How to find Missing values in a data frame using Python/Pandas
如何使用Python / Pandas查找數據框中的缺失值
介紹: (Introduction:)
When you start working on any data science project the data you are provided is never clean. One of the most common issue with any data set are missing values. Most of the machine learning algorithms are not able to handle missing values. The missing values needs to be addressed before proceeding to applying any machine learning algorithm.
當您開始從事任何數據科學項目時,所提供的數據永遠不會干凈。 任何數據集最常見的問題之一就是缺少值。 大多數機器學習算法無法處理缺失值。 在繼續應用任何機器學習算法之前,需要解決缺少的值。
Missing values can be handled in different ways depending on if the missing values are continuous or categorical. In this section I will address how to find missing values. In the next article i will address on how to address the missing values.
根據缺失值是連續的還是分類的,可以用不同的方式來處理缺失值。 在本節中,我將介紹如何查找缺失值。 在下一篇文章中,我將介紹如何解決缺失值。
查找缺失值: (Finding Missing Values:)
For this exercise i will be using “listings.csv” data file from Seattle Airbnb data. The data can be found under this link : https://www.kaggle.com/airbnb/seattle?select=listings.csv
在本練習中,我將使用Seattle Airbnb數據中的“ listings.csv”數據文件。 可以在以下鏈接下找到數據: https : //www.kaggle.com/airbnb/seattle?select=listings.csv
Step 1: Load the data frame and study the structure of the data frame.
步驟1:加載數據框并研究數據框的結構。
First step is to load the file and look at the structure of the file. When you have a big dateset with high number of columns it is hard to look at each columns and study the types of columns.
第一步是加載文件并查看文件的結構。 如果日期集較大且列數很高,則很難查看每個列并研究列的類型。
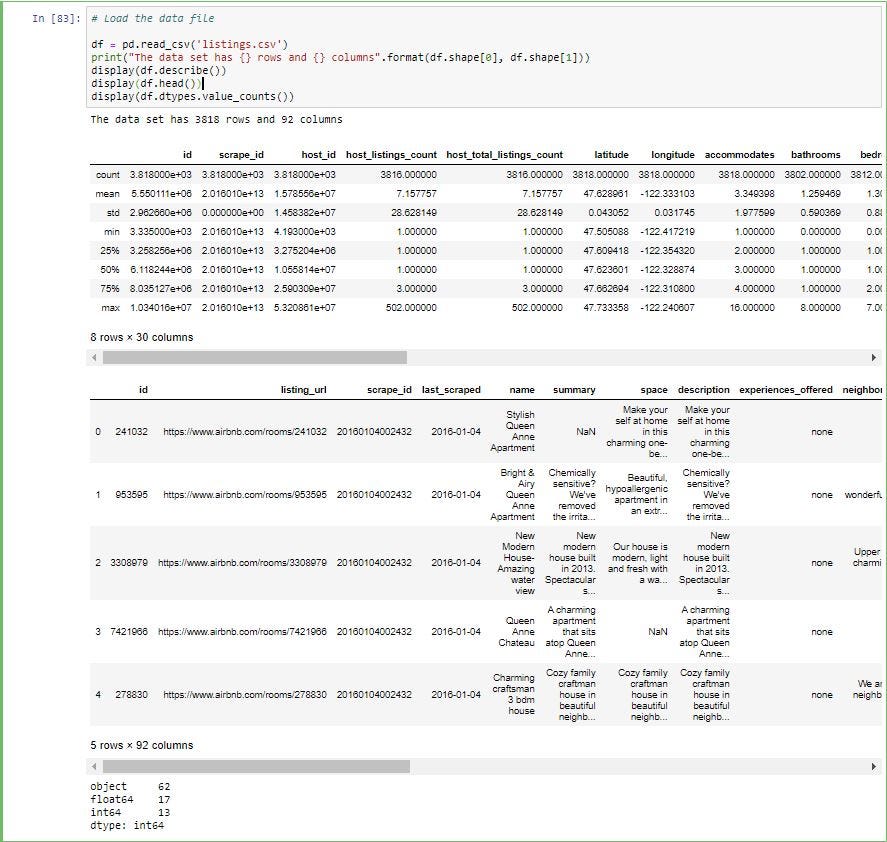
To find out how many of the columns are categorical and numerical we can use pandas “dtypes” to get the different data types and you can use pandas “value_counts()” function to get count of each data type. Value_counts groups all the unique instances and gives the count of each of those instances.
要了解有多少列是分類列和數字列,我們可以使用pandas“ dtypes”來獲取不同的數據類型,還可以使用pandas“ value_counts()”函數來獲取每種數據類型的計數。 Value_counts對所有唯一實例進行分組,并給出每個實例的計數。
As you can see below we have 62 columns which are objects (categorical data), 17 columns which are of float data type and 13 columns which are of int data type.
如下所示,我們有62列是對象(分類數據),有17列是浮點數據類型,有13列是int數據類型。
Step 2: Separate categorical and numerical columns in the data frame
步驟2:將數據框中的類別和數字列分開
The reason to separate the categorical and numerical columns in the data frame is the method of handling missing values are different between these two data type which i will walk through in the next section.
在數據框中分隔類別和數字列的原因是,這兩種數據類型之間處理缺失值的方法不同,我將在下一節中介紹這些方法。
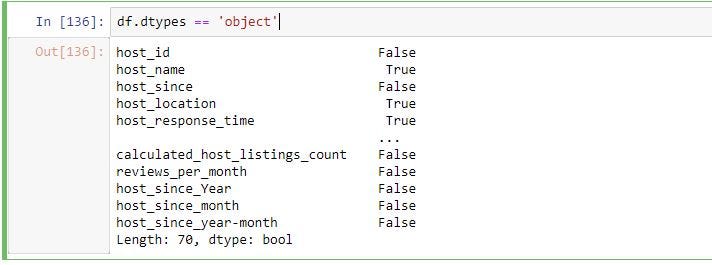
The easiest way to achieve this step is through filtering out the columns from the original data frame by data type. By using “dtypes” function and equality operator you can get which columns are objects (categorical variable) and which are not.
實現此步驟的最簡單方法是按數據類型從原始數據幀中過濾出列。 通過使用“ dtypes”函數和相等運算符,您可以了解哪些列是對象(分類變量),哪些不是。
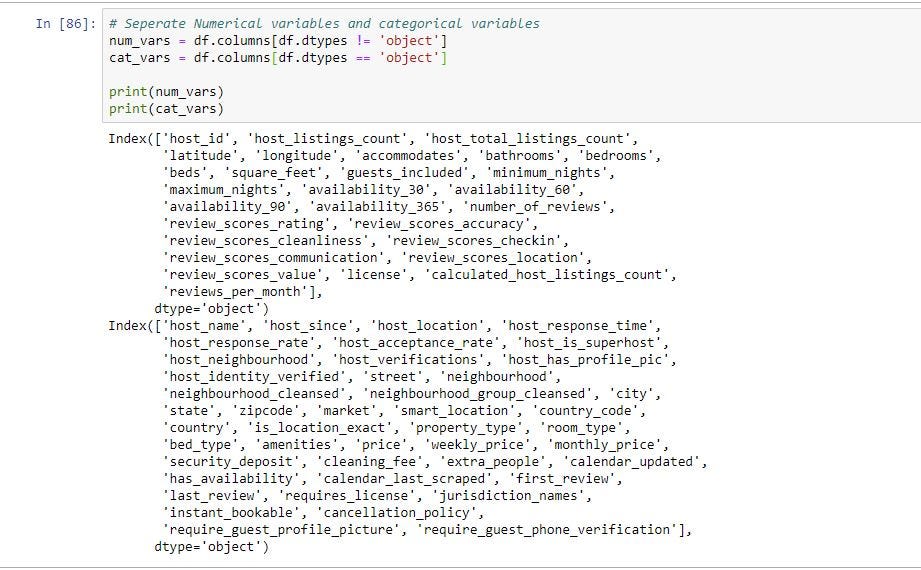
To get the column names of the columns which satisfy the above conditions we can use “df.columns”. The below code gives column names which are objects and column names which are not objects.
要獲得滿足上述條件的列的列名,我們可以使用“ df.columns”。 下面的代碼給出了作為對象的列名和不是對象的列名。
As you can see below we separated the original data frame into 2 and assigned them new variables. One for for categorical variables and one for non-categorical variables.
如下所示,我們將原始數據幀分為2個并為其分配了新變量。 一種用于分類變量,另一種用于非分類變量。
Step 3: Find the missing values
步驟3:找出遺漏的值
Finding the missing values is the same for both categorical and continuous variables. We will use “num_vars” which holds all the columns which are not object data type.
對于分類變量和連續變量,找到缺失值都是相同的。 我們將使用“ num_vars”來保存所有非對象數據類型的列。
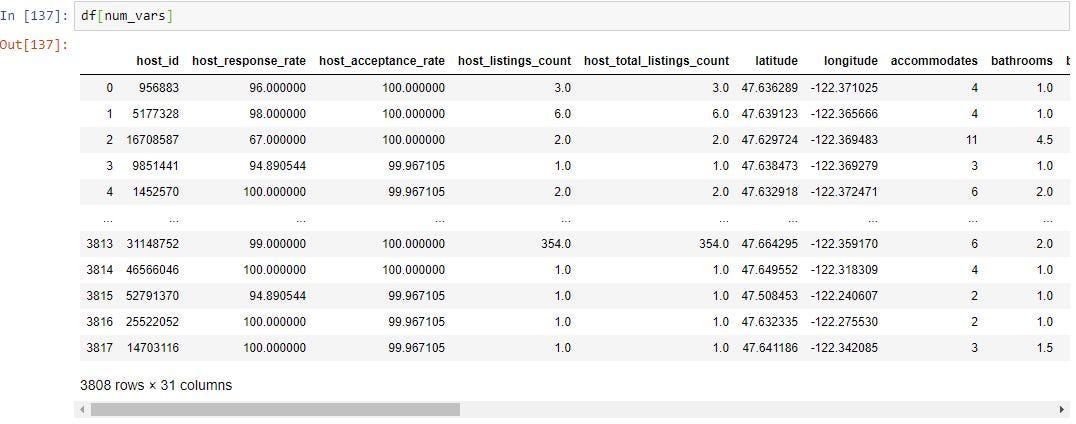
df[num_vars] will give you all the columns in “num_vars” which consists of all the columns in the data frame which are not object data type.
df [num_vars]將為您提供“ num_vars”中的所有列,該列由數據框中的所有非對象數據類型的列組成。
We can use pandas “isnull()” function to find out all the fields which have missing values. This will return True if a field has missing values and false if the field does not have missing values.
我們可以使用熊貓的“ isnull()”函數來找出所有缺少值的字段。 如果字段缺少值,則返回True,否則返回false。
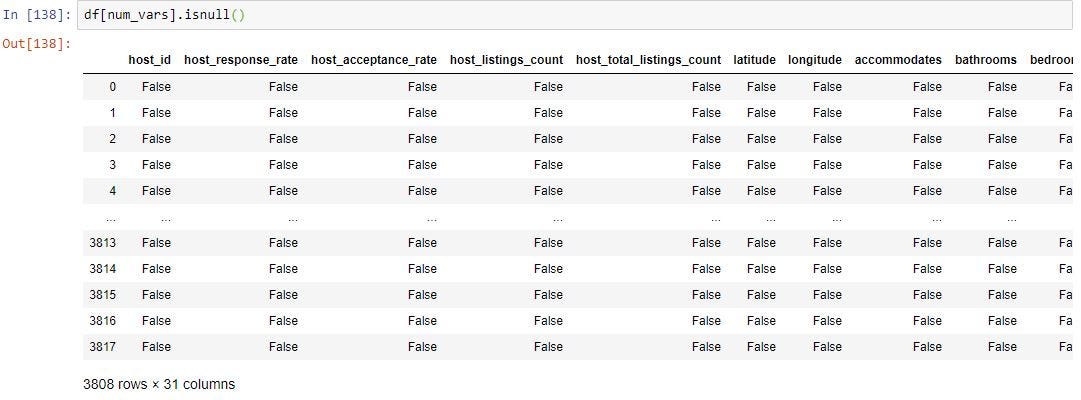
To get how many missing values are in each column we use sum() along with isnull() which is shown below. This will sum up all the True’s in each column from the step above.
為了獲得每列中有多少個缺失值,我們使用sum()以及isull() ,如下所示。 這將匯總上述步驟中每一列中的所有True。
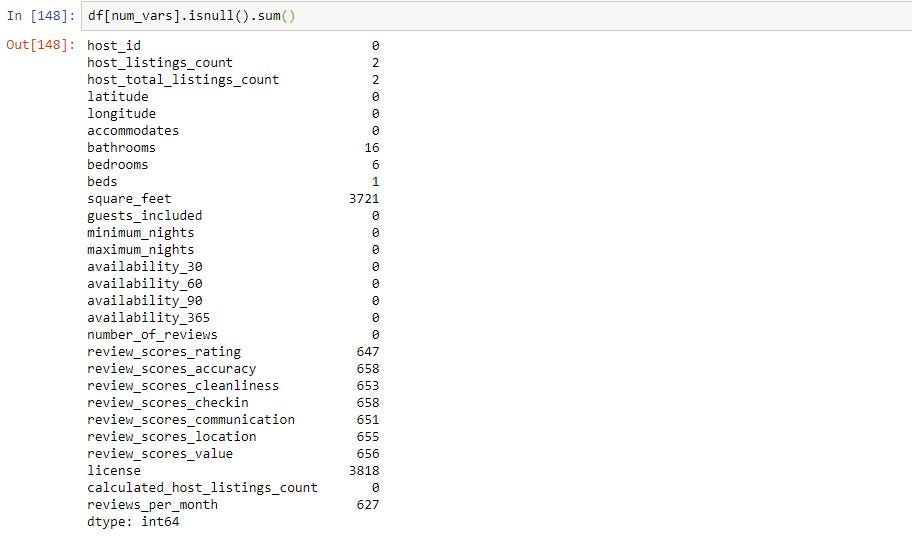
Its always good practice to sort the columns in descending order so you can see what are the columns with highest missing values. To do this we can use sort_values() function. By default this function will sort in ascending order. Since we want the columns with highest missing values first we want to set it to descending. You can do this by passing “ascending=False” paramter in sort_values().
始終最好的做法是按降序對列進行排序,以便您可以看到缺失值最高的列。 為此,我們可以使用sort_values()函數。 默認情況下,此功能將按升序排序。 因為我們首先要使缺失值最高的列,所以我們希望將其設置為降序。 您可以通過在sort_values()中傳遞“ ascending = False”參數來實現。

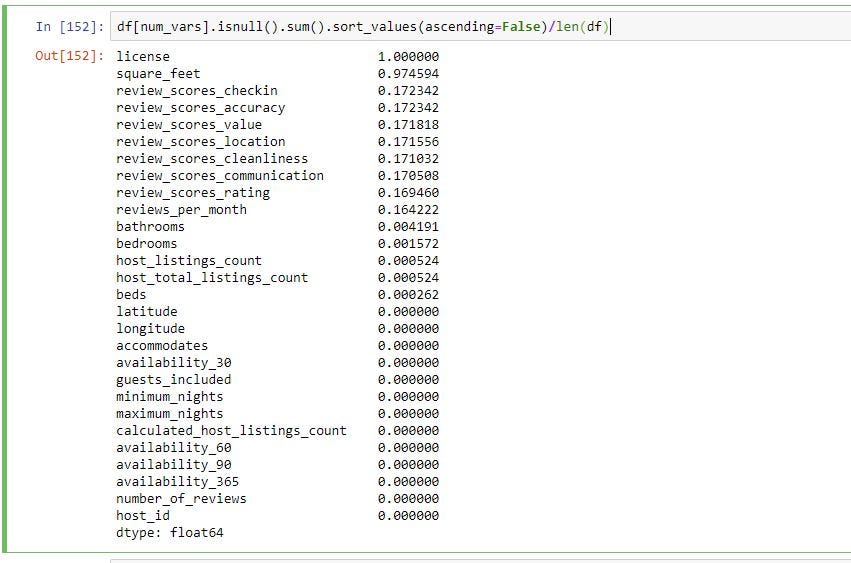
The above give you the count of missing values in each column. To get % of missing values in each column you can divide by length of the data frame. You can “len(df)” which gives you the number of rows in the data frame.
上面給出了每一列中缺失值的計數。 要獲得每一列中丟失值的百分比,您可以除以數據幀的長度。 您可以“ len(df)”,它為您提供數據框中的行數。
As you can see below license column is missing 100% of the data and square_feet column is missing 97% of data.
如您所見,License列缺少100%的數據,square_feet列缺少97%的數據。

結論 (Conclusion)
The above article goes over on how to find missing values in the data frame using Python pandas library. Below are the steps
上面的文章介紹了如何使用Python pandas庫在數據框中查找缺失值。 以下是步驟
Use isnull() function to identify the missing values in the data frame
使用isnull()函數來識別數據框中的缺失值
Use sum() functions to get sum of all missing values per column.
使用sum()函數可獲取每列所有缺失值的總和。
use sort_values(ascending=False) function to get columns with the missing values in descending order.
使用sort_values(ascending = False)函數以降序獲取缺少值的列。
Divide by len(df) to get % of missing values in each column.
用len(df)除以得到每一列中丟失值的%。
In this section we identified missing values, in the next we go over on how to handle these missing values.
在本節中,我們確定了缺失值,接下來,我們將繼續介紹如何處理這些缺失值。
翻譯自: https://medium.com/analytics-vidhya/python-finding-missing-values-in-a-data-frame-3030aaf0e4fd
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/391612.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/391612.shtml 英文地址,請注明出處:http://en.pswp.cn/news/391612.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

)
leetcode 54. 螺旋矩陣(遞歸)


phpstorm 調試_PhpStorm中的多用戶調試

Tableau Desktop認證:為什么要關心以及如何通過

約束布局constraint-layout導入失敗的解決方案 - 轉

)
leetcode 59. 螺旋矩陣 II(遞歸)
:函數與函數式編程)
前端基礎進階(七):函數與函數式編程

期權數據 獲取_我如何免費獲得期權數據


js值的拷貝和值的引用_到達P值的底部:直觀的解釋
)
leetcode 115. 不同的子序列(dp)

監督學習-KNN最鄰近分類算法

istio 和 kong_如何啟動和運行Istio
)
js練習--貪吃蛇(轉)
![bzoj千題計劃169:bzoj2463: [中山市選2009]誰能贏呢?](http://pic.xiahunao.cn/bzoj千題計劃169:bzoj2463: [中山市選2009]誰能贏呢?)
bzoj千題計劃169:bzoj2463: [中山市選2009]誰能贏呢?

無監督學習-主成分分析和聚類分析

struts實現分頁_在TensorFlow中實現點Struts
