什么是ROI?
ROI是 Region of interest 的簡寫,指的是 Faster R-CNN 結構中,經過 RPN 層后,產生的 proposal 對應的 box 框。
ROI Pooling 顧名思義,是 pooling 層的一種,而且是針對 ROIs 的 pooling。整個 ROI 的過程,就是將這些 proposal 摳出來的過程,得到大小統一的 feature map。
ROI Pooling 的輸入
ROI Pooling 該層有兩個輸入:
- 從具有多個卷積核池化的深度網絡中獲得的固定大小的feature maps;
- 一個表示所有 ROI 的 N*5 的矩陣,其中N表示ROI的數目。一列表示圖像index,其余四列表示其余的左上角和右下角坐標;
ROI Pooling 的輸出
輸出是 batch 個 vector,其中 batch 的值等于 roi 的個數,vector的大小為 channel?w?hchannel*w*hchannel?w?h;ROI Pooling 的過程就是將一個個大小不同的 box 矩形框,都映射成大小為 w?hw*hw?h 的矩形框;

如圖所示,我們先把 roi 中的坐標映射到 feature map 上,映射規則比較簡單,就是把各個坐標除以輸入圖片與 feature map 的大小的比值,得到了 feature map 上的 box 坐標后,我們使用 pooling 得到輸出;由于輸入的圖片大小不一,所以這里我們使用的 spp pooling,spp pooling 在 pooling 的過程中需要計算 pooling 后的結果對應的像素點反映射到 feature map 上所占的范圍,然后在那個范圍中進行取 max 或者取 average。理解起來有點繞,看后面,你會豁然開朗。
ROI pooling具體操作如下
- 根據輸入image,將 ROI 映射到 feature map 對應位置;
- 將映射后的區域劃分為相同大小的 sections(sections數量與輸出的維度相同);
- 對每個 sections 進行 max pooling 操作;
這樣我們就可以從不同大小的方框得到固定大小的相應的 feature maps。值得一提的是,輸出的 feature maps 的大小不取決于 ROI 和卷積 feature maps 大小。ROI pooling 最大的好處就在于極大地提高了處理速度。
ROI pooling example
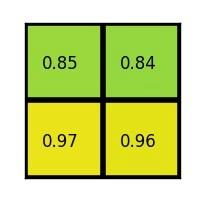
我們有一個 8?88*88?8 大小的 feature map,一個ROI,以及輸出大小為 2?22*22?2.
輸入的固定大小的feature map
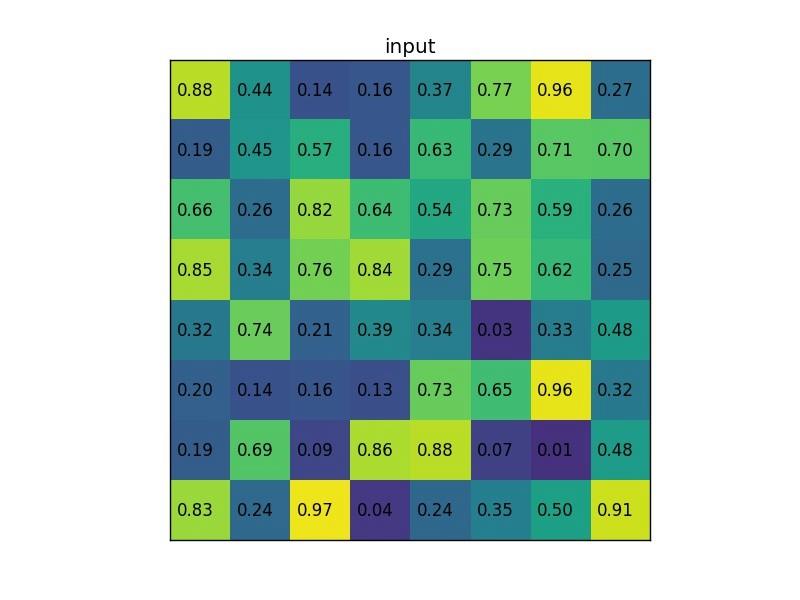
region proposal 投影之后位置(左上角,右下角坐標):(0,3),(7,8)(0,3),(7,8)(0,3),(7,8)。
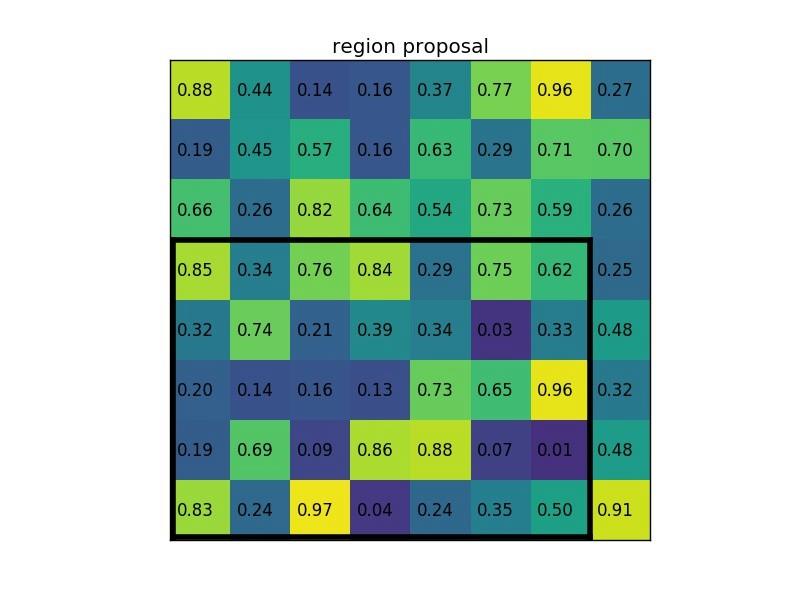
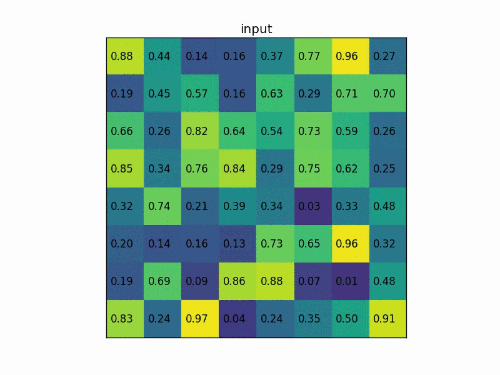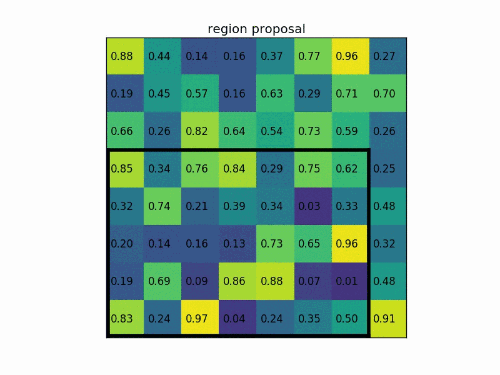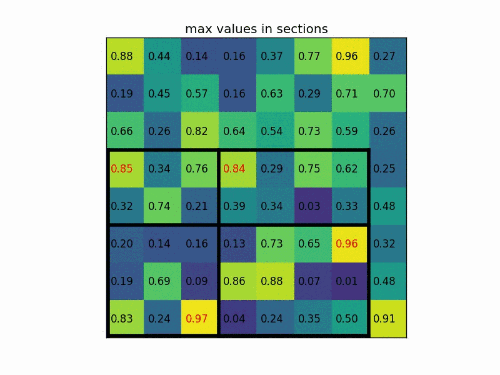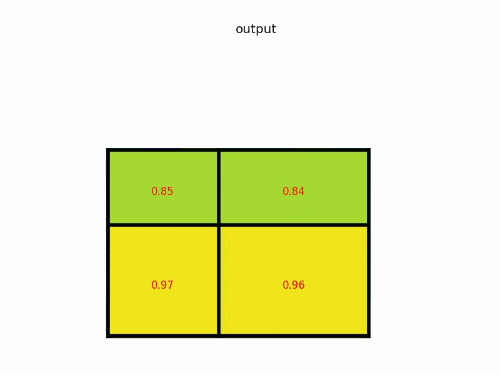
將其劃分為(2*2)個 sections(因為輸出大小為2*2),我們可以得到:
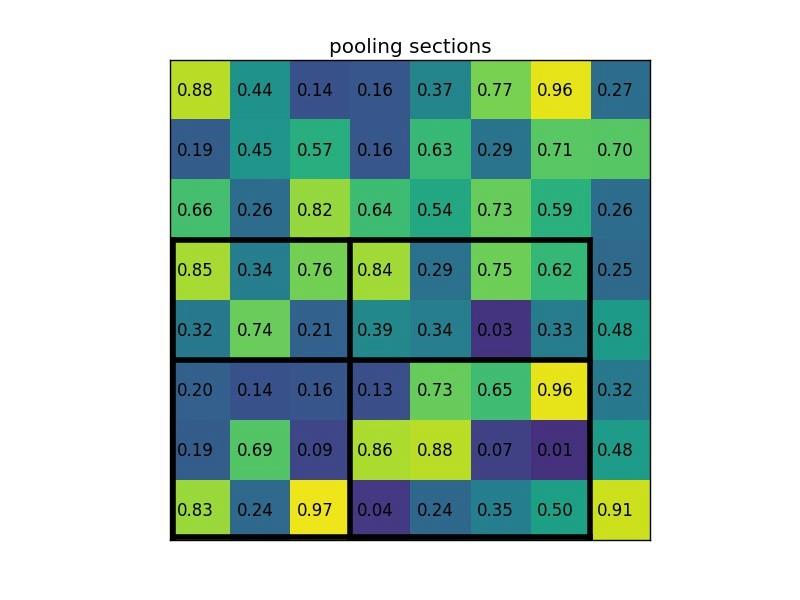
對每個section做max pooling,可以得到:
整體過程如下:
說明:在此案例中 region proposals 是 5*7 大小的,在 pooling 之后需要得到 2*2 的,所以在 5*7 的特征圖劃分成 2*2 的時候不是等分的,行是 5/2,第一行得到2,剩下的那一行是3,列是7/2,第一列得到3,剩下那一列是4。
CNN 中的ROI Pooling
在CNN中,Pooling 層的作用主要有兩個:
- 引入 invariance,包括 translation-invariance,rotation-invariance,scale-invariance。
- 完成 feature map 的聚合,實現數據降維,防止過擬合。
ROI Pooling 將不同輸入尺寸的 feature map 通過分塊池化的方法得到固定尺寸的輸出,其思想來自于 SPPNet。
rbg 大神在 Fast RCNN 中使用時,將 sppnet 中多尺度的池化簡化為單尺度,只輸出固定尺寸為(w, h)的 feature map。
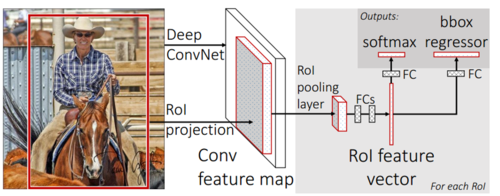
在 Fast R-CNN 網絡中,原始圖片經過多層卷積與池化后,得到整圖的 feature map。而由 selective search 產生的大量 proposal 經過映射可以得到其在 feature map 上的映射區域(ROIs),這些ROIs即作為ROI Pooling層的輸入。
ROI Pooling時,將輸入的 h?wh * wh?w 大小的 feature map 分割成 H?WH * WH?W 大小的子窗口(每個子窗口的大小約為 h/H,w/Wh/H,w/Wh/H,w/W,其中H、W為超參數,如設定為7 x 7),對每個子窗口進行 max-pooling 操作,得到固定輸出大小的 feature map。而后進行后續的全連接層操作。
ROI Pooling層的加入對R-CNN網絡的改進
在R-CNN中,整個檢測的流程是:

R-CNN網絡的主要問題有:
- 使用 selective search 產生 proposal,操作耗時,且不利于網絡的整體訓練和測試
- 產生的 proposal 需要經過 warp 操作再送入后續網絡,導致圖像的變形和扭曲
- 每一個 proposal 均需要單獨進行特征提取,重復計算量大
ROI Pooling的加入,相對于R-CNN網絡來說,至少有兩個改善:
- 由于ROI Pooling可接受任意尺寸的輸入,warp操作不再需要,這有效避免了物體的形變扭曲,保證了特征信息的真實性
- 不需要對每個proposal都提取特征,采用映射方式從整張圖片的 feature map 上獲取ROI feature區域
除了上述兩個改進外,其實還有一點。R-CNN 中在獲取到最終的 CNN 特征后先采用 SVM 進行類別判斷,再進行 bounding-box 的回歸得到位置信息。整個過程是個串行的流程。這極大地影響了網絡的檢測速度。Fast R-CNN 中則將 Classification 和 regression 的任務合二為一,變成一個 multi-task 的模型,實現了特征的共享與速度的進一步提升。
不知大家注意沒有,Fast R-CNN 只是解決了R-CNN中的兩點問題,而仍然沿用了 R-CNN 中 selective search 生成 proposal 的方法。這一方法產生的 proposal 即使經過NMS也會達到 2k~3k 個。一方面生成過程耗時耗力,另一方面給存儲也帶來壓力。
那么,有沒有辦法改進呢?答案當然是 Yes。那就是 Faster R-CNN 的提出。


- 區域候選網絡)


)



)





)



