文章目錄
- 1.stacking模型以及做模型融合的知識
- 1.1 從提交結果中融合
- 1.2 stacking
- 1.3 blending
- 2. 怎樣去優化SVM算法模型的?
- 2.1 SMO優化算法
- 2.2 libsvm 和 Liblinear
- 3.現有底層是tensorflow的keras框架,如果現在有一個tensorflow訓練好的模型,keras怎么讀取?
- 3.1 tf模型的保存與導入
- 模型保存:
- 導入預訓練好的模型
- 4.卷積層為什么能抽取特征? Pool層的作用
- 4.1 激活函數的種類和特點?
- 4.2 卷積層為什么能抽取特征?
- 4.3 **Pool層的作用**
- 5.LR模型
- 6.LR模型為什么采用似然估計損失函數
- 7.了解深度學習嗎?能否講下CNN的特點?
- 8.說說RBM編碼器
- 9.進程和線程的區別
1.stacking模型以及做模型融合的知識
模型融合常常是在使用機器學習方法解決問題過程中比較重要的一步,常常是在做完模型優化后面。顧名思義,模型融合就是綜合考慮不同模型的情況,并將它們的結果融合在一起,從而提高模型的性能。
模型融合可以分為:從提交結果文件中融合,stacking和blending
1.1 從提交結果中融合
最簡單的方法就是將不同模型預測的結果直接進行融合,因為這樣做并不需要重新訓練模型,只需要把不同模型的測試結果弄出來,然后采取某種措施得出一個最終結果就ok。
投票機制(voting)是集成學習里面針對分類問題的一種結合策略。基本思想是選擇所有機器學習算法當中輸出最多的那個類。機器學習分類算法的輸出有兩種類型:一種是直接輸出類標簽,另外一種是輸出類概率,使用前者進行投票叫做硬投票(Majority/Hard voting),使用后者進行分類叫做軟投票(Soft voting)。
1).硬投票方法
當多個不同模型直接輸出的是類別的標簽的時候,使用硬投票,直接選擇投票數最多的那個類作為最終的分類結果。
2).軟投票(加權表決融合)
當多個不同模型輸出的是屬于某個類別的概率的時候,就使用軟投票的方法,對相同的類別概率進行疊加,最終選出概率值最大的那個類別為分類的結果。
3). 對結果取平均
當我們面對的問題是回歸問題的時候,我們就通過對不同模型的預測結果求平均當做融合模型的結果。
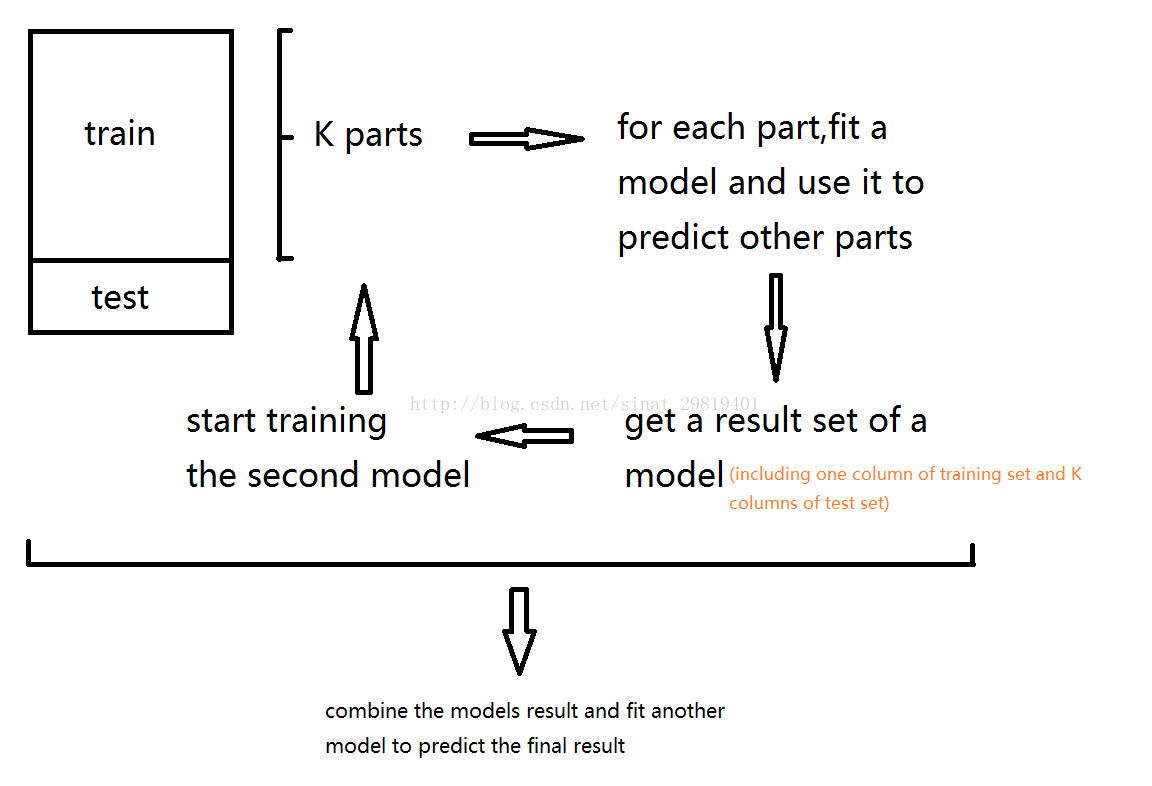
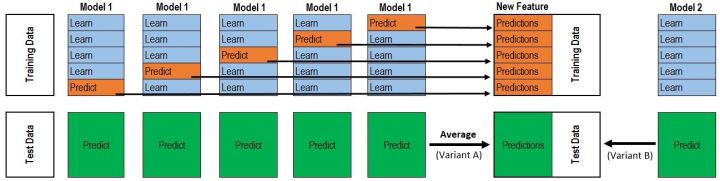
1.2 stacking
Stacking的基本思想是用一些基分類器進行分類,然后使用另一個分類器對結果進行整合。
例子:2-fold stacking
1.將訓練集分成兩個不相交的集合
2.使用第一個集合訓練基分類器
3.在訓練好的基分類器上對第二個集合做預測
4.將第三步得到的預測結果作為高層(融合分類器)分類器的輸入,正確的標簽作為輸出,訓練高層的分類器。
Stacking的模型可以在特征空間上獲取更加多的信息,因為第二階段模型是以第一階段模型的預測值會作為特征。
相比于bagging和boosting方法,stacking方法的區別
- bagging主要用于減少方差
- boosting方法主要用于減少方差
- stacking方法既可以減少方差也可以減少偏差
1.3 blending
Blending與Stacking大致相同,只是Blending的主要區別在于訓練集不是通過K-Fold的CV策略來獲得預測值從而生成第二階段模型的特征,
而是建立一個Holdout集,例如說10%的訓練數據,第二階段的stacker模型就基于第一階段模型對這10%訓練數據的預測值進行擬合。說白了,就是把Stacking流程中的K-Fold CV(相當于把樣本全過了一遍) 改成 HoldOut CV(一開始就直接分好)。
優點
- 比stacking簡單(因為不用進行k次的交叉驗證來獲得stacker feature)
- 避開了一個信息泄露問題:generlizers和stacker使用了不一樣的數據集
- 在團隊建模過程中,不需要給隊友分享自己的隨機種子
缺點 - 使用了很少的數據(第二階段的blender只使用training set10%的量)
- blender可能會過擬合(其實大概率是第一點導致的)
- stacking使用多次的CV會比較穩健
對于實踐中的結果而言,stacking和blending的效果是差不多的,所以使用哪種方法都沒什么所謂,完全取決于個人愛好。
2. 怎樣去優化SVM算法模型的?
2.1 SMO優化算法
SMO算法是支持向量機的快速算法,不斷的將原二次規劃問題分解為只有兩個變量的二次規劃子問題求解,直到所有變量滿足KTT條件,這樣通過啟發式的方法得到原二次規劃問題的最優解。
2.2 libsvm 和 Liblinear
LIBSVM是臺灣大學林智仁(Lin Chih-Jen)教授等開發設計的一個簡單、易于使用和快速有效的SVM模式識別與回歸的軟件包,他不但提供了編譯好的可在Windows系列系統的執行文件,還提供了源代碼,方便改進、修改以及在其它操作系統上應用;該軟件對SVM所涉及的參數調節相對比較少,提供了很多的默認參數,利用這些默認參數可以解決很多問題;并提供了交互檢驗(Cross Validation)的功能。該軟件可以解決C-SVM、ν-SVM、ε-SVR和ν-SVR等問題,包括基于一對一算法的多類模式識別問題。
Libsvm和Liblinear都是國立臺灣大學的Chih-Jen Lin博士開發的,Libsvm主要是用來進行非線性svm 分類器的生成,提出有一段時間了,而Liblinear則是去年才創建的,主要是應對large-scale的data classification,因為linear分類器的訓練比非線性分類器的訓練計算復雜度要低很多,時間也少很多,而且在large scale data上的性能和非線性的分類器性能相當,所以Liblinear是針對大數據而生的。
有關Liblinear和Libsvm各自的優勢可以歸納如下:
1.libsvm用來就解決通用典型的分類問題
2.liblinear主要為大規模數據的線性模型設計
3.現有底層是tensorflow的keras框架,如果現在有一個tensorflow訓練好的模型,keras怎么讀取?
- 直接通過API讀取tensflow的模型文件
- keras.models.load_model(‘my_model.h5’
- 不同深度學習框架模型的轉換可以使用微軟的MMdnn。
3.1 tf模型的保存與導入
模型保存:
saver = tf.train.Saver()
saver.save(sess, 'my_test_model')
主要有2個文件
-
meta graph(.meta結尾)
這是一個 protocol buffer,保存了完整的 Tensorflow 圖,即所有變量、操作和集合等。擁有一個.meta的擴展名。 -
checkpoint file(.ckpt結尾)
這是一個二進制文件包含了所有權重、偏置、梯度和其他變量的值。這個文件有一個.ckpt的擴展名。在0.11版本以前只有一個文件,現在有兩個。
導入預訓練好的模型
如果你想用別人預訓練好的模型進行fine-tuning,有兩件事情需要做。
- 創造網絡
你可以通過python寫好和原來模型一樣的每一層代碼來創造網絡,可是,仔細一想,我們已經通過.metaa把網絡存儲起來,我們可以用來再創造網絡使用tf.train.import()語句。
saver = tf.train.import_meta_graph('my_test_model-1000.meta')
- 加載參數
我們可以恢復網絡的參數,通過使用saver,它是tf.train.Saver()類的一個實例。
with tf.Session() as sess:new_saver = tf.train.import_meta_graph('my_test_model-1000.meta')new_saver.restore(sess, tf.train.latest_checkpoint('./'))
4.卷積層為什么能抽取特征? Pool層的作用
4.1 激活函數的種類和特點?
-
sigmoid 、反正切tanh 都有梯度消失問題
-
relu 快,問題:負值0梯度
1.sigmoid


-
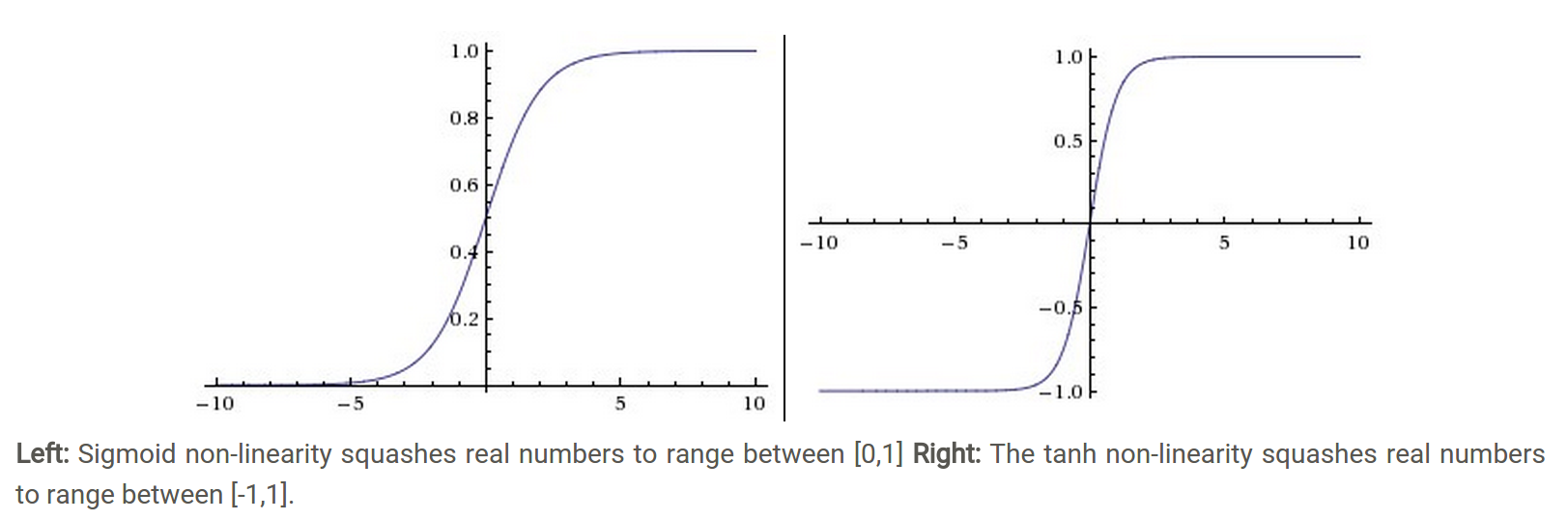
Sigmoid(也叫邏輯激活函數) 非線性激活函數的形式是,其圖形如上圖左所示。之前我們說過,sigmoid函數輸入一個實值的數,然后將其壓縮到0~1的范圍內。特別地,大的負數被映射成0,大的正數被映射成1。sigmoid function在歷史上流行過一段時間因為它能夠很好的表達“激活”的意思,未激活就是0,完全飽和的激活則是1。而現在sigmoid已經不怎么常用了,主要是因為它有兩個缺點:
-
Sigmoids saturate and kill gradients. Sigmoid容易飽和,并且當輸入非常大或者非常小的時候,神經元的梯度就接近于0了,從圖中可以看出梯度的趨勢。這就使得我們在反向傳播算法中反向傳播接近于0的梯度,導致最終權重基本沒什么更新,我們就無法遞歸地學習到輸入數據了。另外,你需要尤其注意參數的初始值來盡量避免saturation的情況。如果你的初始值很大的話,大部分神經元可能都會處在saturation的狀態而把gradient kill掉,這會導致網絡變的很難學習。
-
Sigmoid outputs are not zero-centered. Sigmoid 的輸出不是0均值的,這是我們不希望的,因為這會導致后層的神經元的輸入是非0均值的信號,這會對梯度產生影響:假設后層神經元的輸入都為正(e.g. x>0 elementwise in ),那么對w求局部梯度則都為正,這樣在反向傳播的過程中w要么都往正方向更新,要么都往負方向更新,導致有一種捆綁的效果,使得收斂緩慢。 當然了,如果你是按batch去訓練,那么每個batch可能得到不同的符號(正或負),那么相加一下這個問題還是可以緩解。因此,非0均值這個問題雖然會產生一些不好的影響,不過跟上面提到的 kill gradients 問題相比還是要好很多的。
2.tanh

Tanh和Sigmoid是有異曲同工之妙的,它的圖形如上圖右所示,不同的是它把實值得輸入壓縮到-1~1的范圍,因此它基本是0均值的,也就解決了上述Sigmoid缺點中的第二個,所以實際中tanh會比sigmoid更常用。但是它還是存在梯度飽和的問題。Tanh是sigmoid的變形.
3.relu: f(x)=max(0,x)
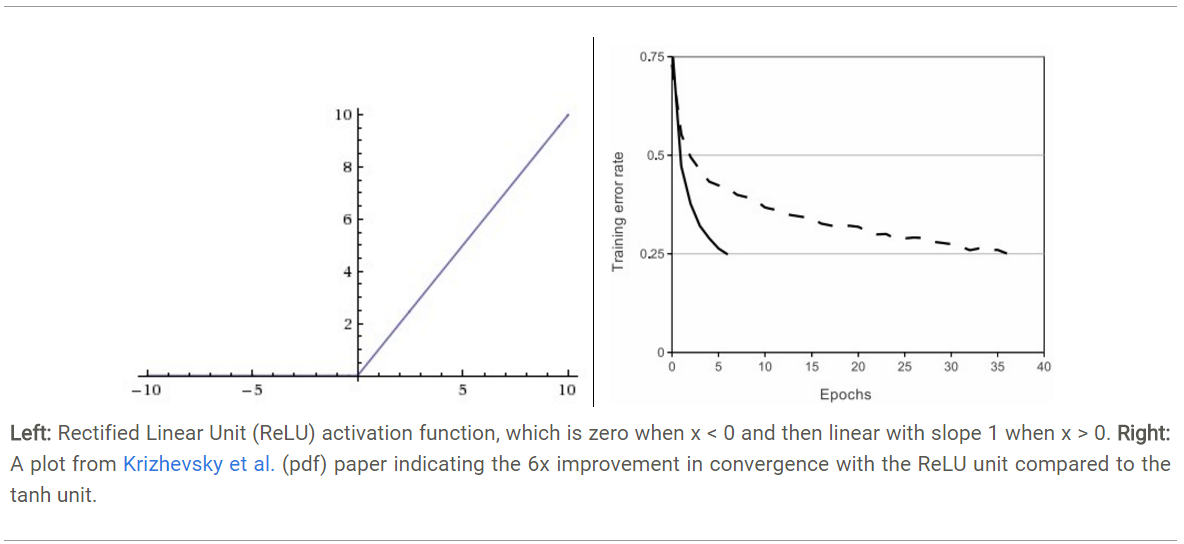
近年來,ReLU 變的越來越受歡迎。它的數學表達式是: f(x)=max(0,x)。很顯然,從上圖左可以看出,輸入信號
<0時,輸出為0,>0時,輸出等于輸入。ReLU的優缺點如下:
- 優點1:Krizhevsky et al. 發現使用 ReLU 得到的SGD的收斂速度會比 sigmoid/tanh 快很多(如上圖右)。有人說這是因為它是linear,而且梯度不會飽和
- 優點2:相比于 sigmoid/tanh需要計算指數等,計算復雜度高,ReLU 只需要一個閾值就可以得到激活值。
- 缺點1: ReLU在訓練的時候很”脆弱”,一不小心有可能導致神經元”壞死”。舉個例子:由于ReLU在x<0時梯度為0,這樣就導致負的梯度在這個ReLU被置零,而且這個神經元有可能再也不會被任何數據激活。如果這個情況發生了,那么這個神經元之后的梯度就永遠是0了,也就是ReLU神經元壞死了,不再對任何數據有所響應。實際操作中,如果你的learning rate 很大,那么很有可能你網絡中的40%的神經元都壞死了。 當然,如果你設置了一個合適的較小的learning rate,這個問題發生的情況其實也不會太頻繁。
- Leaky ReLU
Leaky ReLUs 就是用來解決ReLU壞死的問題的。和ReLU不同,當x<0時,它的值不再是0,而是一個較小斜率(如0.01等)的函數。也就是說f(x)=1(x<0)(ax)+1(x>=0)(x),其中a是一個很小的常數。這樣,既修正了數據分布,又保留了一些負軸的值,使得負軸信息不會全部丟失。關于Leaky ReLU 的效果,眾說紛紜,沒有清晰的定論。有些人做了實驗發現 Leaky ReLU 表現的很好;有些實驗則證明并不是這樣。
激活函數的作用:非線性。
4.2 卷積層為什么能抽取特征?
- 卷積層負責提取特征,采樣層負責特征選擇,全連接層負責分類
- 卷積神經網絡的特點就是權重共享,利用不同的卷積核對輸入的圖像進行卷積,可以得到一張張特征圖
多種濾波器和對應的濾鏡效果,比如邊緣檢測、銳化、均值模糊、高斯模糊

4.3 Pool層的作用
- pooling確實起到了整合特征的作用
- pooling的結果是使得特征減少,參數減少,但pooling的目的并不僅在于此
- pooling目的是為了保持某種不變性(旋轉、平移、伸縮等),常用的有mean-pooling,max-pooling和Stochastic-pooling(隨機池化)三種
5.LR模型
-
在線性回歸的基礎上加了sigmoid函數,所以變成了分類模型,輸出可以表示概率。
-
采用似然估計構造目標函數,目標是優化最大似然估計,公式H(x)=-(ylogf(x)+(1-y)log(1-f(x)),一般優化方法采用的是梯度下降法
6.LR模型為什么采用似然估計損失函數
- 最小二乘法反映的是線性空間上的線性投影的最短距離,在非線性空間上表現不如MLE。(MLE可以看作一種特殊情況下的Bayesian 估計)
- 如果采用均方差損失函數的時候,梯度下降求偏導時會有一項導數項,這樣會導致梯度在一定階段會收斂的特別慢,而對數損失函數log正好能和sigmoid的exp抵消掉,會加快收斂速度。
- 最小二乘法是高斯分布下最大似然估計的一般結果,LR是伯努利分布下最大似然估計的一般結果(交叉熵損失),所以兩者本質上都是最大似然估計。
7.了解深度學習嗎?能否講下CNN的特點?
CNN,特點是局部感受和權值共享
通過卷積核掃描原始數據能夠學習到不同的局部的特征,接著通過池化進一步提取特征,這些做的能夠讓參數數目有量級的減少,同時權值共享是同一層隱含層共享權值,這樣也是減少了隱含層的參數,很多卷積核學習的到特征最后傳遞到下一層網絡,到最后一層采用分類器分類
深度學習解決了以往神經網絡深度網絡很多問題,
梯度消失爆炸問題,幾個方面:
- 是激活函數不光是只用sigmoid函數,還有 ReLU函數
- 是在參數并不是初始化的時候并不是隨機選擇的,而是在前面有自編碼器做了預訓練,這樣避免了梯度下降法求解陷入局部最優解;
- 深度學習一些手段,權值共享,卷積核,pooling等都能抑制梯度消失問題
- 二次代價函數換成交叉熵損失函數或者選用softmax+對數似然代價函數的組合
8.說說RBM編碼器
RBM包括隱層,可見層和偏置層。可見層和隱含層可以雙向傳播。標準的RBM,隱含層和可見層都是二進制表示,既激活函數的激活值服從二項分布。每一層的節點沒有鏈接,如果假設所有的節點都只能取0或者1,同時全概率分布p(v,h)滿足伯努利分布。
參數:
- 可視層和隱含層之間的權重矩陣
- 可視節點的偏移量
- 隱含層的偏移量
應用 - 降維,類似稀疏自編碼器
- 用RBM訓練得到的權重舉證和偏移量作為BP神經網路的初始值,避免陷入局部極小值
- 可以估計聯合分布P(v,h),進而求出p(h|v)。生成式模型
- 直接計算p(h|v)進行分類。判別式模型
9.進程和線程的區別
有一個是進程的開銷比線程大,通信麻煩一些,但更安全,所以很多時候我們用多線程加速,但有時候線程用不了,只能用進程
python:為了加速嘗試過很多方法,比如GPU加速、C++動態庫調用、還有就是多進程。
為什么要用多進程加速。
- 因為python這個語言是解釋型語言,本來用來進行cpu密集型計算就不適合,
- 還有就是python沒有類型,因為全是用哈希表實現的動態內存分配方式,比如你定義a = 2 ,其實底層的實現是先分配一個內存塊,在用一個指針指向這個內存塊,最后返回的是這個指針
- 最重要的一點是當初在設計python的時候,為了圖簡單,加了一個全局鎖,也就是一個時刻只能使用一個線程,多核完全浪費了



-流型)
)
)


-面向對象2-繼承,多態)

)

-面向對象3-可迭代類對象Pokemon)
)

-單例設計模式)



-異常)