人體動作識別(Human activity recognition)是健康領域一個熱點問題,它通過加速度計,陀螺儀等傳感器記錄人體運動數據,對人體動作進行識別。最近用微信小程序做了一個動作識別的項目,同時嘗試部署了單片機。首先奉上b站的視頻鏈接,里面詳細介紹了項目的思路和代碼:https://b23.tv/4VRvff
下面我將這個過程分成以下幾部分給大家進行講解:
1.數據收集
人體動作的數據是通過手機內部自帶的六軸傳感器收集的,借助于微信小程序的API可以直接調用。
其中蹲起的數據采集頁面如下圖所示:

右手持手機,點擊“開始讀取”后,開始做深蹲,加速度軸和陀螺儀的實時數據會在數據框內顯示。做完動作后點擊存儲,會將采集的數據上傳到微信自帶的云數據庫,并且關閉加速度計和陀螺儀。
我們將每個動作分為不同的document,每個實驗者作為一個record,在數據庫中進行存儲。每條record由六個軸的六個數組、時間戳數組和用戶的其他信息組成,數組長度約為采樣頻率f*采樣總時間,大約是700。
將數據導出成JSON或csv文件之后便可以開始信號處理了。
2.信號處理
2.1濾波
本部分中的信號處理是通過python中的signal包來完成。
將csv文件導入到python中,將數組長度統一為700。首先我們可以先直觀地感受一下數據:
plt展示出六個軸的數據,可以看出某些軸的數據是有明顯的周期性的,但是噪聲較多,需要進行濾波處理。
首先使用中值濾波器,這可以通過signal包中的medfilt函數來完成:
#中值濾波
然后是巴特沃斯濾波器,同樣是使用signal包中的函數來完成:
# butterworth濾波器
2.2數據切割
數據經過濾波之后在圖像上的體現是變得更加平滑,濾掉了高頻的噪音,此時我們將數據進行切割:設定一個時間窗口,以及一個overlap的比例,將數據切分成許多小段。這樣就增加了樣本的數量,滿足機器學習需要的數據量。
2.3特征提取
注意,通過微信小程序提取的數據為時間序列,本身不能作為輸入直接喂給機器學習模型,而是需要從中提取一些特征,作為輸入向量。此處我們首先將數據進行了快速傅里葉變換,計算功率譜密度、自相關函數,在此基礎上得到了時間序列的特征向量。將以上功能封裝到一個函數中:
def 當我們將時域數據轉換到頻域數據上之后,便可以提取特征,使用分類器進行建模。提取特征的常用方法可以是信號的頻率分量以及在此分量上的振幅。
3.模型構建
數據的處理工作完成之后就要開始機器學習的核心部分:模型訓練了。此處我們用python強大的機器學習第三方包:sklearn來完成這一部分的工作。
3.1模型選擇
機器學習模型眾多,如何選擇一個適合自己的呢?在此我們選擇了一些常用的機器學習模型,查看它們在此數據集上的表現。
首先構建一個裝有模型的字典:
dict_classifiers 然后,我們可以在此字典和每個分類器上迭代:
- 訓練分類器.fit(X_train, Y_train)
- 評估分類器在訓練集中的性能.score(X_train, Y_train)
- 評估分類器在測試集上的性能.score(X_test, Y_test)
- 記錄訓練分類器所需的時間。
- 將訓練模型、訓練分數、測試分數和訓練時間保存到字典中。如有必要,此字典可以使用 Python 的pickle模塊保存。
def 最終結果如下所示:
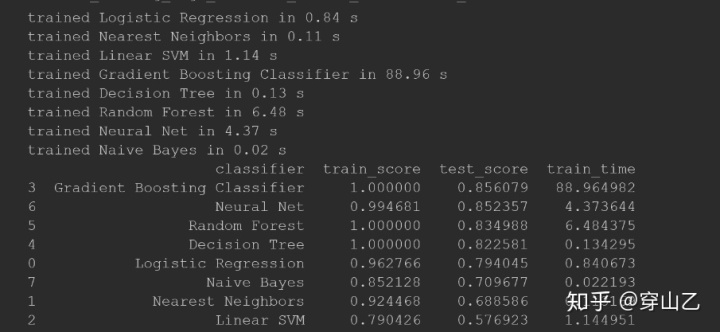
可以發現,Gradient Boosting算法效果是最好的,同時訓練時間也最長,高達88秒;表現最不好的是SVM;訓練時間最短的是Native Bayes。
通過模型的訓練與對比,結合我們自身的需求,選擇最為合適的模型進行參數調優。考慮到本項目后期需要部署JS,因此需要在算法的復雜程度和準確率之間取舍,此處我選擇MLP(多層神經網絡)作為最終的模型。
3.2超參數調優
當選擇好合適的模型之后,我們就需要調整模型的參數,使其表現的最好,這就是超參數調優。MLP模型的參數主要有:激活函數、學習率
MLP_params可以看出,當激活函數relu,alpha=1,隱藏層神經元個數為100時,MLP模型表現是最好的;同時relu函數運算較快,100個神經元大小適中,用來部署JS較為合適。
模型訓練好后,用sklearn自帶的函數輸出權重矩陣和偏置向量,保存到csv文件中,便于后續模型的部署。
對于大部分的機器學習教程而言,模型訓練完之后就算是萬事大吉了,但我們的目標是最終做出一個能用于實際生活的小程序,因此還需要進行模型的部署。
4.模型部署
4.1小程序部署
我們將上面保存好的csv文件復制到小程序的js里,對六軸到的數據進行計算。通過幾次實驗發現,由于安卓系統傳感器采集數據的頻率較低,因此濾波對本數據集的影響不大。同時因為時間前后的相關性,不對序列進行特征提取,直接將序列喂給模型也能達到同樣的準確率。
每隔2秒鐘對數據進行一次分類,js代碼就是根據MLP的原理進行矩陣的乘法,此處不再贅述。
4.2單片機部署
由于近些年來手環的興起,因此我也嘗試部署了單片機。這里模型比較龐大,即便是功能強大的STC8A8K系列的單片機也只有64KB的內存,是遠遠不夠的,需要進行內存擴展。此處給出我的老師提供的一種方案:
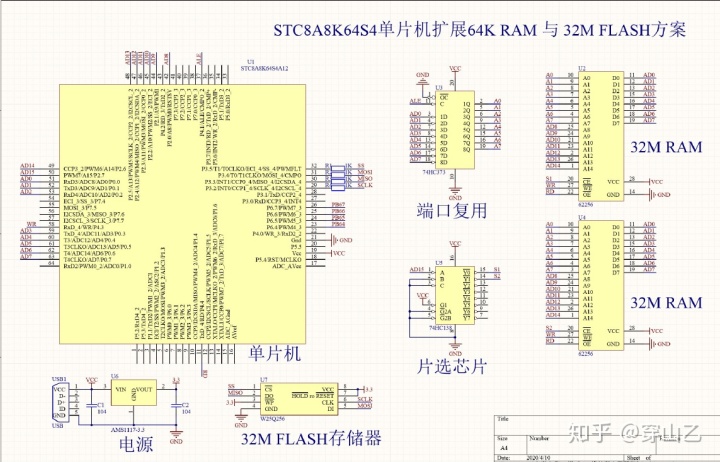
按照上述方案,我使用了洞洞板+單片機的方式進行了連接,洞洞板上是內存擴展芯片,另一塊板子是做其他項目時用到的,這里只用到了它的單片機:

十分凌亂,大家實驗沒問題之后還是用PCB打樣吧。。。
最終我通過離線的方式,測試準確率達到了70%,實現了單片機的部署。
寫在最后
本文從零開始實現了一個能夠落地的人工智能項目,同時部署到小程序端可以實現離線識別,擺脫了對網絡的依賴。
非常感謝大家的耐心閱讀,我也是一名正在學習中的大二學生,所寫內容如有不當之處歡迎大家批評指正。
















)


