redis官網
微軟寫的windows下的redis
我們下載第一個
額案后基本一路默認就行了
安裝后,服務自動啟動,以后也不用自動啟動。
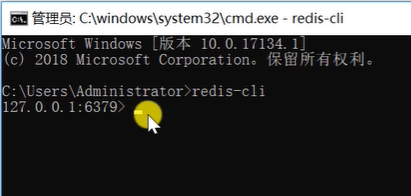
出現這個表示我們連接上了。
?
redis命令參考鏈接
String
字符串結構
struct sdshdr{//記錄buf數組中已使用字節的數量int len;//記錄buf數組中未使用的數量int free;//字節數組,用于保存字符串char buf[];
}常見操作
127.0.0.1:6379> set hello world
OK
127.0.0.1:6379> get hello
"world"
127.0.0.1:6379> del hello
(integer) 1
127.0.0.1:6379> get hello
(nil)
127.0.0.1:6379>應用場景
String是最常用的一種數據類型,普通的key/value存儲都可以歸為此類,value其實不僅是String,也可以是數字:比如想知道什么時候封鎖一個IP地址(訪問超過幾次)。INCRBY命令讓這些變得很容易,通過原子遞增保持計數。
LIST
數據結構
typedef struct listNode{//前置節點struct listNode *prev;//后置節點struct listNode *next;//節點的值struct value;
}常見操作
> lpush list-key item
(integer) 1
> lpush list-key item2
(integer) 2
> rpush list-key item3
(integer) 3
> rpush list-key item
(integer) 4
> lrange list-key 0 -1
1) "item2"
2) "item"
3) "item3"
4) "item"
> lindex list-key 2
"item3"
> lpop list-key
"item2"
> lrange list-key 0 -1
1) "item"
2) "item3"
3) "item"應用場景
Redis list的應用場景非常多,也是Redis最重要的數據結構之一。
我們可以輕松地實現最新消息排行等功能。
Lists的另一個應用就是消息隊列,可以利用Lists的PUSH操作,將任務存在Lists中,然后工作線程再用POP操作將任務取出進行執行。
HASH
數據結構
dictht是一個散列表結構,使用拉鏈法保存哈希沖突的dictEntry。
typedef struct dictht{//哈希表數組dictEntry **table;//哈希表大小unsigned long size;//哈希表大小掩碼,用于計算索引值unsigned long sizemask;//該哈希表已有節點的數量unsigned long used;
}typedef struct dictEntry{//鍵void *key;//值union{void *val;uint64_tu64;int64_ts64;}struct dictEntry *next;
}Redis的字典dict中包含兩個哈希表dictht,這是為了方便進行rehash操作。在擴容時,將其中一個dictht上的鍵值對rehash到另一個dictht上面,完成之后釋放空間并交換兩個dictht的角色。
typedef struct dict {dictType *type;void *privdata;dictht ht[2];long rehashidx; /* rehashing not in progress if rehashidx == -1 */unsigned long iterators; /* number of iterators currently running */
} dict;rehash操作并不是一次性完成、而是采用漸進式方式,目的是為了避免一次性執行過多的rehash操作給服務器帶來負擔。
漸進式rehash通過記錄dict的rehashidx完成,它從0開始,然后沒執行一次rehash例如在一次 rehash 中,要把 dict[0] rehash 到 dict[1],這一次會把 dict[0] 上 table[rehashidx] 的鍵值對 rehash 到 dict[1] 上,dict[0] 的 table[rehashidx] 指向 null,并令 rehashidx++。
在 rehash 期間,每次對字典執行添加、刪除、查找或者更新操作時,都會執行一次漸進式 rehash。
采用漸進式rehash會導致字典中的數據分散在兩個dictht中,因此對字典的操作也會在兩個哈希表上進行。
例如查找時,先從ht[0]查找,沒有再查找ht[1],添加時直接添加到ht[1]中。
常見操作
> hset hash-key sub-key1 value1
(integer) 1
> hset hash-key sub-key2 value2
(integer) 1
> hset hash-key sub-key1 value1
(integer) 0
> hgetall hash-key
1) "sub-key1"
2) "value1"
3) "sub-key2"
4) "value2"
> hdel hash-key sub-key2
(integer) 1
> hdel hash-key sub-key2
(integer) 0
> hget hash-key sub-key1
"value1"
> hgetall hash-key
1) "sub-key1"
2) "value1"SET
常見操作
> sadd set-key item
(integer) 1
> sadd set-key item2
(integer) 1
> sadd set-key item3
(integer) 1
> sadd set-key item
(integer) 0
> smembers set-key
1) "item2"
2) "item"
3) "item3"
> sismember set-key item4
(integer) 0
> sismember set-key item
(integer) 1
> srem set-key item
(integer) 1
> srem set-key item
(integer) 0
> smembers set-key
1) "item2"
2) "item3"應用場景
Redis為集合提供了求交集、并集、差集等操作,故可以用來求共同好友等操作。
ZSET
數據結構
typedef struct zskiplistNode{//后退指針struct zskiplistNode *backward;//分值double score;//成員對象robj *obj;//層struct zskiplistLever{//前進指針struct zskiplistNode *forward;//跨度unsigned int span;}lever[];}typedef struct zskiplist{//表頭節點跟表尾結點struct zskiplistNode *header, *tail;//表中節點的數量unsigned long length;//表中層數最大的節點的層數int lever;}跳躍表,基于多指針有序鏈實現,可以看作多個有序鏈表。
與紅黑樹等平衡樹相比,跳躍表具有以下優點:
- 插入速度非常快速,因為不需要進行旋轉等操作來維持平衡性。
- 更容易實現。
- 支持無鎖操作。
常見操作
> zadd zset-key 728 member1
(integer) 1
> zadd zset-key 982 member0
(integer) 1
> zadd zset-key 982 member0
(integer) 0
> zrange zset-key 0 -1
1) "member1"
2) "member0"
> zrange zset-key 0 -1 withscores
1) "member1"
2) "728"
3) "member0"
4) "982"
> zrangebyscore zset-key 0 800 withscores
1) "member1"
2) "728"
> zrem zset-key member1
(integer) 1
> zrem zset-key member1
(integer) 0
> zrange zset-key 0 -1 withscores
1) "member0"
2) "982"應用場景
以某個條件為權重,比如按頂的次數排序
ZREVRANGE命令可以用來按照得分來獲取前100名的用戶,ZRANK可以用來獲取用戶排名,非常直接而且操作容易。
Redis sorted set的使用場景與set類似,區別是set不是自動有序的,而sorted set可以通過用戶額外提供一個優先級(score)的參數來為成員排序,并且是插入有序的,即自動排序。
?
-Argparse 簡易使用教程)


-元組tuple)
 Keras)
)
-數據載入接口:Dataloader、datasets)
)
-- NoSQL數據庫)

-字典dictionary、集合)


)
-字符串、Unicode字符串)

-高級數據類型的公共方法)


--名片管理系統開發)