熊貓tv新功能介紹
Out of all technologies that is introduced in Data Analysis, Pandas is one of the most popular and widely used library.
在Data Analysis引入的所有技術中,P andas是最受歡迎和使用最廣泛的庫之一。
So what are we going to cover :
那么我們要講的是:
- Installation of pandas 熊貓的安裝
- Key components of pandas 大熊貓的主要成分
- Read/Import data from CSV file 從CSV文件讀取/導入數據
- Write/Export data to CSV files 將數據寫入/導出到CSV文件
- Viewing and selecting data 查看和選擇數據
1.安裝熊貓 (1. Installation of pandas)
Let’s take care of the boring but important stuff first. Setting up the space to work with pandas.
首先讓我們處理無聊但重要的事情。 設置與熊貓共處的空間。
If you are using conda as your environment with miniconda or Anaconda then:
如果您使用的 暢達 與 miniconda 或 Python 那么 你的環境 :
- Activate your environment 激活您的環境
conda activate ./env
conda激活./env
- Install pandas package 安裝熊貓包
conda install pandas
conda安裝熊貓
If you are using virtual environment with virtualenv then :
如果您通過virtualenv使用虛擬環境,則:
- Activate your environment 激活您的環境
source ./env/bin/activate
源./env/bin/activate
- Install pandas package 安裝熊貓包
pip install pandas
點安裝熊貓
If you are using virtual environment with pipenv then :
如果您通過pipenv使用虛擬環境,則:
- create and environment and install pandas in that environment 在該環境中創建和環境并安裝熊貓
pipenv install pandas
pipenv安裝熊貓
- Activate the environment 激活環境
pipenv shell
皮殼
2.大熊貓的主要成分 (2. Key components of pandas)
Pandas provides two compound data types, which are the key components of pandas that gives us so much flexibility on selecting, viewing and manipulating the data. Those two key components are:
熊貓提供了兩種復合數據類型,它們是熊貓的關鍵組成部分,這使我們在選擇,查看和操作數據方面具有如此大的靈活性。 這兩個關鍵組成部分是:
- Pandas Series 熊貓系列
- Pandas Data Frame 熊貓數據框
熊貓系列 (Pandas Series)
It is an one dimensional array offered by pandas. It can store different types of data ( meaning int,string, float, boolean etc..)
它是熊貓提供的一維數組。 它可以存儲不同類型的數據(表示int,string,float,boolean等。)
A pandas series data be created as:
將熊貓系列數據創建為:
import pandas as pd
將熊貓作為pd導入
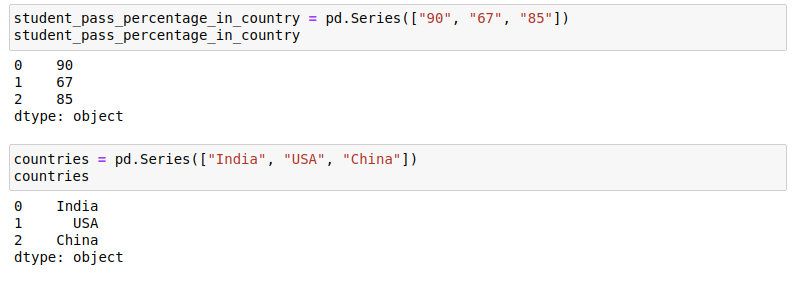
student_pass_percentage_in_country = pd.Series([“90”, “67”, “85”])
student_pass_percentage_in_country = pd.Series([“ 90”,“ 67”,“ 85”])
countries = pd.Series([“India”, “USA”, “China”])
國家= pd.Series([“印度”,“美國”,“中國”])
熊貓數據框 (Pandas Data Frame)
It is the one where most of the magic happens. It is a two dimensional array , you can think of it as an excel sheet.
這是大多數魔術發生的地方。 它是一個二維數組,您可以將其視為Excel工作表。
- The index in pandas starts from 0. 熊貓的索引從0開始。
- The row is referred as axis=1 and column as axis=0. 該行稱為axis = 1,而列稱為axis = 0。
- Its first column represents the index. 它的第一列代表索引。
- More then one row can be associated with one index. So there are two ways of looking for data: one by index, one by position. Position also starts from 0. 多于一行可以與一個索引相關聯。 因此,有兩種查找數據的方法:一種是按索引,一種是按位置。 位置也從0開始。
A pandas data frame can be created as:
熊貓數據框可以創建為:
student_pass_percent_by_country = pd.DataFrame({ ‘Country’: countries, ‘Pass Percent’: student_pass_percentage_in_country})
student_pass_percent_by_country = pd.DataFrame({'Country':國家,'Pass Percent':student_pass_percentage_in_country})

3.從CSV文件讀取/導入數據 (3. Read / import data from CSV file)
First lets see how CSV file data looks like.
首先,讓我們看看CSV文件數據的外觀。
A CSV file contains data in comma separated format, which looks like:
CSV文件包含逗號分隔格式的數據,如下所示:
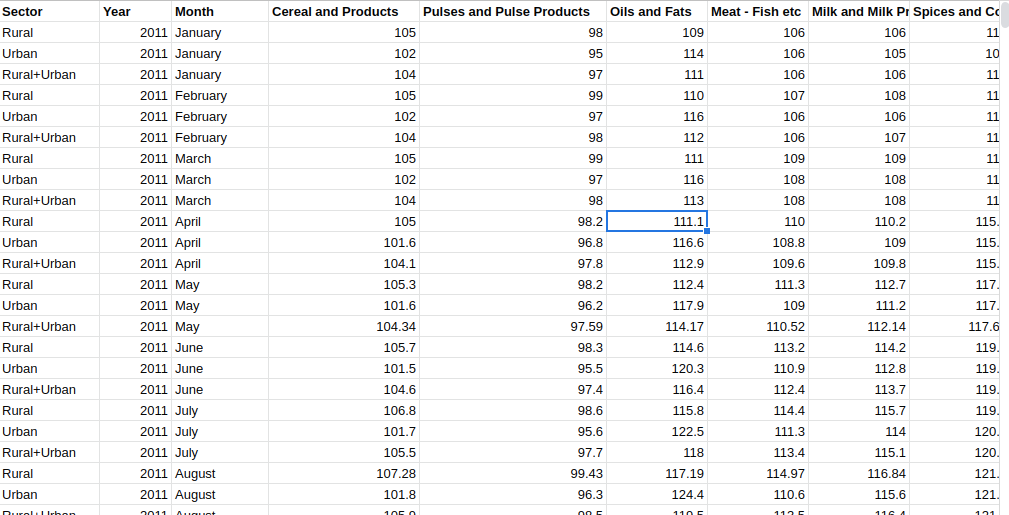
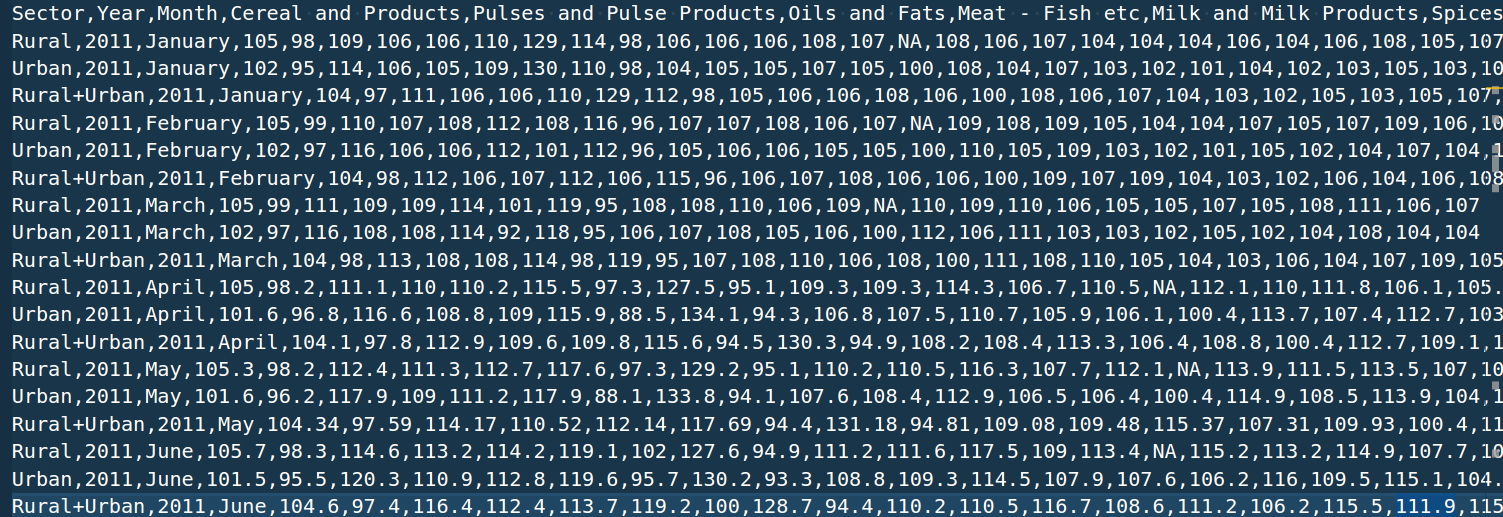
Reading CSV data is very straight forward in pandas. It provides you two functions : read_csv(‘file_path’) or read_csv(‘file_url’) , the data gets stored in data frame.
在熊貓中,讀取CSV數據非常簡單。 它提供了兩個功能:read_csv('file_path')或read_csv('file_url'),數據被存儲在數據框中。
i have taken this public repository from curran, so that you can use it as well.
我已經從curran那里獲取了這個公共存儲庫,以便您也可以使用它。
csv_data = pd.read_csv(‘https://github.com/curran/data/blob/gh-pages/indiaGovOpenData/All_India_Index-February2016.csv’)
csv_data = pd.read_csv(' https://github.com/curran/data/blob/gh-pages/indiaGovOpenData/All_India_Index-February2016.csv ')
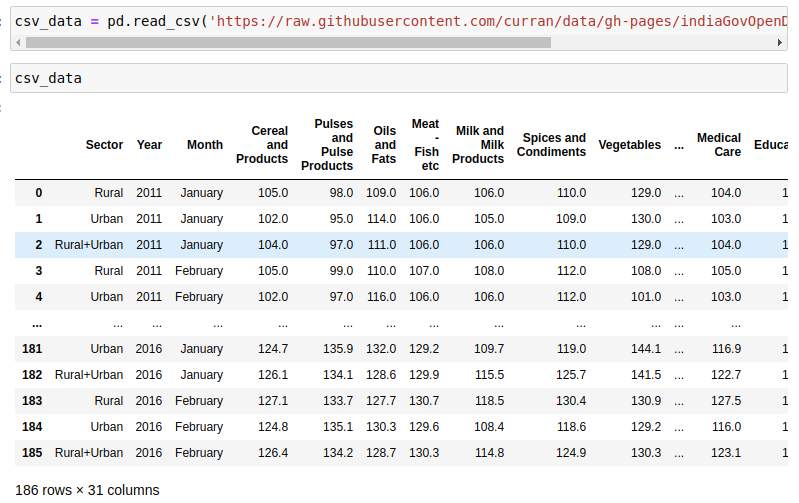
As you can see it right away tells us how many rows and columns are there in the data.
如您所見,它立即告訴我們數據中有多少行和多少列。
4.將數據寫入/導出到CSV文件 (4. Write/Export data to CSV files)
Exporting data to CSV file is as simple as importing it. Pandas has a function called : to_csv(‘file_name’), this will export the data from a data frame to CSV file.
將數據導出到CSV文件就像導入數據一樣簡單。 熊貓有一個名為:to_csv('file_name')的函數,它將數據從數據幀導出到CSV文件。
csv_data.to_csv(‘new_exported_data.csv;’)
csv_data.to_csv('new_exported_data.csv;')
5.查看和選擇數據 (5. Viewing and Selecting data)
As we get to work with a lot of data so if we can view and select the data the way we want, it can give us more insights on the data at the first place.
當我們開始處理大量數據時,如果我們可以按照自己的方式查看和選擇數據,那么它首先可以為我們提供關于數據的更多見解。
To view a snippet of data , ( 5 rows by default ):
要查看數據片段,(默認為5行):
csv_data.head()
csv_data.head()
To view more then just 5 records, let’s say you want to see 23 records from the top:
要查看僅5條記錄,假設您要從頂部查看23條記錄:
csv_data.head(23)
csv_data.head(23)

To view a snippet of data from bottom:
要從底部查看數據片段:
csv_data.tail()
csv_data.tail()
To view more then just 5 records from bottom, let’s say you want to see 11 records from the bottom:
要從底部僅查看5條記錄,假設您要從底部查看11條記錄:
csv_data.tail(11)
csv_data.tail(11)

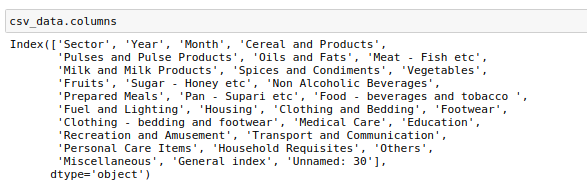
To list out all the columns in the data:
列出數據中的所有列:
csv_data.columns
csv_data.columns
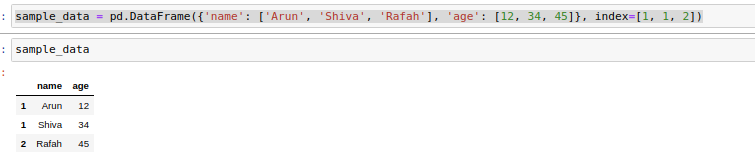
In pandas dataframe we can assign more then one data in an index. and the index starts from 0.
在pandas數據框中,我們可以在一個索引中分配多個數據。 索引從0開始。
sample_data = pd.DataFrame({‘name’: [‘Arun’, ‘Shiva’, ‘Rafah’], ‘age’: [12, 34, 45]}, index=[1, 1, 2])
sample_data = pd.DataFrame({'name':['Arun','Shiva','Rafah'],'age':[12,34,45]},index = [1,1,2])
One thing you have noticed above is that , i can create data frame from plan python lists as well.
您在上面注意到的一件事是,我也可以從計劃python列表創建數據框。
View data at index 3:
查看索引3的數據:
sample_data.loc[1]
sample_data.loc [1]
View data at position 3:
查看位置3的數據:
sample_data.iloc[1]
sample_data.iloc [1]

Selecting a column , you can select a column in two ways
選擇列,您可以通過兩種方式選擇列
a. Dot notation:
一個。 點表示法:
sample_data.age
sample_data.age
b. Index/Attribute notation:
b。 索引/屬性符號:
sample_data[‘age’]
sample_data ['age']
The first option (a) will not work if the column name has spaces. So select one and stick to that.
如果列名包含空格,則第一個選項(a)將不起作用。 因此,選擇一個并堅持下去。
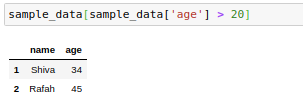
Selecting only those data where age is greater than 20:
僅選擇年齡大于20的那些數據:
sample_data[sample_data[‘age’] > 20]
sample_data [sample_data ['age']> 20]
I have just listed only most used functions here. I am planning to keep updating the article as i am going to refer it as well if i forget anything. If you have any questions or want to discuss any project feel free to comment here.
我在這里只列出了最常用的功能。 我打算繼續更新文章,因為如果我忘記了任何內容,我也會參考它。 如果您有任何疑問或想要討論任何項目,請在此處發表評論。
Thank you for reading :)
謝謝您的閱讀:)
翻譯自: https://medium.com/@lax_17478/data-analysis-a-complete-introduction-to-pandas-part-1-3dd06922144a
熊貓tv新功能介紹
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/391647.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/391647.shtml 英文地址,請注明出處:http://en.pswp.cn/news/391647.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

關于sublime-text-2的Package Control組件安裝方法,自動和手動

上海區塊鏈會議演講ppt_進行第一次會議演講的完整指南
 error問題)
windows下Call to undefined function curl_init() error問題

數據轉換軟件_數據轉換
)
leetcode 1047. 刪除字符串中的所有相鄰重復項(棧)

spring boot: spring Aware的目的是為了讓Bean獲得Spring容器的服務

10張圖帶你深入理解Docker容器和鏡像

matlab界area_Matlab的數據科學界

javascript異步_JavaScript異步并在循環中等待


hdf5文件和csv的區別_使用HDF5文件并創建CSV文件

CSS仿藝龍首頁鼠標移入圖片放大
)
leetcode 224. 基本計算器(棧)

機械制圖國家標準的繪圖模板_如何使用p5js構建繪圖應用

機器學習常用模型:決策樹_fairmodels:讓我們與有偏見的機器學習模型作斗爭

高德地圖如何將比例尺放大到10米?

Android 手把手帶你玩轉自己定義相機

如何在JavaScript中克隆數組
)
leetcode 227. 基本計算器 II(棧)
