[閱讀指南]
這是該系列第三篇
基于kubernetes 1.27 stage版本
為了方便閱讀,后續所有代碼均省略了錯誤處理及與關注邏輯無關的部分。
文章目錄
- 為什么需要resync
- resync做了什么
為什么需要resync
如果看過上一篇,大概能了解,client數據主要通過reflector 的list/watch進行同步。
回顧一下informer整體的數據同步邏輯。
- informer初始化時,調用list接口獲取制定類型的全量資源數據,此時的resource version默認為0。假如指定資源類型為pod,那么就是獲取所有pod數據
- list 獲取到數據后,將全量數據同步到本地緩存。首次list完成后,informer后續都將通過watch來同步資源更新
- watcher監控到資源更新事件,將接收到的事件放入存儲隊列中(delta FIFO)
- informer 的另一個process會不斷取出存儲隊列中的delta事件進行數據更新
- 緩存數據更新成功后,將數據變化通過回調函數同步至custom controller workqueue中
- custom controller順序處理workqueue中的數據變更事件
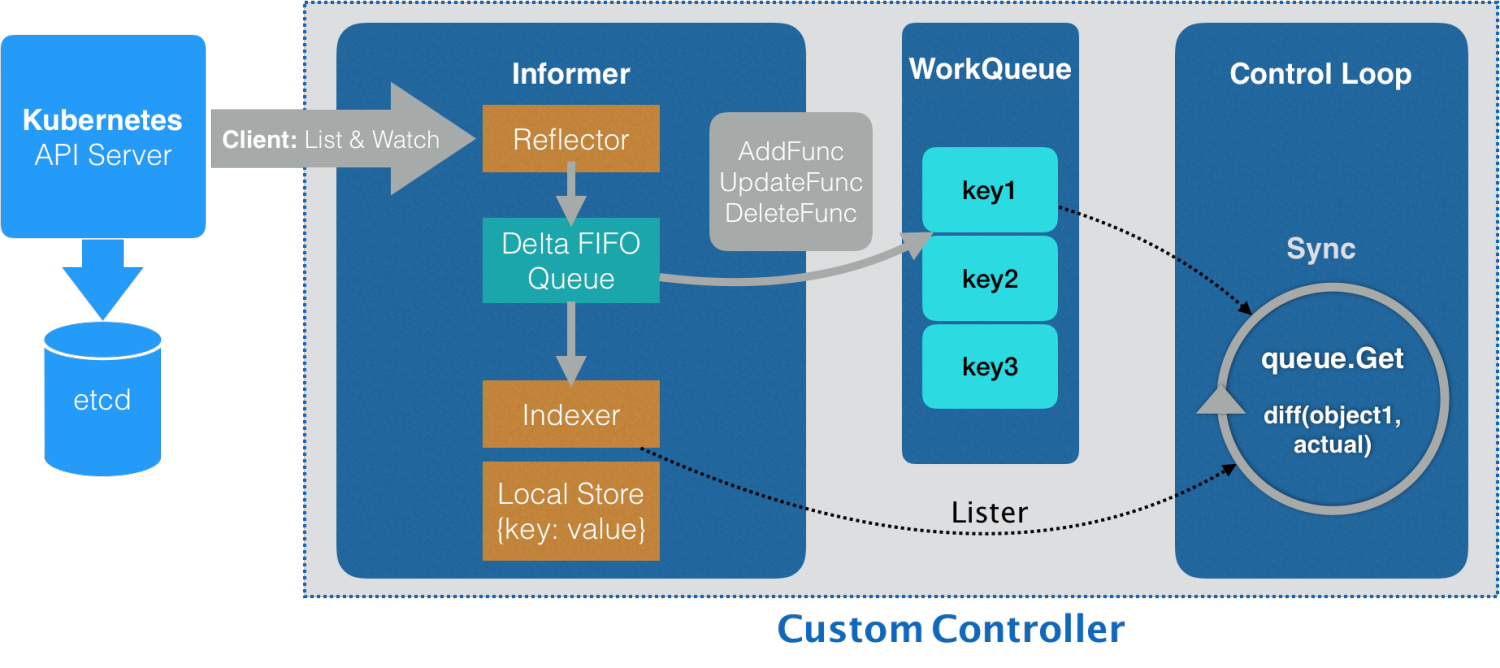
流程包括了三端的數據同步。
-
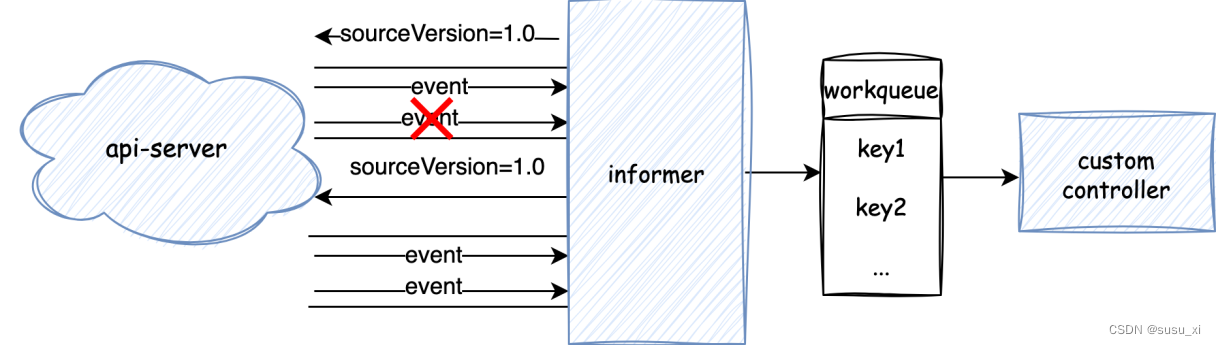
首先api-server與informer中間通過sourceVersion可以保證數據的一致性
client攜帶本地的sourceVersion請求api-server,api-server會將最新版本的增量變化通過事件返回給client。
如圖所示,在此期間,如果數據連接發生任何異常,informer會在重新建立watcher連接時,攜帶上個版本的sourceVersion,并再次更新所有的增量變化。
-
然后是本地informer與custom之間,通過workqueue來進行事件通知。
informer的協程將FIFO隊列中的事件取出更新至本地后,還會將事件同步回調至custom controller,加入到workqueue隊列中。
但是回看informer的代碼,informer在處理回調事件時,并不會關注回調的結果。
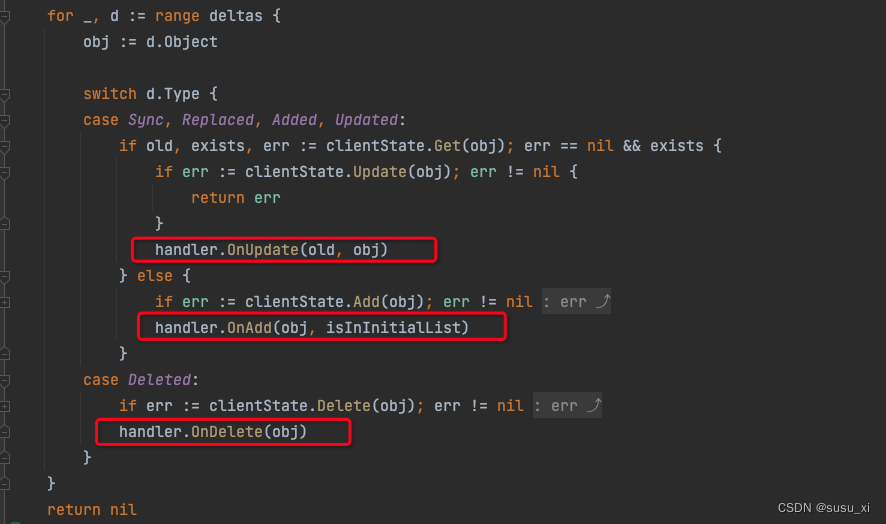
也就是說,如果custom controller側的消費出現異常導致數據同步失敗,informer是不知情的。
所以還需要引入別的機制來保障custom數據與本地緩存的一致性,以維持體的可靠性,也就是resync。
(當然如果controller本身也存在對比sourceVersion的邏輯,其實不需要這一機制也是可以確保數據一致的,resync相當于從框架層增加了一層保護,這篇博客有對相關的問題進行探討)
resync做了什么
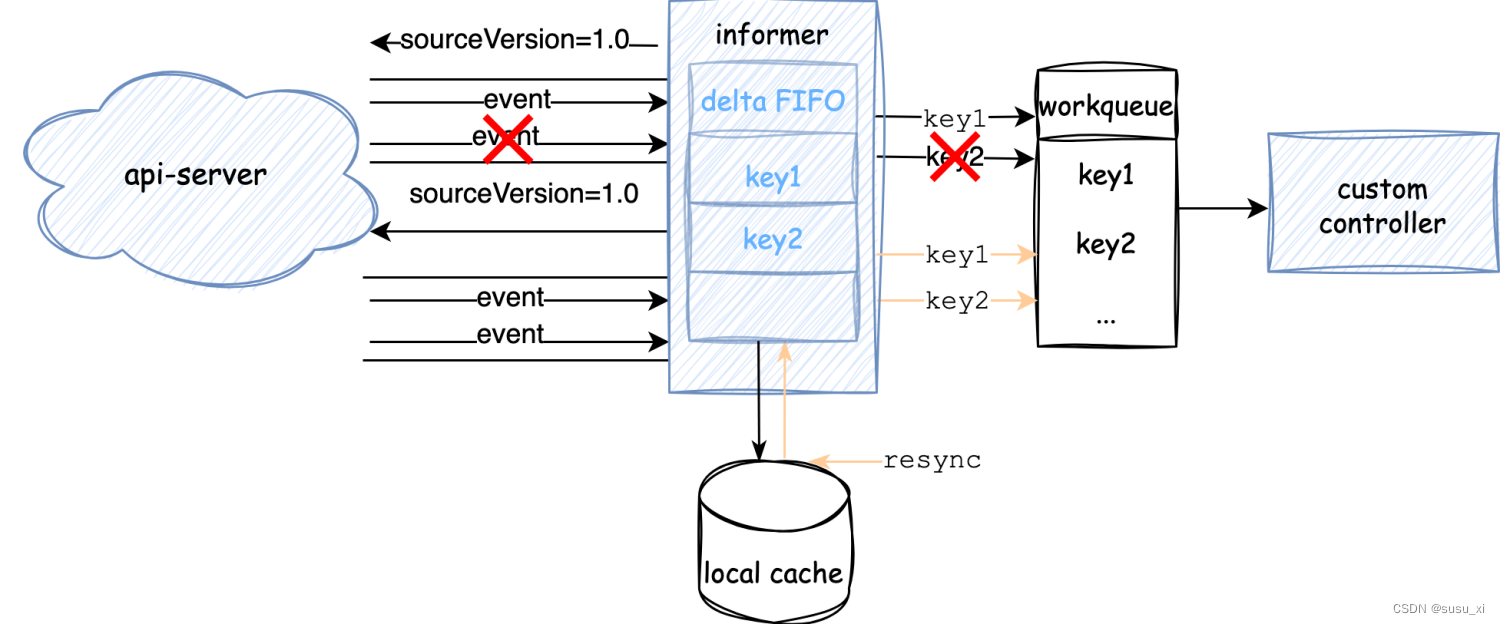
resync的邏輯非常簡單,就是定時將本地緩存中所有的資源對象生成事件重新推送到FIFO中,重新觸發controller的回調。
參考《Programming Kubernetes》一書中的概念,其實就是在邊緣觸發,水平驅動的基礎上,附加了定時同步的能力。
具體來看下resync的代碼實現。
informer在初始化時指定了resync執行間隔。
// informer創建方法
func NewIndexerInformer(lw ListerWatcher,objType runtime.Object,resyncPeriod time.Duration, // Resync執行周期h ResourceEventHandler,indexers Indexers,
) (Indexer, Controller) {}// workqueue調用示例
// 0 代表不重復執行
indexer, informer := cache.NewIndexerInformer(podListWatcher, &v1.Pod{}, 0, cache.ResourceEventHandlerFuncs{...})
在informer初始化完成后,拉起一個協程進行定時resync
func (r *Reflector) ListAndWatch(stopCh <-chan struct{}) error {...go r.startResync(stopCh, cancelCh, resyncerrc)return r.watch(w, stopCh, resyncerrc)
}
該協程會按照informer配置的時間間隔定時調用存儲對象的resync方法。
比較特殊的是,sharedIndexInformer類型的informer會另外有ShouldResync方法來輪詢每個監聽了當前資源對象的listener的是否需要進行resync操作。
func (r *Reflector) startResync(stopCh <-chan struct{}, cancelCh <-chan struct{}, resyncerrc chan error) {resyncCh, cleanup := r.resyncChan() // 返回一個觸發resync的信號,內部實現就是一個timerdefer func() {cleanup() // Call the last one written into cleanup}()for {select {case <-resyncCh:case <-stopCh:returncase <-cancelCh:return}// sharedIndexInformer 中用ShouldResync()來管理各個listener的resyncif r.ShouldResync == nil || r.ShouldResync() {if err := r.store.Resync(); err != nil { resyncerrc <- err return}}cleanup()resyncCh, cleanup = r.resyncChan()}
}
resync只做一件事,將本地緩存里的資源對象全部重新添加到FIFO隊列中,再觸發contronller處理一次。
不過,為了避免與最新的變更發生沖突,FIFO隊列中已有delta且還沒有處理的資源對象,不會被重新添加。
func (f *DeltaFIFO) Resync() error {f.lock.Lock()defer f.lock.Unlock()if f.knownObjects == nil {return nil}// f.knownObjects 可以獲取到本地緩存中所有資源對象的列表keys := f.knownObjects.ListKeys()for _, k := range keys {// 過濾掉已經有新的事件在隊列中等待處理的資源對象// 把所有資源對象以resync類型添加到隊列中if err := f.syncKeyLocked(k); err != nil {return err}}return nil
}
參考:
https://www.kubernetes.org.cn/2693.html
https://github.com/cloudnativeto/sig-kubernetes/issues/11
https://www.cnblogs.com/WisWang/p/13897782.html


介紹及示例)




:機器學習入門的概念)


)


方法并行執行多個請求)





)