循環神經網絡(RNN)、LSTM 與 GRU (一)
文章目錄
- 循環神經網絡(RNN)、LSTM 與 GRU (一)
- 循環神經網絡(RNN)、LSTM 與 GRU
- 一、RNN(Recurrent Neural Network)
- 1. 基本思想
- 2. 數學表達
- 3. 優缺點
- 二、LSTM(Long Short-Term Memory)
- 1. 引入背景
- 2. 核心結構
- 3. 狀態更新
- 4. 優缺點
- 三、GRU(Gated Recurrent Unit)
- 1. 概述
- 2. 核心公式
- 3. 特點
- 四、對比總結
- 五、結構對比圖
- 六、結語
循環神經網絡(RNN)、LSTM 與 GRU
一、RNN(Recurrent Neural Network)
1. 基本思想
- RNN 通過在網絡中引入“循環”結構,使得當前時刻的輸出不僅依賴當前輸入,還依賴之前的隱藏狀態。
- 適合處理 序列數據,如文本、語音、時間序列預測。
2. 數學表達
- 隱藏層更新:
ht=f(Wxhxt+Whhht?1+bh)h_t = f(W_{xh}x_t + W_{hh}h_{t-1} + b_h) ht?=f(Wxh?xt?+Whh?ht?1?+bh?) - 輸出層:
yt=g(Whyht+by)y_t = g(W_{hy}h_t + b_y) yt?=g(Why?ht?+by?)
3. 優缺點
- 優點:能夠建模序列信息,捕捉上下文依賴。
- 缺點:存在梯度消失和梯度爆炸問題,難以學習長期依賴。
二、LSTM(Long Short-Term Memory)
1. 引入背景
- 針對 RNN 的 長期依賴問題,LSTM 在結構上引入了“門控機制”,有效緩解梯度消失問題。
- 在自然語言處理、語音識別、時間序列預測等任務中應用廣泛。
2. 核心結構
LSTM 的關鍵在于 細胞狀態(Cell State) 和 三個門(Gates):
-
遺忘門(Forget Gate):決定丟棄多少歷史信息。
ft=σ(Wf[xt,ht?1]+bf)f_t = \sigma(W_f[x_t, h_{t-1}] + b_f) ft?=σ(Wf?[xt?,ht?1?]+bf?) -
輸入門(Input Gate):決定寫入多少新信息。
it=σ(Wi[xt,ht?1]+bi)i_t = \sigma(W_i[x_t, h_{t-1}] + b_i) it?=σ(Wi?[xt?,ht?1?]+bi?)
C~t=tanh?(Wc[xt,ht?1]+bc)\tilde{C}_t = \tanh(W_c[x_t, h_{t-1}] + b_c) C~t?=tanh(Wc?[xt?,ht?1?]+bc?) -
輸出門(Output Gate):決定輸出多少細胞狀態的信息。
ot=σ(Wo[xt,ht?1]+bo)o_t = \sigma(W_o[x_t, h_{t-1}] + b_o) ot?=σ(Wo?[xt?,ht?1?]+bo?)
3. 狀態更新
- 細胞狀態:
Ct=ft?Ct?1+it?C~tC_t = f_t * C_{t-1} + i_t * \tilde{C}_t Ct?=ft??Ct?1?+it??C~t? - 隱藏狀態:
ht=ot?tanh?(Ct)h_t = o_t * \tanh(C_t) ht?=ot??tanh(Ct?)
4. 優缺點
- 優點:能解決長期依賴問題,更好地捕捉長距離信息。
- 缺點:結構復雜,計算量大,訓練速度較慢。
三、GRU(Gated Recurrent Unit)
1. 概述
- GRU 是 LSTM 的簡化版本,僅包含 更新門(Update Gate) 和 重置門(Reset Gate)。
- 沒有獨立的細胞狀態,直接用隱藏狀態傳遞信息。
2. 核心公式
- 更新門:
zt=σ(Wz[xt,ht?1])z_t = \sigma(W_z[x_t, h_{t-1}]) zt?=σ(Wz?[xt?,ht?1?]) - 重置門:
rt=σ(Wr[xt,ht?1])r_t = \sigma(W_r[x_t, h_{t-1}]) rt?=σ(Wr?[xt?,ht?1?]) - 新隱藏狀態:
h~t=tanh?(W[xt,(rt?ht?1)])\tilde{h}_t = \tanh(W[x_t, (r_t * h_{t-1})]) h~t?=tanh(W[xt?,(rt??ht?1?)]) - 最終隱藏狀態:
ht=(1?zt)?ht?1+zt?h~th_t = (1 - z_t) * h_{t-1} + z_t * \tilde{h}_t ht?=(1?zt?)?ht?1?+zt??h~t?
3. 特點
- 結構更簡潔,參數更少,訓練更快。
- 在很多任務中性能與 LSTM 接近甚至更優。
四、對比總結
| 特性 | RNN | LSTM | GRU |
|---|---|---|---|
| 結構 | 簡單,循環層 | 復雜,含門控單元(3門+細胞狀態) | 較簡潔,僅2門 |
| 長期依賴建模 | 弱 | 強 | 強 |
| 計算復雜度 | 低 | 高 | 中等 |
| 訓練速度 | 快 | 慢 | 較快 |
| 典型應用 | 簡單序列建模 | 機器翻譯、語音識別 | NLP、推薦系統、時序預測 |
五、結構對比圖
六、結語
- RNN 是序列建模的基礎,但受限于梯度消失問題。
- LSTM 通過門控機制成功解決長期依賴,是深度學習里程碑式的模型。
- GRU 在保持效果的同時,計算更高效,是實際工程中的常見選擇。
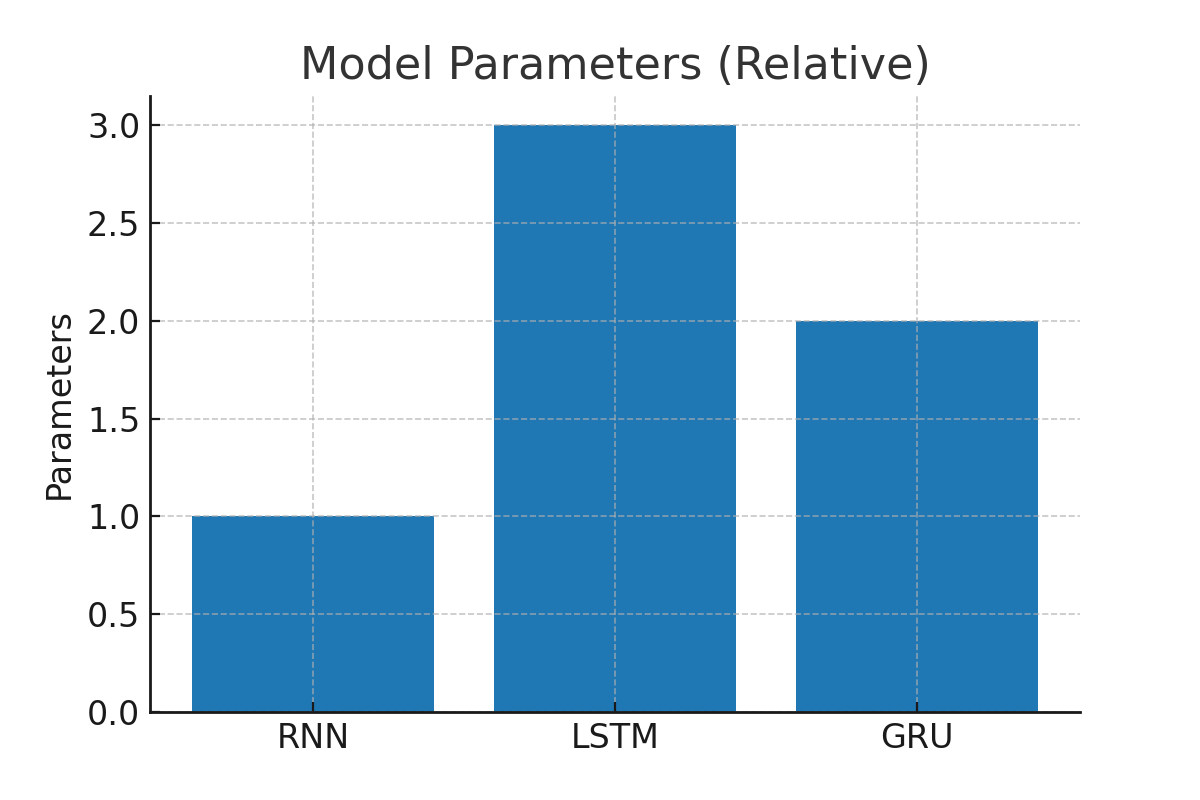
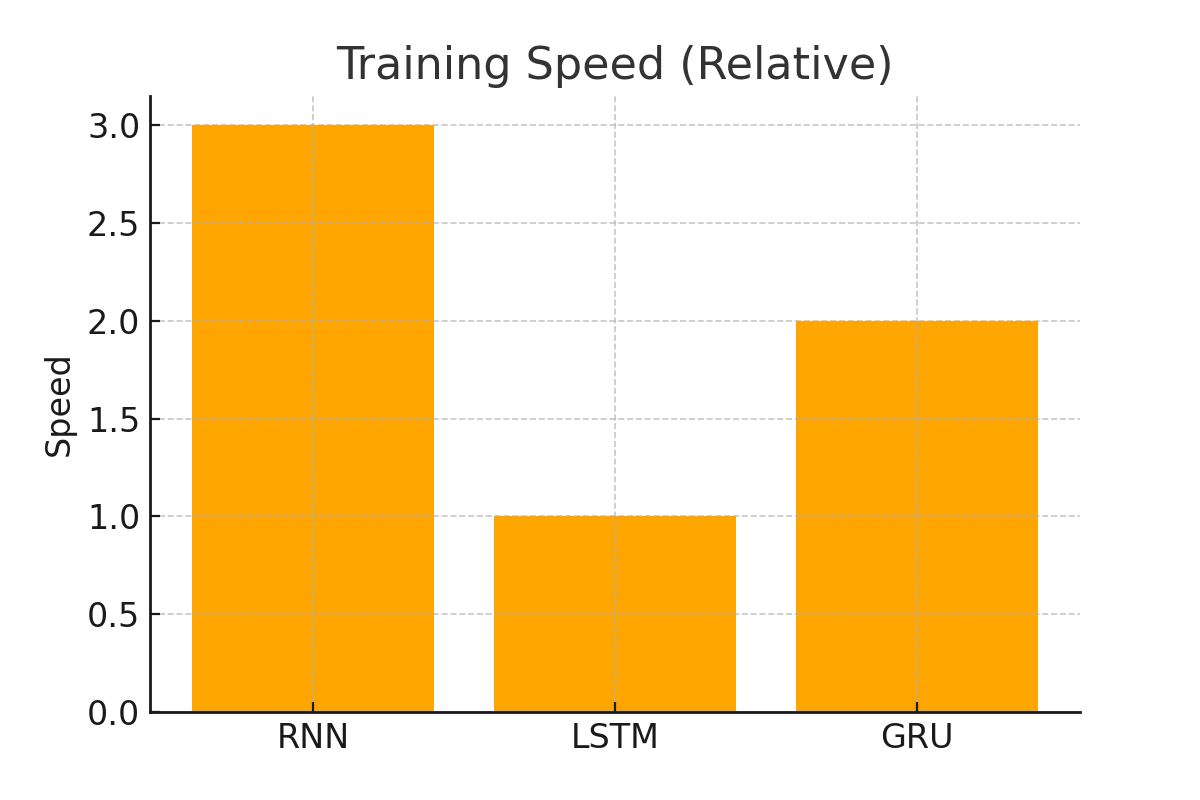
總結一句:
如果序列較短,用 RNN 即可;
如果需要捕捉長期依賴,LSTM 更穩健;
如果追求訓練速度和效果平衡,GRU 是不錯的選擇。






)

)






)
)

,95. 城市間貨物運輸 II(卡碼網),96. 城市間貨物運輸 III(卡碼網))
