文章目錄
- 目錄
- 1.spark介紹
- 1.1 spark介紹
- 1.2 scale介紹
- 1.3 spark和Hadoop比較
- 2.spark生態系統
- 3.spark運行框架
- 3.1 基本概念
- 3.2 架構的設計
- 3.3 spark運行基本流程
- 3.4 spark運行原理
- 3.5 RDD運行原理
- 3.5.1 設計背景
- 3.5.2 RDD概念和特性
- 3.5.3 RDD之間的依賴關系
- 3.5.4 stage的劃分
- 3.5.5 RDD的運行過程
- 4.spark SQL
- 4.1 shark的介紹
- 4.2 spark SQL的介紹
- 5.spark的部署和運行
- 5.1 三種部署方式
- 5.2 從Hadoop+Strom 架構轉向spark架構
- 5.3 Hadoop 和spark的統一部署
- 6.spark編程實踐
- 6.1 spark安裝
- 6.2 啟動spark shell
- 6.3 spark RDD的操作
- 6.4 spark應用程序
目錄
1.spark介紹
1.1 spark介紹


spark不僅僅是一個計算框架,而是一個大數據處理的平臺,或者說生態。
1.2 scale介紹

1.3 spark和Hadoop比較



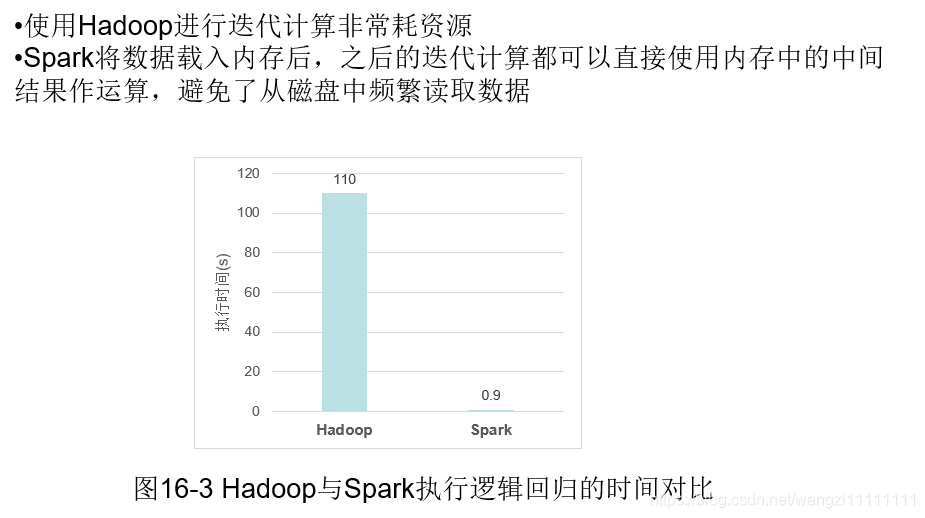
spark將運行的中間結果寫入內存,而不是如MapReduce那樣每次都寫入磁盤,所以速度非常快,那么肯定就有疑問,內存相比于磁盤來說,那么小,如何解決大數據的中間結果的存儲,spark是采用優先寫內存,內存寫滿后,才往磁盤中寫入。
2.spark生態系統


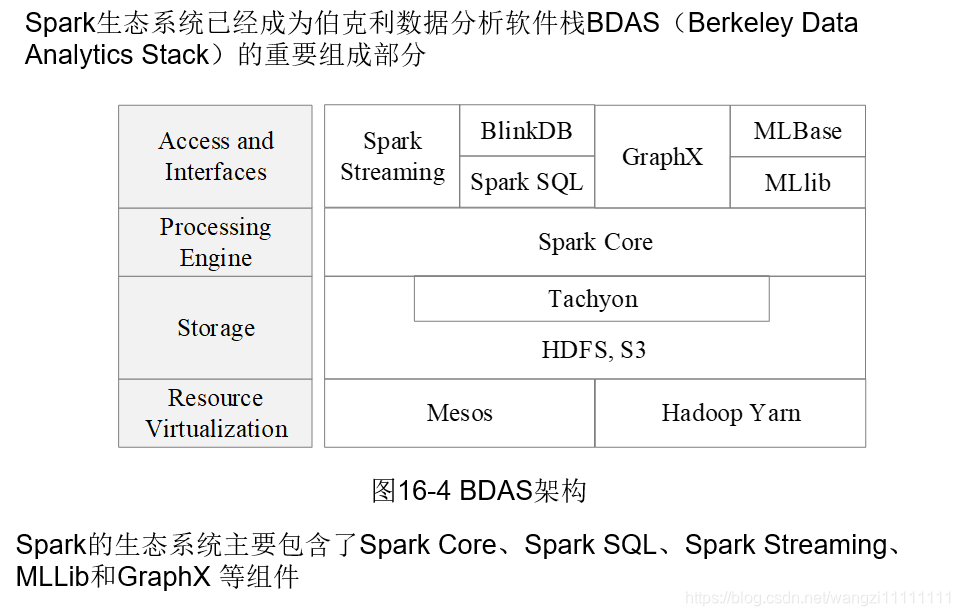
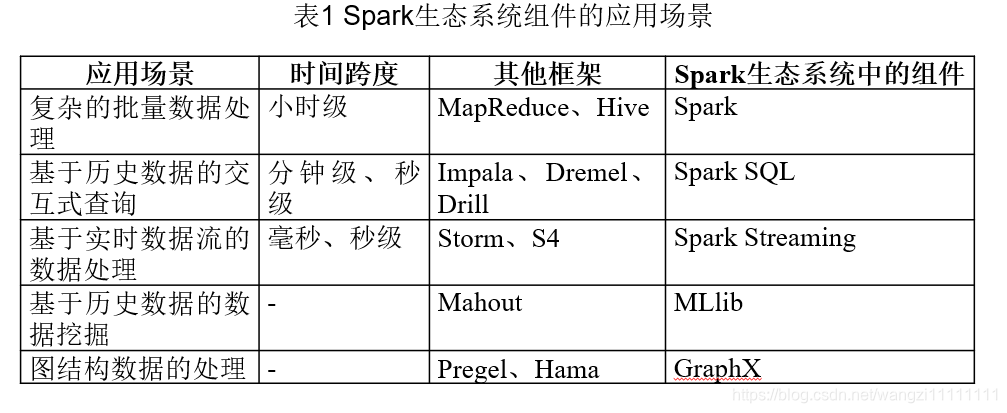
3.spark運行框架
3.1 基本概念

3.2 架構的設計
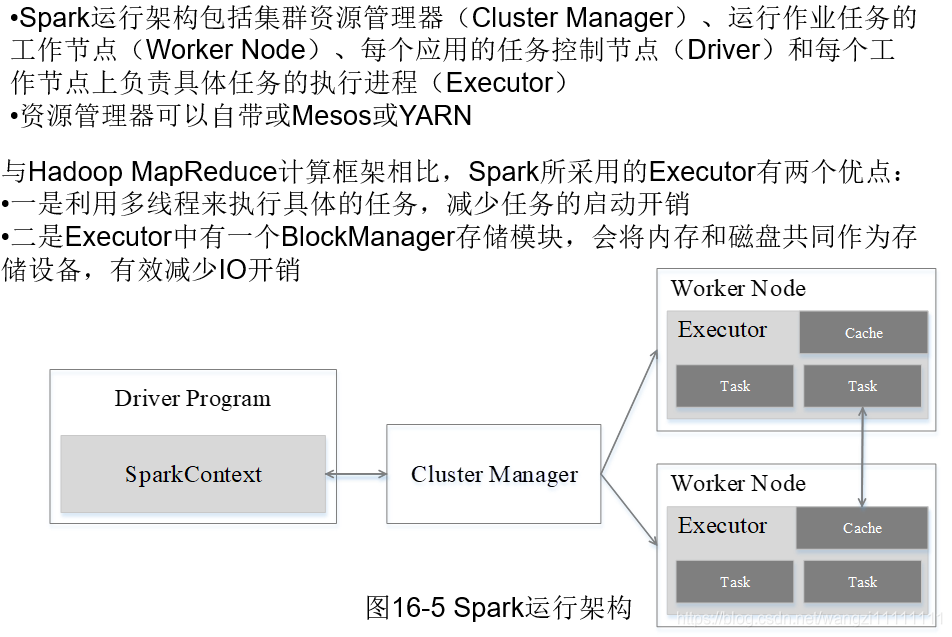

3.3 spark運行基本流程
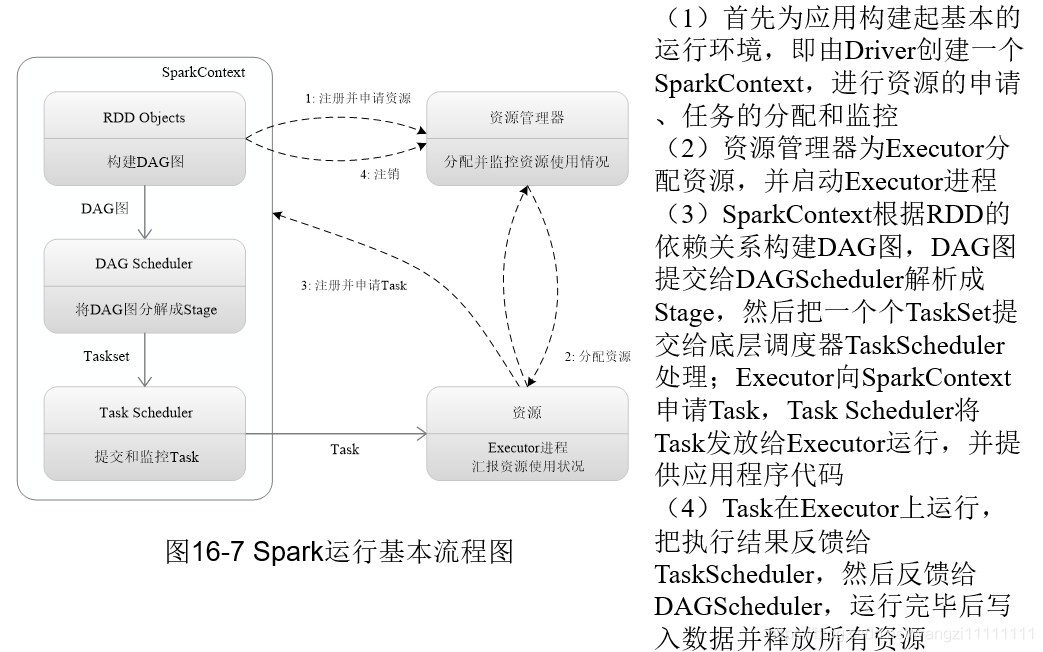
3.4 spark運行原理

3.5 RDD運行原理
3.5.1 設計背景

3.5.2 RDD概念和特性


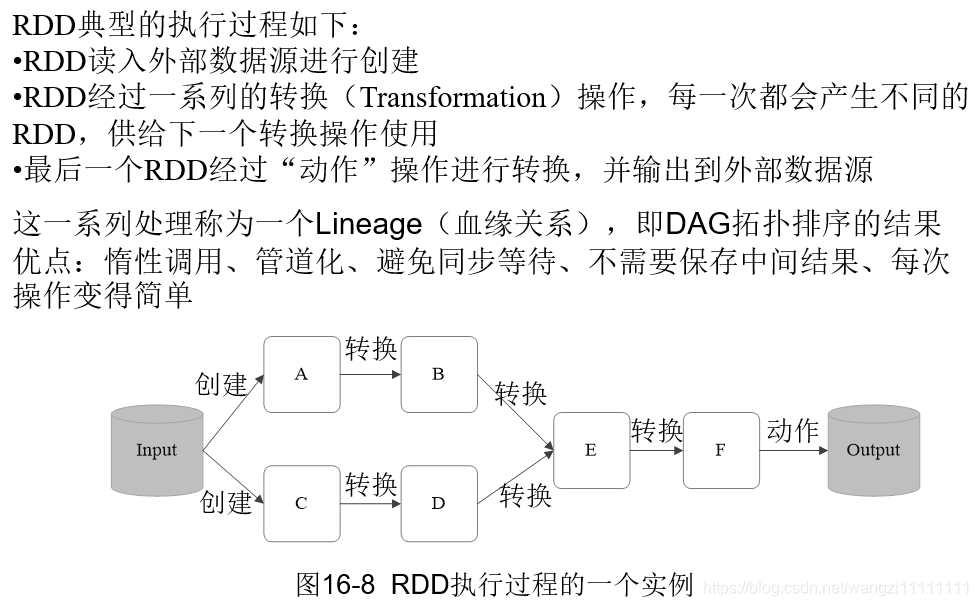

3.5.3 RDD之間的依賴關系
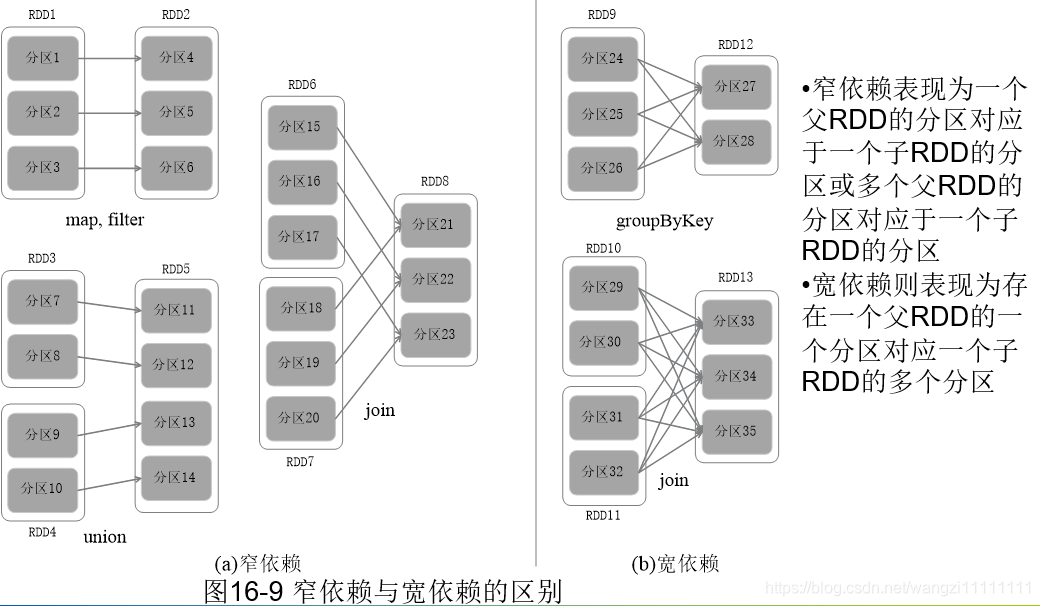
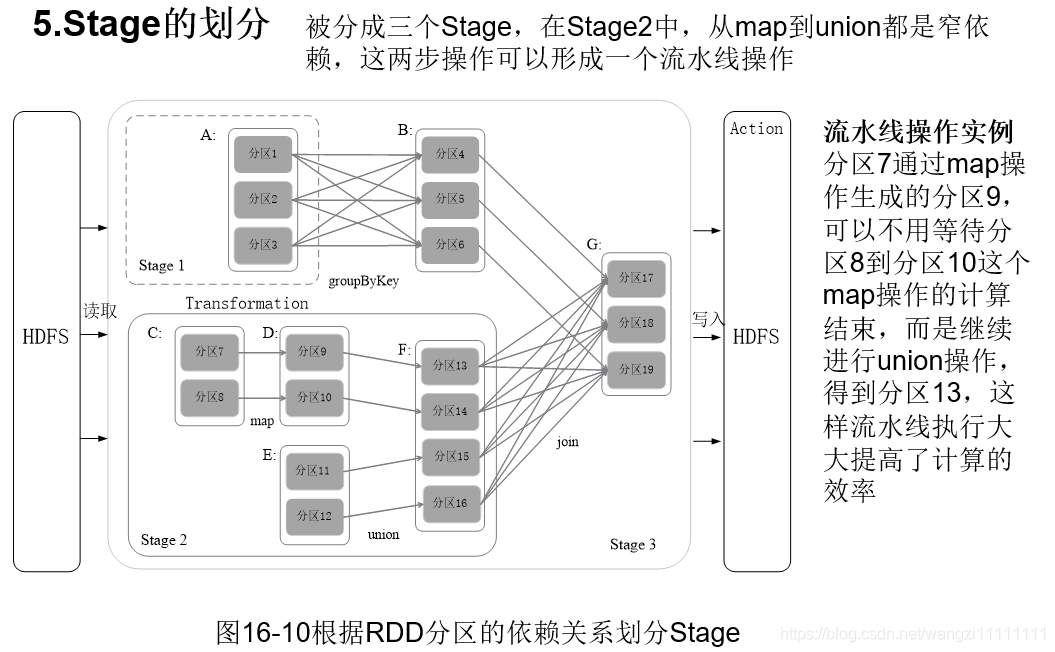
3.5.4 stage的劃分


3.5.5 RDD的運行過程

4.spark SQL
4.1 shark的介紹
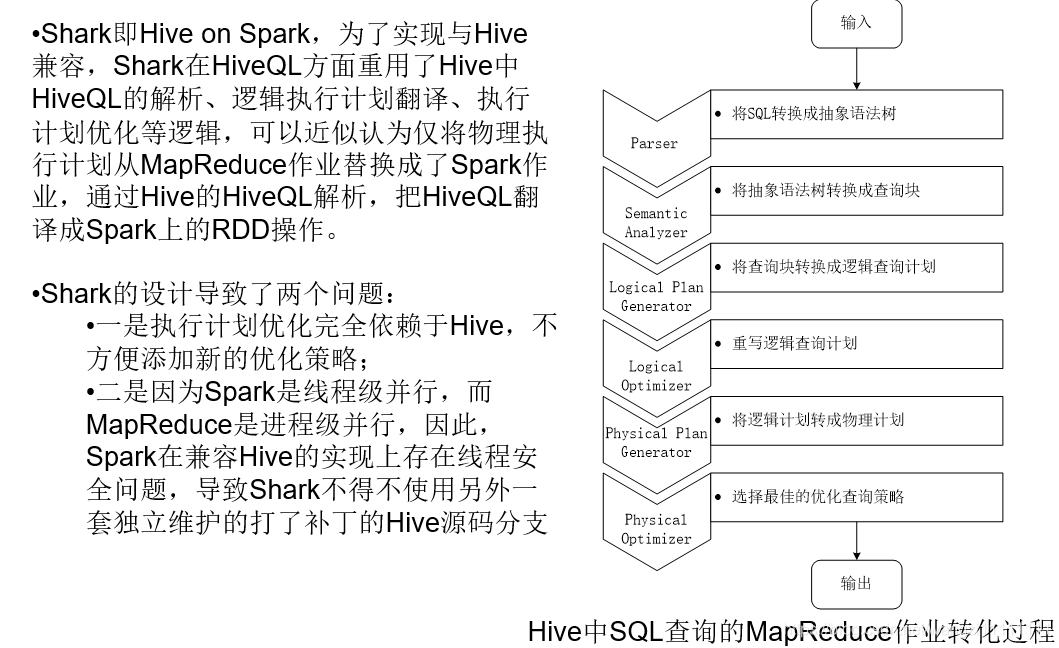
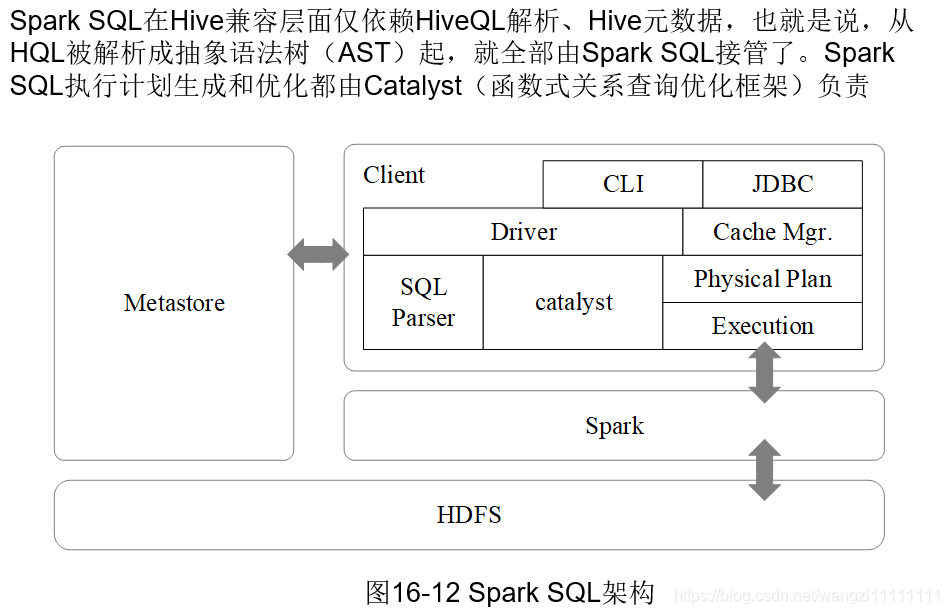
4.2 spark SQL的介紹

5.spark的部署和運行
5.1 三種部署方式

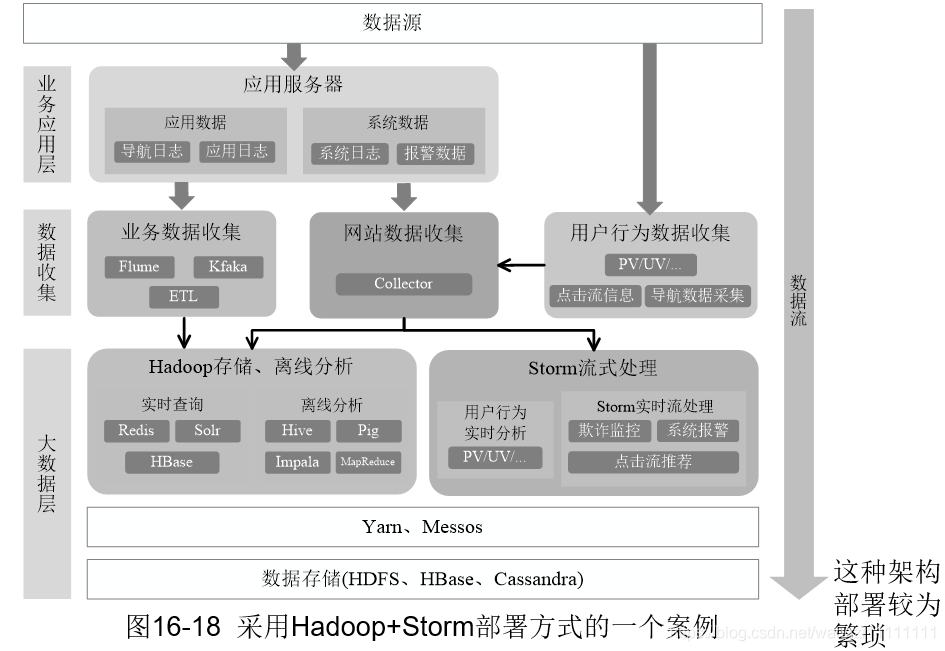
5.2 從Hadoop+Strom 架構轉向spark架構

5.3 Hadoop 和spark的統一部署

6.spark編程實踐
參考博客
6.1 spark安裝


6.2 啟動spark shell

6.3 spark RDD的操作




6.4 spark應用程序





![Python的Pexpect詳解 [圖片]](http://pic.xiahunao.cn/Python的Pexpect詳解 [圖片])


-隨機變量函數變換)

-Numpy 簡易使用教程)
)



--面向對象1-封裝)
)



-流型)
)
)
