Google又有大動作!
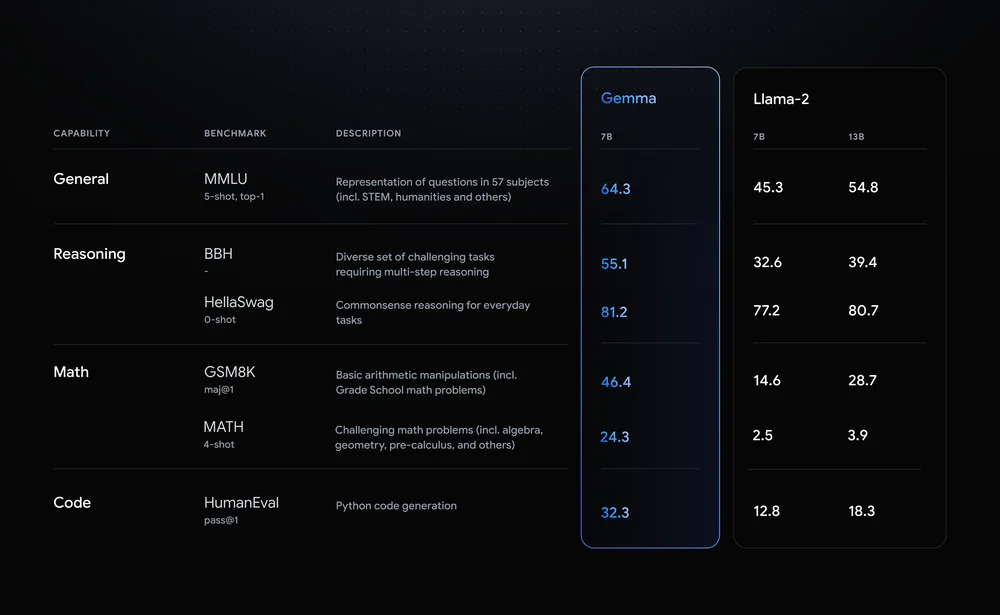
近日,他們發布了Gemma 2B和7B兩個開源AI模型,與大型封閉模型不同,它們更適合小型任務,如聊天和文本摘要。
這兩個模型在訓練過程中使用了6萬億個Tokens的數據,包括網頁文檔、代碼和數學文本,確保模型能應對廣泛的文本和編程問題。
相比之下,其他知名模型如LLaMA 2的訓練集都要小得多,大約只用了2萬億Tokens。
現在,你可以通過Kaggle、Hugging Face、Nvidia的NeMo以及Google的Vertex AI來獲取這些模型。
Gemma模型的特點是什么?如何使用?
內容遷移微信公眾號:李孟聊AI








)



)







