機器學習常用模型:決策樹
TL; DR (TL;DR)
The R Package fairmodels facilitates bias detection through model visualizations. It implements a few mitigation strategies that could reduce bias. It enables easy to use checks for fairness metrics and comparison between different Machine Learning (ML) models.
R Package 公平模型 通過模型可視化促進偏差檢測。 它實施了一些緩解策略,可以減少偏差。 它使易于使用的公平性檢查檢查和不同機器學習(ML)模型之間的比較成為可能。
長版 (Long version)
Bias mitigation is an important topic in Machine Learning (ML) fairness field. For python users, there are algorithms already implemented, well-explained, and described (see AIF360). fairmodels provides an implementation of a few popular, effective bias mitigation techniques ready to make your model fairer.
偏差緩解是機器學習(ML)公平性領域的重要主題。 對于python用戶,已經實現,充分解釋和描述了算法(請參閱AIF360 )。 fairmodels提供了一些流行的有效的偏差緩解技術的實現,這些技術可以使您的模型更加公平。
我的模型有偏見,現在呢? (I have a biased model, now what?)
Having a biased model is not the end of the world. There are lots of ways to deal with it. fairmodels implements various algorithms to help you tackle that problem. Firstly, I must describe the difference between the pre-processing algorithm and the post-processing one.
帶有偏見的模型并不是世界末日。 有很多方法可以處理它。 fairmodels實現了各種算法來幫助您解決該問題。 首先,我必須描述預處理算法和后處理算法之間的區別。
Pre-processing algorithms work on data before the model is trained. They try to mitigate the bias between privileged subgroup and unprivileged ones through inference from data.
在訓練模型之前, 預處理算法會對數據進行處理 。 他們試圖通過數據推斷來減輕特權子群體與非特權子群體之間的偏見。
Post-processing algorithms change the output of the model explained with DALEX so that its output does not favor the privileged subgroup so much.
后處理算法更改了用DALEX解釋的模型的輸出,因此其輸出不太喜歡特權子組。
這些算法如何工作? (How do these algorithms work?)
In this section, I will briefly describe how these bias mitigation techniques work. Code for more detailed examples and some visualizations used here may be found in this vignette.
在本節中,我將簡要描述這些偏差緩解技術的工作原理。 在此插圖中可以找到更詳細的示例代碼和此處使用的一些可視化效果。
前處理 (Pre-processing)
不同的沖擊消除劑(Feldman等,2015) (Disparate impact remover (Feldman et al., 2015))
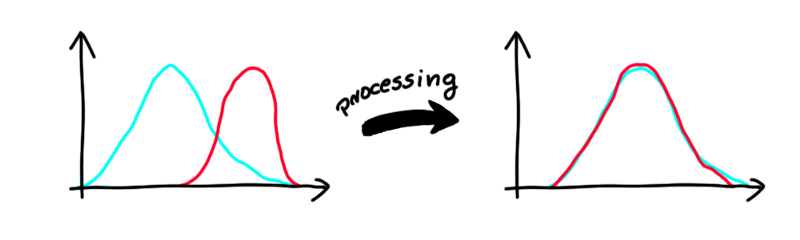
This algorithm works on numeric, ordinal features. It changes the column values so the distributions for the unprivileged (blue) and privileged (red) subgroups are close to each other. In general, we would like our algorithm not to judge on value of the feature but rather on percentiles (e.g., hiring 20% of best applicants for the job from both subgroups). The way that this algorithm works is that it finds such distribution that minimizes earth mover’s distance. In simple words, it finds the “middle” distribution and changes values in this feature for each subgroup.
此算法適用于數字順序特征。 它更改列的值,以便非特權(藍色)和特權(紅色)子組的分布彼此接近。 總的來說,我們希望我們的算法不是根據功能的價值來判斷,而是根據百分位數來判斷(例如,從兩個子組中聘請20%的最佳求職者)。 該算法的工作方式是找到使推土機距離最小的分布。 用簡單的話說,它找到“中間”分布并為每個子組更改此功能中的值。
Reweightnig (Kamiran et al。,2012) (Reweightnig (Kamiran et al., 2012))

Reweighting is a simple but effective tool for minimizing bias. The algorithm looks at the protected attribute and on the real label. Then, it calculates the probability of assigning favorable label (y=1) assuming the protected attribute and y are independent. Of course, if there is bias, they will be statistically dependent. Then, the algorithm divides calculated theoretical probability by true, empirical probability of this event. That is how weight is created. With these 2 vectors (protected variable and y ) we can create weights vector for each observation in data. Then, we pass it to the model. Simple as that. But some models don’t have weights parameter and therefore can’t benefit from this method.
重新加權是最小化偏差的簡單但有效的工具。 該算法查看受保護的屬性和實標簽。 然后,假設受保護的屬性和y獨立,則計算分配有利標簽(y = 1)的可能性。 當然,如果存在偏差,它們將在統計上相關。 然后,算法將計算出的理論概率除以該事件的真實,經驗概率。 重量就是這樣產生的。 使用這兩個向量(保護變量和y),我們可以為數據中的每個觀察值創建權重向量。 然后,我們將其傳遞給模型。 就那么簡單。 但是某些模型沒有權重參數,因此無法從該方法中受益。
重采樣(Kamiran et al。,2012) (Resampling (Kamiran et al., 2012))
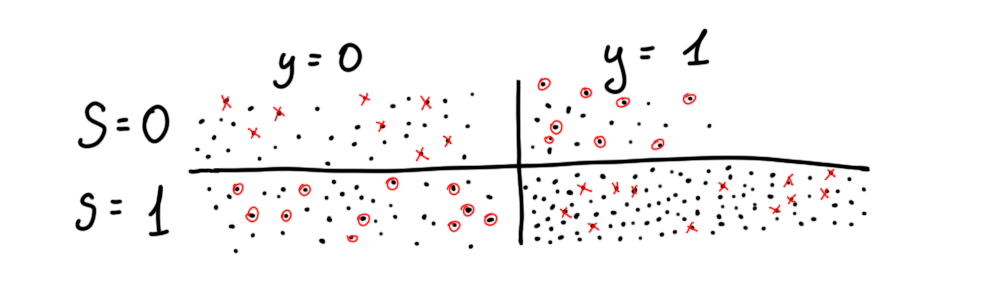
Resampling is closely related to the prior method as it implicitly uses reweighting to calculate how many observations must be omitted/duplicated in a particular case. Imagine there are 2 groups, deprived (S = 0) and favored (S = 1). This method duplicates observations from a deprived subgroup when the label is positive and omits observations with a negative label. The opposite is then performed on the favored group. There are 2 types of resampling methods implemented- uniform and preferential. Uniform randomly picks observations (like in the picture) whereas preferential utilizes probabilities to pick/omit observations close to cutoff (default is 0.5).
重采樣與先前的方法密切相關,因為它隱式使用重新加權來計算在特定情況下必須省略/重復多少個觀測值。 想象一下,有2個組,被剝奪(S = 0)和受青睞(S = 1)。 當標簽為正時,此方法復制來自被剝奪子組的觀察結果,而忽略帶有負標簽的觀察。 然后對喜歡的組執行相反的操作。 有兩種重采樣方法: 統一和優先 。 均勻地隨機選擇觀測值(如圖中所示),而“ 優先級”則利用概率來選擇/忽略接近臨界值的觀測值(默認值為0.5)。
后期處理 (Post-processing)
Post-processing takes place after creating an explainer. To create explainer we need the model and DALEX explainer. Gbm model will be trained on adult dataset predicting whether a certain person earns more than 50k annually.
在創建解釋器后進行后處理。 要創建解釋器,我們需要模型和DALEX解釋器。 Gbm模型將接受成人訓練 預測某個人的年收入是否超過5萬的數據集。
library(gbm)library(DALEX)library(fairmodels)data("adult")
adult$salary <- as.numeric(adult$salary) -1
protected <- adult$sex
adult <- adult[colnames(adult) != "sex"] # sex not specified
# making modelset.seed(1)
gbm_model <-gbm(salary ~. , data = adult, distribution = "bernoulli")
# making explainer
gbm_explainer <- explain(gbm_model,
data = adult[,-1],
y = adult$salary,
colorize = FALSE)基于拒絕選項的分類(數據透視) (Kamiran等,2012) (Reject Option based Classification (pivot) (Kamiran et al., 2012))
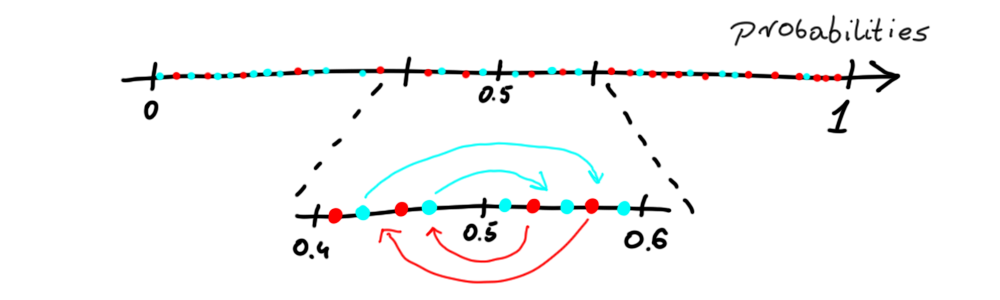
ROC pivot is implemented based on Reject Option based Classification. Algorithm switches labels if an observation is from the unprivileged group and on the left of the cutoff. The opposite is then performed for the privileged group. But there is an assumption that the observation must be close (in terms of probabilities) to cutoff. So the user must input some value theta so that the algorithm will know how close must observation be to the cutoff for the switch. But there is a catch. If just the label was changed DALEX explainer would have a hard time properly calculating the performance of the model. For that reason instead of labels, in fairmodels implementation of this algorithm that is the probabilities that are switched (pivoted). They are just moved to the other side but with equal distance to the cutoff.
ROC數據透視是基于基于拒絕選項的分類實現的。 如果觀察值來自非特權組且位于截止值的左側,則算法會切換標簽。 然后對特權組執行相反的操作。 但是有一個假設,即觀察結果(在概率方面)必須接近臨界值。 因此,用戶必須輸入一些值theta,以便算法將知道必須觀察到與開關的截止點有多接近。 但是有一個問題! 如果僅更改標簽,DALEX解釋器將很難正確計算模型的性能。 因此,在公平模型中 ,此算法代替了標簽,而是切換(樞軸化)的概率。 它們只是移動到另一側,但與截止點的距離相等。
截止操作 (Cutoff manipulation)
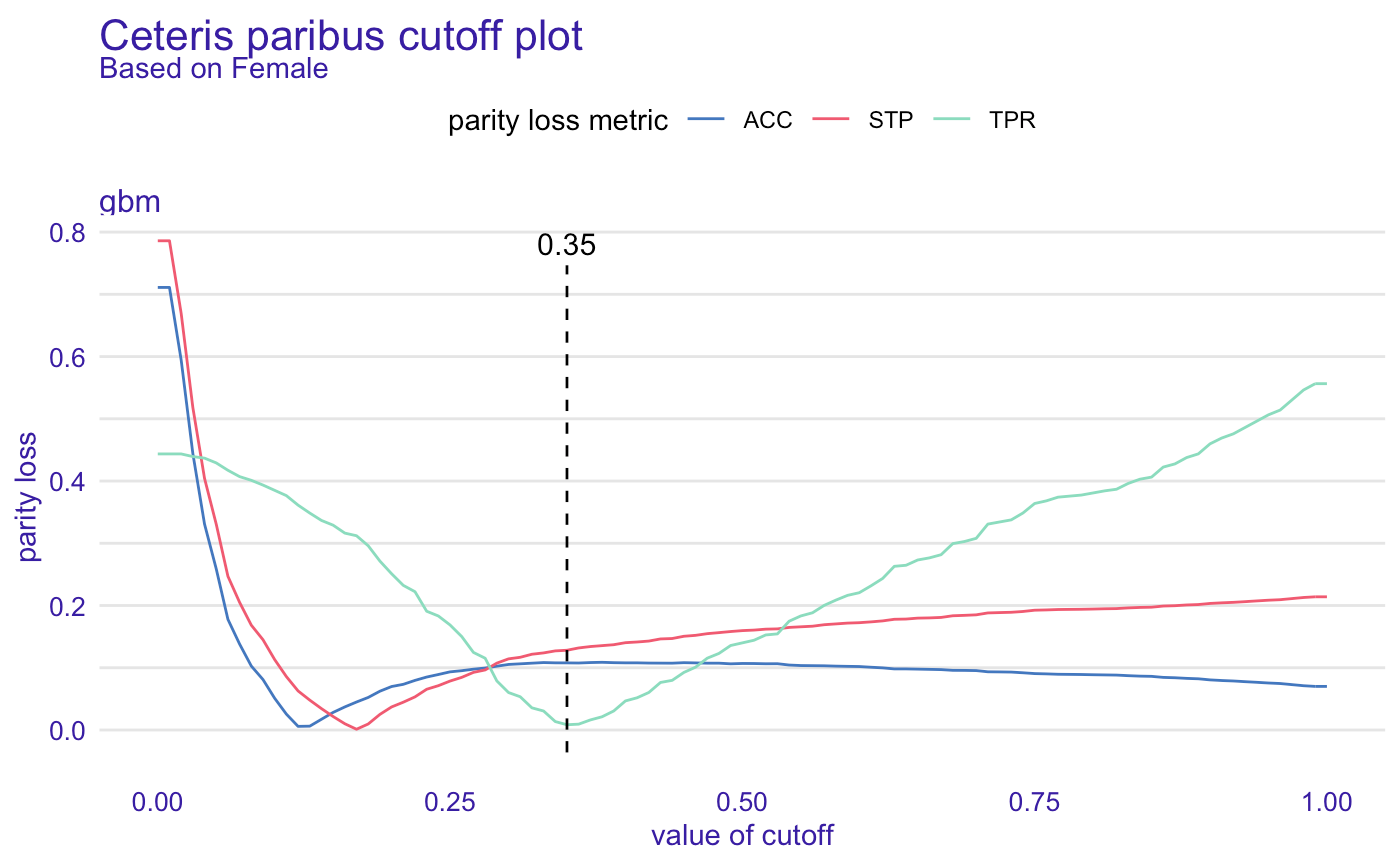
Cutoff manipulation might be a great idea for minimizing the bias in a model. We simply choose metrics and subgroup for which the cutoff will change. The plot shows where the minimum is and for that value of cutoff parity loss will be the lowest. How to create fairness_object with the different cutoff for certain subgroup? It is easy!
截斷操作對于最小化模型中的偏差可能是一個好主意。 我們僅選擇截止值將更改的指標和子組。 該圖顯示了最小值所在的位置,并且對于該閾值, 奇偶校驗損耗將是最低的。 如何為某些子組創建具有不同截止值的fairness_object? 這很容易!
fobject <- fairness_check(gbm_explainer,
protected = protected,
privileged = "Male",
label = "gbm_cutoff",
cutoff = list(Female = 0.35))Now the fairness_object (fobject) is a structure with specified cutoff and it will affect both fairness metrics and performance.
現在, fairness_object(fobject)是具有指定截止值的結構,它將同時影響公平性指標和性能。
公平與準確性之間的權衡 (The tradeoff between fairness and accuracy)
If we want to mitigate bias we must be aware of possible drawbacks of this action. Let’s say that Statical Parity is the most important metric for us. Lowering parity loss of this metric will (probably) result in an increase of False Positives which will cause the accuracy to drop. For this example (that you can find here) a gbm model was trained and then treated with different bias mitigation techniques.
如果我們想減輕偏見,我們必須意識到這一行動的可能弊端。 假設靜態奇偶校驗是我們最重要的指標。 降低此度量的奇偶校驗損失將(可能)導致誤報的增加,這將導致準確性下降。 對于此示例(您可以在此處找到),對gbm模型進行了訓練,然后使用了不同的偏差緩解技術對其進行了處理。
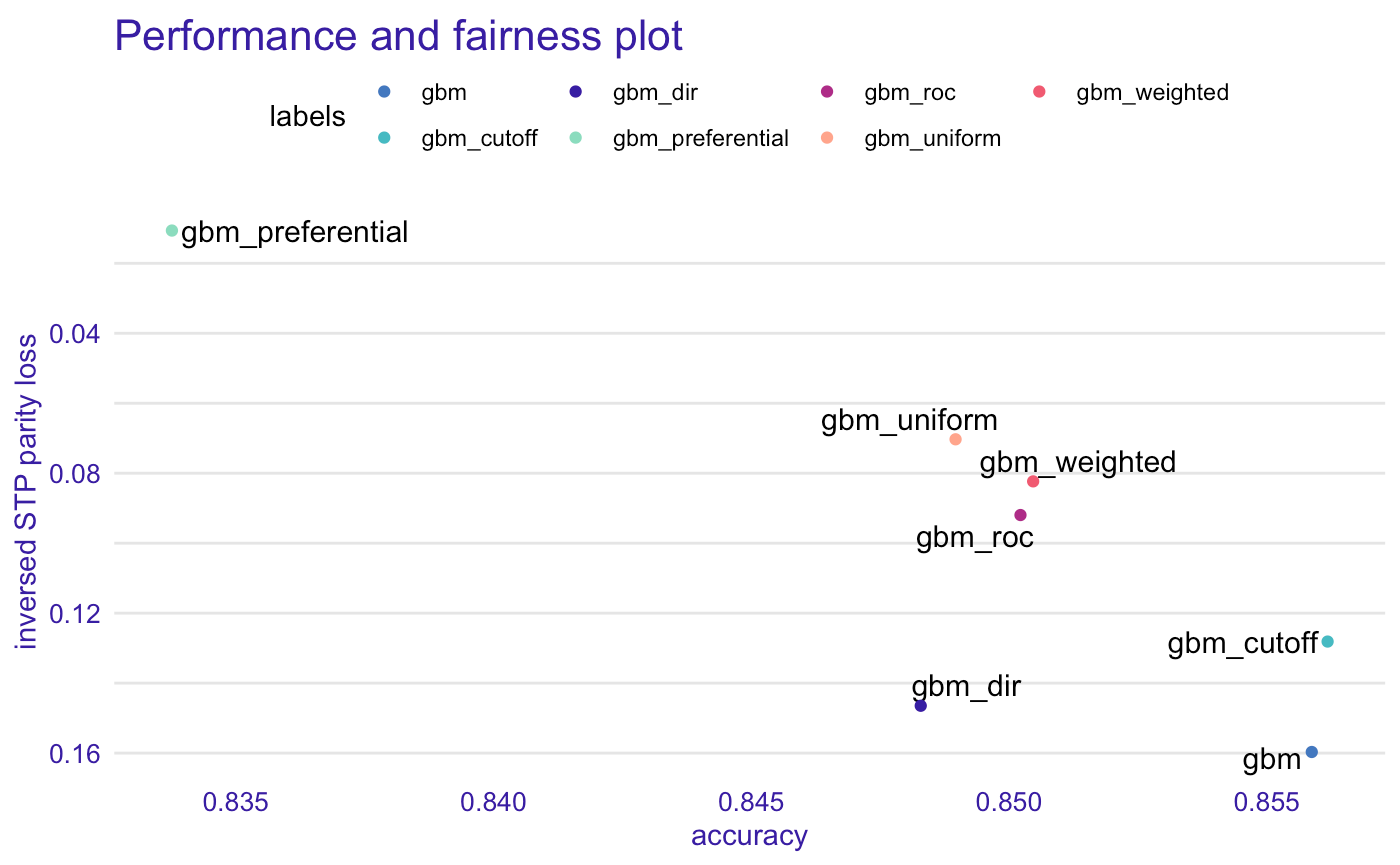
The more we try to mitigate the bias, the less accuracy we get. This is something natural for this metric and the user should be aware of it.
我們越努力減輕偏差,獲得的準確性就越低。 這對于該指標是很自然的事情,用戶應該意識到這一點。
摘要 (Summary)
Debiasing methods implemented in fairmodels are certainly worth trying. They are flexible and most of them are suited for every model. Most of all they are easy to use.
在公平模型中實現的去偏置方法當然值得嘗試。 它們非常靈活,并且大多數適用于每種型號。 最重要的是它們易于使用。
接下來要讀什么? (What to read next?)
Blog post about introduction to fairness, problems, and solutions
關于公平,問題和解決方案介紹的博客文章
Blog post about fairness visualization
關于公平可視化的博客文章
學到更多 (Learn more)
Check the package’s GitHub website for more details
檢查軟件包的GitHub網站以獲取更多詳細信息
Tutorial on full capabilities of the fairmodels package
fairmodels軟件包的全部功能教程
Tutorial on bias mitigation techniques
緩解偏見技術的教程
翻譯自: https://towardsdatascience.com/fairmodels-lets-fight-with-biased-machine-learning-models-f7d66a2287fc
機器學習常用模型:決策樹
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/391631.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/391631.shtml 英文地址,請注明出處:http://en.pswp.cn/news/391631.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

高德地圖如何將比例尺放大到10米?

Android 手把手帶你玩轉自己定義相機

如何在JavaScript中克隆數組
)
leetcode 227. 基本計算器 II(棧)

100米隊伍,從隊伍后到前_我們的隊伍

idea使用 git 撤銷commit
pdf)
ES6標準入門(第二版)pdf

hexo博客添加暗色模式_我如何向網站添加暗模式

leetcode 331. 驗證二叉樹的前序序列化

mongodb數據可視化_使用MongoDB實時可視化開放數據

4.kafka的安裝部署

javascript初學者_針對JavaScript初學者的調試技巧和竅門

leetcode 705. 設計哈希集合

ecshop 前臺個人中心修改側邊欄 和 側邊欄顯示不全 或 導航現實不全

leetcode 706. 設計哈希映射

數據庫語言 數據查詢_使用這種簡單的查詢語言開始查詢數據

面向對象編程思想-觀察者模式

typescript 使用_如何使用TypeScript輕松修改Minecraft

