Transformer Memory as a Differentiable Search Index
- 摘要
- 1. 引言
- 2. 相關工作
- 3. 可微搜索索引
- 3.1 索引策略
- 3.1.1 索引方法
- 3.1.2 文檔表示策略
- 3.2 用于檢索的 Docids 表示
- 3.3 訓練和優化
- 4. 實驗
- 4.1 基線
- 4.2 實驗結果
- 5. 結論
- 參考資料
原文鏈接:https://proceedings.neurips.cc/paper_files/paper/2022/file/892840a6123b5ec99ebaab8be1530fba-Paper-Conference.pdf
(2022)
摘要
在本文中,我們證明可以使用單個 Transformer 來完成信息檢索,其中有關語料庫的所有信息都編碼在模型的參數中。為此,我們引入了可微搜索索引(DSI),這是一種新的范例,它學習文本到文本的模型,將字符串查詢直接映射到相關的文檔 id;換句話說,DSI 模型僅使用其參數直接回答查詢,從而極大地簡化了整個檢索過程。我們研究文檔及其標識符的表示方式的變化、訓練程序的變化以及模型和語料庫大小之間的相互作用。實驗表明,如果選擇適當的設計,DSI 的性能顯著優于雙編碼器模型等強基線。此外,DSI 展示了強大的泛化能力,在零樣本設置中優于 BM25 基線。
1. 引言
信息檢索 (IR) 系統將用戶查詢 q ∈ Q 映射到相關文檔的排序列表 {d1,… , dn} ? D,通常由稱為文檔標識符 (docids) 的整數或短字符串表示。最廣泛使用的 IR 方法基于流水線 “ 檢索然后排序 ” 策略。對于檢索,基于倒排索引或最近鄰搜索的方法很常見,其中基于對比學習的雙編碼器(DE)(Gillick 等人,2018;Karpukhin 等人,2020;Ni 等人,2021)是當前的soat。
本文提出了一種替代架構,其中使用序列到序列(seq2seq)學習系統(Sutskever 等人,2014)將查詢 q 直接映射到相關的 docid j ∈ Y。該建議顯示在下半部分圖 1 的序列到序列編碼器-解碼器架構。
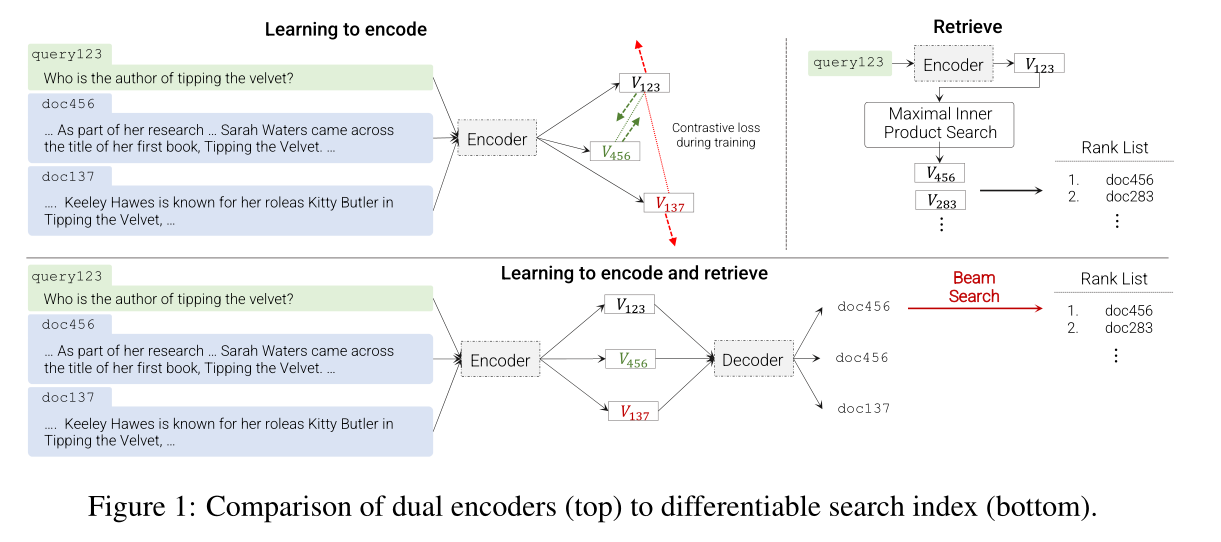
我們將這種提出的架構稱為可微搜索索引(DSI),并使用大型預訓練 Transformer(V aswani 等人,2017)模型來實現它,該模型建立在大型生成語言模型(LM)(Brown 等人)最近成功的基礎上,2020;Raffel 等,2019;Devlin 等,2018;Thoppilan 等,2022;Du 等,2021)。在這個提出的架構中,語料庫的所有信息都被編碼在 Transformer 語言模型的參數內。
在推理時,訓練后的模型將文本查詢 q 作為輸入并輸出 docid j。如果需要,可以使用集束搜索來生成潛在相關 docid 的排名列表。正如我們所展示的,如果訓練得當,這個過程可以出奇地順利。在我們的實驗中,它可以始終優于 DE 基線,有時甚至遠遠超過:對于 base 大小的 T5 模型,最小語料庫上的 Hits@1 提高了 20 多個點,從 DE 的 12.4% 提高到 DSI 的 33.9%;在 30 倍大的語料庫上,性能提高了近 7 個百分點。當使用更大的模型時,這些增益會增加:對于 11B 參數的 T5 模型,Hits@1 性能在小語料庫上比 DE 提高了 25 點以上,在大語料庫上提高了 15 點以上。 DSI 在零樣本設置中也表現得非常好,例如,Hits@1 比 BM25 提高了 14 點。
除了這些定量收益之外,DSI 架構比 DE 簡單得多(參見表 1)。DE 系統固定搜索過程 (MIPS,Maximal Inner Product Search) 并學習內部表示來優化該搜索過程的性能;相反,DSI 系統不包含特殊用途的固定搜索過程,而是使用標準模型推理從編碼映射到 docids。
正如表 1 所示,機器學習社區特別感興趣的是,在 DSI 中,檢索的所有方面都被映射到易于理解的 ML 任務中。這可能會帶來新的潛在方法來解決長期存在的IR問題。舉一個例子,由于索引現在是模型訓練的一種特殊情況,因此增量更新索引成為模型更新的一種特殊情況(Sun 等人,2020)。
(通過訓練模型來建立索引)
在本文中,DSI 應用于中等規模的語料庫(從 10k 到 320k 文檔),所有這些都源自一項具有挑戰性的檢索任務,我們將 DSI 擴展到更大語料庫的重要問題留給未來的工作。考慮的任務是從自然問題(NQ)數據集中檢索給定問題的支持段落,這對于詞匯模型來說是一項具有挑戰性的任務。
雖然 DSI 的想法很簡單,但實現它的方法有很多種,其中一些方法效果出奇的好,而另一些方法的效果卻出奇的差。下面我們探討 DSI 架構的多種變體。

文檔表示
我們探索了幾種表示文檔的方法,包括使用文檔全文的“簡單”方法,以及傳統 IR 引擎使用的詞袋表示的變體。
Docid 表示
我們研究了幾種表示 docids 的方法。除了將整數簡單地表示為文本字符串之外,我們還考慮非結構化原子文檔ID,其中每個文檔都被分配一個唯一的標記,以及一些用于構建結構化語義文檔ID的簡單基線,這些文檔描述如何通過語料庫的層次聚類導航到文檔。結構化文檔ID(通過聚類進行語義結構化,或者簡單地結構化為標記化整數)可以更好地擴展到大型語料庫,因為解碼器中使用的詞匯量更大。
索引
可訓練的 IR 系統傳統上有兩個階段:對語料庫建立索引(即記住每個文檔的信息),以及學習如何有效地從索引中檢索。在DSI中,索引存儲在模型參數中,索引只是另一種模型訓練。圖 1 提出了一種對語料庫進行索引的方法:即,訓練 (1) 示例 (dj, j),將文檔 dj 與其 docid j 配對, (2) 示例 (q, j) 將查詢 q 與相關 docid j 配對。在此設置中,類型 (1) 的示例是“索引”示例。
雖然很明顯,類型(2)的示例本身并不能為系統提供足夠的信息來推廣到新穎的檢索,但類型(1)的示例有許多替代方案,可以合理地“teach”模型文檔和docid之間的關系。我們在下面探討了其中的一些,并表明一些看似合理的技術表現非常差。我們還探索了許多替代的多任務優化和課程學習方案來結合這些類型的示例。
1)如何表示文檔;2)如何表示文檔id
a)如何建立文檔與文檔id的聯系;b)如何建立query與文檔id的聯系
模型和語料庫大小的影響
由于最近的結果表明,大型 LM 的某些屬性僅在非常大的模型大小下出現(Brown 等人(2020)),因此我們探索了 DSI 對于一系列模型大小和 10k、100k 和 320k 文檔的語料庫大小的性能。
總結
我們證明,即使是簡單的文檔和 docids 表示,再加上適當的訓練程序來微調現代大型 LM,也能表現得令人驚訝地好;我們提出了兩種改進的 docid 表示,即非結構化 docids 和語義結構化 docid,它們改進了樸素表示選擇。我們表明,索引/訓練策略之間的性能存在很大差異,并且 DSI 的性能隨著模型規模的擴大而顯著且持續地提高。據我們所知,這是生成索引在經過充分研究的文檔檢索任務的強基線上提高性能的第一個案例。
1)docid 的兩種表示方式
2)index / train 的策略對于性能有很大影響
3)DSI 性能跟模型規模相關
2. 相關工作
De Cao 等人 (2020) 描述了一種稱為自回歸實體鏈接的相關序列到序列系統,其中提及實體的文檔(可能是隱式的,例如通過提出該實體作為答案的問題)被映射到規范該實體的名稱。就維基百科而言,規范實體名稱對應于頁面標題,因此這可以被視為一種文檔檢索。這種方法已適應其他目的,例如以規范形式生成知識庫三元組(Josifoski 等人,2021)。我們考慮的任務與自回歸實體鏈接中考慮的任務不同:我們的目標是檢索包含答案的文檔,而不是標題是答案的文檔。更重要的是,在自回歸實體中,鏈接生成目標是一個語義上有意義的名稱,而我們允許目標是任意的 docids。這使得我們的方法適用于一般檢索任務,但提出了有關文檔id表示和索引策略的新問題。
在自回歸實體鏈接中,生成被限制為從固定集合返回輸出。將 DSI 生成輸出限制為有效的 docids 是可行的。盡管我們不使用這種技術,但它能在多大程度上提高性能是一個值得思考的問題。
不使用限制生成
在檢索增強生成方面有大量工作,即檢索輔助文檔以增強語言模型(Borgeaud 等人,2021;Guu 等人,2020)。這些技術對于包括問答在內的許多任務都很有用,但依賴于傳統的檢索方法,例如 DE。在這里,我們使用生成來代替檢索過程,而不是使用檢索來增強生成過程。
雙編碼器(Dehghani 等人,2017;Gillick 等人,2018;Gao 等人,2021;Ni 等人,2021;Karpukhin 等人,2020)是一種成熟的檢索范例。關鍵思想是獨立生成查詢和文檔嵌入,并在向量空間中跨所有嵌入對執行相似性檢索。查詢和候選文檔由序列編碼器生成,并使用對比損失的形式進行訓練。
之前的工作已經研究過將大型 Transformer 模型解釋為內存存儲。 (Roberts 等人,2020)在閉卷 QA 任務上取得了成功,他們訓練 T5 模型以檢索在預訓練期間在模型參數中編碼的事實。然而,與 CBQA 不同的是,本文提出的問題是基于 docids 檢索完整文檔,而不是生成直接答案。同時,(Petroni et al, 2019)還研究了作為知識庫的語言模型,發現預訓練的語言模型可能已經包含關系知識。 (Geva 等人,2020)分析了 Transformer 前饋層中編碼的知識。還有一些作品證明了 Transformers 與聯想記憶和 Hopfield 網絡的關系(Ramsauer 等人,2020),這強化了 Transformers 應該直觀地充當良好的聯想記憶存儲或搜索索引的概念。
3. 可微搜索索引
所提出的可微搜索索引(DSI)背后的核心思想是在單個神經模型中完全參數化傳統的多階段檢索然后排名管道。為此,DSI 模型必須支持兩種基本操作模式:
索引
DSI 模型應該學會將每個文檔 dj 的內容與其相應的 docid j 相關聯。本文采用簡單的序列到序列(seq2seq)方法,將文檔標記作為輸入并生成標識符作為輸出。
檢索
給定輸入查詢,DSI 模型應返回候選 docid 的排序列表。在這里,這是通過自回歸生成來實現的。
在這兩個操作之后,可以訓練 DSI 模型來索引文檔語料庫,并可選擇對可用的標記數據集(查詢和標記文檔)進行微調,然后用于檢索相關文檔 - 所有這些都在一個統一的框架內進行。檢索然后排序方法相反,這種類型的模型允許簡單的端到端訓練,并且可以輕松用作更大、更復雜的神經模型的可微分子組件。
可微分的意思是說:搜索索引的結構和算法能夠被嵌入到神經網絡中,并且能夠通過梯度下降等優化算法進行端到端的訓練。
3.1 索引策略
我們研究了各種旨在了解文檔及其標識符之間關聯的索引策略。我們訓練模型來根據給定的文檔標記序列來預測 docids。這使得我們的模型能夠了解哪個標識符屬于哪個文檔,并且可以被視為傳統搜索索引的可微分形式。我們考慮各種替代方案,并在后續部分中取消這些設置。最終采用的策略是帶有直接索引的Inputs2Targets。
索引策略:直接索引(doc前 k 個token)+ Inputs2Targets(doc--》docid)
3.1.1 索引方法
本節討論我們考慮的索引任務變體。
Inputs2Target
我們將其構建為 doc_tokens → docid 的 seq2seq 任務。顧名思義,這以一種簡單的目標輸入方式將 docids 綁定到文檔標記。這里的優點是標識符是去噪目標,這使其更接近損失函數。由于檢索任務還涉及預測標識符,因此該公式允許網絡在序列長度方面遵循類似的輸入目標平衡。一個潛在的弱點是文檔標記不是去噪目標,因此沒有機會對文檔標記進行一般預訓練。
Targets2Input
該公式考慮了與上述相反的情況,即從標識符生成文檔標記,即 docid → doc_tokens。直觀上,這相當于訓練一個以 docid 為條件的自回歸語言模型。
Bidirectional
此公式在同一協同訓練設置中訓練 Inputs2Targets 和 Targets2Inputs。前置前綴標記是為了讓模型知道任務正在執行的方向。
Span Corruption
我們還探索了一種執行基于跨度損壞的去噪的設置(Raffel 等人,2019),其中包含 docid 令牌。在這種方法中,我們將標識符連接到文檔標記作為前綴,可以在跨度損壞目標中隨機屏蔽為跨度。該方法的優點是(1)在索引期間也執行一般預訓練,(2)實現 docids 作為去噪目標和輸入的良好平衡。將 docid 作為屏蔽 span。
3.1.2 文檔表示策略
在上一節中,我們探討了“如何索引”。本節研究“索引什么?”,即如何最好地表示 doc_tokens。我們在這里陳述我們的選擇,并在稍后的實驗中仔細消除它們。最終最好的選擇是直接索引方法。
Direct Indexing
該策略準確地代表了一個文檔。我們獲取文檔的前 L 個標記,并保留順序,并將它們與 docid 相關聯。
Set Indexing
文檔可能包含重復的術語和/或非信息性單詞(例如,停用詞)。此策略使用默認的 Python set(集合)操作來刪除重復的術語,并從文檔中刪除停用詞。過濾后文檔的其余部分以與直接索引類似的方式傳遞到模型中。
Inverted Index
該策略將分塊文檔(連續的標記塊)而不是整個文檔直接映射到 docid。我們對 k 個標記的單個連續塊進行隨機下采樣,并將它們與 docid 相關聯。這種方法的主要優點是允許查看前 k 個標記之外的內容。
3.2 用于檢索的 Docids 表示
基于 seq2seq 的 DSI 模型中的檢索是通過解碼給定輸入查詢的 docids 來完成的。如何有效地進行解碼很大程度上取決于 docids 在模型中的表示方式。本節的其余部分探討了表示 docids 的多種可能方法以及如何處理每種方法的解碼。
非結構化原子標識符
表示文檔的最簡單的方法是為每個文檔分配一個任意(并且可能是隨機的)唯一整數標識符。我們將它們稱為非結構化原子標識符。有了這些標識符,一個明顯的解碼公式是學習標識符的概率分布。在這種情況下,模型經過訓練,為每個唯一的 docid (|Ndocuments|) 發出一個 logit。這類似于標準語言模型中的輸出層,但擴展為包括 docids。為了適應這一點,我們擴展了標準語言模型的輸出詞匯,如下所示:
![]()
在哪里 [; ] 是逐行串聯運算符,Wtokens ∈ Rdmodel×|Ntokens|且 Wdocs ∈ Rdmodel×|Ndocuments|。 hlast 是解碼器堆棧的最后一層的隱藏狀態(ε Rdmodel)。要檢索給定查詢的前 k 個文檔,我們只需對輸出 logits 進行排序并返回相應的索引。這也讓人想起標準的列表學習,其中所有文檔都被同時考慮進行排名。
簡單結構化的字符串標識符
我們還考慮了一種表面上荒謬的方法,它將非結構化標識符(即任意唯一整數)視為可標記的字符串。我們將這些稱為簡單的結構化標識符。在此公式中,檢索是通過一次一個標記順序解碼 docid 字符串來完成的。這消除了對非結構化原子標識符附帶的大型 softmax 輸出空間的需要。它還消除了學習每個單獨的 docid 嵌入的需要。解碼時,使用波束搜索來獲得預測的最佳docid。通過這種策略,獲得 top-k 排名就不那么簡單了。人們可以詳盡地梳理整個 docid 空間并獲得給定查詢的每個 docid 的可能性。相反,我們使用部分波束搜索樹來構建 top-k 檢索分數。我們發現這種近似在實踐中非常有效。
語義結構標識符
迄今為止,用于表示 docids 的所有方法都假設標識符是以任意方式分配的。雖然探索任意標識符的限制非常有趣,但直觀的是,將語義結構注入文檔空間可以帶來更好的索引和檢索功能。因此,本節探討語義結構化標識符。
具體來說,我們的目標是自動創建滿足以下屬性的標識符:(1) docid 應捕獲有關其關聯文檔語義的一些信息,(2) docid 的結構應能夠有效減少搜索空間每個解碼步驟。這會產生語義相似的文檔共享標識符前綴的標識符。
在這項工作中,我們將其視為完全無監督的預處理步驟。然而,作為未來工作的一部分,有可能以完全端到端的方式集成并自動學習語義標識符。
為了構造具有此屬性的標識符,我們在文檔嵌入上采用簡單的層次聚類過程來生成十進制樹(或更一般地說,trie樹)。
給定一個要索引的語料庫,所有文檔都分為 10 個簇。每個文檔都分配有一個標識符,其簇號為 0-9。對于包含超過 c 個文檔的每個簇,遞歸應用該算法,并將下一級的結果(標識符的剩余后綴)附加到現有標識符。
對于具有 c 個或更少文檔的簇,每個元素都被分配一個從 0 到最多 c-1 的任意數字,同樣,它的數字會附加到現有標識符后。雖然這個特定過程會產生十進制樹,但可以使用任意數量的其他合理策略來產生類似類型的嘗試。在實踐中,我們簡單地將 k 均值應用于小型 8 層 BERT 模型生成的嵌入,其中 c = 100. 我們在算法 1 中包含此過程的偽代碼。

3.3 訓練和優化
我們訓練的 DSI 模型針對 seq2seq 交叉熵損失進行了優化,并使用教師強制進行訓練。我們探索了訓練 DSI 模型的兩種主要策略。
1)第一個也是更直接的策略是首先訓練模型來執行索引(記憶),然后是微調階段,其中訓練的模型用于將查詢映射到 docids(例如檢索)。
2)第二個策略是在多任務設置中一起訓練他們。為此,我們以與 T5 式協同訓練類似的方式構建協同訓練任務(例如,使用任務提示來區分它們)。后者的表現明顯更好,特別是當索引與檢索任務示例的比例很高時。因此,我們采用多任務學習作為默認策略。
聯合訓練是類似于 T5 任務提示的方式,本工作使用聯合訓練 / 多任務學習方式
在這里,我們觀察到我們的設置是獨特的,與傳統的多任務學習或遷移學習不同。在典型的多任務設置中,兩個任務具有共同點,如果一起學習,可以提高這兩個任務的性能。然而,在我們的設置中,檢索任務完全依賴于索引任務。特別是,如果沒有索引任務,檢索任務所利用的標識符將完全沒有意義。因此,為了解決任務 B(檢索),模型需要足夠好地學習任務 A(索引)。這個問題設置提出了 ML 社區可能感興趣的獨特且很大程度上尚未探索的研究挑戰。
4. 實驗
在本節中,我們討論我們的實驗設置、使用的數據集和比較的基線。我們還討論了本文前面部分討論的實驗結果、發現和各種策略的效果。由于這是一個相當新的概念,因此這項工作旨在提出 “ 概念驗證 ” 并尋求回答研究問題,而不是進行“sotaesque”比較。我們將其他設置和基線的廣泛比較留給未來的工作。
重點在驗證概念,而不是比較方法
數據集
我們在具有挑戰性的自然問題(NQ)(Kwiatkowski 等人,2019)數據集上進行了實驗。 NQ 由 307K 個查詢-文檔訓練對和 8K 驗證對組成,其中查詢是自然語言問題,文檔是維基百科文章。給定一個問題,檢索任務是識別回答該問題的維基百科文章。為了評估 DSI 模型在不同規模下的表現,我們從 NQ 構建了三個集合來形成我們的測試床,即 NQ10K、NQ100K 和 NQ320K,表示組合訓練和驗證分割中不同數量的總查詢文檔對。 NQ320K 是完整的 NQ 集,并使用其預定的訓練和驗證分割來進行評估。與 NQ320K 不同,NQ10K 和 NQ100K 構建隨機采樣的驗證集。對于所有數據集,我們對所有非結構化原子和樸素結構化標識符實驗使用相同的 320K 令牌的文檔空間/預算。為每個數據集單獨生成語義結構化標識符,以防止語義信息從較大的分割泄漏到較小的分割中。文本為小寫。請注意,這些數據集中存在的唯一文檔少于查詢文檔對。請參閱表4(附錄),其中報告了這些數據集的統計數據。
評價
我們在 Hits@N 上評估我們的模型,其中 N={1, 10}。該指標報告排名前 N 個預測的正確文檔的比例。
實現細節
所有 DSI 模型均使用標準預訓練 T5(Raffel 等人,2019)模型配置進行初始化。配置名稱和相應的模型參數數量為:Base (0.2B)、Large (0.8B)、XL (3B) 和 XXL (11B)。1)對于非結構化原子標識符運行,我們將標識符隨機初始化為新參數,并且僅在索引階段微調權重。我們使用 Jax/T5X 2 實現進行實驗。 DSI 模型使用 128 的批量大小進行最多 1M 步驟的訓練。我們根據檢索驗證性能選擇最佳檢查點。我們的訓練硬件由 128-256 個 TPUv4 芯片(用于 1B 參數以上的模型)和 64-128 個 TPUv3 或 TPUv4 芯片組成。據估計,NQ320K 參數高于 1B 的模型通常至少需要一整天的時間才能收斂。我們在 {0.001, 0.0005} 之間調整學習率,并在 {10K, 100K, 200K, 300K} 和/或無之間調整線性預熱。
2)語義結構化標識符是使用 8 層 BERT(Devlin 等人,2018)模型和 scikit-learn 中默認的 k-means 聚類生成的。基于我們對各種 DSI 設置的早期消融實驗,給出的主要結果使用直接索引 (L = 32) 和 Inputs2Targets 索引策略。我們展示了所有文檔id表示方法的結果。在主要結果之后,我們介紹了我們的消融研究。
4.1 基線
對于基線,我們使用 (Ni et al, 2021) 實現的基于 T5 的雙編碼器。我們使用 gensim4包來計算 BM25 分數。
1)對于基于 T5 的雙編碼器,我們對 NQ 對進行對比學習進行訓練,直到收斂(約 10K 步),并使用類似于 ScaNN 的系統獲得前 k 個最近鄰(Guo 等人,2020)。
2)對于零樣本檢索,我們還與最先進的無監督基線 Sentence T5(Ni 等人,2021)進行比較,該基線經過相似性學習任務的專門預訓練。我們考慮(Ni et al, 2021)這項工作的相關雙編碼器基線而不是其他密集檢索工作(例如 DPR)(Karpukhin et al, 2020)有兩個原因。首先,我們采用完全相同的預訓練模型,它允許系統地消除所提出的方法,而不會合并其他因素。從科學角度來說,我們相信與微調 T5 的比較是我們提供的最佳同類比較。其次,微調 T5 雙編碼器被認為在架構和方法上與 DPR 非常相似(有一些細微的差別,例如參數共享,但使用相同的批內負片概念)。
4.2 實驗結果
表 2 報告了經過微調的 NQ10K、NQ100K 和 NQ320K 的檢索結果,表 3 報告了零樣本檢索結果。對于零樣本檢索,模型僅針對索引任務而不是檢索任務進行訓練,因此模型看不到帶標簽的 query → docid 數據。附錄第 7.2 節報告了有關 DSI 索引性能和訓練動態的擴展結果。
監督微調結果
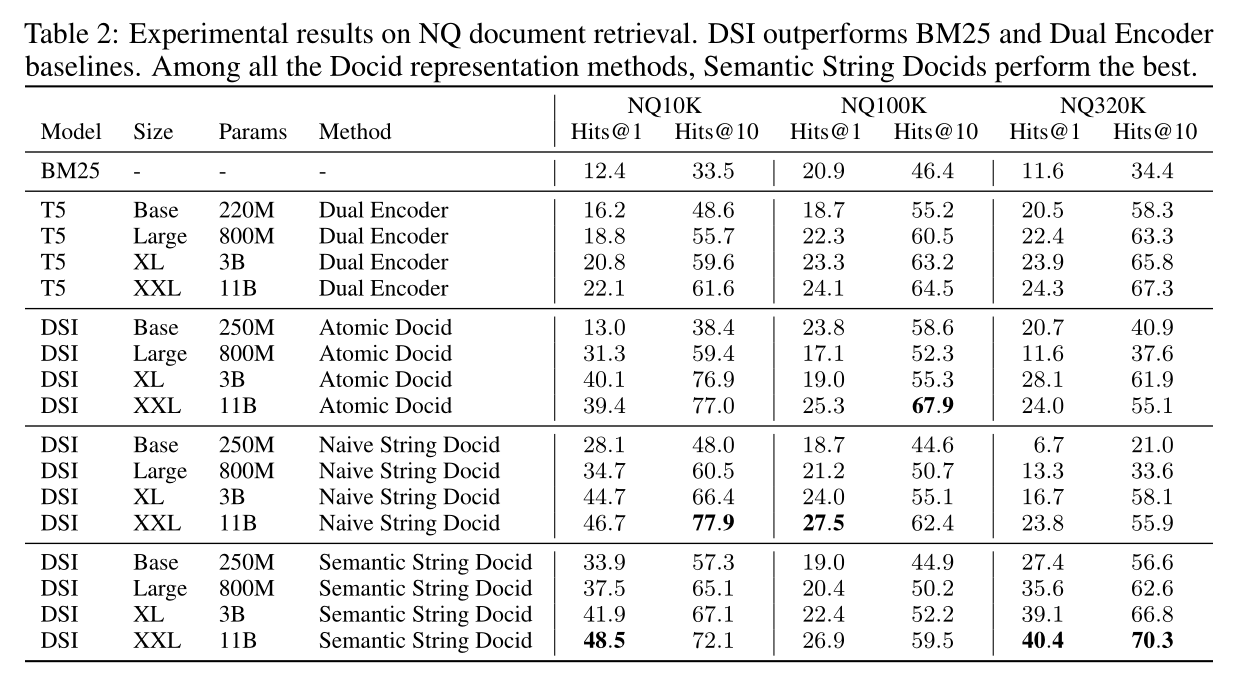
我們的結果表明,DSI 在所有數據集大小上都優于 DE。在小數據集(NQ10K)上,DSI 和 DE 之間的性能差距很大,例如,最好的 DSI 變體比 DE 性能好 2 倍。在 NQ100K 上,差距變得不那么明顯,最佳 DSI 模型(非結構化原子標識符)的 Hits@1 和 Hits@10 的表現優于 DE +5%。在大型數據集 (NQ320K) 上,最佳 DSI 模型(結構化語義標識符)比最佳 DE 模型的性能高出 +66% 相對 Hits@1 和 +4.5% Hits@10。
zero-shot 結果
零樣本是只訓練索引,不訓練檢索。
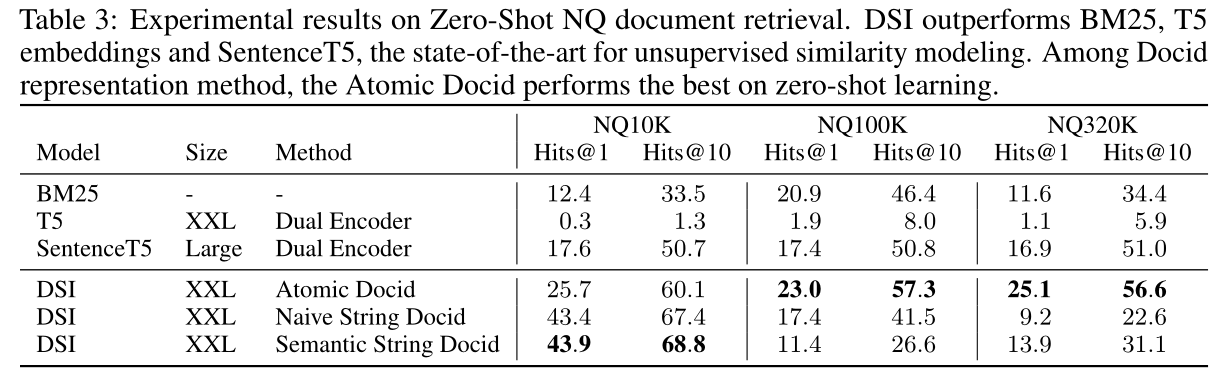
表 3 報告了零樣本檢索的結果。回想一下,零樣本檢索是通過僅執行索引而不執行檢索任務來執行的。換句話說,模型看不到任何帶注釋的查詢或文檔對。一般來說,在 NQ100K 和 NQ320K 上通過使用非結構化原子標識符的 DSI 可以獲得最佳結果。
所有 NQ 數據集上的最佳性能均優于 BM25 等完善的無監督檢索基線。此外,DSI 優于無監督表示學習方法,例如 SentenceT5(Ni 等人,2021),該方法經過訓練以通過對比學習來學習相似性感知表示。我們還注意到,原始 T5 嵌入的性能極差,并且在無監督檢索任務中無法產生合理的結果。鑒于無監督神經方法通常很難超越 BM25,我們發現這些早期結果非常令人鼓舞。
文檔標識符
本文的一個關鍵研究問題是如何表示 docids 的關鍵選擇。一般來說,我們發現結構化語義標識符很有幫助,并且比非結構化標識符有所改進。在比較樸素字符串標識符和語義字符串標識符時,如果可能的話,似乎必須使用語義標識符。這是直觀的,因為向目標空間注入語義結構可以促進更輕松的優化和額外的無監督表示學習方法作為外部知識。非結構化原子標識符的競爭力有些好壞參半,我們在優化此類模型時遇到了一些困難。我們假設這可能是因為新初始化的 softmax 層,并且從頭開始訓練這樣的系統可以緩解這些問題。然而,我們將這一調查線推遲到未來的工作中。由于非結構化原子標識符的不穩定性和高方差,不同數據集的性能并不一致。此外,這些文檔也可能會遇到間歇性不收斂的情況,我們可以追溯到與優化相關的怪癖。然而,我們還注意到,非結構化原子標識符在零樣本檢索設置上表現最好,并且性能通常比波束解碼方法高出一倍以上。
索引策略
在本節中,我們探討不同索引方法的效果(第 3.1.1 節)。我們使用前面描述的不同索引策略在 NQ100K 上進行實驗。使用 Naive Docid 方法訓練模型。在沒有索引的情況下,該模型實現了 0% Hits@1。這是直觀的,因為如果沒有索引任務,文檔就沒有意義。其次,Inputs2Targets 和雙向公式表現最好,與前者相比,雙向方法表現稍差(13.5 比 13.2)。最后,Targets2Inputs 的準確性和 Docids 的 Span Corrpution 沒有產生任何有意義的結果(0% 準確性)。這表明索引策略之間可能存在巨大差異,有些策略效果相當好,有些則完全不起作用。
不同的索引策略,效果差距很大。(索引策略:利用模型訓練 doc--》docid)
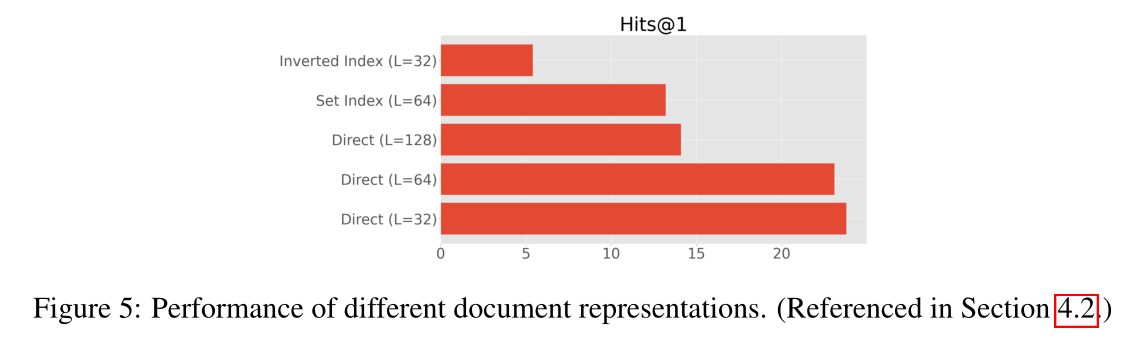
文檔表示
在本節中,我們將探討第 3.1.2 節中描述的不同文檔表示策略的性能。圖 5 報告了 NQ320K 上的結果。總的來說,我們發現直接索引方法效果最好。我們還發現,由于 docid 反復暴露于不同的 token,因此很難訓練倒排索引方法。我們還發現,較短的文檔長度似乎在性能似乎大幅下降到超過 64 個標記的情況下效果很好,這表明當文檔標記數量較多時,優化或有效記憶可能會更加困難。最后,我們還發現對文檔標記應用集合處理或停用詞預處理沒有額外的優勢。
使用少量的 token 表示文檔反而更好。
Scaling Laws
另一個有趣的見解是 DSI 的縮放法則與雙編碼器有何不同。近年來,了解 Transformer 的縮放行為引起了人們的極大興趣(Kaplan 等人,2020;Tay 等人,2021;Abnar 等人,2021)。我們發現,在 DE 中增加模型參數化所獲得的檢索性能增益似乎相對較小。相反,DSI 的擴展特性似乎更為樂觀。圖 3 繪制了三種方法(具有樸素 ID 和語義 ID 的 DE 和 DSI)的縮放行為(對數刻度)。 DSI(天真的)從從基礎到 XXL 的規模中受益匪淺,并且似乎仍有改進的空間。與此同時,DSI(語義)一開始與 DE 基礎具有同樣的競爭力,但在規模方面表現得更好。不幸的是,DE 模型在較小的參數化下或多或少處于穩定狀態。

索引和檢索之間的相互作用
我們早期的實驗表明,首先學習索引任務,然后按順序學習檢索任務會導致表現平庸。在那里,我們專注于探索使用多任務學習共同訓練索引和檢索任務的良好比率 r。圖 4 顯示了修改索引與檢索樣本比率的效果。我們發現優化過程受到索引和檢索任務之間相互作用的顯著影響。將 r 設置得太高或太低通常會導致性能不佳。我們發現 32 的比率通常表現良好。
1)先 index,然后 retrieve 效果不好
2)index / retrieve = 32,效果最好

5. 結論
本文提出了可微分搜索索引(DSI),這是一種以統一方式學習端到端搜索系統的新范式,為下一代搜索鋪平了道路(Metzler et al, 2021)。我們定義了新穎的索引和檢索任務,將術語和文檔之間的關系完全編碼在 Transformer 模型的參數內。論文提出了多種不同的方式來表示文檔和docid,并探索了不同的模型架構和模型訓練策略。在 Natural Questions 數據集上進行的實驗表明,無論是在標準微調設置還是零樣本設置中,DSI 的性能都優于 BM25 和雙編碼器等常見基線。盡管這里提出的模型和結果很有希望,但基于這項工作可以探索大量潛在的未來研究來改進這種方法。例如,探索表示文檔和文檔id的替代策略,以及研究專家混合模型(Du et al, 2021; Fedus et al, 2021; Lepikhin et al, 2020)來擴展DSI 的內存容量。一個重要的方向也是探索如何針對動態語料庫更新此類模型,其中可以在系統中添加或刪除文檔。最后,進一步研究 DSI 作為一種無監督表示學習方法和/或內存存儲以供其他語言模型利用也可能很有趣。
參考資料
【1】TPU:https://zhuanlan.zhihu.com/p/619847662
)
![LeetCode 刷題 [C++] 第55題.跳躍游戲](http://pic.xiahunao.cn/LeetCode 刷題 [C++] 第55題.跳躍游戲)

)



|198.打家劫舍 213.打家劫舍II 337.打家劫舍III)
)



)

)

》第5章-軟件工程基礎知識-05-凈室軟件工程(CSE))


