關注gongzhonghao【CVPR頂會精選】
當今數字化時代,多模態技術正迅速改變我們與信息互動的方式。多模態被定義為在特定語境中多種符號資源的共存與協同。這種技術通過整合不同模態的數據,如文本、圖像、音頻等,為用戶提供更豐富、更自然的交互體驗。
近年來,多模態技術取得了顯著進展,尤其是在深度學習和變換器架構的推動下,多模態模型能夠更靈活地處理和融合多種輸入模態的信息。這些進步不僅提升了模型的性能,也為實現更通用的人工智能奠定了基礎。今天小圖給大家精選3篇CVPR有關多模態方向的論文,請注意查收!
圖靈學術論文輔導
論文一:Beyond Text: Frozen Large Language Models in Visual Signal Comprehension
方法:
文章首先將圖像視為一種“外語”,通過V2L Tokenizer將其翻譯為LLM詞匯表中的離散詞。然后,利用擴展的LLM詞匯表和CLIP模型生成全局和局部令牌,分別用于捕捉圖像的語義信息和細節特征。最后,通過結合任務指令、上下文學習樣本和這些令牌,使凍結的LLM能夠執行多種視覺理解任務,如圖像識別、圖像描述和視覺問答。
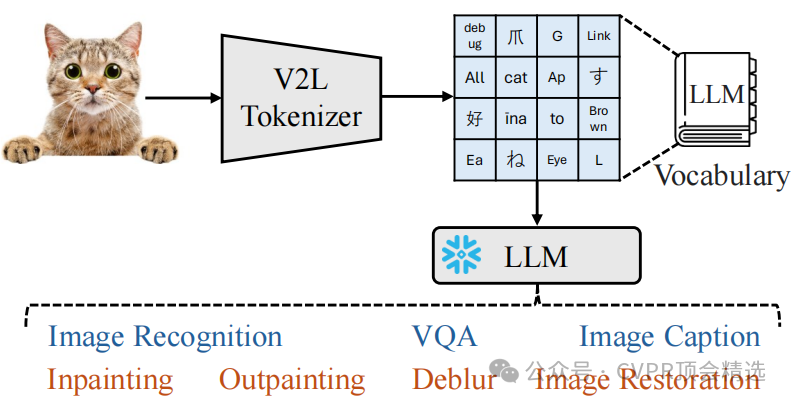
創新點:
提出了Vision-to-Language Tokenizer,將圖像轉換為LLM詞匯表中的離散詞,使LLM能夠直接處理視覺信息。
引入了詞匯擴展技術,通過構建雙詞和三詞組合來增強LLM詞匯表的語義表示能力,從而提高對圖像的語義理解。
設計了全局和局部令牌,分別用于圖像理解任務和圖像去噪任務,實現了對圖像的多層次理解和生成。

論文鏈接:
https://arxiv.org/pdf/2403.07874
圖靈學術論文輔導
論文二:InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks
方法:
文章首先設計了一個60億參數的視覺編碼器 InternViT-6B,并通過多語言增強的LLaMA初始化語言中間件QLLaMA來對齊視覺特征和語言模型。接著,利用從網絡收集的多源圖像-文本數據,采用漸進式對齊訓練策略,先進行對比學習,再進行生成學習,最后進行監督微調。這種設計使InternVL能夠在多種視覺和視覺-語言任務上展現出強大的性能,如圖像分類、視頻分類、圖像-文本檢索、圖像描述、視覺問答和多模態對話等。
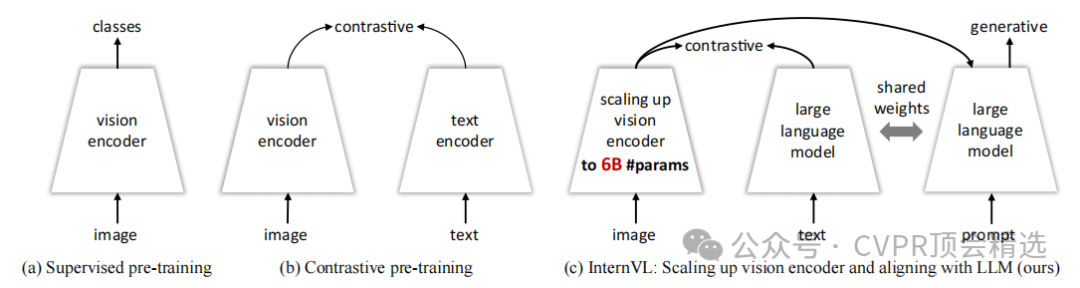
創新點:
提出了InternVL,這是首個將視覺基礎模型擴展到60億參數并與LLM對齊的模型,有效填補了視覺基礎模型與LLM之間的參數規模和特征表示能力的差距。
引入了漸進式圖像-文本對齊策略,先在大規模噪聲數據上進行對比學習,再在高質量數據上進行生成學習,確保了訓練的穩定性并持續提升模型性能。
設計了參數平衡的視覺和語言組件,包括60億參數的視覺編碼器和80億參數的語言中間件,能夠靈活組合以應對對比學習和生成學習任務。

論文鏈接:
?https://arxiv.org/pdf/2312.14238
圖靈學術論文輔導
論文三:ViLa-MIL: Dual-scale Vision-Language Multiple Instance Learning for Whole Slide Image Classification
方法:
文章首先利用凍結的LLM生成與WSI不同分辨率對應的雙尺度視覺描述性文本提示,以更好地利用病理診斷中的先驗知識。接著,為高效處理WSI,提出了原型引導的圖像分支解碼器,通過分組相似圖像塊特征并逐步聚合,生成最終的幻燈片特征。同時,引入上下文引導的文本分支解碼器,借助多粒度圖像上下文信息優化文本特征。最后,通過計算圖像特征和文本特征之間的相似性,結合交叉熵損失函數進行端到端訓練,從而實現對WSI的分類。

創新點:
提出了雙尺度視覺描述性文本提示,基于凍結的大語言模型生成,能夠有效提升VLM的性能,使其更好地捕捉WSI中的診斷相關特征。
設計了原型引導的圖像分支解碼器,通過將相似的圖像塊特征分組到同一原型中,逐步聚合圖像塊特征,從而更有效地處理WSI。
引入了上下文引導的文本分支解碼器,利用多粒度圖像上下文來增強文本特征,進一步提升模型對WSI的分類能力。
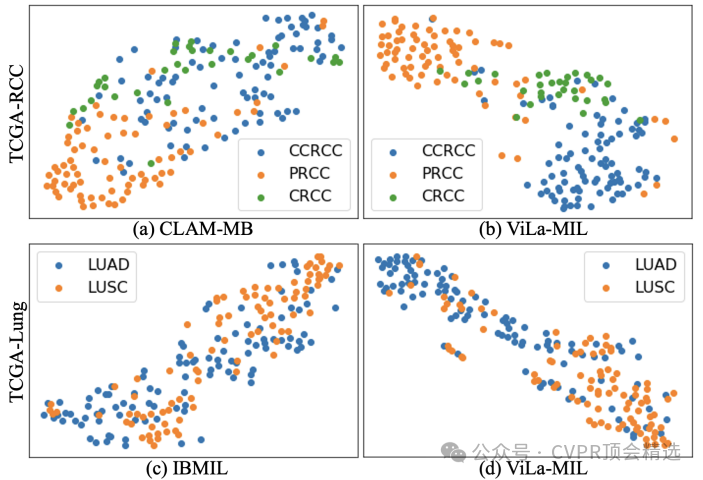
論文鏈接:
https://arxiv.org/pdf/2502.08391
??論文發表難題,一站式解決!
TURING
選題是論文的第一步,非常重要!
但很多學生找到了熱門的選題,卻卡在代碼和寫作上!可見論文要錄用,選題-idea-代碼-寫作都缺一不可!
圖靈學術論文輔導,匯聚經驗豐富的實戰派導師團隊,針對計算機各類領域提供1v1專業指導,直至論文錄用!每天2個免費咨詢名額,機會有限先到先得!
本文選自gongzhonghao【CVPR頂會精選】









的安裝過程以及GD32的IAR工程模板搭建)

 鑰匙串信息)
)

 配置IP封禁(防暴力破解))




