各種網絡模型:來源《動手學深度學習》
一,卷積神經網絡(LeNet)
LeNet分為卷積層塊和全連接層塊兩個部分。下面我們分別介紹這兩個模塊。
卷積層塊里的基本單位是卷積層后接最大池化層:卷積層用來識別圖像里的空間模式,如線條和物體局部,之后的最大池化層則用來降低卷積層對位置的敏感性。卷積層塊由兩個這樣的基本單位重復堆疊構成。在卷積層塊中,每個卷積層都使用 5×5 的窗口,并在輸出上使用sigmoid激活函數。第一個卷積層輸出通道數為6,第二個卷積層輸出通道數則增加到16。這是因為第二個卷積層比第一個卷積層的輸入的高和寬要小,所以增加輸出通道使兩個卷積層的參數尺寸類似。卷積層塊的兩個最大池化層的窗口形狀均為 2×2 ,且步幅為2。由于池化窗口與步幅形狀相同,池化窗口在輸入上每次滑動所覆蓋的區域互不重疊。
卷積層塊的輸出形狀為(批量大小, 通道, 高, 寬)。當卷積層塊的輸出傳入全連接層塊時,全連接層塊會將小批量中每個樣本變平(flatten)。也就是說,全連接層的輸入形狀將變成二維,其中第一維是小批量中的樣本,第二維是每個樣本變平后的向量表示,且向量長度為通道、高和寬的乘積。全連接層塊含3個全連接層。它們的輸出個數分別是120、84和10,其中10為輸出的類別個數。
下面我們通過Sequential類來實現LeNet模型。
net = nn.Sequential()
net.add(nn.Conv2D(channels=6, kernel_size=5, activation='sigmoid'),nn.MaxPool2D(pool_size=2, strides=2),nn.Conv2D(channels=16, kernel_size=5, activation='sigmoid'),nn.MaxPool2D(pool_size=2, strides=2),# Dense會默認將(批量大小, 通道, 高, 寬)形狀的輸入轉換成# (批量大小, 通道 * 高 * 寬)形狀的輸入nn.Dense(120, activation='sigmoid'),nn.Dense(84, activation='sigmoid'),nn.Dense(10))
二,深度卷積神經網絡(AlexNet)
AlexNet與LeNet的設計理念非常相似,但也有顯著的區別。
第一,與相對較小的LeNet相比,AlexNet包含8層變換,其中有5層卷積和2層全連接隱藏層,以及1個全連接輸出層。下面我們來詳細描述這些層的設計。
AlexNet第一層中的卷積窗口形狀是 11×11 。因為ImageNet中絕大多數圖像的高和寬均比MNIST圖像的高和寬大10倍以上,ImageNet圖像的物體占用更多的像素,所以需要更大的卷積窗口來捕獲物體。第二層中的卷積窗口形狀減小到 5×5 ,之后全采用 3×3 。此外,第一、第二和第五個卷積層之后都使用了窗口形狀為 3×3 、步幅為2的最大池化層。而且,AlexNet使用的卷積通道數也大于LeNet中的卷積通道數數十倍。
緊接著最后一個卷積層的是兩個輸出個數為4,096的全連接層。這兩個巨大的全連接層帶來將近1 GB的模型參數。由于早期顯存的限制,最早的AlexNet使用雙數據流的設計使一塊GPU只需要處理一半模型。幸運的是,顯存在過去幾年得到了長足的發展,因此通常我們不再需要這樣的特別設計了。
第二,AlexNet將sigmoid激活函數改成了更加簡單的ReLU激活函數。一方面,ReLU激活函數的計算更簡單,例如它并沒有sigmoid激活函數中的求冪運算。另一方面,ReLU激活函數在不同的參數初始化方法下使模型更容易訓練。這是由于當sigmoid激活函數輸出極接近0或1時,這些區域的梯度幾乎為0,從而造成反向傳播無法繼續更新部分模型參數;而ReLU激活函數在正區間的梯度恒為1。因此,若模型參數初始化不當,sigmoid函數可能在正區間得到幾乎為0的梯度,從而令模型無法得到有效訓練。
第三,AlexNet通過丟棄法(參見“丟棄法”一節)來控制全連接層的模型復雜度。而LeNet并沒有使用丟棄法。
第四,AlexNet引入了大量的圖像增廣,如翻轉、裁剪和顏色變化,從而進一步擴大數據集來緩解過擬合。我們將在后面的“圖像增廣”一節詳細介紹這種方法。
下面我們實現稍微簡化過的AlexNet。
net = nn.Sequential()
# 使用較大的11 x 11窗口來捕獲物體。同時使用步幅4來較大幅度減小輸出高和寬。這里使用的輸出通
# 道數比LeNet中的也要大很多
net.add(nn.Conv2D(96, kernel_size=11, strides=4, activation='relu'),nn.MaxPool2D(pool_size=3, strides=2),# 減小卷積窗口,使用填充為2來使得輸入與輸出的高和寬一致,且增大輸出通道數nn.Conv2D(256, kernel_size=5, padding=2, activation='relu'),nn.MaxPool2D(pool_size=3, strides=2),# 連續3個卷積層,且使用更小的卷積窗口。除了最后的卷積層外,進一步增大了輸出通道數。# 前兩個卷積層后不使用池化層來減小輸入的高和寬nn.Conv2D(384, kernel_size=3, padding=1, activation='relu'),nn.Conv2D(384, kernel_size=3, padding=1, activation='relu'),nn.Conv2D(256, kernel_size=3, padding=1, activation='relu'),nn.MaxPool2D(pool_size=3, strides=2),# 這里全連接層的輸出個數比LeNet中的大數倍。使用丟棄層來緩解過擬合nn.Dense(4096, activation="relu"), nn.Dropout(0.5),nn.Dense(4096, activation="relu"), nn.Dropout(0.5),# 輸出層。由于這里使用Fashion-MNIST,所以用類別數為10,而非論文中的1000nn.Dense(10))
三,使用重復元素的網絡(VGG)
VGG塊
VGG塊的組成規律是:連續使用數個相同的填充為1、窗口形狀為 3×3 的卷積層后接上一個步幅為2、窗口形狀為 2×2 的最大池化層。卷積層保持輸入的高和寬不變,而池化層則對其減半。我們使用vgg_block函數來實現這個基礎的VGG塊,它可以指定卷積層的數量num_convs和輸出通道數num_channels。
VGG網絡
與AlexNet和LeNet一樣,VGG網絡由卷積層模塊后接全連接層模塊構成。卷積層模塊串聯數個vgg_block,其超參數由變量conv_arch定義。該變量指定了每個VGG塊里卷積層個數和輸出通道數。全連接模塊則與AlexNet中的一樣。
現在我們構造一個VGG網絡。它有5個卷積塊,前2塊使用單卷積層,而后3塊使用雙卷積層。第一塊的輸出通道是64,之后每次對輸出通道數翻倍,直到變為512。因為這個網絡使用了8個卷積層和3個全連接層,所以經常被稱為VGG-11。
def vgg(conv_arch):net = nn.Sequential()# 卷積層部分for (num_convs, num_channels) in conv_arch:net.add(vgg_block(num_convs, num_channels))# 全連接層部分net.add(nn.Dense(4096, activation='relu'), nn.Dropout(0.5),nn.Dense(4096, activation='relu'), nn.Dropout(0.5),nn.Dense(10))return netnet = vgg(conv_arch)
四,網絡中的網絡(NiN)
NiN塊
NiN塊是NiN中的基礎塊。它由一個卷積層加兩個充當全連接層的 1×1 卷積層串聯而成。其中第一個卷積層的超參數可以自行設置,而第二和第三個卷積層的超參數一般是固定的。
def nin_block(num_channels, kernel_size, strides, padding):blk = nn.Sequential()blk.add(nn.Conv2D(num_channels, kernel_size,strides, padding, activation='relu'),nn.Conv2D(num_channels, kernel_size=1, activation='relu'),nn.Conv2D(num_channels, kernel_size=1, activation='relu'))return blk
NiN模型
NiN是在AlexNet問世不久后提出的。它們的卷積層設定有類似之處。NiN使用卷積窗口形狀分別為 11×11 、 5×5 和 3×3 的卷積層,相應的輸出通道數也與AlexNet中的一致。每個NiN塊后接一個步幅為2、窗口形狀為 3×3 的最大池化層。
除使用NiN塊以外,NiN還有一個設計與AlexNet顯著不同:NiN去掉了AlexNet最后的3個全連接層,取而代之地,NiN使用了輸出通道數等于標簽類別數的NiN塊,然后使用全局平均池化層對每個通道中所有元素求平均并直接用于分類。這里的全局平均池化層即窗口形狀等于輸入空間維形狀的平均池化層。NiN的這個設計的好處是可以顯著減小模型參數尺寸,從而緩解過擬合。然而,該設計有時會造成獲得有效模型的訓練時間的增加。
net = nn.Sequential()
net.add(nin_block(96, kernel_size=11, strides=4, padding=0),nn.MaxPool2D(pool_size=3, strides=2),nin_block(256, kernel_size=5, strides=1, padding=2),nn.MaxPool2D(pool_size=3, strides=2),nin_block(384, kernel_size=3, strides=1, padding=1),nn.MaxPool2D(pool_size=3, strides=2), nn.Dropout(0.5),# 標簽類別數是10nin_block(10, kernel_size=3, strides=1, padding=1),# 全局平均池化層將窗口形狀自動設置成輸入的高和寬nn.GlobalAvgPool2D(),# 將四維的輸出轉成二維的輸出,其形狀為(批量大小, 10)nn.Flatten())
五,含并行連結的網絡(GoogLeNet)
Inception 塊
Inception塊里有4條并行的線路。前3條線路使用窗口大小分別是 1×1 、 3×3 和 5×5 的卷積層來抽取不同空間尺寸下的信息,其中中間2個線路會對輸入先做 1×1 卷積來減少輸入通道數,以降低模型復雜度。第四條線路則使用 3×3 最大池化層,后接 1×1 卷積層來改變通道數。4條線路都使用了合適的填充來使輸入與輸出的高和寬一致。最后我們將每條線路的輸出在通道維上連結,并輸入接下來的層中去。
Inception塊中可以自定義的超參數是每個層的輸出通道數,我們以此來控制模型復雜度。

class Inception(nn.Block):# c1 - c4為每條線路里的層的輸出通道數def __init__(self, c1, c2, c3, c4, **kwargs):super(Inception, self).__init__(**kwargs)# 線路1,單1 x 1卷積層self.p1_1 = nn.Conv2D(c1, kernel_size=1, activation='relu')# 線路2,1 x 1卷積層后接3 x 3卷積層self.p2_1 = nn.Conv2D(c2[0], kernel_size=1, activation='relu')self.p2_2 = nn.Conv2D(c2[1], kernel_size=3, padding=1,activation='relu')# 線路3,1 x 1卷積層后接5 x 5卷積層self.p3_1 = nn.Conv2D(c3[0], kernel_size=1, activation='relu')self.p3_2 = nn.Conv2D(c3[1], kernel_size=5, padding=2,activation='relu')# 線路4,3 x 3最大池化層后接1 x 1卷積層self.p4_1 = nn.MaxPool2D(pool_size=3, strides=1, padding=1)self.p4_2 = nn.Conv2D(c4, kernel_size=1, activation='relu')def forward(self, x):p1 = self.p1_1(x)p2 = self.p2_2(self.p2_1(x))p3 = self.p3_2(self.p3_1(x))p4 = self.p4_2(self.p4_1(x))return nd.concat(p1, p2, p3, p4, dim=1) # 在通道維上連結輸出
GoogLeNet模型
GoogLeNet跟VGG一樣,在主體卷積部分中使用5個模塊(block),每個模塊之間使用步幅為2的 3×3 最大池化層來減小輸出高寬。第一模塊使用一個64通道的 7×7 卷積層。
b1 = nn.Sequential()
b1.add(nn.Conv2D(64, kernel_size=7, strides=2, padding=3, activation='relu'),nn.MaxPool2D(pool_size=3, strides=2, padding=1))
第二模塊使用2個卷積層:首先是64通道的 1×1 卷積層,然后是將通道增大3倍的 3×3 卷積層。它對應Inception塊中的第二條線路。
b2 = nn.Sequential()
b2.add(nn.Conv2D(64, kernel_size=1, activation='relu'),nn.Conv2D(192, kernel_size=3, padding=1, activation='relu'),nn.MaxPool2D(pool_size=3, strides=2, padding=1))
第三模塊串聯2個完整的Inception塊。第一個Inception塊的輸出通道數為 64+128+32+32=256 ,其中4條線路的輸出通道數比例為 64:128:32:32=2:4:1:1 。其中第二、第三條線路先分別將輸入通道數減小至 96/192=1/2 和 16/192=1/12 后,再接上第二層卷積層。第二個Inception塊輸出通道數增至 128+192+96+64=480 ,每條線路的輸出通道數之比為 128:192:96:64=4:6:3:2 。其中第二、第三條線路先分別將輸入通道數減小至 128/256=1/2 和 32/256=1/8 。
b3 = nn.Sequential()
b3.add(Inception(64, (96, 128), (16, 32), 32),Inception(128, (128, 192), (32, 96), 64),nn.MaxPool2D(pool_size=3, strides=2, padding=1))
第四模塊更加復雜。它串聯了5個Inception塊,其輸出通道數分別是 192+208+48+64=512 、 160+224+64+64=512 、 128+256+64+64=512 、 112+288+64+64=528 和 256+320+128+128=832 。這些線路的通道數分配和第三模塊中的類似,首先是含 3×3 卷積層的第二條線路輸出最多通道,其次是僅含 1×1 卷積層的第一條線路,之后是含 5×5 卷積層的第三條線路和含 3×3 最大池化層的第四條線路。其中第二、第三條線路都會先按比例減小通道數。這些比例在各個Inception塊中都略有不同。
b4 = nn.Sequential()
b4.add(Inception(192, (96, 208), (16, 48), 64),Inception(160, (112, 224), (24, 64), 64),Inception(128, (128, 256), (24, 64), 64),Inception(112, (144, 288), (32, 64), 64),Inception(256, (160, 320), (32, 128), 128),nn.MaxPool2D(pool_size=3, strides=2, padding=1))
第五模塊有輸出通道數為 256+320+128+128=832 和 384+384+128+128=1024 的兩個Inception塊。其中每條線路的通道數的分配思路和第三、第四模塊中的一致,只是在具體數值上有所不同。需要注意的是,第五模塊的后面緊跟輸出層,該模塊同NiN一樣使用全局平均池化層來將每個通道的高和寬變成1。最后我們將輸出變成二維數組后接上一個輸出個數為標簽類別數的全連接層。
b5 = nn.Sequential()
b5.add(Inception(256, (160, 320), (32, 128), 128),Inception(384, (192, 384), (48, 128), 128),nn.GlobalAvgPool2D())net = nn.Sequential()
net.add(b1, b2, b3, b4, b5, nn.Dense(10))
六,殘差網絡(ResNet)
殘差塊

ResNet沿用了VGG全 3×3 卷積層的設計。殘差塊里首先有2個有相同輸出通道數的 3×3 卷積層。每個卷積層后接一個批量歸一化層和ReLU激活函數。然后我們將輸入跳過這2個卷積運算后直接加在最后的ReLU激活函數前。這樣的設計要求2個卷積層的輸出與輸入形狀一樣,從而可以相加。如果想改變通道數,就需要引入一個額外的 1×1 卷積層來將輸入變換成需要的形狀后再做相加運算。
殘差塊的實現如下。它可以設定輸出通道數、是否使用額外的 1×1 卷積層來修改通道數以及卷積層的步幅。
class Residual(nn.Block): # 本類已保存在d2lzh包中方便以后使用def __init__(self, num_channels, use_1x1conv=False, strides=1, **kwargs):super(Residual, self).__init__(**kwargs)self.conv1 = nn.Conv2D(num_channels, kernel_size=3, padding=1,strides=strides)self.conv2 = nn.Conv2D(num_channels, kernel_size=3, padding=1)if use_1x1conv:self.conv3 = nn.Conv2D(num_channels, kernel_size=1,strides=strides)else:self.conv3 = Noneself.bn1 = nn.BatchNorm()self.bn2 = nn.BatchNorm()def forward(self, X):Y = nd.relu(self.bn1(self.conv1(X)))Y = self.bn2(self.conv2(Y))if self.conv3:X = self.conv3(X)return nd.relu(Y + X)
ResNet模型
ResNet的前兩層跟之前介紹的GoogLeNet中的一樣:在輸出通道數為64、步幅為2的 7×7 卷積層后接步幅為2的 3×3 的最大池化層。不同之處在于ResNet每個卷積層后增加的批量歸一化層。
net = nn.Sequential()
net.add(nn.Conv2D(64, kernel_size=7, strides=2, padding=3),nn.BatchNorm(), nn.Activation('relu'),nn.MaxPool2D(pool_size=3, strides=2, padding=1))
GoogLeNet在后面接了4個由Inception塊組成的模塊。ResNet則使用4個由殘差塊組成的模塊,每個模塊使用若干個同樣輸出通道數的殘差塊。第一個模塊的通道數同輸入通道數一致。由于之前已經使用了步幅為2的最大池化層,所以無須減小高和寬。之后的每個模塊在第一個殘差塊里將上一個模塊的通道數翻倍,并將高和寬減半。
下面我們來實現這個模塊。注意,這里對第一個模塊做了特別處理。
def resnet_block(num_channels, num_residuals, first_block=False):blk = nn.Sequential()for i in range(num_residuals):if i == 0 and not first_block:blk.add(Residual(num_channels, use_1x1conv=True, strides=2))else:blk.add(Residual(num_channels))return blk
接著我們為ResNet加入所有殘差塊。這里每個模塊使用2個殘差塊。
net.add(resnet_block(64, 2, first_block=True),resnet_block(128, 2),resnet_block(256, 2),resnet_block(512, 2))
最后,與GoogLeNet一樣,加入全局平均池化層后接上全連接層輸出。
net.add(nn.GlobalAvgPool2D(), nn.Dense(10))
七,稠密連接網絡(DenseNet)
DenseNet與ResNet的主要區別在于,DenseNet里模塊 B 的輸出不是像ResNet那樣和模塊 A 的輸出相加,而是在通道維上連結。這樣模塊 A 的輸出可以直接傳入模塊 B 后面的層。在這個設計里,模塊 A 直接跟模塊 B 后面的所有層連接在了一起。這也是它被稱為“稠密連接”的原因。
DenseNet的主要構建模塊是稠密塊(dense block)和過渡層(transition layer)。前者定義了輸入和輸出是如何連結的,后者則用來控制通道數,使之不過大。
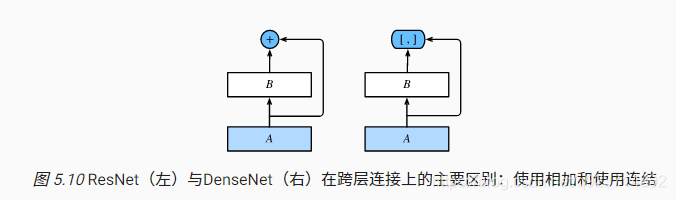
稠密塊
DenseNet使用了ResNet改良版的“批量歸一化、激活和卷積”結構,我們首先在conv_block函數里實現這個結構。
def conv_block(num_channels):blk = nn.Sequential()blk.add(nn.BatchNorm(), nn.Activation('relu'),nn.Conv2D(num_channels, kernel_size=3, padding=1))return blkclass DenseBlock(nn.Block):def __init__(self, num_convs, num_channels, **kwargs):super(DenseBlock, self).__init__(**kwargs)self.net = nn.Sequential()for _ in range(num_convs):self.net.add(conv_block(num_channels))def forward(self, X):for blk in self.net:Y = blk(X)X = nd.concat(X, Y, dim=1) # 在通道維上將輸入和輸出連結return X
過渡層
由于每個稠密塊都會帶來通道數的增加,使用過多則會帶來過于復雜的模型。過渡層用來控制模型復雜度。它通過 1×1 卷積層來減小通道數,并使用步幅為2的平均池化層減半高和寬,從而進一步降低模型復雜度。
def transition_block(num_channels):blk = nn.Sequential()blk.add(nn.BatchNorm(), nn.Activation('relu'),nn.Conv2D(num_channels, kernel_size=1),nn.AvgPool2D(pool_size=2, strides=2))return blk
DenseNet模型
我們來構造DenseNet模型。DenseNet首先使用同ResNet一樣的單卷積層和最大池化層。
net = nn.Sequential()
net.add(nn.Conv2D(64, kernel_size=7, strides=2, padding=3),nn.BatchNorm(), nn.Activation('relu'),nn.MaxPool2D(pool_size=3, strides=2, padding=1))
類似于ResNet接下來使用的4個殘差塊,DenseNet使用的是4個稠密塊。同ResNet一樣,我們可以設置每個稠密塊使用多少個卷積層。這里我們設成4,從而與上一節的ResNet-18保持一致。稠密塊里的卷積層通道數(即增長率)設為32,所以每個稠密塊將增加128個通道。
ResNet里通過步幅為2的殘差塊在每個模塊之間減小高和寬。這里我們則使用過渡層來減半高和寬,并減半通道數。
num_channels, growth_rate = 64, 32 # num_channels為當前的通道數
num_convs_in_dense_blocks = [4, 4, 4, 4]for i, num_convs in enumerate(num_convs_in_dense_blocks):net.add(DenseBlock(num_convs, growth_rate))# 上一個稠密塊的輸出通道數num_channels += num_convs * growth_rate# 在稠密塊之間加入通道數減半的過渡層if i != len(num_convs_in_dense_blocks) - 1:num_channels //= 2net.add(transition_block(num_channels))
同ResNet一樣,最后接上全局池化層和全連接層來輸出
net.add(nn.BatchNorm(), nn.Activation('relu'), nn.GlobalAvgPool2D(),nn.Dense(10))
八,批量歸一化
從零開始實現
下面我們通過NDArray來實現批量歸一化層。
def batch_norm(X, gamma, beta, moving_mean, moving_var, eps, momentum):# 通過autograd來判斷當前模式是訓練模式還是預測模式if not autograd.is_training():# 如果是在預測模式下,直接使用傳入的移動平均所得的均值和方差X_hat = (X - moving_mean) / nd.sqrt(moving_var + eps)else:assert len(X.shape) in (2, 4)if len(X.shape) == 2:# 使用全連接層的情況,計算特征維上的均值和方差mean = X.mean(axis=0)var = ((X - mean) ** 2).mean(axis=0)else:# 使用二維卷積層的情況,計算通道維上(axis=1)的均值和方差。這里我們需要保持# X的形狀以便后面可以做廣播運算mean = X.mean(axis=(0, 2, 3), keepdims=True)var = ((X - mean) ** 2).mean(axis=(0, 2, 3), keepdims=True)# 訓練模式下用當前的均值和方差做標準化X_hat = (X - mean) / nd.sqrt(var + eps)# 更新移動平均的均值和方差moving_mean = momentum * moving_mean + (1.0 - momentum) * meanmoving_var = momentum * moving_var + (1.0 - momentum) * varY = gamma * X_hat + beta # 拉伸和偏移return Y, moving_mean, moving_var
接下來,我們自定義一個BatchNorm層。它保存參與求梯度和迭代的拉伸參數gamma和偏移參數beta,同時也維護移動平均得到的均值和方差,以便能夠在模型預測時被使用。BatchNorm實例所需指定的num_features參數對于全連接層來說應為輸出個數,對于卷積層來說則為輸出通道數。該實例所需指定的num_dims參數對于全連接層和卷積層來說分別為2和4。
class BatchNorm(nn.Block):def __init__(self, num_features, num_dims, **kwargs):super(BatchNorm, self).__init__(**kwargs)if num_dims == 2:shape = (1, num_features)else:shape = (1, num_features, 1, 1)# 參與求梯度和迭代的拉伸和偏移參數,分別初始化成1和0self.gamma = self.params.get('gamma', shape=shape, init=init.One())self.beta = self.params.get('beta', shape=shape, init=init.Zero())# 不參與求梯度和迭代的變量,全在內存上初始化成0self.moving_mean = nd.zeros(shape)self.moving_var = nd.zeros(shape)def forward(self, X):# 如果X不在內存上,將moving_mean和moving_var復制到X所在顯存上if self.moving_mean.context != X.context:self.moving_mean = self.moving_mean.copyto(X.context)self.moving_var = self.moving_var.copyto(X.context)# 保存更新過的moving_mean和moving_varY, self.moving_mean, self.moving_var = batch_norm(X, self.gamma.data(), self.beta.data(), self.moving_mean,self.moving_var, eps=1e-5, momentum=0.9)return Y
接口實現
與我們剛剛自己定義的BatchNorm類相比,Gluon中nn模塊定義的BatchNorm類使用起來更加簡單。它不需要指定自己定義的BatchNorm類中所需的num_features和num_dims參數值。在Gluon中,這些參數值都將通過延后初始化而自動獲取。下面我們用Gluon實現使用批量歸一化的LeNet。
net = nn.Sequential()
net.add(nn.Conv2D(6, kernel_size=5),nn.BatchNorm(),nn.Activation('sigmoid'),nn.MaxPool2D(pool_size=2, strides=2),nn.Conv2D(16, kernel_size=5),nn.BatchNorm(),nn.Activation('sigmoid'),nn.MaxPool2D(pool_size=2, strides=2),nn.Dense(120),nn.BatchNorm(),nn.Activation('sigmoid'),nn.Dense(84),nn.BatchNorm(),nn.Activation('sigmoid'),nn.Dense(10))






)







 的認知)




