
🔥個人主頁:艾莉絲努力練劍
?專欄傳送門:《C語言》、《數據結構與算法》、C語言刷題12天IO強訓、LeetCode代碼強化刷題、洛谷刷題、C/C++基礎知識知識強化補充、C/C++干貨分享&學習過程記錄
🍉學習方向:C/C++方向學習者
??人生格言:為天地立心,為生民立命,為往圣繼絕學,為萬世開太平
前言:距離我們學完C語言已經過去一段時間了,在學習了初階的數據結構之后,博主還要更新的內容就是【C語言16天強化訓練】,之前博主更新過一個【C語言刷題12天IO強訓】的專欄,那個只是從入門到進階的IO模式真題的訓練。【C語言16天強化訓練】既有IO型,也有接口型。和前面一樣,今天依然是訓練五道選擇題和兩道編程算法題,希望大家能夠有所收獲!

目錄
正文
一、五道選擇題
1.1? 題目1
1.2? 題目2
1.3? 題目3
1.4? 題目4
1.5? 題目5
二、兩道算法題
2.1? 圖片整理
2.1.1 題目理解
2.1.2 思路
2.2? 尋找數組的中心下標
2.2.1? 嘗試暴力寫代碼
2.2.2? 加深題目理解
2.2.3? 優化思路
2.2.4? 優化方案實現
結尾
正文
一、五道選擇題
1.1? 題目1
題干:以下對C語言函數的有關描述中,正確的有( )【多選】
A. 在C語言中,一個函數一般由兩個部分組成,它們是函數首部和函數體
B. 函數的實參和形參可以是相同的名字
C. 在main()中定義的變量都可以在其它被調函數中直接使用
D. 在C程序中,函數調用不能出現在表達式語句中
解析:正確選項是AB。
A.?正確。函數首部包括函數返回類型、函數名和參數列表,函數體包括一對花括號內的語句序列。
B. 正確。實參和形參的作用域不同,實參是調用函數時的實際值,形參是函數定義中的變量,它們可以同名,但代表不同的實體。
C.?錯誤。在main函數中定義的變量是局部變量,只能在main函數內部使用,其他函數不能直接訪問。除非這些變量是全局變量或通過參數傳遞。
D.?錯誤。函數調用可以出現在表達式語句中,例如:int result = add(a,b); 或 printf("Hello"); 都是表達式語句中包含函數調用。
1.2? 題目2
題干:在C語言中,以下正確的說法是( )
A. 實參和與其對應的形參各占用獨立的存儲單元
B. 實參和與其對應的形參共占用一個存儲單元
C. 只有當實參和與其對應的形參同名時才共占用存儲單元
D. 形參是虛擬的,不占用存儲單元
解析:正確選項是A選項。
A. 正確。實參和形參各占用獨立的存儲單元。
B. 錯誤。它們不共享存儲單元,而是各自獨立。
C. 錯誤。是否同名不影響存儲單元的占用,即使同名也是不同的存儲單元(因為作用域不同);
D. 錯誤。形參是函數內的局部變量,會占用存儲單元(通常在棧上)。
在C語言中,函數參數的傳遞是值傳遞(pass by value)。這意味著:
(1)當函數被調用時,實參的值會被復制到形參中;
(2)因此,實參和形參占用不同的存儲單元(即獨立的內存空間);
(3)對形參的修改不會影響實參(除非通過指針間接修改)。
1.3? 題目3
題干:在上下文及頭文件均正常的情況下,下列代碼的輸出是( )(注:print 已經聲明過了)
int main()
{char str[] = "Geneius";print(str);return 0;
}
print(char *s)
{if(*s){print(++s);printf("%c", *s);}
}A.?suiene? ? ?B. neius? ? ?C. run-time error? ? ?D. suieneG
解析:正確選項是A選項。
代碼理解:
1、main函數定義了一個字符串 str =?"Geneius",然后調用?print(str); 。
2、printf 函數是一個遞歸函數——
(1)如果當前字符?
*s?不是空字符(即字符串未結束),則遞歸調用?print(++s)(注意:這里先遞增?s,然后傳入遞歸)。(2)遞歸返回后,打印當前字符?
*s(注意:此時?s?已經遞增過一次,所以指向的是下一個字符)。
執行過程:
原始字符串: "Geneius"(注意:字符串以空字符 '\0' 結尾)。
遞歸調用過程(每次調用 print(++s),所以指針不斷后移):
第一次調用:s指向"Geneius" -> 遞歸調用 print(++s)(現在s指向"eneius");
第二次調用:s指向"eneius" -> 遞歸調用 print(++s)(現在s指向"neius");
第三次調用:s指向"neius" -> 遞歸調用 print(++s)(現在s指向"eius");
第四次調用:s指向"eius" -> 遞歸調用 print(++s)(現在s指向"ius");
第五次調用:s指向"ius" -> 遞歸調用 print(++s)(現在s指向"us");
第六次調用:s指向"us" -> 遞歸調用 print(++s)(現在s指向"s");
第七次調用:s指向"s" -> 遞歸調用 print(++s)(現在s指向空字符'\0');
第八次調用:s指向'\0',條件if(*s)為假,遞歸終止并返回。
調用完然后開始回溯(從最深層的遞歸返回):
第七次調用:s原本指向"s",但調用時是print(++s),所以遞歸返回后,s現在指向空字符(即'\0'之后?實際上已經越界了)。但注意:在遞歸調用中,s的值已經被改變(因為++s是前置遞增,修改了s本身)。所以每次遞歸返回后,s指向的是原來字符串的下一個字符(甚至最后是空字符之后)。
具體回溯時打印的字符:
從最深層的遞歸(第八次調用)返回第七次調用:此時s指向空字符(即'\0')之后?但實際第七次調用時,傳入的s是遞增后的(指向空字符),然后遞歸返回后,s仍然指向空字符(但字符串已經結束)。所以打印的是空字符(不顯示),不過這里的代碼實際上是有問題的。
關鍵錯誤:
在遞歸調用中,使用了 print(++s),這修改了指針s的值。當遞歸返回時,s已經指向下一個字符(而不是原來的字符)。因此——
(1)第一次遞歸調用后,s指向"eneius"(即第二個字符);
(2)當遞歸返回時,打印的是當前s指向的字符(即第二個字符'e'),而不是第一個字符'G'。
類似地,整個回溯過程打印的是字符串從第二個字符開始逆序 (但最后一個是空字符之后,未定義) ,實際上,字符串"Geneius"的長度為7 (加上空字符共8個字節)。遞歸調用直到遇到空字符(第八次調用時,s指向空字符,遞歸停止) 。然后回溯——
第七次調用:s原本指向"s"(最后一個字符),但調用print(++s)后,s指向空字符。然后遞歸返回后,打印*s(即空字符,不顯示)。
第六次調用:s原本指向"us"(即字符'u'),調用print(++s)后,s指向"s"。遞歸返回后,打印*s(即's')。
第五次調用:s原本指向"ius"(即字符'l'),調用print(++s)后,s指向"us"。遞歸返回后,打印*s(即'u')。
第四次調用:s原本指向"eius"(即字符'e'),調用print(++s)后,s指向"lus"。遞歸返回后,打印*s(即'l')。
第三次調用:s原本指向"neius"(即字符'n'),調用print(++s)后,s指向"eius"。遞歸返回后,打印*s(即'e')。
第二次調用:s原本指向"eneius"(即字符'e'),調用print(++s)后,s指向"neius"。遞歸返回后,打印*s(即'n')。
第一次調用:s原本指向"Geneius"(即字符'G'),調用print(++s)后,s指向"eneius"。遞歸返回后,打印*s(即'e')。
所以打印的字符序列是(從最深回溯):' '(空字符,不顯示)、's'、'u'、'i'、'e'、'n'、'e'。
即最終輸出為:"suien"(但缺少第一個字符'G',并且似乎多打了一個'e')。
實際上,輸出應該是:"suiene"(但注意第一個字符'e'是第二次調用打印的,而第一次調用打印的是'e'(第二個字符))。
觀察字符串"Genelus":
索引0: 'G'
索引1: 'e'
索引2: 'n'
索引3: 'e'
索引4: 'i'
索引5: 'u'
索引6: 's'
索引7: '\0'
回溯打印:
遞歸深度7(s指向索引7): 打印*s(即'\0',不顯示);
遞歸深度6(s指向索引6): 打印*s(即's');
遞歸深度5(s指向索引5): 打印*s(即'u');
遞歸深度4(s指向索引4): 打印*s(即'i');
遞歸深度3(s指向索引3): 打印*s(即'e');
遞歸深度2(s指向索引2): 打印*s(即'n');
遞歸深度1(s指向索引1): 打印*s(即'e')。
所以輸出是:suiene(即"suiene")。
注意:原字符串是"Geneius",逆序應為"suieneG",但這里由于遞歸偏移,打印的是從第二個字符開始逆序(即"eneius"的逆序)為"suiene",而沒有第一個'G',所以輸出是"suiene"。
選項D是"suieneG"(多了一個G),實際上,代碼不會打印第一個字符'G',因為第一次調用就遞增了指針;另外,最后遞歸到空字符時,嘗試打印空字符(不顯示),所以沒有額外輸出。
我們來看這四個選項——
選項A正確;
選項B "neius" 是正序"Geneius"的一部分(錯誤);
選項C "run-time error":可能因為最后打印空字符(但不會錯誤,只是不顯示),或者指針越界(但通常不會立即錯誤);
選項D "suieneG" 包含第一個字符'G',但實際沒有。
所以正確答案就是A. suiene。
1.4? 題目4
題干:對于函數 void f(int x); ,下面調用正確的是( )
A. int y=f(9);? ? ?B. f(9);? ? ?C. f(f(9));? ? ?D. x=f();
解析:正確選項是B選項。
于函數?void f(int x); ,這是一個返回類型為 void 的函數,即它不返回任何值。因此:
A. 錯誤,因為 f(9)?沒有返回值,不能賦值給 int y。
B. 正確,直接調用函數,不需要使用返回值。
C. 錯誤,因為?f(9)?沒有返回值,不能作為 f?的參數。
D.?錯誤,因為 f 需要一個 int 類型的參數,這里沒有提供參數;而且 f?沒有返回值,不能賦值給 x。
1.5? 題目5
題干:給定 fun 函數如下,那么 fun(10) 的輸出結果是( )
int fun(int x)
{return (x==1) ? 1 : (x + fun(x-1));
}A. 0? ? ?B. 10? ? ?C. 55? ? ?D. 3628800
解析:正確選項是C選項。
這道題很簡單,函數?fun(int x)?是一個遞歸函數,其邏輯如下:
1)如果 x == 1,返回 1;
2)否則,返回 x + fun(x-1)。
因此,fun(10)?的計算過程如下所示:
fun(10) = 10 + fun(9)
fun(9) = 9 + fun(8)
fun(8) = 8 + fun(7)
fun(7) = 7 + fun(6)
fun(6) = 6 + fun(5)
fun(5) = 5 + fun(4)
fun(4) = 4 + fun(3)
fun(3) = 3 + fun(2)
fun(2) = 2 + fun(1)
fun(1) = 1我們代入計算之后得到——
fun(2) = 2 + 1 = 3
fun(3) = 3 + 3 = 6
fun(4) = 4 + 6 = 10
fun(5) = 5 + 10 = 15
fun(6) = 6 + 15 = 21
fun(7) = 7 + 21 = 28
fun(8) = 8 + 28 = 36
fun(9) = 9 + 36 = 45
fun(10) = 10 + 45 = 55所以,fun(10)?的結果是 55,正確答案選擇C選項。
選擇題答案如下:
1.1? AB
1.2? A
1.3? A
1.4? B
1.5? C
校對一下,大家都做對了嗎?
二、兩道算法題
2.1? 圖片整理
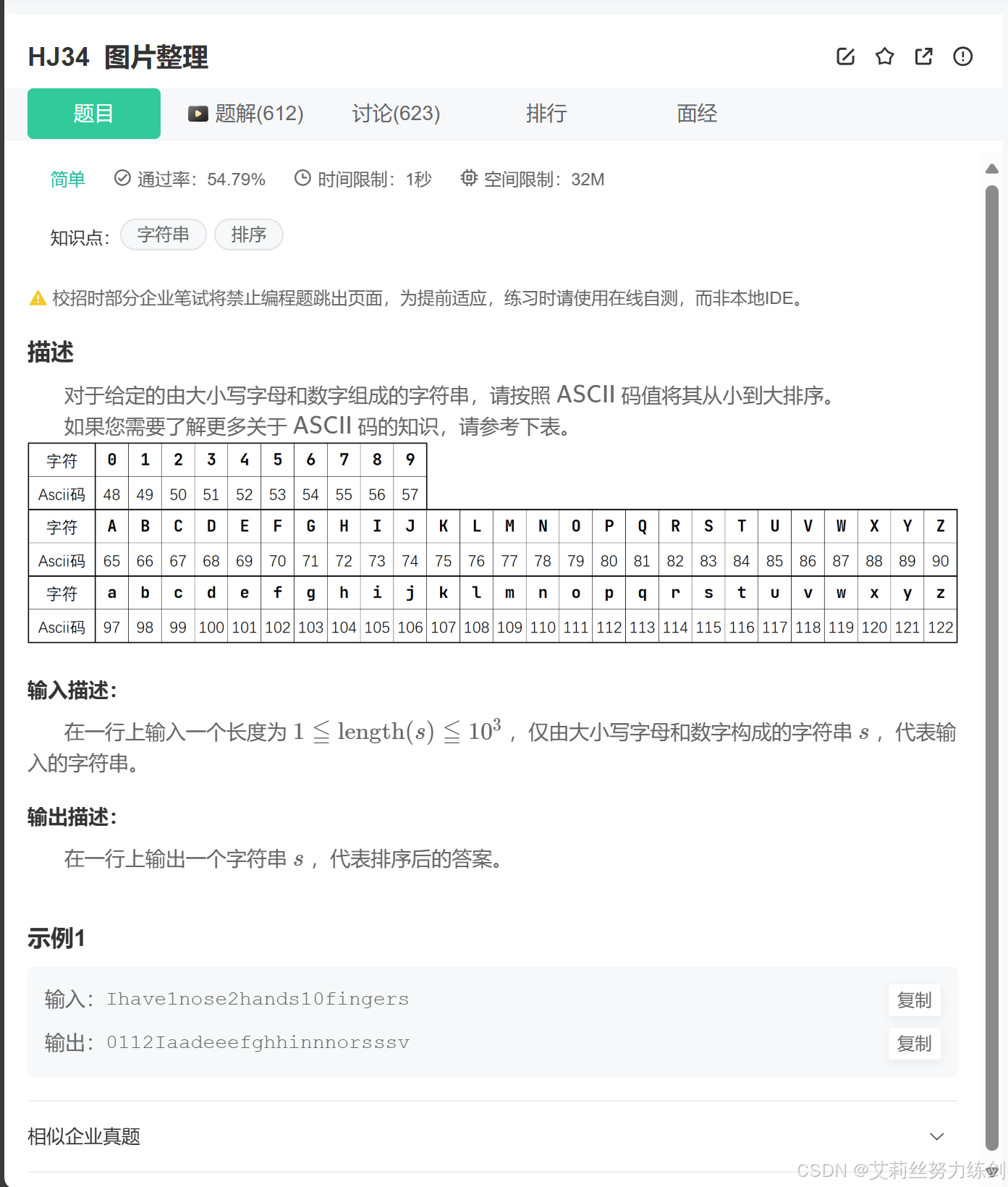
牛客網鏈接:HJ34 圖片整理
題目描述:
2.1.1 題目理解
我們根據題目要求,需要對輸入的字符串按照ASCII碼值進行排序。
這道題是接口型的,下面是C語言的模版(如果是IO型就可以不用管它們了)——
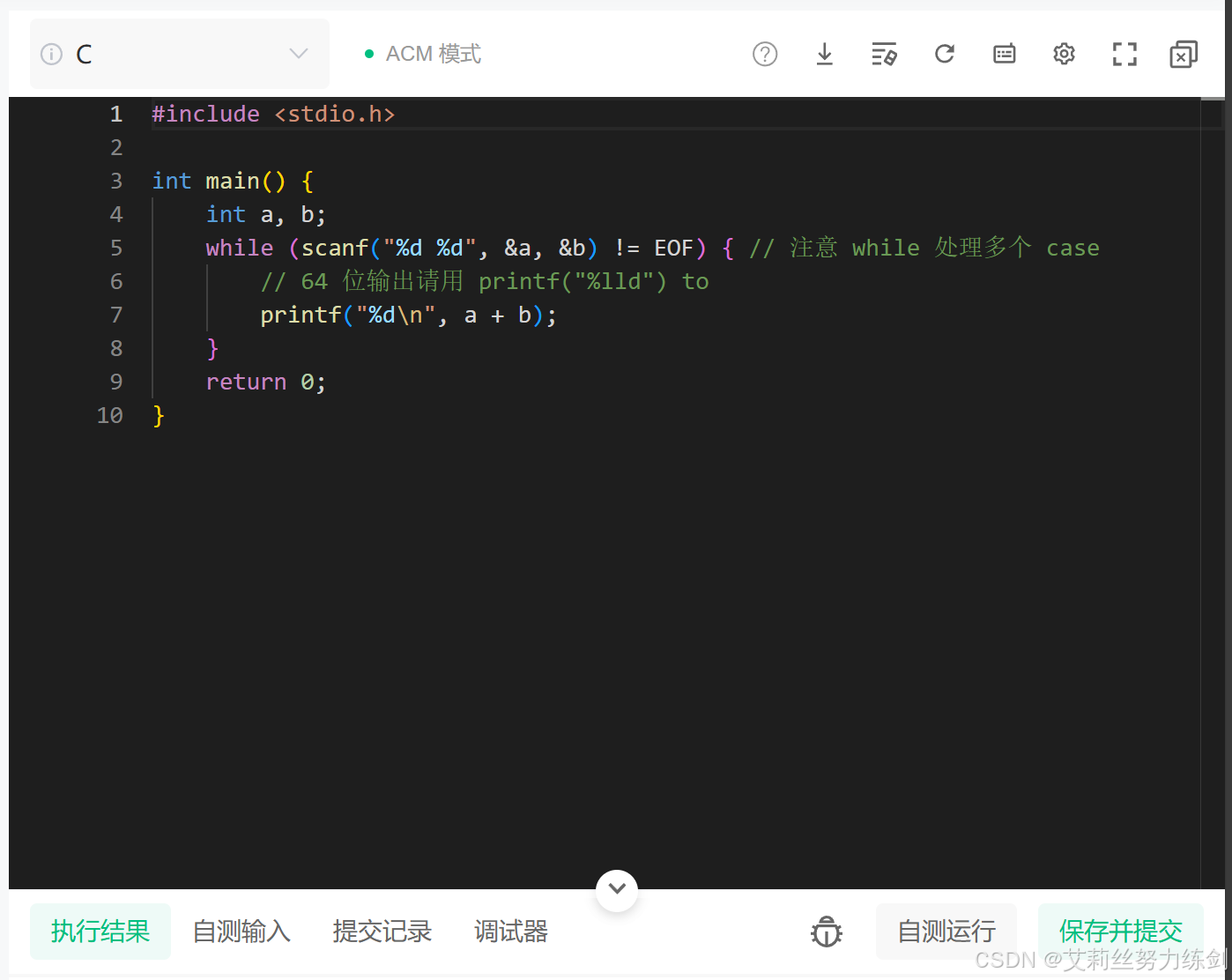
2.1.2 思路
(1)使用scanf讀取輸入字符串;
(2)使用qsort函數進行排序,需要提供一個;
(3)比較函數compare比較函數直接通過字符的ASCII碼值相減來確定順序;
(4)最后使用printf輸出排序后的字符串。
代碼演示:
//C語言
#include <stdio.h>
#include <stdlib.h>
#include <string.h>int compare(const void* a, const void* b)
{return (*(char*)a - *(char*)b);
}int main()
{char s[1001];scanf("%s", s);int len = strlen(s);qsort(s, len, sizeof(char), compare);printf("%s", s);return 0;
}時間復雜度:O(1);
空間復雜度:O(1)。
我們學習了C++之后也可以嘗試用C++來實現一下,看看自己前段時間C++學得怎么樣——
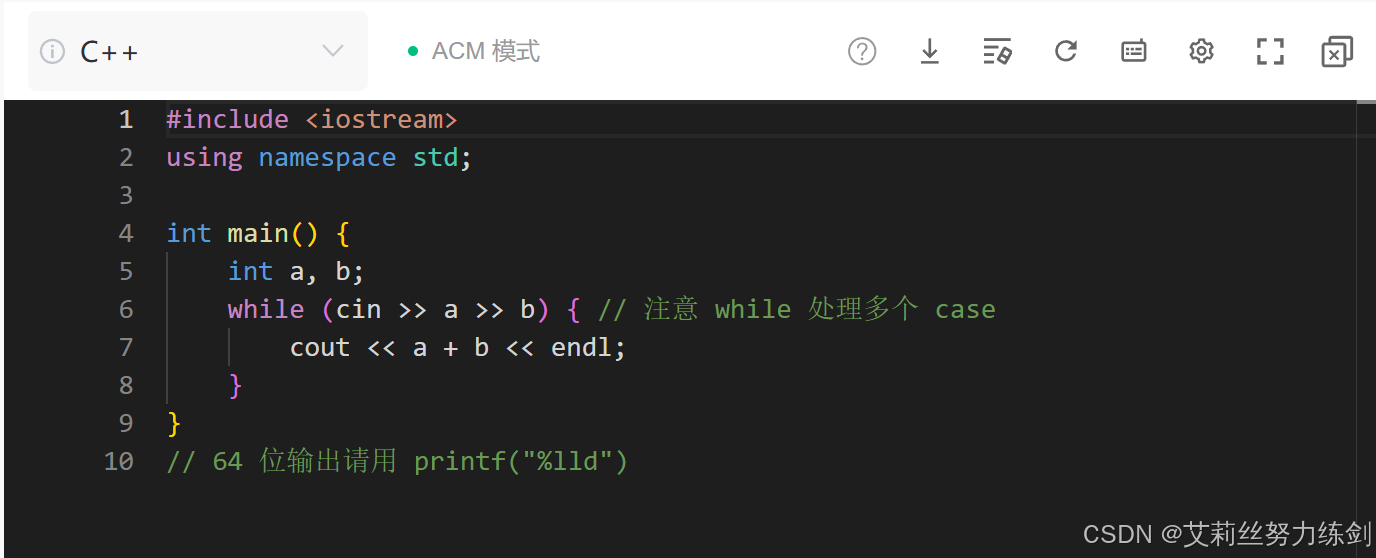
代碼演示:
//C++復盤
#include <iostream>
#include"string"
#include"algorithm"
using namespace std;int main()
{string s;cin >> s;sort(s.begin(), s.end());cout << s << endl;return 0;
}時間復雜度:O(logn),空間復雜度:O(1)。
我們目前要寫出來C++的寫法是非常考驗前面C++的學習情況好不好的,大家可以嘗試去寫一寫,優先掌握C語言的寫法,博主還沒有介紹C++的算法題,之后會涉及的,敬請期待!
2.2? 尋找數組的中心下標
鏈接:724. 尋找數組的中心下標
力扣題解鏈接:前綴和優化法解決【尋找數組的中心下標】問題
題目描述:

2.2.1? 嘗試暴力寫代碼
我們先嘗試用傳統暴力方法:(循環)直接解題——
大致思路:
// 時間復雜度 O(n2)
for (int i = 0; i < n; i++)
{int leftSum = 0, rightSum = 0;// 計算左側和:O(i)for (int j = 0; j < i; j++) {leftSum += nums[j];}// 計算右側和:O(n-i-1)for (int j = i + 1; j < n; j++) {rightSum += nums[j];}if (leftSum == rightSum) return i;
}有了第一種思路,博主展示一下用【暴力方法】解題的代碼:
//C語言實現——迭代暴力方法
int pivotIndex(int* nums, int numsSize)
{for (int i = 0; i < numsSize; i++){int leftsum = 0, rightsum = 0;for (int j = 0; j < i; j++){leftsum += nums[j];}for (int j = i + 1; j < numsSize; j++){rightsum += nums[j];}if (leftsum == rightsum){return i;}}return -1;
}時間復雜度:O(n^2);
空間復雜度:O(1)。
我們不推薦這種方法,時間復雜度不好,還能再優化一下。
2.2.2? 加深題目理解
我們可以用前綴和優化法處理諸如【尋找數組的中心下標】這類"尋找平衡點"問題; 這種方法避免了每次計算左右兩側和的重復計算,通過數學關系直接判斷,效率很高。
2.2.3? 優化思路
(1)計算總和:首先遍歷整個數組,計算所有元素的總和;
(2)遍歷尋找中心下標:再次遍歷數組,維護一個左側和的變量;
(3)檢查條件:對于每個位置i,檢查 左側和 == 總和 - 左側和 - 當前元素,
等價于檢查 2 * 左側和 == 總和 - 當前元素;
(4)返回結果:如果找到滿足條件的位置,立即返回;如果遍歷完都沒找到,返回-1。
這道題是接口型的,下面是C語言的模版(如果是IO型就可以不用管它們了)——
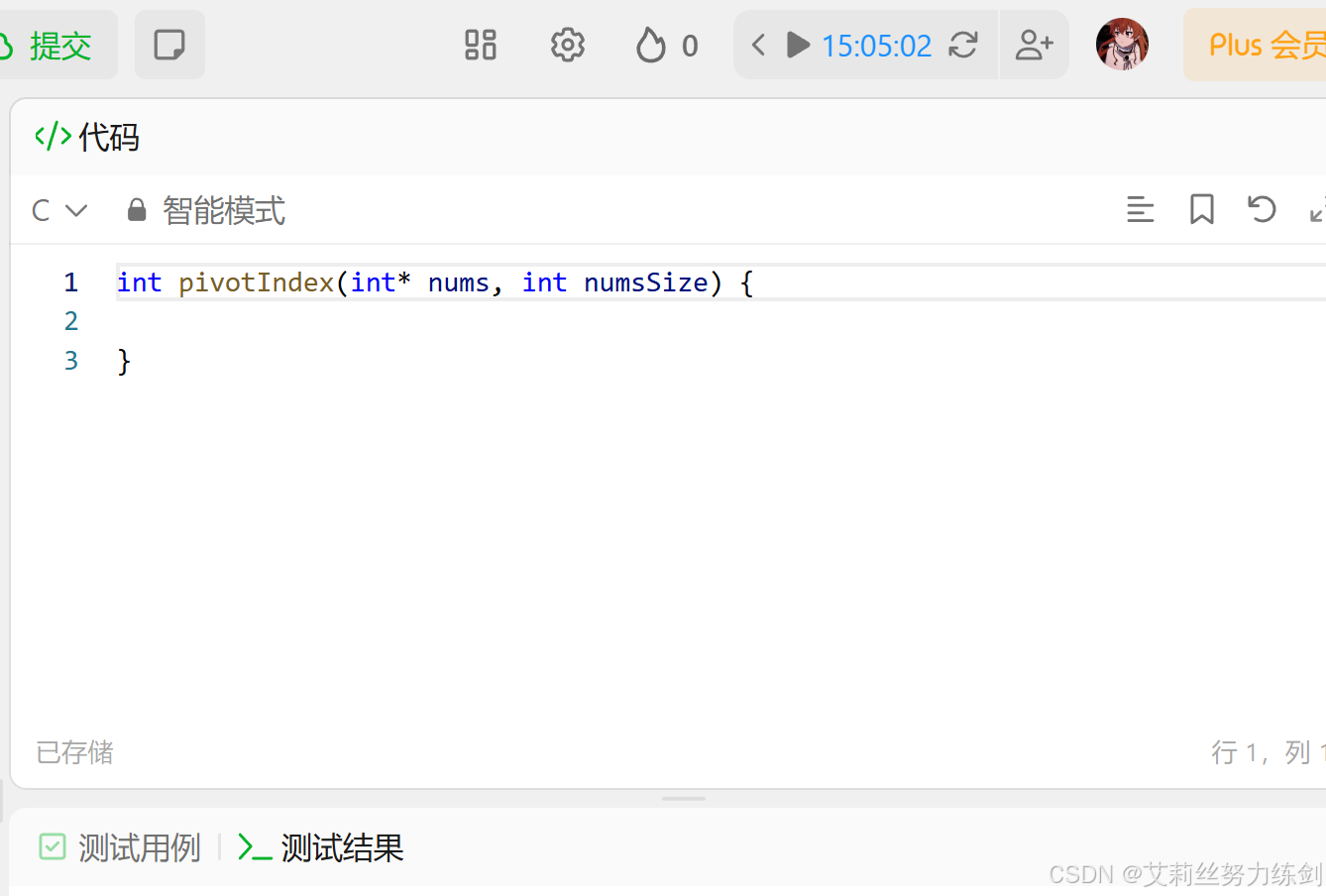
2.2.4? 優化方案實現
代碼演示:
int pivotIndex(int* nums, int numsSize) {int total = 0;// 計算數組所有元素的總和for (int i = 0; i < numsSize; i++){total += nums[i];}int leftSum = 0;for (int i = 0; i < numsSize; i++){// 右側元素之和 = 總和 - 左側元素之和 - 當前元素if (leftSum == total - leftSum - nums[i]){return i;}leftSum += nums[i];}return -1;
}時間復雜度:O(1);
空間復雜度:O(1)。
我們學習了C++之后也可以嘗試用C++來實現一下,看看自己前段時間C++學得怎么樣——
代碼演示:
//C++實現
#include<vector>
using namespace std;class Solution {
public:int pivotIndex(vector<int>& nums) {int total = 0;// 計算數組所有元素的總和for (int num : nums){total += num;}int leftSum = 0;for (int i = 0; i < nums.size(); i++){// 右側元素之和 = 總和 - 左側元素之和 - 當前元素if (leftSum == total - leftSum - nums[i]){return i;}leftSum += nums[i];}return -1;}
};時間復雜度:O(n),空間復雜度:O(1)。
我們目前要寫出來C++的寫法是非常考驗前面C++的學習情況好不好的,大家可以嘗試去寫一寫,優先掌握C語言的寫法,博主還沒有介紹C++的算法題,之后會涉及的,敬請期待!
結尾
本文內容到這里就全部結束了,希望大家練習一下這幾道題目,這些基礎題最好完全掌握!
往期回顧:
【C語言16天強化訓練】從基礎入門到進階:Day 6
【C語言16天強化訓練】從基礎入門到進階:Day 5
【C語言16天強化訓練】從基礎入門到進階:Day 4
【C語言16天強化訓練】從基礎入門到進階:Day 3
【C語言16天強化訓練】從基礎入門到進階:Day 2
【C語言16天強化訓練】從基礎入門到進階:Day 1
結語:感謝大家的閱讀,記得給博主“一鍵四連”,感謝友友們的支持和鼓勵!

:概念篇 - 從“想當然”到“真相”)

)















