python 插補數據
Most machine learning algorithms expect complete and clean noise-free datasets, unfortunately, real-world datasets are messy and have multiples missing cells, in such cases handling missing data becomes quite complex.
大多數機器學習算法期望完整且干凈的無噪聲數據集,但不幸的是,現實世界的數據集比較雜亂,缺少多個單元格,在這種情況下,處理丟失的數據變得相當復雜。
Therefore in today’s article, we are going to discuss some of the most effective and indeed easy-to-use data imputation techniques which can be used to deal with missing data.
因此,在今天的文章中,我們將討論一些最有效且確實易于使用的數據插補技術,這些技術可用于處理丟失的數據。
So without any further delay, let’s get started.
因此,沒有任何進一步的延遲,讓我們開始吧。

什么是數據歸因? (What is Data Imputation?)
Data Imputation is a method in which the missing values in any variable or data frame(in Machine learning) is filled with some numeric values for performing the task. Using this method the sample size remains the same, only the blanks which were missing are now filled with some values. This method is easy to use but the variance of the dataset is reduced.
數據插補是一種方法,其中(在機器學習中)任何變量或數據框中的缺失值都填充有一些數字值,以執行任務。 使用此方法,樣本大小保持不變,現在僅將缺少的空白 填充一些值 。 這種方法易于使用,但數據集的方差減小了。
為什么要進行數據插補? (Why Data Imputation?)
There can be various reasons for imputing data, many real-world datasets(not talking about CIFAR or MNIST) containing missing values which can be in any form such as blanks, NaN, 0s, any integers or any categorical symbol. Instead of just dropping the Rows or Columns containing the missing values which come at the price of losing data which may be valuable, a better strategy is to impute the missing values.
插補數據可能有多種原因,許多現實世界的數據集(不涉及CIFAR或MNIST)包含缺失值,這些缺失值可以采用任何形式,例如空格,NaN,0,任何整數或任何分類符號 。 更好的策略是估算缺失值 ,而不是僅僅刪除包含缺失值的行或列,而這些缺失值會以丟失可能有價值的數據為代價 。
Having a good theoretical knowledge is amazing but implementing them in code in a real-time machine learning project is a completely different thing. You might get different and unexpected results based on different problems and datasets. So as a Bonus,I am also adding the links to the various courses which has helped me a lot in my journey to learn Data science and ML, experiment and compare different data imputations strategies which led me to write this article on comparisons between different data imputations methods.
擁有良好的理論知識是驚人的,但是在實時機器學習項目中以代碼實現它們是完全不同的。 根據不同的問題和數據集,您可能會得到不同且出乎意料的結果。 因此,作為獎勵,我還添加了到各種課程的鏈接,這些鏈接對我學習數據科學和ML,實驗和比較不同的數據歸因策略有很大幫助,這使我撰寫了有關不同數據之間的比較的本文。歸因方法。
I am personally a fan of DataCamp, I started from it and I am still learning through DataCamp and keep doing new courses. They seriously have some exciting courses. Do check them out.
我個人是 DataCamp 的粉絲 ,我從此開始,但仍在學習 DataCamp 并繼續 學習 新課程。 他們認真地開設了一些令人興奮的課程。 請檢查一下。
1.處理缺少輸入的數據 (1. handling-missing-data-with-imputations-in-r)
2.在Python中處理丟失的數據 (2. dealing-with-missing-data-in-python)
3.處理R中的缺失數據 (3. dealing-with-missing-data-in-r)
4.在Python中構建數據工程管道 (4. building-data-engineering-pipelines-in-python)
5.數據工程概論 (5. introduction-to-data-engineering)
6.用Python進行數據處理 (6. data-manipulation-with-python)
7.熊貓數據處理 (7. data-manipulation-with-pandas)
8.使用R進行數據處理 (8. data-manipulation-with-r)
P.S: I am still using DataCamp and keep doing courses in my free time. I actually insist the readers to try out any of the above courses as per their interest, to get started and build a good foundation in Machine learning and Data Science. The best thing about these courses by DataCamp is that they explain it in a very elegant and different manner with a balanced focus on practical and well as conceptual knowledge and at the end, there is always a Case study. This is what I love the most about them. These courses are truly worth your time and money. These courses would surely help you also understand and implement Deep learning, machine learning in a better way and also implement it in Python or R. I am damn sure you will love it and I am claiming this from my personal opinion and experience.
PS:我仍在使用 DataCamp, 并在 業余時間 繼續 上課 。 我實際上是堅持要求讀者根據自己的興趣嘗試上述任何課程,以開始并為機器學習和數據科學打下良好的基礎。 DataCamp 開設的這些課程的最好之 處 在于,他們以非常優雅且與眾不同的方式 對課程進行了 解釋,同時重點關注實踐和概念知識,最后始終進行案例研究。 這就是我最喜歡他們的地方。 這些課程確實值得您花費時間和金錢。 這些課程肯定會幫助您更好地理解和實施深度學習,機器學習,并且還可以在Python或R中實現它。我該死的,您一定會喜歡它的,我是從我個人的觀點和經驗中主張這一點的。
Also, I have noticed that DataCamp is giving unlimited access to all the courses for free for one week starting from 1st of September through 8th September 2020, 12 PM EST. So this would literally be the best time to grab some yearly subscriptions(which I have) which basically has unlimited access to all the courses and other things on DataCamp and make fruitful use of your time sitting at home during this Pandemic. So go for it folks and Happy learning
此外,我注意到, DataCamp 自2020年9月1日至美國東部時間12 PM,為期一周免費無限制地訪問所有課程。 因此,從字面上看,這將是獲取一些年度訂閱(我擁有)的最佳時間,該訂閱基本上可以無限制地訪問 DataCamp 上的所有課程和其他內容, 并可以在這次大流行期間充分利用您在家里的時間。 因此,請親朋好友學習愉快
Coming back to the topic -
回到主題-
Sklearn.impute package provides 2 types of imputations algorithms to fill in missing values:
Sklearn.impute包提供了兩種插補算法來填充缺失值:
1. SimpleImputer (1. SimpleImputer)
SimpleImputer is used for imputations on univariate datasets, univariate datasets are datasets that have only a single variable. SimpleImputer allows us to impute values in any feature column using only missing values in that feature space.
SimpleImputer用于單變量數據集的插補, 單變量數據集是僅具有單個變量的數據集。 SimpleImputer允許我們僅使用該要素空間中的缺失值來插補任何要素列中的值 。
There are different strategies provided to impute data such as imputing with a constant value or using the statistical methods such as mean, median or mode to impute data for each column of missing values.
提供了不同的策略來估算數據,例如以恒定值進行估算,或使用統計方法(例如均值,中位數或眾數)為缺失值的每一列估算數據。
For categorical data representations, it has support for ‘most-frequent’ strategy which is like the mode of numerical values.
對于分類數據表示,它支持“最頻繁”策略,就像數值模式一樣。





2.迭代計算機 (2. IterativeImputer)
IterativeImputer is used for imputations on multivariate datasets, multivariate datasets are datasets that have more than two variables or feature columns per observation. IterativeImputer allows us to make use of the entire dataset of available features columns to impute the missing values.
IterativeImputer用于對多元數據集進行插補, 多元數據集是每個觀察值具有兩個以上變量或特征列的數據集。 IterativeImputer允許我們利用可用要素列的整個數據集來估算缺失值。
In IterativeImpute each feature with a missing value is used as a function of other features with known output and models the function for imputations. The same process is then iterated in a loop for some iterations and at each step, a feature column is selected as output y and other feature columns are treated as inputs X, then a regressor is fit on (X, y) for known y and is used to predict the missing values of y.
在IterativeImpute與缺失值的每個特征被用作與已知的輸出和模式插補函數其它特征的函數 。 然后,在循環中重復相同的過程進行一些迭代,并在每個步驟中,選擇一個特征列作為 輸出y ,將其他特征列視為 輸入X ,然后將 回歸器擬合到(X,y)上 以獲取已知 y 和用于 預測y的缺失值 。
The same process is repeated for each feature column in a loop and the average of all the multiple regression values are taken to impute the missing values for the data points.
對循環中的每個要素列重復相同的過程,并采用所有多個回歸值的平均值來估算數據點的缺失值。

失蹤圖書館 (Missingpy library)
Missingpy is a library in python used for imputations of missing values. Currently, it supports K-Nearest Neighbours based imputation technique and MissForest i.e Random Forest-based imputation technique.
Missingpy是python中的一個庫,用于估算缺失值。 當前,它支持基于K最近鄰的插補技術和MissForest即基于隨機森林的插補技術。
To install missingpy library, you can type the following in command line:
要安裝missingpy庫,可以在命令行中鍵入以下內容:
pip install missingpy
pip install missingpy
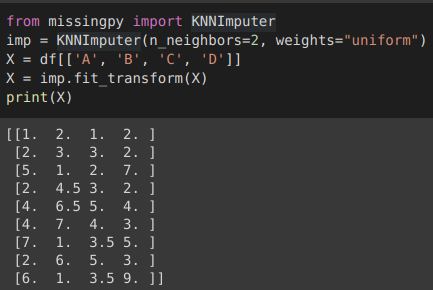
3. KNNImputer (3. KNNImputer)
KNNImputer is a multivariate data imputation technique used for filling in the missing values using the K-Nearest Neighbours approach. Each missing value is filled by the mean value form the n nearest neighbours found in the training set, either weighted or unweighted.
KNNImputer是一種多變量數據插補技術,用于使用K最近鄰方法填充缺失值。 每個缺失值都由在訓練集中找到的n個最近鄰居 (加權或未加權)的平均值填充。
If a sample has more than one feature missing then the neighbour for that sample can be different and if the number of neighbours is lesser than n_neighbour specified then there is no defined distance in the training set, the average of that training set is used during imputation.
如果樣本缺少一個以上的特征,則該樣本的鄰居可能會有所不同 ;如果鄰居的數量小于指定的n_neighbour,則訓練集中沒有定義的距離,則在插補過程中將使用該訓練集的平均值。
Nearest neighbours are selected on the basis of distance metrics, by default it is set to euclidean distance and n_neighbour are specified to consider for each step.
根據距離量度 選擇最近的鄰居 ,默認情況下將其設置為歐式距離,并為每個步驟指定要考慮的n_neighbour 。
4.小姐森林 (4. MissForest)
It is another technique used to fill in the missing values using Random Forest in an iterated fashion. The candidate column is selected from the set of all the columns having the least number of missing values.
這是另一種使用“ 隨機森林 ”以迭代方式填充缺失值的技術。 從缺少值最少的所有列的集合中選擇候選列 。
In the first step, all the other columns i.e non-candidate columns having missing values are filled with the mean for the numerical columns and mode for the categorical columns and after that imputer fits a random forest model with the candidate columns as the outcome variable(target variable) and remaining columns as independent variables and then filling the missing values in candidate column using the predictions from the fitted Random Forest model.
第一步,將所有其他列(即缺少值的非候選列)填充為數值列的平均值和分類列的眾數,然后,imputer將候選列作為結果變量擬合隨機森林模型 (目標變量)和其余列作為自變量 ,然后使用擬合隨機森林模型的預測填充候選列中的缺失值。
Then the imputer moves on and the next candidate column is selected with the second least number of missing values and the process repeats itself for each column with the missing values.
然后,推動者繼續前進,并選擇缺失值次之的下一個候選列,并且該過程針對具有缺失值的每一列重復其自身。

進一步閱讀 (Further Readings)
FancyImpute:
FancyImpute:
IterativeImputer was originally a part of the fancy impute but later on was merged into sklearn. Apart from IterativeImputer, fancy impute has many different algorithms that can be helpful in imputing missing values. Few of them are not much common in the industry but have proved their existence in some particular projects, that is why I am not including them in today's article. You can study them here.
IterativeImputer最初是幻想式估算的一部分,但后來合并為sklearn。 除了IterativeImputer之外,花式插補還具有許多不同的算法,可用于插補缺失值。 它們很少在行業中并不常見,但是已經證明它們在某些特定項目中的存在,這就是為什么我不在今天的文章中包括它們。 你可以在這里學習。
AutoImpute:
自動提示:
It is yet another python package for analysis and imputation of missing values in datasets. It supports various utility functions to examine patterns in missing values and provides some imputations methods for continuous, categorical or time-series data. It also supports multiple and single imputation frameworks for imputations. You can study them here.
它是另一個python軟件包,用于分析和估算數據集中的缺失值。 它支持各種實用程序功能以檢查缺失值中的模式,并為連續,分類或時間序列數據提供一些插補方法。 它還支持用于插補的多個和單個插補框架。 你可以在這里學習。
If you enjoyed reading this article, I am sure that we share similar interests and are/will be in similar industries. So let’s connect via LinkedIn and Github. Please do not hesitate to send a contact request!
如果您喜歡閱讀本文,那么我相信我們有相同的興趣并且會/將會從事相似的行業。 因此,讓我們通過LinkedIn和Github進行連接。 請不要猶豫,發送聯系請求!
翻譯自: https://medium.com/analytics-vidhya/a-quick-guide-on-missing-data-imputation-techniques-in-python-2020-5410f3df1c1e
python 插補數據
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/389696.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/389696.shtml 英文地址,請注明出處:http://en.pswp.cn/news/389696.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

5186. 區間內查詢數字的頻率

![[原創]java獲取word里面的文本](http://pic.xiahunao.cn/[原創]java獲取word里面的文本)
[原創]java獲取word里面的文本

ab 模擬_Ab測試第二部分的直觀模擬

1886. 判斷矩陣經輪轉后是否一致

samba登陸密碼不正確

Java構造函數的深入理解

1967. 作為子字符串出現在單詞中的字符串數目

判斷IE版本與各瀏覽器的語句

各類軟件馬斯洛需求層次分析_需求的分析層次


HTTP/2 學習筆記

MySQL的變量分類總結

859. 親密字符串

python函數不同類型參數順序

亞洲國家互聯網滲透率_發展中亞洲國家如何回應covid 19

create-react-app項目使用假數據

1854. 人口最多的年份

snake4444勒索病毒成功處理教程方法工具達康解密金蝶/用友數據庫sql后綴snake4444...
