主成份分析算法PCA
非監督學習算法
PCA的實現:
簡單來說,就是將數據從原始的空間中轉換到新的特征空間中,例如原始的空間是三維的(x,y,z),x、y、z分別是原始空間的三個基,我們可以通過某種方法,用新的坐標系(a,b,c)來表示原始的數據,那么a、b、c就是新的基,它們組成新的特征空間。在新的特征空間中,可能所有的數據在c上的投影都接近于0,即可以忽略,那么我們就可以直接用(a,b)來表示數據,這樣數據就從三維的(x,y,z)降到了二維的(a,b)。
問題是如何求新的基(a,b,c)?
一般步驟是這樣的:
對原始數據零均值化(中心化),
求協方差矩陣,
對協方差矩陣求特征向量和特征值,這些特征向量組成了新的特征空間。
PCA–零均值化(中心化):
中心化即是指變量減去它的均值,使均值為0。
其實就是一個平移的過程,平移后使得所有數據的中心點是(0,0)
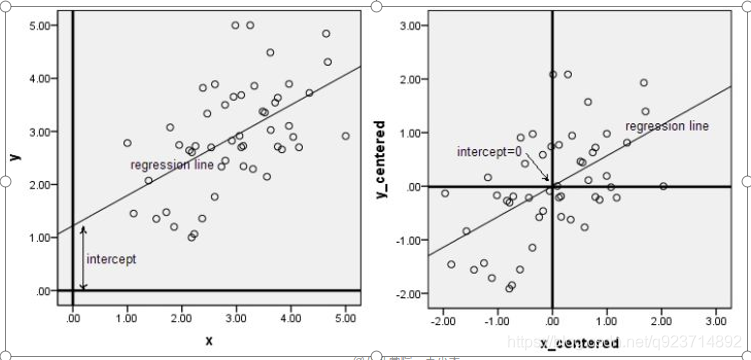
只有中心化數據之后,計算得到的方向才能比較好的“概括”原來的數據。
此圖形象的表述了,中心化的幾何意義,就是將樣本集的中心平移到坐標系的原點O上。

PCA–PCA降維的幾何意義:
我們對于一組數據,如果它在某一坐標軸上的方差越大,說明坐標點越分散,該屬性能夠比較好的反映源數據。所以在進行降維的時候,主要目的是找到一個超平面,它能使得數據點的分布方差呈最大,這樣數據表現在新的坐標軸上時候已經足夠分散了。
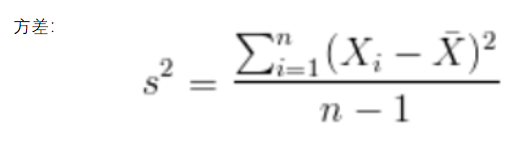
PCA算法的優化目標就是:
① 降維后同一維度的方差最大 ② 不同維度之間的相關性為0(協方差)
PCA–協方差矩陣:
定義:

比如,三維(x,y,z)的協方差矩陣: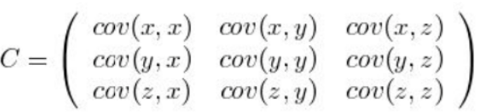
協方差矩陣的特點:
協方差矩陣計算的是不同 維度之間的協方差, 而不是不同樣本之間的。
樣本矩陣的每行是一個樣本, 每列為一個維度, 所以我們要按列計算均值。
協方差矩陣的對角線就是各個維度上的方差
特別的,如果做了中心化,則協方差矩陣為(中心化矩陣的協方差矩陣公式):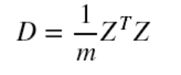
PCA–對特征值進行排序:

PCA–評價模型的好壞,K值的確定
通過特征值的計算我們可以得到主成分所占的百分比,用來衡量模型的好壞。
對于前k個特征值所保留下的信息量計算方法如下:
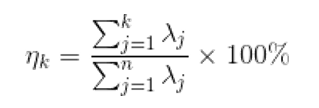
代碼實現:
手動實現:
import numpy as np
class PCA():def __init__(self,n_components):self.n_components = n_componentsdef fit_transform(self,X):self.n_features_ = X.shape[1]# 求協方差矩陣X = X - X.mean(axis=0) #0均值化self.covariance = np.dot(X.T,X)/X.shape[0] #求協方差# 求協方差矩陣的特征值和特征向量eig_vals,eig_vectors = np.linalg.eig(self.covariance)# 獲得降序排列特征值的序號idx = np.argsort(-eig_vals)# 降維矩陣self.components_ = eig_vectors[:,idx[:self.n_components]]# 對X進行降維return np.dot(X,self.components_)# 調用
pca = PCA(n_components=2) #降維為2
X = np.array([[-1,2,66,-1], [-2,6,58,-1], [-3,8,45,-2], [1,9,36,1], [2,10,62,1], [3,5,83,2]]) #導入數據,維度為4
newX=pca.fit_transform(X)
print(newX) #輸出降維后的數據結果展示:
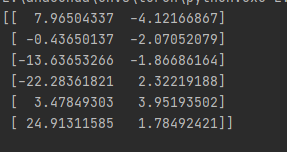
接口實現:
import numpy as np
from sklearn.decomposition import PCA
X = np.array([[-1,2,66,-1], [-2,6,58,-1], [-3,8,45,-2], [1,9,36,1], [2,10,62,1], [3,5,83,2]]) #導入數據,維度為4
pca = PCA(n_components=2) #降到2維
pca.fit(X) #訓練
newX=pca.fit_transform(X) #降維后的數據
# PCA(copy=True, n_components=2, whiten=False)
print(pca.explained_variance_ratio_) #輸出貢獻率
print(newX) #輸出降維后的數據結果展示:
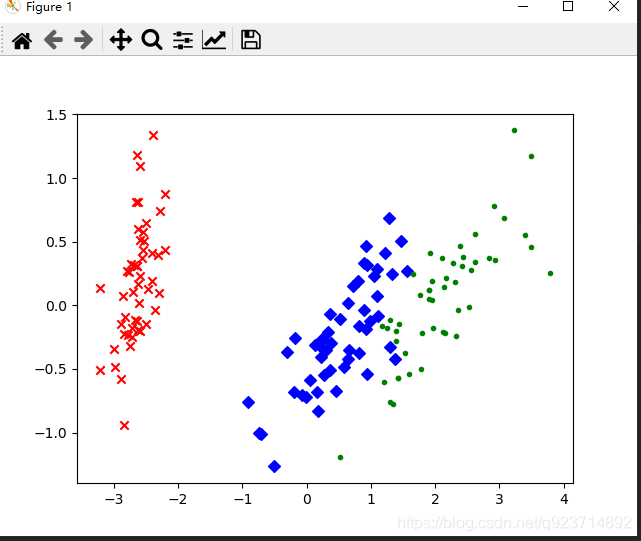
PCA–鳶尾花實例:
我們通過Python的sklearn庫來實現鳶尾花數據進行降維,數據本身是4維的降維后變成2維。
其中樣本總數為150,鳶尾花的類別有三種。
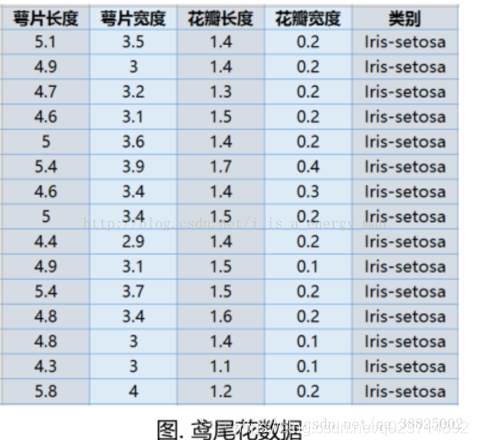
代碼實現:
import matplotlib.pyplot as plt
import sklearn.decomposition as dp
from sklearn.datasets import load_irisx,y=load_iris(return_X_y=True) #加載數據,x表示數據集中的屬性數據,y表示數據標簽
pca=dp.PCA(n_components=2) #加載pca算法,設置降維后主成分數目為2
reduced_x=pca.fit_transform(x) #對原始數據進行降維,保存在reduced_x中
red_x,red_y=[],[]
blue_x,blue_y=[],[]
green_x,green_y=[],[]
for i in range(len(reduced_x)): #按鳶尾花的類別將降維后的數據點保存在不同的表中if y[i]==0:red_x.append(reduced_x[i][0])red_y.append(reduced_x[i][1])elif y[i]==1:blue_x.append(reduced_x[i][0])blue_y.append(reduced_x[i][1])else:green_x.append(reduced_x[i][0])green_y.append(reduced_x[i][1])
plt.scatter(red_x,red_y,c='r',marker='x')
plt.scatter(blue_x,blue_y,c='b',marker='D')
plt.scatter(green_x,green_y,c='g',marker='.')
plt.show()結果展示:
PCA算法的優缺點:
優點:
它是無監督學習,完全無參數限制的。在PCA的計算過程中完全不需要人為的設定參數或是根據任何經驗模型對計算進行干預,最后的結果只與數據相關,與用戶是獨立的。
用PCA技術可以對數據進行降維,同時對新求出的“主元”向量的重要性進行排序,根據需要取前面最重要的部分,將后面的維數省去,可以達到降維從而簡化模型或是對數據進行壓縮的效果。同時最大程度的保持了原有數據的信息。
各主成分之間正交,可消除原始數據成分間的相互影響。
計算方法簡單,易于在計算機上實現。
缺點:
如果用戶對觀測對象有一定的先驗知識,掌握了數據的一些特征,卻無法通過參數化等方法對處理過程進行干預,可能會得不到預期的效果,效率也不高。
貢獻率小的主成分往往可能含有對樣本差異的重要信息。
特征值矩陣的正交向量空間是否唯一有待討論。
在非高斯分布的情況下,PCA方法得出的主元可能并不是最優的,此時在尋找主元時不能將方差作為衡量重要性的標準。














DDL增強功能-數據類型、同義詞、分區表)

初衷、感想與筆記目錄)


