在之前的文章《2024 年,一個大數據從業者決定……》《存儲技術背后的那些事兒》中,我們粗略地回顧了大數據領域的存儲技術。在解決了「數據怎么存」之后,下一步就是解決「數據怎么用」的問題。
其實在大數據技術興起之前,對于用戶來講并沒有存儲和計算的區分,都是用一套數據庫或數據倉庫的產品來解決問題。而在數據量爆炸性增長后,情況就變得不一樣了。單機系統無法存儲如此之多的數據,先是過渡到了分庫分表這類偽分布式技術,又到了 Hadoop 時代基于分布式文件系統的方案,后來又到了數據庫基于一致性協議的分布式架構,最終演進為現在的存算分離的架構。
最近十幾年,Data Infra 領域的計算技術以及相關公司層出不窮,最終要解決的根本問題其實只有一個:如何讓用戶在既靈活又高效,架構既簡單又兼具高擴展性,接口既兼容老用戶習慣、又能滿足新用戶場景的前提下使用海量數據。
解讀一下,需求如下:
數據量大、數據種類多、數據邏輯復雜
支持 SQL 接口,讓習慣了 SQL 接口的 BI 老用戶們實現無縫遷移,同時要想辦法支持 AI 場景的接口——Python
交互式查詢延遲要低,能支持復雜的數據清洗任務,數據接入要實時
架構盡量簡單,不要有太多的運維成本,同時還能支持縱向、橫向的水平擴展,有足夠的彈性
據太可研究所(techinstitute)所知,目前市面上沒有哪款產品能同時滿足以上所有要求,如果有,那一定是騙人的。所以在計算領域誕生了眾多計算引擎、數據庫、計算平臺、流處理、ETL 等產品,甚至還有一個品類專門做數據集成,把數據在各個產品之間來回同步,對外再提供統一的接口。
不過,如果在計算領域只能選一個產品作為代表,那毫無疑問一定是 Spark。從 09 年誕生起到現在,Spark 已經發布至 3.5.0 版本,社區依舊有很強的生命力,可以說穿越了一個技術迭代周期。它背后的商業公司 Databricks 已經融到了 I 輪,估值 430 億💲,我們不妨沿著 Spark 的發展歷史梳理一下計算引擎技術的變革。
Vol.1
大數據計算的場景主要分兩類,一是離線數據處理,二是交互式數據查詢。離線數據處理的的特點產生的數據量大、任務時間長(任務時長在分鐘級甚至是小時級),主要對應數據清洗任務;交互式查詢的特點是任務時間短、并發大、輸出結果小,主要對應 BI 分析場景。
時間撥回 2010 年之前,彼時 Spark 還沒開源,當時計算引擎幾乎只有 Hadoop 配套的 MapReduce 可以用,早年間手寫 MapReduce 任務是一件門檻很高的事情。MapReduce 提供的接口非常簡單,只有 mapper、reducer、partitioner、combiner 等寥寥幾個,任務之間傳輸數據只有序列化存到 hdfs 這一條路,而真實世界的任務不可能只有 Word Count 這種 demo。所以要寫好 MapReduce 肯定要深入理解其中的原理,要處理數據傾斜、復雜的參數配置、任務編排、中間結果落盤等。現在 MapReduce 已經屬于半入土的技術了,但它還為業界留下了大量的徒子徒孫,例如各個云廠商的 EMR 產品,就是一種傳承。
Spark 開源之后為業界帶來了新的方案,RDD 的抽象可以讓用戶像正常編寫代碼一樣寫分布式任務,還支持 Python、Java、Scala 三種接口,大大降低了用戶編寫任務的門檻。總結下來,Spark 能短時間內獲得用戶的青睞有以下幾點:
更好的設計,包括基于寬窄依賴的 dag 設計,能大大簡化 job 編排
性能更高,計算在內存而非全程依賴 hdfs,這是Spark 早期最大的賣點,直到 Spark2.x 的官網上還一直放著一張和 mapreduce 的性能對比,直到這幾年沒人關心 mapreduce 之后才撤掉
更優雅的接口,RDD 的抽象以及配套的 API 更符合人類的直覺
API 豐富,除了 RDD 和配套的算子,還支持了Python 接口,這直接讓受眾提升了一個數量級
但早期的 Spark 也有很多問題,例如內存管理不當導致程序 OOM、數據傾斜問題、繼承了 Hadoop 那套復雜的配置。Spark 誕生之初非常積極地融入 Hadoop 體系,例如,代碼里依賴了大量 Hadoop 的包,文件系統和文件訪問接口沿用了 Hadoop 的設計,資源管理一開始只有 Hadoop 的 Yarn。直到現在這些代碼依舊大量使用,未來也不可能再做修改,所以說盡管 Hadoop 可能不復存在,但 Hadoop 的代碼會一直保留下去,在很多計算引擎里面發揮著不可替代的作用。
Vol.2
無論是非常難用的 MapReduce 接口,還是相對沒那么難用的 Spark RDD 接口,受眾只是研發人員,接口是代碼。
無論是做數據清洗的數據工程師,還是使用 BI 的數據分析師,最熟悉的接口還是 SQL。
因此,市面上便誕生了大量 SQL on Hadoop 的產品,很多產品直到現在也還很有生命力。
最早出現的是 Hive,Hive 的影響力在大數據生態里太大,大到很多人都以為它是 Hadoop 原生自帶的產品,不知道它是 Facebook 開源的。Hive 主要的能力只有一個就是把 SQL 翻譯成 MapReduce 任務,這件事說來簡單,好像也就是本科生大作業的水平,但想把它做好卻是件非常有挑戰性的工作,早期也只有 Hive 做到了,而且成為了事實上的標準。
要把 SQL 翻譯成 MapReduce 任務,需要有幾個必備組件,一是 SQL 相關的 Parser、Planner、Optimizer、Executor,基本上是一個 SQL 數據庫的標配,二是 metadata,需要存儲數據庫、表、分區等信息,以及表和 HDFS數據之間的關系。
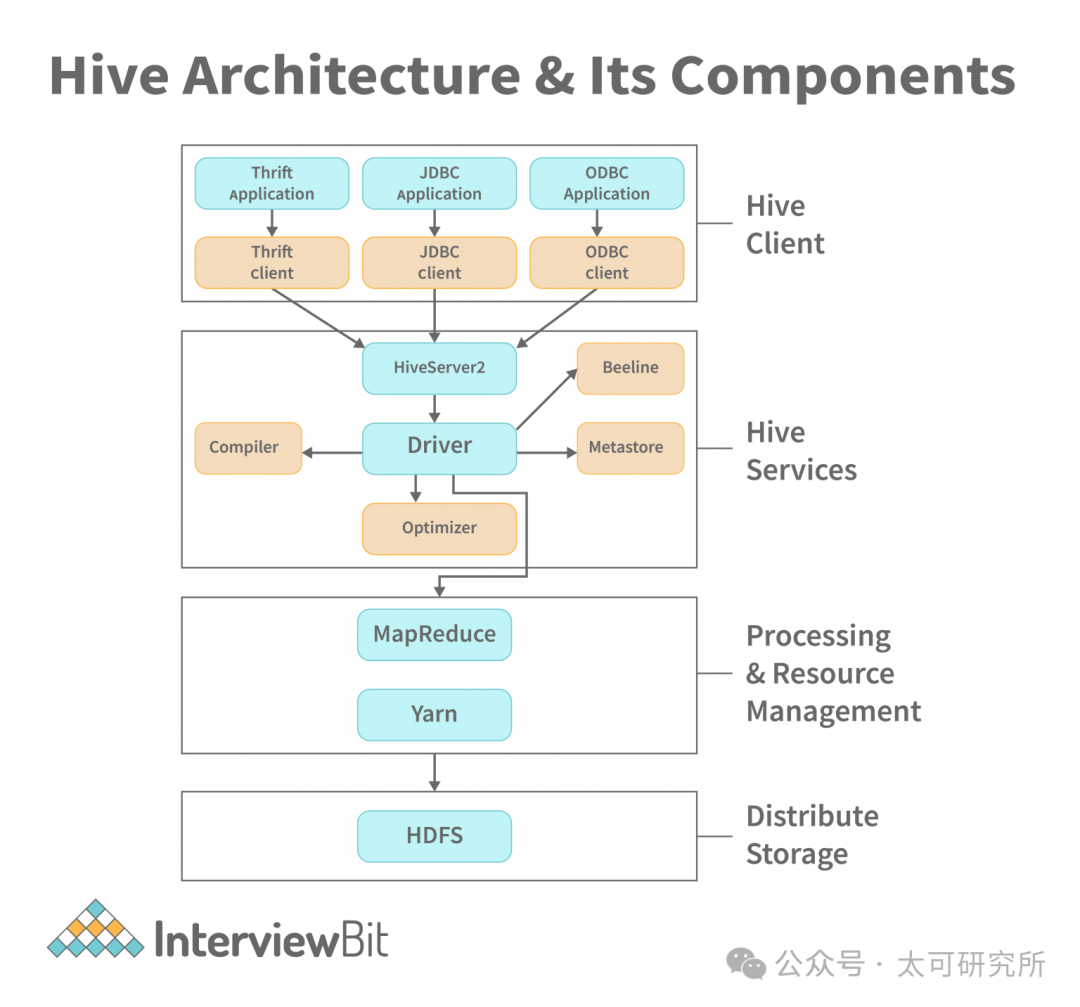 圖源|https://www.interviewbit.com/blog/hive-architecture/
圖源|https://www.interviewbit.com/blog/hive-architecture/
Hive 的這套思路影響了后來眾多的計算引擎,例如 Spark SQL、Presto 等默認都會支持 Hive Metastore。Hive 的架構最大的瓶頸就在 MapReduce 上,無法做到低延遲的查詢,也就無法解決用戶低延遲、交互式分析的需求。有個很直觀的例子,每次用戶提交一個 Hive 查詢,可以去喝一杯咖啡再回來看結果。此外,哪怕是離線數據清洗的任務使用 Hive 也相對較慢。
Spark 在 2012 年發布的 0.8 版本中開發了 Spark SQL 模塊,類似 Hive 的思路,把 SQL 編譯成 RDD 任務,同時期的 Presto 也進入了 Apache 孵化器,目標也是解決大數據場景下交互式分析的場景。Spark 和 Presto 支持 SQL 的時間相仿,但后來走上了相當不同的道路,Presto 的定位更接近一個 OLAP 數據庫,重心在交互式查詢場景,而 Spark 則將注意力放在數據處理任務上,是一個開發分布式任務的框架,自始至終都不是一個完整的數據庫,市面上基于 Spark 開發的數據庫產品,倒是有不少。
通過 SQL 交互在 10 年代早期,逐漸變成了主流使用大數據產品的主流范式,包括離線任務、交互式查詢的接口都逐漸統一到了SQL。隨著數據量進一步增長,查詢性能一直解決得不好,哪怕是 Spark SQL、Presto,也只能把延遲降低到分鐘級別,還是遠遠無法滿足業務的需求。
這種情況直到 2015 年 Kylin 開源才得以解決,基于Cube、預計算技術第一次將大數據領域的交互式查詢延遲降低到了秒級,做到了和傳統數倉達類似的查詢體驗。但 kylin 的做法代價也很大,用戶需要自定義各種模型、Cube、維度、指標等等概念非常復雜,還要學會設計 rowkey 否則性能也不會很好。Kylin 的出現讓業界看到了秒級延遲的可能性,至此內業一些同學甚至覺得大數據場景下 Hadoop + Hive + Spark + Kylin + HBase 可能就是最優解了,頂多還需要加上 Kafka + Flink 去解決實時數據的問題。
但是,2018 年 Clickhouse 橫空出世,通過 SIMD、列存、索引優化、數據預熱等一系列的暴力優化,竟然也可把查詢延遲降低到秒級,而且架構極其簡單,只要 Zookeeper + Clickhouse,就能解決上面一堆產品疊加才可解決的問題。這一下子戳中了 Hadoop 體系的痛點——Hadoop 體系產品太多、架構太復雜、運維困難。
自 ClickHouse 后,數據庫產品們便開始瘋狂吸收其優秀經驗,大數據和數據庫兩個方向逐漸融合,業界重新開始思考「大數據技術真的需要單獨的一個體系嗎?」「Hadoop 的方向是對的嗎?」「數據庫能不能解決海量數據的場景?」這個話題有點宏大,可以放在以后討論。
Vol.3
說回計算引擎,早期的引擎無論是 Hive 也好,Spark 的 RDD 接口也罷,都不適合實時的數據寫入。而在大數據技術演進的這些年里,用戶的場景也越來越復雜。早期的離線計算引擎只能提供離線數據導入,這就使得用戶只能做 T+1 或近似 T+0 的分析。但很多場景需要的是實時分析,到現在,實時分析已經成為了新引擎的標配。
Spark 在 0.9 本版里提供了一套 Spark streaming 接口嘗試解決實時的問題,但扒開 Spark streaming 的代碼,不難發現它實際上是一段時間觸發一個微批任務,對于延遲沒那么敏感的用戶其實已經夠用了。當然也有想要近乎沒有延遲的用戶,例如金融交易監控、廣告營銷場景、物聯網的場景等。
實時流數據的難度要遠高于批處理,首先,如何做到低延遲就是個難點。其次,流數據本身質量遠低于批數據,具體體現在流數據會有亂序、數據丟失、數據重復的問題。此外,要做流處理還需要確保任務能長期穩定地運行,這與批處理任務跑完就結束對穩定性的要求很不一樣。最后,還有很復雜的數據狀態管理,包括 checkpoint 管理、增量更新、狀態數據一致性、持久化的問題。
Apache Flink 對這些問題解決的遠比 Spark streaming 要好,所以在很長時間內 Flink 就是流計算的代名詞。Spark 直到 2.0 發布了 structured streaming 模塊之后,才有了和 Flink 同臺競技的資格。Flink 雖然在流計算場景里是無可爭議的領導者,但在流計算的場景和市場空間遠小于離線計算、交互式分析的市場。可以這樣認為,其在數據分析領域錦上添花的功能而非必備能力,Flink 背后的團隊和 Databricks 差距也很大,曾創業兩次,又先后賣給阿里和 Confluent,這可能也是 Flink 的影響力遠小于 Spark 的原因。
好了,本次的大數據計算技術漫談(上)就先談到這里,下周同一時間,咱們繼續!
本文由 mdnice 多平臺發布












![[計算機網絡]---TCP協議](http://pic.xiahunao.cn/[計算機網絡]---TCP協議)

![P1024 [NOIP2001 提高組] 一元三次方程求解](http://pic.xiahunao.cn/P1024 [NOIP2001 提高組] 一元三次方程求解)


)
:程序環境和預處理詳解)
