使用機器學習預測天氣
Based on every NFL play from 2009–2017
根據2009-2017年每場NFL比賽
Ah, yes. The times, they are changin’. The leaves are beginning to fall, the weather is slowly starting to cool down (unless you’re where I’m at in LA, where it’s only getting hotter), and the mental transition of changing from shorts & sandals to jeans & hoodies is beginning. But, there is one other great fall tradition peeking its head over the horizon — FOOTBALL SEASON! Well, hopefully. Cause you know… Coronavirus.
是的。 時代在變。 葉子開始掉落,天氣開始慢慢降溫(除非您在我在洛杉磯的地方,那里只會變得更熱),從短褲和涼鞋到牛仔褲和帽衫的轉變是一種精神上的轉變開始。 但是,還有另一種偉大的秋季傳統正在悄然興起–足球賽季! 好吧,希望如此。 因為你知道……冠狀病毒。
I love football. I am a deeply rooted Minnesota Vikings fan, and every season I can go into Week 1 fully optimistic that “this is our year!” Because, for those who may not know, my Vikings have never… won… a Super Bowl. *sigh*
我愛足球。 我是明尼蘇達州維京人隊的根深蒂固的球迷,每個賽季我都可以完全樂觀地認為“今年是我們的一年!” 因為,對于那些可能不知道的人,我的維京人從來沒有……贏得過……超級碗。 *嘆*
There have been 54 Super Bowls and the Vikings don’t have a single trophy. But like I said, this is our year!
已經有54個超級碗,維京人沒有一個獎杯。 但是就像我說的,這是我們的一年!
On top of loving football, I also love working with data. And as an aspiring data scientist, I decided to take these two passions and join them together. I’m excited to share my process on answering the ever important question in the football world— can we use data to predict touchdowns?
除了熱愛足球,我還喜歡使用數據。 作為一名有抱負的數據科學家,我決定接受這兩種激情并將它們融合在一起。 我很高興與大家分享我在回答足球界日益重要的問題上的過程-我們可以使用數據來預測達陣嗎?
第1部分-目標 (Part 1— Objectives)
I had three primary objectives for this project. First, I wanted to use a classification model to classify touchdown plays versus non-touchdown plays. This was the prediction part. One really important thing I want to note, is that these are not predicting plays in the future. The model uses data it already has to make its predictions on data it’s never seen before. I’ll expand on this in a moment.
對于這個項目,我有三個主要目標。 首先,我想使用分類模型對觸地得分與非觸地得分進行分類。 這是預測部分。 我要指出的一件事是, 真正重要的是,這些都不是未來的預測。 該模型使用已經必須對之前從未見過的數據進行預測的數據。 稍后我將對此進行詳細說明。
Second, I wanted to discover what the most important predictors (which I may also refer to as ‘features’) were for the machine in determining what separates a touchdown from a non-touchdown. Having this valuable information will allow me to achieve my third objective, which is to use all that I’ve learned to make data-driven recommendations for offensive and defensive coaches.
其次,我想發現對于機器而言,最重要的預測指標(我也可以稱為“特征”)是什么,它決定了將觸地得分與非觸地得分區分開的因素。 擁有這些寶貴的信息將使我實現我的第三個目標,那就是利用我所學到的所有知識,為進攻型和防守型教練提供數據驅動的建議。
第2部分-數據 (Part 2— The Data)
For anyone interested, the dataset for this project can be found on Kaggle, here. There were a couple options to choose from, but I decided to use the play-by-play data from 2009–2017 so that I could have as much data as possible to work with. This set contains every single play, from every single game, for every single team, for all of the NFL Regular Season games that were played between the 2009 and 2017 seasons. So, there is no preseason or postseason included.
對于任何感興趣的人,可以在Kaggle的此處找到該項目的數據集。 有兩個選項可供選擇,但我決定使用2009-2017年的逐次播放數據,以便可以使用盡可能多的數據。 這組包含2009年至2017賽季之間所有NFL常規賽比賽的每場比賽,每場比賽,每支球隊的比賽。 因此,不包括季前賽或季后賽。
After going through the process of preprocessing and cleaning my data, I finished up with 7,068 predictors (columns) and 407,688 entries (rows) of data to work with. So in total, there were about 2.88 billion pieces of data. Some will say, “woah! that’s a lot!”, and others will say “meh. that’s nothin.” And to each their own. But in my experience, this was by far the largest dataset I have worked with. However, I viewed that as a good thing — more data should mean high-quality and highly reproducible results.
在完成預處理和清理數據的過程之后,我完成了7,068個預測變量(列)和407,688個數據條目(行)可以使用。 因此,總共有大約28.8億條數據。 有人會說:“哇! 太多了!”,其他人會說“嗯。 那沒什么。 并給每個人自己。 但是根據我的經驗,這是迄今為止我使用過的最大的數據集。 但是,我認為這是一件好事-更多數據應意味著高質量和高度可重復的結果。
第3部分-建模 (Part 3 — Modeling)
Now that the data had been obtained and properly preprocessed, I could begin modeling. My first step was to determine my target variable, which was whether a play resulted in a touchdown or not (this column was a boolean — 0=False, meaning no touchdown, and 1=True, meaning a touchdown was scored.) Then, I performed a train-test split. I decided to use a 75% training/25% testing split. What this means is that the machine will learn (hence, ‘machine learning’) from 75% of the data on which predictors are most featured in both touchdown plays and non-touchdown plays (target variable). Then, the machine will use what it learned from its training process to make its predictions on the remaining 25% of the data that it has yet to see.
現在已經獲得了數據并進行了適當的預處理,我可以開始建模了。 我的第一步是確定我的目標變量,這是一個游戲是否導致觸地得分(此列為布爾值-0 = False,表示無觸地得分,1 = True,表示觸地得分。)然后,我進行了火車測試拆分。 我決定使用75%的培訓/ 25%的測試分組。 這意味著機器將從75%的數據中學習(因此稱為“機器學習”),預測值在觸地得分比賽和非觸地得分比賽(目標變量)中最有特色。 然后,機器將使用從訓練過程中學到的知識對尚未看到的剩余25%數據做出預測。
*Quick Side Note* For anyone reading this that may be new to data science or machine learning, creating your target and performing a train-test split should always be your first two steps, no matter what kind of machine learning model you may be running.
*快速說明*對于任何可能不了解數據科學或機器學習的人,無論您正在運行哪種機器學習模型,創建目標和執行火車測試拆分始終應該是您的前兩個步驟。
For this project, I decided to try two different types of ensemble methods, which were a decision trees model and a random forest model. A random forest is basically a bunch of different decision trees, and I figured that it would produce better results. Interestingly though, the decision trees model created much more meaningful and reliable results, and that is what I will display in this blog post.
對于這個項目,我決定嘗試兩種不同類型的集成方法,即決策樹模型和隨機森林模型。 隨機森林基本上是一堆不同的決策樹,我認為它將產生更好的結果。 但是,有趣的是,決策樹模型創建了更有意義,更可靠的結果,這就是我將在此博客文章中顯示的內容。
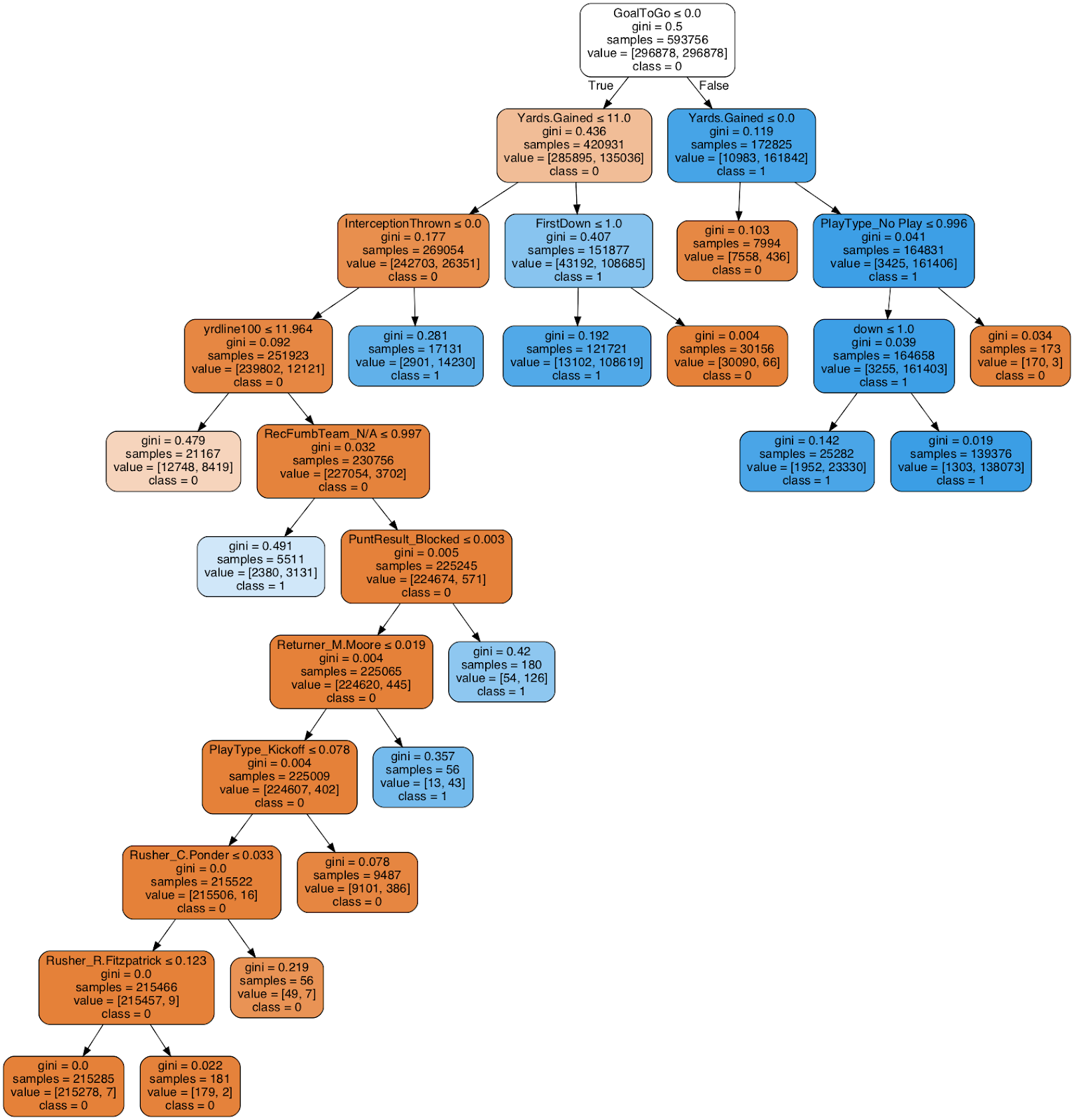
This is the actual decision tree from my project. Essentially, decision trees work by breaking down the samples of a particular set of data into smaller and smaller groups, which creates the tree-like structure you see above. The white box is known as the decision node, which is broken into a number of branches that is equal to the number of classes in your target variable. So, because there are two classes in my target, it is broken into two branches, 0 equaling False (non-touchdown) and 1 equaling True (touchdown). Then, each colored box is called a leaf node, which is a representation of the machine’s classification, or decision. So, the orange boxes represent plays that were not touchdowns, and the blue boxes represent plays that were touchdowns.
這是我項目中的實際決策樹。 本質上,決策樹通過將一組特定數據的樣本分成越來越小的組來工作,從而創建了您在上面看到的樹狀結構。 白框稱為決策節點 ,它分為多個分支,這些分支等于您的目標變量中的類數。 因此,由于目標中有兩個類,因此將其分為兩個分支,0等于False(非觸地得分)和1等于True(觸地得分)。 然后,每個有色框稱為葉節點 ,它代表機器的分類或決策 。 因此,橙色框代表的不是觸地得分,藍色框代表的不是觸地得分。
Typically, running a model with its vanilla features (or in other words, without tuning them) will result in suboptimal results. It is common to utilize something like GridSearchCV from sklearn to determine the optimal features. However, with the machine I have and the size of the dataset, GridSearch was too resource-heavy and proved to be inefficient. I instead used a smiliair tool called RandomizedSearchCV, which still took a while to run, but proved to be more efficient than GridSearch and the good old-fashioned trial & error method. In this model, I tuned two features: max_depth & min_samples_split.
通常,運行具有原始特征的模型(或者說,不對其進行調整)將導致結果欠佳。 通常使用sklearn中的GridSearchCV之類的東西來確定最佳功能。 但是,使用我擁有的計算機和數據集的大小,GridSearch太耗資源,因此效率低下。 相反,我使用了一個名為RandomizedSearchCV的輔助工具,該工具仍然需要一段時間才能運行,但事實證明它比GridSearch和老式的反復試驗方法更有效。 在此模型中,我調整了兩個功能:max_depth和min_samples_split。
max_depth determines the maximum depth of the tree. Normally, the tree will continue to diverge until all the leaves are fulfilled, or the leaves contain fewer than the min_samples_split parameter has designated. My max_depth was set to 10.
max_depth確定樹的最大深度。 通常,樹將繼續發散,直到所有葉子都滿足為止,或者葉子包含的數量少于min_samples_split參數指定的數量。 我的max_depth設置為10。
min_samples_split determines the minimum number of samples needed before breaking off into a new leaf node. This feature is cool because you can use a whole number of samples (aka an integer) or you can use a percentage of the samples (aka a float). The default value is 2… which, when working with almost 2.9 billion pieces of data, is going to do one of two things: One, create terrible results; Or two, create results that are so good, it’s almost impossible to believe. The latter happened to me. So, I set my min_samples_split to 0.25.
min_samples_split確定在分解為新的葉節點之前所需的最少樣本數。 此功能很酷,因為您可以使用全部樣本(也就是整數),也可以使用一定比例的樣本(也就是浮點數)。 默認值為2…,當處理近29億條數據時,它將執行以下兩項操作之一: 或兩個,創造出如此出色的結果,幾乎是難以置信的。 后者發生在我身上。 因此,我將我的min_samples_split設置為0.25。
第4部分-結果 (Part 4 — Results)
Above, you will see my confusion matrix, which is a representation of how well the model did predicting touchdowns and non-touchdowns. The purple boxes are what is important to focus on because the top-left represents “true negatives”, which means correctly predicted non-touchdowns, and the bottom right represents “true positives”, which means correctly predicted touchdowns. Overall, the testing accuracy was 93%, which is excellent (and also believable!)
在上方,您將看到我的混淆矩陣,該矩陣表示模型預測著陸和非著陸的效果。 紫色框是需要重點關注的地方,因為左上角代表“真實否定”,這意味著正確預測的非觸地得分,右下角代表“真實正向”,這意味著正確預測的觸地得分。 總體而言,測試精度為93%,這非常好(也是令人信服的!)
For those that are curious, the random forest model that I ran with the same parameter tuning (max_depth & min_samples_split) predicted 90% of non-touchdowns correctly, only 55% of touchdowns correctly, and had an overall testing accuracy of 89%. Like I said in the intro, this definitely was a surprise to me.
對于那些好奇的人,我使用相同的參數調整(max_depth和min_samples_split)運行的隨機森林模型正確地預測了90%的非觸地得分,正確地預測了55%的非觸地得分,并且總體測試準確性為89%。 就像我在介紹中所說的那樣,這絕對讓我感到驚訝。
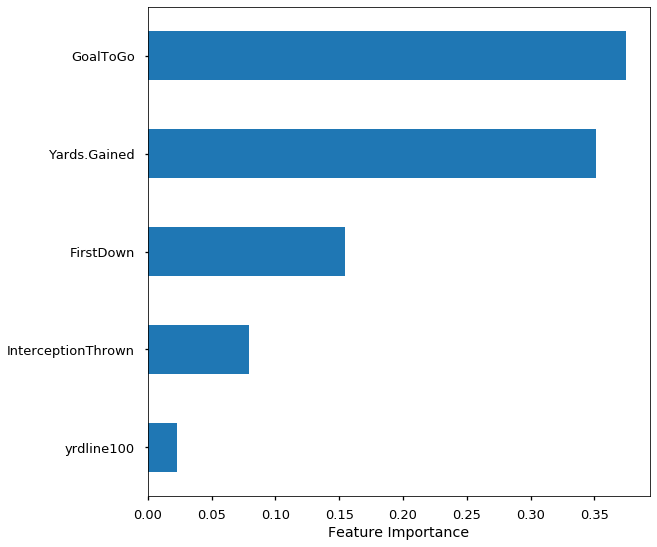
Objective #1 has been achieved, so now we’re on to objective #2: what are the important features? So, remember how I said that there were 7,068 features for the machine to learn from? Well, it turns out that there were only 5 — yes, five — that really mattered. That’s .0007% of the features. Woah! Of these five features, two had positive influences on touchdowns and three had negative influences on touchdowns:
目標1已經實現,所以現在我們進入目標2: 重要特征是什么? 因此,還記得我說過要為機器學習的7,068項功能嗎? 好吧,事實證明只有5個-是的, 五個 -確實很重要。 這就是功能的0.007%。 哇! 在這五個功能中,兩個對觸地得分有正面影響,三個對觸地得分有負面影響:
Goal To Go — Was the ball placed on the opponents 10 yard line or closer? Influence: Positive. It’s much easier to score from 10 yards out than 90 yards out.
要進球 –球是放在對手10碼線上或更近的位置上嗎? 影響: 積極 。 從10碼以外的地方得分比90碼以外的地方容易得多。
Yards Gained — Did the offense gain positive yardage? Influence: Positive. Gaining positive yardage means you’re moving in the right direction, thus increasing the chance to score a touchdown.
亂碼 —進攻是否獲得了正碼數? 影響: 積極 。 獲得正碼數意味著您朝著正確的方向前進,從而增加了達陣得分的機會。
First Down — Did the play result in a first down? Influence: Negative. Gaining first downs is a good thing for an offense. However, a play ruled as a touchdown is not also considered a first down. Therefore, you can’t have a touchdown and a first down on the same play.
第一回合 -比賽是否導致第一??回合? 影響: 負面 。 獲得先攻是對進攻的好事。 但是,被視為觸地得分的比賽也不會被視為首發。 因此,您不能在同一場比賽中觸地得分和先擊球。
Interception Thrown — Was there an interception thrown on the play? Influence: Negative. On offense, if you turn the ball over, you can’t score. One thing I find interesting is that fumbles weren’t nearly as important as interceptions were.
攔截攔截 -劇中是否有攔截? 影響: 負面 。 進攻時,如果您將球翻過來,就無法得分。 我發現有趣的一件事是,騙局并不像攔截一樣重要。
Yard Line (100) — Imagine the field being one 100 yard field, as opposed to two 50 yard halves. The 1 would be the offense’s one yard line, the 50 would be midfield, and the 99 would be the opponent’s one yard line. Where is the ball on the field? Influence: Negative. This is kind of the opposite of Goal to Go, in a sense. Most offensive plays happen on the offense’s own side of the field, let alone inside their opponent’s 10 yard line. The more distance needed, the harder it is to score.
碼線(100) -假設該字段是一個100碼的字段,而不是兩個50碼的一半。 1是進攻方的一碼線,50是中場,而99是對手的一碼線。 球場上的球在哪里? 影響: 負面 。 從某種意義上講,這與“ Goal to Go”相反。 大多數進攻戰術發生在進攻方自己的領域,更不用說在對手的10碼線內了。 需要的距離越長,得分就越困難。
第5部分-數據驅動的建議 (Part 5 — Data-Driven Recommendations)
Now that we have all of these fantastic insights, how can this information be applied? I believe that the group that would most benefit from this analysis would be coaches, both on offense and on defense.
既然我們擁有所有這些奇妙的見解,那么如何應用這些信息? 我相信從分析中受益最大的是教練,無論是進攻還是防守。
進攻教練 (Offensive Coaches)
Get big plays, but don’t get carried away — We’ve seen that gaining positive yardage has a positive influence on being able to score touchdowns. However, that doesn’t mean you need to go bombs away every play. Scout the defense, attack their weaknesses, and move the ball downfield. Typically, more yards equals more points.
發揮重要作用,但不要束手無策 —我們已經看到,獲得正碼數對能夠觸地得分有積極影響。 但是,這并不意味著您每次玩都需要炸掉炸彈。 偵察防守,攻擊他們的弱點,并將球移至低位。 通常,更多的碼等于更多的點。
When you’re in the money zone, you got to make a deposit! — If you get the ball inside your opponent’s 10 yard line, you gotta score. Period. Inside the 10 is your easiest chance to score because of the short distance, so you got to take advantage of those opportunities when they present themselves.
當您處于貨幣區時,您必須進行存款! —如果將球傳到對手10碼線內,您就可以得分。 期。 十桿之內是最容易得分的機會,這是因為距離很短,所以當他們展現自己時,您必須利用這些機會。
Limit turnovers, especially interceptions — You can’t score if you don’t have the ball. That’s good old-fashioned football 101 right there. Personally, I believe interceptions have a much stronger negative influence than fumbles because interceptions tend to be returned for more yards than fumbles do. This correlates with the Yard Line (100) feature explained above, in that the closer your offense can be to your opponent’s end zone, the easier it will be to score.
限制失誤,尤其是攔截 -如果沒有球,就無法得分。 那就是那輛不錯的老式足球101。 就我個人而言,我認為攔截比騙局具有更大的負面影響,因為攔截往往比騙局返回更多碼。 這與上文所述的“圍場線(100)”特征相關,因為您的進攻越接近對手的終點區域,得分就越容易。
防守教練 (Defensive Coaches)
Use controlled, precise aggression to force interceptions — Defensive players love playing defense because they love to hit people! But, so many times we have seen defenses get burned for big plays when they are too aggressive. You want to put pressure on the offense so that you can force bad decisions, poor execution, and turnovers (ahem, interceptions). Offenses are throwing the ball more than ever, so there are plenty of opportunities to force quarterbacks into making mistakes.
使用可控的,精確的進攻來強制攔截 -防守球員喜歡打防守,因為他們喜歡打人! 但是,很多時候我們都看到,防守過于激進時,他們的防守就會被大打大鬧。 您想對進攻施加壓力,以便您可以做出錯誤的決定,執行不力和失誤(糟糕,攔截)。 進攻比以往任何時候都更為重要,因此有很多機會迫使四分衛犯錯。
Limit yardage — I know, duh, right? That’s the defense’s job. But, the data verifies how important this is. Just like how on offense there is a positive correlation between yards gained and touchdowns scored, the same effect is felt in the opposite direction. If you limit how many yards the offense gains, you control where the ball is on the field, and you will limit the amount of touchdowns the offense can score.
限制碼數 -我知道,對不對? 那是國防部的工作。 但是,數據驗證了這一點的重要性。 就像在進攻端獲得的碼數和觸地得分之間有正相關關系一樣,在相反的方向上也能感覺到相同的效果。 如果您限制進攻獲得多少碼,則可以控制球在場上的位置,并且可以限制進攻得分的觸地得分數量。
結論 (Conclusion)
I had so much fun working on this project. I have always been a nerd for football stats, and I think it’s truly amazing that we have technology now where we can use that statistical information to create high-value insights in order to increase performance. At the end of the day, it is up to both the coaches and the players to execute their game-plan against their opponent. But, taking advantage of technology and knowledge like this to create the best gameplan possible will create the ultimate advantage. I hope you enjoyed reading! Go Vikings!
我在這個項目上工作非常有趣。 我一直是足球統計專家的書呆子,我認為我們擁有現在可以使用統計信息來創造高價值洞察力以提高績效的技術確實令人驚訝。 歸根結底,教練和球員都必須執行對對手的比賽計劃。 但是,利用這樣的技術和知識來創造最佳的游戲計劃將創造最終的優勢。 希望您喜歡閱讀! 去維京人!
#Skol
#斯科爾

Github Repo
Github回購
翻譯自: https://medium.com/the-sports-scientist/how-to-use-machine-learning-to-predict-touchdowns-12c3fa4cf3d8
使用機器學習預測天氣
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/389543.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/389543.shtml 英文地址,請注明出處:http://en.pswp.cn/news/389543.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

laravel 導出插件

國外 廣告牌_廣告牌下一首流行歌曲的分析和預測,第1部分

Jmeter測試普通java類說明

opencv:Canny邊緣檢測算法思想及實現


opencv:畸變矯正:透視變換算法的思想與實現

數據多重共線性_多重共線性對您的數據科學項目的影響比您所知道的要多

PHP工廠模式計算面積與周長

K-Means聚類算法思想及實現
DDL增強功能-數據類型、同義詞、分區表)
(2.1)DDL增強功能-數據類型、同義詞、分區表

初衷、感想與筆記目錄)
【java并發編程藝術學習】(一)初衷、感想與筆記目錄

層次聚類和密度聚類思想及實現

通配符 或 怎么濃_濃咖啡的咖啡渣新鮮度


《netty入門與實戰》筆記-02:服務端啟動流程


Tengine HTTPS原理解析、實踐與調試【轉】

Linux 指定運行時動態庫路徑【轉】
