還記得筆者在上篇文章無意中挖的一個坑么?如若不知,強烈建議看官先行閱讀前面兩文-《SparkSQL Join原理》和《Join中竟然也有謂詞下推?》
第一篇文章主要分析了大數據領域Join的三種基礎算法以及各自的適用場景,第二篇文章在第一篇的基礎上進一步深入,討論了Join基礎算法的一種優化方案 – Runtime Filter,文章最后還引申地聊了聊謂詞下推技術。同時,在第二篇文章開頭,筆者引出了兩個問題,SQL執行引擎如何知曉參與Join的兩波數據集大小?衡量兩波數據集大小的是物理大小還是紀錄多少抑或兩者都有?這關系到SQL解析器如何正確選擇Join算法的問題。好了,這些就是這篇文章要為大家帶來的議題-基于代價優化(Cost-Based Optimization,簡稱CBO)。
CBO基本原理
提到CBO,就不得不提起一位’老熟人’ – 基于規則優化(Rule-Based Optimization,簡稱RBO)。RBO是一種經驗式、啟發式的優化思路,優化規則都已經預先定義好,只需要將SQL往這些規則上套就可以(對RBO還不了解的童鞋,可以參考筆者的另一篇文章 – 《從0到1認識Catalyst》)。說白了,RBO就像是一個經驗豐富的老司機,基本套路全都知道。
然而世界上有一種東西叫做 – 不按套路來,與其說它不按套路來,倒不如說它本身并沒有什么套路。最典型的莫過于復雜Join算子優化,對于這些Join來說,通常有兩個選擇題要做:
1、Join應該選擇哪種算法策略來執行?BroadcastJoin or ShuffleHashJoin or SortMergeJoin?不同的執行策略對系統的資源要求不同,執行效率也有天壤之別,同一個SQL,選擇到合適的策略執行可能只需要幾秒鐘,而如果沒有選擇到合適的執行策略就可能會導致系統OOM。
2、對于雪花模型或者星型模型來講,多表Join應該選擇什么樣的順序執行?不同的Join順序意味著不同的執行效率,比如A join B join C,A、B表都很大,C表很小,那A join B很顯然需要大量的系統資源來運算,執行時間必然不會短。而如果使用A join C join B的執行順序,因為C表很小,所以A join C會很快得到結果,而且結果集會很小,再使用小的結果集 join B,性能顯而易見會好于前一種方案。
大家想想,這有什么固定的優化規則么?并沒有。說白了,你需要知道更多關于表的基礎信息(表大小、表記錄總條數等),再通過一定規則代價評估才能從中選擇一條最優的執行計劃。CBO意為基于代價優化策略,就是從多個可能的語法樹中選擇一條代價最小的語法樹來執行,換個說法,CBO的核心在于評估出一條給定語法樹的實際代價。比如下面這顆SQL語法樹:
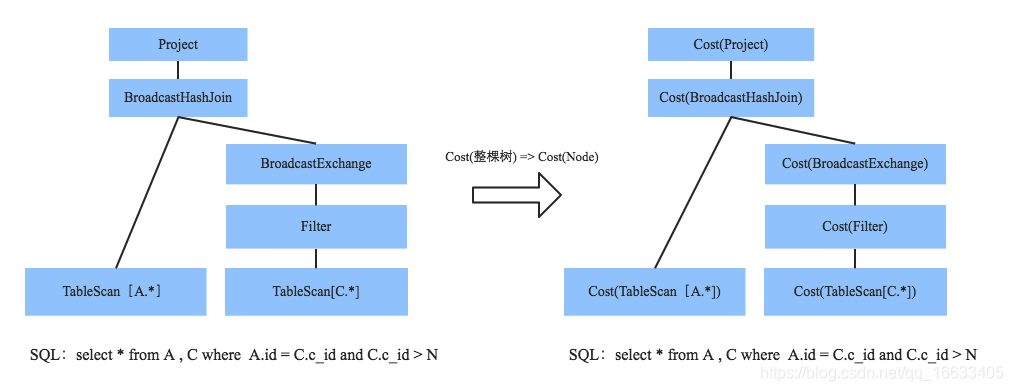
要評估給定整棵樹的代價,分而治之只需要評估每個節點執行的代價,最后將所有節點代價累加即可。而要評估單個節點執行實際代價,又需要知道兩點,其一是這種算子的代價規則,每種算子的代價計算規則必然都不同,比如Merge-Sort Join、Shuffle Hash Join、GroupBy都有自己的一套代價計算算法。其二是參與操作的數據集基本信息(大小、總記錄條數),比如實際參與Merge-Sort Join的兩表大小,作為節點實際執行代價的一個重要因素,當然非常重要。試想,同樣是Table Scan操作,大表和小表的執行代價必然不同。
為給定算子的代價進行評估說到底也是一種算法,算法都是死的,暫且不表,下文詳述。而參與的數據集基本信息卻是活的,為什么如此說,因為這些數據集都是原始表經過過濾、聚合之后的中間結果,沒有規則直接告訴你這個中間結果有多少數據!那中間結果的基本信息如何評估呢?推導!對,原始表基本信息我們是可以知道的,如果能夠一層一層向上推導,是不是就有可能知道所求中間結果信息!
這里又將任意節點中間結果信息評估拆分為兩個子問題:首先評估葉子節點(原始表)的基本信息,其次一層一層往上推導。評估原始表基本信息想想總是有辦法的,粗暴點就全表掃描,獲取記錄條數、最大值、最小值,總之是可以做到的。那基本信息如何一層一層往上推導呢?規則!比如原始表經過 id = 12這個Filter過濾之后的數據集信息(數據集大小等)就可以經過一定的規則推導出來,不同算子有不同的規則,下文詳述!
好吧,上文花費了大量時間將一個完整的CBO解剖的零零碎碎,變成了一堆規則加原始表的掃描。相信大家都有點懵懵的。莫慌,我們再來理一遍:
1. 基于代價優化(CBO)原理是計算所有執行路徑的代價,并挑選代價最小的執行路徑。問題轉化為:如何計算一條給定執行路徑的代價
2. 計算給定路徑的執行代價,只需要計算這條路徑上每個節點的執行代價,最后相加即可。問題轉化為:如何計算其中任意一個節點的執行代價
3. 計算任意節點的執行代價,只需要知道當前節點算子的代價計算規則以及參與計算的數據集(中間結果)基本信息(數據量大小、數據條數等)。問題轉化為:如何計算中間結果的基本信息以及定義算子代價計算規則
4. 算子代價計算規則是一種死的規則,可定義。而任意中間結果基本信息需要通過原始表基本信息順著語法樹一層一層往上推導得出。問題轉化為:如何計算原始表基本信息以及定義推導規則
很顯然,上述過程是思維過程,真正工程實踐是反著由下往上一步一步執行,最終得到代價最小的執行路徑。現在再把它從一個個零件組裝起來:
1. 首先采集原始表基本信息
2. 再定義每種算子的基數評估規則,即一個數據集經過此算子執行之后基本信息變化規則。這兩步完成之后就可以推導出整個執行計劃樹上所有中間結果集的數據基本信息
3. 定義每種算子的執行代價,結合中間結果集的基本信息,此時可以得出任意節點的執行代價
4. 將給定執行路徑上所有算子的代價累加得到整棵語法樹的代價
5. 計算出所有可能語法樹代價,并選出一條代價最小的
CBO基本實現思路
上文從理論層面分析了CBO的實現思路,將完整的CBO功能拆分為了多個子功能,接下來聊聊對每一個子功能的實現。
第一步:采集參原始表基本信息
這個操作是CBO最基礎的一項工作,采集的主要信息包括表級別指標和列級別指標,如下所示,estimatedSize和rowCount為表級別信息,basicStats和Histograms為列級別信息,后者粒度更細,對優化更加重要。
- estimatedSize: 每個LogicalPlan節點輸出數據大小(解壓)
- rowCount: 每個LogicalPlan節點輸出數據總條數
- basicStats: 基本列信息,包括列類型、Max、Min、number of nulls, number of distinct values, max column length, average column length等
- Histograms: Histograms of columns, i.e., equi-width histogram (for numeric and string types) and equi-height histogram (only for numeric types).
這里有兩個問題值得思考:
1、為什么要采集這些信息?每個對象在優化過程中起到什么作用?
2、實際工程一般是如何實現這些數據采集的?
為什么要采集這些信息?很顯然,estimatedSize和rowCount這兩個值是算子代價評估的直觀體現,這兩個值越大,給定算子執行代價必然越大,所以這兩個值后續會用來評估實際算子的執行代價。那basicStats和Histograms這倆用來干啥呢,要不忘初心,之所以采集原始表的這些信息,是為了順著執行語法樹往上一層一層推導出所有中間結果的基本信息,這倆就是來干這個的,至于怎么實現的,下一小節會舉個例子解釋。
實際工程如何實現這些數據采集?一般有兩種比較可行的方案:打開所有表掃描一遍,這樣最簡單,而且統計信息準確,缺點是對于大表來說代價比較大;針對一些大表,掃描一遍代價太大,可以采用采樣(sample)的方式統計計算。
支持CBO的系統都有命令對原始數據信息進行統計,比如Hive的Analyze命令、Impala的Compute命令、Greenplum的Analyze命令等,但是需要注意這些命令并不是隨時都應該執行的,首先在表數據沒有大變動的情況下沒必要執行,其次在系統查詢高發期也不應該執行。這里有個最佳實踐:盡可能在業務低峰期對表數據有較大變動的表單獨執行統計命令,這句話有三個重點,不知道你看出來沒有?
第二步:定義核心算子的基數推導規則
規則推導意思是說在當前子節點統計信息的基礎上,計算父節點相關統計信息的一套推導規則。對于不同算子,推導規則必然不一樣,比如fliter、group by、limit等等的評估推導是不同的。這里以filter為例進行講解。先來看看這樣一個SQL:select * from A , C where A.id = C.c_id and C.c_id > N ,經過RBO之后的語法樹如下圖所示: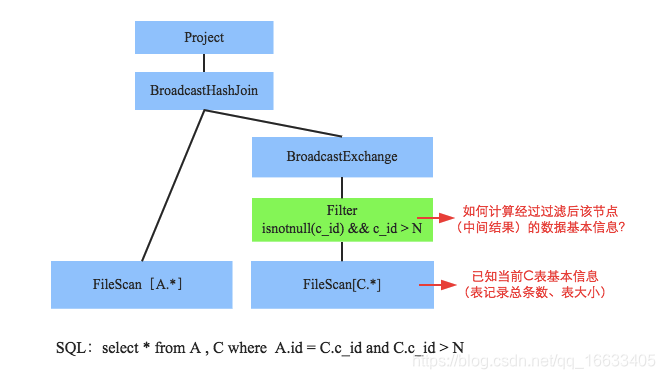
問題定義為:假如現在已經知道表C的基本統計信息(estimatedSize、rowCount、basicStats以及histograms),如何推導出經過C.c_id > N過濾后中間結果的基本統計信息。我們來看看:
1、假設已知C列的最小值c_id.Min、最大值c_id.Max以及總行數c_id.Distinct,同時假設數據分布均勻,如下圖所示:
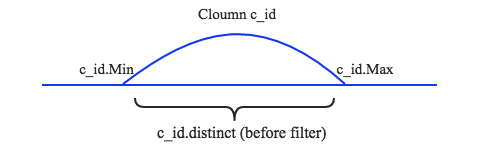
2、現在分別有三種情況需要說明,其一是N小于c_id.Min,其二是N大于c_id.Max,其三是N介于c_id.Min和c_id.Max之間。前兩種場景是第三種場景的特殊情況,這里簡單的針對第三種場景說明。如下圖所示:
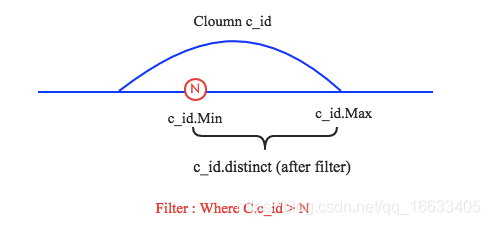
在C.c_id > N過濾條件下,c_id.Min會增大到N,c_id.Max保持不變。而過濾后總行數c_id.distinct(after filter) = (c_id.Max – N) / (c_id.Max – c_id.Min) * c_id.distinct(before filter)
簡單吧,但是注意哈,上面計算是在假設數據分布均勻的前提下完成的,而實際場景中數據分布很顯然不可能均衡。數據分布通常成概率分布,histograms在這里就要登場了,說白了它就是一個柱狀分布圖,如下圖:
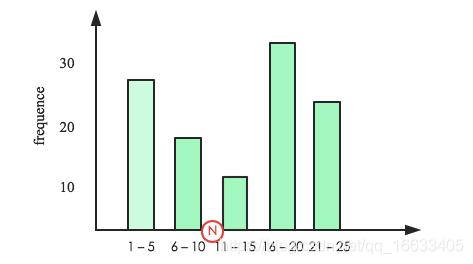
柱狀圖橫坐標表示列值大小分布,縱坐標表示頻率。假設N在如圖所示位置,那過濾后總行數c_id.distinct(after filter) = height(>N) / height(All) * c_id.distinct(before filter)
當然,上述所有計算都只是示意性計算,真實算法會復雜很多。另外,如果大家對group by 、limit等謂詞的評估規則比較感興趣的話,可以閱讀SparkSQL CBO設計文檔,在此不再贅述。至此,通過各種評估規則以及原始表統計信息就可以計算出語法樹中所有中間節點的基本統計信息了,這是萬里長征的第二步,也是至關重要的一步。接下來繼續往前走,看看如何計算每種核心算子的實際代價。
第三步:核心算子實際代價計算
打文章一開始就開口閉口代價代價的,可到底什么是代價,怎么定義代價?這么說吧,每個系統對代價的定義并不非常一致,有的因為實現的原因設置的比較簡單,有的會比較復雜。這一節主要來簡單聊聊每個節點的執行代價,上文說了,一條執行路徑的總代價就是這條路徑上所有節點的代價累加之和。
通常來講,節點實際執行代價主要從兩個維度來定義:CPU Cost以及IO Cost。為后續講解方便起見,需要先行定義一些基本參數:
- Hr:從HDFS上讀取1byte數據所需代價
- Hw:往HDFS上寫入1byte數據所需代價
- Tr:數據總條數(the number of tuples in the relation )
- Tsz:數據平均大小(Average size of the tuple in the relation )
- CPUc:兩值比較所需CPU資源代價(CPU cost for a comparison in nano seconds )
- NEt:1byte數據通過網絡在集群節點間傳輸花費代價(the average cost of transferring 1 byte
over network in the Hadoop cluster from any node to any node ) - ……
- 上文說過,每種算子的實際執行代價計算方式都不同,在此不可能列舉所有算子,就挑兩個比較簡單、容易理解的來分析,第一個是Table
Scan算子,第二個是Hash Join算子。
Table Scan算子
Scan算子一般位于語法樹的葉子結點,直觀上來講這類算子只有IO Cost,CPU Cost為0。Table Scan Cost = IO Cost = Tr * Tsz * Hr,很簡單,Tr * Tsz表示需要scan的數據總大小,再乘以Hr就是所需代價。OK,很直觀,很簡單。
Hash Join算子
以Broadcast Hash Join為例(如果看官對Broadcast Hash Join工作原理還不了解,可戳這里),假設大表分布在n個節點上,每個節點的數據條數\平均大小分別為Tr(R1)\Tsz(R1),Tr(R2)\Tsz(R2), … Tr(Rn)\Tsz(Rn),小表數據條數為Tr(Rsmall)\Tsz(Rsmall),那么CPU代價和IO代價分別為:
CPU Cost = 小表構建Hash Table代價 + 大表探測代價 = Tr(Rsmall) * CPUc + (Tr(R1) + Tr(R2) + … + Tr(Rn)) * N * CPUc,此處假設HashTable構建所需CPU資源遠遠高于兩值簡單比較代價,為N * CPUc
IO Cost = 小表scan代價 + 小表廣播代價 + 大表scan代價 = Tr(Rsmall) * Tsz(Rsmall) * Hr + n * Tr(Rsmall) * Tsz(Rsmall) * NEt + (Tr(R1)* Tsz(R1) + … + Tr(Rn) * Tsz(Rn)) * Hr
很顯然,Hash Join算子相比Table Scan算子來講稍稍復雜了一點,但是無論哪種算子,代價計算都和參與的數據總條數、數據平均大小等因素直接相關,這也就是為什么在之前兩個步驟中要不懈余力地計算中間結果相關詳細的真正原因。可謂是步步為營、環環相扣。這下好了,任意節點的實際代價都能評估出來,那么給定任意執行路徑的代價必然也就很簡單嘍。
第四步:選擇最優執行路徑(代價最小執行路徑)
這個思路很容易理解的,經過上述三步的努力,可以很容易地計算出任意一條給定路徑的代價。那么你只需要找出所有可行的執行路徑,一個一個計算,就必然能找到一個代價最小的,也就是最優的執行路徑。
這條路看起來確實很簡單,但實際做起來卻并不那么容易,為什么?所有可行的執行路徑實在太多,所有路徑都計算一遍,黃花菜都涼了。那么有什么好的解決方案么?當然,其實看到這個標題-選擇代價最小執行路徑,就應該很容易想到-動態規劃,如果你沒有想到,那只能說明你沒有讀過《數學之美》、沒刷過LeetCode、沒玩過ACM,ACM、LeetCode如果覺得太枯燥,那就去看看《數學之美》,它會告訴你從當前這個你所在的地方開車去北京,如何使用動態規劃選擇一條最短的路線。在此不再贅述。
至此,筆者粗線條地介紹了當前主流SQL引擎是如何將CBO這么一個看似高深的技術一步一步落地的。接下來,筆者將會借用Hive、Impala這兩大SQL引擎開啟CBO之后的優化效果讓大家對CBO有一個更直觀的理解。
Hive – CBO優化效果
Hive本身沒有去從頭實現一個SQL優化器,而是借助于Apache Calcite ,Calcite是一個開源的、基于CBO的企業級SQL查詢優化框架,目前包括Hive、Phoniex、Kylin以及Flink等項目都使用了Calcite作為其執行優化器,這也很好理解,執行優化器本來就可以抽象成一個系統模塊,并沒有必要花費大量時間去重復造輪子。
hortonworks曾經對Hive的CBO特性做了相關的測試,測試結果認為CBO至少對查詢有三個重要的影響:Join ordering optimization、Bushy join support以及Join simplification,本文只簡單介紹一下Join ordering optimization,有興趣的同學可以繼續閱讀這篇文章來更多地了解其他兩個重要影響。(下面數據以及示意圖也來自于該篇文章,特此注明)
hortonworks對TPCDS的部分Query進行了研究,發現對于大部分星型\雪花模型,都存在多Join問題,這些Join順序如果組織不好,性能就會很差,如果組織得當,性能就會很好。比如Query Q3:
select dt.d_year,item.i_brand_id brand_id,item.i_brand brand,sum(ss_ext_sales_price) sum_agg
from date_dim dt,store_sales,item
where dt.d_date_sk = store_sales.ss_sold_date_sk
and store_sales.ss_item_sk = item.i_item_sk
and item.i_manufact_id =436
and dt.d_moy =12
groupby dt.d_year , item.i_brand , item.i_brand_id
order by dt.d_year , sum_agg desc , brand_id
limit 10
上述Query涉及到3張表,一張事實表store_sales(數據量大)和兩張維度表(數據量小),三表之間的關系如下圖所示:
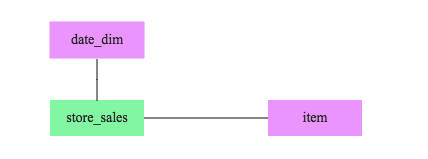
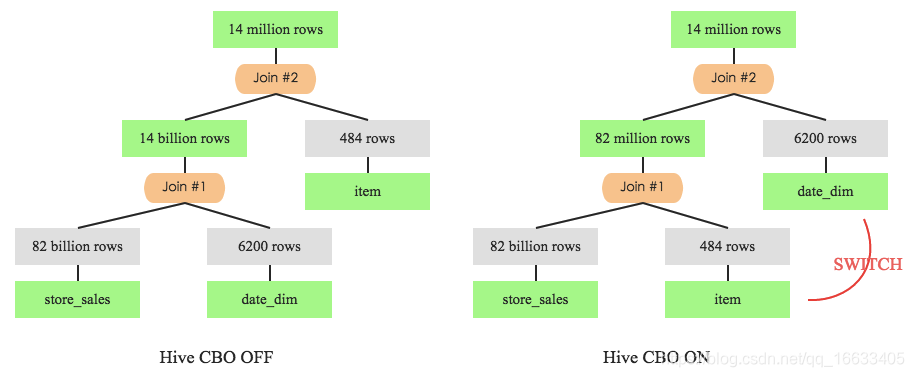
這里就涉及上文提到的Join順序問題,從原始表來看,date_dim有73049條記錄,而item有462000條記錄。很顯然,如果沒有其他暗示的話,Join順序必然是store_sales join date_dim join item。但是,where條件中還帶有兩個條件,CBO會根據過濾條件對過濾后的數據進行評估,結果如下:
| Table | Table | Cardinality after filter | Selectivity |
|---|---|---|---|
| date_dim | 73,049 | 6200 | 8.5% |
| item | 462,000 | 484 | 0.1% |
根據上表所示,過濾后的數據量item明顯比date_dim小的多,劇情反轉的有點快。于是乎,經過CBO之后Join順序就變成了store_sales join item join date_time,為了進一步確認,可以在開啟CBO前后分別記錄該SQL的執行計劃,如下圖所示:
左圖是未開啟CBO特性時Q3的執行計劃,store_sales先與date_dim進行join,join后的中間結果數據集有140億條。而再看右圖,store_sales先于item進行join,中間結果只有8200w條。很顯然,后者執行效率會更高,實踐出真知,來看看兩者的實際執行時間:
| Table | Query Response Time(seconds) | Intermediate Rows | CPU(seconds) |
|---|---|---|---|
| Q3 CBO OFF | 255 | 13,987,506,884 | 51,967 |
| Q3 CBO ON | 142 | 86,217,653 | 35,036 |
上圖很明顯的看出Q3在CBO的優化下性能將近提升了1倍,與此同時,CPU資源使用率也降低了一半左右。不得不說,TPCDS中有很多相似的Query,有興趣的同學可以深入進一步深入了解。
Impala – CBO優化效果
和Hive優化的原理相同,也是針對復雜join的執行順序、Join的執行策略選擇優化等方面進行的優化,本人使用TPC-DS對Impala在開啟CBO特性前后的部分Query進行了性能測試,測試結果如下圖所示: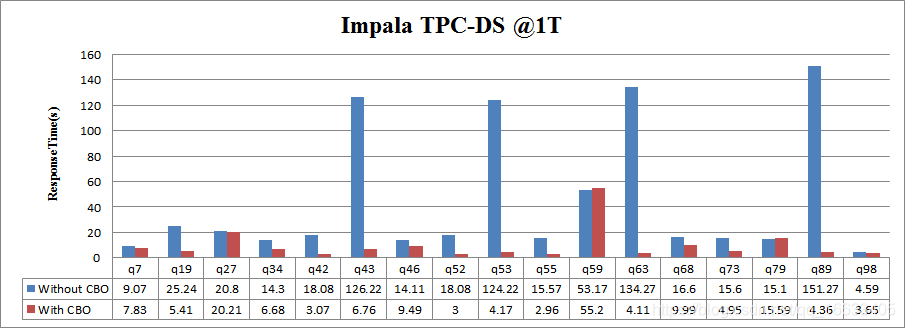
參考:
http://hbasefly.com/2017/05/04/bigdata%ef%bc%8dcbo/
)




分頁器paginate方法)

簡介)








的開發過程(1))

 E: 無法獲取 dpkg 前端鎖 (/var/lib/dpkg/lock-front)
