非極大值抑制(Non-maximum suppression,NMS)是一種去除非極大值的算法,常用于計算機視覺中的邊緣檢測、物體識別等。
算法流程
給出一張圖片和上面許多物體檢測的候選框(即每個框可能都代表某種物體),但是這些框很可能有互相重疊的部分,我們要做的就是只保留最優的框。假設有N個框,每個框被分類器計算得到的分數為Si,(1<=i<=N)S_i, (1<=i<=N)Si?,(1<=i<=N)。
-
建造一個存放待處理候選框的集合H,初始化為包含全部N個框;建造一個存放最優框的集合M,初始化為空集。
-
將所有集合 H 中的框進行排序,選出分數最高的框 m,從集合 H 移到集合 M;
-
遍歷集合 H 中的框,分別與框 m 計算交并比(Interection-over-union,IoU),如果高于某個閾值(一般為0~0.5),則認為此框與 m 重疊,將此框從集合 H 中去除。
-
回到第1步進行迭代,直到集合 H 為空。集合 M 中的框為我們所需。
需要優化的參數
IoU 的閾值是一個可優化的參數,一般范圍為0~0.5,可以使用交叉驗證來選擇最優的參數。
示例
比如人臉識別的一個例子:
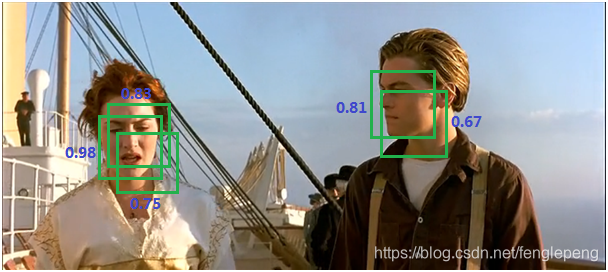
已經識別出了 5 個候選框,但是我們只需要最后保留兩個人臉。
首先選出分數最大的框(0.98),然后遍歷剩余框,計算 IoU,會發現露絲臉上的兩個綠框都和 0.98 的框重疊率很大,都要去除。
然后只剩下杰克臉上兩個框,選出最大框(0.81),然后遍歷剩余框(只剩下0.67這一個了),發現0.67這個框與 0.81 的 IoU 也很大,去除。
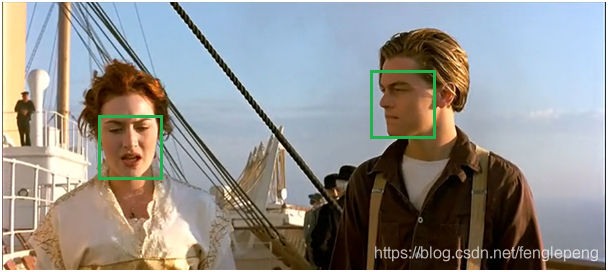
至此所有框處理完畢。
??
再比如定位一個車輛,最后算法就找出了一堆的方框,我們需要判別哪些矩形框是沒用的。非極大值抑制:先假設有6個矩形框,根據分類器類別分類概率做排序,從小到大分別屬于車輛的概率分別為A、B、C、D、E、F。
(1)從最大概率矩形框F開始,分別判斷A~E與F的重疊度IOU是否大于某個設定的閾值;
(2)假設B、D與F的重疊度超過閾值,那么就扔掉B、D;并標記第一個矩形框F,是我們保留下來的。
(3)從剩下的矩形框A、C、E中,選擇概率最大的E,然后判斷E與A、C的重疊度,重疊度大于一定的閾值,那么就扔掉;并標記E是我們保留下來的第二個矩形框。
就這樣一直重復,找到所有被保留下來的矩形框A、E。
代碼
import numpy as npdef py_cpu_nms(dets, thresh):# 單獨獲取各個參數,以下參數shape = (5,)x1 = dets[:,0]y1 = dets[:,1]x2 = dets[:,2]y2 = dets[:,3]scores = dets[:,4]areas = (y2-y1+1) * (x2-x1+1)print("areas.shape: {}".format(areas.shape))print("areas: {}".format(areas))keep = []# 得分按照由高到低排序的索引, index.shape = (6,)index = scores.argsort()[::-1]print("index.shape: {}".format(index.shape))print("index: {}".format(index))while index.size >0:# i為得分最高的索引i = index[0] # 將得分最高的索引追加到列表中keep.append(i)# 計算兩個box左上角點坐標的最大值x11、y11和右下角坐標的最小值x22、y22# x11、y11、x22、y22 shape = (5,)x11 = np.maximum(x1[i], x1[index[1:]])y11 = np.maximum(y1[i], y1[index[1:]])x22 = np.minimum(x2[i], x2[index[1:]])y22 = np.minimum(y2[i], y2[index[1:]])print("index[1:]: {}".format(index[1:]))print("x1[index[1:]]: {}".format(x1[index[1:]]))print("x11: {}".format(x11))print("x11.shape: {}".format(x11.shape))# 當兩個方框相交時,22-11最后得到w,h是正值# 當兩個方框不相交的時候,22-11最后得到w,h是負值,則設置為0# w、h shape = (5,)w = np.maximum(0, x22-x11+1)h = np.maximum(0, y22-y11+1)print("w: {}".format(w))print("w.shape: {}".format(w.shape))# 計算交集面積# overlaps.shape = (5,)overlaps = w * hprint("overlaps: {}".format(overlaps))print("overlaps.shape: {}".format(overlaps.shape))# 計算交并比# ious.shape = (5,)ious = overlaps / (areas[i] + areas[index[1:]] - overlaps)print("ious.shape: {}".format(ious.shape))print("ious: {}".format(ious))# 得到滿足閾值條件的ious中的索引(ious相比index缺少第一個最大值)ious_idx = np.where(ious<=thresh)[0]print("ious<=thres idx: {}".format(ious_idx))# ious_idx+1得到在index中的索引index = index[ious_idx + 1] # because index start from 1print("index: {}".format(index))return keepif __name__ == "__main__":boxes=np.array([[100,100,210,210,0.72], # 0[250,250,420,420,0.8], # 1[220,220,320,330,0.92], # 2[100,100,210,210,0.72], # 3[230,240,325,330,0.81], # 4[220,230,315,340,0.9]]) # 5keep = py_cpu_nms(boxes, thresh=0.7)print("keep: {}".format(keep))






- 區域候選網絡)


)



)





)