數據探索性分析
When we hear about Data science or Analytics , the first thing that comes to our mind is Modelling , Tuning etc. . But one of the most important and primary steps before all of these is Exploratory Data Analysis or EDA.
當我們聽到有關數據科學或分析的知識時,想到的第一件事就是建模,調整等。 但是,在所有這些步驟中最重要和最主要的步驟之一是探索性數據分析或EDA。

為什么選擇EDA (Why EDA)
In Data Science one of the Major problem Data Scientists/Analysts are facing today is the Data Quality . Since we rely on multiple sources for data , data quality is often compromised.The quality of Data determines the quality of models which we are building on it .As the adage goes,Garbage in , garbage out . The above statement holds very true in the case of Data science.
在數據科學領域,數據科學家/分析師當今面臨的主要問題之一是數據質量。 由于我們依賴于多個數據源,因此數據質量常常受到損害。數據的質量決定了我們在其上構建的模型的質量。 上面的陳述在數據科學領域非常正確。
We cannot build Empire State Building or Burj Khalifa on a shaky foundation !
我們不能在搖搖欲墜的基礎上建造帝國大廈或哈利法塔!
And that explains why 60–80% of time of Data Scientists are being spent on Data gathering and Data preparation.
這就解釋了為什么將60-80%的數據科學家的時間都花在數據收集和數據準備上。
When we are working with Data , EDA or Exploratory Data Analysis is the most important step .It is very important to gather as much information and insights from data as we could before processing it . This could be done by EDA. EDA Also help us to analyse the underlying trends and patterns in data and also help us to formulate our problem statement in a better way .
當我們處理數據時,EDA或探索性數據分析是最重要的步驟。在處理數據之前,從數據中收集盡可能多的信息和見解非常重要。 這可以由EDA完成。 EDA還可以幫助我們分析數據的潛在趨勢和模式,還可以幫助我們更好地制定問題陳述。
“ Well begun is half done”
“ 好的開始已經完成了一半”
Exploratory Data Analysis helps to understand the data better and also it helps to understand what Data speaks.This could be done both by visual analysis as well as with few other analysis.Also EDA helps to distinguish between what to be pursued further and what is not worth following up.
探索性數據分析有助于更好地理解數據,也有助于理解數據的含義,這既可以通過可視化分析也可以通過很少的其他分析來完成,此外EDA有助于區分需要進一步追求的目標和不追求的目標值得跟進。
Exploratory Data Analysis
探索性數據分析
Let’s explore steps of Exploratory data analysis using Bank loan Data set
讓我們探索使用銀行貸款數據集進行探索性數據分析的步驟
Import the Libraries:
導入庫:
To perform initial analysis , we would need libraries like Numpy, Pandas,Seaborn and Matplotlib. Numpy is an array processing package.Its a library for numerical computations .Pandas is used for data manipulation and analysis. Matplotlib and Seaborn are statistical libraries used for data visualization
為了進行初步分析,我們需要Numpy,Pandas,Seaborn和Matplotlib之類的庫。 Numpy是一個數組處理程序包,它是一個用于數值計算的庫.Pandas用于數據處理和分析。 Matplotlib和Seaborn是用于數據可視化的統計庫

Import Dataset:
導入數據集:
Data is stored in csv file format, hence we are importing it using pd.read_csv
數據以csv文件格式存儲,因此我們使用pd.read_csv導入數據

Imported data from the file is stored in bankloan_df dataframe
從文件導入的數據存儲在bankloan_df數據框中
Information of data set:
數據集信息:
.info() will display information about the data frames
.info()將顯示有關數據幀的信息

It shows the column names,number of rows and columns, data types etc.It gives an idea about what type of data it is .It is very important to understand whether a column represents categorical or numerical variable , if categorical we should understand whether its ordinal or nominal .We need to treat each of these data types differently which I will explain in another post.You can use .astype to change the datatype of a column
它顯示列名,行數和列數,數據類型等。它給出有關數據類型的信息。了解列是表示類別變量還是數值變量非常重要,如果是類別變量,則應了解其類型順序或標稱。我們需要對每種數據類型進行不同的處理,這將在另一篇文章中進行解釋。您可以使用.astype更改列的數據類型

If need to know only the number of rows and columns .shape can be used
如果只需要知道行數和列數,可以使用.shape

To see the data type , bankloan_df.dtypes can be used
要查看數據類型,可以使用bankloan_df.dtypes
To check the null values bankloan_df.isnull().sum() can be used
要檢查空值,可以使用bankloan_df.isnull()。sum()

Descriptive Analysis :
描述性分析:
.describe() is used for descriptive analysis , it provides details like count, mean, standard deviation, Inter Quartile Range etc.This analysis helps to understand the skewness of data.
.describe()用于描述性分析,它提供了諸如計數,均值,標準差,四分位數間距等詳細信息。此分析有助于理解數據的偏度。

In the case of categorical variables,to check the representation of different groups , we use groupby. This is used to analyze whether any group is over represented than other . If such under representation is there for target variable, we need to treat it with certain techniques like SMOTE.
對于分類變量,為了檢查不同組的表示形式,我們使用groupby。 這用于分析是否有任何一個組比另一個組高。 如果目標變量存在這種表示不足的情況,則需要使用某些技術(例如SMOTE)對其進行處理。

Graphical analysis:
圖形分析:
Graphs are very important tool to understand the data distribution .We use different graphs for analyzing data. We use it for Univariate, Bi Variate and Multi Variate Analysis. Seaborn is a very good library to explore different graphs. I will explain few very common graphs in the analysis here and will write a post in detail about graphs later.
圖是了解數據分布的非常重要的工具。我們使用不同的圖來分析數據。 我們將其用于單變量,雙變量和多變量分析。 Seaborn是一個很好的圖書館,可以探索不同的圖形。 在這里的分析中,我將解釋一些非常常見的圖形,稍后將詳細撰寫有關圖形的文章。
Uni variate Analysis — Analysis where we consider only one variable. Few uni variate graphs are Count Plot, Box Plot etc.
單變量分析-僅考慮一個變量的分析。 很少有單變量圖是計數圖,箱形圖等。
Countplot:-Countplot shows the counts of observations in each category using bars
Countplot:-Countplot使用條形圖顯示每個類別中的觀察計數


Boxplot:-A box plot (or box-and-whisker plot) shows the distribution of quantitative data.The box shows the quartiles of the dataset while the whiskers extend to show the rest of the distribution, except for points that are determined to be “outliers” using a method that is a function of the inter-quartile range.
Boxplot:-箱形圖(或箱須圖)顯示定量數據的分布。框顯示數據集的四分位數,而晶須延伸以顯示其余分布,確定點除外使用四分位間距范圍的函數的“異常值”。

To identify outliers also we use boxplots
為了識別異常值,我們還使用箱線圖

Bi Variate Analysis is where relationship between two variables are plotted in the graph and in Multi variate Analysis , relationship between different variables represented using graphs.
雙變量分析是在圖中繪制兩個變量之間的關系的地方,而在多變量分析中,則是使用圖表表示的不同變量之間的關系的地方。
Pairplot is a Bi Variate graph which is used to analyse the relationship between different variables in a dataset. This is very important step for Model building.
Pairplot是Bi Variate圖,用于分析數據集中不同變量之間的關系。 這對于模型構建非常重要。

Correlation
相關性
Correlation is another important step of EDA. While building a model, its important to understand whether any correlation exists between the independent variables and also with independent variable and dependent variable. This also helps in feature selection/elimination.
關聯是EDA的另一個重要步驟。 在構建模型時,重要的是要了解自變量之間以及自變量和因變量之間是否存在任何關聯。 這也有助于特征選擇/消除。
Values closer to +1 and -1 are considered as maximum correlated variables.The values in diagonal is the correlation of variable with itself and it will always be +1.
接近+1和-1的值被視為最大相關變量。對角線的值是變量與其自身的相關性,它將始終為+1。

Correlation graphs can be designed using the below code snippet
可以使用以下代碼片段設計相關圖

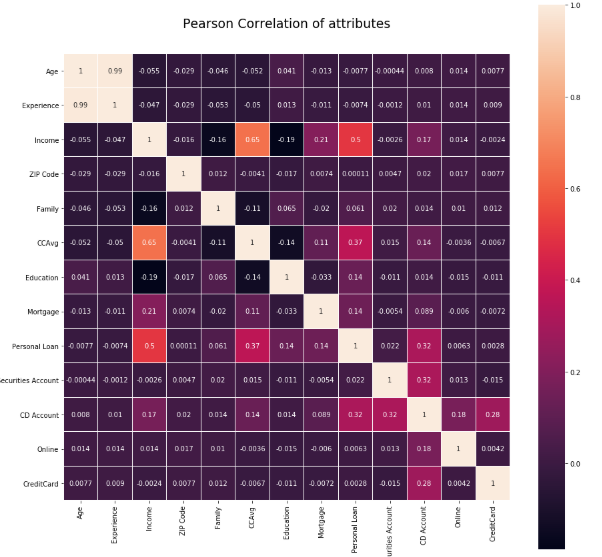
These are initial few steps of Exploratory data analysis. Based on the findings of each step ,one can take appropriate action to improve data quality ,analyse the trend or to treat missing variables/Outliers or anomaly appropriately.
這些是探索性數據分析的最初幾個步驟。 根據每個步驟的發現,可以采取適當的措施來改善數據質量,分析趨勢或適當地處理缺失的變量/異常值或異常。
“Information is the oil of the 21st century, and analytics is the combustion engine.” — Peter Sondergaard,Gartner Research
“信息是21世紀的石油,分析是內燃機。” -Peter Sondergaard,Gartner研究
翻譯自: https://medium.com/@viveksmenon/exploratory-data-analysis-d464f3adb777
數據探索性分析
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/389704.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/389704.shtml 英文地址,請注明出處:http://en.pswp.cn/news/389704.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

5930. 兩棟顏色不同且距離最遠的房子


c++與c語言的區別部分

stata中心化處理_帶有stata第2部分自定義配色方案的covid 19可視化

5201. 給植物澆水

Anaconda配置和使用

qml: C++調用qml函數

python 插補數據_python 2020中缺少數據插補技術的快速指南

5186. 區間內查詢數字的頻率

![[原創]java獲取word里面的文本](http://pic.xiahunao.cn/[原創]java獲取word里面的文本)
[原創]java獲取word里面的文本

ab 模擬_Ab測試第二部分的直觀模擬

1886. 判斷矩陣經輪轉后是否一致

samba登陸密碼不正確

Java構造函數的深入理解

1967. 作為子字符串出現在單詞中的字符串數目

判斷IE版本與各瀏覽器的語句

各類軟件馬斯洛需求層次分析_需求的分析層次

