圖像識別
- 信息時代的一門重要技術;
- 目的是讓計算機代替人類處理大量的物理信息;
- 隨著計算機技術的發展,人類對圖像識別技術的認識越來越深刻;
- 圖像識別技術利用計算機對圖像進行處理\分析\理解,識別不同模式的目標和對象;
- 過程分為信息的獲取\預處理\特征抽取和選擇\分類器設計\分類決策;
模式識別
- 是人工智能和信息科學的重要組成部分;
- 指對表示事物或現象的不同形式的信息做分析和處理,得到對事物或現象描述\辨認和分類的過程;
- 計算機圖像識別技術是模擬人類的圖像識別過程;
- 在圖像識別的過程中進行模式識別是必不可少的;
- 模式識別是人類的一項基本智能;
- 隨著計算機的發展和人工智能的興起;
- 人類本身的模式識別滿足不了生活的需要;
- 希望用計算機代替或擴展人類的部分腦力勞動,于是產生了計算機模式識別;
- 模式識別就是對數據進行分類,與數學緊密結合,所用思想大部分是概率與統計;
圖像識別的過程
- 信息的獲取;
- 預處理;
- 特征抽取和選擇;
- 分類器設計;
信息的獲取
- 通過傳感器,將光或聲音等信息轉化為電信號;
- 通過某種方法將其轉變為機器能夠認識的信息;
預處理
- 指圖像處理中的去噪\平滑\變換等操作;
- 加強圖像的重要特征;
- 圖像增強;
特征抽取和選擇
- 模式識別中,需要進行特征抽取和選擇;
- 是圖像識別過程中非常關鍵的技術;
分類器設計
- 通過訓練得到一種識別規則;
- 通過該識別規則得到一種特征分類;
- 使得圖像識別技術可以得到高德識別率;
- 分類決策時在特征空間中對被識別對象進行分類;
- 從而更好的識別所研究的對象;
圖像識別的應用
- 圖像分類
- 網絡搜索
- 以圖搜圖
- 智能家居
- 拍照識別/掃描識別
- 農林:森林調查;
- 金融
- 安防
- 醫療
- 娛樂監管
機器學習方法的發展

分類與檢測
- 分類是識別圖片內容,并進行歸類的過程;
- 檢測是知道了圖片的內容,在圖片中將其框選出來的過程;
- 分類與檢測在很多領域廣泛應用;
分類與檢測的應用領域
- ?人臉識別
- 行人檢測
- 智能視頻分析
- 行人跟蹤
- 交通場景物體識別
- 車輛計數
- 逆行檢測
- 車牌檢測與識別;
- 基于內容的圖像檢索
- 相冊自動歸類

常見的卷積神經網絡
?
VGG
- VGG的經典之處在首次將深度學習做的非常"深",達到16-19層;
- 同時使用了非常小的卷積核(3x3);

VGG16

- 一張原始圖片,resize到(224,224,3);
- conv1兩次[3,3]卷積,輸出特征層64,形狀為(224,224,64),2x2最大池化,輸出net(112,112,64);
- conv2兩次[3,3]卷積,輸出特征層128,形狀為(112,112,128),2x2最大池化,輸出net(56,56,128);
- conv3三次[3,3]卷積,輸出特征層256,形狀為(56,56,256),2x2最大池化,輸出net(28,28,256);
- conv3三次[3,3]卷積,輸出特征層256,形狀為(28,28,512),2x2最大池化,輸出net(14,14,512);
- conv3三次[3,3]卷積,輸出特征層256,形狀為(14,14,512),2x2最大池化,輸出net(7,7,512);
- 卷積模擬全鏈接層,效果等同,輸出net(1,1,4096),進行兩次;
- 卷積模擬全鏈接層,效果等同,輸出net(1,1,1000);
卷積層與全鏈接層的區別
- 卷積層為局部鏈接;
- 全鏈接層使用圖像的全局信息;
- 最大的局部等于全局;
- 說明全鏈接層使用卷積層替代可行;
卷積層代替全鏈接層
- 卷積層和全鏈接層都進行了一個點乘操作;
- 他們的函數形式相同;
- 全鏈接層可以轉化為對應的卷積層;
- 只需要把卷積核的尺寸變為和輸入的feature?map大小一致,為(h,w);
- 這樣卷積和全鏈接層的參數一樣多;
1X1卷積的作用
- 實現特征通道的升維和降維;
- 控制卷積核的數量,從而控制通道數;
- 池化層只改變尺寸,無法改變通道數;
Residual net(殘差網絡)
- 將靠前若干層的某一層數輸出直接跳過多層引入到后面數據層的輸入;
殘差神經單元
- 某段神經網絡的輸入為x;
- 期望輸出為H(x);
- 如果我們直接將輸入x傳到輸出作為初始結果;
- 需要學習的目標為:
;
- 這就是一個殘差神經單元;
- 相當于改變了學習目標;
- 不再是學習一個完整的輸出
;
- 而是學習輸出和輸入的差別:
,即殘差;

?直連卷積神經網絡與ResNet的區別
- ResNet有很多旁路的支線將輸入直連到后面的層;
- 后面的層可以直接學習殘差;
- 這種結構也被稱為shortcut或skip?connections;
- 傳統卷積層或全連接層在信息傳遞時會存在信息丟失\損耗等問題;
- ResNet直接將輸入信息繞道傳到輸出,保護信息的完整性;
- 整個網絡只學習輸入\輸出差別的那部分,簡化了學習目標和難度;

ResNet50
- ResNet50有兩個基本的模塊;
- 分別是Conv?Block和Identity?Block;
- Conv?Block的輸入和輸出維度不一樣,不能連續串聯;
- 其作用是改變網絡的維度;
- Identity Block輸入維度和輸出維度相同,可串聯,用于加深網絡;

BatchNormalization
- 所有輸出保證在0~1之間;
- 所有輸出數據的均值接近0;
- 標準差接近1的正態分布;
- 這樣能夠使數據落入激活函數的敏感區,避免梯度消失,加快收斂;
- 加快模型收斂速度,并具有一定的泛化能力;
- 可減少dropout的使用;

卷積神經網絡遷移學習-fine?tuning
- 實踐中,由于數據集不夠大,很少有人從頭開始訓練網絡;
- 常見的做法是使用預訓練的網絡;
- 對預訓練的網絡來重新fine-tuning;
- 或者使用預訓練網絡作為特征提取器;
- 遷移學習就是將訓練好的模型,通過簡單的調整快速移動到另一個數據集上;
- 隨模型層數及復雜度的增加,錯誤率不斷降低;
- 訓練復雜的神經網絡需要非常多的標注信息;
- 也需要長至幾天甚至幾周的訓練時間;
- 為了解決上述問題可以使用遷移學習;
常見的兩類遷移學習場景
- 卷積網絡當做特征提取器;
- Fine-tuning卷積網絡;
卷積網絡當做特征提取器
- 使用在ImageNet上預訓練的網絡;
- 去掉最后的全連接層;
- 剩余部分當做特征提取器;
- 這樣提取的特征稱為CNN節點;
- 可以使用線性分類器來分類圖像;
Fine-tuning卷積網絡
- 替換網絡的輸入層;
- 使用新的數據來訓練;
- 可以選擇fine-tune全部曾或部分層;
- 通常前面的層提取圖像的通用特征(generic?features);
- 通用特征對許多任務都有用;
- 后面的層提取與特定類別有關的特征;
- Fine-tuning常常只需要微調后面的層;
Inception
- Inception網絡是CNN發展史上的一個重要里程碑;
- Inception出現之前的CNN僅是堆疊卷積層,網絡越來越深;
- 以期得到更好的性能;
多層卷積網絡深度存在的問題
- 圖像中突出部分的大小差別很大;
- 由于信息位置的巨大差異,卷積操作選擇合適大小的卷積核比較困難;
- 信息分布更全局的圖像偏好較大的卷積核;
- 信息分布較局部的圖像偏好較小的卷積核;
- 非常深的網絡更容易過擬合;
- 將梯度更新傳到整個網絡是困難的;
- 簡單堆疊卷積層非常消耗計算資源;
Inception?module解決方案
- 鑒于多層卷積神經網絡具有的以上問題;
- 為什么不在同一層上運行多個尺寸的濾波器呢?
- 那么網絡本質上變得寬一些,而不是更深一些;
Inception模塊
- 使用三個不同尺寸的濾波器:1X1,3x3,5x5,以及最大池化;
- 對輸入執行卷積操作;
- 所有子層的輸出最后被級聯起來;
- 傳送至下一個模塊;
- 一方面增加了網絡的寬度;
- 另一方面增加了網絡的尺度適應性;

降維Inception模塊
- ?如前,深度神經網絡耗費大量資源;
- 為了降低算力成本,在3x3,5x5卷積層之前添加額外的1x1卷積層;
- 以此來限制輸入通道的數量;
- 盡管添加額外的卷積操作反直覺;
- 但是1x1的卷積較5x5的卷積廉價許多;
- 輸入通道數量的減少有利于降低計算成本;

1x1卷積降低運算成本比較
?
Inception V1?
- Googlenet出品
- 采用了Inception?模塊化結構;
- 共計9個模塊,22層;
- 避免梯度消失,增加2個輔助softmax;
- 用于前向傳導梯度;

Inception V2
- ?輸入增加了BatchNormalization;
- 用兩個連續的3x3卷積層(stride=1)組成的小網絡代替單個5x5卷積;
- 5x5卷積核參數是3x3卷積核參數的25/9=2.78倍;

- 此外,作者將?nxn的卷積核尺寸分解為1xn和nx1的兩個卷積;

- ?前面三個原則用來構建三種不同類型的Inception模塊;
| type | patch?size/stride | input? size |
| conv | 3x3/2 | 299x299x3 |
| conv | 3x3/1 | 149x149x32 |
| conv?padded | 3x3/1 | 147x147x32 |
| pool | 3x3/2 | 147x147x64 |
| conv | 3x3/1 | 73x73x64 |
| conv | 3x3/2 | 71x71x80 |
| conv | 3x3/1 | 35x35x192 |
| 3 X Inception |  | 35x35x288 |
| 5 X Inception |  | 17x17x768 |
| 2 x?Inception |  | 8x8x1280 |
| pool | 8x8 | 8x8x2048 |
| linear | logits | 1x1x2048 |
| softmax | classifier | 1x1x1000 |
Inception V3
- 整合了InceptionV2的所有升級,使用了7X7卷積
| type | patch?size/stride | input? size |
| conv | 3x3/2 | 299x299x3 |
| conv | 3x3/1 | 149x149x32 |
| conv | 3x3/1 | 147x147x32 |
| pool | 3x3/2 | 147x147x64 |
| conv | 3x3/1 | 73x73x64 |
| conv | 3x3/2 | 71x71x80 |
| conv | 3x3/1 | 35x35x192 |
| 3 X Inception | | 35x35x288 |
| 3 X Inception | | 17x17x768 |
| 3 x?Inception | | 8x8x1280 |
| pool | 8x8 | 8x8x2048 |
| linear | logits | 1x1x2048 |
| softmax | classifier | 1x1x1000 |
Inception V3?設計思想
- 分解成小卷積很有效;
- 可以降低參數量,減輕過擬合;
- 增加網絡非線性的表達能力;
- 卷積網絡從輸入到輸出;
- 應該讓圖片尺寸逐漸減小;
- 輸出通道數逐漸增加;
- 讓空間結構化,將空間信息轉化為高階抽象的特征信息;
- Inception?Module使用多個分支;
- 提取不同抽象程度的高階特征;
- 豐富網絡的表達能力;
Inception?V4

- 圖中1為基本的Inception?V2/V3模塊;
- 使用兩個3x3卷積代替5x5卷積;
- 并且使用average?pooling;
- 該模塊主要處理尺寸為35x35的feature?map;
- 圖2中模塊使用1xn和nx1卷積代替nxn卷積;
- 同樣使用average?pooling;
- 該模塊主要處理尺寸為17x17的feature?map;?
- 圖3將3x3卷積用1x3卷積和3x1卷積代替;
- Inception?V4中基本的Inception?module沿襲了Inception?V2/V3的結構;
- 不同的是結構看起來更為簡潔統一;
- 且使用更多的Inception?module,實驗效果更好;
?
?Inception模型優勢
- 采用1x1卷積核,性價比高;
- 很少的計算量可增加一層特征變換和非線性變換;
- 提出Batch?Normalization;
- 通過一定手段,將每層神經元的輸入分布拉到均值0方差1的正態分布;
- 使其落入激活函數的敏感區;
- 避免梯度消失,加快收斂;
- 引入Inception?module 4個分支結合的結構;
卷積神經網絡遷移學習
- 現在工程中最常用的是vgg\resnet\Inception這幾種結構;
- 設計者通常先直接套用原版模型;
- 對數據進行一次訓練;
- 選擇較好的模型進行微調與模型縮減;
- 工程上使用的模型必須高進度和高速度;
- 常用模型縮減的方法是減少卷積個數與減少resnet的模塊數;
卷積神經網絡遷移學習-Inception
- 據相關論文,保留訓練好的Inception模型所有卷積層的參數;
- 只替換最后一層全鏈接層;
- 最后全鏈接層之前的網絡稱為瓶頸層;
- 瓶頸層輸出的節點向量可作為任何圖像的一個具有表達能力的特征向量;
- 在新的數據集上,利用訓練好的網絡對圖像進行特征提取;
- 提取的特征向量作為輸入訓練一個全新的單層全連接神經網絡;
- 處理新的分類問題;
- 在數據量足夠的情況下;
- 遷移學習的效果不如完全重新訓練的效果;
- 遷移學習所需的訓練時間和樣本遠小于完整模型的訓練;
- Inception模型與Alexnet結構完全不同;
- Alexnet模型中,不同卷積層串聯連接;
- Inception模型中Inception結構并聯不同的卷積層;
Mobilenet
- google針對手機等嵌入式設備提出;
- 一種輕量級的深層神經網絡;
- 其核心思想為深度可分離卷積;
- depthwise?separable?convolution;
- 3x3卷積核厚度只有一層;
- 卷積核在輸入張量上一層層的滑動;
- 每一次卷積生成一個輸出通道;
- 卷積完成后,利用1x1的卷積調整厚度;

- 對于一個卷積點;
- 假設有一個3x3大小的卷積層;
- 其輸入通道為16,輸出通道為32;
- 32個3x3大小的卷積核會遍歷16個通道中的每個數據;
- 可得所需的32個輸出通道;
- 所需參數為16x32x3x3=4608個;
- 應用深度可分離卷積;
- 用16個3x3大小的卷積核遍歷16通道的數據;
- 得到16個特征圖譜;
- 接著用32個1x1大小的卷積核遍歷16個特征圖譜;
- 所需參數為16x3x3+16x32x1x1=656個;
- 可以看出,depression?separable?convolution?可減少模型的參數;


卷積神經網絡設計的問題背景
- 熟練掌握訓練神經網絡的能力并不容易;
- 與機器學習的思維一樣,細節決定成敗;
- 訓練神經網絡需要處理更多的技術細節;
- 應該了解數據和硬件;
- 知道從何種網絡開始;
- 了解需要建立多少卷積層;
- 熟悉激勵函數的設置;
- 學習速率是調整神經網絡訓練的最重要超參數;
- 也是最難優化的參數之一;
- 學習率太小,可能永遠不會得到一個解決方案;
- 學習率太大,可能會錯過最優解;
- 自適應的匹配學習率,可能需要花費代價在硬件資源上;
- 設計選擇和超參數的設置極大影響了CNN訓練和性能;
- 資源的稀缺和分散對深度學習的新進者,可能更有利于架構設計的直覺培養;
卷積神經網絡的設計技巧

1.架構遵循應用
- Google?Brain?或者Deep?Mind?實驗室有許多耀眼的新模型;
- 但其中很多是不可實現,或于你的需求不適用;
- 應該使用對特定的應用最有意義的模型;
- 這種模型或許非常簡單,但仍然強大,比如VGG;
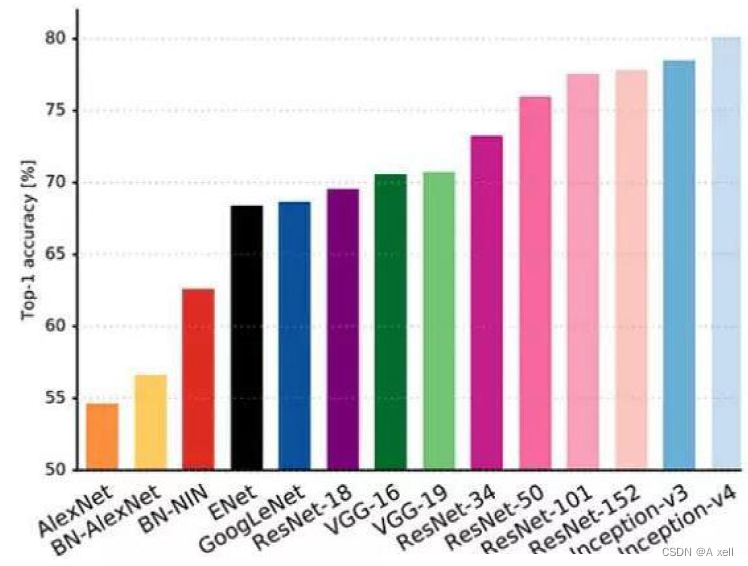
2.路徑激增
- 每年ImageNet?Challenge的冠軍都比上一年使用更加深層的網絡;
- 從AlexNet到Inception再到Resnets;
- 網絡路徑的數量有成倍增長的趨勢;
3.追求簡約
- 更大的不一定是更好的
4.增加對稱性
- 對稱性是質量和工藝的標志;
5.金字塔形狀
- 總是在表征能力和減少冗余或者無用信息之間權衡;
- CNNs通常會降低激活函數的采樣;
- 增加從輸入層到最終層之間的連接通道;
6.過度訓練
- 訓練準確度和泛化能力是衡量模型的另一個標準;
- 可使用drop-out或dro-path提升泛化能力;
- 這是神經網絡的重要優勢;
- 用比實際用例更難的問題訓練網絡,以提高泛化能力;
7.覆蓋問題的空間
- 為了擴大訓練數據和提升泛化能力;
- 使用噪聲和人工增加訓練集的大小;
- 比如隨機旋轉\裁剪和一些圖像增強操作;
8.遞增的功能結構
- 成功的結構會簡化每一層的工作;
- 在非常深的神經網絡中,每層會遞增的修改輸入;
- 在ResNet中,每一層的輸出可能類似于輸入;
- 在實踐中,請在ResNet中使用短的跳過長度;
9.標準化層的輸入
- 標準化是可以使計算層的工作變得更加容易的一條捷徑;
- 在實際中可以提升訓練的準確性;
- 標準化?把所有曾的輸入樣本放在了一個平等的基礎上;
- 允許反向傳播可以更有效的訓練;
10.使用微調過的預訓練網絡(fine?tuning)
- 如果你的視覺數據和ImageNet相似;
- 可用預訓練網絡使得模型學習的更快;
- 低水平的CNN通常可被重復使用;
- 他們大多能夠檢測線條和邊緣這些常見的模式;
- 比如用自己的層替換分類層,用特定的數據訓練最后幾層;
11.使用循環的學習率
- 學習率的實驗會消耗大量時間;
- 且中間會遇到錯誤;
- 自適應學習率在計算上可能是非常昂貴的;
- 循環學習率不會大量消耗計算資源;
- 使用循環學習率,可設置一組最大最小邊界;
- 并在最大最小范圍內改變;
















-使用InnoDB的全文索引)
)
:Transformer Memory as a Differentiable Search Index)
)