文章目錄
- 一、預定義符號
- 二、#define定義常量:便捷的符號替換
- 常見用法示例:
- 注意事項:
- 三、#define定義宏:帶參數的文本替換
- 關鍵注意點:
- 四、帶有副作用的宏參數
- 五、宏替換的規則:預處理的執行步驟
- 重要注意:
- 六、宏與函數的對比:各有優劣
- 宏的獨特優勢:
- 七、#和##運算符:字符串化與記號粘合
- 7.1 #運算符:字符串化
- 7.2 ##運算符:記號粘合
- 八、命名約定:區分宏與函數
- 九、#undef:移除宏定義
- 十、命令行定義:編譯時動態配置
- 十一、條件編譯:選擇性編譯代碼
- 常見條件編譯指令:
- 應用示例:調試代碼控制
- 十二、頭文件的包含:正確引入外部代碼
- 12.1 包含方式及查找策略
- 12.2 避免頭文件重復包含
- 十三、其他預處理指令
C語言的預處理階段是代碼編譯前的重要環節,它負責處理以
#開頭的各種指令,為后續的編譯過程做好準備。預處理看似簡單,實則包含了豐富的功能和細節,掌握這些知識能讓我們寫出更高效、更靈活的代碼。
一、預定義符號
C語言為我們內置了一些預定義符號,它們在預處理期間就會被處理,我們可以直接在代碼中使用,無需額外定義。這些符號能為我們提供很多有用的信息:
__FILE__:進行編譯的源文件的文件名__LINE__:當前代碼在文件中的行號__DATE__:文件被編譯的日期(格式為“Mmm dd yyyy”)__TIME__:文件被編譯的時間(格式為“hh:mm:ss”)__STDC__:如果編譯器遵循ANSI C標準,其值為1;否則未定義
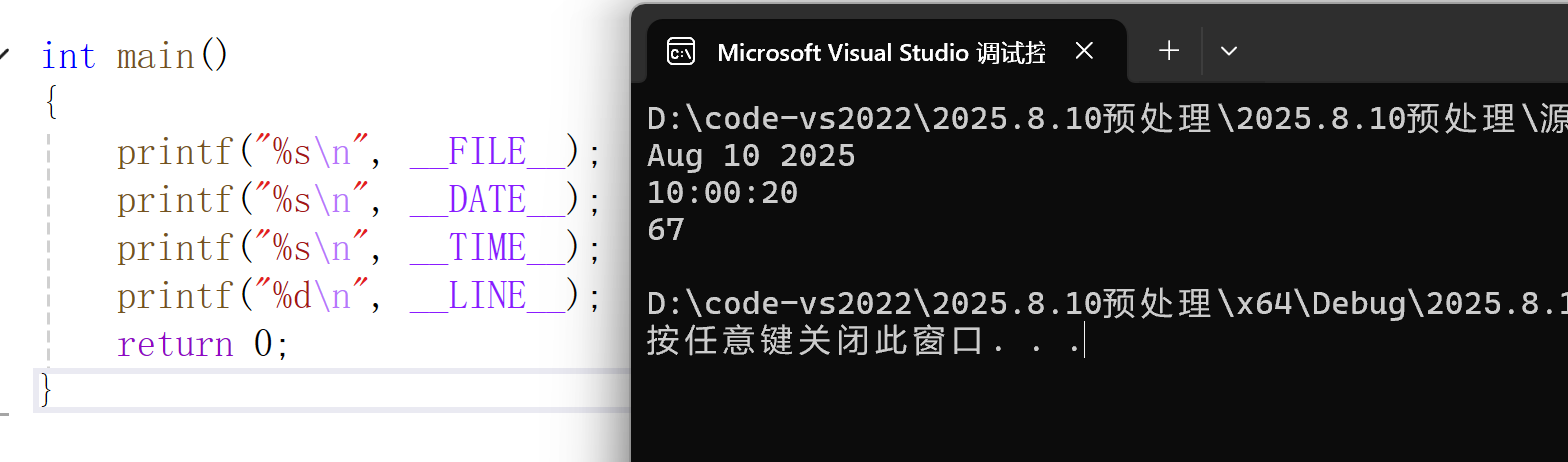
這些符號在調試代碼時非常有用,例如:
printf("Error in file: %s at line: %d\n", __FILE__, __LINE__);
當程序運行到這里時,會自動打印出錯誤所在的文件名和行號,幫助我們快速定位問題。
二、#define定義常量:便捷的符號替換
#define最基本的用法是定義常量,其基本語法為:
#define name stuff
常見用法示例:
- 定義數值常量:
#define MAX 1000 - 為關鍵字創建簡短別名:
#define reg register - 替換復雜實現為更形象的符號:
#define do_forever for(;;) - 簡化代碼編寫:
#define CASE break;case(在switch語句中自動添加break)
注意事項:
- 不要隨意添加分號:
例如#define MAX 1000;這樣的定義是不推薦的。當在
if(condition)max = MAX; else max = 0;
中使用時,替換后會變成
if(condition) max = 1000;;
else max = 0;
導致if和else之間出現兩條語句,引發語法錯誤。
- 長內容的分行處理:
如果定義的內容過長,可以分成多行書寫,除最后一行外,每行末尾都加上反斜杠(續行符)。反斜杠后面不能有任何內容
#define DEBUG_PRINT printf("file:%s\tline:%d\t \date:%s\ttime:%s\n", \__FILE__, __LINE__, \__DATE__, __TIME__)
三、#define定義宏:帶參數的文本替換
#define還允許我們定義帶參數的宏(macro),實現更靈活的文本替換。宏的聲明方式為:
#define name(parameter-list) stuff
其中parameter-list是由逗號分隔的參數列表,它們會出現在stuff中。
關鍵注意點:
-
參數列表與名稱緊連:參數列表的左括號必須與
name緊鄰,中間不能有空白,否則參數列表會被解釋為stuff的一部分。 -
運算符優先級問題:
例如#define SQUARE(x) x * x這個宏,當傳入SQUARE(a + 1)時,會被替換為a + 1 * a + 1,結果為a + a + 1而非預期的(a+1)^2。解決方法是給參數和整體加上括號:#define SQUARE(x) (x) * (x)。更復雜的情況:
#define DOUBLE(x) (x) + (x),當調用10 * DOUBLE(5)時,會被替換為10 * (5) + (5),結果為55而非100。正確的定義應為#define DOUBLE(x) ((x) + (x))。結論:用于數值表達式求值的宏,應給參數和整體都加上括號,避免運算符優先級導致的意外結果。
四、帶有副作用的宏參數
當宏參數在宏定義中出現多次,且參數帶有副作用時,可能會產生不可預測的結果。副作用指表達式求值時產生的永久性效果(如x++會改變x的值,而x+1則不會)。
例如:
#define MAX(a, b) ((a) > (b) ? (a) : (b))int x = 5, y = 8, z;
z = MAX(x++, y++);
預處理后會變成:
z = ((x++) > (y++) ? (x++) : (y++));
執行后,x的值變為6,y變為10,z變為9,與直觀預期可能不符。這就是副作用參數帶來的問題。
五、宏替換的規則:預處理的執行步驟
在擴展#define定義的符號和宏時,預處理器遵循以下步驟:
- 調用宏時,首先檢查參數是否包含
#define定義的符號,若有則先替換。 - 將替換文本插入到原位置,宏的參數名被其值替換。
- 再次掃描結果文件,若包含
#define定義的符號,重復上述過程。
重要注意:
- 宏參數中可以包含其他
#define定義的符號,但宏不能遞歸。 - 預處理器不會搜索字符串常量的內容(即字符串中的符號不會被替換)。
六、宏與函數的對比:各有優劣
宏和函數都能實現代碼復用,但它們在多個方面存在差異:
| 屬性 | #define定義宏 | 函數 |
|---|---|---|
| 代碼長度 | 每次使用都會插入代碼,可能大幅增加程序長度(除非宏很短) | 代碼只出現一次,每次調用都使用同一份代碼 |
| 執行速度 | 更快(無函數調用和返回開銷) | 較慢(存在函數調用和返回的額外開銷) |
| 操作符優先級 | 可能受周圍表達式優先級影響,需謹慎使用括號 | 參數只在傳參時求值,結果傳遞給函數,表達式求值可預測 |
| 副作用參數 | 參數若多次出現,副作用可能導致不可預料的結果 | 參數只在傳參時求值一次,副作用易控制 |
| 參數類型 | 與類型無關,只要操作合法即可用于任何類型 | 與類型相關,不同類型可能需要不同函數(即使功能相同) |
| 調試 | 不方便調試(預處理階段已替換) | 可逐語句調試 |
| 遞歸 | 不能遞歸 | 可以遞歸 |
宏的獨特優勢:
宏可以接受類型作為參數,而函數無法做到。例如:
#define MALLOC(num, type) (type *)malloc(num * sizeof(type))// 使用
int *p = MALLOC(10, int);
// 替換后:(int *)malloc(10 * sizeof(int));
七、#和##運算符:字符串化與記號粘合
7.1 #運算符:字符串化
#運算符能將宏的參數轉換為字符串字面量,僅用于帶參數的宏的替換列表中。
例如:
#define PRINT(n) printf("the value of "#n " is %d", n);// 調用
int a = 10;
PRINT(a); // 替換后:printf("the value of ""a"" is %d", a);
輸出結果為:the value of a is 10
7.2 ##運算符:記號粘合
##可以將兩邊的符號合并為一個符號,允許從分離的文本片段創建標識符(稱為“記號粘合”)。
為不同類型定義求最大值的函數:
#define GENERIC_MAX(type)\
type type##_max(type a,type b)\
{\return a > b ? a : b;\
}GENERIC_MAX(int);//int_max()
GENERIC_MAX(float);//float_max()int main()
{int r1 = int_max(3, 9);float r2 = float_max(4.6, 8.9);printf("%d %f", r1, r2);return 0;
}
八、命名約定:區分宏與函數
宏和函數的使用語法相似,為了區分二者,通常遵循以下約定:
- 宏名全部大寫(如
MAX、SQUARE) - 函數名不要全部大寫(如
int_max、add)
九、#undef:移除宏定義
#undef指令用于移除已有的宏定義,語法為:
#undef NAME
如果需要重新定義一個已存在的宏,應先使用#undef移除其舊定義。
十、命令行定義:編譯時動態配置
許多C編譯器允許在命令行中定義符號,用于啟動編譯過程。這在根據同一源文件編譯程序的不同版本時非常有用。
根據內存大小動態調整數組長度:
// 源文件program.c
#include <stdio.h>
int main() {int array[ARRAY_SIZE];for (int i = 0; i < ARRAY_SIZE; i++) {array[i] = i;printf("%d ", array[i]);}return 0;
}
編譯時在命令行定義ARRAY_SIZE:
# Linux環境
gcc -D ARRAY_SIZE=10 program.c # 定義數組長度為10
十一、條件編譯:選擇性編譯代碼
條件編譯指令允許我們選擇性地編譯或放棄某些語句,常用于調試代碼的開關控制。
常見條件編譯指令:
- 基本形式:
#if 常量表達式// 代碼段#endif
預處理器會求值常量表達式,為真則編譯代碼段。
- 多分支形式:
#if 常量表達式// 代碼段1#elif 常量表達式// 代碼段2#else// 代碼段3#endif
- 判斷符號是否定義:只判斷是否被定義,不判斷真假
#if defined(symbol) // 等價于 #ifdef symbol// 代碼段#endif#if !defined(symbol) // 等價于 #ifndef symbol// 代碼段#endif
- 嵌套指令:
#if defined(OS_UNIX)#ifdef OPTION1unix_version_option1();#endif#elif defined(OS_MSDOS)#ifdef OPTION2msdos_version_option2();#endif#endif
應用示例:調試代碼控制
#define __DEBUG__ 1 // 定義調試符號int main() {int arr[10] = {0};for (int i = 0; i < 10; i++) {arr[i] = i;#ifdef __DEBUG__printf("arr[%d] = %d\n", i, arr[i]); // 僅調試時編譯#endif}return 0;
}
十二、頭文件的包含:正確引入外部代碼
頭文件包含是預處理階段的重要操作,用于將其他文件的內容插入到當前文件中。
12.1 包含方式及查找策略
-
本地文件包含:
#include "filename"
查找策略:先在源文件所在目錄查找,若未找到,再到標準庫目錄查找。 -
庫文件包含:
#include <filename.h>
查找策略:直接到標準庫目錄查找,效率更高。
注意:庫文件也可以用""包含,但會降低查找效率,且不易區分是本地文件還是庫文件。
12.2 避免頭文件重復包含
頭文件被多次包含會導致代碼冗余、編譯時間增加,甚至出現重復定義錯誤。解決方法是使用條件編譯:
- 方式一:
ifndef/define/endif
// test.h#ifndef __TEST_H__ // 如果未定義__TEST_H__#define __TEST_H__ // 定義__TEST_H__// 頭文件內容(函數聲明、結構體定義等)void test();struct Stu { int id; char name[20]; };#endif // __TEST_H__
- 方式二:
#pragma once
更簡潔的方式,直接在頭文件開頭添加:
#pragma once // 確保頭文件只被包含一次// 頭文件內容
十三、其他預處理指令
除了上述內容,C語言還有一些其他預處理指令,如:
#error:在編譯時輸出錯誤信息,終止編譯#pragma:用于向編譯器提供額外信息(如#pragma pack()控制結構體對齊)#line:修改當前行號和文件名
預處理是C語言編譯過程中的第一個環節,它通過#define、#include、條件編譯等指令,為代碼的編譯做好準備。掌握預處理的各種特性,不僅能幫助我們寫出更高效、更靈活的代碼,還能讓我們在調試和維護程序時更得心應手。
WLAN熱點名稱修改不生效問題分析)
vmware vmdk磁盤教程)
:布局的“原子”——RectTransform的核心數據模型與幾何學)
----設計模式(橋接模式與適配器模式))








是一種在操作系統中用于**進程間通信(IPC)** 的機制)
)
)




