大工程 從0到1 數據治理 之數倉篇
我這里還是sample database classicmodels為案列,可以下載,我看 網上還沒有類似的 案列,那就 從 0-1開始吧!
提示:寫完文章后,目錄可以自動生成,如何生成可參考右邊的幫助文檔
文章目錄
- 大工程 從0到1 數據治理 之數倉篇
- 什么是數倉?
- 企業為什么要建數倉?
- 建數倉的數據庫選型
- 關系型數據庫:
- 列式數據庫:
- 分布式數據庫:
- 云數據庫服務:
- Mpp數據庫:
- 數倉的備份
- 全量備份:
- 增量備份:
- 定期備份計劃:
- 分層備份:
- 異地備份:
- 壓縮和加密:
- 測試恢復流程:
- 日志備份:
- 監控和報警:
- TB級數倉的硬件配置
- [clickhouse -data warehouse](https://clickhouse.com/blog/building-a-data-warehouse-with-clickhouse) 
什么是數倉?
數倉是指數據倉庫的簡稱(Data Warehouse)。數據倉庫是一個用于集中存儲和管理大量結構化和非結構化數據的系統。它的目標是幫助組織更好地理解和分析其數據,支持決策和業務運營或者說是 支持企業在決策和分析方面的需求,提供可靠、一致、高性能的數據存儲和訪問。
以通俗易懂的方式來說,你可以把數據倉庫比喻為一個大型的數據存儲倉庫,就像企業中的“數據中心”。這個倉庫里存放著各種各樣的數據,包括銷售數據、客戶信息、交易記錄等等,這些數據來自企業內部的不同部門和系統。
數倉的主要功能是將這些分散的數據整合在一起,清理和轉換成可分析的格式,使企業管理層和決策者能夠更輕松地查看、理解和利用這些信息。通過數倉,企業可以進行更有效的業務分析、趨勢預測、決策制定,從而提升業務的智能化和競爭力。
數倉的優勢包括:
- 決策支持: 提供高性能的查詢和報表功能,幫助企業領導和分析師做出更好的決策。
- 數據一致性: 集中存儲數據,確保數據的一致性和準確性。
- 歷史數據追溯: 可以存儲歷史數據,支持時間序列分析和趨勢觀察。
- 數據整合: 整合來自不同業務系統的數據,提供一個全面的視圖。
- 總的來說,數據倉庫在企業中扮演著重要角色,幫助組織更好地理解和利用其數據資產。
數倉通常從不同的業務系統中匯總數據,將其清洗、轉換、加載(ETL)到一個統一的存儲庫中,以便用戶可以執行復雜的查詢和分析。數據倉庫的設計通常遵循維度建模的原則,其中數據被組織成事實表和維度表,以支持多維分析。
企業為什么要建數倉?
企業建立數據倉庫(Data Warehouse)有多個重要原因,其中一些主要的包括:
集中數據存儲: 數據倉庫提供一個集中存儲和管理企業內部和外部數據的地方。這使得數據更容易訪問、管理和維護,有助于確保數據的一致性和準確性。
支持決策制定: 數據倉庫能夠整合不同來源的數據,提供更全面、準確的信息,幫助企業管理層做出更明智的戰略和戰術決策。通過分析歷史數據和當前趨勢,企業能更好地了解市場、客戶、業務運營等方面的情況。
提高數據質量: 數據倉庫通常包括數據清洗、轉換和加載(ETL)過程,通過這些過程,可以提高數據的質量,確保數據的一致性和準確性。這有助于避免在決策中因為數據質量問題而導致的錯誤。
支持業務智能和分析: 數據倉庫是業務智能和分析的基礎。通過對數據倉庫中的數據進行查詢和分析,企業可以獲取深刻的見解,發現潛在的模式和趨勢,幫助業務更好地了解市場、客戶需求和業務績效。
滿足合規性要求: 數據倉庫的建立可以有助于滿足法規和合規性方面的要求。通過確保數據的一致性和準確性,企業能夠更容易地滿足監管機構的規定。
支持大數據處理: 隨著大數據的崛起,企業需要處理和分析海量的數據。數據倉庫提供了一種結構化的方法,幫助企業有效地管理和分析大規模數據集。
促進數據驅動文化: 數據倉庫可以促進數據驅動的企業文化。通過使數據更易于訪問和理解,員工更有可能使用數據支持其決策和行動。
總的來說,建立數據倉庫有助于企業更好地管理、分析和利用數據資源,從而提高決策的準確性和效率,推動業務的發展。
建數倉的數據庫選型
關系型數據庫:
Oracle Database: Oracle是一種強大的關系型數據庫管理系統,廣泛用于大型企業和復雜的數據倉庫環境。
Microsoft SQL Server: SQL Server是微軟推出的關系型數據庫管理系統,適用于Windows環境,并提供強大的商業智能和分析功能。
MySQL: MySQL是一種開源的關系型數據庫,適用于中小型企業的數據倉庫建設。
列式數據庫:
Greenplum: Greenplum是一種基于開源的列式數據庫,專注于大規模數據倉庫和分析場景。
ClickHouse: ClickHouse是俄羅斯的一種列式數據庫,以其高性能和可擴展性而聞名。
分布式數據庫:
Hadoop和Hive: 使用Hadoop作為分布式存儲,結合Hive進行數據倉庫查詢。這適用于大規模的數據分析和處理。
Spark SQL: 基于Apache Spark的分布式數據庫,適用于大規模數據處理和復雜分析。
NoSQL數據庫:
MongoDB: MongoDB是一種面向文檔的NoSQL數據庫,適用于半結構化數據和靈活的數據模型。
Cassandra: Cassandra是一種分布式的NoSQL數據庫,適用于具有高可擴展性和高可用性需求的場景。
還有
云數據庫服務:
阿里云 AnalyticDB: 阿里云的AnalyticDB是一種云上數據倉庫服務,具有高性能、彈性擴展和集成大數據處理的特點。
騰訊云 ClickHouse: 騰訊云提供的ClickHouse服務,可以方便地在云上搭建基于列式存儲的數據倉庫。
Mpp數據庫:
StarRocks 和 Doris:
StarRocks 和 Doris 都是分布式的實時分析數據庫,屬于MPP(Massively Parallel Processing)架構的一種。它們的設計目標是支持大規模數據存儲和分析,特別適用于OLAP(Online Analytical Processing)場景,即面向復雜查詢和分析的工作負載。
中國的一些MPP(Massively Parallel Processing)數據庫包括:
OceanBase:
OceanBase是由阿里巴巴開發的分布式數據庫系統。它支持水平擴展和MPP處理,用于應對大規模數據存儲和處理需求。OceanBase不僅支持事務型工作負載,還能夠處理大量的分析型查詢。
TencentDB:
騰訊云的數據庫服務TencentDB(原騰訊云分布式數據庫TDSQL)具有分布式架構和MPP處理能力,適用于OLAP和OLTP場景。它提供了MySQL、PostgreSQL和SQL Server等不同引擎的版本。
Huawei GaussDB:
華為的GaussDB是一款分布式數據庫產品,支持MPP處理,適用于海量數據的存儲和分析。它支持多模型數據庫,包括關系型、時序型、圖形型等。
數倉的備份
數據倉庫的備份是保障數據安全、可用性和完整性的關鍵步驟。備份策略應該根據業務需求、數據重要性和恢復時間目標(Recovery Time Objective, RTO)等因素進行制定。以下是關于數據倉庫備份的一些建議:
全量備份:
定期進行全量備份是數據倉庫備份策略的基礎。全量備份包含整個數據庫的數據,是恢復數據的基礎。
增量備份:
為減少備份時間和存儲成本,可以考慮增量備份。增量備份只備份自上次備份以來發生變化的數據,節省存儲空間和備份時間。
定期備份計劃:
制定定期的備份計劃,根據業務需求和數據變化頻率來決定備份的頻率。一般來說,每日全量備份和更頻繁的增量備份是常見的做法。
分層備份:
根據數據倉庫的不同層次,可以考慮采用分層備份策略。比如,可以對ODS層和DWD層采用不同的備份頻率和保留期限,根據數據變更的頻率和重要性進行調整。
異地備份:
將備份數據存儲在與數據倉庫主體不同的物理位置,以防止因自然災害、硬件故障等原因導致的數據丟失。云存儲服務也是一個常見的異地備份選擇。
壓縮和加密:
在備份數據時,可以考慮對備份文件進行壓縮,以節省存儲空間。同時,對備份數據進行加密有助于確保備份文件的安全性。
測試恢復流程:
定期測試備份的恢復過程,以確保備份數據的完整性和可用性。這可以在面臨真實災難時提高數據恢復的成功率。
日志備份:
在數據庫支持的情況下,進行事務日志的備份,以支持點時間恢復(Point-in-Time Recovery)。這可以減小數據丟失的范圍。
監控和報警:
設置備份任務的監控和報警機制,及時發現備份失敗、存儲空間不足等問題,確保備份任務按計劃執行。
備份是數據管理中至關重要的一環,一個健全的備份策略有助于最小化數據丟失、確保系統可用性,并提供在緊急情況下迅速恢復數據的能力。
TB級數倉的硬件配置
要構建一個TB級別的大規模數據倉庫,需要精心設計硬件配置以滿足高性能、可伸縮性和可靠性的要求。以下是一個概括性的TB級數據倉庫的硬件配置示例:
計算節點(Compute Nodes):
數量: 數十至數百臺計算節點,具體數量根據數據規模和性能需求而定。
處理器: 每個計算節點配備多個高性能的多核處理器,如Intel Xeon或AMD EPYC系列。
內存: 大量的RAM,通常每個節點需要幾百GB到數TB的內存,以支持大規模數據的并行處理和分析。
存儲節點(Storage Nodes):
數量: 數十至數百臺存儲節點,用于存儲大規模的數據。
存儲類型: 高性能的分布式存儲系統,可能包括SSD和HDD的混合存儲,以平衡性能和成本。分布式文件系統或對象存儲可用于提供高可用性和可伸縮性。
存儲容量: 每個節點具有數十TB到數百TB的存儲容量,總存儲容量達到TB級別。
網絡架構:
高速網絡: 使用高速網絡互聯計算節點和存儲節點,例如40Gbps或100Gbps以保障快速數據傳輸。
InfiniBand或Ethernet: 選擇適當的網絡技術,以支持低延遲和高帶寬的通信,確保計算節點和存儲節點之間的有效通信。
數據庫引擎和軟件:
分布式數據庫: 選擇適合大規模數據倉庫的分布式數據庫引擎,如StarRocks、Doris、Greenplum等。
操作系統: 使用穩定、高性能的操作系統,如Linux發行版(例如CentOS、Red Hat)。
負載均衡和管理工具:
負載均衡器: 在前端引入負載均衡器以平衡查詢負載,確保計算和存儲資源充分利用。
集群管理工具: 使用專業的集群管理工具,確保節點的高可用性和故障恢復。
冗余備份和災難恢復:
冗余節點: 在計算和存儲層面引入冗余節點,以防單個節點故障。這可以通過數據復制和備份機制來實現。
災難恢復: 考慮在不同地理位置部署冗余數據中心,以實現災難恢復和數據備份的安全性。
以上硬件配置只是一個示例,具體的TB級數據倉庫硬件配置需要根據實際需求、預算和性能目標進行調整。在設計和建設過程中,建議進行性能測試和負載測試,以確保硬件配置能夠滿足數據倉庫的需求。
一些學習資料
github
wiki-data_warehouse
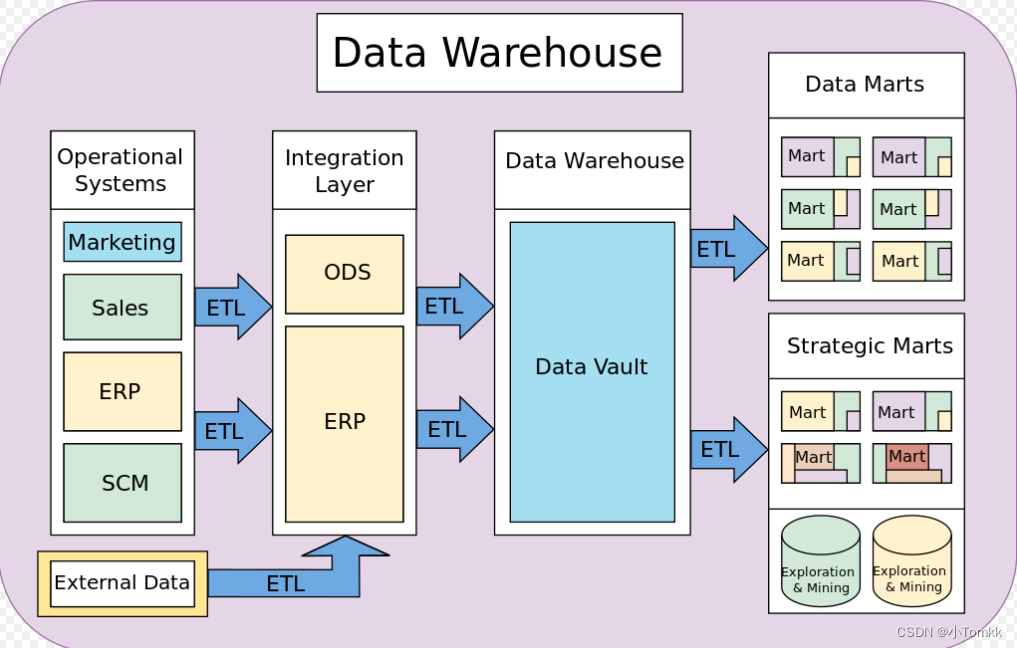
aws-data-warehouse
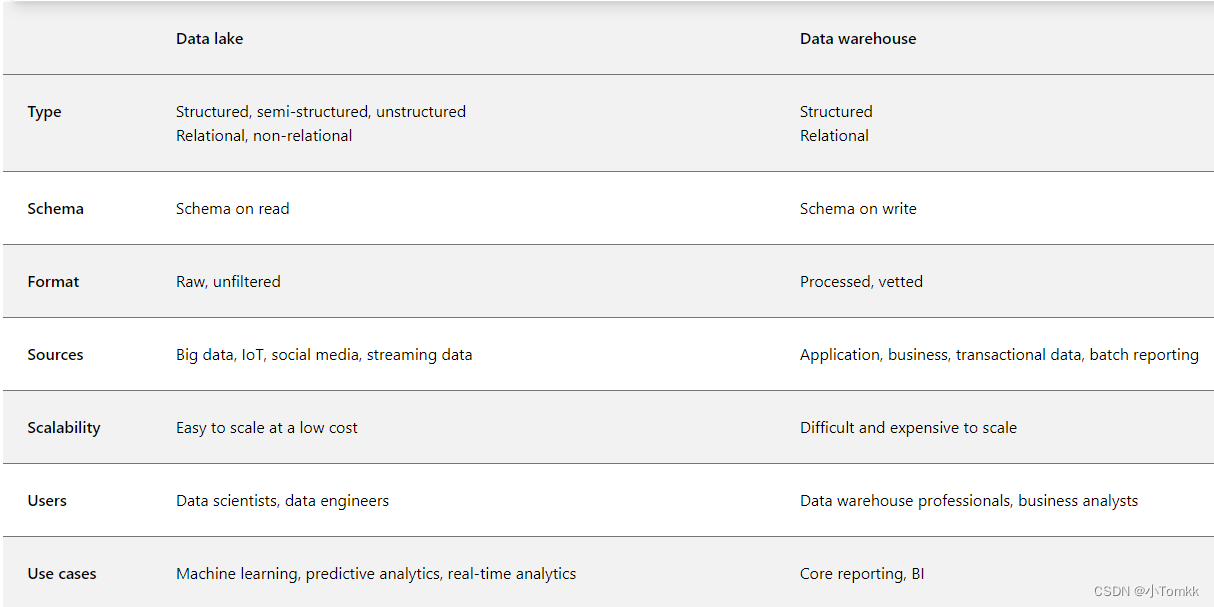
azure-data-warehouse
IBM-data-warehouse
clickhouse -data warehouse

文本 將使用 clickhouse 做數據倉庫,后面一章會說到,謝謝大家



)












![[計算機網絡]---TCP協議](http://pic.xiahunao.cn/[計算機網絡]---TCP協議)

![P1024 [NOIP2001 提高組] 一元三次方程求解](http://pic.xiahunao.cn/P1024 [NOIP2001 提高組] 一元三次方程求解)
