1 JVM組成
1.1 JVM由那些部分組成,運行流程是什么?
難易程度:☆☆☆
出現頻率:☆☆☆☆
JVM是什么
Java Virtual Machine Java程序的運行環境(java二進制字節碼的運行環境)
好處:
-
一次編寫,到處運行
-
自動內存管理,垃圾回收機制
JVM由哪些部分組成,運行流程是什么?

從圖中可以看出 JVM 的主要組成部分
-
ClassLoader(類加載器)
-
Runtime Data Area(運行時數據區,內存分區)
-
Execution Engine(執行引擎)
-
Native Method Library(本地庫接口)
運行流程:
(1)類加載器(ClassLoader)把Java代碼轉換為字節碼
(2)運行時數據區(Runtime Data Area)把字節碼加載到內存中,而字節碼文件只是JVM的一套指令集規范,并不能直接交給底層系統去執行,而是有執行引擎運行
(3)執行引擎(Execution Engine)將字節碼翻譯為底層系統指令,再交由CPU執行去執行,此時需要調用其他語言的本地庫接口(Native Method Library)來實現整個程序的功能。
1.2 什么是程序計數器?
難易程度:☆☆☆
出現頻率:☆☆☆☆
程序計數器:線程私有的,內部保存的字節碼的行號。用于記錄正在執行的字節碼指令的地址。
javap -verbose xx.class 打印堆棧大小,局部變量的數量和方法的參數。

? java虛擬機對于多線程是通過線程輪流切換并且分配線程執行時間。在任何的一個時間點上,一個處理器只會處理執行一個線程,如果當前被執行的這個線程它所分配的執行時間用完了【掛起】。處理器會切換到另外的一個線程上來進行執行。并且這個線程的執行時間用完了,接著處理器就會又來執行被掛起的這個線程。
? 那么現在有一個問題就是,當前處理器如何能夠知道,對于這個被掛起的線程,它上一次執行到了哪里?那么這時就需要從程序計數器中來回去到當前的這個線程他上一次執行的行號,然后接著繼續向下執行。
? 程序計數器是JVM規范中唯一一個沒有規定出現OOM的區域,所以這個空間也不會進行GC。
1.3 你能給我詳細的介紹Java堆嗎?
難易程度:☆☆☆
出現頻率:☆☆☆☆
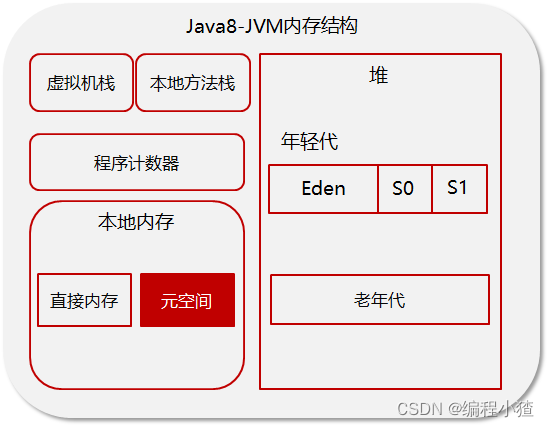
線程共享的區域:主要用來保存對象實例,數組等,當堆中沒有內存空間可分配給實例,也無法再擴展時,則拋出OutOfMemoryError異常。
-
年輕代被劃分為三部分,Eden區和兩個大小嚴格相同的Survivor區,根據JVM的策略,在經過幾次垃圾收集后,任然存活于Survivor的對象將被移動到老年代區間。
-
老年代主要保存生命周期長的對象,一般是一些老的對象
-
元空間保存的類信息、靜態變量、常量、編譯后的代碼
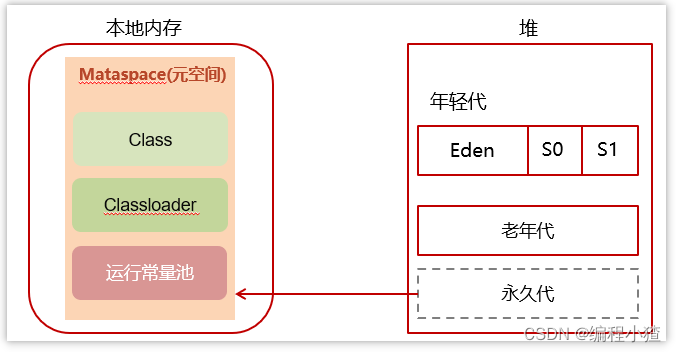
為了避免方法區出現OOM,所以在java8中將堆上的方法區【永久代】給移動到了本地內存上,重新開辟了一塊空間,叫做元空間。那么現在就可以避免掉OOM的出現了。
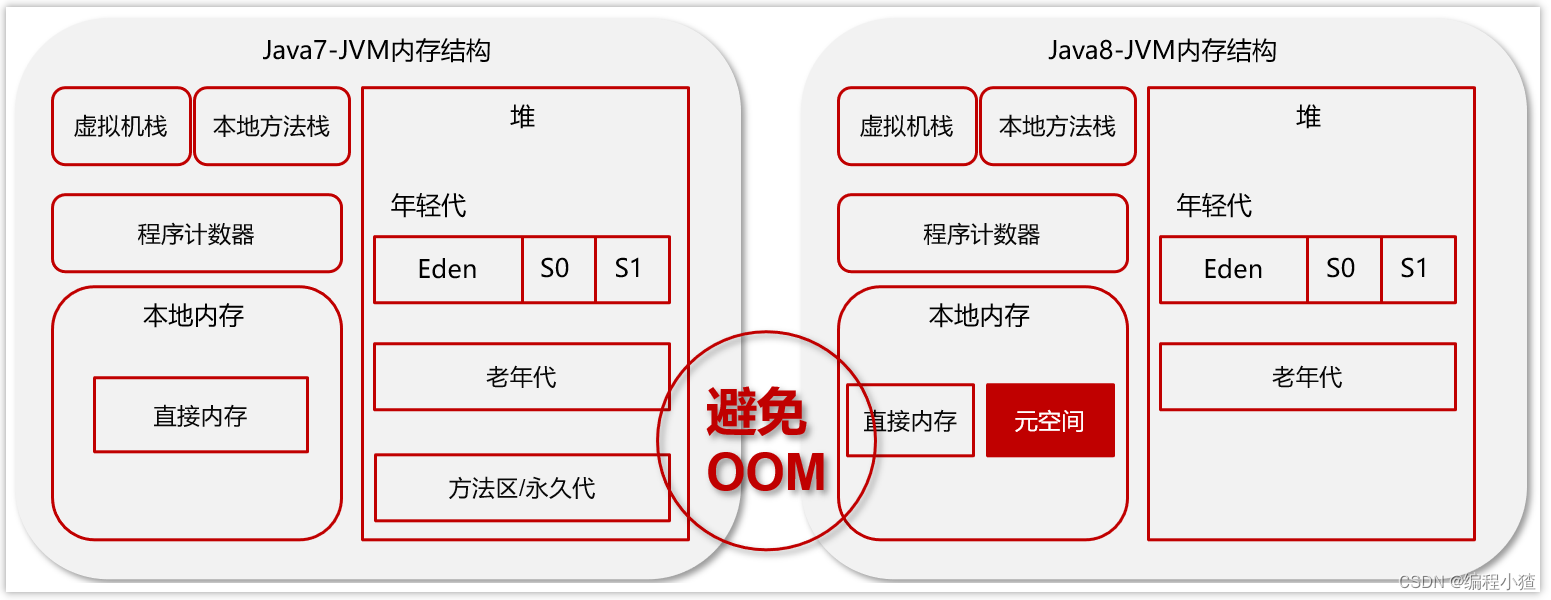
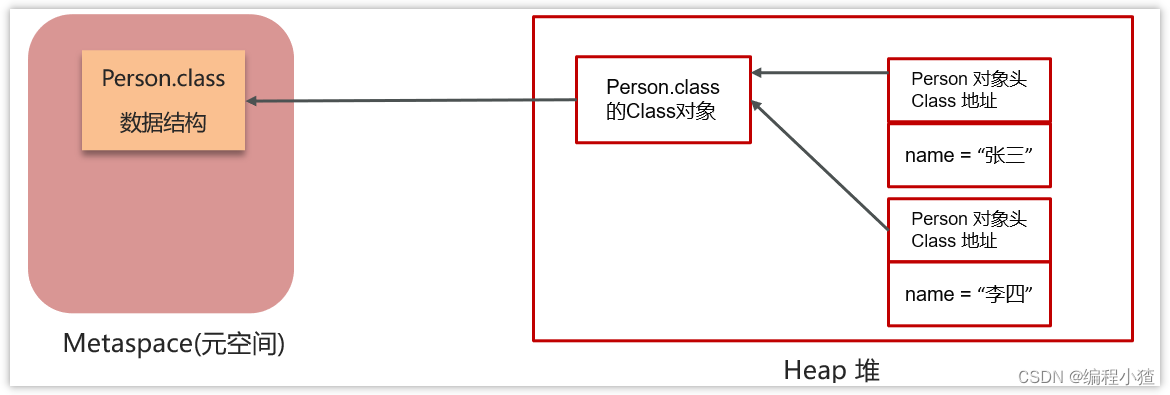
元空間(MetaSpace)介紹
? 在 HotSpot JVM 中,永久代( ≈ 方法區)中用于存放類和方法的元數據以及常量池,比如Class 和 Method。每當一個類初次被加載的時候,它的元數據都會放到永久代中。
? 永久代是有大小限制的,因此如果加載的類太多,很有可能導致永久代內存溢出,即OutOfMemoryError,為此不得不對虛擬機做調優。
? 那么,Java 8 中 PermGen 為什么被移出 HotSpot JVM 了?
官網給出了解釋:JEP 122: Remove the Permanent Generation
This is part of the JRockit and Hotspot convergence effort. JRockit customers do not need to configure the permanent generation (since JRockit does not have a permanent generation) and are accustomed to not configuring the permanent generation. ? 移除永久代是為融合HotSpot JVM與 JRockit VM而做出的努力,因為JRockit沒有永久代,不需要配置永久代。
1)由于 PermGen 內存經常會溢出,引發OutOfMemoryError,因此 JVM 的開發者希望這一塊內存可以更靈活地被管理,不要再經常出現這樣的 OOM。
2)移除 PermGen 可以促進 HotSpot JVM 與 JRockit VM 的融合,因為 JRockit 沒有永久代。
? 準確來說,Perm 區中的字符串常量池被移到了堆內存中是在 Java7 之后,Java 8 時,PermGen 被元空間代替,其他內容比如類元信息、字段、靜態屬性、方法、常量等都移動到元空間區。比如 java/lang/Object 類元信息、靜態屬性 System.out、整型常量等。
? 元空間的本質和永久代類似,都是對 JVM 規范中方法區的實現。不過元空間與永久代之間最大的區別在于:元空間并不在虛擬機中,而是使用本地內存。因此,默認情況下,元空間的大小僅受本地內存限制。
1.4 什么是虛擬機棧
難易程度:☆☆☆
出現頻率:☆☆☆☆
Java Virtual machine Stacks (java 虛擬機棧)
-
每個線程運行時所需要的內存,稱為虛擬機棧,先進后出
-
每個棧由多個棧幀(frame)組成,對應著每次方法調用時所占用的內存
-
每個線程只能有一個活動棧幀,對應著當前正在執行的那個方法

-
垃圾回收是否涉及棧內存?
垃圾回收主要指就是堆內存,當棧幀彈棧以后,內存就會釋放
-
棧內存分配越大越好嗎?
未必,默認的棧內存通常為1024k
棧幀過大會導致線程數變少,例如,機器總內存為512m,目前能活動的線程數則為512個,如果把棧內存改為2048k,那么能活動的棧幀就會減半
-
方法內的局部變量是否線程安全?
- 如果方法內局部變量沒有逃離方法的作用范圍,它是線程安全的
- 如果是局部變量引用了對象,并逃離方法的作用范圍,需要考慮線程安全
- 比如以下代碼:

棧內存溢出情況
-
棧幀過多導致棧內存溢出,典型問題:遞歸調用

-
棧幀過大導致棧內存溢出
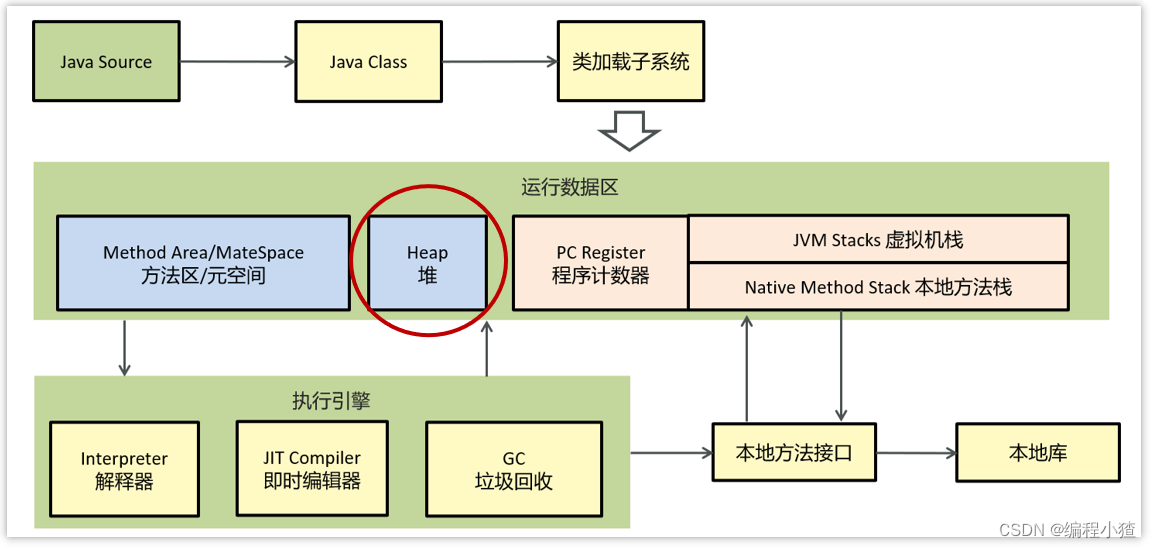
運行數據區的組成
難易程度:☆☆☆
出現頻率:☆☆☆
組成部分:堆、方法區、棧、本地方法棧、程序計數器
1、堆解決的是對象實例存儲的問題,垃圾回收器管理的主要區域。2、方法區可以認為是堆的一部分,用于存儲已被虛擬機加載的信息,常量、靜態變量、即時編譯器編譯后的代碼。3、棧解決的是程序運行的問題,棧里面存的是棧幀,棧幀里面存的是局部變量表、操作數棧、動態鏈接、方法出口等信息。4、本地方法棧與棧功能相同,本地方法棧執行的是本地方法,一個Java調用非Java代碼的接口。5、程序計數器(PC寄存器)程序計數器中存放的是當前線程所執行的字節碼的行數。JVM工作時就是通過改變這個計數器的值來選取下一個需要執行的字節碼指令。
1.5 能不能解釋一下方法區?
難易程度:☆☆☆
出現頻率:☆☆☆
1.5.1 概述
-
方法區(Method Area)是各個線程共享的內存區域
-
主要存儲類的信息、運行時常量池
-
虛擬機啟動的時候創建,關閉虛擬機時釋放
-
如果方法區域中的內存無法滿足分配請求,則會拋出OutOfMemoryError: Metaspace
1.5.2 常量池
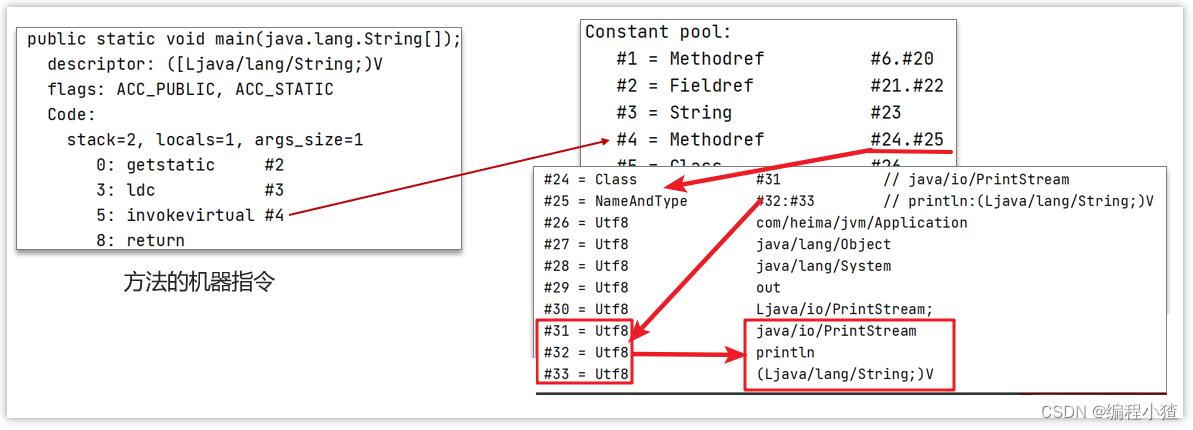
可以看作是一張表,虛擬機指令根據這張常量表找到要執行的類名、方法名、參數類型、字面量等信息
查看字節碼結構(類的基本信息、常量池、方法定義)javap -v xx.class
比如下面是一個Application類的main方法執行,源碼如下:
public class Application {public static void main(String[] args) {System.out.println("hello world");}
}找到類對應的class文件存放目錄,執行命令:javap -v Application.class 查看字節碼結構
D:\code\jvm-demo\target\classes\com\heima\jvm>javap -v Application.class
Classfile /D:/code/jvm-demo/target/classes/com/heima/jvm/Application.classLast modified 2023-05-07; size 564 bytes ? ?//最后修改的時間MD5 checksum c1b64ed6491b9a16c2baab5061c64f88 ? //簽名Compiled from "Application.java" ? //從哪個源碼編譯
public class com.heima.jvm.Application ? //包名,類名minor version: 0major version: 52 ? ? //jdk版本flags: ACC_PUBLIC, ACC_SUPER ?//修飾符
Constant pool: ? //常量池#1 = Methodref ? ? ? ? ?#6.#20 ? ? ? ? // java/lang/Object."<init>":()V#2 = Fieldref ? ? ? ? ? #21.#22 ? ? ? ?// java/lang/System.out:Ljava/io/PrintStream;#3 = String ? ? ? ? ? ? #23 ? ? ? ? ? ?// hello world#4 = Methodref ? ? ? ? ?#24.#25 ? ? ? ?// java/io/PrintStream.println:(Ljava/lang/String;)V#5 = Class ? ? ? ? ? ? ?#26 ? ? ? ? ? ?// com/heima/jvm/Application#6 = Class ? ? ? ? ? ? ?#27 ? ? ? ? ? ?// java/lang/Object#7 = Utf8 ? ? ? ? ? ? ? <init>#8 = Utf8 ? ? ? ? ? ? ? ()V#9 = Utf8 ? ? ? ? ? ? ? Code#10 = Utf8 ? ? ? ? ? ? ? LineNumberTable#11 = Utf8 ? ? ? ? ? ? ? LocalVariableTable#12 = Utf8 ? ? ? ? ? ? ? this#13 = Utf8 ? ? ? ? ? ? ? Lcom/heima/jvm/Application;#14 = Utf8 ? ? ? ? ? ? ? main#15 = Utf8 ? ? ? ? ? ? ? ([Ljava/lang/String;)V#16 = Utf8 ? ? ? ? ? ? ? args#17 = Utf8 ? ? ? ? ? ? ? [Ljava/lang/String;#18 = Utf8 ? ? ? ? ? ? ? SourceFile#19 = Utf8 ? ? ? ? ? ? ? Application.java#20 = NameAndType ? ? ? ?#7:#8 ? ? ? ? ?// "<init>":()V#21 = Class ? ? ? ? ? ? ?#28 ? ? ? ? ? ?// java/lang/System#22 = NameAndType ? ? ? ?#29:#30 ? ? ? ?// out:Ljava/io/PrintStream;#23 = Utf8 ? ? ? ? ? ? ? hello world#24 = Class ? ? ? ? ? ? ?#31 ? ? ? ? ? ?// java/io/PrintStream#25 = NameAndType ? ? ? ?#32:#33 ? ? ? ?// println:(Ljava/lang/String;)V#26 = Utf8 ? ? ? ? ? ? ? com/heima/jvm/Application#27 = Utf8 ? ? ? ? ? ? ? java/lang/Object#28 = Utf8 ? ? ? ? ? ? ? java/lang/System#29 = Utf8 ? ? ? ? ? ? ? out#30 = Utf8 ? ? ? ? ? ? ? Ljava/io/PrintStream;#31 = Utf8 ? ? ? ? ? ? ? java/io/PrintStream#32 = Utf8 ? ? ? ? ? ? ? println#33 = Utf8 ? ? ? ? ? ? ? (Ljava/lang/String;)V
{public com.heima.jvm.Application(); ?//構造方法descriptor: ()Vflags: ACC_PUBLICCode:stack=1, locals=1, args_size=10: aload_01: invokespecial #1 ? ? ? ? ? ? ? ? ?// Method java/lang/Object."<init>":()V4: returnLineNumberTable:line 3: 0LocalVariableTable:Start ?Length ?Slot ?Name ? Signature0 ? ? ? 5 ? ? 0 ?this ? Lcom/heima/jvm/Application;
?public static void main(java.lang.String[]); ?//main方法descriptor: ([Ljava/lang/String;)Vflags: ACC_PUBLIC, ACC_STATICCode:stack=2, locals=1, args_size=10: getstatic ? ? #2 ? ? ? ? ? ? ? ? ?// Field java/lang/System.out:Ljava/io/PrintStream;3: ldc ? ? ? ? ? #3 ? ? ? ? ? ? ? ? ?// String hello world5: invokevirtual #4 ? ? ? ? ? ? ? ? ?// Method java/io/PrintStream.println:(Ljava/lang/String;)V8: returnLineNumberTable:line 7: 0line 8: 8LocalVariableTable:Start ?Length ?Slot ?Name ? Signature0 ? ? ? 9 ? ? 0 ?args ? [Ljava/lang/String;
}
SourceFile: "Application.java"下圖,左側是main方法的指令信息,右側constant pool 是常量池
main方法按照指令執行的時候,需要到常量池中查表翻譯找到具體的類和方法地址去執行

1.5.3 運行時常量池
常量池是 *.class 文件中的,當該類被加載,它的常量池信息就會放入運行時常量池,并把里面的符號地址變為真實地址

1.6 你聽過直接內存嗎?
難易程度:☆☆☆
出現頻率:☆☆☆
不受 JVM 內存回收管理,是虛擬機的系統內存(操作系統的內存),常見于 NIO 操作時,用于數據緩沖區,分配回收成本較高,但讀寫性能高,不受 JVM 內存回收管理
舉例:
需求,在本地電腦中的一個較大的文件(超過100m)從一個磁盤挪到另外一個磁盤

代碼如下:
/*** 演示 ByteBuffer 作用*/
public class Demo1_9 {static final String FROM = "E:\\編程資料\\第三方教學視頻\\youtube\\Getting Started with Spring Boot-sbPSjI4tt10.mp4";static final String TO = "E:\\a.mp4";static final int _1Mb = 1024 * 1024;
?public static void main(String[] args) {io(); // io 用時:1535.586957 1766.963399 1359.240226directBuffer(); // directBuffer 用時:479.295165 702.291454 562.56592}
?private static void directBuffer() {long start = System.nanoTime();try (FileChannel from = new FileInputStream(FROM).getChannel();FileChannel to = new FileOutputStream(TO).getChannel();) {ByteBuffer bb = ByteBuffer.allocateDirect(_1Mb);while (true) {int len = from.read(bb);if (len == -1) {break;}bb.flip();to.write(bb);bb.clear();}} catch (IOException e) {e.printStackTrace();}long end = System.nanoTime();System.out.println("directBuffer 用時:" + (end - start) / 1000_000.0);}
?private static void io() {long start = System.nanoTime();try (FileInputStream from = new FileInputStream(FROM);FileOutputStream to = new FileOutputStream(TO);) {byte[] buf = new byte[_1Mb];while (true) {int len = from.read(buf);if (len == -1) {break;}to.write(buf, 0, len);}} catch (IOException e) {e.printStackTrace();}long end = System.nanoTime();System.out.println("io 用時:" + (end - start) / 1000_000.0);}
}可以發現,使用傳統的IO的時間要比NIO操作的時間長了很多了,也就說NIO的讀性能更好。
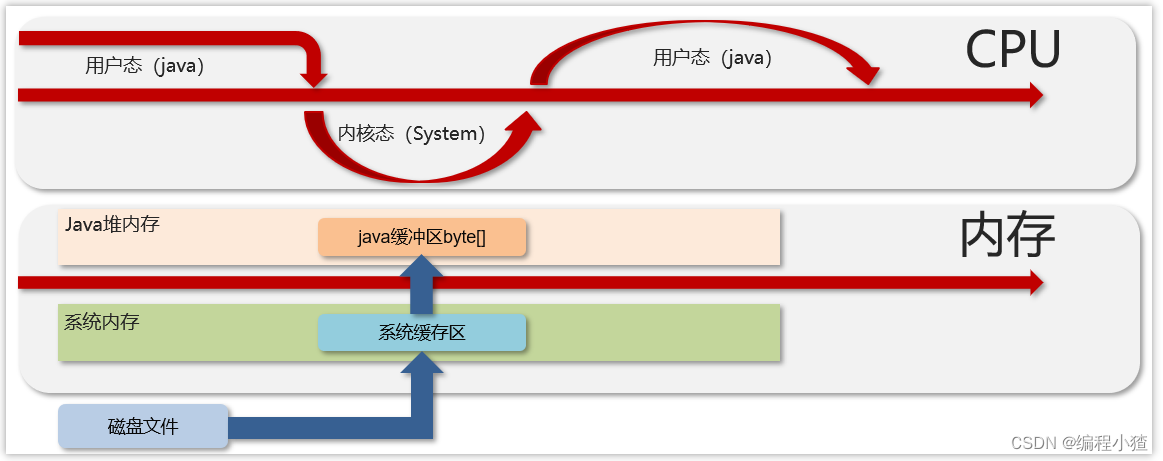
這個是跟我們的JVM的直接內存是有一定關系,如下圖,是傳統阻塞IO的數據傳輸流程
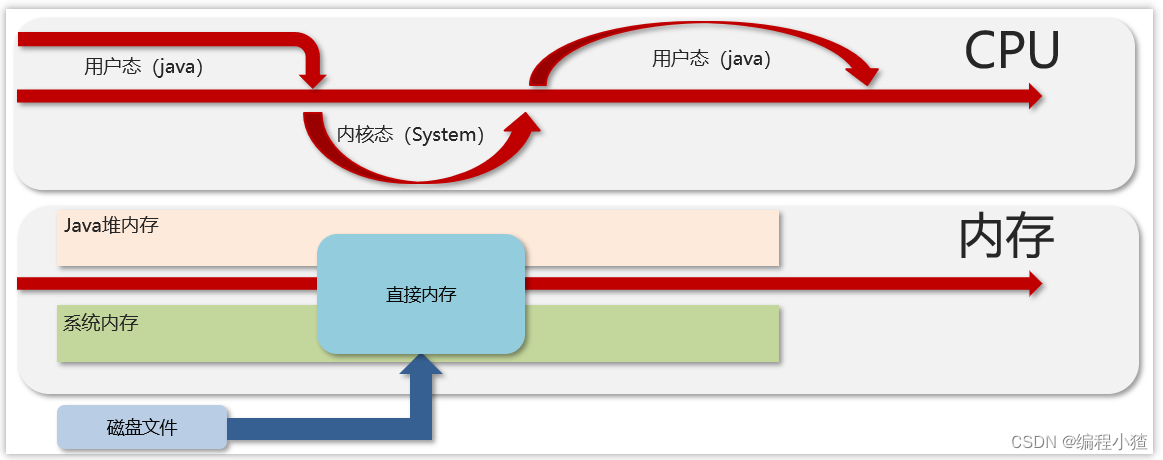
下圖是NIO傳輸數據的流程,在這個里面主要使用到了一個直接內存,不需要在堆中開辟空間進行數據的拷貝,jvm可以直接操作直接內存,從而使數據讀寫傳輸更快。
1.7 堆棧的區別是什么?
難易程度:☆☆☆
出現頻率:☆☆☆☆
1、棧內存一般會用來存儲局部變量和方法調用,但堆內存是用來存儲Java對象和數組的的。堆會GC垃圾回收,而棧不會。
2、棧內存是線程私有的,而堆內存是線程共有的。
3,、兩者異常錯誤不同,但如果棧內存或者堆內存不足都會拋出異常。
棧空間不足:java.lang.StackOverFlowError。
堆空間不足:java.lang.OutOfMemoryError。
2 類加載器
2.1 什么是類加載器,類加載器有哪些?
難易程度:☆☆☆☆
出現頻率:☆☆☆
要想理解類加載器的話,務必要先清楚對于一個Java文件,它從編譯到執行的整個過程。
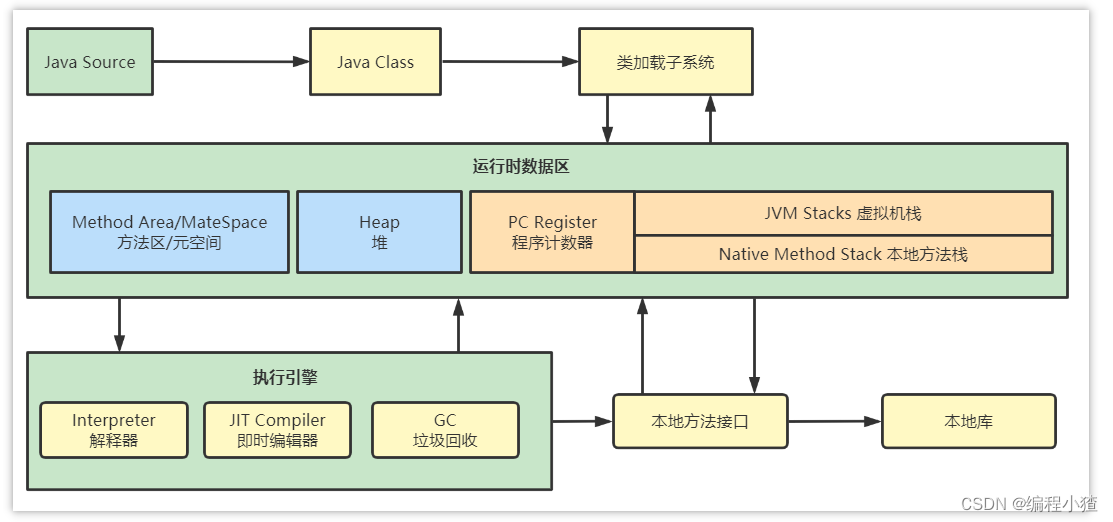
-
類加載器:用于裝載字節碼文件(.class文件)
-
運行時數據區:用于分配存儲空間
-
執行引擎:執行字節碼文件或本地方法
-
垃圾回收器:用于對JVM中的垃圾內容進行回收
類加載器
JVM只會運行二進制文件,而類加載器(ClassLoader)的主要作用就是將字節碼文件加載到JVM中,從而讓Java程序能夠啟動起來。現有的類加載器基本上都是java.lang.ClassLoader的子類,該類的只要職責就是用于將指定的類找到或生成對應的字節碼文件,同時類加載器還會負責加載程序所需要的資源
類加載器種類
類加載器根據各自加載范圍的不同,劃分為四種類加載器:
-
啟動類加載器(BootStrap ClassLoader):
該類并不繼承ClassLoader類,其是由C++編寫實現。用于加載JAVA_HOME/jre/lib目錄下的類庫。主要加載以下類:
核心Java類庫:包括java.lang、java.util等核心類庫,這些類庫提供了Java程序運行所必需的基本功能和類定義。
JVM運行時的支持類:包括與JVM運行時相關的類,如sun.misc.Unsafe等。
其他一些關鍵的類:例如java.lang.Object、java.lang.Class等核心類。
-
擴展類加載器(ExtClassLoader):
該類是ClassLoader的子類,主要加載JAVA_HOME/jre/lib/ext目錄中的類庫。主要加載以下類:
JRE擴展目錄中的JAR包和類庫:即<JRE_HOME>/lib/ext目錄下的JAR包和類庫,這些類庫提供了對JRE的擴展功能,通常是一些官方或第三方的擴展組件和庫。
JDK自帶的一些擴展性API:例如JDK自帶的JMX(Java Management Extensions)等。
-
應用類加載器(AppClassLoader):
該類是ClassLoader的子類,主要用于加載classPath下的類,也就是加載開發者自己編寫的Java類。
-
自定義類加載器:
開發者自定義類繼承ClassLoader,實現自定義類加載規則。
上述三種類加載器的層次結構如下如下:
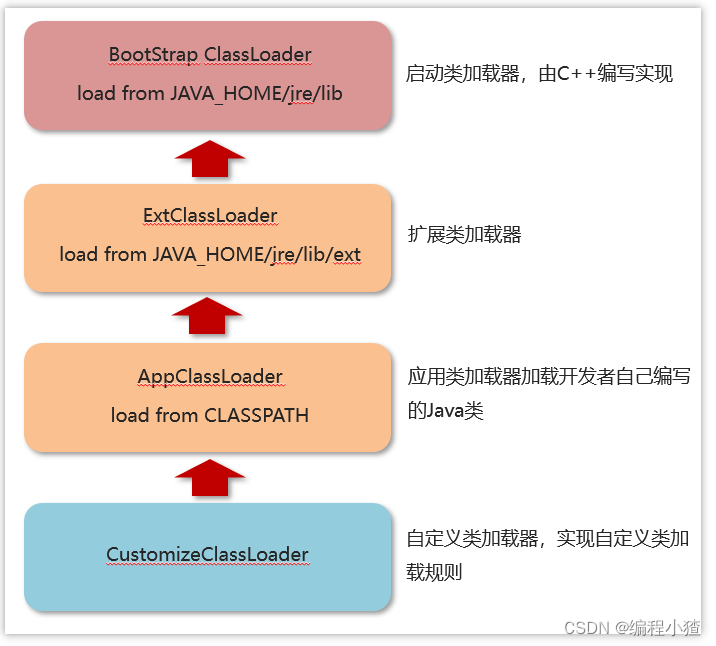
類加載器的體系并不是“繼承”體系,而是委派體系,類加載器首先會到自己的parent中查找類或者資源,如果找不到才會到自己本地查找。類加載器的委托行為動機是為了避免相同的類被加載多次。
2.2 什么是雙親委派模型?
難易程度:☆☆☆☆
出現頻率:☆☆☆☆
如果一個類加載器在接到加載類的請求時,它首先不會自己嘗試去加載這個類,而是把這個請求任務委托給父類加載器去完成,依次遞歸,如果父類加載器可以完成類加載任務,就返回成功;只有父類加載器無法完成此加載任務時,才由下一級去加載。

2.3 JVM為什么采用雙親委派機制
難易程度:☆☆☆
出現頻率:☆☆☆
(1)通過雙親委派機制可以避免某一個類被重復加載,當父類已經加載后則無需重復加載,保證唯一性。
(2)為了安全,保證類庫API不會被修改
在工程中新建java.lang包,接著在該包下新建String類,并定義main函數
public class String {
?public static void main(String[] args) {
?System.out.println("demo info");}
}? 此時執行main函數,會出現異常,在類 java.lang.String 中找不到 main 方法

? 出現該信息是因為由雙親委派的機制,java.lang.String的在啟動類加載器(Bootstrap classLoader)得到加載,因為在核心jre庫中有其相同名字的類文件,但該類中并沒有main方法。這樣就能防止惡意篡改核心API庫。
2.4 說一下類裝載的執行過程?
難易程度:☆☆☆☆☆
出現頻率:☆☆☆
類從加載到虛擬機中開始,直到卸載為止,它的整個生命周期包括了:加載、驗證、準備、解析、初始化、使用和卸載這7個階段。其中,驗證、準備和解析這三個部分統稱為連接(linking)。
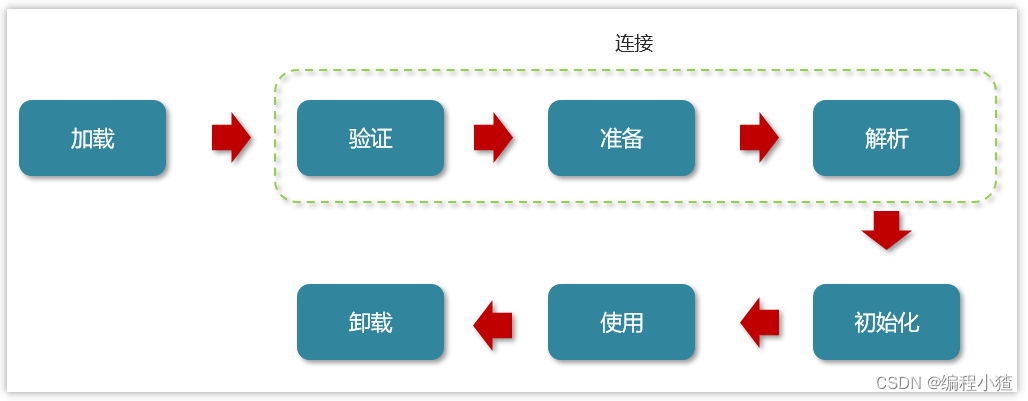
類加載過程詳解
1.加載

-
通過類的全名,獲取類的二進制數據流。
-
解析類的二進制數據流為方法區內的數據結構(Java類模型)
-
創建java.lang.Class類的實例,表示該類型。作為方法區這個類的各種數據的訪問入口
2.驗證

驗證類是否符合JVM規范,安全性檢查
(1)文件格式驗證:是否符合Class文件的規范(2)元數據驗證 這個類是否有父類(除了Object這個類之外,其余的類都應該有父類) 這個類是否繼承(extends)了被final修飾過的類(被final修飾過的類表示類不能被繼承) 類中的字段、方法是否與父類產生矛盾。(被final修飾過的方法或字段是不能覆蓋的) (3)字節碼驗證 主要的目的是通過對數據流和控制流的分析,確定程序語義是合法的、符合邏輯的。(4)符號引用驗證:符號引用以一組符號來描述所引用的目標,符號可以是任何形式的字面量
比如:int i = 3;字面量:3符號引用:i
3.準備

為類變量分配內存并設置類變量初始值
-
static變量,分配空間在準備階段完成(設置默認值),賦值在初始化階段完成
-
static變量是final的基本類型,以及字符串常量,值已確定,賦值在準備階段完成
-
static變量是final的引用類型,那么賦值也會在初始化階段完成

4.解析

把類中的符號引用轉換為直接引用
比如:方法中調用了其他方法,方法名可以理解為符號引用,而直接引用就是使用指針直接指向方法。
5.初始化

對類的靜態變量,靜態代碼塊執行初始化操作
-
如果初始化一個類的時候,其父類尚未初始化,則優先初始化其父類。
-
如果同時包含多個靜態變量和靜態代碼塊,則按照自上而下的順序依次執行。
6.使用

JVM 開始從入口方法開始執行用戶的程序代碼
-
調用靜態類成員信息(比如:靜態字段、靜態方法)
-
使用new關鍵字為其創建對象實例
7.卸載
當用戶程序代碼執行完畢后,JVM 便開始銷毀創建的 Class 對象,最后負責運行的 JVM 也退出內存
3 垃圾收回
3.1 簡述Java垃圾回收機制?(GC是什么?為什么要GC)
難易程度:☆☆☆
出現頻率:☆☆☆
為了讓程序員更專注于代碼的實現,而不用過多的考慮內存釋放的問題,所以,在Java語言中,有了自動的垃圾回收機制,也就是我們熟悉的GC(Garbage Collection)。
有了垃圾回收機制后,程序員只需要關心內存的申請即可,內存的釋放由系統自動識別完成。
在進行垃圾回收時,不同的對象引用類型,GC會采用不同的回收時機
換句話說,自動的垃圾回收的算法就會變得非常重要了,如果因為算法的不合理,導致內存資源一直沒有釋放,同樣也可能會導致內存溢出的。
當然,除了Java語言,C#、Python等語言也都有自動的垃圾回收機制。
3.2 對象什么時候可以被垃圾器回收
難易程度:☆☆☆☆
出現頻率:☆☆☆☆
簡單一句就是:如果一個或多個對象沒有任何的引用指向它了,那么這個對象現在就是垃圾,如果定位了垃圾,則有可能會被垃圾回收器回收。
如果要定位什么是垃圾,有兩種方式來確定,第一個是引用計數法,第二個是可達性分析算法
3.2.1 引用計數法
一個對象被引用了一次,在當前的對象頭上遞增一次引用次數,如果這個對象的引用次數為0,代表這個對象可回收
String demo = new String("123");String demo = null;
當對象間出現了循環引用的話,則引用計數法就會失效

先執行右側代碼的前4行代碼
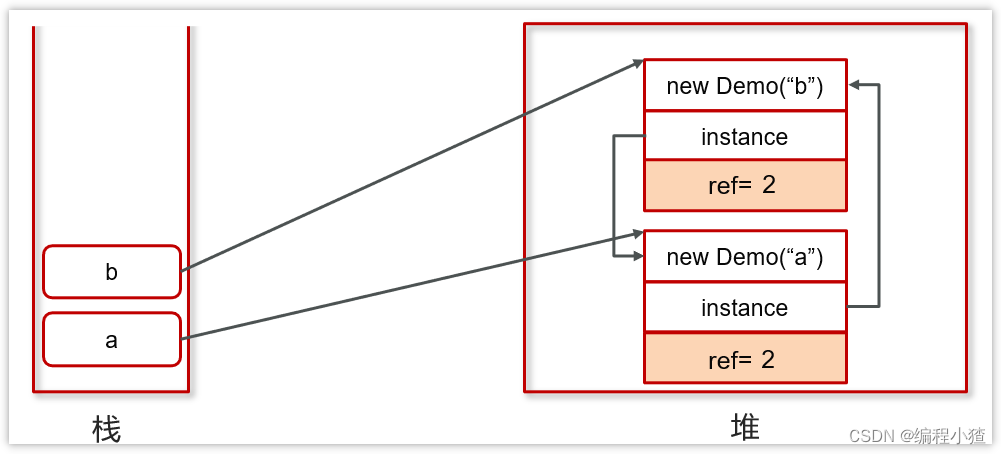
目前上方的引用關系和計數都是沒問題的,但是,如果代碼繼續往下執行,如下圖

雖然a和b都為null,但是由于a和b存在循環引用,這樣a和b永遠都不會被回收。
優點:
-
實時性較高,無需等到內存不夠的時候,才開始回收,運行時根據對象的計數器是否為0,就可以直接回收。
-
在垃圾回收過程中,應用無需掛起。如果申請內存時,內存不足,則立刻報OOM錯誤。
-
區域性,更新對象的計數器時,只是影響到該對象,不會掃描全部對象。
缺點:
-
每次對象被引用時,都需要去更新計數器,有一點時間開銷。
-
浪費CPU資源,即使內存夠用,仍然在運行時進行計數器的統計。
-
無法解決循環引用問題,會引發內存泄露。(最大的缺點)
3.2.2 可達性分析算法
? 現在的虛擬機采用的都是通過可達性分析算法來確定哪些內容是垃圾。
? 會存在一個根節點【GC Roots】,引出它下面指向的下一個節點,再以下一個節點節點開始找出它下面的節點,依次往下類推。直到所有的節點全部遍歷完畢。
根對象是那些肯定不能當做垃圾回收的對象,就可以當做根對象
局部變量,靜態方法,靜態變量,類信息
核心是:判斷某對象是否與根對象有直接或間接的引用,如果沒有被引用,則可以當做垃圾回收
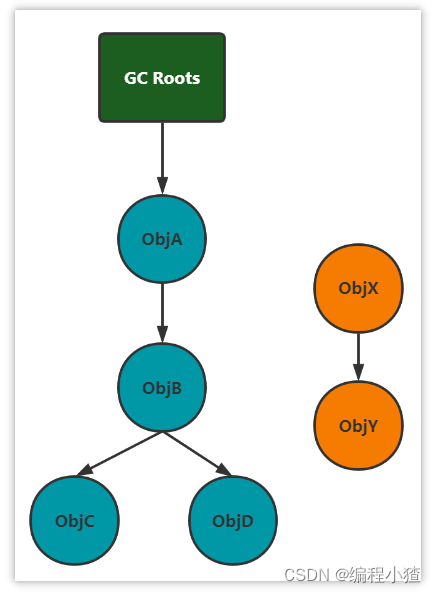
? X,Y這兩個節點是可回收的,但是并不會馬上的被回收!! 對象中存在一個方法【finalize】。當對象被標記為可回收后,當發生GC時,首先會判斷這個對象是否執行了finalize方法,如果這個方法還沒有被執行的話,那么就會先來執行這個方法,接著在這個方法執行中,可以設置當前這個對象與GC ROOTS產生關聯,那么這個方法執行完成之后,GC會再次判斷對象是否可達,如果仍然不可達,則會進行回收,如果可達了,則不會進行回收。
? finalize方法對于每一個對象來說,只會執行一次。如果第一次執行這個方法的時候,設置了當前對象與RC ROOTS關聯,那么這一次不會進行回收。 那么等到這個對象第二次被標記為可回收時,那么該對象的finalize方法就不會再次執行了。
GC ROOTS:
-
虛擬機棧(棧幀中的本地變量表)中引用的對象
/*** demo是棧幀中的本地變量,當 demo = null 時,由于此時 demo 充當了 GC Root 的作用,demo與原來指向的實例 new Demo() 斷開了連接,對象被回收。*/
public class Demo {public static ?void main(String[] args) {Demo demo = new Demo();demo = null;}
}-
方法區中類靜態屬性引用的對象
/*** 當棧幀中的本地變量 b = null 時,由于 b 原來指向的對象與 GC Root (變量 b) 斷開了連接,所以 b 原來指向的對象會被回收,而由于我們給 a 賦值了變量的引用,a在此時是類靜態屬性引用,充當了 GC Root 的作用,它指向的對象依然存活!*/
public class Demo {public static Demo a;public static ?void main(String[] args) {Demo b = new Demo();b.a = new Demo();b = null;}
}-
方法區中常量引用的對象
/*** 常量 a 指向的對象并不會因為 demo 指向的對象被回收而回收*/
public class Demo {public static final Demo a = new Demo();public static ?void main(String[] args) {Demo demo = new Demo();demo = null;}
}-
本地方法棧中 JNI(即一般說的 Native 方法)引用的對象
3.3 JVM 垃圾回收算法有哪些?
難易程度:☆☆☆
出現頻率:☆☆☆☆
3.3.1 標記清除算法
標記清除算法,是將垃圾回收分為2個階段,分別是標記和清除。
1.根據可達性分析算法得出的垃圾進行標記
2.對這些標記為可回收的內容進行垃圾回收
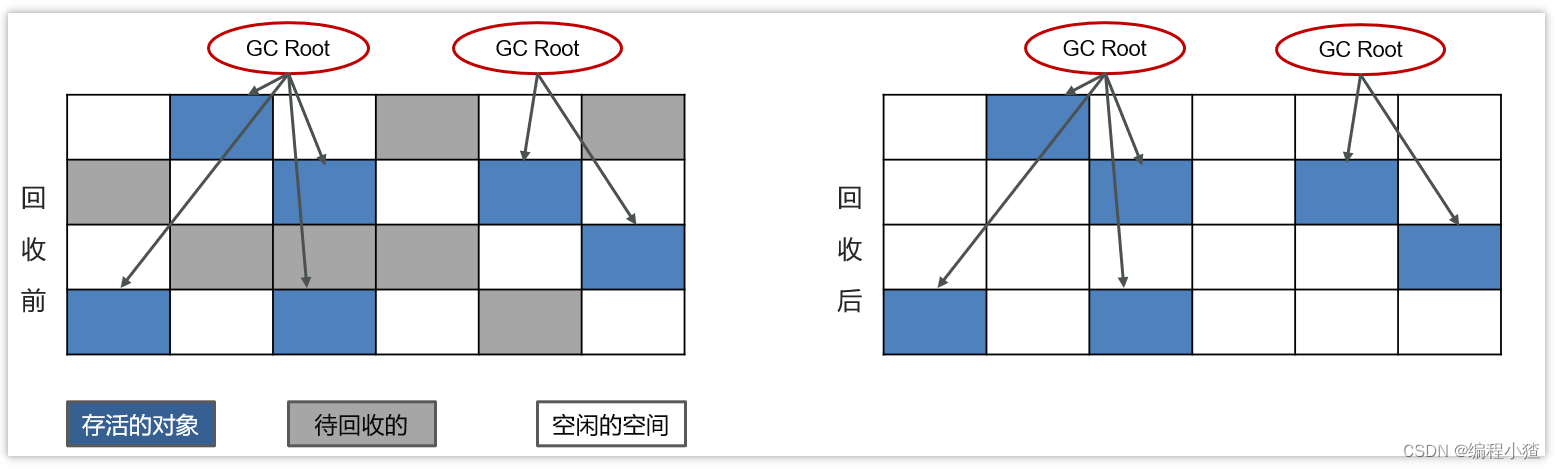
可以看到,標記清除算法解決了引用計數算法中的循環引用的問題,沒有從root節點引用的對象都會被回收。
同樣,標記清除算法也是有缺點的:
-
效率較低,標記和清除兩個動作都需要遍歷所有的對象,并且在GC時,需要停止應用程序,對于交互性要求比較高的應用而言這個體驗是非常差的。
-
(重要)通過標記清除算法清理出來的內存,碎片化較為嚴重,因為被回收的對象可能存在于內存的各個角落,所以清理出來的內存是不連貫的。因此對存儲數組是非常不友好的。
3.3.2 復制算法
? 復制算法的核心就是,將原有的內存空間一分為二,每次只用其中的一塊,在垃圾回收時,將正在使用的對象復制到另一個內存空間中,然后將該內存空間清空,交換兩個內存的角色,完成垃圾的回收。
? 如果內存中的垃圾對象較多,需要復制的對象就較少,這種情況下適合使用該方式并且效率比較高,反之,則不適合。
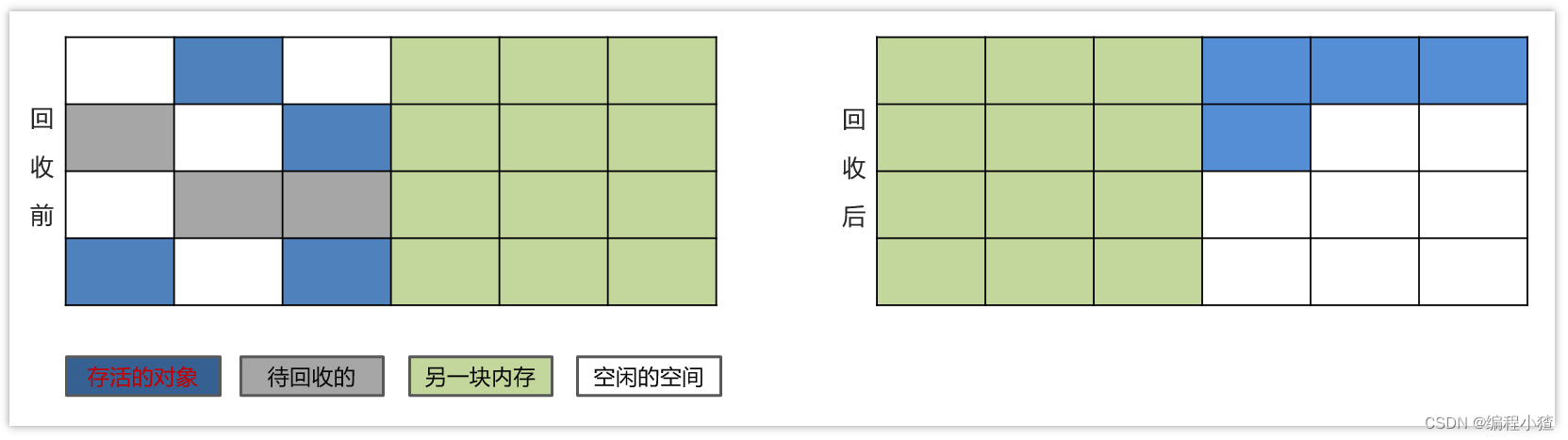
1)將內存區域分成兩部分,每次操作其中一個。
2)當進行垃圾回收時,將正在使用的內存區域中的存活對象移動到未使用的內存區域。當移動完對這部分內存區域一次性清除。
3)周而復始。
優點:
-
在垃圾對象多的情況下,效率較高
-
清理后,內存無碎片
缺點:
-
分配的2塊內存空間,在同一個時刻,只能使用一半,內存使用率較低
3.3.3 標記整理算法
? 標記壓縮算法是在標記清除算法的基礎之上,做了優化改進的算法。和標記清除算法一樣,也是從根節點開始,對對象的引用進行標記,在清理階段,并不是簡單的直接清理可回收對象,而是將存活對象都向內存另一端移動,然后清理邊界以外的垃圾,從而解決了碎片化的問題。
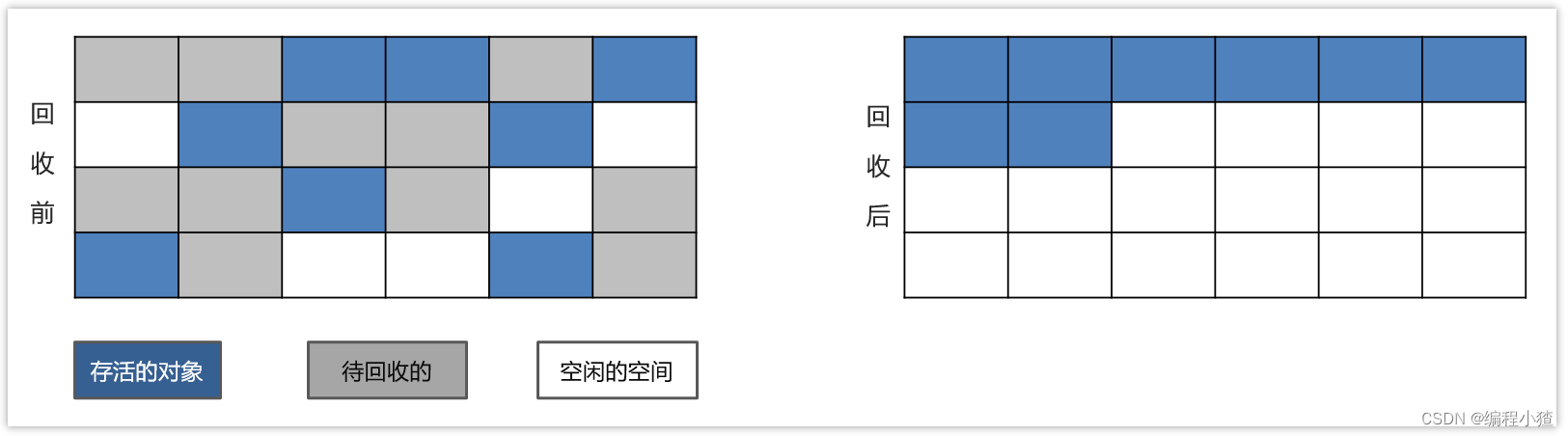
1)標記垃圾。
2)需要清除向右邊走,不需要清除的向左邊走。
3)清除邊界以外的垃圾。
優缺點同標記清除算法,解決了標記清除算法的碎片化的問題,同時,標記壓縮算法多了一步,對象移動內存位置的步驟,其效率也有有一定的影響。通常堆中的老年代區域會采用該算法。
與復制算法對比:復制算法標記完就復制,但標記整理算法得等把所有存活對象都標記完畢,再進行整理
3.4 分代收集算法
3.4.1 概述
在java8時,堆被分為了兩份:新生代和老年代【1:2】,在java7時,還存在一個永久代。
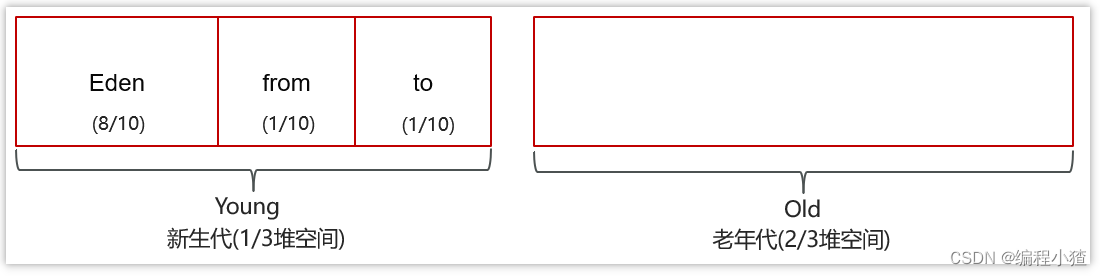
對于新生代,內部又被分為了三個區域。Eden區,S0區,S1區【8:1:1】
當對新生代產生GC:MinorGC【young GC】
當對老年代代產生GC:Major GC
當對新生代和老年代產生FullGC: 新生代 + 老年代完整垃圾回收,暫停時間長,應盡力避免
3.4.2工作機制

-
新創建的對象,都會先分配到eden區

-
當伊甸園內存不足,標記伊甸園與 from(現階段沒有)的存活對象
-
將存活對象采用復制算法復制到 to 中,復制完畢后,伊甸園和 from 內存都得到釋放

-
經過一段時間后伊甸園的內存又出現不足,標記eden區域to區存活的對象,將存活的對象復制到from區


-
當幸存區對象熬過幾次回收(最多15次),晉升到老年代(幸存區內存不足或大對象會導致提前晉升)
MinorGC、 Mixed GC 、 FullGC的區別是什么
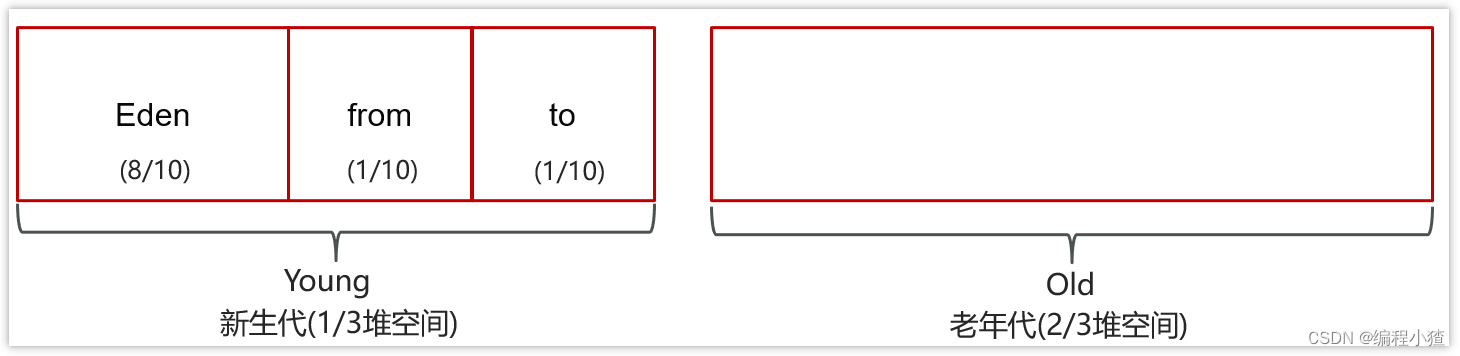
-
MinorGC【young GC】發生在新生代的垃圾回收,暫停時間短(STW)
-
Mixed GC 新生代 + 老年代部分區域的垃圾回收,G1 收集器特有
-
FullGC: 新生代 + 老年代完整垃圾回收,暫停時間長(STW),應盡力避免?
名詞解釋:
STW(Stop-The-World):暫停所有應用程序線程,等待垃圾回收的完成
3.5 說一下 JVM 有哪些垃圾回收器?
難易程度:☆☆☆☆
出現頻率:☆☆☆☆
在jvm中,實現了多種垃圾收集器,包括:
-
串行垃圾收集器
-
并行垃圾收集器
-
CMS(并發)垃圾收集器
-
G1垃圾收集器
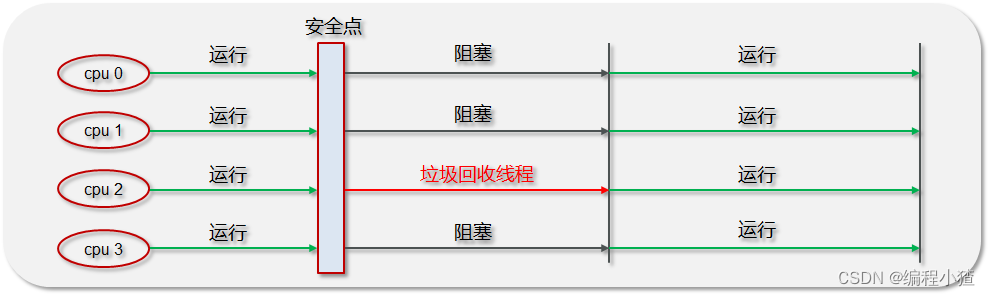
3.5.1 串行垃圾收集器
Serial和Serial Old串行垃圾收集器,是指使用單線程進行垃圾回收,堆內存較小,適合個人電腦
-
Serial 作用于新生代,采用復制算法
-
Serial Old 作用于老年代,采用標記-整理算法
垃圾回收時,只有一個線程在工作,并且java應用中的所有線程都要暫停(STW),等待垃圾回收的完成。
3.5.2 并行垃圾收集器
Parallel New和Parallel Old是一個并行垃圾回收器,JDK8默認使用此垃圾回收器
-
Parallel New作用于新生代,采用復制算法
-
Parallel Old作用于老年代,采用標記-整理算法
垃圾回收時,多個線程在工作,并且java應用中的所有線程都要暫停(STW),等待垃圾回收的完成。

3.5.2 CMS(并發)垃圾收集器
CMS全稱 Concurrent Mark Sweep,是一款并發的、使用標記-清除算法的垃圾回收器,該回收器是針對老年代垃圾回收的,是一款以獲取最短回收停頓時間為目標的收集器,停頓時間短,用戶體驗就好。其最大特點是在進行垃圾回收時,應用仍然能正常運行。
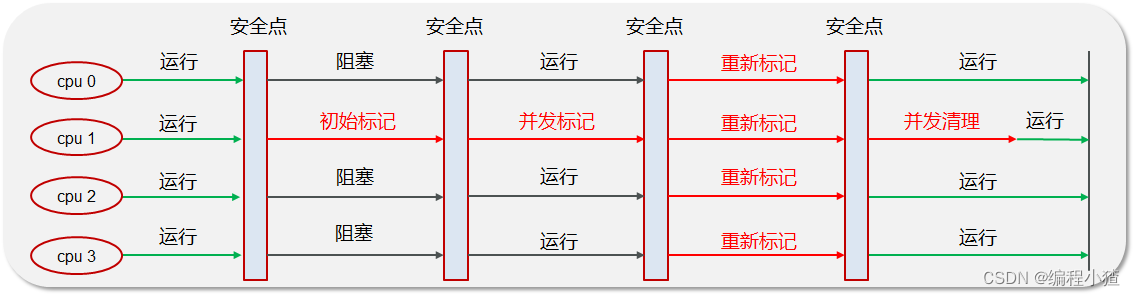

3.6 詳細聊一下G1垃圾回收器
難易程度:☆☆☆☆
出現頻率:☆☆☆☆
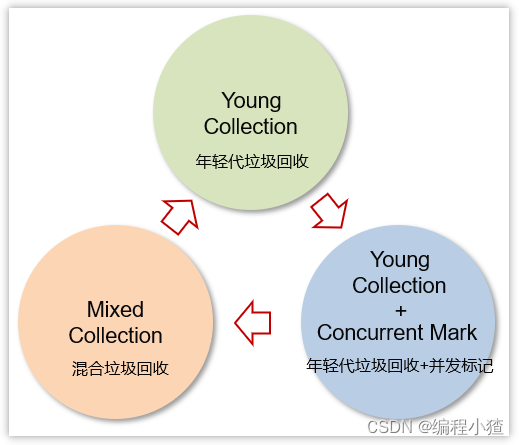
3.6.1 概述
-
應用于新生代和老年代,在**JDK9之后默認使用G1**
-
劃分成多個區域,每個區域都可以充當 eden,survivor,old, humongous,其中 humongous 專為大對象準備
-
采用復制算法
-
響應時間與吞吐量兼顧
-
分成三個階段:新生代回收、并發標記、混合收集
-
如果并發失敗(即回收速度趕不上創建新對象速度),會觸發 Full GC
3.6.2 Young Collection(年輕代垃圾回收)
-
初始時,所有區域都處于空閑狀態

-
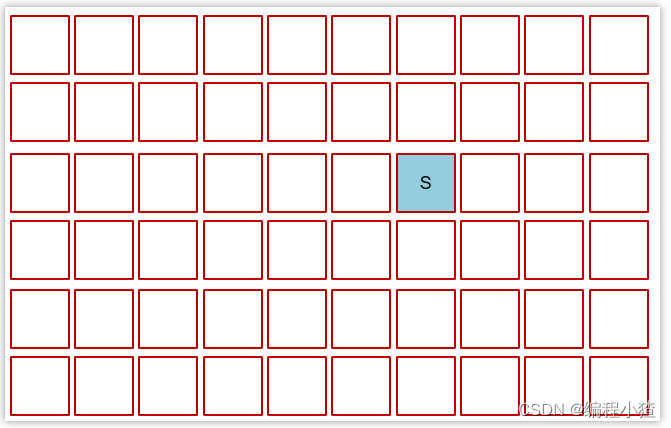
創建了一些對象,挑出一些空閑區域作為伊甸園區存儲這些對象
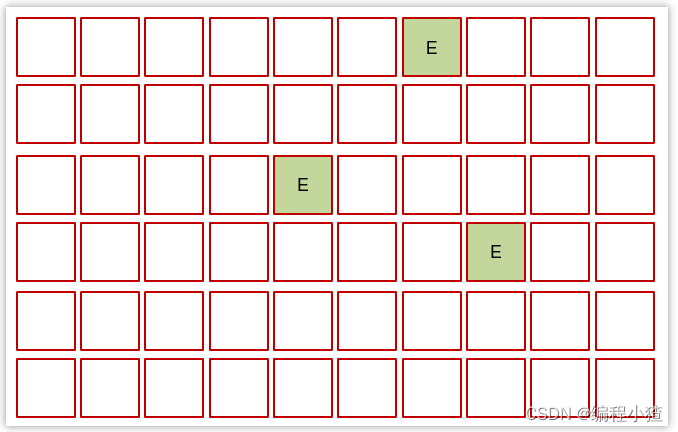
-
當伊甸園需要垃圾回收時,挑出一個空閑區域作為幸存區,用復制算法復制存活對象,需要暫停用戶線程
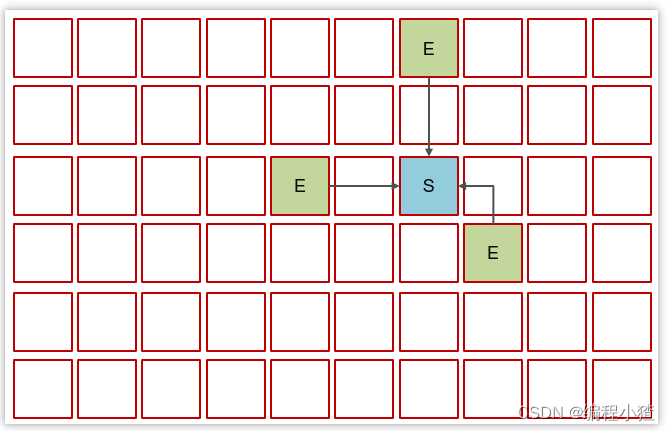
-
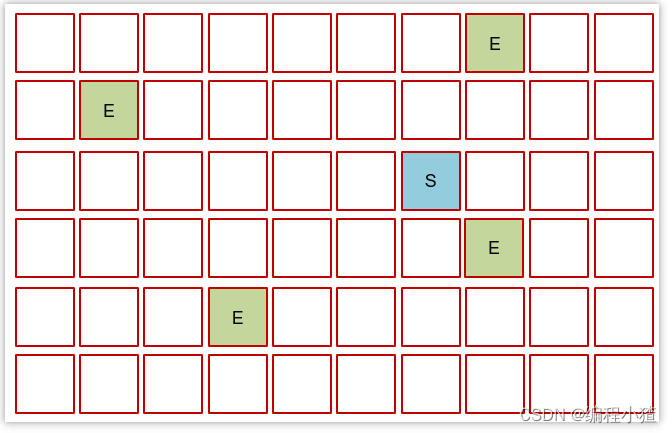
隨著時間流逝,伊甸園的內存又有不足
-
將伊甸園以及之前幸存區中的存活對象,采用復制算法,復制到新的幸存區,其中較老對象晉升至老年代
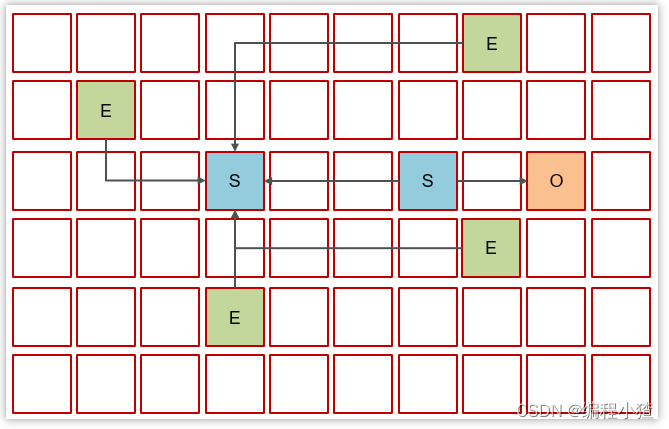
3.6.3 Young Collection + Concurrent Mark (年輕代垃圾回收+并發標記)
當老年代占用內存超過閾值(默認是45%)后,觸發并發標記,這時無需暫停用戶線程
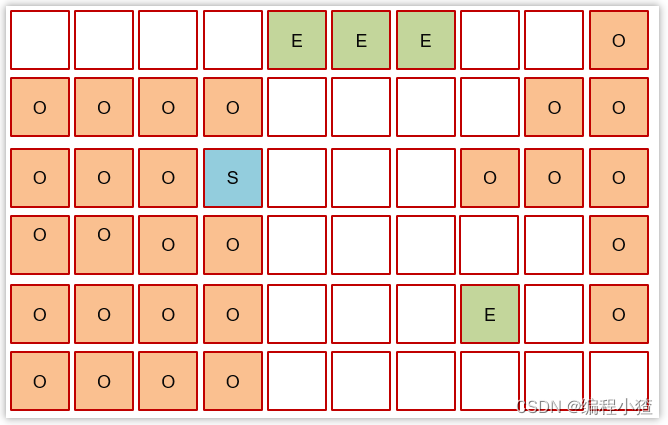
-
并發標記之后,會有重新標記階段解決漏標問題,此時需要暫停用戶線程。
-
這些都完成后就知道了老年代有哪些存活對象,隨后進入混合收集階段。此時不會對所有老年代區域進行回收,而是根據暫停時間目標優先回收價值高(存活對象少)的區域(這也是 Gabage First 名稱的由來)。
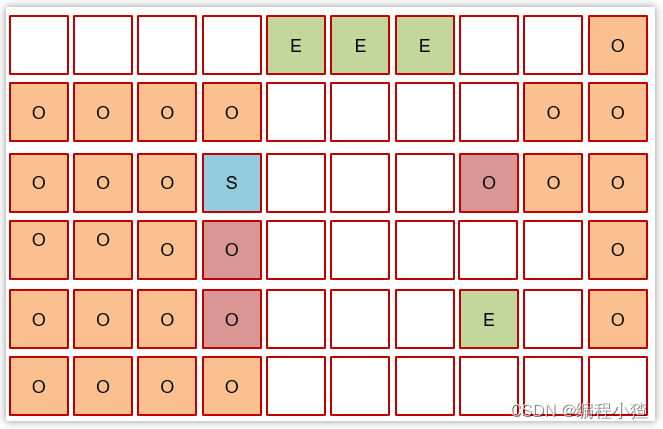
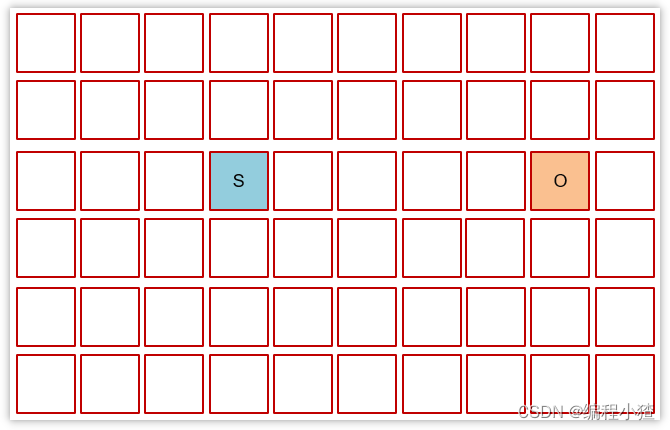
3.6.4 Mixed Collection (混合垃圾回收)
復制完成,內存得到釋放。進入下一輪的新生代回收、并發標記、混合收集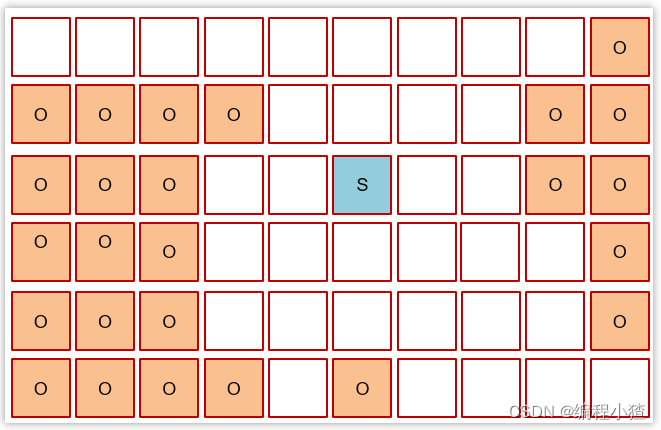
其中H叫做巨型對象,如果對象非常大,會開辟一塊連續的空間存儲巨型對象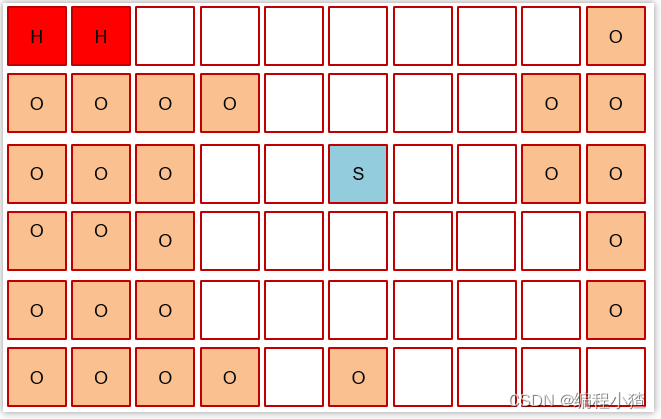
3.7 強引用、軟引用、弱引用、虛引用的區別?
難易程度:☆☆☆☆
出現頻率:☆☆☆
3.7.1 強引用
強引用:只有所有 GC Roots 對象都不通過【強引用】引用該對象,該對象才能被垃圾回收
User user = new User();
3.7.2 軟引用
軟引用:僅有軟引用引用該對象時,在垃圾回收后,內存仍不足時會再次出發垃圾回收
User user = new User();
SoftReference softReference = new SoftReference(user);
3.7.3 弱引用
弱引用:僅有弱引用引用該對象時,在垃圾回收時,無論內存是否充足,都會回收弱引用對象
User user = new User();
WeakReference weakReference = new WeakReference(user);
延伸話題:ThreadLocal內存泄漏問題
ThreadLocal用的就是弱引用,看以下源碼:
static class Entry extends WeakReference<ThreadLocal<?>> {Object value;
?Entry(ThreadLocal<?> k, Object v) {super(k);value = v; //強引用,不會被回收}
}Entry的key是當前ThreadLocal,value值是我們要設置的數據。
WeakReference表示的是弱引用,當JVM進行GC時,一旦發現了只具有弱引用的對象,不管當前內存空間是否足夠,都會回收它的內存。但是value是強引用,它不會被回收掉。
ThreadLocal使用建議:使用完畢后注意調用清理方法。
3.7.4 虛引用
虛引用:必須配合引用隊列使用,被引用對象回收時,會將虛引用入隊,由 Reference Handler 線程調用虛引用相關方法釋放直接內存

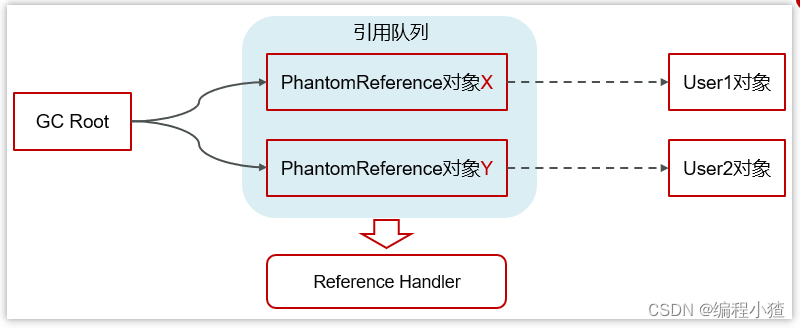
4 JVM實踐(調優)
4.1 JVM 調優的參數可以在哪里設置參數值?
難易程度:☆☆
出現頻率:☆☆☆
4.1.1 tomcat的設置vm參數
修改TOMCAT_HOME/bin/catalina.sh文件,如下圖
JAVA_OPTS="-Xms512m -Xmx1024m"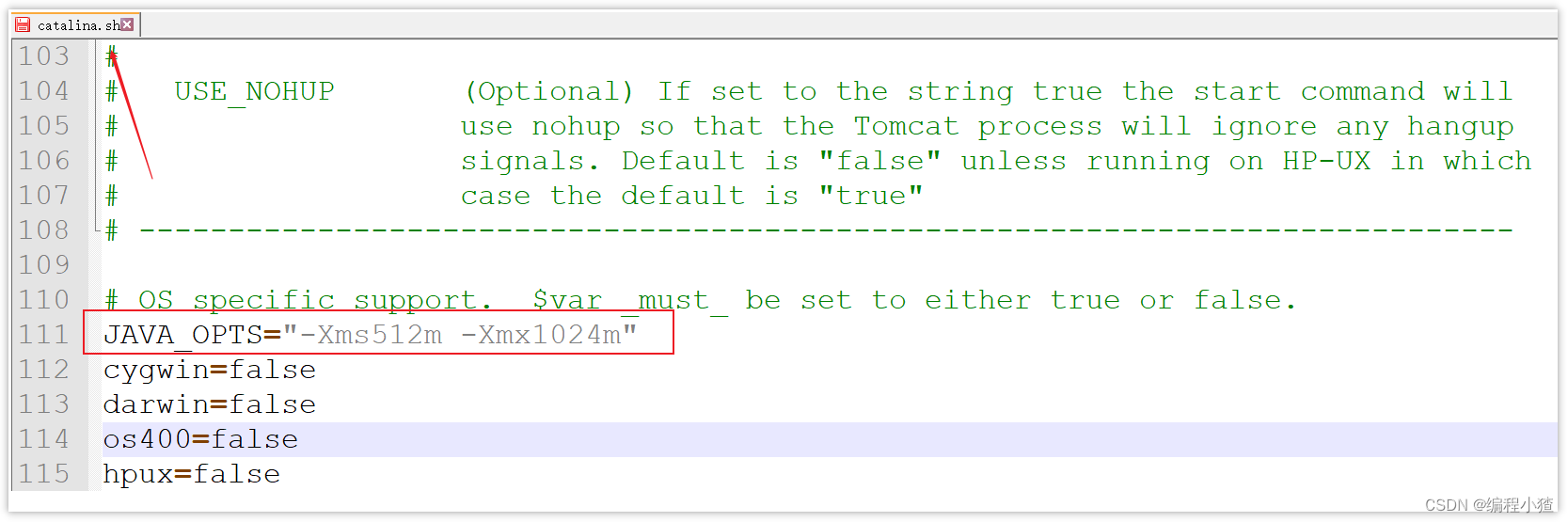
4.1.2 springboot項目jar文件啟動
通常在linux系統下直接加參數啟動springboot項目
nohup java -Xms512m -Xmx1024m -jar xxxx.jar --spring.profiles.active=prod &nohup : 用于在系統后臺不掛斷地運行命令,退出終端不會影響程序的運行
參數 & :讓命令在后臺執行,終端退出后命令仍舊執行。
4.2 用的 JVM 調優的參數都有哪些?
難易程度:☆☆☆
出現頻率:☆☆☆☆
? 對于JVM調優,主要就是調整年輕代、年老大、元空間的內存空間大小及使用的垃圾回收器類型。
Java HotSpot VM Options
1)設置堆的初始大小和最大大小,為了防止垃圾收集器在初始大小、最大大小之間收縮堆而產生額外的時間,通常把最大、初始大小設置為相同的值。
-Xms:設置堆的初始化大小 ? -Xmx:設置堆的最大大小
2) 設置年輕代中Eden區和兩個Survivor區的大小比例。該值如果不設置,則默認比例為8:1:1。Java官方通過增大Eden區的大小,來減少YGC發生的次數,但有時我們發現,雖然次數減少了,但Eden區滿
的時候,由于占用的空間較大,導致釋放緩慢,此時STW的時間較長,因此需要按照程序情況去調優。
-XXSurvivorRatio=3,表示年輕代中的分配比率:survivor:eden = 2:3
3)年輕代和老年代默認比例為1:2。可以通過調整二者空間大小比率來設置兩者的大小。
-XX:newSize ? 設置年輕代的初始大小 -XX:MaxNewSize ? 設置年輕代的最大大小, 初始大小和最大大小兩個值通常相同
4)線程堆棧的設置:每個線程默認會開啟1M的堆棧,用于存放棧幀、調用參數、局部變量等,但一般256K就夠用。通常減少每個線程的堆棧,可以產生更多的線程,但這實際上還受限于操作系統。
-Xss ? 對每個線程stack大小的調整,-Xss128k
5)一般來說,當survivor區不夠大或者占用量達到50%,就會把一些對象放到老年區。通過設置合理的eden區,survivor區及使用率,可以將年輕對象保存在年輕代,從而避免full GC,使用-Xmn設置年輕代的大小
6)系統CPU持續飆高的話,首先先排查代碼問題,如果代碼沒問題,則咨詢運維或者云服務器供應商,通常服務器重啟或者服務器遷移即可解決。
7)對于占用內存比較多的大對象,一般會選擇在老年代分配內存。如果在年輕代給大對象分配內存,年輕代內存不夠了,就要在eden區移動大量對象到老年代,然后這些移動的對象可能很快消亡,因此導致full GC。通過設置參數:-XX:PetenureSizeThreshold=1000000,單位為B,標明對象大小超過1M時,在老年代(tenured)分配內存空間。
8)一般情況下,年輕對象放在eden區,當第一次GC后,如果對象還存活,放到survivor區,此后,每GC一次,年齡增加1,當對象的年齡達到閾值,就被放到tenured老年區。這個閾值可以同構-XX:MaxTenuringThreshold設置。如果想讓對象留在年輕代,可以設置比較大的閾值。
(1)-XX:+UseParallelGC:年輕代使用并行垃圾回收收集器。這是一個關注吞吐量的收集器,可以盡可能的減少垃圾回收時間。 ? (2)-XX:+UseParallelOldGC:設置老年代使用并行垃圾回收收集器。
9)嘗試使用大的內存分頁:使用大的內存分頁增加CPU的內存尋址能力,從而系統的性能。
-XX:+LargePageSizeInBytes 設置內存頁的大小
10)使用非占用的垃圾收集器。
-XX:+UseConcMarkSweepGC老年代使用CMS收集器降低停頓。
4.3 說一下 JVM 調優的工具?
難易程度:☆☆☆☆
出現頻率:☆☆☆☆
4.3.1 命令工具
4.3.1.1 jps(Java Process Status)
輸出JVM中運行的進程狀態信息(現在一般使用jconsole)
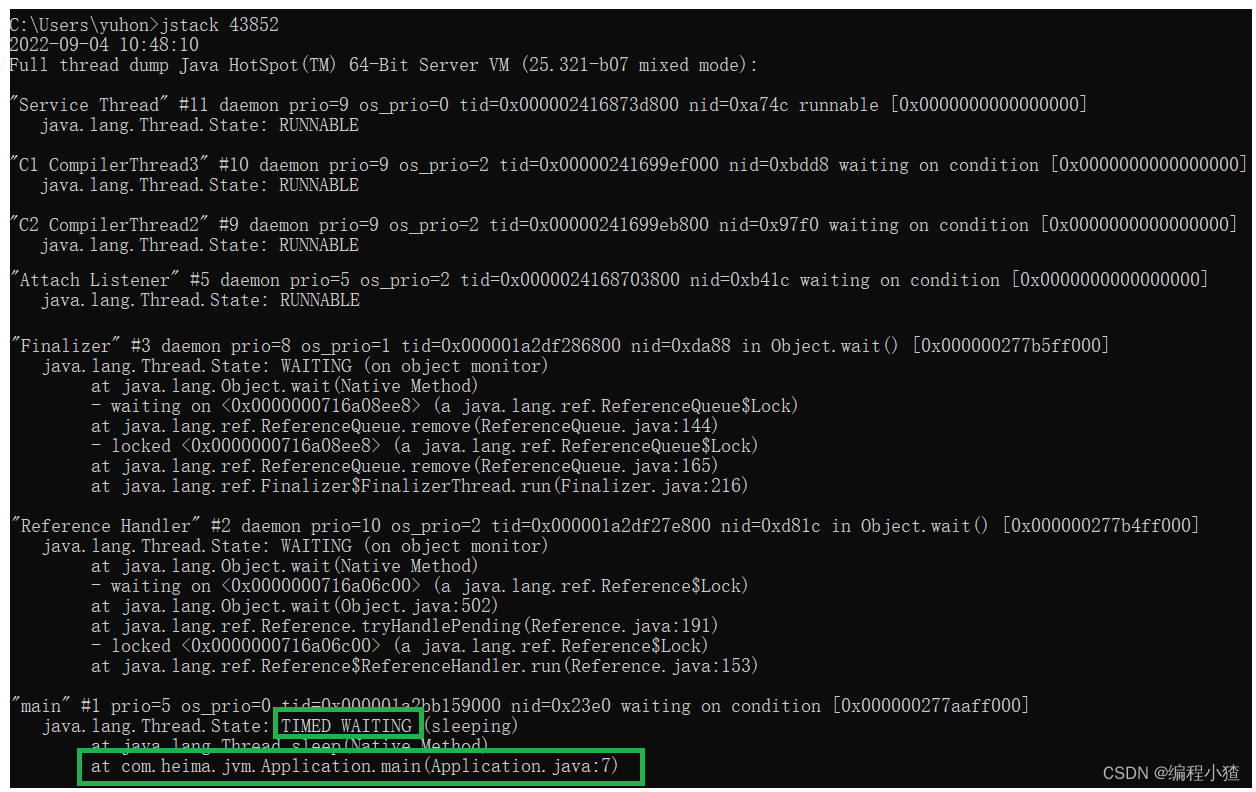
4.3.1.2 jstack
查看java進程內線程的堆棧信息。
jstack [option] <pid> ?
java案例
package com.kjz.jvm;
?
public class Application {
?public static void main(String[] args) throws InterruptedException {while (true){Thread.sleep(1000);System.out.println("哈哈哈");}}
}使用jstack查看進行堆棧運行信息
4.3.1.3 jmap
用于生成堆轉存快照
jmap [options] pid 內存映像信息
jmap -heap pid 顯示Java堆的信息
jmap -dump:format=b,file=heap.hprof pid
? format=b表示以hprof二進制格式轉儲Java堆的內存? file=<filename>用于指定快照dump文件的文件名。
例:顯示了某一個java運行的堆信息
C:\Users\yuhon>jmap -heap 53280
Attaching to process ID 53280, please wait...
Debugger attached successfully.
Server compiler detected.
JVM version is 25.321-b07
?
using thread-local object allocation.
Parallel GC with 8 thread(s) ? //并行的垃圾回收器
?
Heap Configuration: ?//堆配置MinHeapFreeRatio ? ? ? ? = 0 ? //空閑堆空間的最小百分比MaxHeapFreeRatio ? ? ? ? = 100 ?//空閑堆空間的最大百分比MaxHeapSize ? ? ? ? ? ? ?= 8524922880 (8130.0MB) //堆空間允許的最大值NewSize ? ? ? ? ? ? ? ? ?= 178257920 (170.0MB) //新生代堆空間的默認值MaxNewSize ? ? ? ? ? ? ? = 2841640960 (2710.0MB) //新生代堆空間允許的最大值OldSize ? ? ? ? ? ? ? ? ?= 356515840 (340.0MB) //老年代堆空間的默認值NewRatio ? ? ? ? ? ? ? ? = 2 //新生代與老年代的堆空間比值,表示新生代:老年代=1:2SurvivorRatio ? ? ? ? ? ?= 8 //兩個Survivor區和Eden區的堆空間比值為8,表示S0:S1:Eden=1:1:8MetaspaceSize ? ? ? ? ? ?= 21807104 (20.796875MB) //元空間的默認值CompressedClassSpaceSize = 1073741824 (1024.0MB) //壓縮類使用空間大小MaxMetaspaceSize ? ? ? ? = 17592186044415 MB //元空間允許的最大值G1HeapRegionSize ? ? ? ? = 0 (0.0MB)//在使用 G1 垃圾回收算法時,JVM 會將 Heap 空間分隔為若干個 Region,該參數用來指定每個 Region 空間的大小。
?
Heap Usage:
PS Young Generation
Eden Space: //Eden使用情況capacity = 134217728 (128.0MB)used ? ? = 10737496 (10.240074157714844MB)free ? ? = 123480232 (117.75992584228516MB)8.000057935714722% used
From Space: //Survivor-From 使用情況capacity = 22020096 (21.0MB)used ? ? = 0 (0.0MB)free ? ? = 22020096 (21.0MB)0.0% used
To Space: //Survivor-To 使用情況capacity = 22020096 (21.0MB)used ? ? = 0 (0.0MB)free ? ? = 22020096 (21.0MB)0.0% used
PS Old Generation ?//老年代 使用情況capacity = 356515840 (340.0MB)used ? ? = 0 (0.0MB)free ? ? = 356515840 (340.0MB)0.0% used
?
3185 interned Strings occupying 261264 bytes.4.3.1.4 jhat
用于分析jmap生成的堆轉存快照(一般不推薦使用,而是使用Ecplise Memory Analyzer)
4.3.1.5 jstat
是JVM統計監測工具。可以用來顯示垃圾回收信息、類加載信息、新生代統計信息等。
常見參數:
①總結垃圾回收統計
jstat -gcutil pid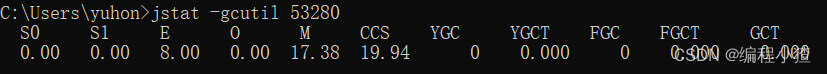
| 字段 | 含義 |
|---|---|
| S0 | 幸存1區當前使用比例 |
| S1 | 幸存2區當前使用比例 |
| E | 伊甸園區使用比例 |
| O | 老年代使用比例 |
| M | 元數據區使用比例 |
| CCS | 壓縮使用比例 |
| YGC | 年輕代垃圾回收次數 |
| YGCT | 年輕代垃圾回收消耗時間 |
| FGC | 老年代垃圾回收次數 |
| FGCT | 老年代垃圾回收消耗時間 |
| GCT | 垃圾回收消耗總時間 |
②垃圾回收統計
jstat -gc pid
4.3.2 可視化工具
4.3.2.1 jconsole
用于對jvm的內存,線程,類 的監控,是一個基于 jmx 的 GUI 性能監控工具
打開方式:java 安裝目錄 bin目錄下 直接啟動 jconsole.exe 就行
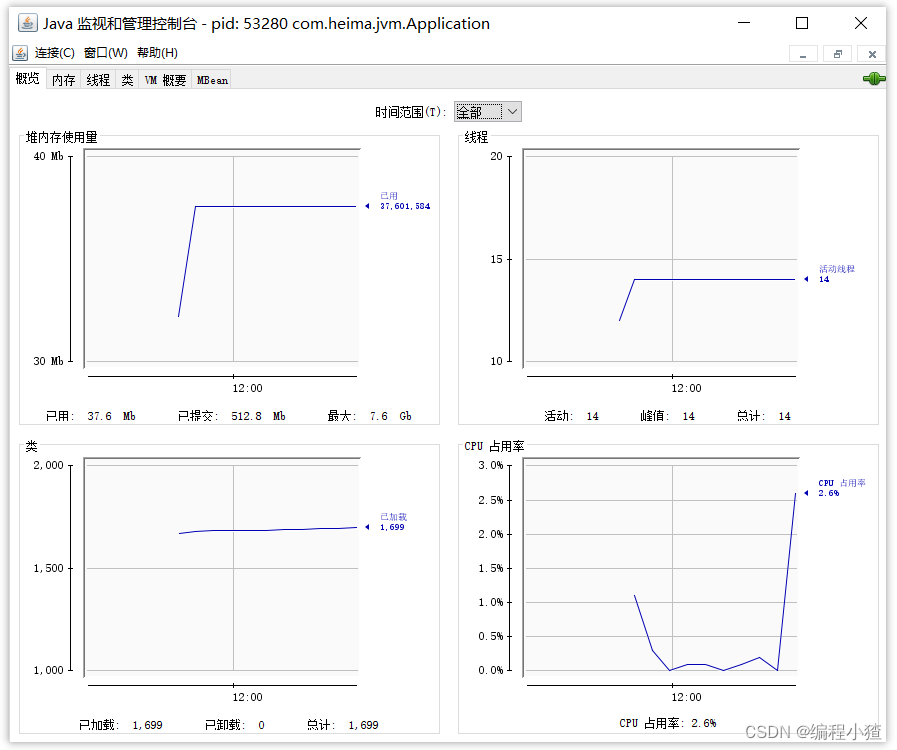
可以內存、線程、類等信息
4.3.2.2 VisualVM:故障處理工具
能夠監控線程,內存情況,查看方法的CPU時間和內存中的對 象,已被GC的對象,反向查看分配的堆棧
打開方式:java 安裝目錄 bin目錄下 直接啟動 jvisualvm.exe就行
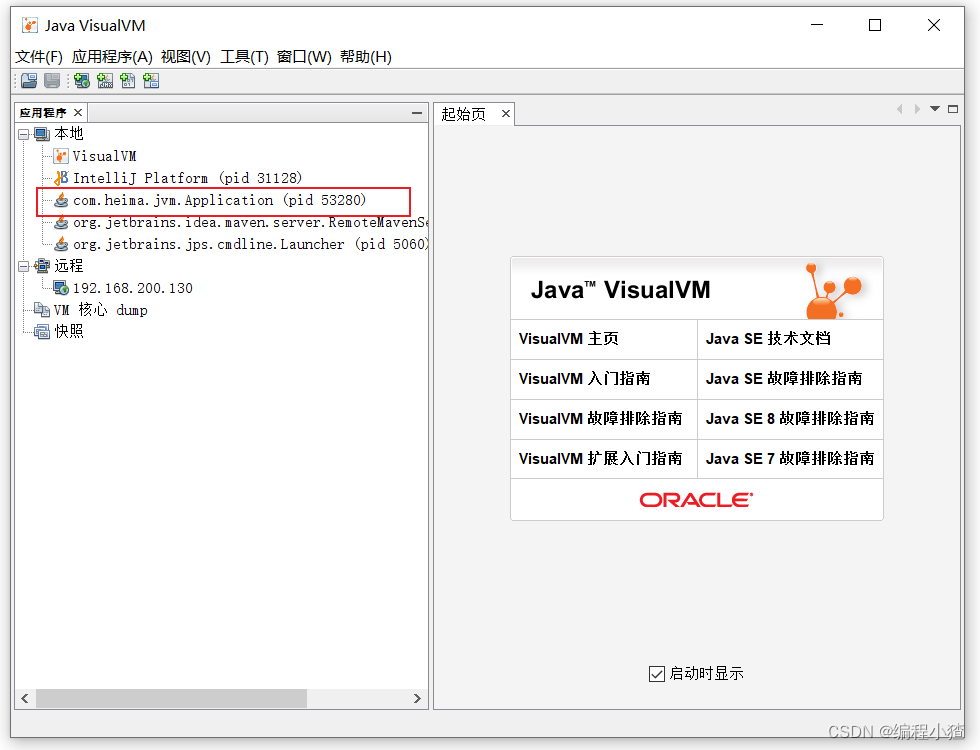
監控程序運行情況
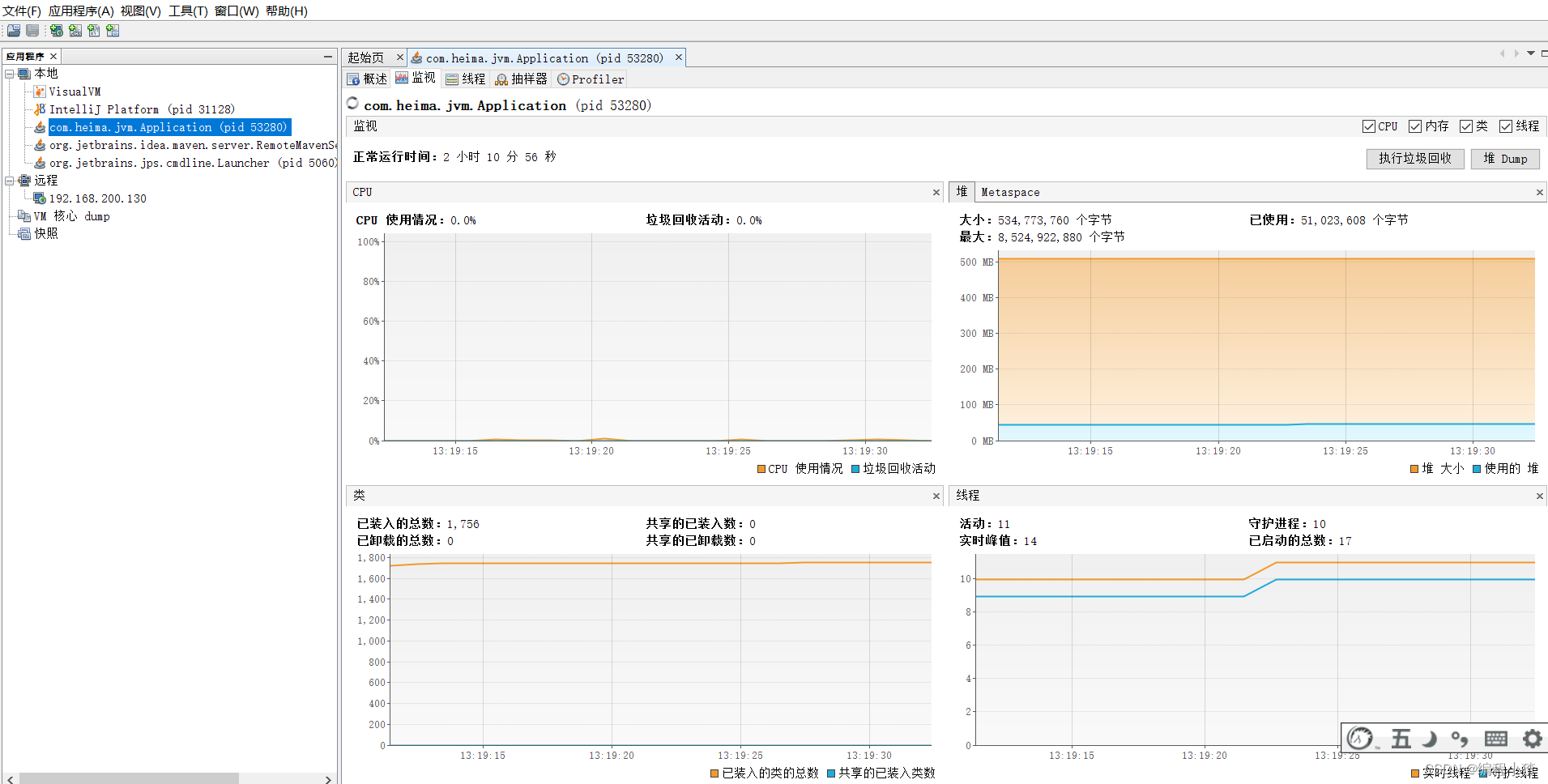
查看運行中的dump
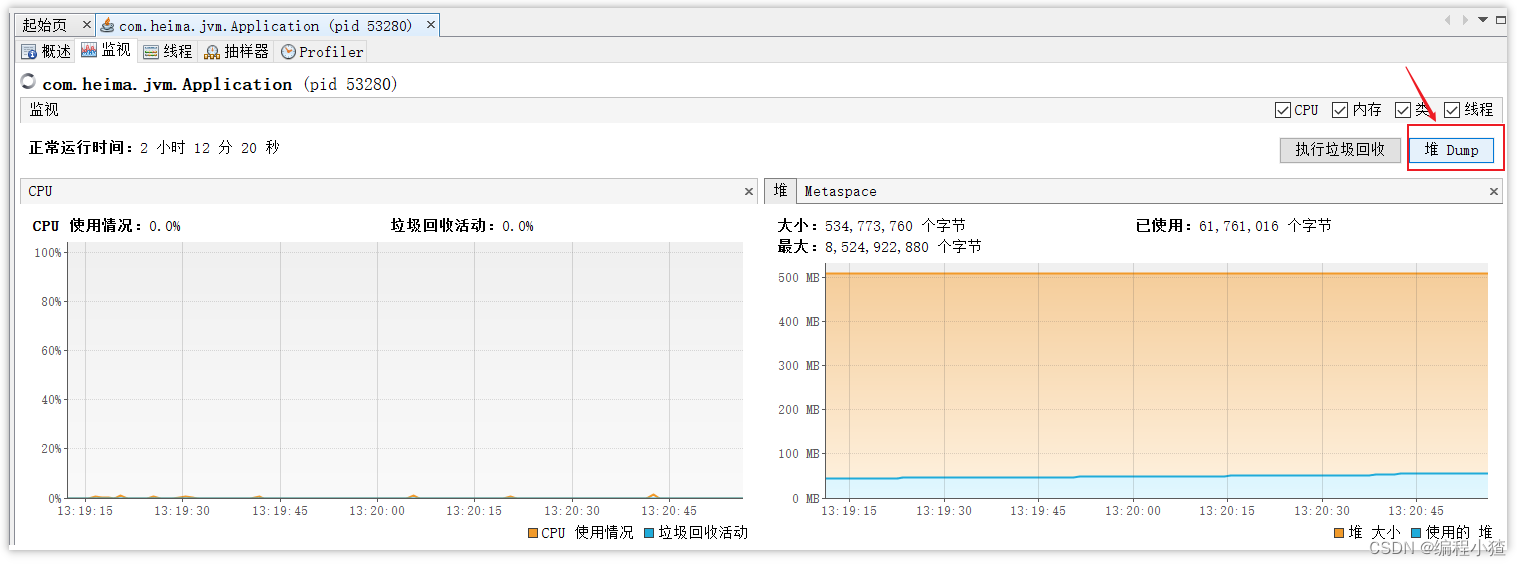
查看堆中的信息

4.4 java內存泄露的排查思路?
難易程度:☆☆☆☆
出現頻率:☆☆☆☆
原因:
如果線程請求分配的棧容量超過java虛擬機棧允許的最大容量的時候,java虛擬機將拋出一個StackOverFlowError異常
如果java虛擬機棧可以動態拓展,并且擴展的動作已經嘗試過,但是目前無法申請到足夠的內存去完成拓展,或者在建立新線程的時候沒有足夠的內存去創建對應的虛擬機棧,那java虛擬機將會拋出一個OutOfMemoryError異常
如果一次加載的類太多,元空間內存不足,則會報OutOfMemoryError: Metaspace
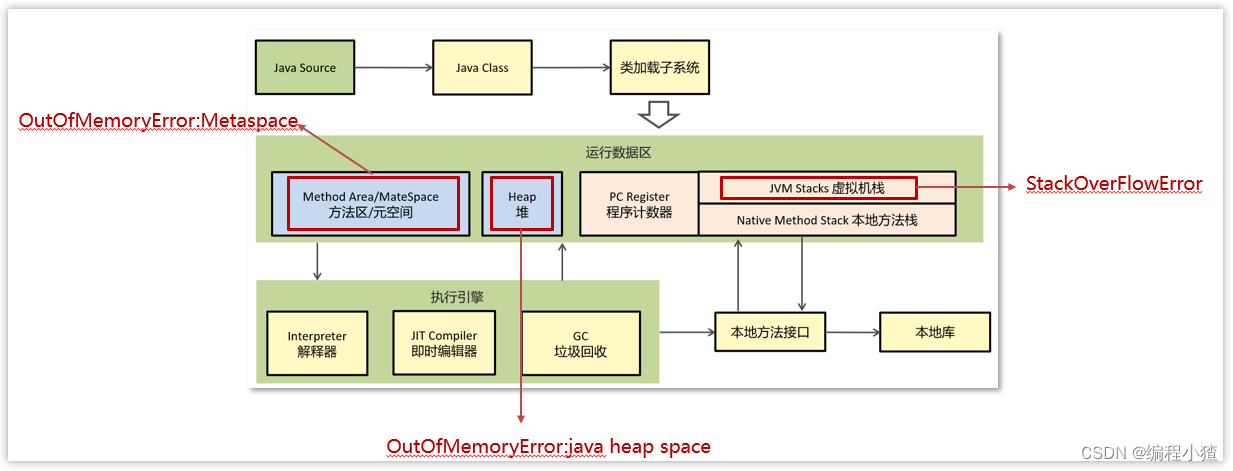
1、通過jmap指定打印他的內存快照 dump
有的情況是內存溢出之后程序則會直接中斷,而jmap只能打印在運行中的程序,所以建議通過參數的方式的生成dump文件,配置如下:
-XX:+HeapDumpOnOutOfMemoryError-XX:HeapDumpPath=/home/app/dumps/ 指定生成后文件的保存目錄
2、通過工具, VisualVM(Ecplise MAT)去分析 dump文件
VisualVM可以加載離線的dump文件,如下圖
文件-->裝入--->選擇dump文件即可查看堆快照信息
如果是linux系統中的程序,則需要把dump文件下載到本地(windows環境)下,打開VisualVM工具分析。VisualVM目前只支持在windows環境下運行可視化
3、通過查看堆信息的情況,可以大概定位內存溢出是哪行代碼出了問題
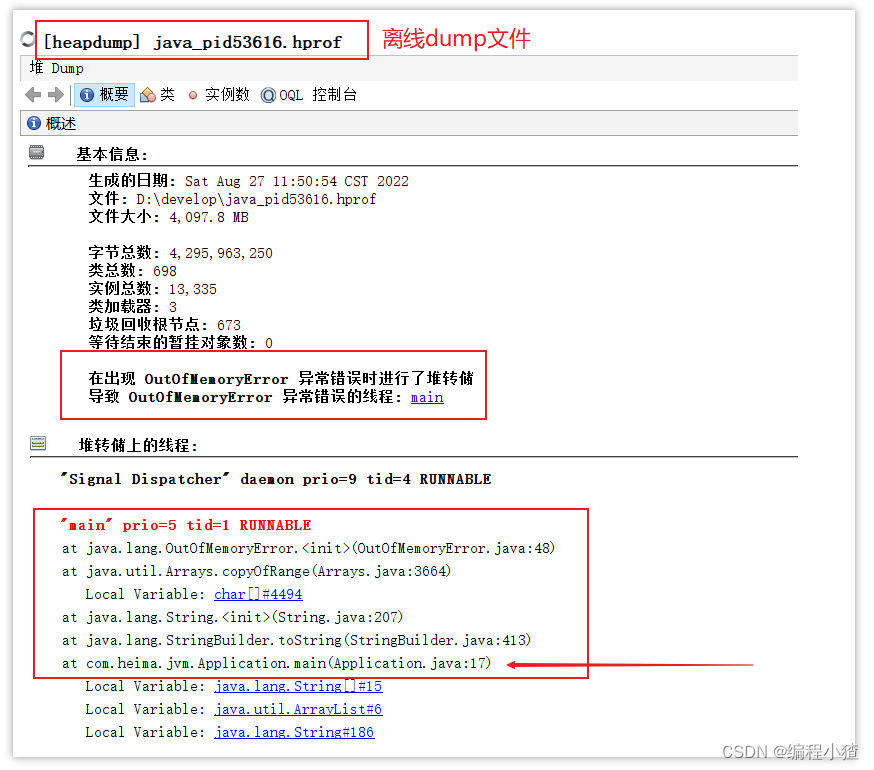
4、找到對應的代碼,通過閱讀上下文的情況,進行修復即可
4.5 CPU飆高排查方案與思路?
難易程度:☆☆☆☆
出現頻率:☆☆☆☆
1.使用top命令查看占用cpu的情況

2.通過top命令查看后,可以查看是哪一個進程占用cpu較高,上圖所示的進程為:30978
3.查看當前線程中的進程信息
ps H -eo pid,tid,%cpu | grep 40940pid 進行id
tid 進程中的線程id
% cpu使用率
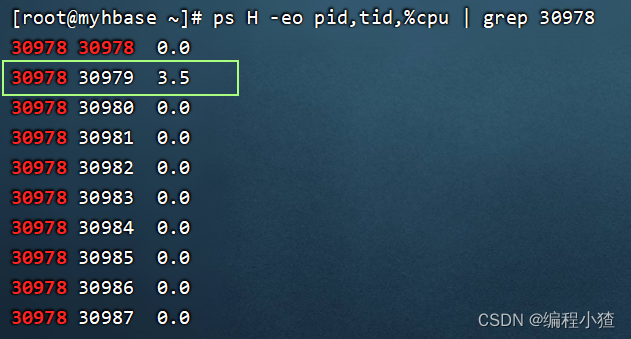
4.通過上圖分析,在進程30978中的線程30979占用cpu較高
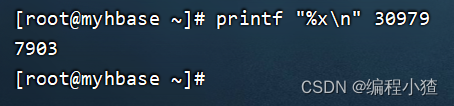
注意:上述的線程id是一個十進制,我們需要把這個線程id轉換為16進制才行,因為通常在日志中展示的都是16進制的線程id名稱
轉換方式:
在linux中執行命令
printf "%x\n" 30979
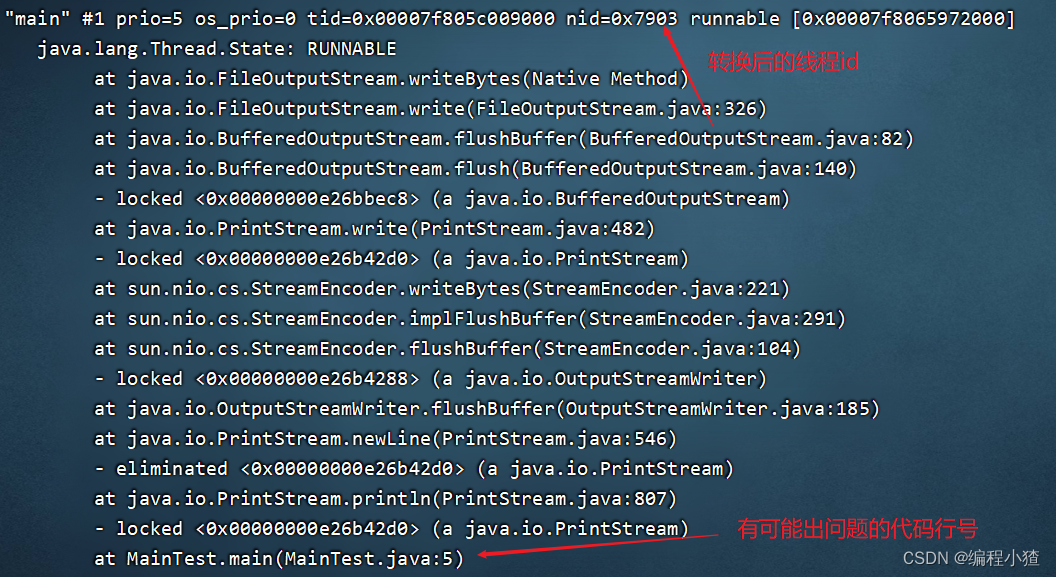
5.可以根據線程 id 找到有問題的線程,進一步定位到問題代碼的源碼行號
執行命令
jstack 30978 ? 此處是進程id
5.面試現場
5.1 JVM組成
面試官:JVM由那些部分組成,運行流程是什么?
候選人:
嗯,好的~~
在JVM中共有四大部分,分別是ClassLoader(類加載器)、Runtime Data Area(運行時數據區,內存分區)、Execution Engine(執行引擎)、Native Method Library(本地庫接口)
它們的運行流程是:
第一,類加載器(ClassLoader)把Java代碼轉換為字節碼
第二,運行時數據區(Runtime Data Area)把字節碼加載到內存中,而字節碼文件只是JVM的一套指令集規范,并不能直接交給底層系統去執行,而是有執行引擎運行
第三,執行引擎(Execution Engine)將字節碼翻譯為底層系統指令,再交由CPU執行去執行,此時需要調用其他語言的本地庫接口(Native Method Library)來實現整個程序的功能。
面試官:好的,你能詳細說一下 JVM 運行時數據區嗎?
候選人:
嗯,好~
運行時數據區包含了堆、方法區、棧、本地方法棧、程序計數器這幾部分,每個功能作用不一樣。
堆解決的是對象實例存儲的問題,垃圾回收器管理的主要區域。
方法區可以認為是堆的一部分,用于存儲已被虛擬機加載的信息,常量、靜態變量、即時編譯器編譯后的代碼。
棧解決的是程序運行的問題,棧里面存的是棧幀,棧幀里面存的是局部變量表、操作數棧、動態鏈接、方法出口等信息。
本地方法棧與棧功能相同,本地方法棧執行的是本地方法,一個Java調用非Java代碼的接口。
程序計數器(PC寄存器)程序計數器中存放的是當前線程所執行的字節碼的行數。JVM工作時就是通過改變這個計數器的值來選取下一個需要執行的字節碼指令。
面試官:好的,你再詳細介紹一下程序計數器的作用?
候選人:
嗯,是這樣~~
java虛擬機對于多線程是通過線程輪流切換并且分配線程執行時間。在任何的一個時間點上,一個處理器只會處理執行一個線程,如果當前被執行的這個線程它所分配的執行時間用完了【掛起】。處理器會切換到另外的一個線程上來進行執行。并且這個線程的執行時間用完了,接著處理器就會又來執行被掛起的這個線程。這時候程序計數器就起到了關鍵作用,程序計數器在來回切換的線程中記錄他上一次執行的行號,然后接著繼續向下執行。
面試官:你能給我詳細的介紹Java堆嗎?
候選人:
好的~
Java中的堆術語線程共享的區域。主要用來保存對象實例,數組等,當堆中沒有內存空間可分配給實例,也無法再擴展時,則拋出OutOfMemoryError異常。
? 在JAVA8中堆內會存在年輕代、老年代
? 1)Young區被劃分為三部分,Eden區和兩個大小嚴格相同的Survivor區,其中,Survivor區間中,某一時刻只有其中一個是被使用的,另外一個留做垃圾收集時復制對象用。在Eden區變滿的時候, GC就會將存活的對象移到空閑的Survivor區間中,根據JVM的策略,在經過幾次垃圾收集后,任然存活于Survivor的對象將被移動到Tenured區間。
? 2)Tenured區主要保存生命周期長的對象,一般是一些老的對象,當一些對象在Young復制轉移一定的次數以后,對象就會被轉移到Tenured區。
面試官:能不能解釋一下方法區?
候選人:
好的~
與虛擬機棧類似。本地方法棧是為虛擬機執行本地方法時提供服務的。不需要進行GC。本地方法一般是由其他語言編寫。
面試官:你聽過直接內存嗎?
候選人:
嗯~~
它又叫做堆外內存,線程共享的區域,在 Java 8 之前有個永久代的概念,實際上指的是 HotSpot 虛擬機上的永久代,它用永久代實現了 JVM 規范定義的方法區功能,主要存儲類的信息,常量,靜態變量,即時編譯器編譯后代碼等,這部分由于是在堆中實現的,受 GC 的管理,不過由于永久代有 -XX:MaxPermSize 的上限,所以如果大量動態生成類(將類信息放入永久代),很容易造成 OOM,有人說可以把永久代設置得足夠大,但很難確定一個合適的大小,受類數量,常量數量的多少影響很大。
? 所以在 Java 8 中就把方法區的實現移到了本地內存中的元空間中,這樣方法區就不受 JVM 的控制了,也就不會進行 GC,也因此提升了性能。
面試官:什么是虛擬機棧
候選人:
虛擬機棧是描述的是方法執行時的內存模型,是線程私有的,生命周期與線程相同,每個方法被執行的同時會創建棧楨。保存執行方法時的局部變量、動態連接信息、方法返回地址信息等等。方法開始執行的時候會進棧,方法執行完會出棧【相當于清空了數據】,所以這塊區域不需要進行 GC。
面試官:能說一下堆棧的區別是什么嗎?
候選人:
嗯,好的,有這幾個區別
第一,棧內存一般會用來存儲局部變量和方法調用,但堆內存是用來存儲Java對象和數組的的。堆會GC垃圾回收,而棧不會。
第二、棧內存是線程私有的,而堆內存是線程共有的。
第三、兩者異常錯誤不同,但如果棧內存或者堆內存不足都會拋出異常。
棧空間不足:java.lang.StackOverFlowError。
堆空間不足:java.lang.OutOfMemoryError。
5.2 類加載器
面試官:什么是類加載器,類加載器有哪些?
候選人:
嗯,是這樣的
JVM只會運行二進制文件,而類加載器(ClassLoader)的主要作用就是將字節碼文件加載到JVM中,從而讓Java程序能夠啟動起來。
常見的類加載器有4個
第一個是啟動類加載器(BootStrap ClassLoader):其是由C++編寫實現。用于加載JAVA_HOME/jre/lib目錄下的類庫。
第二個是擴展類加載器(ExtClassLoader):該類是ClassLoader的子類,主要加載JAVA_HOME/jre/lib/ext目錄中的類庫。
第三個是應用類加載器(AppClassLoader):該類是ClassLoader的子類,主要用于加載classPath下的類,也就是加載開發者自己編寫的Java類。
第四個是自定義類加載器:開發者自定義類繼承ClassLoader,實現自定義類加載規則。
面試官:說一下類裝載的執行過程?
候選人:
嗯,這個過程還是挺多的。
類從加載到虛擬機中開始,直到卸載為止,它的整個生命周期包括了:加載、驗證、準備、解析、初始化、使用和卸載這7個階段。其中,驗證、準備和解析這三個部分統稱為連接(linking)
1.加載:查找和導入class文件
2.驗證:保證加載類的準確性
3.準備:為類變量分配內存并設置類變量初始值
4.解析:把類中的符號引用轉換為直接引用
5.初始化:對類的靜態變量,靜態代碼塊執行初始化操作
6.使用:JVM 開始從入口方法開始執行用戶的程序代碼
7.卸載:當用戶程序代碼執行完畢后,JVM 便開始銷毀創建的 Class 對象,最后負責運行的 JVM 也退出內存
面試官:什么是雙親委派模型?
候選人:
嗯,它是是這樣的。
如果一個類加載器收到了類加載的請求,它首先不會自己嘗試加載這個類,而是把這請求委派給父類加載器去完成,每一個層次的類加載器都是如此,因此所有的加載請求最終都應該傳說到頂層的啟動類加載器中,只有當父類加載器返回自己無法完成這個加載請求(它的搜索返回中沒有找到所需的類)時,子類加載器才會嘗試自己去加載
面試官:JVM為什么采用雙親委派機制
候選人:
主要有兩個原因。
第一、通過雙親委派機制可以避免某一個類被重復加載,當父類已經加載后則無需重復加載,保證唯一性。
第二、為了安全,保證類庫API不會被修改
5.3 垃圾回收
面試官:簡述Java垃圾回收機制?(GC是什么?為什么要GC)
候選人:
嗯,是這樣~~
為了讓程序員更專注于代碼的實現,而不用過多的考慮內存釋放的問題,所以,在Java語言中,有了自動的垃圾回收機制,也就是我們熟悉的GC(Garbage Collection)。
有了垃圾回收機制后,程序員只需要關心內存的申請即可,內存的釋放由系統自動識別完成。
在進行垃圾回收時,不同的對象引用類型,GC會采用不同的回收時機
面試官:強引用、軟引用、弱引用、虛引用的區別?
候選人:
嗯嗯~
強引用最為普通的引用方式,表示一個對象處于有用且必須的狀態,如果一個對象具有強引用,則GC并不會回收它。即便堆中內存不足了,寧可出現OOM,也不會對其進行回收
軟引用表示一個對象處于有用且非必須狀態,如果一個對象處于軟引用,在內存空間足夠的情況下,GC機制并不會回收它,而在內存空間不足時,則會在OOM異常出現之間對其進行回收。但值得注意的是,因為GC線程優先級較低,軟引用并不會立即被回收。
弱引用表示一個對象處于可能有用且非必須的狀態。在GC線程掃描內存區域時,一旦發現弱引用,就會回收到弱引用相關聯的對象。對于弱引用的回收,無關內存區域是否足夠,一旦發現則會被回收。同樣的,因為GC線程優先級較低,所以弱引用也并不是會被立刻回收。
虛引用表示一個對象處于無用的狀態。在任何時候都有可能被垃圾回收。虛引用的使用必須和引用隊列Reference Queue聯合使用
面試官:對象什么時候可以被垃圾器回收
候選人:
思考一會~~
如果一個或多個對象沒有任何的引用指向它了,那么這個對象現在就是垃圾,如果定位了垃圾,則有可能會被垃圾回收器回收。
如果要定位什么是垃圾,有兩種方式來確定,第一個是引用計數法,第二個是可達性分析算法
通常都使用可達性分析算法來確定是不是垃圾
面試官: JVM 垃圾回收算法有哪些?
候選人:
我記得一共有四種,分別是標記清除算法、復制算法、標記整理算法、分代回收
面試官: 你能詳細聊一下分代回收嗎?
候選人:
關于分代回收是這樣的
在java8時,堆被分為了兩份:新生代和老年代,它們默認空間占用比例是1:2
對于新生代,內部又被分為了三個區域。Eden區,S0區,S1區默認空間占用比例是8:1:1
具體的工作機制是有些情況:
1)當創建一個對象的時候,那么這個對象會被分配在新生代的Eden區。當Eden區要滿了時候,觸發YoungGC。
2)當進行YoungGC后,此時在Eden區存活的對象被移動到S0區,并且當前對象的年齡會加1,清空Eden區。
3)當再一次觸發YoungGC的時候,會把Eden區中存活下來的對象和S0中的對象,移動到S1區中,這些對象的年齡會加1,清空Eden區和S0區。
4)當再一次觸發YoungGC的時候,會把Eden區中存活下來的對象和S1中的對象,移動到S0區中,這些對象的年齡會加1,清空Eden區和S1區。
5)對象的年齡達到了某一個限定的值(默認15歲 ),那么這個對象就會進入到老年代中。
當然也有特殊情況,如果進入Eden區的是一個大對象,在觸發YoungGC的時候,會直接存放到老年代
當老年代滿了之后,觸發FullGC。FullGC同時回收新生代和老年代,當前只會存在一個FullGC的線程進行執行,其他的線程全部會被掛起。 我們在程序中要盡量避免FullGC的出現。
面試官:講一下新生代、老年代、永久代的區別?
候選人:
嗯!是這樣的,簡單說就是
新生代主要用來存放新生的對象。
老年代主要存放應用中生命周期長的內存對象。
永久代指的是永久保存區域。主要存放Class和Meta(元數據)的信息。在Java8中,永久代已經被移除,取而代之的是一個稱之為“元數據區”(元空間)的區域。元空間和永久代類似,不過元空間與永久代之間最大的區別在于:元空間并不在虛擬機中,而是使用本地內存。因此,默認情況下,元空間的大小僅受本地內存的限制。
面試官:說一下 JVM 有哪些垃圾回收器?
候選人:
在jvm中,實現了多種垃圾收集器,包括:串行垃圾收集器、并行垃圾收集器(JDK8默認)、CMS(并發)垃圾收集器、G1垃圾收集器(JDK9默認)
面試官:Minor GC、Major GC、Full GC是什么
候選人:
嗯,其實它們指的是不同代之間的垃圾回收
Minor GC 發生在新生代的垃圾回收,暫停時間短
Major GC 老年代區域的垃圾回收,老年代空間不足時,會先嘗試觸發Minor GC。Minor GC之后空間還不足,則會觸發Major GC,Major GC速度比較慢,暫停時間長
Full GC 新生代 + 老年代完整垃圾回收,暫停時間長,應盡力避免
5.4 JVM實踐(調優)
面試官:JVM 調優的參數可以在哪里設置參數值?
候選人:
我們當時的項目是springboot項目,可以在項目啟動的時候,java -jar中加入參數就行了
面試官:用的 JVM 調優的參數都有哪些?
候選人:
嗯,這些參數是比較多的
我記得當時我們設置過堆的大小,像-Xms和-Xmx
還有就是可以設置年輕代中Eden區和兩個Survivor區的大小比例
還有就是可以設置使用哪種垃圾回收器等等。具體的指令還真記不太清楚。
面試官:嗯,好的,你們平時調試 JVM都用了哪些工具呢?
候選人:
嗯,我們一般都是使用jdk自帶的一些工具,比如
jps 輸出JVM中運行的進程狀態信息
jstack查看java進程內線程的堆棧信息。
jmap 用于生成堆轉存快照
jstat用于JVM統計監測工具
還有一些可視化工具,像jconsole和VisualVM等
面試官:假如項目中產生了java內存泄露,你說一下你的排查思路?
候選人:
嗯,這個我在之前項目排查過
第一呢可以通過jmap指定打印他的內存快照 dump文件,不過有的情況打印不了,我們會設置vm參數讓程序自動生成dump文件
第二,可以通過工具去分析 dump文件,jdk自帶的VisualVM就可以分析
第三,通過查看堆信息的情況,可以大概定位內存溢出是哪行代碼出了問題
第四,找到對應的代碼,通過閱讀上下文的情況,進行修復即可
面試官:好的,那現在再來說一種情況,就是說服務器CPU持續飆高,你的排查方案與思路?
候選人:
嗯,我思考一下~~
可以這么做~~
第一可以使用使用top命令查看占用cpu的情況
第二通過top命令查看后,可以查看是哪一個進程占用cpu較高,記錄這個進程id
第三可以通過ps 查看當前進程中的線程信息,看看哪個線程的cpu占用較高
第四可以jstack命令打印進行的id,找到這個線程,就可以進一步定位問題代碼的行號









![[計算機網絡]---TCP協議](http://pic.xiahunao.cn/[計算機網絡]---TCP協議)

![P1024 [NOIP2001 提高組] 一元三次方程求解](http://pic.xiahunao.cn/P1024 [NOIP2001 提高組] 一元三次方程求解)


)
:程序環境和預處理詳解)



)