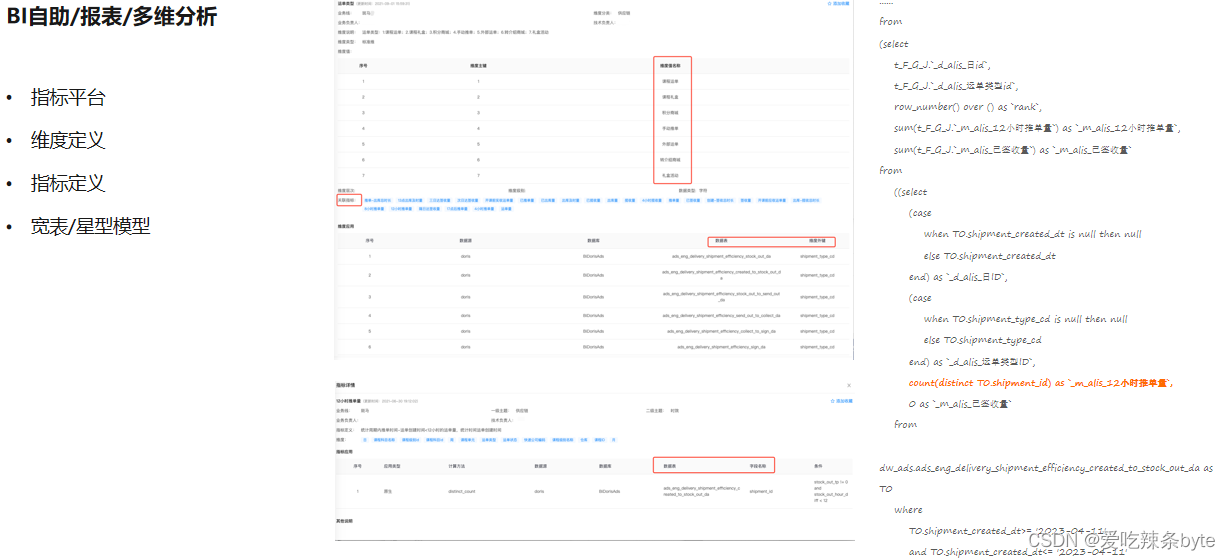
? ?上圖是一個簡單的例子,上圖左上角是定義一些維度表,左下角是指標的定義,包括其查詢條件和計算方式,右邊可以看到在實際執行的SQL。這里的數據還是以離線數倉為主,因為需要對模型有一個明確的定義。
4.3 實時事件分析
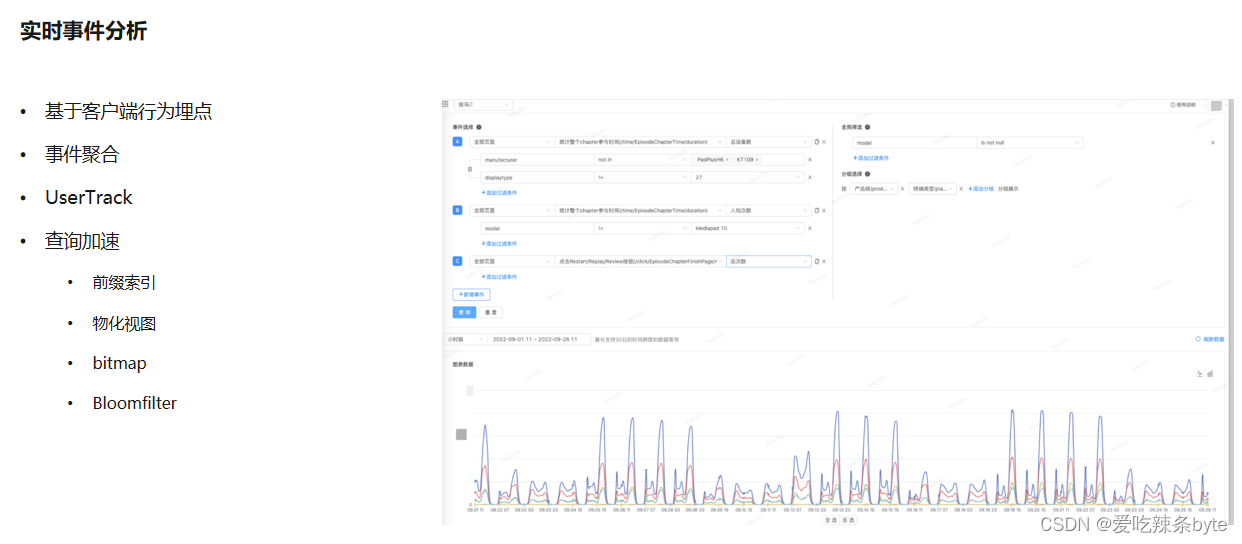
? 上圖是一個用戶的行為分析。主要是基于客戶端的用戶行為埋點數據。最早的時候,是通過 Druid 來做的,Druid在時序數據方面的性能還是非常不錯的,但是對于一些復雜的查詢,它本身提供的算子是比較有限的。另外希望能對維度數據做一些組合,Druid也是無法實現。所以我們用StarRocks把用戶行為分析做了重構。利用到StarRocks查詢加速的能力,去給用戶提供實踐的聚合數據,能提供UserTrack 的一個能力。
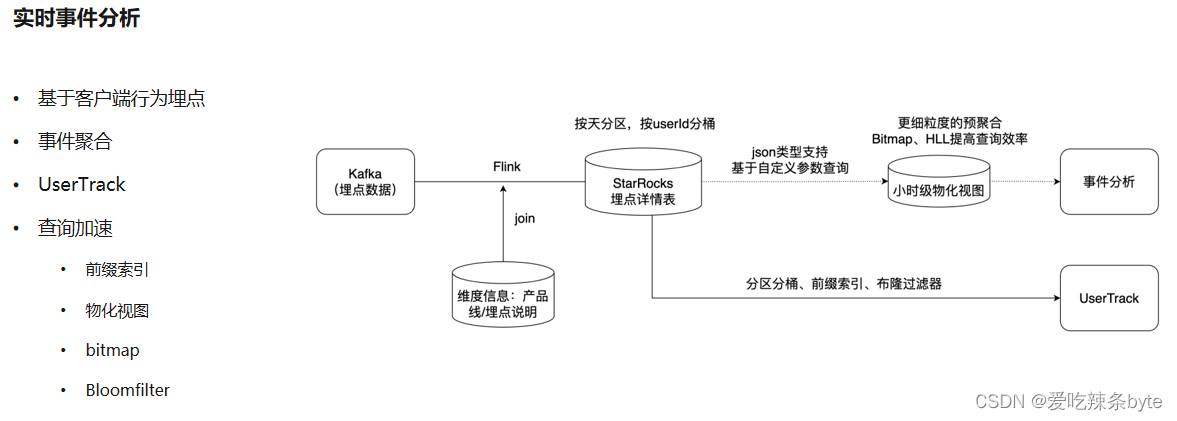
? 它的鏈路也比較簡單,會把埋點數據往kafka里面放一份,在flink這一層去增加一些維度信息,包括產品線,埋點的元數據。在StarRocks里會先嘗試做一層明細表,按照天做分區,按照用戶id去做分桶,在?UserTrack 場景下,以用戶維度去看這部分數據的時候,主要利用到分區分桶的能力,利用它的前綴索引和Bloomfilter過濾器,去實現快速地點查,以及高并發查詢的需求。在事件分析的場景,主要是用到了小時的物化視圖,去加速查詢,利用bitmap做精準的用戶去重計算,用HLL來做設備維度的模糊去重。

? ?上圖展示的是研發的一個監控看板,場景實時采集引擎指標,進行數據分析,也有一些主題化定制的報表。數倉的粒度分的比較粗放,會放一層明細,有一些維度的數據,再做一些聚合。
4.5 直播教室引擎性能監控
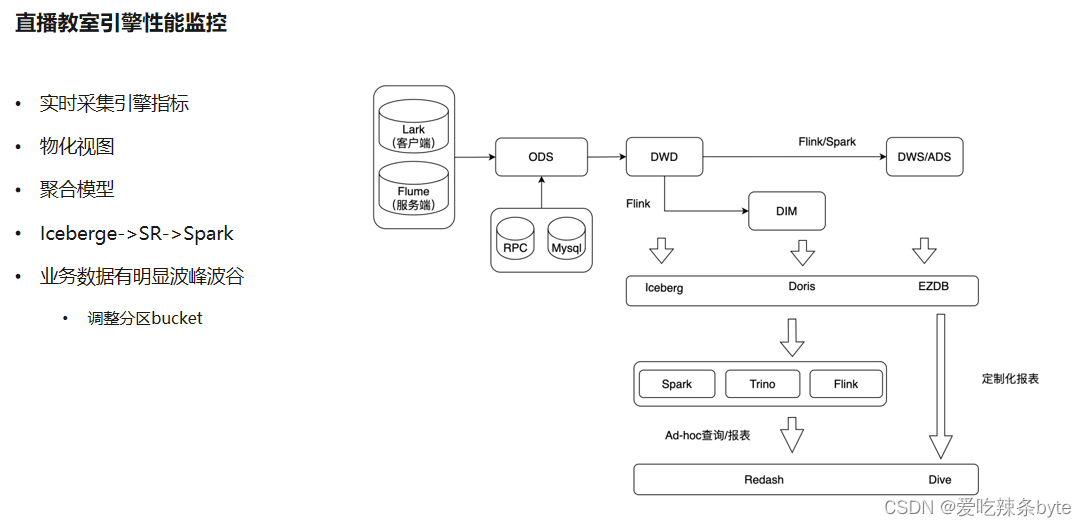
? ? 值得一提的是,這套架構相對較復雜,因為有一部分數據是通過湖式的數據來做第一層數據接入,會先往 Iceberge 里存一次,中間通過 Spark 、 Flink 的引擎去計算,再往 StarRocks 里放,并且會在 Hive 和 StarRocks 去做數據的雙寫。
?另外,互聯網教育直播課堂有一個特點是它的波峰波谷特別明顯,因為孩子們大部分是在同一個時間段上課,比如在周五下午上課,在上課的這兩三個小時里面的數據量是非常爆炸的,平時的時候就沒有什么流量。它帶來的一個問題是,StarRocks的表都是按照天,小時去做分區的,波峰時段的單個分區的數據就會非常多,分區里的template會非常大,那么在這個時候做compaction,對集群的性能消耗就會非常嚴重。所以這里做了一個自適應的處理,會去動態調整partition的bucket,保證整個的查詢性能保持在一個比較穩定的水平上。
4.4 B端業務后臺—斑馬

? 上面是一個B端的業務后臺,主要是給老師的一些數據看板,叫斑馬數據看板。它主要是做督學看板、學情溝通,幫助老師去做學生上課情況的一些追蹤,去做一些反饋。
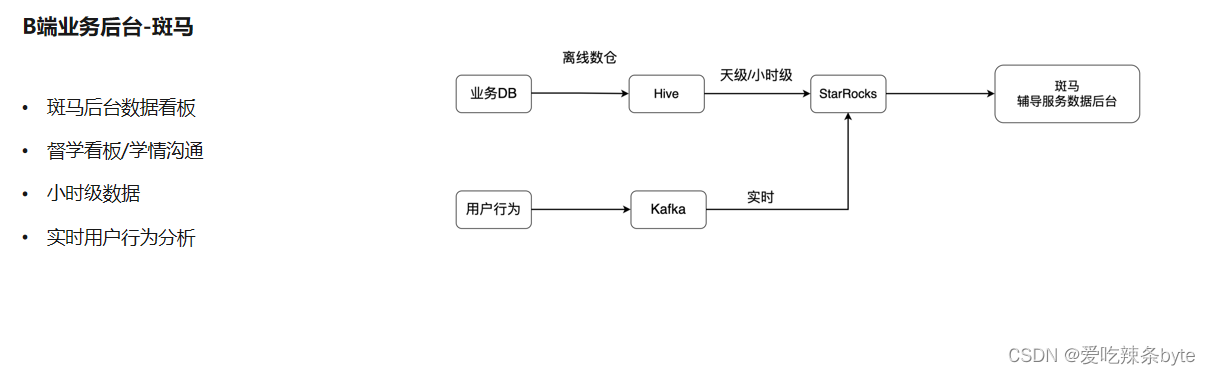
? ?它的特點主要是以小時的數據為主,也會有一些實時的用戶行為的數據。這也是一個比較經典的鏈路,數倉的數據會放到hive里,以小時級放到StarRocks,直接才業務的后臺去查詢。它幾乎涵蓋了目前斑馬所有的業務場景,包括課程的體驗、電商的增長,以及一些輔導的服務等等。

?上面是猿輔導的一個 B 端的場景,是輔導老師工作臺。它的特點是重度依賴于數倉的加工數據,大部分的數據源是由數倉同學先加工好的比較標準的數據,并且指標和維度都是預先明確定義的
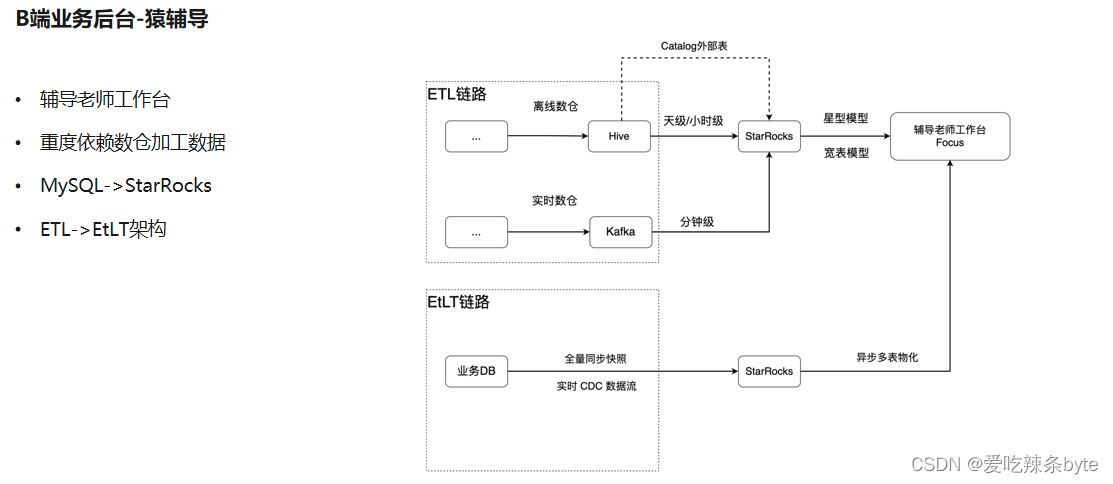
? 上述鏈路中,由一部分用的是離線數倉的數據,也有一部分用的實時數倉的數據。這些數據還是通過天級,小時級,分鐘級的粒度同步到StarRocks里。這里用到了Catalog 做外表,因為對于分區裁剪的性能沒有很高的要求,數據量不大的情況下,通過Catalog 外表能夠更敏捷、更快速地在業務上使用倉庫的數據。
4.5 學校端數據產品—飛象星球

? 飛象星球是公司一個比較新的產品線,它是給學校以及政府教育相關部門提供的教育產品,飛象 BI 產品主要是把抽象化的數據通過可視化的報表提供給客戶,它是完全基于StarRocks的底座來實現的。圖中可以看到,除了一些可視化的能力以外,它還支持用戶按照表和字段去定義后臺的數據源模型,通過 NOSQL 的方式,自己去配置數據看板。

? 由上圖可知,它的數據鏈路比較簡單,主要是業務DB,先同步到 Hive 里,再同步到 StarRocks ,最近也在推動 CDC 同步的事情,希望未來能夠完全實現從業務 DB 直接到StarRocks 的同步的方式,減少中間的鏈路。
4.6 電商訂單分析
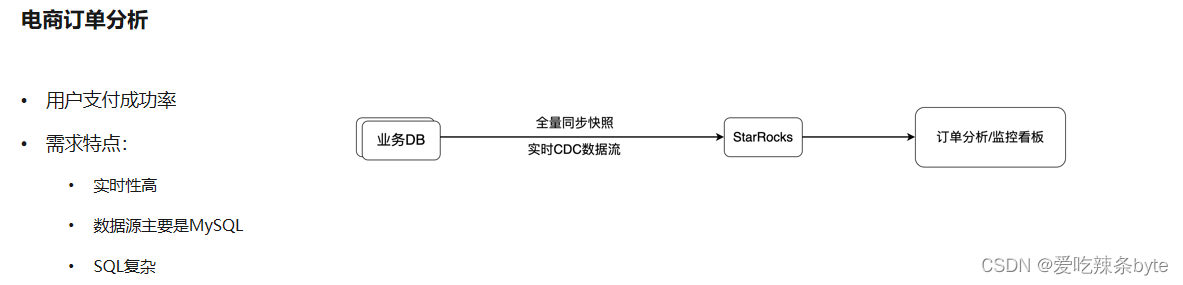
? 最后一個案例是比較新的一個鏈路,它是一個電商場景,做用戶支持成功率的監控,幫助電商的同學去做問題的排查。特點是實時性要求比較高,原本的業務DB的數據量非常大,業務的DB會做一些分庫分表的架構,也有一些多表Join的需求,所以業務的數據是沒有辦法直接來做分析的,所以我們把它通過CDC的方式同步到 StarRocks 里,統一用 StarRocks 去處理。目前來看跑的效果非常好,由業務的研發同學直接來主導,不需要數據開發同學來介入。
五、基礎建設
再簡單介紹一下我們做的基礎建設。
5.1 運維
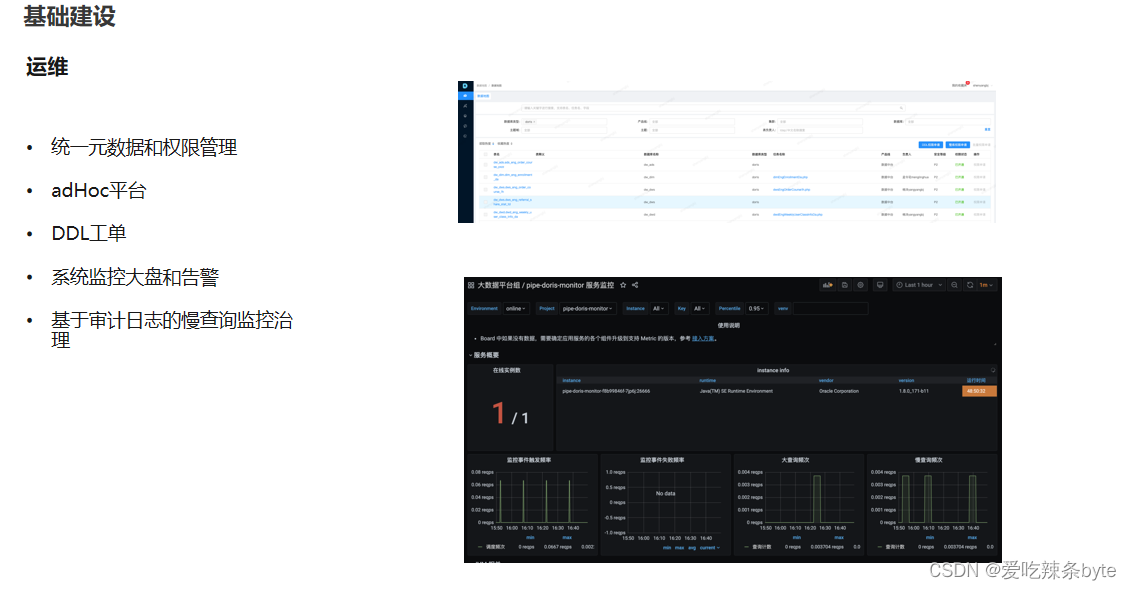
? ? 我們自研了一些平臺化的工具,例如統一的元數據、權限管理平臺。還有一套adHoc平臺(即席查詢),幫助用戶做數據分析和數據提取。DDL工單系統,主要是幫用戶去做數據的規范和權限的約束。另外,還有基于原生的系統去做監控大盤和告警,基于審計日志去做慢查詢的監控,幫助用戶持續優化查詢性能。
? ?目前正在推進的工作包括,首先從UNIQ 模型去往 PRI 模型演進;第二是希望把Mysql到StarRocks同步的鏈路做的更輕,更快,通過一個平臺化的工具把這條鏈路打通,能夠實現離線的快照,也能實現實時的同步;另外,因為整個StarRocks的集群非常多,大概有七八個集群,新的業務將會開更多的集群,所以需要有一些跨集群的數據同步的能力。
? ?再來討論一下自建和上云。如果僅從機器層面來考慮,那么自建集群的成本是更低的。但如果結合人力和機器成本來看的話,阿里云EMR則有一些優勢。公司本身在大數據上的團隊規模不是很大,大家要維護的組件和服務非常多,EMR能夠提供一個比較好的協助和補充。首先是彈性的能力,當一些業務需要快速地去開一個集群,需要快速地去擴縮容的時候,可以利用到彈性的能力去實現,并且可以隨時地去釋放;另外,StarRocks 社區迭代非常快,我們在快速跟進和學習的過程中,難免會遇到一些問題,可能沒有辦法很快地得到社區的反饋,這時與阿里云的團隊合作,就能夠得到一個比較好的專家支持服務。
? 我們現在是以自建和EMR集群混合云的模式,去支撐業務需求。對于一些業務上跑得比較快,尤其是一些 B 端的,隔離性要求非常高的場景,更傾向于在阿里云上直接開 EMR 的集群。
5.2 EMR-Serverless- StarRocks
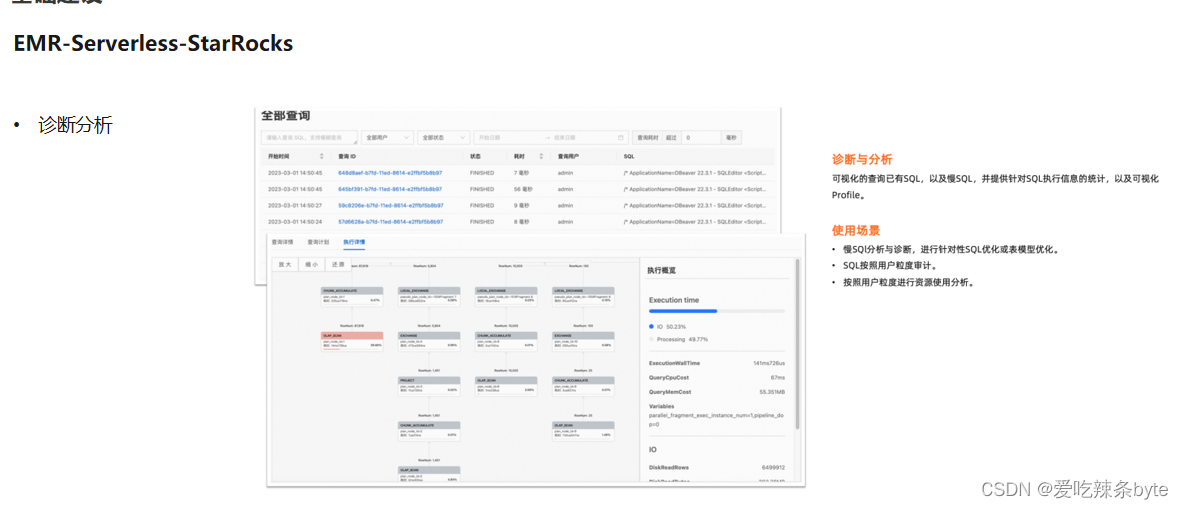
? ?最近也在跟阿里云EMR合作去測試Serverless- StarRocks的產品。在新的產品形態下面能夠提供給用戶的,首先是診斷分析的能力,能夠幫助用戶可視化的去檢索到慢SQL,從而可以對SQL進行針對性優化。第二是它能夠提供一個比較好的用戶管理和權限管理的能力,提升運維同學的工作效率。另外,也希望借助未來 StarRocks 3.0 以上存儲分離的架構,節省更多的成本。
參考文章:
猿輔導基于 EMR StarRocks 的 OLAP 演進之路-阿里云開發者社區
)

)

Vue環境搭建第一個項目)

(一)-CNN的基本原理與結構)


)





運行時間)



