Deep Domain Adversarial Neural Network(深度領域對抗神經網絡,DDANN)
是一類結合 深度學習 與 領域自適應(domain adaptation) 思想的神經網絡結構,主要用于不同數據域之間的知識遷移,尤其是在源域(source domain)和目標域(target domain)數據分布存在差異時,依然能夠保持較好的特征表示和預測性能。
1. 背景
在很多實際場景中,我們有:
源域:有充足的標注數據(如實驗室樣本)
目標域:無標注或少量標注數據(如真實應用環境中的樣本)
由于 數據分布差異(domain shift),直接用源域訓練的模型在目標域上性能會大幅下降。
領域對抗網絡(Domain Adversarial Network) 就是通過對抗學習,讓模型學到的特征在不同域之間“不可區分”,從而實現領域無關的特征提取。
2. 核心思想
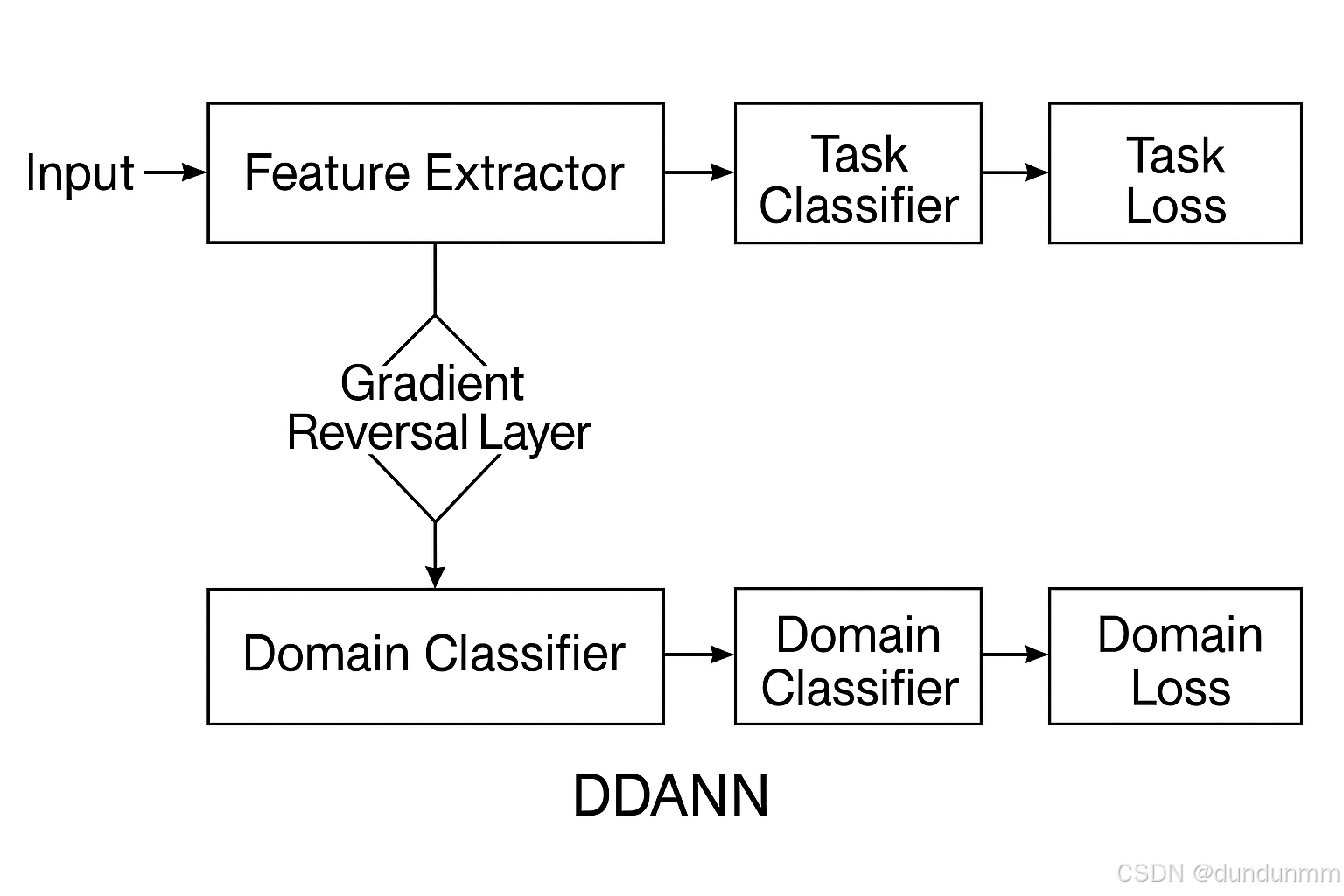
DDANN 在普通的深度神經網絡中引入一個 域分類器(domain classifier),并通過 梯度反轉層(Gradient Reversal Layer, GRL) 實現對抗訓練:
特征提取器(Feature Extractor)
深度神經網絡(CNN、MLP 等),從輸入數據中提取高層特征表示。
任務分類器(Task Classifier)
用源域標注數據進行監督訓練,完成目標任務(如分類、回歸、分解等)。
域分類器(Domain Classifier)
預測樣本來自哪個域(源域還是目標域)。
通過 GRL 實現特征提取器與域分類器的對抗訓練:
域分類器希望能分辨域的不同;
特征提取器希望生成的特征讓域分類器無法區分,即學習域不變特征。
3. 工作機制
DDANN 的訓練目標包含兩個部分:
任務損失 LtaskL_{task}:確保在源域任務上性能最優。
對抗域損失 LdomainL_{domain}:確保源域與目標域的特征分布盡可能接近。
整體優化目標為:

其中 λ控制任務性能與領域不變性的權衡。
4. 應用場景
跨域圖像分類(如不同相機拍攝的圖片)
跨批次生物數據分析(如蛋白質組、轉錄組中不同批次實驗數據)
語音識別(不同口音、不同錄音設備)
醫學影像(不同醫院、不同成像條件)

WLAN熱點名稱修改不生效問題分析)
vmware vmdk磁盤教程)
:布局的“原子”——RectTransform的核心數據模型與幾何學)
----設計模式(橋接模式與適配器模式))








是一種在操作系統中用于**進程間通信(IPC)** 的機制)
)
)



